


ProtecTIER parsers
This appendix describes the ProtecTIER parsers that are used with various backup applications to improve deduplication ratios. It describes terminology, explains how metadata from backup applications hinders deduplication and what the ProtecTIER parser does to reverse this effect, and the supported parsers in ProtecTIER.
Read through this appendix to help you understand what workloads benefit from ProtecTIER parsers, and what are the causes of low deduplication ratios. It also reviews several sample environments and describes whether they benefit from parsers.
This appendix also describes the analyze_sessions utility to monitor a ProtecTIER parser.
The ProtecTIER parsers
The ProtecTIER product excels when it finds large matches that can be deduplicated. Some common backup applications add metadata, also known as backup application headers, to the backup stream for various purposes. This metadata interrupts the large matches, which hinders deduplication. The ProtecTIER parsers separate the metadata from the backup stream dynamically, leaving the user data to deduplicate without interruptions. When the data is restored, the ProtecTIER product adds the metadata back in to the data stream so that the backup application can use it.
The following sections describe terminology, why the ProtecTIER product needs a parser, and the causes of fragmented data, which hinders the matches and ProtecTIER performance and deduplication ratios. They also review several sample environments and describe whether they benefit from parsers.
Terminology
Consider the following terms:
•New data and old data
The users’ servers send data to the ProtecTIER server, which deduplicates the data. On arrival at the ProtecTIER server, the data is first passed through the deduplication engine, which searches for the data in the repository. Some data is not found (the new data) and some is found (the old data).
•Change rate
The change rate is the ratio of new data to total data in the backup, that is, the percentage of data that the deduplication engine did not find.
•Old data not factored
The ProtecTIER server examines the old data and might decide that some of it cannot be deduplicated efficiently because doing so would introduce fragmentation and affect the restore performance. The percentage of data in these cases is called old data not factored, that is, the percent of data that could not be stored effectively.
•System change rate
In terms of deduplication, both the change rate and old data not factored represent data that was written to the ProtecTIER disk without being deduplicated. Their sum is termed the system change rate, that is, the percentage of data that could not be deduplicated because the data was either new to the repository or because deduplicating the data would cause unacceptable fragmentation.
|
Note: System change rate = change rate + old data not factored.
|
How metadata from the backup application hinders deduplication
Some backup applications insert metadata into the backup stream for various control purposes by prefixing each block of user data with a small header that includes items such as the sequence number, session identifier, and cartridge bar code.
Figure C-1 shows how a backup application adjusts the sequence of user data by inserting its headers (the backup application metadata) at regular intervals in the tape image.

Figure C-1 Backup applications inserting metadata at regular intervals
The headers are always at regular intervals regarding the start of the tape cartridge. Figure C-2 shows how this spacing affects the tape image if the user data changes its configuration, perhaps because of an insertion of data (for example, the A-tag in Figure C-2). The block B in the original tape image is unchanged, but in the modified tape image, this block is split between B1 and B2, separated by a header.

Figure C-2 Top - changes to data; bottom - fragmented data
The deduplication engine finds the B1 and B2 data blocks, but the backup application header between them interrupts their original sequence. The ProtecTIER server needs one pointer for B1 (pointing to part of the original data in B). A second pointer points to where the data of the backup application header is stored (not shown in Figure C-2). A third pointer is needed to point to the location that stores the data of segment B2.
The sequence of backup application headers introduces artificial change. Because the data in the backup image is shifted, it has a ripple effect all the way to the end of the backup or the end of the virtual cartridge. This effect multiplies the number of pointers that are needed to store the new data. Each of these pointers point to smaller data segments than the previous backup. Each generation of the backup potentially amplifies the fragmentation. The cost of adding a pointer to these fragments of old data eventually becomes so high, both in terms of extra I/Os and extra space, that the ProtecTIER server decides not to add the pointers. This old data is merged with adjacent new data and stored again as though it were new. This is how fragmentation leads to old data not factored.
ProtecTIER parser functionality
A ProtecTIER parser reverses the effect of the backup application headers by extracting them from the data stream. The backup data then deduplicates much better against previous backups and other data that is in the repository. When a user asks to restore the data, the ProtecTIER product reinserts the metadata in to the backup stream before it returns it to the backup application.
A ProtecTIER parser examines the start of each backup stream to determine whether the backup application is one that it needs to parse. If the backup application is not identified as needing a parser, the rest of the cartridge is processed normally. If the backup application needs parsing, the parser infrastructure sets up a mechanism in the data path that extracts the backup application headers from the user data. The backup application headers are compressed and stored separately. The remaining user data is now free of the backup application headers and the ripple effects that they cause, and is passed on to the deduplication engine.
The usage of a parser introduces a performance effect that is below 3%.
Deduplication ratios can increase by as much as the value of old data not factored, depending on the characteristics of the data, because the benefit is achieved by avoiding fragmentation. To estimate the expected improvement on your system, see “Estimating the benefit of a parser” on page 466.
ProtecTIER parsers support
Applications like Commvault, Legato, IBM Spectrum Protect (formerly Tivoli Storage Manager), and NetWorker add metadata to the backup stream.
|
Notes:
•Starting with version 7.1.3 Tivoli Storage Manager was rebranded to IBM Spectrum Protect.
•For legacy and reference purposes, we continue to refer to the parser that was built for Tivoli Storage Manager as the Tivoli Storage Manager parser.
|
For VTL models of the ProtecTIER product, the following ProtecTIER parsers are available:
•Commvault: Parser available since IBM acquired ProtecTIER.
•Legato parser
– ProtecTIER V2.3.4 and V2.4.1 introduced a parser for Legato 7.4/7.5/7.6 (May/June 2010)
– ProtecTIER V2.4.7 and V 2.5.5 introduced a parser for Legato 7.6.1.6 (August 2011)
•Tivoli Storage Manager): ProtecTIER V3.1.4 introduced a parser for Tivoli Storage Manager V5.5 and later (October 2011).
For CIFS models of ProtecTIER servers, the following ProtecTIER parsers are available:
•IBM Spectrum Protect (formerly Tivoli Storage Manager).
|
Important: When you use the Tivoli Storage Manager parser with a CIFS model of the ProtecTIER product, use the DATAFormat = NATive option with the disk storage pool definitions. This value is the default value and is the format that the CIFS ProtecTIER Tivoli Storage Manager parser recognizes. Do not use the DATAFormat-NONblock option.
|
•Commvault
A Legato parser was not written for CIFS because Legato settings make it unnecessary. Legato users should choose Advanced File rather than File disk storage when setting up the CIFS share on a ProtecTIER server. This setting does not require a parser.
|
Backup applications and parsers: Sometimes, although rarely, new versions of backup applications introduce changes to the format of headers that they insert in the tape stream. This situation might cause the ProtecTIER parser to miss headers. Although this situation does not risk backup data in any way, it can cause deduplication to drop as the old data not factored increases. ProtecTIER Quality Assurance monitors the new versions of these backup applications, so check with ProtecTIER Support before you upgrade backup applications. Support can advise whether there is a change in the efficiency of the parser at that level.
|
What workloads benefit from the ProtecTIER parsers
The deduplication ratio that is achieved by a backup is affected by two key factors:
•The change rate of the data (change rate): This rate depends on how much the data in the backup changes from day to day and some of the parameters that are set as part of the backup (for example, encryption, compression, and multiplexing).
•The amount of data that is not factored (old data not factored): This rate can be high in environments where changes are interspersed throughout the data, causing fragmentation, such as might happen with a backup application that inserts metadata.
The ProtecTIER parsers are designed to reduce the amount of old data not factored and therefore increase the deduplication ratio in environments where the backup application inserts metadata in the backup stream. A system with a larger percentage of data in this category (for example, 15%) benefits more from adding a ProtecTIER parser than a system with a smaller amount of data in this category (for example, 3%).
|
High change rate: If the system also has a high change rate, the benefit from the parser might be less noticeable.
|
Workloads that achieve lower deduplication ratios because of a high change rate should look at other avenues to increase the deduplication rate.
Background information: Causes of low deduplication ratios
There are two bases to good deduplication:
•The first and most important is multiple copies of the data. If multiple copies of the data do not exist, deduplication does not occur.
•The second is the similarity between (successive) copies. If the copies are similar (low-change rate), they deduplicate well.
Poor deduplication is caused by not enough copies or too much change between copies. However, sometimes successive copies are similar but the changes are small and evenly distributed. In this case, the storage system cannot effectively store just the changes, but must rewrite some of the common data as though it were new. This phenomenon is measured by old data not factored.
The objective of parsers in the ProtecTIER environment is to focus on the old data not factored that is caused by the backup application headers in the backup stream. By removing these headers and storing them separately, the ProtecTIER parsers remove a cause of small and evenly distributed change that interferes with the underlying user data. This action prevents some of the fragmentation in the data and the extra pointers that are needed to track
the data.
the data.
Often, the number of copies of the data (retention) is set by company policy. The old data not factored is controlled by characteristics of the actual and imposed changes. If the deduplication ratio is still low, then reducing the change rate is the best place to concentrate your efforts. Many causes of a high change rate exist. Some common causes of high-change rate are as follows:
•Multiplexed backups: Some backup applications intermix backups from multiple sources in to the same (virtual) tape image. This situation causes the deduplication engine to try to search too many different sources for common data. A similar phenomenon occurs if the order of files in the backup does not remain stable.
•Backup of compressed or encrypted data: Sometimes unchanged compressed files deduplicate by using their previous backup as a reference, but in general, compressed or encrypted data does not deduplicate well.
•Cross-deduplication between files with similar content but a different layout: This situation can happen when different VM images are backed up. Each VM has similar files in it, but their layout in each VM's file system is different.
•Files with common data but high internal change: Some applications occasionally reorganize, defragment, or reindex their data. Backups that are made immediately after these operations are not likely to deduplicate well.
In extreme cases, the ProtecTIER product has a set of parameters that control the deduplication engine and the storage system. ProtecTIER Level 3 support can suggest parameter changes to help in cases of poor deduplication.
Estimating the benefit of a parser
The guidance in this section can help you estimate the benefit of a parser.
Consider a hypothetical system with a change rate of 20% and old data not factored of 13.3% before you implement the parser. This situation means that the system change rate is 33.3% and the user sees one-third of the data change each backup, or two-thirds of the data deduplicated. Such a system might reach a deduplication ratio of 3:1 (before compression) if sufficient backup copies are retained. If the parser reduces the old data not factored to 5%, then the system change rate drops to 25%, and the user sees one-quarter of the data change each backup. The system might now reach a 4:1 deduplication ratio (before compression) if sufficient backup copies are retained. If compression achieves a 2:1 ratio, then this system can improve from 6:1 to 8:1 ratio.
ProtecTIER Support can review a system and provide the figures for change rate and old data not factored to help with this calculation.
Environments that benefit from parsers
The following four cases illustrate scenarios in two application environments: NetBackup and Tivoli Storage Manager. The cases that are provided demonstrate environments where a parser would be helpful in improving deduplication ratio and sometimes performance. Each case has a graph that shows the change rate and old data not factored values. The graphs were created by using data from a ProtecTIER server and a spreadsheet graphing tool.
Case 1: Low change rate and low old data not factored
This case shows a customer who is using NetBackup. The workload has a low change rate and low old data not factored values Figure C-3. This workload does not need a parser.

Figure C-3 Case 1 - low change rate and low old data not factored
Case 2: Moderate change rate and high old data not factored
Figure C-4 shows a case where a parser is effective. The backup application is Tivoli Storage Manager. The change rate is moderate, but the old data not factored is high.

Figure C-4 Case 2 - moderate change rate and high old data not factored
Case 3: High change rate, moderate to low old data not factored
In Figure C-5, the change rate is high and the old data not factored is moderate to low. A parser might help, but the benefit that it offers is marginalized by the high change rate. In this case, the best action might be to look for causes of the high change rate in the environment and try to reduce that value.

Figure C-5 Case 3 - high change rate, moderate to low old data not factored
Case 4: High change rate, low old data not factored
Taking Case 3 to an extreme, Figure C-6 shows a ProtecTIER installation that reports a high change rate and a low old data not factored. The Tivoli Storage Manager parser does not help in this situation, and the best action is to look for causes of the high change rate in the environment.
|
Note: Starting with version 7.1.3 Tivoli Storage Manager was rebranded to IBM Spectrum Protect. For legacy and reference purposes, we continue to refer to the parser that was built for Tivoli Storage Manager as the Tivoli Storage Manager parser.
|

Figure C-6 Case 4 - high change rate, low old data not factored
Experience from one user site
Figure C-7 tracks the change in old data not factored of a ProtecTIER installation. It shows about four weeks of history while the site was running a ProtecTIER version with no parser, and about six weeks after upgrading to a ProtecTIER version with a parser. Over a period of one week after the upgrade, the old data not factored dropped fairly rapidly from 6% to 3% (approximately).
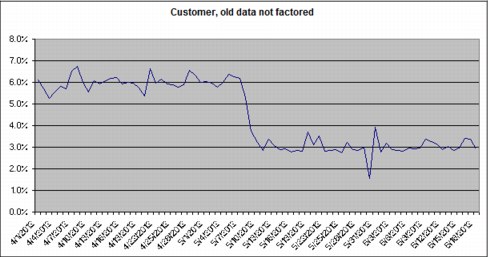
Figure C-7 Change in old data not factored at a user site after implementing a ProtecTIER parser
Not every site upgrading to a ProtecTIER release with a parser sees such an immediate improvement in the old data not factored. The actual improvement depends on many factors outside of the ProtecTIER product.
Use the analyze_sessions utility to monitor the benefit of a ProtecTIER parser
You can monitor changes in the deduplication ratio at a fine-grain level, whether it is at a per cartridge, per session, daily, or even hourly level.
The analyze_sessions utility assists with understanding the deduplication of the workloads sent to the ProtecTIER. It examines the deduplication logs of the ProtecTIER cluster and produces a report with the deduplication split (by default) into sessions. The definition of a session is a period of system ingest activity. A session ends when there is a short break in the I/O, during which the ProtecTIER product is idle. There can be therefore one session that covers a multiple hour period, or many sessions in an hour.
The analyze_sessions utility is in the /opt/dtc/app/utils directory on a ProtecTIER server. This utility examines the deduplication logs in their default location in the repository of the ProtecTIER server and generates a report on the deduplication that is achieved by the ProtecTIER cluster. The report is in CSV format and is placed in the /pt_work directory. The report is best viewed by using a spreadsheet program, which can also be used to plot the deduplication ratios of the sessions and their trends.
Several parameters can be used with analyze_sessions:
-n <number> Report only <number> of months back.
-s <start date> Start reporting only from date (date format is YYYY-MM-DD-HH-MM).
-e <end date> Report only up until the end date.
-sd <directory> The directory that contains the deduplication logs (if it is not the
default location).
default location).
-min Report only overall statistics.
-daily Include a daily summary.
-hourly Include an hourly summary.
-d <minutes> The number of minutes of idle time that defines a session boundary.
-i <file of carts> The file that contains a list of cartridge bar codes. Only these bar codes are reported.
-c Used with -i. Create a separate file for each cartridge.
-l Used with -i. Add a line to the report for each cartridge.
-o <output> Specify an output file name other than the default.
Figure C-8 shows the default output of the analyze_sessions utility. The important fields are the system change rate (the effect of only the deduplication, not the compression), and the compressedBytesCount (the actual amount of data that is written to the repository by this session). The deduplication of a particular session (regarding all the data already in the repository) is column C divided by column F, and includes the effects of deduplication and compression of the data.

Figure C-8 Output from the analyze_sessions command
Planning for the Tivoli Storage Manager parser
|
Note: Starting with version 7.1.3 Tivoli Storage Manager was rebranded to IBM Spectrum Protect. For legacy and reference purposes, we continue to refer to the parser that was built for Tivoli Storage Manager, the Tivoli Storage Manager parser.
|
When a new parser is added to a ProtecTIER system, a slight performance degradation (less than 3%) might occur.
Initially, a temporary and slight decrease in deduplication ratio might occur and an increase in the space that is used in the repository because the newly parsed user backups might not match as well with the existing unparsed backups in the repository. After a few generations, a new steady state is reached, where parsed user backups deduplicate by using other parsed user backups as their reference for deduplication.
Because there are no interfering headers, old data not factored is expected to decline, causing the deduplication ratio to reach an improved level. Consequently, used space in the repository drops. Performance might also be improved because the ProtecTIER product processes data more efficiently when the deduplication level is higher.
For environments where the backup window is tight or the repository is full, clients should work with ProtecTIER Support before they load the first ProtecTIER release that contains the applicable parser. ProtecTIER Support has tools to analyze problem reports that give an historic breakdown of actual change rate and old data not factored. These figures can help you understand both the startup effect and how effective the parser is in improving deduplication ratio over time.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.