
Now that you understand some of the fundamental data structures used in today's software applications, you can use those data structures to organize the large amounts of data that your applications need to process. Sorting data into a logical order is a critical prerequisite for many of the algorithms in the chapters to come, and it is such a potential performance bottleneck that an enormous amount of research has been done over many decades to determine the most efficient way to sort various types of data. This chapter introduces three sorting algorithms that are easy to implement and are best suited to smaller sets of data, as their performance is O(N2). Chapter 7 covers more complex sorting algorithms with better performance characteristics for very large data sets.
This chapter discusses the following:
You already know from the real world how important sorting is when working with searching algorithms. To look up a word in a dictionary, you use an algorithm: You open the dictionary at a point roughly equivalent to the word's position in the sorted list of all the words in the dictionary. You then do a few quick narrowing searches until you find the page it's on, and then finally scan the page for the word. Now imagine the words in the dictionary were not sorted. You'd probably decide to give up because the time to search the unsorted data would be prohibitive, and you'd be right!
Without sorting, searching is impractical for very large sets of data. You could apply the same principle to many other types of data in the real world, such as the names in a phone book or the books on the shelves of a library. The problem with these examples is that you have never (I hope) had to deal with any of these types of data before they were sorted for you, so you've never had to create an efficient algorithm for sorting them. In the computer world, however, it is not uncommon to encounter sets of data just as large as these that arrive at your program unsorted, or in an order other than the one you need. A good grasp of the established algorithms helps you tackle this type of problem.
Sorting data into some kind of meaningful order requires a data structure that is capable of maintaining the order of its contents. As you learned in Chapter 4, this is the distinguishing feature of a list, so we will be using lists as the data structure on which the sorting algorithms operate.
After the objects to be sorted are contained in a list, all of the sorting algorithms are built upon two fundamental operations:
Comparing items to determine whether they are out of order
Moving items into sorted position
The advantages and disadvantages of each sorting algorithm are based on how many times these fundamental operations need to be performed and how expensive these operations are in performance terms. The task of comparing objects to determine whether they are sorted is a larger topic than you might at first imagine, so we will deal with it in the following section on comparators. The list data structure supports several methods for moving the objects—namely, get(), set(), insert(), and delete(). These operations are covered in detail in Chapter 3.
In Java, as in many other languages, when you wish to compare two integers, you can do something like the following:
int x, y;
...
if (x < y) {
...
}This works fine for primitive types, but things get more difficult when dealing with more complex objects. For example, when you look at a list of files on your computer, you might typically look at them sorted by their filename. Sometimes, however, you might want to look at them in the order they were created, or the order in which they were modified, or even by the type of file they happen to be.
It is important to support different orderings without having to write a whole new algorithm. This is where comparators come in. A comparator is responsible for imposing a specific ordering on objects, so when you're trying to sort files, you might have one comparator for filenames, one for file types, and yet another for modification times. All these comparators would enable a single sorting algorithm to sort a list of file objects in different ways.
This is an example of an important design principle known as separation of concerns. In this case, you separate the concern of how to compare two individual objects (the comparator) from the concern of how to efficiently sort a large list of objects (the algorithm). This enables you to extend the usefulness of an algorithm by plugging in comparators that you had not imagined when creating it, and enables you to reuse a given comparator across multiple algorithm implementations to compare their performance.
A comparator consists of a single operation that enables you to compare two objects for relative order. It returns a negative integer, zero, or a positive integer, depending on whether the first argument is less than, equal to, or greater than the second, respectively. It throws a ClassCastException if the type of either object prevents them from being compared.
A comparator is very simple—it has a single method that enables you to compare two objects to determine whether the first object is less than, equal to, or greater than the second object. The following code shows the Comparator interface:
public interface Comparator {
public int compare(Object left, Object right);
}The compare operation takes two arguments: left and right. We have chosen to label them as such because, in this context, they are conceptually rather like the left-side and right-side arguments when comparing primitive values. When calling compare, if left comes before right (left < right), the result is an integer less than zero (usually −1); if left comes after right (left > right), the result is an integer greater than zero (usually 1); and if left equals right, the result of the comparison is zero.
In addition to the many custom comparators you will create, there are also a few standard comparators that will greatly simplify your application code. Each one is simple in concept and implementation yet quite powerful when used with some of the more complex algorithms discussed later in the book.
Many data types, especially primitives such as strings, integers, and so on, have a natural sort order: A comes before B, B comes before C, and so on. A natural comparator is simply a comparator that supports this natural ordering of objects. You will see that it is possible to create a single comparator that can sort any object that has a natural sorting order by basing it on a convention established by the Java language itself. Java has the concept of Comparable— an interface that can be implemented by any class you are using to provide a natural sort order.
The Comparable interface is simple, consisting of the single method shown here:
public interface Comparable {
public int compareTo(Object other);
}Similar to a Comparator, it returns a negative integer, a positive integer, or zero to indicate that one object comes before, after, or is equal to another, respectively. The difference between a Comparator and a Comparable object is that a Comparator compares two objects with each other, whereas a Comparable object compares another object with itself.
Sometimes you may want to have your own classes implement Comparable to give them a natural sort order. A Person class, for example, may be defined as sorting by name. The fact that this concept is reflected in the standard Java language enables you to create a generic Comparator for sorting based on the natural ordering of a type. You can create a Comparator that will work for any class that implements Comparable. The fact that many of the commonly used classes in the java.lang package implement this interface makes it a handy comparator to start with.
When you think about the desired behavior of the NaturalComparator, you can see that there are three possible scenarios to handle, one for each of the three possible types of comparison result. You already know that strings in Java implement Comparable, so you can use strings as test data. In the next Try It Out, you test and then implement the NaturalComparator.
Next, you determine whether a positive integer results when the left argument sorts after the right argument:
public void testGreaterThan() {
assertTrue(NaturalComparator.INSTANCE.compare("B", "A") > 0);
}Finally, when the two arguments are equal, you determine whether the result is zero:
public void testEqualTo() {
assertTrue(NaturalComparator.INSTANCE.compare("A", "A") == 0);
}The test case contains one test method for each of the three cases we identified above. Each test method assumes that the NaturalComparator provides a single static instance that you can use without needing to instantiate it. Each test method uses two simple character strings as test data to validate that the NaturalComparator behaves as expected.
To ensure this, you mark the constructor as private to prevent instantiation and instead provide a publicly accessible static variable holding the single instance of the class. You must also be sure to mark the class as final to prevent it from being extended erroneously.
Next you implement compare(). Because you are implementing this on top of the Comparable interface, most of the actual work will be performed by the arguments themselves, making the implementation almost trivial:
public int compare(Object left, Object right) {
assert left != null : "left can't be null";
return ((Comparable) left).compareTo(right);
}After first ensuring you haven't been passed a NULL argument, you cast the left argument to a Comparable and call the defined compareTo() method, passing the right argument.
You never check to see whether the left argument is actually an instance of Comparable because the Comparator interface specifically allows a ClassCastException to be thrown, meaning you can perform the cast without the additional check.
The NaturalComparator is designed to compare two objects that implement the Comparable interface. Many built-in Java objects implement this interface, and classes you create are free to implement it as well. The code only needs to cast the left operand to the Comparable interface so that it can call the compareTo() method, passing in the right operand for the comparison to be performed by the left operand itself. The comparator here is not actually required to implement any comparison logic because it is all handled by the objects themselves.
Often, you will want to sort things in reverse order. For example, when looking at a list of files on your computer, you may want to see the files from smallest to largest, or in reverse order from largest to smallest. One way to achieve a reverse version of the NaturalComparator described previously is to copy its implementation and reimplement the compare() method, as shown here:
public int compare(Object left, Object right) {
assert right != null : "right can't be null";
return ((Comparable) right).compareTo(left);
}You swap the right and left arguments, confirming that the right argument is not null and then passing the left argument to its compare() method.
Although this approach works perfectly well in this particular case, it isn't very extensible. For each complex type, such as Person or File, you always end up creating two comparators: one to sort ascending, and one to sort descending.
A better approach, which you take in the next Try It Out, is to create a generic comparator that wraps (or "decorates") another comparator and reverse the result. This way, you only need one comparator for each complex type you wish to sort. You use the generic ReverseComparator to sort in the opposite direction.
If the left argument would normally sort before the right, you want the ReverseComparator to cause the opposite to occur; that is, if the underlying comparator returns a negative integer, indicating that the left argument is less than the right argument, you need to ensure that the result from the ReverseComparator is a positive integer:
public void testLessThanBecomesGreaterThan() {
ReverseComparator comparator =
new ReverseComparator(NaturalComparator.INSTANCE);
assertTrue(comparator.compare("A", "B") > 0);
}If the underlying comparator returns a positive integer, indicating that the left argument would normally sort after the right, the result should be a negative integer:
public void testGreaterThanBecomesLessThan() {
ReverseComparator comparator =
new ReverseComparator(NaturalComparator.INSTANCE);
assertTrue(comparator.compare("B", "A") < 0);
}If the two arguments are equal, then the result must be zero:
public void testEqualsRemainsUnchanged() {
ReverseComparator comparator =
new ReverseComparator(NaturalComparator.INSTANCE);
assertTrue(comparator.compare("A", "A") == 0);
}The preceding code works by instantiating ReverseComparator objects and passing to them a NaturalComparator to which the comparison logic can be delegated. The first two test methods then make what look like nonsensical assertions: You know that A comes before B, but the opposite is true in this case, and the first test method makes sure this is the case. The second test method is similarly counterintuitive. The final test method ensures that objects that are equal remain equal when the ReverseComparator is used.
In the following Try It Out, you implement your ReverseComparator.
You start, of course, by implementing the Comparator interface and defining a constructor that accepts the underlying Comparator to which you will eventually delegate the compare call.
Then comes the actual implementation of compare:
public int compare(Object left, Object right) {
return _comparator.compare(right, left);
}At first glance, the code looks rather innocuous, simply delegating to the underlying comparator, but if you look carefully at the code, you will see that the two arguments are reversed before you pass them. If the ReverseComparator was called with (A, B), then the underlying comparator would be passed (B, A), thereby inducing the opposite result.
Because you don't actually need to access any of the attributes for either argument, this solution is completely generic; you need only implement it once to have a solution for all situations. You can now start to build your first sorting algorithm, the bubble sort algorithm.
Before implementing the bubble sort algorithm, you need to define some test cases for the implementation to pass. Because all of the sorting algorithms need to pass the same basic test (that is, prove that they actually sort objects correctly), you establish a base class for your unit tests to extend for each specific implementation. Each of the algorithms implements an interface so that they can be replaced easily. This means that you can use a single test case to prove any sorting algorithm's basic features, even one you haven't thought of yet!
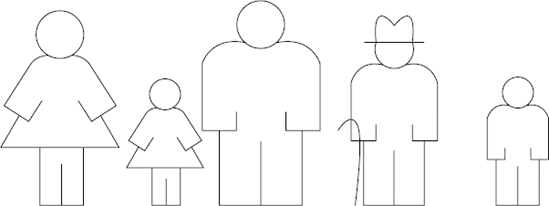
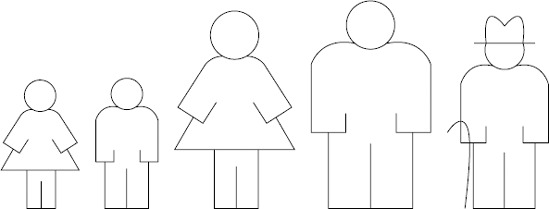
To apply a bubble sort to this problem, turn your attention to the two people at the left of the line of family members. Ask them which one is older. If the one on the right of the pair is older, then do nothing, as they are sorted relative to each other. If the one on the left is older, then ask them to swap positions. In this case, the swap needed to happen. Figure 6-2 shows the family after this first swap has taken place.
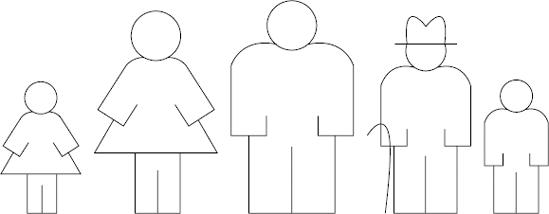
Now move your attention along the line one place to address the second and third people in the line. The second person has just been compared with the first person and is now about to be compared with the third person. Repeat the same procedure as before, asking them which one is older and swapping them if they are out of order.
By the time you get to the last pair on the line of people and perform any necessary swaps, what will have happened? Figure 6-3 shows the family group after this first pass.
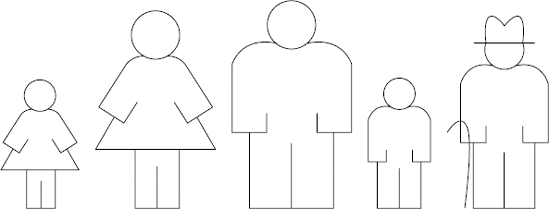
The group is by no means sorted, but the oldest person has bubbled up to the end of the line and is now in final sorted position. It probably seems like that was a lot of comparing and swapping just to get one person sorted, and that's true. Algorithms you'll see later have improved efficiency, but don't worry about that for now.
The next pass in the bubble sort algorithm is exactly the same as the first except you ignore the person at the right end of the line, as that person is already sorted. Starting at the far left again, do the same compare/swap process until the second oldest person is at the second rightmost position in the line, as shown in Figure 6-4.
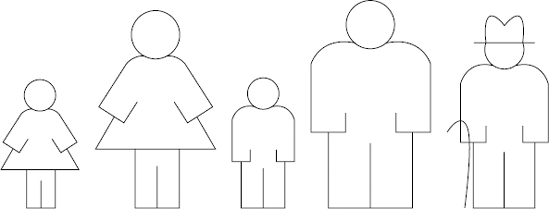
Continue in this way, gradually sorting the smaller and smaller remaining groups until the whole group is sorted. Now you can take your picture (see Figure 6-5).
Like many interfaces, the ListSorter interface is extremely simple, consisting of a single operation to sort a list.
The Sort operation accepts a list as its input and produces as its result a sorted version of the list. Depending on the implementation, the returned list might be the same as the provided list—that is, some implementations sort the list in place, whereas others create a new list.
Here is the code for the ListSorter interface:
public interface ListSorter {
public List sort(List list);
}Even though you have not yet written a single sorting algorithm, in the next Try It Out, you write a test that exercises any implementation of the ListSorter interface. This example uses an abstract test class, meaning that it can't be run until it has been extended for a specific sorting algorithm implementation. The actual implementation of the test for each specific algorithm will be trivial as a result.
AbstractListSorterTest performs the following tasks:
Creates an unsorted list of strings
Creates a sorted list of the same strings to act as an expected result for the test
Creates a
ListSorter(via an abstract method)Uses the
ListSorterto sort the unsorted listCompares the sorted list with the expected result list
Next, implement tearDown(), which frees the references to the two List objects:
protected void tearDown() throws Exception {
_sortedList = null;
_unsortedList = null;
}Finally, define the abstract method to create the specific sorting algorithm and the test itself:
protected abstract ListSorter createListSorter(Comparator comparator);
public void testListSorterCanSortSampleList() {
ListSorter sorter = createListSorter(NaturalComparator.INSTANCE);
List result = sorter.sort(_unsortedList);
assertEquals(result.size(), _sortedList.size());
Iterator actual = result.iterator();
actual.first();
Iterator expected = _sortedList.iterator();
expected.first();
while (!expected .isDone()) {
assertEquals(expected.current(), actual.current());
expected.next();
actual.next();
}
}The first two lines of the test method create the sorting algorithm implementation and use it to sort the unsorted list. You pass a natural comparator because your expected results have been set up in the natural sequence of the strings themselves. The bulk of the test verifies that the result of the sort matches the expected result list. You do this by creating an iterator over the lists and comparing each item in turn to ensure an item-by-item exact match. Every one of your sorting algorithms must be able to pass this test or it will be of very little use in practice!
In the following Try It Out, you make a test that is specific to your bubble sort implementation.
That's all you need to do to complete the test for the BubblesortListSorter. Of course, the preceding code won't compile yet, as we don't have a BubblesortListSorter class; that's what we'll do now. In the next Try It Out, you implement your bubble sort.
Despite the fact that you only implemented a single method with a single line of code, the key point here is that you are extending the AbstractListSorterTest class in the preceding code. The abstract class provides the test data and several test methods; all you need to do is provide the ListSorter implementation for these tests to use, and that's what you have done here.
With these guidelines in place, you begin implementation with the constructor, as shown here:
package com.wrox.algorithms.sorting;
import com.wrox.algorithms.lists.List;
public class BubblesortListSorter implements ListSorter {
private final Comparator _comparator;
public BubblesortListSorter(Comparator comparator) {
assert comparator != null : "comparator cannot be null";
_comparator = comparator;
}
...
}You now need to implement the bubble sort algorithm itself. Recall from the description of the algorithm that it is comprised of a number of passes through the data, with each pass resulting in one item being moved into its final sorted position. The first thing to determine is how many passes are needed. When all but the last item have been moved into their final sorted position, the last item has nowhere to go and must therefore also be in its final position, so you need a number of passes that is one less than the number of items. The code that follows calls this the outer loop.
On each pass, you compare each pair of items and swap them if they are out of order (as determined by the comparator you have been given). Remember, however, that on each pass, one item is moved into final sorted position and can therefore be ignored on subsequent passes. Therefore, each pass deals with one less item than the previous pass. If N is the number of items in the list, then on the first pass, the number of comparisons you need to make is (N – 1), on the second pass it is (N – 2), and so on. This is why the inner loop in the following code has the condition left < (size – pass) to control how many comparisons are performed:
public List sort(List list) {
assert list != null : "list cannot be null";
int size = list.size();
for (int pass = 1; pass < size; ++pass) { // outer loop
for (int left = 0; left < (size - pass); ++left) { // inner loop
int right = left + 1;
if (_comparator.compare(list.get(left), list.get(right)) > 0) {
swap(list, left, right);
}
}
}
return list;
}The preceding code uses the supplied comparator to determine whether the two items under scrutiny are out of order. If they are, then it calls the swap() method to correct their relative placement in the list. Here is the code for swap():
private void swap(List list, int left, int right) {
Object temp = list.get(left);
list.set(left, list.get(right));
list.set(right, temp);
}
}When you compile and run this test, it passes with flying colors. Just to make sure, you can place a deliberate mistake in the test's expectation and run it again to see that it will indeed catch you if you slip up when implementing your next sorting algorithm.
Imagine that you have a bookshelf filled with several books of varying sizes that are arranged haphazardly. Your mother is coming to visit, and to impress her with your housekeeping prowess, you decide to arrange the books neatly on the shelf in order from the tallest to the shortest. Figure 6-6 shows the bookshelf before you begin.
You'd be unlikely to use bubble sort in this case, because all that swapping would be a waste of time. You'd be taking each book out and putting it back on the shelf many times, and that would take too long. In this example, the cost of moving the items is relatively large when measured against the cost of comparing items. A selection sort is a better choice here, and you'll soon see why.
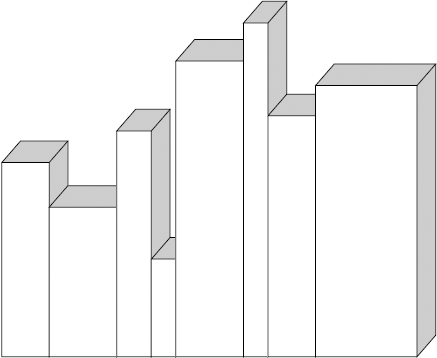
Start by scanning the shelf for the tallest book. Pull it out, as it needs to move to the far left of the shelf. Rather than move all the other books along the shelf to make room for it, just pull out the book that happens to be in the space where you want this one to go and swap them. Of course, the rest of the books will have to move a little because the books vary in thickness, but that won't matter in this software implementation, so just ignore that little issue. (Choosing to swap two books in this way, rather than slide all the books along, makes this implementation unstable, a topic covered later in this chapter, but don't worry about that for now.) Figure 6-7 shows how the shelf looks after your first swap.
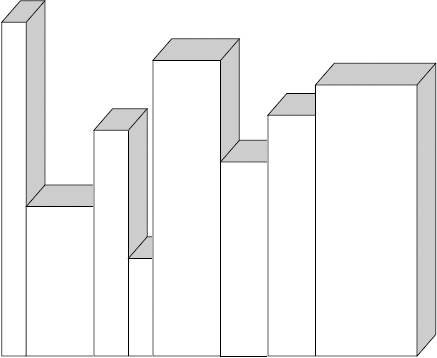
Leaving the tallest book where it is, scan the shelf for the tallest of the remaining books. Once you've found it, swap it with the book that happens to be just to the right of the tallest book. You now have sorted two books that you won't have to touch again. Figure 6-8 shows your shelf now.
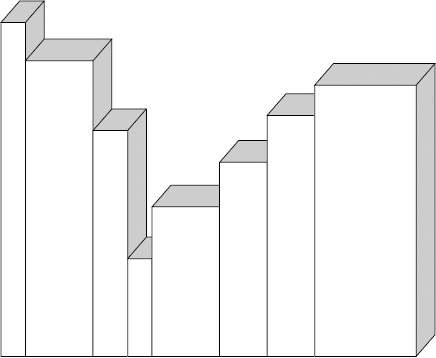
Leaving the largest books where they are, continue to scan the remaining books for the tallest among them, each time swapping it with the book that is just to the right of the already sorted books at the left end of the shelf. Each time you scan the shelf, you are selecting the next book in order and moving it into its final sorted position. That's why this algorithm is called selection sort. Figure 6-9 shows the shelf after each book is moved.
Sometimes, while scanning the unsorted books to find the tallest among them, you will find that it is already in position and no swap is required. You can see that after each book is moved, the set of sorted books grows, and the set of unsorted books shrinks until it is empty and the whole shelf is sorted. Each book is moved directly into its final sorted position, rather than taking small steps toward its final position (as in a bubble sort), which is a good reason to use this algorithm in this case.
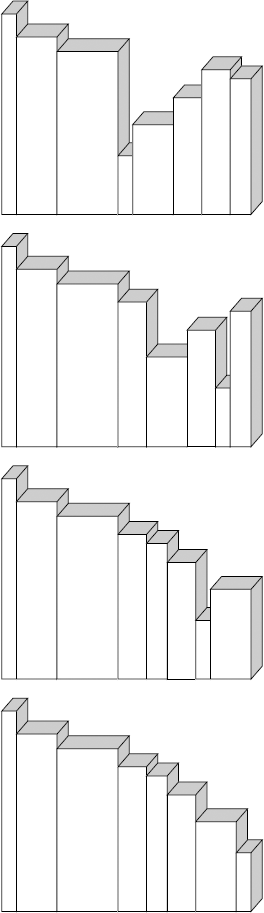
You can re-use a lot of the work you did with the bubble sort algorithm to test your selection sort. In the next Try It Out, you start by creating a test case for it and then implementing the algorithm itself, making sure it passes the test to prove you implemented it correctly.
In the next Try It Out, you implement SelectionSortListSorter.
Despite the fact that you only implemented a single method with a single line of code, the key point here is that you are extending the AbstractListSorterTest class in the preceding code. The abstract class provides the test data and several test methods; all you need to do is provide the ListSorter implementation for these tests to use, which is what you have done here.
The implementation has both an outer loop and an inner loop, like bubble sort, but there are subtle differences that might escape your attention if you don't look at this code closely. First, the outer loop index ranges between zero and (N – 2), rather than between 1 and (N – 1) in bubble sort. Note that this is still the same number of passes (N – 1), but it reflects your focus in the selection sort on filling a given "slot" with the right object on each pass. For example, on the first pass, your goal is to get the right object into position zero of the list. On the second pass, the goal is to fill position 1, and so on. Once again, you can get by with only (N – 1) passes because the last object naturally ends up in sorted position as a result of sorting every other object first.
No swapping occurs during the inner loop, as it did in bubble sort. During the inner loop, the only requirement is to remember the position of the smallest item. When the inner loop finishes, you then swap the smallest item into the slot you are trying to fill. This is slightly different from the earlier bookshelf example, in which the books were sorted from largest to smallest, but the algorithm would work just as well in that case. In fact, you simply plug in the ReverseComparator you created earlier in this chapter:
public List sort(List list) {
assert list != null : "list cannot be null";
int size = list.size();
for (int slot = 0; slot < size − 1; ++slot) { // outer loop
int smallest = slot;
for (int check = slot + 1; check < size; ++check) { // inner loop
if (_comparator.compare(list.get(check), list.get(smallest)) < 0) {
smallest = check;
}
}
swap(list, smallest, slot);
}
return list;
}There is also one small difference in the implementation of swap() for a selection sort when compared to a bubble sort. You add a guard clause to ignore requests to swap a slot with itself, which can occur quite easily with a selection sort, but not a bubble sort:
private void swap(List list, int left, int right) {
if (left == right) {
return;
}
Object temp = list.get(left);
list.set(left, list.get(right));
list.set(right, temp);
}
}Insertion sort is the algorithm very commonly used by people playing cards to sort the hand they have been dealt. Imagine you have been given five cards face down and you want to sort them according to the following rules:
Separate into suits in the following order: spades, clubs, diamonds, and hearts
Within each suit, sort in ascending order: Ace, 2, 3, . . ., 9, 10, jack, queen, king
Figure 6-10 shows your hand of cards, face down. They are unsorted, although they may already be in just the order you need. (Even if they are, the algorithm will need to run its course.)

You begin by turning over the first card. Nothing could be easier than sorting a single card, so you hold it in your hand on its own. In this case, it's the seven of diamonds. Figure 6-11 shows the current situation: one sorted card and four still unsorted cards lying face down.

Pick up the second card. It's the jack of spades. Because you know spades come before diamonds, you insert it into your hand to the left of your current card. Figure 6-12 shows the situation now.

Pick up the third card. In the example it's the ace of clubs. Looking at your two already sorted cards, this new one needs to be inserted between them. Figure 6-13 shows the state of your hand now.

An insertion sort works by dividing the data into two groups: already sorted items and unsorted items. Initially, the sorted group is empty and the unsorted group contains all the items. One by one, an item is taken from the unsorted group and inserted at the appropriate position in the growing group of sorted items. Eventually, all of the items are in the sorted group and the unsorted group is empty. Figure 6-14 shows what happens when you pick up the final two cards.
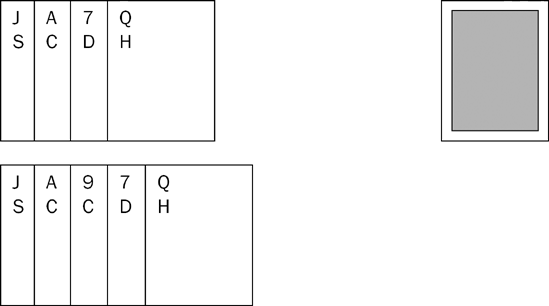
In the next Try It Out, you start by creating a test case for the insertion sort algorithm. Then you implement it to complete the three basic sorting algorithms for this chapter.
Although you implemented a single method with a single line of code, the key point here is that you are extending the AbstractListSorterTest class in the preceding code. The abstract class provides the test data and several test methods; all you need to do is provide the ListSorter implementation for these tests to use, and that's what you have done here.
The implementation of the sort() method is very different from the two algorithms you have seen earlier in the chapter. This algorithm does not sort the objects in place by rearranging the order of the list it is given; rather, this algorithm creates a new, empty list and inserts each item from the original list into the result list in sorted order.
In addition, the original list is processed using an iterator instead of accessing the items by index because you have no need for direct access to the items in the original list. You simply process each one in turn, which is the natural idiom for an iterator:
public List sort(List list) {
assert list != null : "list cannot be null";
final List result = new LinkedList();
Iterator it = list.iterator();
for (it.first(); !it.isDone(); it.next()) {
int slot = result.size();
while (slot > 0) {
if (_comparator.compare(it.current(), result.get(slot − 1)) >= 0) {
break;
}
−−slot;
}
result.insert(slot, it.current());
}
return result;
}Finally, notice that the inner loop is a while loop, rather than a for loop. Its task is to find the right position in the result list to insert the next item. After it finds the right position (or falls off the end of the result list), it exits the inner loop. The current item is then inserted into the result list. At all times, the result list is entirely sorted; each item is placed into position relative to those items already in the list, thereby maintaining the overall sorted sequence. This example uses a LinkedList for the result list because it is better suited to insertion operations.
Note also that the algorithm searches backwards through the result list looking for the right position, rather than forwards. This is a big advantage when it comes to sorting already sorted or nearly sorted objects, as demonstrated in the section "Comparing the Basic Sorting Algorithms," later in this chapter. It is also the reason why this algorithm is stable, which is the subject of the next section.
Some sorting algorithms share an interesting characteristic called stability. To illustrate this concept, examine the list of people sorted by their first names shown in Table 6-1.
Table 6.1. List Sorted by First Names
First Name | Last Name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Now imagine that you want to sort the same people by their last names. The list in Table 6-1 contains some common last names, such as Smith and Barnes. What would you expect to happen to the order of people with the same last name? You might expect that people with the same last name would be in the same relative order as the original list—that is, sorted by first name within the same last name group. This is stability. If a sorting algorithm maintains the relative order of items with a common sort key, it is said to be a stable algorithm.
Table 6-2 shows a stable last name sort of the people in this example.
Table 6.2. Stable Last Name Sort of Table 6-1
First Name | Last Name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Two of the three implementations discussed so far—bubble sort and insertion sort—are stable. It is simple to make the selection sort implementation stable. Some of the more advanced sorting algorithms in later chapters may be faster than the three you have seen here, but they often fail to preserve stability, and you should take this into account if it is important to your particular application.
Now that you have seen a number of sorting algorithms in action, and how you can easily plug in any implementation that supports the ListSorter interface, you might be wondering when to use which algorithm. This section compares each algorithm using a practical approach, rather than a theoretical or mathematical approach. This is not intended to give you a definitive list of criteria for selecting an algorithm; rather, it provides an example of how comparative analysis can be put to use when you need to make implementation choices in the systems you build.
Recall from the introduction to this chapter that sorting algorithms perform two basic steps many times: comparing items and moving items around. This discussion assesses the behavior of the three sorting algorithms with regard to the first of these operations and puts the algorithms through their paces using much larger data sets than you used when implementing them. This is important because any divergence in their relative performance will be clearer on larger sets of data. It is also important that each algorithm receive input data in varying arrangements, as follows:
Already sorted (the best case)
Already sorted but in reverse order from our desired order (the worst case)
Random order (the average case)
If you give each algorithm the same set of input data for each of these cases, then you can make an informed decision about the relative merits in a given real-world situation. The first task is to gather the information about how many times comparisons are made.
All comparisons in the sorting algorithms are performed by their respective comparator. To count the number of times the comparator's compare() method is called, you could alter the code for each comparator to specify that it remember the number of calls. Alternatively, you could make all the comparators extend a common base class and put the call counting behavior there. However, to re-use much of the code you've already written, you can add the call counting behavior by decorating any other comparator you already have, as you did with the ReverseComparator:
public final class CallCountingComparator implements Comparator {
private final Comparator _comparator;
private int _callCount;
public CallCountingComparator(Comparator comparator) {
assert comparator != null : "comparator cannot be null";
_comparator = comparator;
_callCount = 0;
}
public int compare(Object left, Object right) {
++_callCount;
return _comparator.compare(left, right);
}
public int getCallCount() {
return _callCount;
}
}Just like the ReverseComparator, the CallCountingComparator accepts any other Comparator in its constructor. The CallCountingComparator delegates the actual comparison check to this underlying comparator after incrementing the call count. All that is left is to provide the getCallCount() method to retrieve the call count when the sorting is complete.
With the help of the CallCountingComparator, you can now build a program to drive each of the sorting algorithms with best case, worst case, and average case test data and collect the results.
Although this is not actually a unit test, the program is written to drive the algorithms as a JUnit test case because you need to do some setup and run several discrete scenarios for each algorithm. You begin by creating the test class, a constant for the size of the lists of data, and instance variables for the best, worst, and average case data sets. You also need an instance variable that holds a reference to the CallCountingComparator created in the previous section:
package com.wrox.algorithms.sorting;
import junit.framework.TestCase;
import com.wrox.algorithms.lists.List;
import com.wrox.algorithms.lists.ArrayList;
public class ListSorterCallCountingTest extends TestCase {
private static final int TEST_SIZE = 1000;
private final List _sortedArrayList = new ArrayList(TEST_SIZE);
private final List _reverseArrayList = new ArrayList(TEST_SIZE);private final List _randomArrayList = new ArrayList(TEST_SIZE);
private CallCountingComparator _comparator;
...
}Next you set up the test data. For the best and worst cases, you fill the respective lists with Integer objects with values ranging between 1 and 1,000. For the average case, you generate random numbers within this same range. You also create the call counting comparator by wrapping a NaturalComparator. This works because java.lang.Integer supports the Comparable interface, just as the strings used in earlier examples do:
protected void setUp() throws Exception {
_comparator = new CallCountingComparator(NaturalComparator.INSTANCE);
for (int i = 1; i < TEST_SIZE; ++i) {
_sortedArrayList.add(new Integer(i));
}
for (int i = TEST_SIZE; i > 0; −−i) {
_reverseArrayList.add(new Integer(i));
}
for (int i = 1; i < TEST_SIZE; ++i) {
_randomArrayList.add(new Integer((int)(TEST_SIZE * Math.random())));
}
}To run each algorithm in the worst case, create the relevant Listsorter implementation and use it to sort the reverse-sorted list created in the setUp() method. The following code has a method to do this for each of our three algorithms. You might wonder how this works. If the reverse-sorted list is an instance variable and you first sort it using the bubble sort algorithm, how can it still be reverse-sorted when the next algorithm starts? This is one of the reasons you use JUnit to structure this driver program. JUnit creates a new instance of the driver class for each of the test methods, so each method in effect has its own copy of the reverse-sorted list, and setUp() will be run for each of them independently. This keeps the tests from interfering with one another:
public void testWorstCaseBubblesort() {
new BubblesortListSorter(_comparator).sort(_reverseArrayList);
reportCalls(_comparator.getCallCount());
}
public void testWorstCaseSelectionSort() {
new SelectionSortListSorter(_comparator).sort(_reverseArrayList);
reportCalls(_comparator.getCallCount());
}
public void testWorstCaseInsertionSort() {
new InsertionSortListSorter(_comparator).sort(_reverseArrayList);
reportCalls(_comparator.getCallCount());
}To produce its output, each of these methods uses the reportCalls() method, described later in this section. Next are three similar methods for the best-case scenario, in which each algorithm is used to sort the already sorted list created in setUp():
public void testBestCaseBubblesort() {
new BubblesortListSorter(_comparator).sort(_sortedArrayList);
reportCalls(_comparator.getCallCount());
}
public void testBestCaseSelectionSort() {
new SelectionSortListSorter(_comparator).sort(_sortedArrayList);
reportCalls(_comparator.getCallCount());
}
public void testBestCaseInsertionSort() {
new InsertionSortListSorter(_comparator).sort(_sortedArrayList);
reportCalls(_comparator.getCallCount());
}You create three more methods to test the average case using the randomly generated list of numbers:
public void testAverageCaseBubblesort() {
new BubblesortListSorter(_comparator).sort(_randomArrayList);
reportCalls(_comparator.getCallCount());
}
public void testAverageCaseSelectionSort() {
new SelectionSortListSorter(_comparator).sort(_randomArrayList);
reportCalls(_comparator.getCallCount());
}
public void testAverageCaseInsertionSort() {
new InsertionSortListSorter(_comparator).sort(_randomArrayList);
reportCalls(_comparator.getCallCount());
}Lastly, you define the reportCalls() method that produces the output for each scenario defined previously:
private void reportCalls(int callCount) {
System.out.println(getName() + ": " + callCount + " calls");
}This simple code contains one subtle point of interest. It uses the getName() method provided by the JUnit TestCase superclass to print the name of the scenario itself. The output produced by the program for the worst case is shown here:
testWorstCaseBubblesort: 499500 calls testWorstCaseSelectionSort: 499500 calls testWorstCaseInsertionSort: 499500 calls
As you can see, all three algorithms do exactly the same number of comparisons when tasked with sorting a completely reverse-sorted list! Don't take this to mean that they will always take the same amount of time to run; you are not measuring speed here. Always be careful to avoid jumping to conclusions based on simple statistics like those here. That said, this is a very interesting thing to know about these algorithms in this particular scenario.
The following numbers are produced for the best case:
testBestCaseBubblesort: 498501 calls testBestCaseSelectionSort: 498501 calls testBestCaseInsertionSort: 998 calls
Once again, the results are interesting. The bubble and selection sorts do the same number of comparisons, but the insertion sort does dramatically fewer indeed. You might want to review the insertion sort implementation now to see why this is the case.
The following numbers are produced in the average case:
testAverageCaseBubblesort: 498501 calls testAverageCaseSelectionSort: 498501 calls testAverageCaseInsertionSort: 262095 calls
Once again, the bubble and selection sorts performed the same number of comparisons, and the insertion sort required about half the number of comparisons to complete its job.
You can draw a few conclusions from the comparative analysis just performed, but you must be careful not to draw too many. To really understand the difference in their behavior, you would need to run additional scenarios, such as the following:
Quantifying how many objects are moved during the sort
Using both
LinkedListandArrayListimplementations for the test dataMeasuring running times for each scenario
Bearing the limitations of the analysis in mind, you can make the following observations:
Bubble and selection sorts always do exactly the same number of comparisons.
The number of comparisons required by the bubble and selection sorts is independent of the state of the input data.
The number of comparisons required by an insertion sort is highly sensitive to the state of the input data. At worst, it requires as many comparisons as the other algorithms. At best, it requires fewer comparisons than the number of items in the input data.
Perhaps the most important point is that bubble and selection sorts are insensitive to the state of the input data. You can, therefore, consider them "brute force" algorithms, whereas the insertion sort is adaptive, because it does less work if less work is required. This is the main reason why the insertion sort tends to be favored over the other two algorithms in practice.
Highlights of this chapter include the following:
You implemented three simple sorting algorithms—the bubble sort, the selection sort, and the insertion sort—complete with unit tests to prove they work as expected.
You were introduced to the concept of comparators, and implemented several of them, including the natural comparator, a reverse comparator, and a call counting comparator.
You looked at a comparative investigation of the three algorithms so that you can make informed decisions about the strengths and weaknesses of each.
The idea of stability as it relates to sorting was also discussed.
Having worked through this chapter, you should understand the importance of sorting and the role it plays in supporting other algorithms, such as searching algorithms. In addition, you should understand that there are many ways to achieve the simple task of arranging objects in sequence. The next chapter introduces some more complex sorting algorithms that can sort huge amounts of information amazingly well.
Write a test to prove that each of the algorithms can sort a randomly generated list of double objects.
Write a test to prove that the bubble sort and insertion sort algorithms from this chapter are stable.
Write a comparator that can order strings in dictionary order, with uppercase and lowercase letters considered equivalent.
Write a driver program to determine how many objects are moved by each algorithm during a sort operation.