
Chapter 4. Separation of Concerns
“separation of concerns” … is what I mean by “focusing one’s attention upon some aspect”: it does not mean ignoring the other aspects, it is just doing justice to the fact that from this aspect’s point of view, the other is irrelevant. It is being one- and multiple-track minded simultaneously.Edsger Dijkstra, On the role of scientific thought
Our source code has grown. 1 Depending on the language, it’s 50-75 lines in one source file. That’s more than a screenful on many display monitors and certainly more than a printed page in this book.
Before we get to the next feature, we’ll spend some time refactoring our code. That’s the subject of this and the next three chapters.
Test and Production Code
Thus far, we’ve written two different types of code.
-
Code that solves our Money problem. This includes
MoneyandPortfolioand all the behavior therein. We call this Production Code -
Code that verifies that the problem is correctly solved. This includes all the tests and the code needed to support these tests. We call this Test Code.
There are similarities between the two types of code: they are in the same language, we write them in quick succession (through the by-now familiar RED-GREEN-REFACTOR cycle), and we commit both to our code repository. However, there are a few key differences between the two types of code.
Unidirectional Dependency
Test code has to depend on Production code — at least on those parts of Production code that it tests. However, there should be no dependencies in the other direction.
Currently, all our code for each language is in one file, as shown in Figure 4-1. So it’s not easy to ensure that there are no accidental dependencies from production code to test code. There is an implicit dependency from the test code to the production code. This has a couple of implications:
-
When writing code, we have to be careful to not accidentally use any test code in our production code.
-
When reading code, we have to recognize the patterns of usage and also notice the missing patterns, i.e. the fact that production code cannot call any test code.
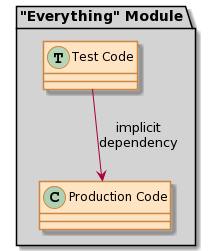
Figure 4-1. When test code and production code are in the same module, the dependency from the former to the latter is implicit
Important
Test code depends on production code; however there should be no dependency in the other direction.
What bad results can ensue if production code is dependent on test code? In particularly bad cases, it can mislead us to a path where the code-path that is tested is “pristine” whereas the paths that are not tested are fraught with bugs. An example is shown in Figure 4-2, which shows how a portion of the pseudocode for the engine control unit in a car. The code works differently if the engine is being tested for emissions-compliance from when the engine is being used “in real world”.

Figure 4-2. Accidental dependency of production code on test code can create production code-paths that behave differently and in untested ways.
If you’re skeptical that such a blatant case of “be on your best behavior for tests” can never happen in reality, you’re encouraged to read about the Volkswagen emissions scandal, from which the above pseudocode is drawn. 2
Having a unidirectional dependency — where production code does not depend on test code in any way and is therefore not susceptible to behaving differently when under test — is vital to ensuring defects of this nature (whether accidental or malicious) do not creep in.
Dependency Injection
Dependency injection is a practice to separate the creation of an object from its usage. It increases the cohesion of code and reduces its coupling. Dependency injection requires different code units (classes and methods) to be independent from each other. Separating test and production code is an important prerequisite to facilitating dependency injection.
We’ll have more to say about dependency injection in Chapter 11, where we’ll use it to improve the design of our code.
Packaging and Deployment
When application code is packaged for deployment, the test code is almost always packaged separately from production code. This allows deploying production and test code independently. Often, only production code is deployed in certain “higher” environments such as the Production environment. This is shown in Figure 4-3.
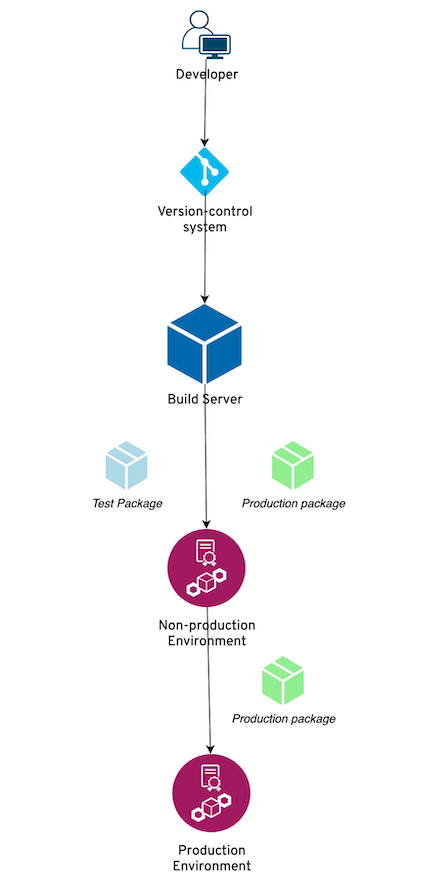
Figure 4-3. Test code should be packaged separately from production code, so that they can be deployed independently via the CI/CD pipeline
We’ll describe deployment in more detail in Chapter 13, when we build a continuous integration pipeline for our code.
Modularization
The first thing we’ll do is to separate the test code from the production code. This will require us to solve the problem of “including”, “importing”, or “requiring” the production code in the test code. It is vital that this should always be a one-way dependency, as shown in Figure 4-4.
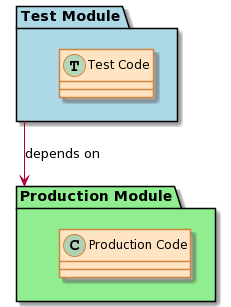
Figure 4-4. Only Test Code should depend on Production Code, not the other way around
In practice, this means that the code should be modularized along these lines:
-
The test and production code should be in separate source files. This allows us to read, edit, and focus on test or production code independently.
-
The code should be use namespaces to clearly identify which entities belong together. A namespace can be a “modules” or “packages”, depending on the language.
-
Insofar as it’s possible, there should be an explicit code directive —
import,require, or similar, depending on the language — to indicate that one module depends on another. This ensures that we can specify the dependency shown in Figure 4-1 explicitly.
We’ll also look for opportunities to make code more self-describing. This would include renaming and reordering entities, methods, and variables to better reflect their intent.
Removing Redundancy
The second thing we’ll do is to remove redundancy in our tests.
We have had two multiplication tests for a while now; one for Euros and one for Dollars. They test the same functionality. In contrast, we have only one test for division. Should we keep both the multiplication tests?
There is seldom an ironclad “yes” or “no” answer to this. We could argue that the two tests protect us from inadvertently hard-coding the currency in the code that does the multiplication — although that argument would be weakened by the fact that we have one test for division and a similar hard-coded currency error could crop up there.
To make it a more objective exercise whether we should delete tests, here is a checklist:
-
Would we have the same code coverage if we delete a test? Line Coverage is a measure of the number of executable lines of code that are executed when running a test. In our case, there would be no loss of coverage if we deleted either one of the multiplication tests.
-
Does one of the tests verify a significant edge case? If, for example, we were multiplying a really large number in one of our tests and our goal was to ensure that there was no overflow/underflow on different CPUs and operating systems, we could make the case for keeping both tests. However, that is also not the case for our two multiplication tests.
-
Do the different tests provide unique value as living documentation? For example, if we were using currency symbols from beyond the alphanumeric character set ($, €, ₩), we could say that displaying these disparate currency symbols provides additional value as documentation. However, we are currently using letters drawn from the same 26 English alphabet (USD, EUR, KRW) for our currencies; so the variation between currencies provides minimal documentation value.
Tip
Line (or Statement) Coverage, Branch Coverage, and Loop Coverage are three different metrics that measure how much of a given body of code has been tested.
Where We Are
In this chapter, we reviewed the significance of separation of concerns and removing redundancy. These are the two goals that will garner our attention in the following three chapters.
Let’s update our feature list to reflect that:
5 USD x 2 = 10 USD |
10 EUR x 2 = 20 EUR |
4002 KRW / 4 = 1000.5 KRW |
5 USD + 10 USD = 15 USD |
Separate test code from production code |
Remove redundant tests |
5 USD + 10 EUR = 17 USD |
1 USD + 1100 KRW = 2200 KRW |
Our goals are clear. The steps to accomplish these — especially the first goal of separation of concerns — will vary significantly from language to language. Therefore, the implementation has been separated into the next three chapters.
-
Chapter 5 - Packages and Modules in Go
-
Chapter 6 - Modules in JavaScript
-
Chapter 7 - Modules in Python
Read these chapters in the order that makes most sense to you. Refer to “How to read this book” for guidance.
1 Remember: you can access the complete source code for this book, including intermediate commits, at https://github.com/saleem/tdd-book-code.
2 On the Volkswagen “dieselgate” scandal, Felix Domke has done a lot of work. There is a whitepaper (of which he’s a co-author) https://cseweb.ucsd.edu/~klevchen/diesel-sp17.pdf . He also delivered a keynote at the Chaos Computer Club conference. https://media.ccc.de/v/32c3-7331-the_exhaust_emissions_scandal_dieselgate