
CHAPTER 9
A SAMPLE OF ADDITIONAL TOPICS
Chapters 2 through 8 all have a theme. For example, regular expressions and data structures underlie chapters 2 and 3, respectively, and chapter 8 focuses on clustering. This one, however, covers three topics in less detail. The goal is to give the interested reader a few parting ideas as well as a few references for text mining.
Not only is Perl free, there are a vast number of free packages already written for Perl. Because the details of obtaining these depends on the operating system, see The Comprehensive Perl Archive Network (CPAN) Web site http://cpan.pen.org/ [54] for instructions on how to download them.
Perl packages are called Perl modules, which are grouped together by topic. Each name typically has two or three parts, which are separated by double colons. The first part usually denotes a general topic, for example, Lingua, String, and Text. The second part is either a subtopic or a specific module. For instance, Lingua’s subtopics are often specific languages; for example, Lingua: : EN for English and Lingua: : DE for German (DE stands for Deutsch). Our first example is from the former.
9.2.1 Modules for Number Words
Lingua: : EN: : Numbers [21] has a three-part name, where Lingua stands for language, and EN for English. The third part states what the package does in particular, and in this case, it involves numbers.
CPAN gives information about each module and tells us there are two functions in this one: num2en and num2en_ordinal. The former converts a number into English, for example, num2en(6) returns the string six. Not surprisingly, num2en_ordinal (6) returns the string sixth. An example of the former is given below.
Once a package has been downloaded to the correct place in the computer, the function use makes it accessible to the programmer. Code sample 9.1 and output 9.1 show how to invoke num2en. Note that at the end of the use command, the name of the desired function (or functions) are listed. Once these are declared, however, they are used like any other Perl function. Finally, if use attempts to access a module that has not been downloaded, then an error occurs that prints out a statement like, “Can’t locate Lingua/EN/Numbers.pm in @INC....” Note that the file extension pm stands for Perl Module.
Code Sample 9.1 Loading the module Lingua: : EN: : Numbers and then using the function num2en.
use Lingua::EN::Nuinbers num2en; |
print num2en(–6), “ ”, num2en(1729), “ ”, num2en(1.23); |
Output 9.1 Results from code sample 9.1.
negative six |
one thousand seven hundred and twenty-nine |
one point two three |
As an aside, recall program 3.5, which makes an anagram dictionary from a word list. This is easily changed into an anagram dictionary for numbers. Are there two of these that are anagrams? The answer is yes, for example, sixty-seven and seventy-six. However, this just exchanges the words six and seven, that is, the same digits are used in both numbers. Are there two numbers that are anagrams, but their digits are not?
This task is much harder without this package. In general, when faced with a text mining challenge, first searching through CPAN for applicable modules is prudent. If there is a module there, then the programming is much easier. If no such module exists, and if you create a program yourself, then this is a chance to convert your code into a module and give back to the Perl community.
Since EN stands for English, perhaps number modules for other languages exist, and this is true. For example, Lingua: : DE: : Num2Word [60] translates numbers into German. This is done in code sample 9.2, which produces output 9.2.
There are other languages that have a numbers module, and the reader can search CPAN for these. The next module we consider provides lists of stop words in a variety of languages.
Code Sample 9.2 The analog of code sample 9.1 for German.

Output 9.2 Results from code sample 9.2.
em, zwei, drei, |
9.2.2 The StopWords Module
Stop words are common function words that often do not add anything to a text analysis such as the prepositions of and up, which is discussed in section 6.3.1. However, one researcher’s stop words is another’s research topic. For example, when studying phrasal verbs, then prepositions are important.
The module Lingua: : StopWords [102] provides an array of stop words for 12 languages. Code sample 9.3 shows how to obtain these for English and German, and output 9.3 shows the beginning of each list.
Code Sample 9.3 Example of the module Lingua: : StopWords.

Note that the function getStopWords produces a hash reference. So @stoplist is created by dereferencing this, then applying keys to the result, which is then printed out.
Moving on, the module in the next section returns one last time to sentence segmentation. This is analyzed several times in chapter 2, and here is yet another solution.
9.2.3 The Sentence Segmentation Module
Sentence segmentation is done in sections 2.6 and 2.7.3. Lingua: :EN: :Sentence [127] also does this task. Code sample 9.4 applies this module to Edgar Allan Poe’s “The Oval Portrait.”
Output 9.3 The first few words of the English and German stoplists from code sample 9.3.
these, you, both, which, my, didn’t, if, we’ll, himself, him, own, doesn’t, he’ll, each, yours, what, them, there’s, your, again, but, too, and, why’s, over, shan’t, of, here’s,... |
Code Sample 9.4 Example of the module Lingua: :EN: :Sentence, which does sentence

Output 9.4 The first three sentences of Poe’s “The Oval Portrait’ found by code sample 9.4.
THE chateau into which my valet had ventured to make forcible entrance, rather than permit me, in my desperately wounded condition, to pass a night in the open air, was one of those piles of commingled gloom and grandeur which have so long frowned among the Appennines, |
To all |
We established ourselves in one of the smallest and least sumptuously furnished apartments. |
As in the last section, the function get_sentences returns a reference to an array. This is dereferenced, and then the result is looped over by the foreach statement. Each entry is one sentence, of which the first three are shown in output 9.4.
All three modules considered above supply the programmer with new functions. However, there is another way to provide them, which is through the object-oriented programming paradigm. Although learning how to program this way requires effort, it is easy to use when provided by a module, which is shown in the next section.
9.2.4 An Object-Oriented Module for Tagging
Object-oriented (00) programming emphasizes modular code, that is, breaking a large program into distinct pieces. How to program this way is not discussed here, but see Conway’s Object Oriented Perl [33] for a detailed explanation. This section only gives one example of using an 00 module.
When analyzing a text, knowing the parts of speech can be useful. For example, identifying verbs and prepositions helps an analysis of phrasal verbs. A program that labels words by their part of speech is called a tagger. The details of how this is done requires sophisticated language models. One approach uses hidden Markov models (HMM). For an example, see section 9.2 of the Foundations of Statistical Natural Language Processing [75]. However, using a tagger does not require knowing the theoretical details.
The key to using an 00 module is the creation of objects. Although 00 programming arose from the needs of software engineering, the core idea is simple. Objects are a way to group related subroutines together, and the latter are called methods.
The module Lingua: : EN: : Tagger [30] is a tagger, as its name suggests. Code sample 9.5 shows an example of how it is used. Note that $taggerObject is an instance of an object that has the method add_tags, which adds tags to text. The symbol -> points to a method, which is the same syntax used for references (see section 3.8.1). Hence, new is a method that creates the desired object. Output 9.5 displays the results.
Code Sample 9.5 Example of the object-oriented module Lingua: : EN: : Tagger, which is a parts-of-speech tagger.
use Lingua: :EN: :Tagger; |
$text = “He lives on the coast.”; |
print “$tagged_version ”; |
Output 9.5 The parts of speech found by code sample 9.5.
<prp>He</prp> <vbz>lives</vbz> <in>on</in> <det>the</det> <nn>coast</nn> <pp> . </pp> |
These tags are similar to the ones in the Penn Treebank, which are widely known. For example, VBZ stands for the singular, third-person form of a verb, and note that these are XML style tags. Although code sample 9.5 looks a little different from the programs earlier in this book, it is straightforward to use.
This module also includes other methods, for example, get_sentences, which (like the module in the preceding section) segments sentences. Finally, before leaving modules, the next section mentions a few more of interest, although without examples.
9.2.5 Miscellaneous Modules
There are a vast number of modules in CPAN, and new modules are added over time. For the latest information, go to the CPAN Web site [54]. This section just mentions a few more examples to whet your appetite.
First, some of the modules are recreational. For example, Acme: : Umlautify [101] takes text and adds umlauts to all the vowels (including e,i, and y). Perhaps this is silly, but it is all in good fun.
Second, there are many modules that start with Math or Statistics. For example, there are modules to work with matrices, so Perl can be used instead of R in chapter 5. There are also modules to compute statistical functions like standard deviations and correlations. For more on this see Baiocchi’s article “Using Perl for Statistics” [8]. However, R can do many complex statistical tasks like kmeans () and hclust (), so it is worth learning, too. Finally, there is a module called Statistics: : R that interfaces with R, so Perl can access it within a program and then use its output for its own computations.
Third, some of the modules are quite extensive and add amazing capabilities to a program, although only one is noted here. LWP [1] enables a Perl program to go online and directly access text from the Web, which is a text miner’s dream come true. For example, like a browser, it can request the HTML code of a Web page and then store the results in a Perl variable, which is then available for use throughout the program. This module is complex enough that there is a book devoted to it: Perl & LWP by Burke [20].
Finally, just as Perl has modules available from CPAN, R also has downloadable libraries from the Comprehensive R Archive Network (CRAN) [34]. So before starting a major programming task, it is worth checking these two Web sites for what already exists. Remember that if you desire some capability enough to program it, then someone else probably felt the same way, and this person might have uploaded their work.
9.3 OTHER LANGUAGES: ANALYZING GOETHE IN GERMAN
All the texts analyzed in the earlier chapters are in English, but this only reflects my status as a monoglot. English uses the Roman alphabet with few diacritical marks, in fact, using no marks is common. Many languages also use the Roman alphabet, but with diacritical marks or extra letters. For example, German has the umlaut (which can be used with the vowels a, o, and u), and the double s, denoted β in the lowercase, and called Eszett in German. In addition, there are other alphabets (Greek, Cyrillic, Hebrew, and so forth), and some languages use characters instead (for example, Chinese).
Thanks to the Unicode standard, a vast number of languages can be written in an electronic format, hence ready for text mining. However, languages are quite different, and an analysis that is useful in one might be meaningless in another.
As a short example, a frequency analysis of letters and words is done for the first volume of the German novel Die Leiden des jungen Werthers by Johann Wolfgang von Goethe. Although German and English are closely related in the Indo-European language tree, they also have numerous differences, and some of these are immediately apparent by looking at letter and word frequencies.
First we compute the letter frequencies for this novel. This is done with program 4.3 in section 4.2.2.1. Applying this to Goethe’s novel produces table 9.1, which builds on output 4.2 by comparing the letter frequencies of Goethe’s novel to those of Charles Dickens’s A Christmas Carol and Poe’s “The Black Cat.”
Table 9.1 Letter frequencies of Dickens’s A Christmas Carol, Poe’s “The Black Cat,” and Goethe’s Die Leiden des jungen Werthers.

The third column is clearly longer than the other two, which has three causes. First, the umlauted vowels are distinct from the nonumlauted vowels. Second, the Perl function lc does not apply to capital, umlauted vowels. For example, the letters ä and Ä are counted separately. Finally, German has the β, as noted above.
Moreover, the order of the letters in the third column is different than the first two columns (which are quite similar). The letter e is the most common in all three texts, and t is ranked second in the first two columns, but seventh in the third, and n is ranked second in Goethe, but seventh and sixth in the English texts. Looking at the infrequent letters, while z ranks last in English, it is much more common in German.
For a final, basic analysis of this German novel, we compute the word counts. Remember that section 2.4 discusses three problematic punctuations: dashes, hyphens, and apostrophes. Goethe certainly used dashes. However, there is only one case of two words connected with a hyphen: Entweder-Oder. Although compound words are plentiful in German, these are combined without hyphens. Apostrophes are rare in German, but Goethe does use them for a few contractions, for example, hab‘ for habe and gibt‘s for gibt es. Note that German has many contractions that do not use an apostrophe, for example, aufs for auf das.
For finding the words in this novel, dashes are removed, hyphens are no problem, and there are apostrophes, but these are used for contractions, not quotations. Code sample 9.6 shows how the punctuation is removed. Note there is one problem with this: using lc does not change the case of capital umlauted vowels, but according to table 9.1, this only happens 19 times, so this complication is ignored.
Code Sample 9.6 How punctuation is removed from Goethe’s Die Leiden des jungen Werthers.

Writing a program to print out the word frequencies has been done: see program 3.3. Output 9.6 shows the 10 most common words in the novel.
Output 9.6 The 10 most frequent words in Goethe’s Die Leiden des jungen Werthers.
und, 700 |
ich, 602 |
die, 454 |
der, 349 |
sie, 323 |
das, 277 |
zu, 259 |
in, 216 |
nicht, 200 |
mich, 182 |
The most frequent word is und (and), which is also common in English (for example, see output 3.21, which shows that and is the second most frequent word in Dickens’s A Christmas Carol). Second most frequent is ich (I). The first part of the novel is written as a series of letters from Werther (the protagonist) to his close friend Wilhelm, so it is not surprising that the first-person, singular pronoun is used quite often.
The most common word in English is the, and this is true in German, too. In fact, output 9.6 also shows that this is true in spite of the und at the top of the list. This happens because German has several inflected forms of the word the, which depends upon the case, grammatical gender, and number of the noun. Discussing the relevant German grammar is too much of a diversion, but table 9.2 gives an example of the different forms of the used with the word Mensch in Goethe’s novel, which were found by concordancing. The lines shown are a subset of those produced by code samples 6.7, 6.8, and 6.10 used with program 6.1. All six lines shown have a form of the in front of Mensch, a masculine noun.
Table 9.2 Inflected forms of the word the in Goethe’s Die Leiden desjungen Werthers.
7 |
| lbst und alles Glück, das dem Menschen gegeben ist. |
9 |
| merzen wären minder unter den Menschen, wenn sie nicht — Gott wei |
16 |
| b’ich nicht — o was ist der Mensch, daβ er über sich kiagen darf |
18 |
| oldenen Worte des Lehrers der Menschen: “wenn ihr nicht werdet wie |
27 |
| Freund, was ist das Herz des Menschen! Dich zu verlassen, den ic |
34 |
| , was ich Anzügliches für die Menschen haben muβ; es mögen mich ih |
To get a total number of uses of the in German, the counts in table 9.3 must be summed. This totals 1450, which is much larger than the number of times und appears (only 700), so the is the most common word in this text. Note, however, German utilizes the in more ways than is true in English. For example, many forms (but not all) of relative pronouns match a form of the.
Table 9.3 Counts of the six forms of the German word for the in Goethe’s Die Leiden des jungen Werthers.
die |
| 454 |
der |
| 349 |
das |
| 277 |
den |
| 164 |
dem |
| 138 |
des |
| 68 |
total |
| 1450 |
Even the simple analysis above shows that assumptions about English may or may not hold for German in spite of their close relationship. This suggests that fluency in the language of a text is important when doing text mining, which is just common sense.
Finally, corpora of other languages have been created, and these have been analyzed for various purposes. To name one example, A Frequency Dictionary of German [63] gives a list of just over 4000 words in order of frequency. Such a book is useful for beginning students of German.
In section 4.5, the bag-of-words model is discussed. This underlies the term-document matrix, the topic of section 5.4. Recall that this matrix has a column for every text and a row for every term. The intersection of each row and column contains the count of the number of times the term appears in that document. However, the term-document matrix of any permutation of a text is the same as the original text. That is, word order makes no difference.
Obviously, the bag-of-words model is incorrect. For example, much of the grammar in English restricts word order. On the other hand, the term-document matrix is useful because it performs well in information retrieval tasks. So the question becomes, when does word order matter in English?
To answer this assume that word order is irrelevant for a particular function, which is applied to many random permutations of a text. Then these values are compared to the value of the original. If the latter seems consistent with the permutation values, then this function probably does not depend on word order for this text. Hence, using a technique like the word-document matrix probably poses no problems in this situation. However, if this is not true, then ignoring word order probably loses information.
Note that looking at all permutations of a text is impossible. There are n! permutations for n objects, and this means that even a 100-word text has 100!≈ 9.33262 × 10157 different orders. Hence, analyzing a sample is the best a researcher can do.
Also note that the unit of permutation makes a big difference. For example, a character document matrix (that is, counting characters in texts) preserves little information. Perhaps languages can be distinguished this way, for example, see table 9.1 for such a matrix comparing a German novel to two English novels. But it is unclear what else is discernible.
At the other extreme, taking a novel and changing the order of the chapters might be readable. For example, the chapters of William Burroughs’s Naked Lunch were returned out of order by his publisher, but Burroughs decided to go ahead using this new order (see page 18 of Burroughs’ Word Virus [22]).
The goal in the next two sections is to test this idea of comparing permutations to the original text. The next section discusses a little of the statistical theory behind it, and the section after gives two examples.
9.4.1 Runs and Hypothesis Testing
We start with a simple example to illustrate the idea of comparing the original value to the permutation values. Then this technique is applied to A Christmas Carol and The Call of the Wild.
Suppose the sequence of zeros and ones in equation 9.1 is given, and a researcher wants to test the hypothesis that these are generated by a random process where each distinct permutation is equally likely. Note that permutations do not change the number of 0’s and 1‘s, and this is consistent with the bag-of-words model, which fixes the counts, but ignores the order.
(9.1) ![]()
The sequence in equation 9.1 does not seem random, but how is this testable? The metric used here is based on the number of runs in the data. The first run begins at the start and continues until the value changes. Where it does change is the start of the second run, which ends once its value changes again, which is the start of the third run, and so forth. So for the above sequence, there are three runs: the first twelve 1‘s, the next eight 0’s, and the last five l’s.
Next, compute a large number of random permutations and for each of these, compute the number of runs. This generates a set of positive numbers, which can be summarized with a histogram. If three runs is near the left end of the histogram (so that most permutations have more), then this hypothesis of the randomness of the above data is unlikely. If three is a typical value near the center of the histogram, then this hypothesis is supported by this data. However, randomness is not proven since other measures might reveal that this hypothesis is unlikely.
The above procedure is straightforward to do in R. Code sample 9.7 defines a function that produces n random permutations, and counts the number of runs in each one. These are obtained by generating uniform random numbers and then using the order() function to find the permutation that sorts these numbers into order. Since the original values are random, the resulting permutation is random. This also can be done by using sample () (see problem 8.3.d). Finally, runs occur exactly when two adjacent values are not equal, and this is tested for and counted in the line that assigns a value to nruns, the number of runs. These results are stored in the vector values.
Code Sample 9.7 An R function that computes the number of runs for n random permutations of an input vector, x.

Output 9.7 shows the code that produces a histogram of the number of runs for each of 100,000 random permutations. Clearly values around 13 are typical in figure 9.1, and since 3 occurs exactly once (applying sum to the logical test of equaling 3 returns 1, and 3 is the minimum value), the probability of such a low number of runs is approximately 1/100,000 = 0.00001.
Figure 9.1 Histogram of the numbers of runs in 100,000 random permutations of digits in equation 9.1.
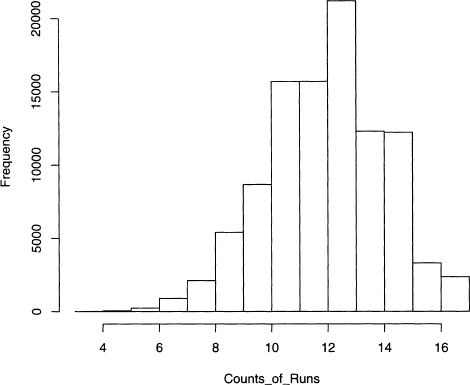
Output 9.7 This produces a histogram of the number of runs after permuting the vector data 100,000 times using the function defined in code sample 9.7.

Since this probability estimate is extremely low, we conclude that the original data values are not consistent with the hypothesis of random generation. This result can be checked using the R package tseries [118], which has runs. test () It reports a p-value equal to 0.0000072, which is quite close to the above estimate. With this example in mind, we apply this to texts in the next section.
9.4.2 Distribution of Character Names in Dickens and London
We apply the technique of the preceding section to names in a novel. Since the plot structure determines when characters appear or are discussed, this is not random, so it is an interesting test to see what an analysis of runs detects.
The first example uses the names Scrooge and Marley in Dickens’s A Christmas Carol. First, note that a random permutation of all the words in the story induces a random permutation of these two names. Hence, it is enough to list the order these names appear in the novel, and then randomly permute these to do the analysis.
Concordancing using program 6.1 makes it easy to find and print out just these two names in the order they appear in the novel. To save space, let 0 stand for Scrooge and 1 for Marley. The Perl code is left for the reader as an exercise. The values are stored in the vector scroogemarley, and note that Manley is more common at the start, and then fairly infrequent for the rest of the novel.
Output 9.8 The 398 uses of Scrooge or Marley in A Christmas Carol. 0 stands for Scrooge, 1 for Marley.

Output 9.9 shows that there are 57 runs for the data shown in output 9.8. Then 10,000 permutations are applied, and the runs for each one is computed by runs_sim (). The results are plotted in the histogram shown in figure 9.2.
Figure 9.2 Histogram of the runs of the 10,000 permutations of the names Scrooge and Marley as they appear in A Christmas Carol.
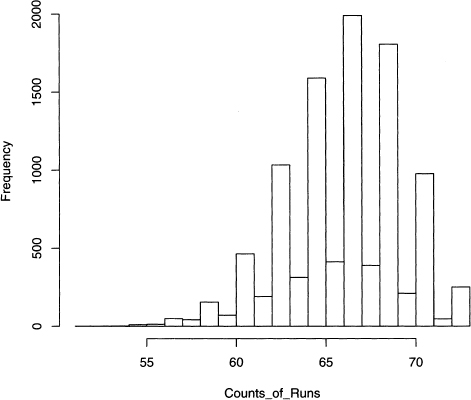
Output 9.9 The results of 10,000 permutations of the data in output 9.8.
> sum(scroogemarley[—1] != scroogemarley[—length(scroogemarley)]) |
[1] 57 |
> Counts_of_Runs = runs_sim(scroogemarley, 10000) |
> min(Counts_of_Runs) |
[1] 51 |
> max(Counts_of_Runs) |
[1] 73 |
> sum(Counts_of_Runs < 57) |
[1] 68 |
> hist(Counts_of_Runs, 51:73) |
First, it is obvious that tall and short bars alternate, where the former happens with odd values and the latter with even ones. This is not an accident because an odd number of runs only occurs when the first and last value in the vector are the same. For scroogemarley, there are 362 0’s and 36 l’s, hence the chances of the first and last values equaling 0 is quite high (about 83%).
Second, there are 68 cases where the number of runs are equal to or less than 57, which is the number of runs in scroogemarley. So the probability of seeing a result as extreme or more extreme is about 68/10,000 = 0.0068, which is quite low. Hence we conclude that the distribution of the names Scrooge and Marley is not random.
A second example comes from The Call of the Wild. In this novel, Buck has a number of owners that come and go before he obtains his freedom at the end. Early in the story he is part of a dog-sled team run by Francois and Perrault, who are two French-Canadians. While they own Buck, they play a prominent role, and their names alternate much more than is true with Scrooge and Marley. See output 9.10, and note that Francois is represented by 0, Perrault by 1.
These two names appear 99 times, 60 for Francois and 39 for Perrault, a much more even division than the previous example. Redoing the above analysis, we see that the conclusion is different because the number of runs in the original sequence of names is 45, and there are 2831 permutations with this or less runs. A probability of 2831/10,000 = 0.2831, however, is not small. The histogram of the 10,000 runs is shown in figure 9.3. Note that it does not have alternating heights since the probability that a random permutation begins and ends with the same name is close to 50%.
Figure 9.3 Histogram of the runs of the 10,000 permutations of the names Francois and Perrault as they appear in The Call of the Wild.
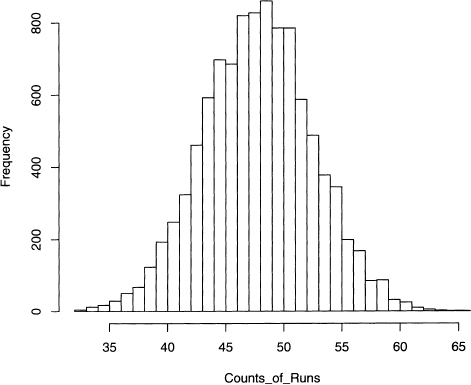
Output 9.10 The appearance of the names Francois and Perrault in The Call of the Wild. Here 0 stands for Francois, 1 for Perrault.
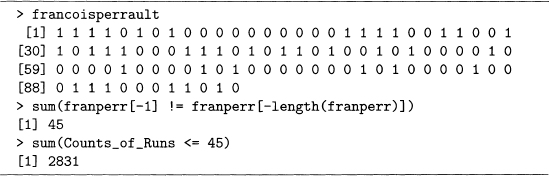
Hence for Scrooge and Marley, the former is common because it is the protagonist’s name. Marley’s ghost appears at the start of the novel, but he is mentioned infrequently after that. However, for Francois and Perrault, these two characters work together as part of a team. Hence it is not surprising that there is a difference in the pattern of how each pair of names appears in their respective novels.
This book draws to an end. The next section gives some text mining references for the interested reader. Finally, I have enjoyed writing this book and hope that you have enjoyed reading and working through it.
This book is an introduction to some of the important techniques of text mining. Many of these are from other research areas such as information retrieval and statistics, and references for these topics are given at the end of the respective chapters. This section lists a few books that focus on text mining itself.
Text mining grew out of data mining. A good introductory book on applying data mining to online texts is Data Mining the Web by Zdravko Markov and Daniel Larose [77]. Another introductory book on using Perl to interact with the Web is Spidering Hacks by Kevin Hemenway and Tara Calishain [53].
For an introduction to text mining, try Text Mining by Sholom Weiss, Nitin Indurkhya, Tong Zhang, and Fred Damerau [125]. Their emphasis is on creating quantitative summaries of one or more texts, then applying data mining techniques. Finally, a more advanced book is The Text Mining Handbook by Ronen Feldman and James Sanger [43].