
Chapter 6
Working with Delegates, Events, and Exceptions
What You Will Learn in This Chapter
- Understanding delegates and predefined delegate types
- Using anonymous methods including lambda expressions
- Publishing and subscribing to events
- Allowing derived classes to raise base class events
- Catching, throwing, and rethrowing exceptions
- Creating custom exceptions
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
You can find the code downloads for this chapter at www.wrox.com/remtitle.cgi?isbn=1118612094 on the Download Code tab. The code is in the chapter11 download and individually named according to the names throughout the chapter.
Chapter 3, “Working with the Type System,” explained data types including predefined types (such as int and string), data structures, and enumerations. For example, the following code snippet defines a Person structure that groups a person’s name and address information:
struct Person
{
public string FirstName, LastName, Street, City, State, ZIP;
}This chapter explains delegates, data types that define kinds of methods. It also explains events (which use delegates), exceptions, and error handling.
Table 6-1 introduces you to the exam objectives covered in this chapter.
Table 6-1: 70-483 Exam Objectives Covered in This Chapter
| Objective | Content Covered |
| Manage program flow | Create and implement events and callbacks. This includes creating event handlers, subscribing and unsubscribing from events, using built-in delegate types to create events, creating delegates, using lambda expressions, and using anonymous methods. Implement exception handling. This includes handling different exception types, catching exceptions of specific and base types, implementing try-catch-finally blocks, throwing exceptions, creating custom exceptions, and determining when to throw or rethrow exceptions. |
Working with Delegates
As you saw in the introduction to this chapter, a delegate is a data type that defines kinds of methods and explains events (which use delegates), exceptions, and error handling. A delegate is a data type much as a class or structure is. Those types define the properties, methods, and events provided by a class or structure. In contrast, a delegate is a type that defines the parameters and return value of a method. The following sections explain how you can define and use delegates.
Delegates
The following code shows how you can define a delegate type.
[accessibility] delegate returnTypeDelegateName([parameters]);Here’s a breakdown of that code:
- accessibility: An accessibility for the delegate type such as public or private.
- delegate: The delegate keyword.
- returnType: The data type that a method of this delegate type returns such as void, int, or string.
- delegateName: The name that you want to give the delegate type.
- parameters: The parameter list that a method of this delegate type should take.
For example, the following code defines a delegate type named FunctionDelegate.
private delegate float FunctionDelegate(float x);This type represents methods that take a float as a parameter and returns an integer.
After you define a delegate type, you can create a variable of that type. The following code declares a variable named TheFunction that has the FunctionDelegate type:
private FunctionDelegate TheFunction;List<FunctionDelegate> functions = new List<FunctionDelegate>();Later you can set the variable equal to a method that has the appropriate parameters and return type. The following code defines a method named Function1. The form’s Load event handler then sets the variable TheFunction equal to this method.
// y = 12 * Sin(3 * x) / (1 + |x|)
private static float Function1(float x)
{
return (float)(12 * Math.Sin(3 * x) / (1 + Math.Abs(x)));
}
// Initialize TheFunction.
private void Form1_Load(object sender, EventArgs e)
{
TheFunction = Function1;
}After the variable TheFunction is initialized, the program can use it as if it were the method itself. For example, the following code snippet sets the variable y equal to the value returned by TheFunction with parameter 1.23.
float y = TheFunction(1.23f);At this point, you don’t actually know which method is referred to by TheFunction. The variable could refer to Function1 or some other method, as long as that method has a signature that matches the FunctionDelegate type.
Figure 6-1: The GraphFunction example program uses a delegate variable to store the function that it should graph.
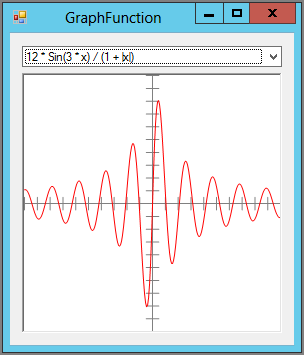
// Select the appropriate function and redraw.
private void equationComboBox_SelectedIndexChanged(
object sender, EventArgs e)
{
switch (equationComboBox.SelectedIndex)
{
case 0:
TheFunction = Function1;
break;
case 1:
TheFunction = Function2;
break;
case 2:
TheFunction = Function3;
break;
}
graphPictureBox.Refresh();
}// Generate points on the curve.
List<PointF> points = new List<PointF>();
for (float x = wxmin; x <= wxmax; x += dx)
points.Add(new PointF(x, TheFunction(x)));To summarize, you can use a delegate much as you use any other type. First, use the delegate keyword to define the delegate type. Next, create variables of the delegate type, and set them equal to methods that match the delegate’s parameters and return type. Finally, write code to invoke the variable, which calls the method referred to by the variable.
Delegate Details
Using a delegate is similar to using any other data type. The only confusing issue is that the values being manipulated are references to methods rather than some more concrete data type such as an int or string.
Addition and subtraction are even defined on delegate variables. Suppose Method1 and Method2 are two methods that take no parameters and return void, and consider the following code:
Action del1 = Method1;
Action del2 = Method2;
Action del3 = del1 + del2 + del1;This makes del3 a delegate variable that includes a series of other delegate variables. Now if you invoke the del3 delegate variable, the program executes Method1 followed by Method2 followed by Method1.
You can even use subtraction to remove one of the delegates from the series. For example, if you execute the statement del3 -= del1 and then invoke del3, the program executes Method1 and then Method2.
There are also a few issues that are unique to delegates. The following sections describe differences between delegates that use static and instance methods, and the two concepts of covariance and contravariance.
Static and Instance Methods
If you set a delegate variable equal to a static method, it’s clear what happens when you invoke the variable’s method. There is only one method shared by all the instances of the class that defines it, so that is the method that is called.
If you set a delegate variable equal to an instance method, the results is a bit more confusing. When you invoke the variable’s method, it executes in the instance that you used to set the variable’s value.
class Person
{
public string Name;
// A method that returns a string.
public delegate string GetStringDelegate();
// A static method.
public static string StaticName()
{
return "Static";
}
// Return this instance's Name.
public string GetName()
{
return Name;
}
// Variables to hold GetStringDelegates.
public GetStringDelegate StaticMethod;
public GetStringDelegate InstanceMethod;
}private void Form1_Load(object sender, EventArgs e)
{
// Make some Persons.
Person alice = new Person() { Name = "Alice" };
Person bob = new Person() { Name = "Bob" };
// Make Alice's InstanceMethod variable refer to her own GetName method.
alice.InstanceMethod = alice.GetName;
alice.StaticMethod = Person.StaticName;
// Make Bob's InstanceMethod variable refer to Alice's GetName method.
bob.InstanceMethod = alice.GetName;
bob.StaticMethod = Person.StaticName;
// Demonstrate the methods.
string result = "";
result += "Alice's InstanceMethod returns: " + alice.InstanceMethod() +
Environment.NewLine;
result += "Bob's InstanceMethod returns: " + bob.InstanceMethod() +
Environment.NewLine;
result += "Alice's StaticMethod returns: " + alice.StaticMethod() +
Environment.NewLine;
result += "Bob's StaticMethod returns: " + bob.StaticMethod();
resultsTextBox.Text = result;
resultsTextBox.Select(0, 0);
}Figure 6-2: The StaticAndInstanceDelegates example program demonstrates delegates set to static and instance methods.
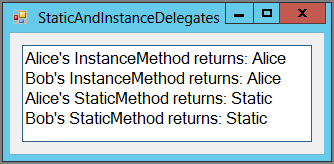
Covariance and Contravariance
Covariance and contravariance give you some flexibility when assigning methods to delegate variables. They basically let you treat the return type and parameters of a delegate polymorphically.
Covariance lets a method return a value from a subclass of the result expected by a delegate. For example, suppose the Employee class is derived from the Person class and the ReturnPersonDelegate type represents methods that return a Person object. Then you could set a ReturnPersonDelegate variable equal to a method that returns an Employee because Employee is a subclass of Person. This makes sense because the method should return a Person, and an Employee is a kind of Person. (A variable is called covariant if it enables covariance.)
Contravariance lets a method take parameters that are from a superclass of the type expected by a delegate. For example, suppose the EmployeeParameterDelegate type represents methods that take an Employee object as a parameter. Then you could set an EmployeeParameterDelegate variable equal to a method that takes a Person as a parameter because Person is a superclass of Employee. When you invoke the delegate variable’s method, you will pass it an Employee (because the delegate requires that the method take an Employee parameter) and an Employee is a kind of Person, so the method can handle it. (A variable is called contravariant if it enables contravariance.)
// A delegate that returns a Person.
private delegate Person ReturnPersonDelegate();
private ReturnPersonDelegate ReturnPersonMethod;
// A method that returns an Employee.
private Employee ReturnEmployee()
{
return new Employee();
}
// A delegate that takes an Employee as a parameter.
private delegate void EmployeeParameterDelegate(Employee employee);
private EmployeeParameterDelegate EmployeeParameterMethod;
// A method that takes a Person as a parameter.
private void PersonParameter(Person person)
{
}
// Initialize delegate variables.
private void Form1_Load(object sender, EventArgs e)
{
// Use covariance to set ReturnPersonMethod = ReturnEmployee.
ReturnPersonMethod = ReturnEmployee;
// Use contravariance to set EmployeeParameterMethod = PersonParameter.
EmployeeParameterMethod = PersonParameter;
}Built-in Delegate Types
The .NET Framework defines two generic delegate types that you can use to avoid defining your own delegates in many cases: Action and Func.
Action Delegates
The generic Action delegate represents a method that returns void. Different versions of Action take between 0 and 18 input parameters. The following code shows the definition of the Action delegate that takes two parameters:
public delegate void Action<in T1, in T2>(T1 arg1, T2 arg2)The keyword in within the generic parameter list indicates that the T1 and T2 type parameters are contravariant.
Unless you need to define a delegate that takes more than 18 parameters, you can use the Action instead of creating your own delegates. For example, the code in the previous section defined an EmployeeParameterDelegate type that takes an Employee object as a parameter and returns void. The following code shows two ways you could declare variables of that type:
// Method 1.
private delegate void EmployeeParameterDelegate(Employee employee);
private EmployeeParameterDelegate EmployeeParameterMethod1;
// Method 2.
private Action<Employee> EmployeeParameterMethod2;This code’s first statement defines the EmployeeParameterDelegate type. The statement after the first comment declares a variable of that type. The statement after the second comment declares a comparable variable of type Action<Employee>.
Func Delegates
The generic Func delegate represents a method that returns a value. As is the case with Action, different versions of Func take between 0 and 18 input parameters. The following code shows the definition of the Func delegate that takes two parameters:
public delegate TResult Func<in T1, in T2, out TResult>(T1 arg1, T2 arg2)The three types defined by the generic delegate represent the types of the two parameters and the return value.
The code in the previous section defined a ReturnPersonDelegate type that takes no parameters and returns a Person object. The following code shows two ways you could declare variables of that type:
// Method 1.
private delegate Person ReturnPersonDelegate();
private ReturnPersonDelegate ReturnPersonMethod1;
// Method 2.
private Func<Person> ReturnPersonMethod2;This code’s first statement defines the ReturnPersonDelegate type. The statement after the first comment declares a variable of that type. The statement after the second comment declares a comparable variable of type Func<Person>.
Anonymous Methods
An anonymous method is basically a method that doesn’t have a name. Instead of creating a method as you usually do, you create a delegate that refers to the code that the method should contain. You can then use that delegate as if it were a delegate variable holding a reference to the method.
The following shows the syntax for creating an anonymous method.
delegate([parameters]) { code... }Here’s a breakdown of that code:
- delegate: The delegate keyword.
- parameters: Any parameters that you want the method to take.
- code: Whatever code you want the method to execute. The code can use a return statement if the method should return some value.
The following code stores an anonymous method in a variable of a delegate type.
private Func<float, float> Function = delegate(float x) { return x * x; };This code declares a variable named Function of the type defined by the built-in Func delegate that takes a float as a parameter and that returns a float. It sets the variable Function equal to a method that returns its parameter squared.
The program cannot refer to this method by name because it’s anonymous, but it can use the variable Function to invoke the method.
The previous line of code shows how you can make a delegate variable refer to an anonymous method. Two other places where programmers often use anonymous methods are defining simple event handlers and executing simple tasks on separate threads.
The following code adds an event handler to a form’s Paint event:
private void Form1_Load(object sender, EventArgs e)
{
this.Paint += delegate(object obj, PaintEventArgs args)
{
args.Graphics.DrawEllipse(Pens.Red, 10, 10, 200, 100);
};
}When the form receives a Paint event, the anonymous method draws a red ellipse.
The following code executes an anonymous method on a separate thread:
private void Form1_Load(object sender, EventArgs e)
{
System.Threading.Thread thread = new System.Threading.Thread(
delegate() { MessageBox.Show("Hello World"); }
);
thread.Start();
}This code creates a new Thread object, passing it a reference to the anonymous method. When the thread starts, it executes that method, in this case displaying a message box.
Lambda Expressions
Anonymous methods give you a shortcut for creating a short method that will be used in only one place. In case that isn’t short enough, lambda methods provide a shorthand notation for creating those shortcuts. A lambda expression uses a concise syntax to create an anonymous method.
Lambda expressions come in a few formats and several variations. To make discussing them a little easier, the following sections group lambda expressions into three categories: expression lambdas, statement lambdas, and async lambdas. Each of these has several variations, which are covered on the next section about expression lambdas.
Expression Lambdas
The following text shows an expression lambda’s simplest form:
() => expression;Here, expression is a single C# statement that should be executed by the delegate. The fact that this lambda expression has a single expression on the right side is what makes it an expression lambda.
The empty parentheses represent the empty parameter list taken by the anonymous method. The => characters indicate that this is a lambda statement.
The following code snippet shows how you could use this kind of lambda expression:
Action note;
note = () => MessageBox.Show("Hi");
note();AnonymousMethods.exe!AnonymousMethods.
Form1..ctor.AnonymousMethod__0(string m)This code’s first statement creates a variable named note of type Action, which the section “Built-in Delegate Types” earlier in this chapter explained is a delegate type representing methods that take no parameters and that return void.
The second statement sets note equal to the anonymous method created by a lambda expression. This expression executes the single statement MessageBox.Show("Hi").
The code’s final statement invokes the anonymous method referred to by the note variable.
Action note = () => MessageBox.Show("Hi");The previous example demonstrates the simplest kind of lambda expression, which takes no parameters and executes a single statement. You can also add parameters to lambda expressions as in the following example:
Action<string> note = (message) => MessageBox.Show(message);This example creates an anonymous method that takes a string as a parameter and then displays that string in a message box.
Action<string> note = message => MessageBox.Show(message);Usually, Visual Studio can infer the data type of a lambda expression’s parameters. In the previous code, for example, the note variable is declared to be of type Action<string>, so the parameter must be a string.
If Visual Studio cannot infer the parameters’ data types, or if you want to make the code more explicit, you can include the parameters’ data types as in the following version:
Action<string> note = (string message) => MessageBox.Show(message);You can add as many parameters as you like to a lambda expression. The following example uses a lambda expression that takes four parameters:
Action<string, string, MessageBoxButtons, MessageBoxIcon> note;
note = (message, caption, buttons, icon) =>
MessageBox.Show(message, caption, buttons, icon);
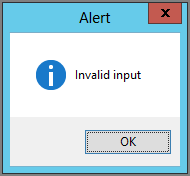
note("Invalid input", "Alert", MessageBoxButtons.OK,
MessageBoxIcon.Asterisk);In this code, the delegate type takes four parameters: two strings, a MessageBoxButtonsenum value, and a MessageBoxIconenum value.
This lambda expression uses the parameters to display a message box with a message and caption, displaying the indicated buttons and icon.
The last line of code displays a message box with message parameter "Invalid input" with caption parameter "Alert". The message box displays the OK button and the asterisk icon, as shown in Figure 6-3.
Figure 6-3: Lambda expressions can take any number of parameters.
In the examples shown up to now, the lambda expressions have returned void, but there’s no reason why a lambda expression cannot return a value. An expression lambda can return a value by simply creating that value.
The following code shows a lambda expression that takes a float as a parameter and returns that value squared.
Func<float, float> square = (float x) => x * x;
float y = square(13);The part of the expression on the right, x * x, creates the return value.
For a more complicated example, the GraphFunction program shown in Figure 6-1 uses delegates to graph one of three functions. The following code shows a key switch statement that sets the delegate variable TheFunction equal to the function that the program should graph:
switch (equationComboBox.SelectedIndex)
{
case 0:
TheFunction = Function1;
break;
case 1:
TheFunction = Function2;
break;
case 2:
TheFunction = Function3;
break;
}Instead of setting TheFunction equal to a named method, the code could set it equal to an anonymous method created by a lambda expression. The following code shows the first case statement rewritten to use a lambda expression:
case 0:
TheFunction = x => (float)(12 * Math.Sin(3 * x) / (1 + Math.Abs(x)));
break;This expression is about as complicated as you should probably get with an expression lambda. If it were much more complicated, reading it would be confusing.
Statement lambdas provide one way to make complicated lambda expressions a bit easier to read.
Statement Lambdas
A statement lambda is similar to an expression lambda except it encloses its code in braces. That makes it a bit easier to separate complicated lambda expressions from the code around them. It also enables you to include more than one statement in an anonymous method.
In addition to the braces, the other way in which statement lambdas differ from expression lambdas is that a statement lambda must use a return statement to return a value.
Figure 6-4 shows the AnonymousGraph example program, which is available for download on the book’s website, graphing the function Ax6 + Bx5 + Cx4 + Dx3 + Ex2 + Fx + G for constants A, B, C, D, E, F, and G. (This program is similar to the GraphFunction example program described earlier except it uses anonymous methods instead of named methods for its functions.)
Figure 6-4: The equation for the GraphFunction program’s third function shown here is easier to read in a statement lambda than in an expression lambda.
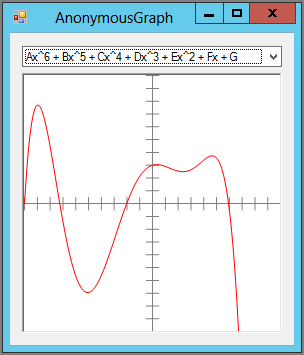
The function graphed in Figure 6-4 is a simple polynomial but it’s long and would be messy if written out in an expression lambda. The following code shows how the program uses a statement lambda to save a reference to an anonymous method that evaluates this function:
TheFunction = (float x) =>
{
const float A = -0.0003f;
const float B = -0.0024f;
const float C = 0.02f;
const float D = 0.09f;
const float E = -0.5f;
const float F = 0.3f;
const float G = 3f;
return (((((A * x + B) * x + C) * x + D) * x + E) * x + F) * x + G;
};Note the use of the braces and the return statement.
Async Lambdas
Chapter 7, “Multithreading and Asynchronous Processing,” explains asynchronous processing and multithreading, but this topic is worth discussing briefly here in the context of lambda expressions.
Basically, you can use the keyword async to indicate that a method can be run asynchronously. You can then use the await keyword to make a piece of code call an asynchronous method and wait for it to return. Usually an asynchronous method is named, but you can use the async keyword to make lambda expressions asynchronous, too.
// The number of times we have run DoSomethingAsync.
private int Trials = 0;
// Create an event handler for the button.
private void Form1_Load(object sender, EventArgs e)
{
runAsyncButton.Click += async (button, buttonArgs) =>
{
int trial = ++Trials;
statusLabel.Text = "Running trial " + trial.ToString() + "...";
await DoSomethingAsync();
statusLabel.Text = "Done with trial " + trial.ToString();
};
}
// Do something time consuming.
async Task DoSomethingAsync()
{
// In this example, just waste some time.
await Task.Delay(3000);
}Working with Events
Events enable objects to communicate with a program to tell it when something interesting has happened. For example, an e-mail object could raise an event to tell the program that it has received a new message; a file transfer object could raise an event to tell the program that a download has completed, and a button object could raise an event to tell the program that the user clicked the button’s graphical representation on the screen.
The object that raises an event is called the event’s publisher. The class that catches an event is called its subscriber. Note that a given event may have many subscribers or no subscribers.
The following sections describe the code that is necessary to publish and subscribe to events.
Publishing Events
Before an object can raise an event, it must declare the event so that subscribers know what the event is called and what parameters it includes. The following shows the basic syntax for declaring an event:
accessibility event delegateEventName;Here’s a breakdown of that code:
- accessibility : The event’s accessibility as in public or private.
- event: The event keyword.
- delegate: A delegate type that defines the kind of method that can act as an event handler for the event.
- EventName : The name that the class is giving the event.
For example, the BankAccount class might use the following code to define the Overdrawn event:
public delegate void OverdrawnEventHandler();
public event OverdrawnEventHandler Overdrawn;The first line declares the OverdrawnEventHandler delegate, which represents methods that take no parameters and that return void.
The second line declares an event named Overdrawn that has the type OverdrawnEventHandler. That means subscribers must use a method that matches the OverdrawnEventHandler delegate to catch the event.
Later a BankAccount object can raise the event as necessary. For example, consider the following simple but complete BankAccount class:
class BankAccount
{
public delegate void OverdrawnEventHandler();
public event OverdrawnEventHandler Overdrawn;
// The account balance.
public decimal Balance { get; set; }
// Add money to the account.
public void Credit(decimal amount)
{
Balance += amount;
}
// Remove money from the account.
public void Debit(decimal amount)
{
// See if there is this much money in the account.
if (Balance >= amount)
{
// Remove the money.
Balance -= amount;
}
else
{
// Raise the Overdrawn event.
if (Overdrawn != null) Overdrawn();
}
}
}The class defines the OverdrawnEventHandler delegate and declares the Overdrawn event to be of that type. It then defines the auto-implemented Balance property.
Next, the class defines two methods, Credit and Debit, to add and remove money from the account. The Credit method simply adds an amount to the balance.
The Debit method first checks the account’s Balance to see if there is enough money in the account. If Balance >= amount, the method simply removes the money from the account.
If there is not enough money in the account, the method raises the Overdrawn event. To raise the event, the code first checks whether the event has any subscribers. If the event has no subscribers, then the “event” appears to be null to the code. If the event isn’t null, the code invokes it to notify its subscribers.
Predefined Event Types
The previous example used the following code to define an event delegate and create an event of that type:
public delegate void OverdrawnEventHandler();
public event OverdrawnEventHandler Overdrawn;This delegate represents methods that take no parameters and that return void. The section “Built-in Delegate Types” earlier in this chapter described that the predefined Action delegate represents the same kind of method. That means you can simplify the previous code to the following:
public event Action Overdrawn;Event Best Practices
Microsoft recommends that all events provide two parameters: the object that is raising the event and another object that gives arguments that are relevant to the event. The second object should be of a class derived from the EventArgs class.
For example, if a program uses several of the BankAccount objects described in the previous section, then the first parameter to the event handler can help the program figure out which account raised the Overdrawn event.
The fact that the event was raised tells the program that the account doesn’t hold enough money to perform a debit, but it doesn’t tell the program how large the debit is. The program can examine the BankAccount object to figure out the current balance, but it can’t figure out how big the debit was. You can use the second parameter to the event handler to give the program that information.
To pass the information in the event handler’s second parameter, derive a class from the EventArgs class to hold the information. By convention, this type’s name should begin with the name of the event and end in EventArgs.
For example, the following code shows an OverdrawnEventArgs class that can pass information to the Overdrawn event handler:
class OverdrawnEventArgs : EventArgs
{
public decimal CurrentBalance, DebitAmount;
public OverdrawnEventArgs(decimal currentBalance, decimal debitAmount)
{
CurrentBalance = currentBalance;
DebitAmount = debitAmount;
}
}This class holds a BankAccount’s current balance and a debit amount. It provides a constructor to make initializing a new object a bit easier.
Now the program can pass the Overdrawn event the object raising the event and an OverdrawnEventArgs object to give the program additional information about the event.
Because the event handler now takes two parameters, you need to revise the event declaration, so the delegate it uses reflects those parameters. You could create a new delegate but the .NET Framework defines a generic EventHandler delegate that makes this easier. Simply use the EventHandler type and include the data type of the second parameter, OverdrawnEventArgs in this example, as the generic delegate’s type parameter.
The following code shows the revised event declaration:
public event EventHandler<OverdrawnEventArgs> Overdrawn;This indicates that the Overdrawn event takes two parameters. The first is assumed to be the object that is raising the event, and the second is an object of type OverdrawnEventArgs.
The following code shows the Debit method revised to use the new event type:
// Remove money from the account.
public void Debit(decimal amount)
{
// See if there is this much money in the account.
if (Balance >= amount)
{
// Remove the money.
Balance -= amount;
}
else
{
// Raise the Overdrawn event.
if (Overdrawn != null)
Overdrawn(this, new OverdrawnEventArgs(Balance, amount));
}
}When the code raises the Overdrawn event, it passes the event the arguments this as the object raising the event and a new OverdrawnEventArgs object giving further information.
The BankAccount example program, which is available for download on the book’s website, demonstrates this version of the BankAccount class.
Event Inheritance
While building Windows Forms classes and classes in the.NET Framework, Microsoft found that simple events such as those described so far don’t work well with derived classes. The problem is that an event can be raised only from within the class that declared it, so a subclass cannot raise the base class’s events.
The solution that Microsoft uses in the .NET Framework and many other class hierarchies is to give the base class a protected method that raises the event. Then a derived class can call that method to raise the event. By convention, this method’s name should begin with On and end with the name of the event, as in OnOverdrawn.
For example, consider the BankAccount class described in the previous section. Its Debit method raises the Overdrawn event if the program tries to remove more money than the account holds. To follow the new event pattern, the class should move the code that raises the event into a new OnOverdrawn method and then call it from the Debit method, as shown in the following code:
// Raise the Overdrawn event.
protected virtual void OnOverdrawn(OverdrawnEventArgs args)
{
if (Overdrawn != null) Overdrawn(this, args);
}
// Remove money from the account.
public void Debit(decimal amount)
{
// See if there is this much money in the account.
if (Balance >= amount)
{
// Remove the money.
Balance -= amount;
}
else
{
// Raise the Overdrawn event.
OnOverdrawn(new OverdrawnEventArgs(Balance, amount));
}
}Now suppose you want to add a new MoneyMarketAccount class derived from the BankAccount class. When its code needs to raise the Overdrawn event, it invokes the base class’s OnOverdrawn method.
The following code shows the MoneyMarketAccount class:
class MoneyMarketAccount : BankAccount
{
public void DebitFee(decimal amount)
{
// See if there is this much money in the account.
if (Balance >= amount)
{
// Remove the money.
Balance -= amount;
}
else
{
// Raise the Overdrawn event.
OnOverdrawn(new OverdrawnEventArgs(Balance, amount));
}
}
}The new DebitFee method subtracts a fee from the account. If the balance is smaller than the amount to be subtracted, the code calls the base class’s OnOverdrawn method to raise the Overdrawn event.
Figure 6-5: An OverdraftAccount object can remove money from its associated SavingsAccount object if necessary.
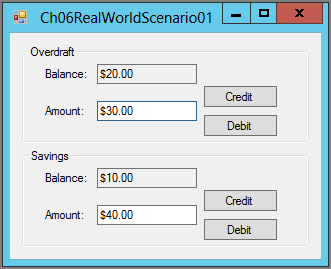
class OverdraftAccount : BankAccount
{
// The associated savings account.
public BankAccount SavingsAccount { get; set; }
// Remove money from the account.
public new void Debit(decimal amount)
{
// See if there is this much money in the account.
if (Balance + SavingsAccount.Balance < amount)
{
// Raise the Overdrawn event.
OnOverdrawn(new OverdrawnEventArgs(Balance, amount));
}
else
{
// Remove the money we can from the overdraft account.
if (Balance >= amount) Balance -= amount;
else
{
amount -= Balance;
Balance = 0m;
// If there's still an unpaid amount, take it from savings.
if (amount > 0m) SavingsAccount.Balance -= amount;
}
}
}
}Subscribing and Unsubscribing to Events
There are several ways you can subscribe and unsubscribe to events depending on whether you want to do so in code or with a form or window designer. The following sections describe those two approaches.
Using Code to Subscribe to an Event
You can use code similar to the following to subscribe to an event:
processOrderButton.Click += processOrderButton_Click;This adds the method named processOrderButton_Click as an event handler for the processOrderButton control’s Click event.
processOrderButton.Click +=
new System.EventHandler(processOrderButton_Click);The following code shows an empty processOrderButton_Click event handler:
void processOrderButton_Click(object sender, EventArgs e)
{
}The parameter list used by the event handler must match the parameters required by the event. In this case, the event handler must take two parameters, a nonspecific object and an EventArgs object.
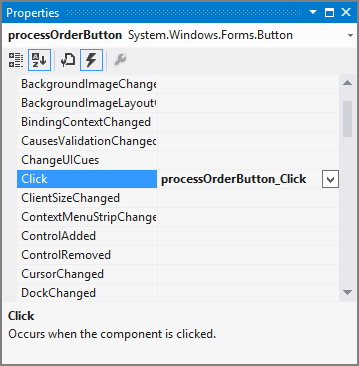
You can write an event handler, or you can let Visual Studio’s code editor generate one for you. If you enter the text processOrderButton.Click +=, the code editor displays the message shown in Figure 6-6. (This message is for a Windows Forms project, but you get a similar message if you write a XAML application.)
Figure 6-6: Visual Studio’s code editor can insert the default event handler name for you.

If you press the Tab key, the code editor inserts the default name for the button, which consists of the button’s name followed by an underscore and then the event’s name, as in processOrderButton_Click.
At that point, if you have not already defined the event handler, the code editor displays the message shown in Figure 6-7. If you press the Tab key, the code editor creates an event handler similar to the following:
Figure 6-7: Visual Studio’s code editor can generate an event handler for you.

void processOrderButton_Click(object sender, EventArgs e)
{
throw new NotImplementedException();
}This initial event handler simply throws an exception to remind you to implement it later. You should delete that statement and insert whatever code you need the event handler to execute.
The following code shows how a program can unsubscribe from an event:
processOrderButton.Click -= processOrderButton_Click;Using Designer to Subscribe to an Event
If you write a Windows Forms application and the event publisher is a control or component that you have added to a form, you can use the form designer to attach an event handler to the event. Open the form in the form designer and select a control. In the Properties window, click the Events button (which looks like a lightning bolt) to see the control’s events. Figure 6-8 shows the Properties window displaying a Form object’s events.
Figure 6-8: Visual Studio’s Properties window enables you to select or create event handlers.
To subscribe an existing event handler to an event, click the event in the Properties window, open the drop-down to its right, and select the event handler.
To create a new empty event handler for an event, double-click the event in the Properties window.
To use the Properties window to unsubscribe from an event, right-click the event’s name and select Reset.
The process for subscribing and unsubscribing events by using the Window Designer in a XAML application is similar to the process for a Windows Forms application. Some of the details are slightly different but the basic approach is the same.
One difference between Windows Forms and XAML applications is where the code is placed to subscribe the event. In a Windows Forms application, that code is normal C# code placed in the form’s designer file, for example, Form1.Designer.cs.
In a XAML application, a Click element is inserted into the XAML code file. The following code snippet shows the definition of a button in a XAML file. The Click element subscribes the processOrderButton_Click event handler to the button’s Click event:
<Button x:Name="processOrderButton" Content="Process Order"
HorizontalAlignment="Left"
VerticalAlignment="Top" Click="processOrderButton_Click" />The previous sections dealt with events. Events trigger some sort of action and, no matter how carefully you write an application, an action can lead to errors. The sections that follow explain how you can use exception handling to catch errors so the program can take reasonable action instead of crashing.
Figure 6-9: The form designer won’t display a form if a subscribed event handler is missing.
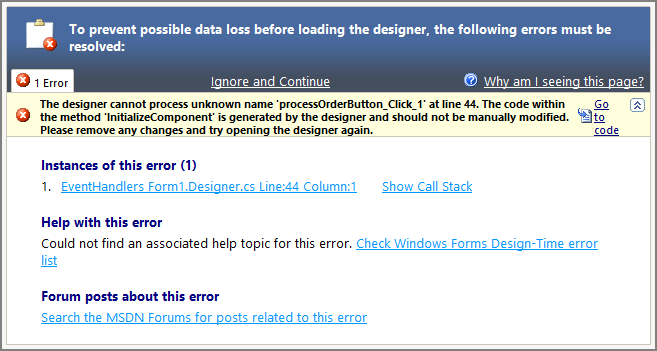
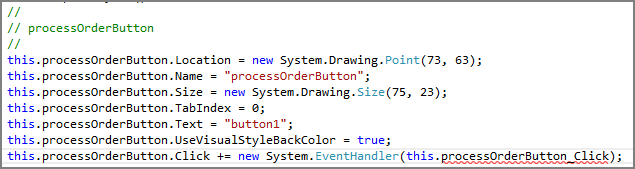
Figure 6-10: Delete the line that subscribes the missing event handler to fix the form.
Exception Handling
No matter how well you design an application, problems are still inevitable. Users will enter invalid values, indispensable files will be deleted, and critical network connections will fail. To avoid and recover from these sorts of problems, a program must perform error checking and exception handling.
Error Checking and Exception Handling
Error checking is the process of anticipating errors, checking to see if they will occur, and working around them. For example, if the user must enter an integer in a text box, eventually someone will enter a non-numeric value. If the program tries to parse the value as if it were an integer, it will crash.
Instead of crashing, the program should validate the text to see if it makes sense before trying to parse it. The int.TryParse method does both, attempting to parse a text value and returning an error indicator if it fails.
Similarly, before opening a file or downloading a file across a network, the program can verify that the file exists and the network connection is present. If the program detects this kind of error, it can tell the user and cancel whatever operation it was attempting.
In contrast to error checking, exception handling is the process of protecting the application when an unexpected error occurs. For example, suppose the program starts downloading a file over a network and then the network disappears. There is no way the program can anticipate this problem because the network was present when the download started.
Even if you validate every value entered by the user and check every possible condition, unexpected exceptions can arise. A file may become corrupted; a network connection that was present may fail; the system may run out of memory; or a code library that you are using and over which you have no control may throw an exception.
If you can, it is generally better to proactively look for trouble before it occurs, rather than react to it after it happens. For example, it is better to check whether a file exists before opening it, rather than just trying to open it and handling an error if the file isn’t there.
If you can spot a problem before it occurs, you usually have a better idea of what the problem is, so you can be more specific when you tell the user what’s wrong. If you look for a file and it’s missing, you can tell the user so. If you try to open a file and fail, you don’t know whether the file is missing, corrupted, locked by another process, or unavailable for some other reason.
Generating exception information also adds some extra overhead to the program, so you’ll usually get better performance if you anticipate errors before they happen.
Even if you validate user input, look for needed files and network connections, and check for every other error you can think of, the program may still encounter unexpected situations. In those cases, a program can protect itself by using try-catch-finally blocks.
try-catch-finally Blocks
The try-catch-finallyblock allows a program to catch unexpected errors and handle them. This block actually consists of three sections: a try section, one or more catch sections, and a finally section. The try section is required, and you must include at least one catch or finally section. Although, you don’t need to include both, and you don’t need to include any code inside the catch or finally section.
The try section contains the statements that might throw an exception. You can include as many statements as you like in this section. You can even nest other try-catch-finally sequences inside a try section to catch errors without leaving the original try section.
The following code shows the syntax for a try section:
try
{
// Statements that might throw an exception.
...
}The following shows the syntax for a catch section:
catch [(ExceptionType [variable])]
{
Statements to execute...
}If an exception occurs in the try section, the program looks through its list of catch sections in the order in which they appear in the code. The program compares the exception that occurred to each catch section’s ExceptionType until it finds an exception that matches.
The exception matches if it can be considered to be of the ExceptionType class. For example, the DivideByZeroException class is derived from the ArithmeticException class, which is derived from the SystemException class, which is derived from the Exception class. If a program throws a DivideByZeroException, then a catch section could match the exception with any of the classes DivideByZeroException, ArithmeticException, SystemException, or Exception. All exception classes inherit directly or indirectly from Exception, so a catch section where ExceptionType is Exception will catch any exception.
When it finds a matching ExceptionType, the program executes that catch section’s statements and then skips any remaining catch sections.
try
{
Statements...
}
catch (SystemException ex)
{
Statements...
}
catch (FormatException ex)
{
Statements...
}
catch (Exception ex)
{
Statements...
}If you omit the ExceptionType, the catch section catches every kind of exception. For example, consider the following code:
int quantity;
try
{
quantity = int.Parse(quantityTextBox.Text);
}
catch
{
MessageBox.Show("The quantity must be an integer.");
}This code tries to parse the value in a TextBox. If the value isn’t an integer, the int.Parse statement throws an exception, and the catch section displays a message box. In this case only one message is appropriate no matter what exception was thrown.
If you include the ExceptionType, then variable is a variable of the class ExceptionType that gives information about the exception. All exception classes provide a Message property that gives textual information about the exception. Sometimes you can display that message to the user, but often the message is technical enough that it might be confusing to users.
If you include the ExceptionType but omit variable, then the catch section executes for matching exception types, but the code doesn’t have a variable that can give information about the exception.
The finally section executes its statements when the try and catch sections are finished no matter how the code leaves those sections. The finally section always executes, even if the program leaves the try and catch sections because of any of the following reasons:
- The code in the try section executes successfully and no catch sections execute.
- The code in the try section throws an exception and a catch section handles it.
- The code in the try section throws an exception and that exception is not caught by any catch section.
- The code in the try section uses a return statement to exit the method.
- The code in a catch section uses a return statement to exit the method.
- The code in a catch section throws an exception.
using (Pen pen = new Pen(Color.Red, 10))
{
// Use the pen to draw...
}Pen pen;
try
{
pen = new Pen(Color.Red, 10);
// Use the pen to draw...
}
finally
{
if (pen != null) pen.Dispose();
}Note that only the code in the try section of a try-catch-finally block is protected by the block. If an exception occurs inside a catch or finally section, the exception is not caught by the block.
You can nest another try-catch-finally block inside a catch or finally section to protect the program from errors in those places. That can make the code rather cluttered, however, so in some cases it may be better to move the risky code into another method that includes its own error handling.
Unhandled Exceptions
An unhandled exception occurs when an exception is thrown and the program is not protected by a try-catch-finally block. This can happen in two ways. First, the statement that throws the error might not be inside a try section of a try-catch-finally block. Second, the statement might be inside a try section, but none of the try-catch-finally block’s catch sections may match the exception.
When a program encounters an unhandled exception, control moves up the call stack to the method that called the code that threw the exception. If that method is executing inside the try section of a try-catch-finally block, its catch sections try to match the exception. If the calling method is not inside the try section of a try-catch-finally block or if no catch section can match the exception, control again moves up the call stack to the method that called this method.
Control continues moving up the call stack until one of two things happens. First, the program may find a method with an active try-catch-finally block that has a catch section that can handle the exception. In that case, the catch section executes its code, and the program continues running from that point.
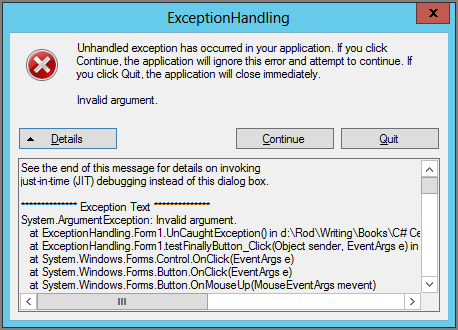
The second thing that can happen is control pops off the top of the stack and the program crashes. If you are running inside the Visual Studio environment, the program stops at the statement that caused the unhandled exception, and you see an error message similar to the one shown in Figure 6-11.
If a program is running outside of Visual Studio and encounters an unhandled exception, control unwinds up the call stack and a message similar to the one shown in Figure 6-12 appears.
Normally a program spends most of its time doing nothing while it waits for an event to occur. When an event occurs, for example if the user clicks a button or selects a menu item, the program takes some action. If that action causes an unhandled exception, the user sees the message shown in Figure 6-12.
Figure 6-11: If a program running inside Visual Studio encounters an unhandled exception, execution stops at the statement that threw the exception and this message box appears.
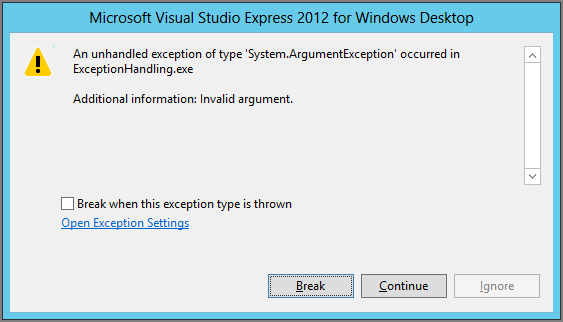
Figure 6-12: If a program running outside of Visual Studio encounters an unhandled exception, this message box appears.
If the user clicks Quit, the program ends. If the user clicks Continue, the program attempts to continue running. Normally that means it goes back to doing nothing while it waits for another event to occur.
Common Exception Types
The .NET Framework defines hundreds of exception classes to represent different error conditions. Figure 6-13 shows the hierarchy of some of the most common and useful exception classes defined in the System namespace. Table 6-2 describes the classes.
Figure 6-13: All of the exception classes in this hierarchy are descendants of the System.Exception class.
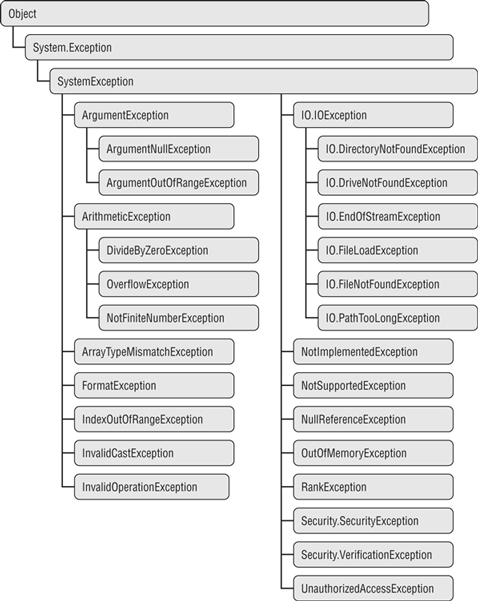
Table 6-2: Useful Exception Classes
| Class | Description |
| Object | This class is the ancestor of all classes. |
| System.Exception | This is the ancestor class of all exception classes. It represents errors at a high level. |
| SystemException | This is the base class for exceptions defined in the System namespace. |
| ArgumentException | One of a method’s arguments is invalid. |
| ArgumentNullException | An argument was null but null is not allowed. |
| ArgumentOutOfRangeException | An argument was outside of the allowed range of values. |
| ArithmeticException | An arithmetic, casting, or conversion error occurred. |
| DivideByZeroException | The program tried to divide an integral or decimal value by 0. This exception is not thrown for floating point operations. If a program divides a floating point value by zero, the result is the special value Infinity. |
| OverflowException | A checked arithmetic, casting, or conversion operation results in an overflow. |
| NotFiniteNumberException | A floating point operation gave a result that was infinity, negative infinity, or NaN (not a number). |
| ArrayTypeMismatchException | The program tried to store the wrong kind of item in an array. |
| FormatException | An argument has an incorrect format. |
| IndexOutOfRangeException | The program tried to access an array element with an index that is outside of the array. |
| InvalidCastException | A cast or conversion was invalid. |
| InvalidOperationException | A method call was invalid for an object’s current state. |
| IO.IOException | An input/output error occurred. |
| IO.DirectoryNotFoundException | A part of a file or directory path was not found. |
| IO.DriveNotFoundException | The program tried to access a drive or network share that is not available. |
| IO.EndOfStreamException | The program tried to read past the end of a stream. |
| IO.FileLoadException | The program tried to load an assembly that is present but could not be loaded. |
| IO.FileNotFoundException | The program tried to access a file that could not be found. |
| IO.PathTooLongException | The program tried to use a path or filename that is too long. |
| NotImplementedException | The program tried to access a feature that is not implemented. You can throw this exception to act as a placeholder for features that you have not yet implemented. |
| NotSupportedException | The program tried to invoke a method that is not supported. You can throw this exception to indicate a method that has been removed in recent versions of a library. |
| NullReferenceException | The program tried to access an object through a null reference. |
| OutOfMemoryException | There is not enough memory for the program to continue. It is hard to recover from this exception because there may not be enough memory to do anything useful. |
| RankException | The program passed an array with the wrong number of dimensions to a method. |
| Security.SecurityException | The program detected a security error. |
| Security.VerificationException | Security policy requires code to be type safe, and the code could not be verified as type safe. |
| UnauthorizedAccessException | The operating system denied access because of an input/output or security error. |
In addition to these basic exceptions, the .NET Framework defines several other exception classes that have more specialized use. For example, SQL exceptions can occur when a program works with SQL Server databases.
The following sections describe some of the more common and useful of these specialized exception classes.
SQL Exceptions
SQL Server uses the single class System.Data.SqlClient.SqlException to represent all errors and exceptions. You can use the SqlException object’s properties to determine what has gone wrong and how severe it is.
Table 6-3 describes some of the most useful SqlException class properties.
Table 6-3: Useful SqlException Properties
| Property | Description |
| Class | A number between 0 and 25 giving the type of error. Values 20 through 25 are fatal and the database connection closes. The values indicate 0–10: Information messages rather than errors. 11–16: User problems that can be fixed by the user. 17: SQL Server has run out of a configurable resource such as locks. The DBA may fix this. 18: A nonfatal internal software problem. 19: SQL Server has exceeded a nonconfigurable resource limit. 20: A problem occurred in a statement issued by the current process. 21: SQL Server encountered a problem that affects all processes in a database. 22: A table or index has been damaged. 23: The database is suspect. 24: Hardware problem. 25: System error. |
| LineNumber | Returns the line number within the T-SQL command batch or stored procedure that caused the error. |
| Message | Returns a message describing the problem. |
| Number | Returns the error number. |
| Procedure | Returns the name of the stored procedure or remote procedure call that caused the error. |
The System.Data.Common.DbException class is the parent class of SqlException and three other classes that return similar information for other database types. The following list summarizes the three other child DbException child classes:
- System.Data.Odbc.OdbcException: Errors in ODBC databases
- System.Data.OleDb.OleDbException: Errors in OLE DB databases
- System.Data.OracleClient.OracleException: Errors in Oracle databases
All these classes provide a Message property that gives information about the exception, although they do not provide the Class, LineNumber, Number, and Procedure properties provided by the SqlException class.
Overflow Exceptions
By default, a C# program does not throw an exception if an arithmetic operation causes an integer overflow. If the operands are integral or decimal, the program discards any extra bits, returns a truncated result, and continues running as if nothing had gone wrong. In that case you might not be aware that the result is gibberish.
You can make the program throw an OverflowException either by using a checked block or by using the Advanced Build Settings dialog. For more information, see the section “Using Widening and Narrowing Conversions” in Chapter 4, “Using Types.”
A C# program also doesn’t throw an exception if a floating point operation causes an overflow or underflow, or if it produces the special value NaN (which stands for “not a number”).
The floating point types define static properties PositiveInfinity, NegativeInfinity, and NaN. You can compare a floating point variable to the PositiveInfinity and NegativeInfinity values. However, if you compare a variable to NaN, the result is always false. (Even float.NaN == float.NaN returns false.)
Instead of trying to compare results to the special values, it is better to use the type’s methods to determine whether a variable holds one of these special values. Table 6-4 describes these methods.
Table 6-4: Floating Point Special Value Methods
| Method | Description |
| IsInfinity | Returns true if the value is PositiveInfinity or NegativeInfinity |
| IsNaN | Returns true if the value is NaN |
| IsNegativeInfinity | Returns true if the value is NegativeInfinity |
| IsPositiveInfinity | Returns true if the value is PositiveInfinity |
Using the special value methods listed in Table 6-4 makes code easier to understand and protects the code in case the special values such as PositiveInfinity change in some later version of .NET, for example if the float data type moves to 64 bits.
- N isn’t an integer
- N < 0
- Overflow
- Other unexpected problems
// Calculate a number's factorial.
private long Factorial(long n)
{
long result = 1;
for (long i = 2; i <= n; i++) result *= i;
return result;
}// Calculate a number's factorial.
private long Factorial(long n)
{
// Make sure n >= 0.
if (n < 0) throw new ArgumentOutOfRangeException(
"n", "The number n must be at least 0 to calculate n!");
checked
{
long result = 1;
for (long i = 2; i <= n; i++) result *= i;
return result;
}
}// Calculate the number's factorial.
private void calculateButton_Click(object sender, EventArgs e)
{
resultTextBox.Clear();
try
{
long n;
if (!long.TryParse(nTextBox.Text, out n))
{
MessageBox.Show("The number must be an integer.");
return;
}
resultTextBox.Text = Factorial(n).ToString();
}
catch (ArgumentOutOfRangeException)
{
MessageBox.Show("The number must be at least 0.");
}
catch (OverflowException)
{
MessageBox.Show("This number is too big to calculate its factorial.");
}
catch (Exception ex)
{
MessageBox.Show(ex.ToString());
}
}Exception Properties
The System.Exception class, which is an ancestor of all other exception classes, defines several properties that a program can use to try to determine what is happening and to tell the user about the problem. Table 6-5 describes those properties.
Table 6-5: Exception Class Properties
| Property | Description |
| Data | A collection of key/value pairs that give extra information about the exception. |
| HelpLink | A link to a help file associated with the exception. |
| HResult | A numeric code describing the exception. |
| InnerException | An Exception object that gives more information about the exception. Some libraries catch exceptions and wrap them in new exception objects to provide information that is more relevant to the library. In that case, they may include a reference to the original exception in the InnerException property. |
| Message | A message describing the exception in general terms. |
| Source | The name of the application or object that caused the exception. |
| StackTrace | A string representation of the program’s stack trace when the exception occurred. |
| TargetSite | Information about the method that threw the exception. |
The Message property doesn’t tell exactly where the error occurred, but tells in general terms what went wrong. For example, an OverflowException object’s Message property is Arithmetic Operation Resulted in an Overflow.
Many programs simply display an exception’s Message to the user and let the user try to determine what went wrong. Although an exception’s Message is correct, it isn’t user-friendly and doesn’t tell the user what calculation caused the exception or how to fix it. A better solution is for the program to catch the exception and display a more meaningful message to the user.
For example, suppose a program processes an order form and catches an OverflowException while multiplying quantity by price per unit for the third item on the form. Instead of telling the user, Arithmetic Operation Resulted in an Overflow, it would be better to say something like, “Quantity Times Price Is Too Large for Item Number 3. Please Enter Smaller Values for Those Amounts.” (It would be even better to validate the quantity and price separately so that you could display a message such as Quantity Must Be Between 1 and 100.)
An exception’s Message isn’t quite specific enough to show a user, but it is sometimes enough to show developers during debugging. The Exception class’s ToString method, however, provides even more useful information for developers. It includes the name of the exception’s class, the Message property, and a stack trace. For example, an OverflowException object’s ToString method might return the following text:
System.OverflowException: Arithmetic operation resulted in an overflow.
at OrderProcessor.OrderForm.CalculateSubtotal() in
d:SupportAppsOrderProcessorOrderForm.cs:line 166Using the class name included in this information, you can add a new catch section to the try-catch-block to look specifically for this exception and display a more user-friendly error message.
Throwing and Rethrowing Exceptions
A method can use a try-catch-finally block to catch exceptions. If that method interacts with the user, it can display a message to tell the user about the problem.
However, often a method should not interact directly with the user. For example, if you’re writing a library of tools that will be called by other methods, your methods probably shouldn’t interact directly with the user. Instead those methods should throw exceptions of their own to tell the calling code what went wrong, and then let that code deal with the problem. That code might display a message to the user, or it might handle the problem without bothering the user.
The question then becomes, “What exceptions should your method catch, what exceptions should it ignore, and what exceptions should it throw?” The following sections discuss some of the issues involved in catching, throwing, and rethrowing exceptions.
Using Exceptions and Return Values
A method can take some action and then return information to the calling code through a return value or through output parameters. Exceptions give a method one more way to communicate with the calling code. An exception tells the program that something exceptional has happened and that the method may not have finished whatever task it was performing.
There is some discussion on the Internet about when a method should return information through a return value or parameters, and when it should return information through an exception. Most developers agree that normal status information should be returned through a return value and that exceptions should be used only when there’s an error.
The best way to decide whether to use an exception is to ask if the calling code should be allowed to ignore the method’s status. If a method returns status information through its return value, the calling code can ignore it. If the method throws an exception, the calling code must include a try-catch-block to handle the exception explicitly.
For example, consider the following method that returns the factorial of a number:
// Calculate a number's factorial.
private long Factorial(long n)
{
// Make sure n >= 0.
if (n < 0) return 0;
checked
{
try
{
long result = 1;
for (long i = 2; i <= n; i++) result *= i;
return result;
}
catch
{
return 0;
}
}
}If the parameter is less than zero or if the calculation causes an integer overflow, the method returns the value 0. Because 0 is not a valid value for the factorial function, the calling code can detect that something went wrong.
There are two problems with this approach. First, the calling code could ignore the error and treat the value 0 as a number’s factorial, giving an incorrect result. If the value is used in a complex calculation, the error might become embedded in the calculation. The program would produce an incorrect result that might be hard to notice and fix later.
The second problem is that the calling code cannot tell what went wrong. The return value 0 doesn’t indicate whether the input parameter was less than 0 or whether there was an integer overflow. You could use multiple return values, so 0 means the parameter was less than 0, and –1 means an integer overflow, but that just creates more status values that the calling code can ignore.
A better solution is to throw appropriate exceptions when appropriate. The following version of the Factorial method, which was shown earlier in this chapter, uses exceptions:
// Calculate a number's factorial.
private long Factorial(long n)
{
// Make sure n >= 0.
if (n < 0) throw new ArgumentOutOfRangeException(
"n", "The number n must be at least 0 to calculate n!");
checked
{
long result = 1;
for (long i = 2; i <= n; i++) result *= i;
return result;
}
}If the parameter is less than zero, the code throws an exception. Because the calculations are enclosed in a checked block, if they cause an integer overflow, they will throw an OverflowException.
In contrast to the Factorial method, suppose the SendInvoice method sends an invoice to a customer. Depending on the customer’s preferences, the method might send e-mail, send a fax, or print an invoice for mailing.
As long as this method sends an invoice, the calling code can probably ignore it. In that case the method could return a status value to indicate which method it used.
However, if the method failed to send an invoice for any reason, it should throw an exception, so the calling code knows the customer will not receive an invoice.
Catching, Throwing, and Rethrowing Exceptions
If a method can explain why an exception occurred rather than merely reporting that an exception did occur, or if it can add new information to make an exception more specific, then it should catch the exception and throw a new one that includes the new information.
For example, suppose a mapping program reads different files with obscure names such as D:mparam.na.wv.map depending on which part of the world it needs to map. If a file is missing, the method receives a FileNotFoundException that includes the name of the file that is missing, but passing that name back to the calling code probably won’t be helpful to the user. In this case it would make sense to catch the exception and throw a new FileNotFoundException with the message, “Could Not Find the Map File for West Virginia.”
If you throw a new exception in this manner, it is good practice to include the original exception in the new exception’s InnerException property so that the calling code has access to the original information if that would be helpful.
If a method cannot add any information to an exception, it should usually not catch it. Instead, it should let the exception move up the call stack and let the calling code handle it.
For example, if the LoadParameters method tries to load settings from file Cparameters.txt and receives a FileNotFoundException, there’s no reason for it to catch the exception. The calling code knows which file wasn’t found, so the method can’t actually add any new information to the exception.
One time when you might want to break this rule is when you want the method to take some “private” action before allowing the exception to move up the call stack. For example, suppose you’re writing a library of tools for other programmers to use. When a method encounters an exception, you may want it to save information about the exception in a log file so that you can fix the problem later. In that case, you might want the method to catch an exception, log the error, and then rethrow the exception so that it can move up the call stack normally.
To rethrow the current exception, use the throw statement without passing it an exception. The following code snippet demonstrates this technique:
try
{
// Do something dangerous.
...
}
catch (Exception)
{
// Log the error.
...
// Re-throw the exception.
throw;
}Contrast this code with the following version:
try
{
// Do something dangerous.
...
}
catch (Exception ex)
{
// Log the error.
...
// Re-throw the exception.
throw ex;
}The new version explicitly throws the same exception object that the try-catch-finally block caught. When the code throws an exception in this way, the exception’s call stack is reset to the current location so that it refers to the line of code that contains the throw statement. That may mislead any programmers who try to locate a problem by making them look at the wrong line of code. The situation is even worse if the line of code that threw the exception was inside another method called by this one. If you rethrow the exception in this way, the fact that the error is in another method is lost.
In all cases a method should clean up as much as possible before throwing or rethrowing an exception. If the method opens a file or connects to a database, it should close the file or database connection before throwing an exception, leaving the calling code with as few side effects as possible.
Creating Custom Exceptions
When your code encounters a problem, it can throw an exception to tell the calling code about it. If possible, you should throw one of the exception classes defined by the .NET Framework. The predefined exception classes have specific meanings so, if you use one, other developers will have a good idea what the exception represents.
Sometimes, however, you may not find a predefined exception class that fits your situation well. In that case, you can create your own exception class.
Derive the new class from the Exception class. End the new class’s name with the word Exception.
To make the new class as useful as possible, give it constructors that match those defined by the Exception class. The following code shows a simple InvalidException class that provides four constructors that take parameters similar to those used by the constructors defined in the Exception class:
[Serializable]
class InvalidProjectionException : Exception
{
public InvalidProjectionException()
: base() { }
public InvalidProjectionException(string message)
: base(message) { }
public InvalidProjectionException(string message,
Exception innerException)
: base(message, innerException) { }
protected InvalidProjectionException(SerializationInfo info,
StreamingContext context)
: base(info, context) { }
}Each of the constructors simply passes its parameters to the base class’s constructors. The SerializationInfo and StreamingContext types are defined in the System.Runtime.Serialization namespace.
Making Assertions
The System.Diagnostics.Debug class provides an Assert method that is often used to validate data as it passes through a method. This method takes a boolean value as its first parameter and throws an exception if that value is false. Other parameters let you specify other messages to display to give you more information about where the assertion failed.
In a debug build, the Assert method halts execution and displays a stack trace. In a release build, the program skips the call to Assert, so it continues running even if the assertion is false.
A method can use Assert to verify that its data makes sense. For example, suppose the PrintInvoice method takes as a parameter an array of OrderItem objects named items and prints an invoice for those items. The method might begin with the following Assert statement to verify that the items array contains no more than 100 items:
Debug.Assert(items.Length <= 100)If an order contains more than 100 items, the Assert statement halts execution, so you can examine the code to decide whether this is a bug or just an unusual order. If this is a valid but unusual order, you can change the statement to look for orders that contain more than 150 items.
In a release build, this Assert statement is ignored, so the program must be prepared to handle orders that contain many items, even if the Assert statement would not allow that in a debug build.
If a piece of data is invalid and the program cannot continue, throw an exception. If a piece of data is unusual and may indicate a bug but the program can meaningfully continue, use Debug.Assert to detect the unusual value during testing.
Summary
This chapter described two methods that different parts of a program can use to communicate: events and exceptions.
Events enable an object to notify other parts of the application when some interesting event occurs. To define and raise an event, a program must use delegates, so this chapter explained delegates. It also explained anonymous methods and lambda expressions, which enable you to make methods that have no names but that can be stored in delegate variables and that can be used as event handlers.
Exceptions let a method tell the calling code that it has encountered a critical problem. This chapter explained how to use the try-catch-block to catch and handle exceptions. It also explained how and when your code can throw exceptions. It described some of the more useful predefined exception classes and explained how you can define new custom exception classes when none of the predefined classes fit your needs.
There are three kinds of lambda expressions: expression lambdas, statement lambdas, and async lambdas. This chapter described all three but only briefly mentioned async lambdas, which let a program indicate that the lamba expression will run asynchronously.
Chapter 7 explains asynchronous processing and multithreading in greater detail. It explains how a program can run processes on different threads to improve responsiveness and how to use asynchronous code such as that defined by async lambdas.
Chapter Test Questions
Read each question carefully and select the answer or answers that represent the best solution to the problem. You can find the answers in Appendix A, “Answers to Chapter Test Questions.”
if (base.EventName != null) base.EventName(this, args);Additional Reading and Resources
Here are some additional useful resources to help you understand the topics presented in this chapter:
Delegates (C# Programming Guide) http://msdn.microsoft.com/library/ms173171.aspx
Anonymous Methods (C# Programming Guide) http://msdn.microsoft.com/library/0yw3tz5k.aspx
Lambda Expressions (C# Programming Guide) http://msdn.microsoft.com/library/bb397687.aspx
Events (C# Programming Guide) http://msdn.microsoft.com/library/awbftdfh.aspx
How to: Raise Base Class Events in Derived Classes (C# Programming Guide) http://msdn.microsoft.com/library/hy3sefw3.aspx
Best Practices for Handling Exceptions http://msdn.microsoft.com/library/seyhszts.aspx
Exception Handling Best Practices in .NET http://www.codeproject.com/Articles/9538/Exception-Handling-Best-Practices-in-NET
SqlException Class http://msdn.microsoft.com/library/system.data.sqlclient.sqlexception.aspx
SystemException Class inheritance hierarchy http://msdn.microsoft.com/library/system.systemexception.aspx#inheritanceContinued
AppDomain Class http://msdn.microsoft.com/library/system.appdomain.aspx
Cheat Sheet
This cheat sheet is designed as a way for you to quickly study the key points of this chapter.
Working with delegates
- A delegate is a type that represents a kind of method. It defines the method’s parameters and return type.
- Often the name of a delegate type ends with Delegate or Callback.
- You can use + and – to combine delegate variables. For example, if a program executes the statement del3 = del1 + del2, then del3 will execute the methods referred to by del1 and del2.
- If a delegate variable refers to an instance method, it executes with the object on whose instance it was assigned.
- Covariance lets a method return a value from a subclass of the result expected by a delegate.
- Contravariance lets a method take parameters that are from a superclass of the type expected by a delegate.
- The .NET Framework defines two built-in delegate types that you can use in many cases: Action and Func. The following code shows the declarations for Action and Func delegates that take two parameters:
public delegate void Action<in T1, in T2>(T1 arg1, T2 arg2) public delegate TResult Func<in T1, in T2, out TResult> (T1 arg1, T2 arg2)
- An anonymous method is a method with no name. The following code saves a reference to an anonymous method in variable function:
Func<float, float> function = delegate(float x) { return x * x; };
- A lambda expression uses a concise syntax to create an anonymous method. The following code shows examples of lambda expressions:
Action note1 = () => MessageBox.Show("Hi"); Action<string> note2 = message => MessageBox.Show(message); Action<string> note3 = (message) => MessageBox.Show(message); Action<string> note4 = (string message) => MessageBox.Show(message); Func<float, float> square = (float x) => x * x;
- An expression lambda evaluates a single expression whose value is returned by the anonymous method.
- A statement lambda executes a series of statements. It must use a return statement to return a value.
- An async lambda is a lambda expression that includes the async keyword.
Working with events
- Events have publishers and subscribers. A given event may have many subscribers or no subscribers.
- Use a delegate type to define an event, as in the following code:
public delegate void OverdrawnEventHandler(); public event OverdrawnEventHandler Overdrawn;
- You can use the predefined Action delegate type to define events, as in the following code:
public event Action Overdrawn;
- Microsoft best practice: Make the event’s first parameter a sender object and the second an object that gives more information about the event. Derive the type of the object from the EventArgs class, and end its name with Args as in OverdrawnEventArgs.
- You can use the predefined EventHandler delegate type to define an event that takes an object named sender as a first parameter and an event data object as a second parameter, as shown in the following code:
public event EventHandler<OverdrawnEventArgs> Overdrawn;
- Raise an event, as in the following code:
if (EventName != null) EventName(arguments...);
- Classes cannot inherit events. To make it possible for derived classes to raise base class events, give the base class an OnEventName method that raises the event.
- A program can use += and -= to subscribe and unsubscribe from events.
- If a program subscribes to an event more than once, the event handler is called multiple times.
- If a program unsubscribes from an event more times than it was subscribed, nothing bad happens.
Exception handling
- Error checking is the process of proactively anticipating errors and looking for them. Exception handling is the process of protecting a program from unexpected errors. Error checking is usually more efficient than exception handling.
- A try-catch-finally block must have at least one catch section or a finally section.
- The finally section always executes no matter how the program leaves a try-catch-finally block.
- The most-specific (most-derived) catch sections must come first in a try-catch-finally block.
- You can include only an exception type and omit the exception variable in a catch section if you don’t need to do anything with the exception.
- The Exception class is an ancestor of all exception classes, so catch (Exception) catches all exceptions.
- A catch section with no exception type catches all exceptions.
- A using statement is equivalent to a try-catch-finally block with a finally section that disposes of the object.
- If an exception is not handled, control moves up the call stack until either a try-catch-finally block handles it or the program crashes.
- An exception object’s Message property gives information about the exception. Its ToString method includes the Message plus additional information including a stack trace.
- The SqlException class represents all SQL Server exceptions. Properties such as Class and Message give additional information about the error.
- By default, integer operations do not throw OverflowExceptions. Use a checked block or the Advanced Build Settings dialog to make overflows throw this exception.
- Floating point operations do not cause overflow. Instead they set the result to PositiveInfinity, NegativeInfinity, or NaN.
- Use the floating point methods IsInfinity, IsInfinity, IsInfinity, and IsNaN to determine whether a result is one of these special values.
- To rethrow the current exception, use the throw statement without passing it an exception object. To rethrow the exception ex while resetting its stack trace, use throw ex.
- To return noncritical status information, a method should return a status value. To prevent a program from ignoring a critical issue, a method should throw an exception.
- If a method cannot add useful information to an exception, it should not catch and rethrow it. Instead it should let it propagate up to the calling code.
- To create a custom exception, derive it from the System.Exception class and end its name with Exception. Mark it serializable and give it constructors that match those defined by the Exception class.
- You can use Debug.Assert to throw an exception in a debug build to find suspicious data. The statement is ignored in release builds, so the program must continue even if Debug.Assert would stop the program in a debug build.
- If you catch an exception and throw a new one to add extra information, include a reference to the original exception in the new one’s InnerException property.
- Clean up as much as possible before throwing or rethrowing an exception so that the calling code faces as few side effects as possible.
Review of Key Terms
checked By default, a program doesn’t throw OverflowExceptions when an arithmetic operation causes an overflow. A program can use a checked block to make arithmetic expressions throw those exceptions.
contravariance A feature of C# that enables a method to take parameters that are from a superclass of the type expected by a delegate. For example, suppose the Employee class is derived from the Person class and the EmployeeParameterDelegate type represents methods that take an Employee object as a parameter. Then you could set an EmployeeParameterDelegate variable equal to a method that takes a Person as a parameter because Person is a superclass of Employee. When you invoke the delegate variable’s method, you will pass it an Employee (because the delegate requires that the method take an Employee parameter) and an Employee is a kind of Person, so the method can handle it.
contravariant A variable is contravariant if it enables contravariance.
covariance A feature of C# that enables a method to return a value from a subclass of the result expected by a delegate. For example, suppose the Employee class is derived from the Person class and the CreatePersonDelegate type indicates a method that returns a Person object. Then you could set a CreatePersonDelegate variable equal to a method that returns an Employee because an Employee is a kind of Person.
delegate A data type that defines a method with given parameters and return value.
error checking The process to anticipate errors, check to see if they occur, and work around them, for example, validating an integer entered by the user in a TextBox instead of simply trying to parse it and failing if the value is not an integer. See also exception handling.
exception handling The process to protect the application when an unexpected error occurs, for example, protecting the code in case a file downloads fails when it is halfway done. See also error checking.
expression lambda A lambda expression that has a single expression on the right side.
lambda expression A concise syntax for defining anonymous methods.
publisher An object that raises an event.
statement lambda Similar to an expression lambda except it encloses its code in braces and it can execute more than one statement. If it should return a value, it must use a return statement.
subscriber An object that receives an event.
try-catch-finally block The program structure used to catch exceptions. The try section contains the code that might throw an exception, catch sections catch different exception types, and the finally section contains code to be executed when the try and catch sections finish executing.
unhandled exception Occurs when an exception is thrown and the program is not protected by a try-catch-finally block, either because the code isn’t inside a try section or because there is no catch section that matches the exception.