
6
AJAX
At this point in the book you are familiar with HTML's versatile markup vocabulary for structuring content (Chapter 2) and HTTP, the primary protocol for requesting information from web servers (Chapter 5). In combination, these two technologies not only provide the foundation for virtually all web services, but they also define a reliable infrastructure for disseminating information throughout the Web.
Despite their popularity, HTML/HTTP impose strict constraints on the way users access information. If you abstract from the examples we have previously introduced, you find that the HTML/HTTP infrastructure implies a rather static display of content in a page layout, which is retrieved through sequential, iterative requests initiated by the user. The inherent inflexibility of HTML/HTTP is most apparent in its inability to create more dynamic displays of information, such as we are used to from standard desktop applications. After receiving an HTML document from the server the visual appearance of the screen will not change since HTTP provides no mechanism to update a page after it has been downloaded. What impedes HTML/HTTP from providing content more dynamically is its lack of three critical elements:
- a mechanism to register user behavior in the browser (and not just on the server);
- a scripting engine to formulate responses to those events;
- a more versatile data requesting mechanism for fetching information asynchronously.
Because HTML/HTTP is technically unable to provide any of the above features, a series of additional web technologies have found their way into the toolkit of modern web developers over the last 15 years. A prominent role in this transformation is assumed by a group of technologies that are subsumed under the term AJAX, short for “Asynchronous JavaScript and XML.” AJAX has become a staple web technology to which we owe much of the sophistication of modern web applications such as Facebook, Twitter, the Google services, or any kind of shopping platform.
Although AJAX-enriched websites provide tremendous advantages from a user perspective, they create difficulties for our efforts to automatically gather web data. This is so because AJAX-enriched webpages constitute a significant departure from the static HTML/HTTP site model in which a HTTP-requested webpage is displayed equally for all users and all information that is displayed on screen is delivered upfront. This presents a serious obstacle to analysts who care to collect web data since a simple HTTP GET request (see Section 5.1.4) may not suffice if information is loaded iteratively only after the site has been requested. We will see that the key to circumventing this problem is to understand at which point the data of interest is loaded and apply this knowledge to trace the origin of the data.
The remainder of this chapter introduces AJAX technologies that turn static into dynamic HTML. We will focus on the conceptual ideas behind AJAX that will inform solutions for data retrieval. In Section 6.1 we start by introducing JavaScript, the most popular programming language for web content and show how it turns HTML websites into dynamic documents via DOM manipulation. In Section 6.2 we discuss the XMLHttpRequest, an Application Programming Interface (API) for browser–server communication and important data retrieval mechanism for dynamic web applications. Finally, to solve problems caused by AJAX, Section 6.3 explicates how browser-implemented Developer Tools can be helpful for gathering insight into a page's underlying structure as well as tracing the source of dynamic data requests.
6.1 JavaScript
The JavaScript programming language has a prominent role in the group of AJAX technologies. Developed by Brendan Eich at Netscape in 1995, JavaScript is a complete, high-level programming language (Crockford 2008). What sets JavaScript apart from other languages is its seamless integration with other web technologies (e.g., HTML, CSS, DOM) as well as its support by all modern browsers, which contain powerful engines to interpret JavaScript code. Because JavaScript has become such an important part in the architecture of web applications, the language has been raised to a W3C web standard. Similar to R’s packaging system, extra functionality in JavaScript is incorporated through the use of libraries. In fact, most web development tasks are not executed in native JavaScript code anymore, but are carried out using special purpose JavaScript libraries. We follow this practice for the examples in this chapter and use functionality from jQuery—the self-ascribed “write less, do more” library—with a particular focus on easing DOM manipulation.
6.1.1 How JavaScript is used
To recognize JavaScript in the wild, it is important to know that there are three methods for enhancing HTML with JavaScript functionality. A dedicated place for in-line code to appear is between the HTML <script> tags (see also Section 2.3.10). These tags are typically located before the <head> section of the document but they may as well be placed at any other position of the document. Another way is to make reference to an externally stored JavaScript code file via a path passed to the scr attribute of the <script> element. This method helps to organize HTML and JavaScript at two separate locations and thus eases maintainability. Lastly, JavaScript code can appear directly in an attribute of a specific HTML element in so-called event handlers. Regardless of the method, a JavaScript-enhanced HTML file requires the browser to not only parse the HTML content and construct the DOM, but also to read the JavaScript code and carry out its commands. Let us illustrate this process with JavaScript's DOM manipulation functionality.
6.1.2 DOM manipulation
A popular application for JavaScript code is to create some kind of alteration of the information or appearance of the current browser display. These modifications are called DOM manipulations and they constitute the basic procedures for generating dynamic browser behavior. The possible alterations allowed in JavaScript are manifold: HTML elements may either be removed, added or shifted, attributes to any HTML element can be added or changed, or CSS styles can be modified. To show how such scripts may be employed, consider fortunes1.html for a lightly JavaScript-enriched webpage.
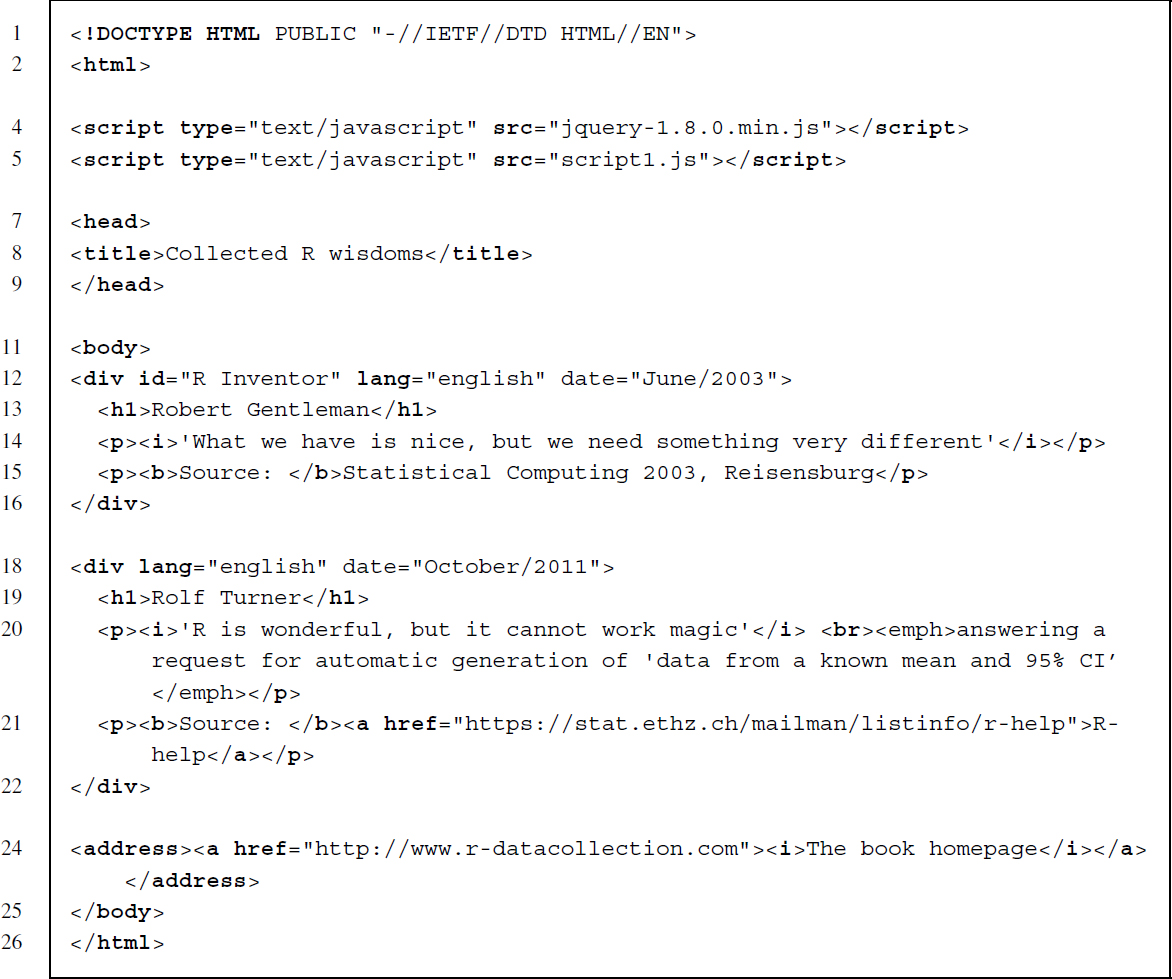
For the most part, the code is identical to the fortunes example we introduced in Section 2.4.1. The only modification of the file concerns the extra code appearing in lines 4 and 5. The HTML <script> element offers a way to integrate HTML with functionality drawn from other scripting languages. The type of scripting language to be used is set via the type attribute. Since browsers expect that incorporated code is written in JavaScript by default, we can leave this attribute unspecified. Here, we include JavaScript using the reference method as it helps emphasize the conceptual difference between the two documents and enhances clarity. In line 4 we make a reference to the jQuery library for which there exists a copy in the folder of the HTML document. By referencing the file jquery-1.8.0.min.js, jQuery can be accessed throughout the program. The next line makes a reference to the file script1.js, which includes the code responsible for the DOM alterations. To view the file's content, you can open the file in any text processor:

Before explaining the script, take the time to download the fortunes1.html file from the materials section at http://www.r-datacollection.com and open it in a browser to discover differences to the example file in Section 2.4.1. Opening the file you should see two named headers and a hyperlink to the book's homepage (see Figure 6.1, panel (a)). Apparently, some information that is contained in the HTML code, such as the quotes and their contexts, has been concealed in the browser display of the webpage. Assuming that JavaScript is enabled in your browser, a click on one of the headers should initiate a rolling transition and further content relating to the quote should become visible (see Figure 6.1, panel (b)). Another click on the header results in the content being hidden again. The dynamic behavior just observed is the result of the code in script1.js. To get an understanding of how these behaviors are produced, let us parse this code line by line and discuss what it does.

Figure 6.1 Javascript-enriched fortunes1.html (a) Initial state (b) After a click on “Robert Gentleman”
The first line starts with the $() operator, jQuery's method for selecting elements in the DOM. Inside the parentheses we write document to indicate that all elements that are defined in the DOM are to be selected. The returned selection of the $() operator is passed to the ready() method. Essentially, the document ready handler ready() instructs the script to pause all JavaScript code execution until the entire DOM has been built inside the browser, meaning that all the HTML elements are in existence. This is necessary for any reasonably sized HTML file since the browser will take some time to build the DOM. Not instructing the script to pause until all HTML information is loaded could lead to a situation where the script acts on elements that do not yet exist in the DOM. The essential part starts in line 2, which defines the dynamic behaviors. Once again we employ the $() operator but only to select all the <p> nodes in the document. As you can see in fortunes1.html, these are the elements that contain more information on the quote and its source. The selection of all paragraph nodes is passed to the hide() method, which accounts for the behavior that in the initial state of the page all paragraph elements are hidden. The third line initiates a selection of all <h1> header nodes in the document, which are used to mark up the names of the quoted. We bind an event handler to this selection for the “click” JavaScript event. The click() handler allows recognizing whenever a mouse click on a <h1> element in the browser occurs and to trigger an action. What we want the action to be is defined in the parentheses from lines 3 to 5. On line 4, we first return the element on which the click has occurred via $(this). The nextAll() method selects all the nodes following after the node on which the click has occurred (see Section 4.1 for the DOM relations) and binds the slideToggle() method to this selection, which defines a rather slow (300 ms) toggle effect for fading the elements in and out again.
On a conceptual level, this example illustrates that the underlying HTML code and the information displayed in the browser do not necessarily coincide in a JavaScript-enriched website. This is due to the flexibility of the DOM and JavaScript that allow HTML elements to be manipulated, for example, by fading them in and out. But what are the implications of this technology for scraping information from this page? Does DOM manipulation complicate the scraping process with the tools introduced earlier? To address this question, we parse fortunes1.html into an R object and display its content:
R> library(XML)
R> (fortunes1 <- htmlParse(”fortunes1.html”))
<!DOCTYPE HTML PUBLIC ”-//IETF//DTD HTML//EN”>
<html>
<head>
<script type=”text/javascript” src=”jquery-1.8.0.min.js”></script><script
type=”text/javascript” src=”script1.js”></script><title>Collected R wisdoms
</title>
</head>
<body>
<div id=”R Inventor” lang=”english” date=”June/2003”>
<h1>Robert Gentleman</h1>
<p><i>’What we have is nice, but we need something very different’</i></p>
<p><b>Source: </b>Statistical Computing 2003, Reisensburg</p>
</div>
<div lang=”english” date=”October/2011”>
<h1>Rolf Turner</h1>
<p><i>’R is wonderful, but it cannot work magic’</i> <br><emph>answering a
request for automatic generation of ’data from a known mean and 95% CI’
</emph></p>
<p><b>Source: </b><a href=”https://stat.ethz.ch/mailman/listinfo/r-help”>R-help</a></p>
</div>
<address><a href=”http://www.r-datacollection.com”><i>The book homepage</i></a>
</address>
</body>
</html>
Evidently, all the information is included in the HTML file and can be accessed via the HTTP request, parsing, and extraction routines we previously presented. As we will see further below, this is unfortunately not always the case.
6.2 XHR
A limitation of the HTTP protocol is that communication between client and server necessarily follows a synchronous request–response pattern. Synchronous communication means that the user's interaction with the browser is being disabled while a request is received, processed, and a new page is delivered by the web server.
A more flexible data exchange mechanism is required to enable a continuous user experience that resembles the behavior of desktop applications. A popular method to allow for a continuous exchange of information between the browser and the web server is the so-called XMLHttpRequest (XHR), an interface that is implemented in nearly all modern web browsers. It allows initiating HTTP or HTTPS requests to a web server in an asynchronous fashion. XHR's principal purpose is to allow the browser to fetch additional information in the background without interfering with the user's behavior on the page.
To illustrate this process, take a look at the graphical illustration of the XHR-enriched communication model in Figure 6.2. As in the traditional HTTP communication process (see Section 5.1.1), XHR provides a mechanism to exchange data between a client and a server. A typical communication proceeds as follows.
- Commonly, but not necessarily, the user of a webpage is also the initiator of the AJAX request. The initiating event can be any kind of event that is recognizable by the browser, for example, a click on a button. JavaScript then instantiates an XHR object that serves as the object that makes the request and may also define how the retrieved data is used via a callback function.
- The XHR object initiates a request to the server for a specified file. This request may either be sent through HTTP or HTTPS. Due to JavaScript's Same Origin Policy, cross-domain requests are forbidden in native AJAX applications, meaning that the file to be requested must be in the domain of the current webpage. While the request is taking place in the background, the user is free to continue interacting with the site.
- On the server side, the request is received, processed, and the response including data is sent back to the browser client via the XHR object.
- Back in the browser client, the data are received and an event is triggered that is caught by an event handler. If the content of the file needs to be displayed on the page, the file may be relayed through a previously defined callback event handler. Via this handler the content can be manipulated to present it in the browser. Once the process handler has processed the information, it can be fed back into the current DOM and displayed on the screen.
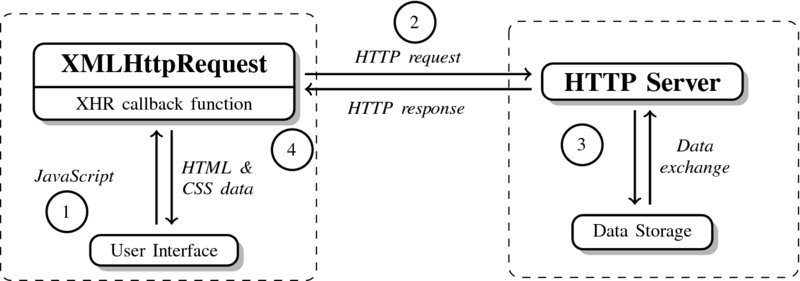
Figure 6.2 The user–server communication process using the XMLHttpRequest. Adapted from Stepp et al. (2012)
To see XHR in action, we now discuss two applications.
6.2.1 Loading external HTML/XML documents
The simplest type of data to be fetched from the server via an XHR request is a document containing HTML code. The task we illustrate here is to gather an HTML code and feed it back into the current webpage. The proper method to carry out this task in jQuery is its load() method. The load() method instantiates an XHR object that sends an HTTP GET request to the server and retrieves the data. Consider the following empty HTML file named fortunes2.html, which will serve as a placeholder document:
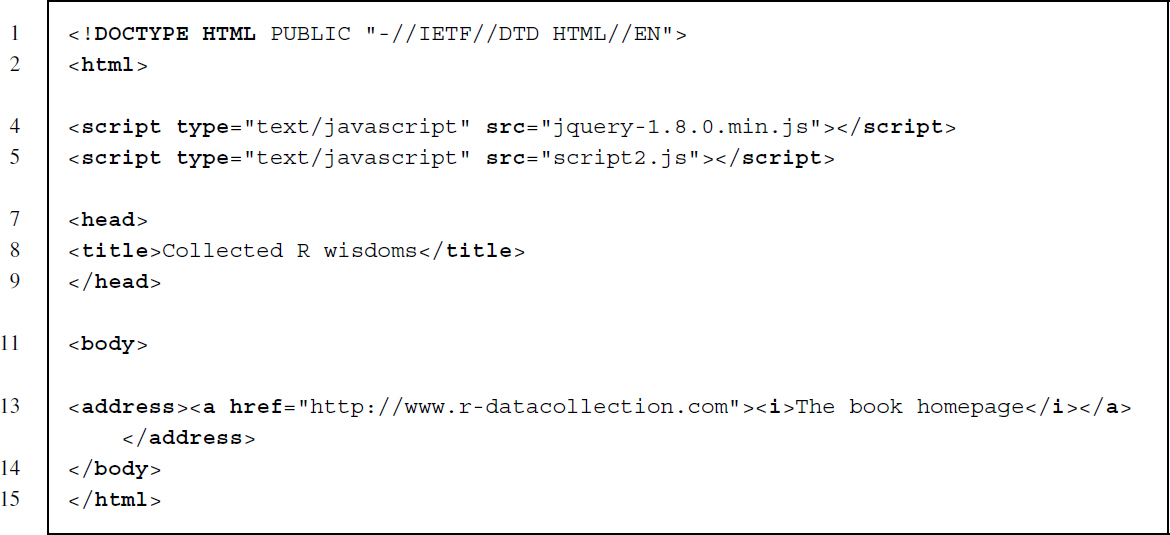
The task is to insert substantially interesting information from another HTML document into fortunes2.html. Key to this task is once again a JavaScript code to which we refer in line 5.

Like the previous script, script2.js starts with the document ready handler ready() to ensure the DOM is completely loaded before executing the script. In line 2 we initiate a selection for the <body> node. The <body> node serves as an anchor to which we link the data returned from the XHR data request. The essential part of the script uses jQuery's load() method to fetch information that is accessible in “quotes/quotes.html.” The load() method creates the XHR object, which is not only responsible for requesting information from the server but also for feeding it back into the HTML document. The file quotes.html contains the marked up quotes.
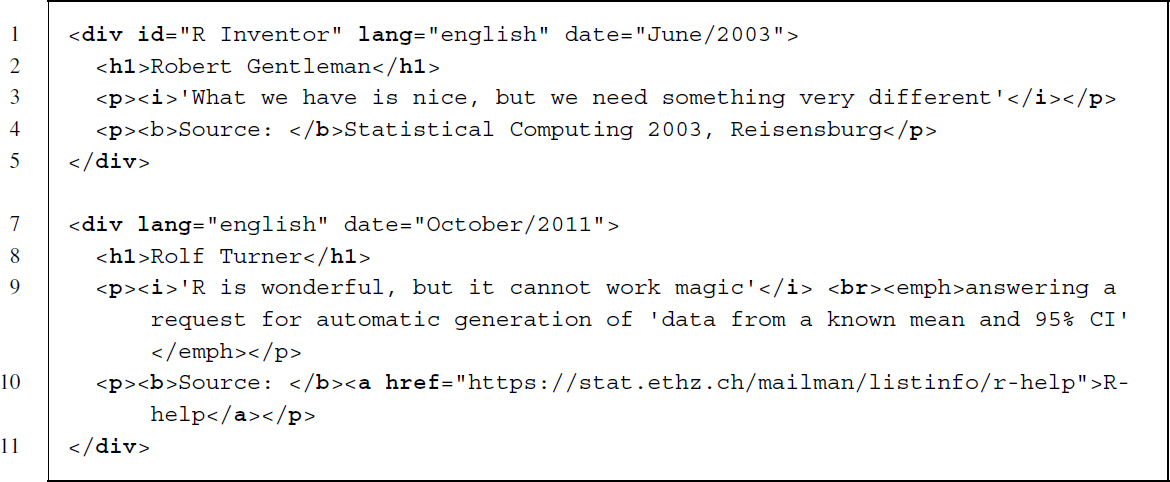
As part of the load() method, we also assign a callback function that is executed in case the XHR request is successful. In line 3, we use JavaScript to open an alert box with the text in quotation marks. This is purely for illustrative purpose and could be omitted without causing any problems. To check the success of the method, open fortunes2.html in a browser and compare the displayed information with the HTML code outlined above.
How does the XHR object interfere with attempts to obtain information from the quotes? Once again we compare the information displayed in the browser with what we get by parsing the document in R:
R> library(XML)
R> (fortunes2 <- htmlParse(”fortunes2.html”))
<!DOCTYPE HTML PUBLIC ”-//IETF//DTD HTML//EN”>
<html>
<head>
<script type=”text/javascript” src=”jquery-1.8.0.min.js”></script><script
type=”text/javascript” src=”script2.js”></script><title>Collected R wisdoms</title>
</head>
<body>
<address><a href=”http://www.r-datacollection.com”><i>The book homepage</i></a>
</address>
</body>
</html>
Unlike in the previous example, we observe that information shown in the browser is not included in the parsed document. As you might have guessed, the reason for this is the XHR object, which loads the quote information only after the placeholder HTML file has been requested.
6.2.2 Loading JSON
Although the X in AJAX stands for the XML format, XHR requests are not limited to retrieving data formatted this way. We have introduced the JSON format in Chapter 3, which has become a viable alternative, preferred by many web developers for its brevity and wide support. jQuery not only provides methods for retrieving JSON via XHR request but it also includes parsing functions that facilitate further processing of JSON files. Compared to the example before, we need to remind ourselves that JSON content is displayed unformatted in the browser. In this example, we therefore show first how to instruct jQuery to access a JSON file and second, how to convert JSON information into HTML tags, to obtain a clearer and more attractive display of the information. Take a look at fortunes3.html for our generic placeholder HTML document.
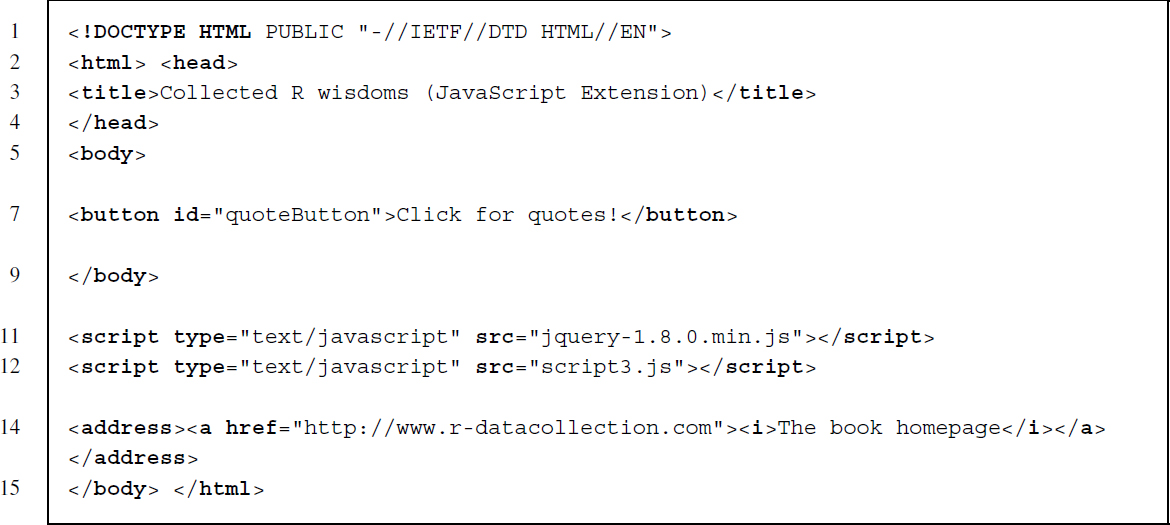
The new element here is an HTML button element to which we assign the id quote Button. Inside the HTML code there is a reference to script3.js.

Once again, go ahead and open fortunes3.html to check out the behavior of the document. What you should observe is that upon clicking on the button, new quote information appears that is visually similar to what we have seen in fortunes.html.
Let us dismantle the script into its constituent parts. In the top line, the scripts initiates a query for a node with id quoteButton. This node is being bound to the click event handler. The next lines detail the click's functionality. If a click occurs a data request is sent via jQuery's getJSON() method. This method does two things. First, the request for the file is initiated and the data fetched using a HTTP GET request. Second, the data are parsed by a JSON parser, which disassembles the file's key and value pairs into usable JavaScript objects. The file to be requested is specified as all_quotes.json, which contains the complete set of R wisdoms and is located in the folder named quotes. The first couple of lines of this file are printed below:

Line 3 initiates a looping construct that iterates over the objects of the retrieved JSON file and defines a function for the key and value variables. The function first performs a selection of the HTML document's <body> node to which it prepends the expression in parentheses. As you can see, this expression is a mixture of HTML markup and some sort of variable objects (encapsulated by + signs) through we can inject JSON information. Effectively, this statement produces familiar HTML code that includes data, author, quote, and source information from each object of the JSON file.
6.3 Exploring AJAX with Web Developer Tools
When sites employ more sophisticated request methods, a cursory look at the source code will usually not suffice to inform our R scraping routine. To obtain a sufficient understanding of the underlying structure and functionality we need to dig a little deeper. Despite our praise for the R environment, using R would render this task unnecessarily cumbersome and, at least for AJAX-enriched sites, it simply does not provide the necessary functionality. Instead, we examine the page directly in the browser. The majority of browsers comes with functionality that has turned them into powerful environments for developing web projects—and helpful companions for web scrapers. These tools are not only helpful for on-the-fly engagement with a site's DOM, but they may also be used for inspecting network performance and activities that are triggered through JavaScript code. In this section, we make use of Google Chrome's suite of Web Developer Tools (WDT), but tools of comparable scope are available in all the major browser clients.
6.3.1 Getting started with Chrome's Web Developer Tools
We return to the previously introduced fortunes2.html file, which caused some headache due to its application of XHR-based data retrieval. Open the file in Google Chrome to accustom yourself once again with the site's structure. By default, WDT are not visible. To bring them to the forefront, you can right-click on any HTML element and select the Inspect Element option. Chrome will split the screen horizontally, with the lower panel showing the WDT and the upper panel the classical page view of fortunes2.html. IInside the WDT (Chrome version 33.0.1750.146), the top-aligned bar shows eight panels named Elements, Network, Sources, Timeline, Profiles, Resources, Audits, and Console and which correspond to the different aspects of a site's behavior that we can analyze. Not all of these panels will be important for our purposes, so the next sections only discuss the Elements and the Network panels in the context of investigating a site's structure and creating an R scraping routine.
6.3.2 The Elements panel
From the Elements panel, we can learn useful information about the HTML structure of the page. It reveals the live DOM tree, that is, all the HTML elements that are displayed at any given moment. Figure 6.3 illustrates the situation upon opening the WDT on fortunes2.html. The Elements panel is particularly useful for learning about the links between specific HTML code and its corresponding graphical representation in the page view. By hovering your cursor over a node in the WDT, the respective element in the HTML page view is highlighted. To do the reverse and identify the code piece that produces an element in the page view, click on the magnifying glass symbol at the top right of the panel bar. Now, once you click on an element in the page view, the WDT highlights the respective HTML element in the DOM tree. The Elements panel is also helpful for generating an XPath expression that can be passed directly to R’s extractor functions (see Chapter 4). Simply right-click on an element and choose “Copy XPath” from the menu.
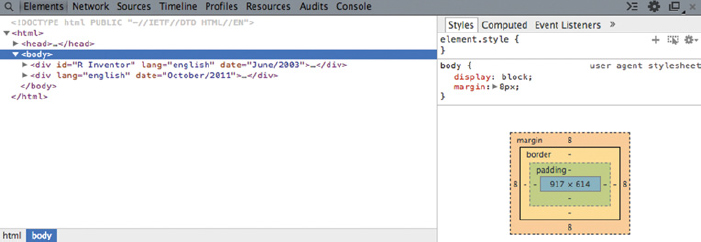
Figure 6.3 View on fortunes2.html from the Elements panel
6.3.3 The Network panel
The Network panel provides insights into resources that are requested and downloaded over the network in real time. It is thus an ideal tool to investigate resource requests that have been initiated by JavaScript-triggered XHR objects. Make sure to open the Network panel tab before loading a webpage, otherwise the request will not be captured. Figure 6.4 shows the Network panel after loading fortunes2.html. The panel shows that altogether four resources have been requested since the fortunes2.html has been opened. The first column of the panel displays the file names, that is, fortunes2.html, jquery-1.8.0.min.js, script2.js, and quotes.html. The second column provides information on the HTTP request method that provided the file. Here, all four files have been requested via HTTP GET. The next column displays the HTTP status code that was returned from the server (see Section 5.1.5). This can be of interest when an error occurs in the data request. The type column depicts the files’ type such as HTML or JavaScript. From the initiator column we learn about the file that triggered the request. Lastly, the size, time, and timeline columns provide auxiliary information on the requested resources.
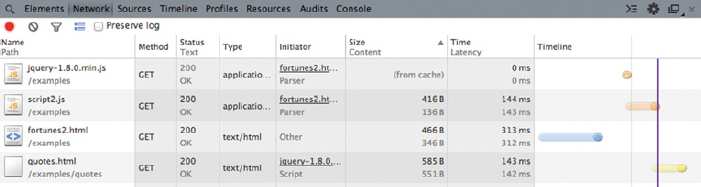
Figure 6.4 View on fortunes2.html from the Network panel
We are interested in collecting the quote information. Since the information is not part of the source HTML, we can refrain from further inspecting fortunes2.html. From the other three files, we can also ignore jquery-1.8.0.min.js as this is a library of methods. While script2.js could include the required quote information in principle, good web development practice usually separates data from scripts. By the principle of exclusion, we have thus identified quotes.html as the most likely candidate for containing the quotes. To take a closer look, click on the file, like in Figure 6.5. From the Preview tab we observe that quotes.html indeed contains the information. In the next step we need to identify the request URL for this specific file so we can pass it to R. This information is easily obtained from the Headers tab, which provides us with the header information that requested quotes.html. For our purpose, we only need the URL next to the Request URL field, which is http://r-datacollection.com/materials/ajax/quotes/quotes.html. With this information, we can return to our R session and pass the URL to RCurl’s getURL() command:

Figure 6.5 Information on quotes.html from the Network panel (a) Preview (b) Headers
R> (fortunes_xhr <- getURL(”r-datacollection.com/materials/ajax/quotes/
quotes.html”))
[1] ”<div id=”R Inventor” lang=”english” date=”June/2003”>
<h1>
Robert Gentleman</h1>
<p><i>’What we have is nice, but we need something
very different’</i></p>
<p><b>Source: </b>Statistical Computing 2003,
Reisensburg</p>
</div>
<div lang=”english” date=”October/2011”>
<h1>Rolf Turner</h1>
<p><i>’R is wonderful, but it cannot work magic’</i>
<br><emph>answering a request for automatic generation of ’data from a known
mean and 95% CI’</emph></p>
<p><b>Source: </b><a href=”https://stat.
ethz.ch/mailman/listinfo/r-help”>R-help</a></p>
</div>”
The results do in fact contain the target information, which we can now process with all the functions that were previously introduced.
Summary
AJAX has made a lasting impact on the user friendliness of services provided on the Web. This chapter gave a short introduction to the principles of AJAX and it sought to convey the conceptual differences between AJAX and classical HTTP-transmitted contents. From the perspective of a web scraper, AJAX constitutes a challenge since it encourages a separation of the stylistic structure of the page (HTML, CSS) and the information that is displayed (e.g., XML, JSON). Therefore, to retrieve data from a page it might not suffice to download and parse the front-end HTML code. Fortunately, this does not prevent our data scraping efforts. As we have seen, the AJAX-requested information was located in a file on the domain of the main page that is accessible to anyone who takes an interest in the data. With Web Developer Tools such as provided in Chrome, we can trace the file's origin and obtain a URL that oftentimes leads us directly to the source of interest. We will come back to problems created by dynamically rendered pages when we discuss the Selenium/Webdriver framework as an alternative solution to these kinds of scraping problems (see Section 9.1.9).
Further reading
To learn more about AJAX consult Holdener III (2008) or Stepp et al. (2012). A good way to learn and discover useful features of the Chrome Web Developer Tools is on the tool's reference pages Google (2014) or for a book reference Zakas (2010).
Problems
-
Why are AJAX-enriched webpages often valuable for web users, but an obstacle to web scrapers?
-
What are the three methods to embed JavaScript in HTML?
-
Why are Web Developer Tools particularly useful for web scraping when the goal is to gather information from websites using dynamic HTML?
-
Return to fortunes3.html. Implement the JavaScript alert() function at two points of the document. First, put the function in the <node> section of the document with text “fortunes3.html successfully loaded!” Second, open script3.js and include the alert() function here as well with text “quotes.html successfully loaded!” Watch the page's behavior in the browser.
-
Use the appropriate parsing function for fortunes3.html and verify that it does not contain the quotes of interest.
-
Use the Web Developer Tools to identify the source of the quote information in fortunes3.html. Obtain the request URL for the file and create an R routine that parses it.
-
Write a script for fortunes2.html that extracts the source of the quote. Conduct the following steps:
- Parse fortunes2.html into an R object called fortunes2.
- Write an XPath statement to extract the names of the JavaScript files and create a regular expression for extracting the name of the JavaScript script (and not the library).
- Import the JavaScript code using readLines() and extract the file path of the requested HTML document quotes.html.
- Parse quotes.html into an R object called quotes and query the document for the names.
-
Repeat exercise two for fortunes3.html. Extract the sources of the quotes.
-
The website http://www.parl.gc.ca/About/Parliament/FederalRidingsHistory/hfer.asp? Language=E&Search=C provides information on candidates in Canadian federal elections via a request to a database.
- Request information for all candidates with the name “Smith.” Inspect the live DOM tree with Web Developer Tools and find out the HTML tags of the returned information.
- Which mechanism is used to request the information from the server? Can you manipulate the request manually to obtain information for different candidates?
-
The city of Seattle maintains an open data platform, providing ample information on city services. Take a look at the violations database at https://data.seattle.gov/ Community/Seattle-code-violations-database/8agr-hifc
- Use the Web Developer Tools to learn about how the database information is stored in HTML code.
- Assess the data requesting mechanism. Can you access the underlying database directly?