
16
Gathering data on mobile phones
In this case study, we gather data on pricing, costumer rating, and sales ranks of a broad range of mobile phones sold on amazon.com, wondering about the price segments covered by leading producers of mobile phones. Amazon sells a broad range of products, allowing us to get comprehensive summary of the products from each of the big mobile phone producers.
The case study makes use of the packages RCurl, XML, and stringr and it features search page manipulation, link extraction, and page downloads using the RCurl curl handle. After reading the case study, you should be able to search information in source code and to apply XPath in real-life problems. Furthermore, within this case study a SQLite database is created to store data in a consistent way and make it reusable for the next case study.
16.1 Page exploration
16.1.1 Searching mobile phones of a specific brand
Amazon sells all kinds of products. Our first task is therefore to restrict the product search to certain categories and specific producers. Furthermore, we have to find a way to exclude accessories or used phones.
Let us have a look at the Amazon website: www.amazon.com. Check out the search bar at the top of the page—see also Figure 16.1. In addition to typing in search keywords, we can select the department in which we want to search. Do the following:
- Type Apple into the search bar and press enter.
- Select Cell Phones & Accessories from the search filter and click Go.
- Now click on Unlocked Cell Phones in the departments filter section on the left hand of the page.
- Type in other producers of mobile phones and compare the resulting URLs—which parts of the URL change?
- Try to eliminate parts of the query string in the address of your browser and watch what happens. Try to find those query strings which are necessary to replicate the search result and which can be left out.

Figure 16.1 Amazon's search form
The URL produced by searching for a specific producer in Unlocked Cell Phones in the browser looks like this:
Trying to delete various parts of the URL we find that the following URL is sufficient to replicate the search results:
The field-keywords part of the query string changes the keywords that are searched for, while url restricts the search results to unlocked cell phones. We found a basic URL that allows us to perform searches in the department of unlocked mobile phones and that we can manipulate to get results for different keywords.
Browsing through the search results we find that often phones of other producers are found as well. A brand filter on the left-hand side of the page helps get rid of this noise. There are two strategies to get the brand-restricted search results: We can either find the rules according to which the link is generated and generate the link ourselves or start with a non-restricted search, extract the link for the restricted results, and later on use it to get filtered search results. We go for the second solution because it is easier to implement. To learn more about how to identify the link, we use the inspect element tool of our browser on the brand filter:
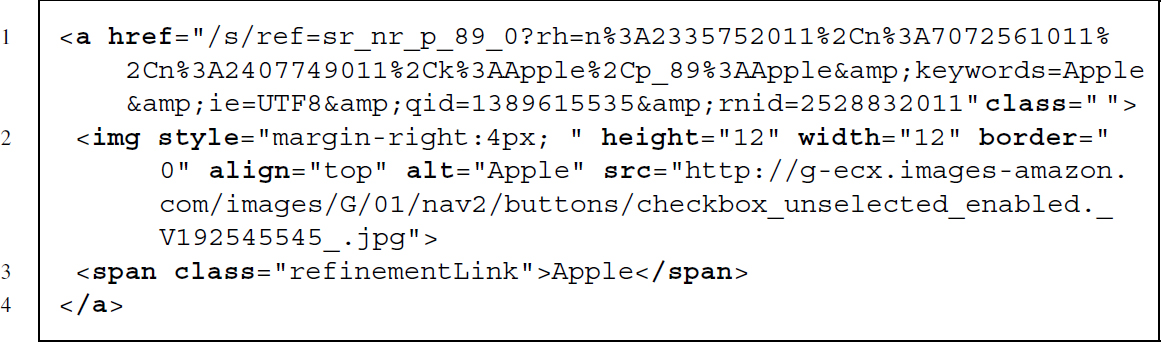
The link we are looking for is part of an <a> node. Unfortunately, the node has no specific class, but it has a <span> node as child with a very specific class called refinementLink. The content of the class is equal to the brand we want to restrict the search to—that should do. Translating this observation into XPath means that we are looking for a <span> node with class refinementLink for which the content of that node is equal to the keyword we are searching for. From this <span> node, we want to move one level up to the parent and select the parent's href attribute:
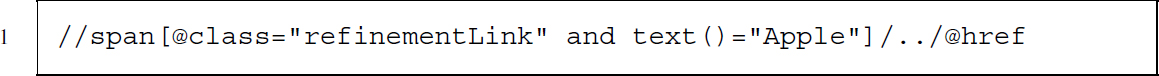
Now we have a way of restricting search results to specific producers, but the results are sorted in the default sorting order. Maybe sorting according to newness of the product is a better idea. After searching for a product on the Amazon page, we are presented with a drop-down list directly above the search results. It allows us to select one of several sorting criteria. Let us choose Newest Arrivals to have new products listed first. After selecting our preferred sorting, a new element is added to the URL—&sort=date-desc-rank. We can use it later on to construct an URL that produces sorted results.
Last but not least, we want to download more than the 24 products listed on the first results page. To do so, we need to select the next page. A link called Next Page at the bottom of the page does the trick. Using the inspect element tool of our browser reveals that the link is marked by a distinctive class attribute—pagnNext:
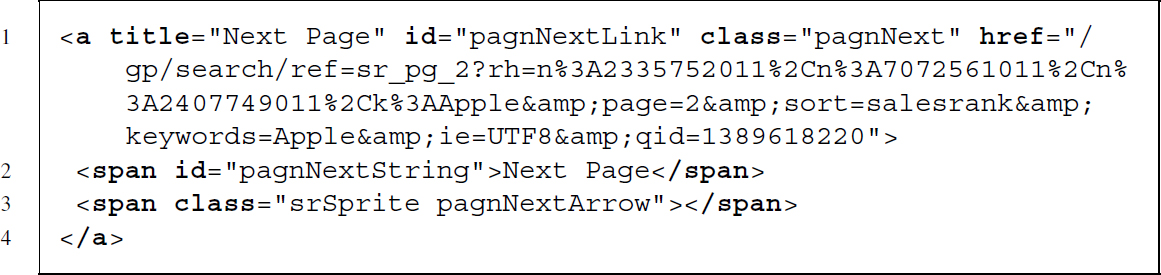
We search for <a> nodes with a next page class and extract their href attribute. This is done using the following XPath expression:

Later on we will use the links gathered in this way to download subsequent search result pages.
Now we have all the elements set up to run product searches for unlocked mobile phones of specific brands with a specific sorting. The following steps now have to be translated into R code:
- Specify the basic search URL for unlocked mobile phones and download the file.
- Search and extract the brand filtering link from the source code of the downloaded file.
- Append the sorting parameter to the query string of the beforehand extracted link and download the page.
- Search and extract the link to next page and download the next page. Repeat this step as needed.
First, we load the necessary packages. The stringr package serves as the all-purpose tool for extracting and manipulating text snippets, whereas XML and RCurl are the workhorses for the scraping tasks. RCurl enables us to download several files via one connection and XML is indispensable for HTML parsing and information extraction via XPath:
R> library(stringr)
R> library(XML)
R> library(RCurl)
Next we save the base URL for our searches and the first producer we want to search for in an object:
R> baseURL <- ”http://www.amazon.com/s/ref=nb_sb_noss_2?url=node%3
D2407749011&field-keywords=”
R> keyword <- ”Apple”
Base URL and producer name are combined with a simple call to str_c() and the page is downloaded and saved in an object:
R> url <- str_c(baseURL, keyword)
R> firstSearchPage <- getURL(url)
To issue XPath queries, we parse the page with htmlParse() and save it in an object:
R> parsedFirstSearchPage <- htmlParse(firstSearchPage)
We specify the XPath expression to extract the link for the brand restricted search results by pasting the producer name into the XPath expression we outlined before:
![]()
We use the XPath expression to extract the link and complete it with the base URL of the server:
R> restSearchPageLink <- xpathApply(parsedFirstSearchPage, xpath)
R> restSearchPageLink <- unlist(as.character(restSearchPageLink))
R> restSearchPageLink <- str_c(”http://www.amazon.com”, restSearchPageLink)
Finally, we add the desired sorting to the query string of the URL:
R> restSearchPageLink <- str_c(restSearchPageLink, ”&sort=date-desc-rank”)
… and download the page:
R> restrictedSearchPage <- getURL(restSearchPageLink)
This provides us with our first search results page for products restricted to a specific producer and the Unlocked Cell Phones product department.
Now we want to download further search results pages and store them in a list object. First, we create the list object and save the first search results page as its the first element. Next, the XPath expression that extracts the link for the next page is stored as well to make the code more readable. We create a loop for the first five search pages. In every iteration we extract the link for the next page and download and store the page in our list object:

16.1.2 Extracting product information
In the previous section, we ran searches to collect our results. In this section, we gather the necessary data from the results.
The first information to be extracted are the product titles of the search results pages as well as the links to the product pages. Using the inspect element tool, we find that links and titles are part of a heading of level three—an <h3> node. Searching the source code for other headings of level three reveals that they are only used for product titles and links to product pages:

We apply this information and construct two XPath expressions, //h3/a/span for titles and //h3/a for the links. As we have a whole list of search pages from which we want to extract data, we wrap the extraction procedure into a function and use lapply() to extract the information from all pages; first the titles:
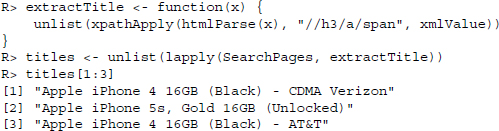
then the links:
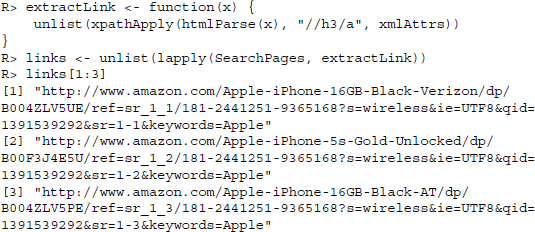
For the retrieval of price, costumer rating, and sales rank, the search pages' structure is hard to exploit or simply does not provide the information we seek. Therefore, we first have to download the individual product pages and extract the information from there.
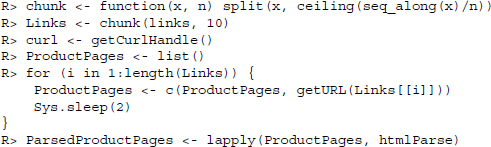
To avoid establishing new connections for all the downloads—which is time consuming—we create a handle that is reused for every call to getURL(). Furthermore, we want to give the server a break every 10 downloads, so we split our link vector into chunks of size 10 and loop over the list of chunks.1 In every loop, we request 10 pages and append them to the list object we created for storage and move to the next chunk. Last but not least we parse all the pages and store them in another list object:
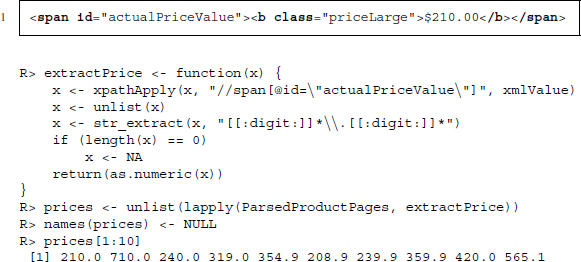
Having gathered all product pages, we move on to extracting the product price. Often, several prices are displayed on a product page: list prices, prices for new items, prices for used or refurbished items, and prices for products that are similar to the one selected. Using the inspect elements tool on the price directly under the product title, we find that it is enclosed by a <span> node with id actualPriceValue. Translated to an XPath expression, it reads: //span[@id=”actualPriceValue”]. One problem is that some items are not in stock anymore and the call to xpathApply() would return NULL for those items. To ensure that for these products we record a price of NA instead of NULL we check for the length of the xpathApply() result. If the length of the result is zero we replace it with NA. Below you find a source code snippet containing the price information we seek as well as the R code to extract the information:
This seems to work. Extracting the average customer ratings—ranging from one star to five—works similar to the procedure we used for the prices. Directly under the product title you find a series of five stars that are filled according to the average costumer rating. This graphical representation is enclosed by a <span> node that contains the average rating in its title attribute. We extract the information with an XPath expression: //span[contains (@title,’ out of 5 stars’)]], and a call to xmlAttr() within xpathApply(). The rating is then extracted from the title with a regular expression:


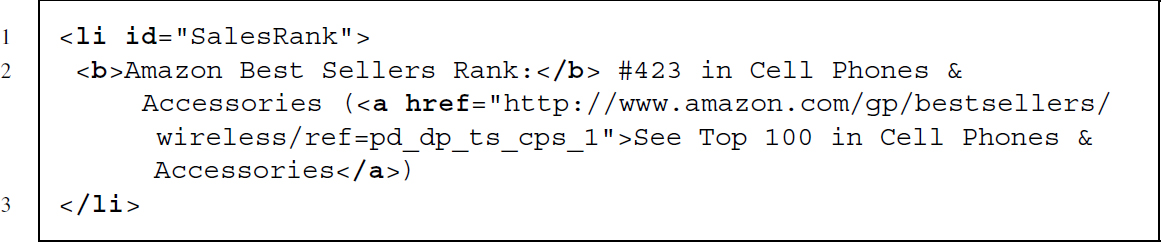
Further down on the page we find a section called Product Details. In this section, further information like the Amazon Standard Identification Number (ASIN), the product model, and the sales rank on Amazon within the category of Cell Phones & Accessories are shown as separate items. Let us start with extracting the sales rank which is enclosed in a <li> node of id SalesRank. We extract the node with XPath and collect the rank with a regular expression that looks for digits after a hash tag character and a second one that deletes everything which is not a digit:
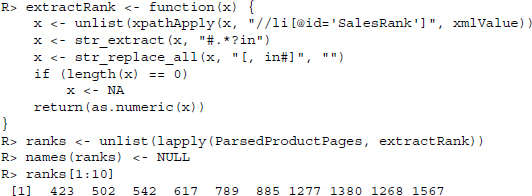
Next, we extract the ASIN from the product page. This information will help us later on to get rid of duplicates and to identify products. The ASIN is found in a list item that is unfortunately not identified with an id attribute or a specific class:

Nevertheless, we can specify its position as XPath expression by searching for a <b> node that has a <li> node as parent and contains text of pattern ASIN. From this node, we move one level up the tree and select the text of the parent:
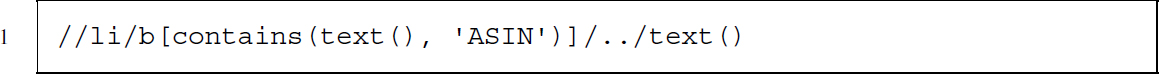
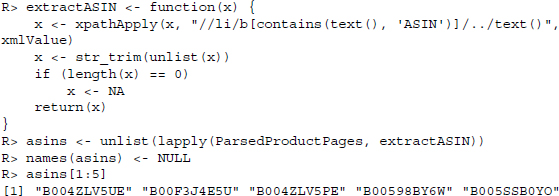
Finally, we extract the product model following the same strategy as before:


16.2 Scraping procedure
16.2.1 Retrieving data on several producers
Above we explored our data source step by step and developed solutions for various data collection and extraction problems. So far, we only used one producer as an example and have not gathered the data for others. To not have to repeat the whole code above for the other producers as well, we have to put its solutions into functions for convenient reuse. The functions can be loaded into our R-session via
R> source(”amazonScraperFunctions.r”)
After sourcing the functions, we set three global options: forceDownload is part of every download function and setting it to TRUE will cause the the functions to redownload all pages while setting it to FALSE will cause them to check whether or not the files to be downloaded exist already and should not be downloaded again. KeyWords is a vector of producer names that is also reused throughout the functions and defines for which producers mobile phone product details should be collected. The n parameter stores a single number that is used to determine how many search result pages should be gathered. With each search results page, we gain 24 further links to product pages:
R> forceDownload <- FALSE
R> KeyWords <- c(”Apple”, ”BlackBerry”, ”HTC”, ”LG”, ”Motorola”,
”Nokia”, ”Samsung”)
R> n <- 5
After having set up our global options, we can use the sourced functions to collect search and product pages and extract the information we seek. The steps we take match those carved out in the exploration section before. We start with collecting search pages:

… extract titles and product page links:
R> titles <- extractTitles(SearchPageList)
R> links <- extractLinks(SearchPageList)
… download product pages:
R> brands <- rep(KeyWords, each = n * 24)
R> productPages <- getProductPages(links, brands, forceDownload)
… and extract further data:
R> stars <- extractStars(productPages)
R> asins <- extractASINs(productPages)
R> models <- extractModels(productPages)
R> ranks <- extractRanks(productPages)
R> prices <- extractPrices(productPages)
16.2.2 Data cleansing
Although we have already done a lot of data cleansing along the way—trim leading and trailing spaces from strings, extract digits, and transform them to type numeric, there are still some tasks to do before we can begin to analyze our data. First of all, we recast the information as a data frame and then try to get rid of duplicated products as best as possible.
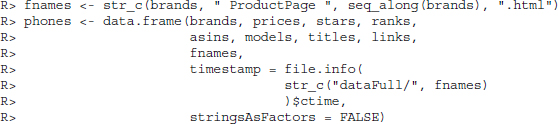
The first task is simple, as the information has already been saved in vectors of the same length with NAs where no information was collected. In addition to combining the information gathered so far, we add the names of the downloaded product pages and use their last change attribute (file.info(fname)$ctime) to store the time when the data were retrieved:
Next, we only keep complete observations and exclude all observations with duplicated ASINs, as this is the easiest way to make sure that we have no redundant data:
R> phones <- phones[complete.cases(phones), ]
R> phones <- phones[!duplicated(phones$asins), ]
16.3 Graphical analysis
To get an overview of the distribution of prices, costumer ratings, and sales ranks, we build a figure containing several plots that show all three variables. We have seven producers and also want to include an All category. Therefore, we specify a plotting function once and reuse it to assemble a plot representing information in all three categories. The main idea is to use transparent markers that allow for different shades of gray, resulting in black regions, where products bulk together, and light or white regions, where products are sparse or non-existent. Because sales ranks are only of ordinal scale, we have a hard time visualizing them directly. For every plot, we take those five products that rank highest in sales and visualize them differently—white dots on dark background with horizontal and vertical lines extending to the borders of each plot.
The plot function accepts a data frame as input and consequently starts with extracting our three variables from it—allowing a data frame as input serves convenient reuse on subsets of the data without repeating the subset three times. Next, we do a dummy plot that has the right range for x and y but do not plot any data. After that we add a modified x-axis and guiding lines. Thereafter comes the plotting of data so that the guiding lines stay in the background. The reason for this procedure is that we want to add guidelines but do not want to overplot the actual data—hence, we do a dummy plot, plot the guidelines, and thereafter plot the actual data. As color of the points we choose black but with an alpha value of 0.2—rgb(0,0,0,0.2). The rgb() function allows us to specify colors by combining red, green, and blue in different intensities. The alpha value which is the fourth parameter defines how opaque the resulting color is and therewith allows for transparent plotting of markers. Last but not least, we construct an index for the five lowest numbers in Ranks—the highest sales ranks—and plot vertical and horizontal lines at their coordinates as well as small white points to distinguish them from the other products.

The result of our efforts is displayed in Figure 16.2.
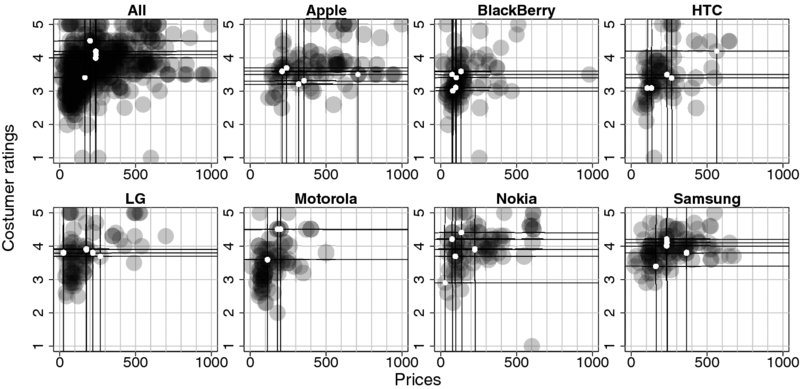
Figure 16.2 Prices, costumer rating, and best seller positioning of mobile phones. Black dots mark placement of individual products and white dots with horizontal and vertical lines mark the five best selling items per plot
With regard to costumer satisfaction, it is most interesting that there are differences not in the level but in the range of costumer ratings. For example, for Apple products, costumers seem to be coherently satisfied, whereas for Motorola products the range is much higher, suggesting that quality and/or feature appealing does vary greatly in Motorola's product palette. Another result is that best sellers are usually in the segments of high costumer satisfaction except for Nokia, who manage to have one of their best selling models at medium costumer satisfaction levels.
16.4 Data storage
16.4.1 General considerations
At this stage, we might end the case study, having gathered all data needed and drawn our conclusions. Or we might think about future applications and further extensions. Maybe we want to track the development of prices and costumer ratings over time and repeat the data gathering process. Maybe we want to add further product pages or simply gather data for other producers as well. Our database grows larger and larger, gets more complex and someday we realize that we do not have a clue how all the .Rdata and HTML files fit together. Maybe we should have built for the future a database tailored to our needs?
In this section, we will build up an SQLite database that captures the data we have extracted so far and leaves room to add further information. These further information will be product reviews that are collected, stored, and analyzed in the next case study. At the end, we will have three functions that can be called as needed: one for creating the database and defining its structure, one for resetting everything and start anew, and one for storing gathered data within the database. Let us start with loading the necessary packages
R> library(RSQLite)
R> library(stringr)
… and establishing a connection to the database. Note that establishing a connection to a not existing database with RSQLite means that the package creates a new one with the name supplied in dbConnect()—here amazonProductInfo.db:
R> sqlite <- dbDriver(”SQLite”)
R> con <- dbConnect(sqlite, ”amazonProductInfo.db”)
Having established a connection to the database, thinking about the design of the database before storing everything in one table probably is a good idea to prevent having problems later on. We first have a look at our data again to recap what we have got:

So far our effort was on gathering data on phone models and all the data were stored in one table. Having all the data in one table most of the time is convenient when analyzing and plotting data within a statistics software, but needlessly complicates data management on the long run. Imagine that we download another set of product information. We could simply append those information to the already existing data frame. But over time model names and ASINs would pile up redundantly—already it takes more than 600 rows to store only seven producer names. Another fact to consider is the planned extension of the data collection. When we add reviews to our data, there are usually several reviews for one product inflating the data even more. If extending the collection further with other still unknown data, further problems in regard to redundancy and mapping may arise. To forestall these and similar problems, it is best to split the data into several tables—see Section 7.2.2 for a discussion of standard procedures to split data in databases.
16.4.2 Table definitions for storage
As our data are on phone models, we should start building a table that stores unique identifiers of phone models. The ASIN already provides such an identifier, so we build a table that only stores these strings and later on link all other data to that variable by using foreign keys. Another feature we might want to add is the UNIQUE clause which ensures that no duplicates enter the column, as it might happen that we gather new data on already existing phone models—so we try to add already existing ASINs into the database which results in an error—we use ON CONFLICT IGNORE to tell the database to do not issue an error but simply ignore the query if it violates the unique constraint. The if(!dbExistsTable(...)) part also is thought to prevent errors—if the table exists already, the function does not send the query:

We set up similar functions createProducers(), createModels(), and createLinks() to define tables for producers, models, and links. They can be inspected in the supplementary materials to this chapter.
Having set up functions for defining tables for ASINs, producers, models, and links that ensure no redundant information is added to them, we now proceed with the table that should store product specific data. Within the table price, average costumer rating, rank in the selling list, title of the product page, the name of the downloaded file, and a time stamp should be saved. Adding a time stamp column to the table serves to allow for downloading information on the same phone model multiple times while allowing to discriminate between the time the information was received. To link the rows of this table to the other information, we furthermore add id columns for the phones, producers, models, and links tables. The ON UPDATE CASCADE part of the foreign key definition ensures that changes to the primary keys are passed through to the foreign keys. Also, we use a unique clause again to make sure no duplicated rows are included:
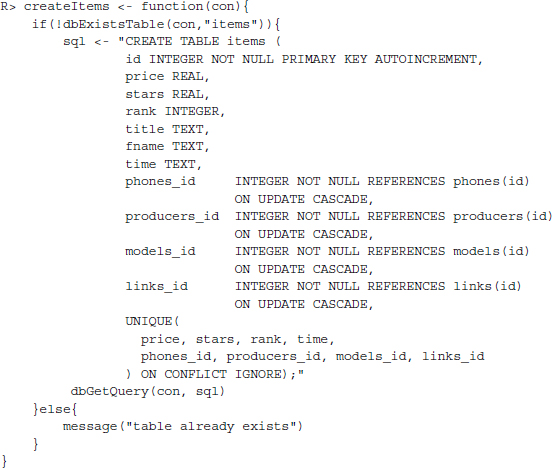
… now we have built tables for all data gathered so far.
16.4.3 Table definitions for future storage
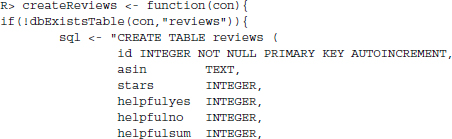
The next tables are thought to store review information that will be collected in the next case study. We start with a table for storing review information with columns for ASIN, the number of stars given by the reviewer, the number of people who found a review useful or not useful and the sum of both, the date the review was written, the title of the review, and of course the actual text:

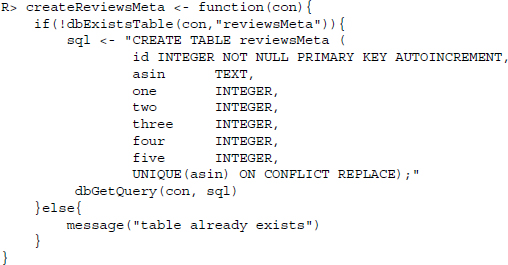
An additional table stores meta information of all reviews on one model with columns for ASIN, the number of times one star was assigned to the product up to the number of times five stars were assigned:
16.4.4 View definitions for convenient data access
While the tables created are good for storing data on models and model reviews consistently and efficient, for retrieving data we probably would like to have something more convenient that automatically puts together the data needed for a specific purpose. Therefore, we create another set of virtual tables called views in database speak. The first view is designed for providing all information on items and therefore brings together information of the items, producers, models, as well as the phones table by making use of JOIN:


The next view provides data on reviews:

Last but not least, we create a view that joins all data we have in one big table by joining together ReviewData and ItemData:
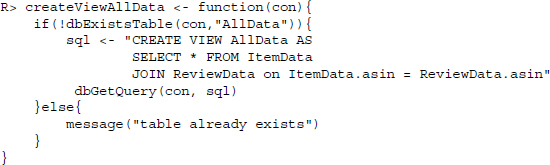
Having created functions for defining tables on product data and review data as well as for creating views for convenient data retrieval, we can wrap all these functions up in one function called defineDatabase() and execute it:

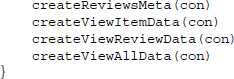
To be able to reverse the process, we also define a function called dropAll() that asks the database which data tables and views exist and sends DROP TABLE and DROP VIEW statements, respectively, to the database to delete them. Note however that this function should be handled with care because calling it will result in loosing all data:

16.4.5 Functions for storing data
So far we have build functions that define the structure of the database, but no data at all was added to the database. In the following, we will define functions that take our phones data (object phones) as argument and store bits of it in the right place. Later on we will put them all in a wrapper function that takes care of creating the database if necessary, defining all tables if necessary and adequately storing the data we pass to it.
Let us start with a function for storing ASINs. Although we could simply send all ASINs to the database and let it handle the rest—remember that the phones table was designed to ignore attempts to insert duplicated ASINs, it is faster to first ask which ASINs are stored within the database already and than only to add those that are missing. For each ASIN still missing in the database, we create a SQL statement for adding the new ASIN to the database and then send it:
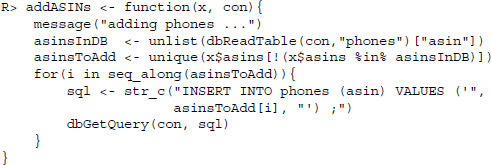
The functions for adding producers (addProducers()), models (addModels()), and links (addLinks()) follow the very same logic and are documented in the supplementary materials to this chapter.
The next function adds the remaining, product specific data to the database. First, we read in data from the phones, producers, models, and links tables to get up to date ids. Thereafter, we start cycling through all rows of phones extracting information from the price, stars, rank, title, fname, and time stamp variables. The next four lines match the ASIN of the current data row to those stored in the phones table; the current producer to those stored in producers; the current model to those stored in models and the current link to those stored in links for each retrieving the corresponding id. Then all these information are combined to an SQL statement that asks to add the data to the items table in the database. Last but not least the query is sent to the database:

As announced, we finally define a wrapper function that establishes a connection to the database, defines the table structure if not already done before and adds the data and when finished closes the connection to the database again:
![]()
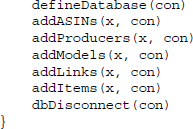
16.4.6 Data storage and inspection
Now we can write our data into the database:
R> saveInDatabase(phones, ”amazonProductInfo.db”)
… establish a connection to it:
R> sqlite <- dbDriver(”SQLite”)
R> con <- dbConnect(sqlite, ”amazonProductInfo.db”)
… and test if the data indeed has been saved correctly:
