
Domain 3
Risk, Identification, Monitoring, and Analysis
Organizations face a wide range of challenges today, including ever-expanding risks to organizational assets, intellectual property, and customer data. Understanding and managing these risks is an integral component of organizational success. The security practitioner is expected to participate in organizational risk management process, assist in identifying risks to information systems, and develop and implement controls to mitigate identified risks. As a result, the security practitioner must have a firm understanding of risk, response, and recovery concepts and best practices.
Topics
- The following topics are addressed in this chapter:
- Understand the risk management process
- Risk management concepts (e.g., impacts, threats, vulnerabilities)
- Risk assessment
- Risk treatment (accept, transfer, mitigate, avoid)
- Risk visibility and reporting (e.g., Risk Register, sharing threat intelligence)
- Audit findings
- Perform security assessment activities
- Participation in security and testing results
- Penetration testing
- Internal and external assessment (e.g., audit, compliance)
- Vulnerability scanning
- Interpretation and reporting of scanning and testing results
- Operate and maintain monitoring systems (e.g., continuous monitoring)
- Events of interest
- Logging
- Source systems
- Analyze and report monitoring results
- Security analytics, metrics, and trends (e.g., baseline)
- Visualization
- Event data analysis (e.g., log, packet dump, machine data)
- Communicate findings
- Understand the risk management process
Objectives
Effective incident response allows organizations to respond to threats that attempt to exploit vulnerabilities to compromise the confidentiality, integrity, and availability of organizational assets.
A Systems Security Certified Practitioner (SSCP) plays an integral role in incident response at any organization. The security practitioner must:
- Understand the organization’s incident response policy and procedures.
- Perform security assessments.
- Operate and maintain monitoring systems.
- Be able to execute the correct role in the incident response process.
Introduction to Risk Management
The security practitioner will be expected to be a key participant in the organizational risk management process. As a result, it is imperative that the security practitioner have a strong understanding of the responsibilities in the risk management process. To obtain this understanding, we will define key risk management concepts and then present an overview of the risk management process. We will then present real-world examples to reinforce key risk management concepts.
Risk Management Concepts
While you are reviewing risk management concepts, it is critical to remember that the ultimate purpose of information security is to reduce risks to organizational assets to levels that are deemed acceptable by senior management. Information security should not be performed using a “secure at any cost” approach. The cost of controls should never exceed the loss that would result if the confidentiality, integrity, or availability of a system were compromised. Risks, threats, vulnerabilities, and potential impacts should be assessed. Only after assessing these factors can cost-effective information security controls be selected and implemented that eliminate or reduce risks to acceptable levels.
We will reproduce the National Institute of Standards and Technology (NIST) Special Publication 800-30 R1, “Risk Management Guide for Information Systems”1 to establish definitions of key risk management concepts.
- Risk—A risk is a function of the likelihood of a given threat source’s exercising a potential vulnerability, and the resulting impact of that adverse event on the organization.
- Likelihood—The probability that a potential vulnerability may be exercised within the construct of the associated threat environment.
- Threat Source—Either intent and method targeted at the intentional exploitation of a vulnerability or a situation or method that may accidentally trigger a vulnerability.
- Threat—The potential for a threat source to exercise (accidentally trigger or intentionally exploit) a specific vulnerability.
- Vulnerability—A flaw or weakness in system security procedures, design, implementation, or internal controls that could be exercised (accidentally triggered or intentionally exploited) and result in a security breach or a violation of the system’s security policy.
- Impact—The magnitude of harm that could be caused by a threat’s exercise of a vulnerability.
- Asset—Anything of value that is owned by an organization. Assets include both tangible items such as information systems and physical property and intangible assets such as intellectual property.
These basic risk management concepts merge to form a model for risk as seen in the NIST diagram shown in Figure 3-1.

Figure 3-1: Determining Likelihood of Organizational Risk
Now that we have established definitions for basic risk management concepts, we can proceed with an explanation of the risk management process. It is important to keep these definitions in mind when reviewing the risk management process because these concepts will be continually referenced.
Risk Management Process
Risk management is the process of identifying risks, assessing their potential impacts to the organization, determining the likelihood of their occurrence, communicating findings to management and other affected parties, and developing and implementing risk mitigation strategies to reduce risks to levels that are acceptable to the organization. The first step in the risk management process is conducting a risk assessment.
Risk Assessment
Risk assessments assess threats to information systems, system vulnerabilities, and weaknesses, and the likelihood that threats will exploit these vulnerabilities and weaknesses to cause adverse effects. For example, a risk assessment could be conducted to determine the likelihood that an un-patched system connected directly to the Internet would be compromised. The risk assessment would determine that there is almost 100% likelihood that the system would be compromised by a number of potential threats such as casual hackers and automated programs. Although this is an extreme example, it helps to illustrate the purpose of conducting risk assessments.
The security practitioner will be expected to be a key participant in the risk assessment process. The security practitioner's responsibilities may include identifying system, application, and network vulnerabilities or researching potential threats to information systems. Regardless of the security practitioner's role, it is important that the security practitioner understand the risk assessment process and how it relates to implementing controls, safeguards, and countermeasures to reduce risk exposure to acceptable levels.
When performing a risk assessment, an organization should use a methodology that uses repeatable steps to produce reliable results. Consistency is vital in the risk assessment process, as failure to follow an established methodology can result in inconsistent results. Inconsistent results prevent organizations from accurately assessing risks to organizational assets and can result in ineffective risk mitigation, risk transference, and risk acceptance decisions.
Although a number of risk assessment methodologies exist, they generally follow a similar approach. NIST Special Publication 800-30 R1, “Risk Management Guide for Information Technology Systems” details a four-step risk assessment process. The risk assessment process described by NIST is composed of the steps shown in Figure 3-2.
Although a complete discussion of each step described within the NIST Risk Assessment Process is outside the scope of this text, we will use the methodology as a guideline to explain the typical risk assessment process. A brief description of a number of the steps is provided to help the security practitioner understand the methodology and functions that the security practitioner will be expected to perform as an SSCP.

Figure 3-2: The NIST Risk Assessment Process
Step 1: Preparing for the Assessment
The first step in the risk assessment process is to prepare for the assessment. The objective of this step is to establish a context for the risk assessment. This context is established and informed by the results from the risk framing step of the risk management process. Risk framing identifies, for example, organizational information regarding policies and requirements for conducting risk assessments, specific assessment methodologies to be employed, procedures for selecting risk factors to be considered, scope of the assessments, rigor of analyses, degree of formality, and requirements that facilitate consistent and repeatable risk determinations across the organization. Preparing for a risk assessment includes the following tasks:
- Identify the purpose of the assessment.
- Identify the scope of the assessment.
- Identify the assumptions and constraints associated with the assessment.
- Identify the sources of information to be used as inputs to the assessment.
- Identify the risk model and analytic approaches (i.e., assessment and analysis approaches) to be employed during the assessment.
Step 2: Conducting the Assessment
The second step in the risk assessment process is to conduct the assessment. The objective of this step is to produce a list of information security risks that can be prioritized by risk level and used to inform risk response decisions. To accomplish this objective, organizations analyze threats and vulnerabilities, impacts and likelihood, and the uncertainty associated with the risk assessment process. This step also includes the gathering of essential information as a part of each task and is conducted in accordance with the assessment context established in the prepare step of the risk assessment process (Step 1). The expectation for risk assessments is to adequately cover the entire threat space in accordance with the specific definitions, guidance, and direction established during the prepare step. However, in practice, adequate coverage within available resources may dictate generalizing threat sources, threat events, and vulnerabilities to ensure full coverage and assessing specific, detailed sources, events, and vulnerabilities only as necessary to accomplish risk assessment objectives. Conducting risk assessments includes the following specific tasks:
- Identify threat sources that are relevant to organizations.
- Identify threat events that could be produced by those sources.
- Identify vulnerabilities within organizations that could be exploited by threat sources through specific threat events and the predisposing conditions that could affect successful exploitation.
- Determine the likelihood that the identified threat sources would initiate specific threat events and the likelihood that the threat events would be successful.
- Determine the adverse impacts to organizational operations and assets, individuals, other organizations, and the Nation resulting from the exploitation of vulnerabilities by threat sources (through specific threat events).
- Determine information security risks as a combination of likelihood of threat exploitation of vulnerabilities and the impact of such exploitation, including any uncertainties associated with the risk determinations.
The specific tasks are presented in a sequential manner for clarity. Depending on the purpose of the risk assessment, the SSCP may find reordering the tasks advantageous. Whatever adjustments the SSCP makes to the tasks, risk assessments should meet the stated purpose, scope, assumptions, and constraints established by the organizations initiating the assessments.
Step 2a: Identifying Threat Sources
As mentioned previously, a threat is the potential for a particular threat source to successfully exercise a specific vulnerability. During the threat identification stage, potential threats to information resources are identified. Threat sources can originate from natural threats, human threats, or environmental threats. Natural threats include earthquakes, floods, tornadoes, hurricanes, tsunamis, and the like. Human threats are events that are either caused through employee error or negligence or are events that are caused intentionally by humans via malicious attacks that attempt to compromise the confidentiality, integrity, and availability of IT systems and data. Environmental threats are those issues that arise because of environmental conditions such as power failure, HVAC failure, or electrical fire.
For the SSCP, the first step of a risk assessment involves understanding the threats that may target an organization. This step considers both adversarial threats and non-adversarial threats such as natural disasters. During this step, the security practitioner may:
- Determine sources for obtaining threat information.
- Determine what threat taxonomy may be used.
- Provide input or determine what threat information will be used in the overall assessment.
Several threat sources may be referenced as part of the threat identification. Honey pots and honey nets provide targeted and specific threat information in near–real time, but they require expert operation, interpretation, and analysis and therefore can be cumbersome and expensive for smaller organizations. Incorrectly configured and deployed honey pots/nets can also provide a staging ground for further attacks against an organization. Organizations may also consider threat catalogs such as Appendix D of NIST SP 800-30 R1 or the German BSI Threats Catalogue.2
An organization can subscribe to threat source information services. These services scan the Internet and the globe to determine active threats and how they may be targeting a specific industry, business, or economy. The more an organization is willing to pay, the more specific threat intelligence the organization may be able to maintain. Some programs such as the United States' FBI Infraguard are designed to provide threat information from the government to businesses and non-governmental organizations.
Since threat information is volatile yet crucial for the risk management process, organizations in similar economies or sectors may band together to share threat information between them. These collations often exist within a “no attribution” environment where confidentiality of the source of the threat information is the norm. While some areas, such as government, have done well in collaborating, other industries have been slow to adopt threat sharing for fear of losing competitive advantage over rivals.
After the threat identification process has been completed, a threat statement should be generated. A threat statement lists potential threat sources that could exploit system vulnerabilities. Successfully identifying threats coupled with vulnerability identification are prerequisites for selecting and implementing information security controls.
Step 2a: Identifying Potential Threat Events
Threat events are characterized by the threat sources that could initiate the events. The SSCP needs to define these threat events with sufficient detail to accomplish the purpose of the risk assessment. Multiple threat sources can initiate a single threat event. Conversely, a single threat source can potentially initiate any of multiple threat events. Therefore, there can be a many-to-many relationship among threat events and threat sources that can potentially increase the complexity of the risk assessment. For each threat event identified, organizations need to determine the relevance of the event. The values selected by organizations have a direct linkage to organizational risk tolerance. The more risk averse, the greater the range of values considered. Organizations accepting greater risk or having a greater risk tolerance are more likely to require substantive evidence before giving serious consideration to threat events. If a threat event is deemed to be irrelevant, no further consideration is given. For relevant threat events, organizations need to identify all potential threat sources that could initiate the events.
Step 2b: Identifying Vulnerabilities and Predisposing Conditions
Identifying vulnerabilities is an important step in the risk assessment process. The step allows for the identification of both technical and nontechnical vulnerabilities that, if exploited, could result in a compromise of system or data confidentiality, integrity, and availability. A review of existing documentation and reports is a good starting point for the vulnerability identification process. This review can include the results of previous risk assessments. It can also include a review of audit reports from compliance assessments, a review of security bulletins and advisories provided by vendors, and data made available via personal and social networking. NIST SP 800-30 R1 Appendix F provides a set of tables for using in identifying predisposing conditions and vulnerabilities.
Vulnerability identification and assessment can be performed via a combination of automated and manual techniques. Automated techniques such as system scanning allow a security practitioner to identify technical vulnerabilities present in assessed IT systems. These technical vulnerabilities may result from failure to apply operating system and application patches in a timely manner, architecture design problems, or configuration errors. By using automated tools, systems can be rapidly assessed and vulnerabilities can be quickly identified.
Although a comprehensive list of vulnerability assessment tools is outside the scope of this text, an SSCP should spend a significant amount of time becoming familiar with the various tools that could be used to perform automated assessments. Although many commercial tools are available, there are also many open-source tools equally as effective in performing automated vulnerability assessments. Figure 3-3 is a screenshot of policy configuration using Nessus, a widely used vulnerability assessment tool.
Manual vulnerability assessment techniques may require more time to perform when compared to automated techniques. Typically, automated tools will initially be used to identify vulnerabilities. Manual techniques can then be used to validate automated findings. By performing manual techniques, one can eliminate false positives. False positives are potential vulnerabilities identified by automated tools that are not actual vulnerabilities.

Figure 3-3: A screenshot of policy configuration using Nessus
Manual techniques may involve attempts to actually exploit vulnerabilities. When approved personnel attempt to exploit vulnerabilities to gain access to systems and data, it is referred to as penetration testing. Although vulnerability assessments merely attempt to identify vulnerabilities, penetration testing actually attempts to exploit vulnerabilities. Penetration testing is performed to assess security controls and to determine if vulnerabilities can be successfully exploited. Figure 3-4 is a screenshot of the Metasploit console, a widely used penetration-testing tool.

Figure 3-4: A screenshot of the Metasploit console
Step 2c: Determining Likelihood
Likelihood determination attempts to define the likelihood that a given vulnerability could be successfully exploited within the current environment. Likelihood is often the most difficult to determine in the risk framework. Factors that must be considered when assessing the likelihood of a successful exploit include:
- The nature of the vulnerability, including factors such as:
- The operating system, application, database, or device affected by the vulnerability
- Whether local or remote access is required to exploit the vulnerability
- The skills and tools required to exploit the vulnerability
- The threat source’s motivation and capability, including factors such as:
- Threat source motivational factors (e.g., financial gain, political motivation, revenge)
- Capability (skills, tools, and knowledge required to exploit a given vulnerability)
- The effectiveness of controls deployed to prevent exploit of the given vulnerability
Step 2d: Determining Impact
An impact analysis defines the impact to an organization that would result if a vulnerability were successfully exploited. An impact analysis cannot be performed until system mission, system and data criticality, and system and data sensitivity have been obtained and assessed. The system mission refers to the functionality provided by the system in terms of business or IT processes supported. System and data criticality refer to the system’s importance to supporting the organizational mission. System and data sensitivity refer to requirements for data confidentiality and integrity.
In many cases, system and data criticality and system and data sensitivity can be assessed by determining the adverse impact to the organization that would result from a loss of system and data confidentiality, integrity, or availability. Remember that confidentiality refers to the importance of restricting access to data so that they are not disclosed to unauthorized parties. Integrity refers to the importance that unauthorized modification of data is prevented. Availability refers to the importance that systems and data are available when needed to support business and technical requirements. When a person assesses each of these factors individually and aggregates the individual impacts resulting from a loss of confidentiality, integrity, and availability, the overall adverse impact from a system compromise can be assessed.
Impact can be assessed in either quantitative or qualitative terms. A quantitative impact analysis assigns a dollar value to the impact. The dollar value can be calculated based on an assessment of the likelihood of a threat source exploiting a vulnerability, the loss resulting from a successful exploit, and an approximation of the number of times that a threat source will exploit a vulnerability over a defined period. To understand how a dollar value can be assigned to an adverse impact, one must review some fundamental concepts. An explanation of each of these concepts is provided below.
- Single Loss Expectancy (SLE)—SLE represents the expected monetary loss to an organization from a threat to an asset. SLE is calculated by determining the value of a particular asset (AV) and the approximated exposure factor (EF). EF represents the portion of an asset that would be lost if a risk to the asset was realized. EF is expressed as a percentage value where 0% represents no damage to the asset and 100% represents complete destruction of the asset. SLE is calculated by multiplying the AV by the EF as indicated by the formula:
Single Loss Expectancy = Asset Value X Exposure Factor
- Annualized Loss Expectancy (ALE)—ALE represents the expected annual loss because of a risk to a specific asset. ALE is calculated by determining the SLE and then multiplying it by the Annualized Rate of Occurrence (ARO) as indicated by the formula:
Annual Loss Expectancy = Single Loss Expectancy X Annualized Rate of Occurrence
- Annualized Rate of Occurrence—ARO represents the expected number of exploitations by a specific threat of a vulnerability to an asset in a given year.
Organizations can use the results of annual loss expectancy calculations to determine the quantitative impact to an organization if an exploitation of a specific vulnerability were successful. In addition to the results of quantitative impact analysis, organizations should evaluate the results of qualitative impact analysis.
A qualitative impact analysis assesses impact in relative terms such as high impact, medium impact, and low impact without assigning a dollar value to the impact. A qualitative assessment is often used when it is difficult or impossible to accurately define loss in terms of dollars. For example, a qualitative assessment may be used to assess the impact resulting from a loss of customer confidence, from negative public relations, or from brand devaluation.
Organizations generally find it most helpful to use a blended approach to impact analysis. When they evaluate both the quantitative and qualitative impacts to an organization, a complete picture of impacts can be obtained. The results of these impact assessments provide required data for the risk determination process.
Step 2e: Risk Determination
In the risk determination step, the overall risk to an IT system is assessed. Risk determination uses the outputs from previous steps in the risk assessment process to assess overall risk. Risk determination results from the combination of:
- The likelihood of a threat source attempting to exploit a specific vulnerability
- The magnitude of the impact that would result if an attempted exploit were successful
- The effectiveness of existing and planned security controls in reducing risk
A risk-level matrix can be created that analyzes the combined impact of these factors to assess the overall risk to a given IT system. The exact process for creating a risk-level matrix is outside the scope of this text. For additional information, refer to NIST Special Publication 800-30 R1, “Risk Management Guide for Information Technology Systems.”
The result of creating a risk-level matrix is that overall risk level may be expressed in relative terms of high, medium, and low risk. Figure 3-5 provides an example of a risk matrix.

Figure 3-5: A risk-level matrix
A description of each risk level and recommended actions:
- High Risk—Significant risk to the organization and to the organizational mission exists. There is a strong need for corrective actions that include reevaluation of existing controls and implementation of additional controls. Corrective actions should be implemented as soon as possible to reduce risk to an acceptable level.
- Medium Risk—A moderate risk to the organization and to the organizational mission exists. There is a need for corrective actions that include reevaluation of existing controls and may include implementation of additional controls. Corrective actions should be implemented within a reasonable time frame to reduce risk to an acceptable level.
- Low Risk—A low risk to the organization exists. An evaluation should be performed to determine if the risk should be reduced or if it will be accepted. If it is determined that the risk should be reduced, corrective actions should be performed to reduce risk to an acceptable level.
Step 3: Communicating and Sharing Risk Assessment Information
The third step in the risk assessment process is to communicate the assessment results and share risk-related information. The objective of this step is to ensure that decision makers across the organization have the appropriate risk-related information needed to inform and guide risk decisions. Communicating and sharing information consists of the following specific tasks:
- Communicate the risk assessment results.
- Share information developed in the execution of the risk assessment to support other risk management activities.
Step 4: Maintaining the Risk Assessment
The fourth step in the risk assessment process is to maintain the assessment. The objective of this step is to keep current the specific knowledge of the risk organizations incur. The results of risk assessments inform risk management decisions and guide risk responses. To support the ongoing review of risk management decisions (e.g., acquisition decisions, authorization decisions for information systems and common controls, connection decisions), organizations maintain risk assessments to incorporate any changes detected through risk monitoring. Risk monitoring provides organizations with the means to, on an ongoing basis:
- Determine the effectiveness of risk responses.
- Identify risk-impacting changes to organizational information systems and the environments in which those systems operate.
- Verify compliance.
Maintaining risk assessments includes the following specific tasks:
- Monitor risk factors identified in risk assessments on an ongoing basis and understand subsequent changes to those factors.
- Update the components of risk assessments reflecting the monitoring activities carried out by organizations.
Risk Treatment
Risk treatment is the next step in the risk assessment process. The goal of risk treatment is to reduce risk exposure to levels that are acceptable to the organization. Risk treatment can be performed using a number of different strategies. These strategies include:
- Risk mitigation
- Risk transference
- Risk avoidance
- Risk acceptance
Risk Mitigation
Risk mitigation reduces risks to the organization by implementing technical, managerial, and operational controls. Controls should be selected and implemented to reduce risk to acceptable levels. When controls are selected, they should be selected based on their cost, effectiveness, and ability to reduce risk. Controls restrict or constrain behavior to acceptable actions. To help understand controls, look at some examples of security controls.
A simple control is the requirement for a password to access a critical system. When an organization implements a password control, unauthorized users would theoretically be prevented from accessing a system. The key to selecting controls is to select controls that are appropriate based on the risk to the organization. Although we noted that a password is an example of a control, we did not discuss the length of the password.
If a password is implemented that is one character long and must be changed on an annual basis, a control is implemented; however, the control will have almost no effect on reducing the risk to the organization because the password could be easily cracked. If the password is cracked, unauthorized users could access the system and, as a result, the control has not effectively reduced the risk to the organization.
On the other hand, if a password that is 200 characters long that must be changed on an hourly basis is implemented, it becomes a control that will effectively prevent authorized access. The issue in this case is that a password with those requirements will have an unacceptably high cost to the organization. End-users would experience a significant productivity loss because they would be constantly changing their passwords.
The key to control selection is to implement cost-effective controls that reduce or mitigate risks to levels that are acceptable to the organization. By implementing controls based on this concept, organizations will reduce risk but not totally eliminate it.
Controls can be categorized in technical, managerial, or operational control categories. Managerial controls are controls that dictate how activities should be performed. Policies, procedures, standards, and guidelines are examples of managerial controls. These controls provide a framework for managing personnel and operations. They also can establish requirements for systems operations. An example of a managerial control is the requirement that information security policies should be reviewed on an annual basis and updated as necessary to ensure that they accurately reflect the environment and remain valid.
Technical controls are designed to control end-user and system actions. They can exist within operating systems, applications, databases, and network devices. Examples of technical controls include password constraints, access control lists, firewalls, data encryption, antivirus software, and intrusion prevention systems.
Technical controls help to enforce requirements specified within administrative controls. For example, an organization could have implemented a malicious code policy as an administrative control. The policy could require that all end-users’ systems have antivirus software installed. Installation of the antivirus software would be the technical control that provides support to the administrative control.
In addition to being categorized as technical, administrative, or operational, controls can be simultaneously categorized as either preventative or detective. Preventative controls attempt to prevent adverse behavior and actions from occurring. Examples of preventative controls include firewalls, intrusion prevention systems, and segregation of duties. Detective controls are used to detect actual or attempted violations of system security. Examples of detective controls include intrusion detection systems and audit logging.
Although implementing controls will reduce risk, some amount of risk will remain even after controls have been selected and implemented. The risk that remains after risk reduction and mitigation efforts are complete is referred to as residual risk. Organizations must determine how to treat this residual risk. Residual risk can be treated by risk transference, risk avoidance, or risk acceptance.
Risk Transference
Risk transference transfers risk from an organization to a third party. Some types of risk such as financial risk can be reduced by transferring it to a third party via a number of methods. The most common risk transference method is insurance. An organization can transfer its risk to a third party by purchasing insurance. When an organization purchases insurance, it effectively sells its risk to a third party. The insurer agrees to accept the risk in exchange for premium payments made by the insured. If the risk is realized, the insurer compensates the insured party for any incurred losses.
Organizations must be cautious when relying on risk transference because some risk cannot be transferred. Outsourcing sensitive information processing may seem like outsourcing the risk of personnel data breaches. If a breach occurs, surely those affected would understand that the outsourced processor caused the breach and focus their rage there, right? Unfortunately, this is rarely the case. In most instances, the victims seek damages against the organization that originally collected the information in the first place. Organizations must ensure they conduct their due diligence when transferring operations and data to third parties when the organization is still responsible for the protection of the data.
Finally, organizations must be aware of risk that cannot be transferred. While financial risk is easy to transfer to a third party through insurance, reputational damage and customer loyalty is almost impossible to transfer. When an information security risk affects these aspects of an organization, the organization must go on the defensive and engage public relations teams to try to maintain the goodwill of their customers and protect the reputation of their organization.
Risk Avoidance
Another alternative to mitigate risk is to avoid the risk. Risk can be avoided by eliminating the entire situation causing the risk. This could involve disabling system functionality or preventing risky activities when risk cannot be adequately reduced. In drastic measures, it can involve shutting down entire systems or parts of a business.
Risk Acceptance
Residual risk can also be accepted by an organization. A risk acceptance strategy indicates that an organization is willing to accept the risk associated with the potential occurrence of a specific event. It is important that when an organization chooses risk acceptance, it clearly understands the risk that is present, the probability that the loss related to the risk will occur, and the cost that would be incurred if the loss were realized. Organizations may determine that risk acceptance is appropriate when the cost of implementing controls exceeds the anticipated losses.
Risk Visibility and Reporting
Once assessed and quantified or qualified, risk should be reported and recorded. Organizations should have a way to aggregate risk in a centralized function that combines information security risk with other risk such as market risk, legal risk, human capital risk, and financial risk. The organizational risk executive function serves as a way to understand total risk to the organization. Risk is aggregated in a system called a risk register or, in some cases, a risk dashboard. The SSCP must ensure only risk information (not vulnerability or threat information) is reported to the risk register. The risk register serves as a way for the organization to know their possible exposure at a given time.
The risk register will generally be shared with stakeholders, allowing them to be kept aware of issues and providing a means of tracking the response to issues. It can be used to flag new risks and to make suggestions on what course of action to take to resolve any issues. The risk register is there to help with the decision-making process and enables managers and stakeholders to handle risk in the most appropriate way. The risk register is a document that contains information about identified risks, analysis of risk severity, and evaluations of the possible solutions to be applied. Presenting this in a spreadsheet is often the easiest way to manage things so that key information can be found and applied quickly and easily.
The SSCP should be familiar with how to create a risk register for the organization. If you are unsure how to create a risk register, the following is a brief guide on how to get started in just a few steps:
- Create the risk register—Use a spreadsheet to document necessary information, as shown in Figure 3-6.

Figure 3-6 Sample risk register
- Record Active Risks—Keep track of active risks by recording them in the risk register along with the date identified, date updated, target date, and closure date. Other useful information to include is the risk identification number, a description of the risk, type and severity of risk, its impact, possible response action, and the current status of risk.
- Assign a Unique Number to Each Risk Element—This will help to identify each unique risk so that you know what the status of the risk is at any given time.
The risk register addresses risk management in four key steps:
- Identifying the risk
- Evaluating the severity of any identified risks
- Applying possible solutions to those risks
- Monitoring and analyzing the effectiveness of any subsequent steps taken
Security Auditing Overview
A security audit is an evaluation of how well the objectives of a security framework are met and a verification to ensure the security framework is appropriate for the organization. Nothing that comes out of an audit should surprise security practitioners if they have been doing their continuous monitoring. Think of it this way. Monitoring is an ongoing evaluation of a security framework done by the folks who manage the security day-to-day, while an audit is an evaluation of the security framework performed by someone outside of the day-to-day security operations. Security audits serve two purposes for the security practitioner. First, they point out areas where security controls are lacking, policy is not being enforced, or ambiguity exists in the security framework. The second benefit of security audits is that they emphasize security things that are being done right. Auditors, in general, should not be perceived as the “bad guys” that are out to prove what a bad job the organization is doing. On the contrary, auditors should be viewed as professionals who are there to assist the organization in driving the security program forward and to assist security practitioners in making management aware of what security steps are being correctly taken and what more needs to be done.
So, who audits and why? There are two categories of auditors; the first type is an internal auditor. These people work for the company, and these audits can be perceived as an internal checkup. The other type of auditor is an external auditor. These folks either are under contract with the company to perform objective audits or are brought in by other external parties. Audits can be performed for several reasons. This list is by no means inclusive of all the reasons that an audit may be performed, but it covers most of them.
- Annual Audit—Most businesses perform a security audit on an annual basis as dictated by policy.
- Event-Triggered Audit—These audits are often conducted after a particular event occurs, such as an intrusion incident. They are used to both analyze what went wrong and, as with all audits, to confirm due diligence if needed.
- Merger/Acquisition Audit—These audits are performed before a merger/acquisition to give the purchasing company an idea of where the company they are trying to acquire stands on security in relation to their own security framework.
- Regulation Compliance Audit—These audits are used to confirm compliance with the IT–security-related portions of legislated regulations such as Sarbanes–Oxley and HIPAA.
- Ordered Audit—Although rare, there are times when a company is ordered by the courts to have a security audit performed.
What are the auditors going to use as a benchmark to test against? Auditors should use the organization's security framework as a basis for them to audit against; however, to ensure that everything is covered, they will first compare the organization's framework against a well-known and accepted standard. What methodology will the auditors use for the audit? There are many different methodologies used by auditors worldwide. Here are a few of them:
- ISO/IEC 27001:2013 (formerly BS 7799-2:2002)—“Specification for Information Security Management.” ISO/IEC 27001:2013 specifies the requirements for establishing, implementing, maintaining, and continually improving an information security management system within the context of the organization. It also includes requirements for the assessment and treatment of information security risks tailored to the needs of the organization. The requirements set out in ISO/IEC 27001:2013 are generic and are intended to be applicable to all organizations, regardless of type, size, or nature.
- ISO/IEC 27002:2013 (previously named ISO/IEC 17799:2005)—“Code of Practice for Information Security Management.” ISO/IEC 27002:2013 gives guidelines for organizational information security standards and information security management practices including the selection, implementation, and management of controls taking into consideration the organization's information security risk environment(s). It is designed to be used by organizations that intend to:
- Select controls within the process of implementing an Information Security Management System based on ISO/IEC 27001.
- Implement commonly accepted information security controls.
- Develop their own information security management guidelines.
- NIST SP 800-37 R1—“Guide for Applying the Risk Management Framework to Federal Information Systems,” which can be retrofitted for private industry. This publication provides guidelines for applying the Risk Management Framework (RMF) to federal information systems. The six-step RMF includes security categorization, security control selection, security control implementation, security control assessment, information system authorization, and security control monitoring. The RMF promotes the concept of near real-time risk management and ongoing information system authorization through the implementation of robust continuous monitoring processes, provides senior leaders the necessary information to make cost-effective, risk-based decisions with regard to the organizational information systems supporting their core missions and business functions, and integrates information security into the enterprise architecture and system development life cycle. Applying the RMF within enterprises links risk management processes at the information system level to risk management processes at the organization level through a risk executive (function) and establishes lines of responsibility and accountability for security controls deployed within organizational information systems and inherited by those systems (i.e., common controls).
- CobIT (Control Objectives for Information and related Technology)—From the Information Systems Audit and Control Association (ISACA). With COBIT 5, ISACA introduced a framework for information security. It includes all aspects of ensuring reasonable and appropriate security for information resources. Its foundation is a set of principles upon which an organization should build and test security policies, standards, guidelines, processes, and controls:
- Meeting stakeholder needs
- Covering the enterprise end-to-end
- Applying a single integrated framework
- Enabling a holistic approach
- Separating governance from management
Auditors may also use a methodology of their own design or one that has been adapted from several guidelines. What difference does it make to you as a security practitioner which methodology they use? From a technical standpoint, it does not matter; however, it is a good idea to be familiar with the methodology they are going to use to understand how management will be receiving the audit results.3
What Does an Auditor Do?
Auditors collect information about your security processes. Auditors are responsible for:
- Providing independent assurance to management that security systems are effective.
- Analyzing the appropriateness of organizational security objectives.
- Analyzing the appropriateness of policies, standards, baselines, procedures, and guidelines that support security objectives.
- Analyzing the effectiveness of the controls that support security policies.
- Stating and explaining the scope of the systems to be audited.
What Is the Audit Going to Cover?
Before auditors begin an audit, they define the audit scope that outlines what they are going to be looking at. One way to define the scope of an audit is to break it down into eight domains of security responsibility; that is, to break up the IT systems into manageable areas upon which audits may be based. For example, an audit may be broken into eight domains such as:
- User Domain—The users themselves and their authentication methods
- Workstation Domain—Often considered the end-user systems
- System/Application Domain—Applications that you run on your network, such as email, database, and web applications
- LAN Domain—Equipment required to create the internal LAN
- LAN-to-WAN Domain—The transition area between your firewall and the WAN, often where your DMZ resides
- WAN Domain—Usually defined as things outside of your firewall
- Remote Access Domain—How remote or traveling users access your network
- Cloud and Outsourced Domain—In what areas has the organization outsourced data, processing or transmission to other entities?
Auditors may also limit the scope by physical location, or they may just choose to review a subset of your security framework.
The security practitioner will be asked to participate in the audit by helping the auditors collect information and interpret the findings for the auditors. Having said that, there may be times when IT will not be asked to participate. They might be the reason for the audit, and the auditors need to get an unbiased interpretation of the data. There are several areas the security practitioner will be asked to participate in. Before participating in an audit, ensure controls, policies, and standards are in place to support target areas and be sure they are working up to the level prescribed. An audit is not the place to realize that logging or some other function is not working.
Documentation
As part of an audit, the auditors will want to review system documentation. This can include:
- Disaster/Business Recovery Documentation—While some IT practitioners and auditors do not see this as part of a security audit, others feel that because the recovery process involves data recovery and system configuration, it is an important and often overlooked piece of information security.
- Host Configuration Documentation—Auditors are going to want to see the documentation on how hosts are configured on the organization’s network both to see that everything is covered and to verify that the configuration documentation actually reflects what is being done.
- Baseline Security Configuration Documentation for Each Type of Host—As with the host configuration, this documentation does not just reflect the standard configuration data, but specifically what steps are being done related to security.
- Acceptable Use Documentation—Organizations often spell out acceptable use policies under the user responsibilities policy and the administrator use policy. Some also include it for particular hosts. For example, a company may say that there is to be no transfer of business confidential information over the FTP (file transfer protocol) server within the user policies and reiterate that policy both in an acceptable use policy for the FTP server as well as use it as a login banner for FTP services. As long as the message is the same, there is no harm in repeating it in several places.
- Change Management Documentation—There are two different types of change management documentation needed to produce for auditors. The first one would be the policy outlining the change management process. The other would be documentation reflecting changes made to a host.
- Data Classification Documentation—How are data classified? Are there some data the organization should spend more effort on securing than others? Having data classification documentation comes in handy for justifying why some hosts have more security restrictions than others do.
- Business Flow Documentation—Although not exactly related to IT security, documentation that shows how business data flow through the network can be a great aid to auditors trying to understand how everything works. For example, how does order entry data flow through the system from when the order is taken until it is shipped out to the customer? What systems do data reside on and how do data move around the network?
Responding to an Audit
Once the security practitioner has finished helping the auditors gather the required data and finished assisting them with interpreting the information, the practitioner’s work is not over. There are still a few more steps that need to be accomplished to complete the audit process.
Exit Interview
After an audit is performed, an exit interview will alert personnel to glaring issues they need to be concerned about immediately. Besides these preliminary alerts, an auditor should avoid giving detailed verbal assessments, which may falsely set the expectation level of the organization with regard to security preparedness in the audited scope.
Presentation of Audit Findings
After the auditors have finished tabulating their results, they will present the findings to management. These findings will contain a comparison of the audit findings versus the company’s security framework and industry standards or “best practices.” These findings will also contain recommendations for mitigation or correction of documented risks or instances of noncompliance.
Management Response
Management will have the opportunity to review the audit findings and respond to the auditors. This is a written response that becomes part of the audit documentation. It outlines plans to remedy findings that are out of compliance, or it explains why management disagrees with the audit findings.
The security practitioner should be involved in the presentation of the audit findings and assist with the management response. Even if input is not sought for the management response, the security practitioner needs to be aware of what issues were presented and what the management’s responses to those issues were.
Once all these steps are completed, the security cycle starts over again. The findings of the audit need to be fixed, mitigated, or introduced into the organization's security framework.
Security Assessment Activities
The security practitioner will be expected to perform security assessment activities including but not limited to vulnerability scanning, penetration testing, internal-external assessment, and interpreting the outcomes of the results.
Vulnerability Scanning and Analysis
Vulnerability scanning is simply the process of checking a system for weaknesses. These vulnerabilities can take the form of applications or operating systems that are missing patches, misconfiguration of systems, unnecessary applications, or open ports. While these tests can be conducted from outside the network, as an attacker would, it is advisable to do a vulnerability assessment from a network segment that has unrestricted access to the host the security practitioner is conducting the assessment against. Why is this? If the security practitioner only tests a system from the outside world, the security practitioner will identify any vulnerability that can be exploited from the outside. However, what happens if an attacker gains access inside the target network? Now there are vulnerabilities exposed to the attacker that could have easily been avoided. Unlike a penetration test, which is discussed later in this domain, a vulnerability tester has access to network diagrams, configurations, login credentials, and other information needed to make a complete evaluation of the system. The goal of a vulnerability assessment is to study the security level of the systems, identify problems, offer mitigation techniques, and assist in prioritizing improvements.
The benefits of vulnerability testing include the following:
- It identifies system vulnerabilities.
- It allows for the prioritization of mitigation tasks based on system criticality and risk.
- It is considered a useful tool for comparing security posture over time, especially when done consistently each period.
The disadvantages of vulnerability testing include:
- It may not effectively focus efforts if the test is not designed appropriately. Sometimes testers bite off more than they can chew.
- It has the potential to crash the network or host being tested if dangerous tests are chosen. (Innocent and noninvasive tests have been known to cause system crashes.)
Note that vulnerability testing software is often placed into two broad categories:
- General vulnerability
- Application-specific vulnerability
General vulnerability software probes hosts and operating systems for known flaws. It also probes common applications for flaws. Application-specific vulnerability tools are designed specifically to analyze certain types of application software. For example, database scanners are optimized to understand the deep issues and weaknesses of Oracle databases, Microsoft SQL Server, etc., and they can uncover implementation problems therein. Scanners optimized for web servers look deeply into issues surrounding those systems.
Vulnerability scanning software, in general, is often referred to as V/A (vulnerability assessment) software, and sometimes combines a port mapping function to identify which hosts are where and the applications they offer with further analysis that assigns vulnerabilities to applications. Good vulnerability software will offer mitigation techniques or links to manufacturer websites for further research. This stage of security testing is often an automated software process. It is also beneficial to use multiple tools and cross-reference the results of those tools for a more accurate picture. As with any automated process, the security practitioner needs to examine the results closely to ensure that they are accurate for the organization's environment.
Vulnerability testing usually employs software specific to the activity and tends to have the following qualities:
- OS Fingerprinting—This technique is used to identify the operating system in use on a target. OS fingerprinting is the process where a scanner can determine the operating system of the host by analyzing the TCP/IP stack flag settings. These settings vary on each operating system from vendor to vendor or by TCP/IP stack analysis and banner grabbing. Banner grabbing is reading the response banner presented for several ports such as FTP, HTTP, and Telnet. This function is sometimes built into mapping software and sometimes into vulnerability software.
- Stimulus and Response Algorithms—These are techniques to identify application software versions and then reference these versions with known vulnerabilities. Stimulus involves sending one or more packets at the target. Depending on the response, the tester can infer information about the target’s applications. For example, to determine the version of the HTTP server, the vulnerability testing software might send an HTTP GET request to a web server, just like a browser would (the stimulus), and read the reply information it receives back (the response) for information that details the fact that it is Apache version X, IIS version Y, etc.
- Privileged Logon Ability—The ability to automatically log onto a host or group of hosts with user credentials (administrator-level or other level) for a deeper “authorized” look at systems is desirable.
- Cross-Referencing—OS and applications/services (discovered during the port-mapping phase) should be cross-referenced to identify possible vulnerabilities. For example, if OS fingerprinting reveals that the host runs Red Hat Linux 8.0 and that portmapper is one of the listening programs, any pre-8.0 portmapper vulnerabilities can likely be ruled out. Keep in mind that old vulnerabilities have resurfaced in later versions of code even though they were patched at one time. While these instances may occur, the filtering based on OS and application fingerprinting will help the security practitioner better target systems and use the security practitioner's time more effectively.
- Update Capability—Scanners must be kept up to date with the latest vulnerability signatures; otherwise, they will not be able to detect newer problems and vulnerabilities. Commercial tools that do not have quality personnel dedicated to updating the product are of reduced effectiveness. Likewise, open-source scanners should have a qualified following to keep them up to date.
- Reporting Capability—Without the ability to report, a scanner does not serve much purpose. Good scanners provide the ability to export scan data in a variety of formats, including viewing in HTML or PDF format or to third-party reporting software, and are configurable enough to give the ability to filter reports into high-, mid-, and low-level detail depending on the intended audience for the report. Reports are used as basis for determining mitigation activities later. Additionally, many scanners are now feeding automated risk management dashboards using application portal interfaces.
Problems that may arise when using vulnerability analysis tools include:
- False Positives—When scanners use generalized tests or if the scanner does not have the ability to deeply scan the application, it might not be able to determine whether the application actually has vulnerability. It might result in information that says the application might have vulnerability. If it sees that the server is running a remote control application, the test software may indicate that the security practitioner has a “High” vulnerability. However, if the security practitioner has taken care to implement the remote control application to a high standard, the organization's vulnerability is not as high.
- Crash Exposure—V/A software has some inherent dangers because much of the vulnerability testing software includes denial-of-service test scripts (as well as other scripts), which, if used carelessly, can crash hosts. Ensure that hosts being tested have proper backups and that the security practitioner tests during times that will have the lowest impact on business operations.
- Temporal Information—Scans are temporal in nature, which means that the scan results the security practitioner has today become stale as time moves on and new vulnerabilities are discovered. Therefore, scans must be performed periodically with scanners that are up to date with the latest vulnerability signatures.
Scanner Tools
A variety of scanner tools are available:
- Nessus open source scanner—http://www.tenable.com/products/nessus
- eEye Digital Security’s Retina—http://www.beyondtrust.com/Products/RetinaNetworkSecurityScanner/
- SAINT—http://www.saintcorporation.com/
- For a more in-depth list, see http://sectools.org/web-scanners.html
Weeding Out False Positives
Even if a scanner reports a service as vulnerable, or missing a patch that leads to vulnerability, the system is not necessarily vulnerable. Accuracy is a function of the scanner’s quality; that is, how complete and concise the testing mechanisms are built (better tests equal better results), how up to date the testing scripts are (fresher scripts are more likely to spot a fuller range of known problems), and how well it performs OS fingerprinting (knowing which OS the host runs helps the scanner pinpoint issues for applications that run on that OS). Double check the scanner’s work. Verify that a claimed vulnerability is an actual vulnerability. Good scanners will reference documents to help the security practitioner learn more about the issue.
Host Scanning
Organizations serious about security create hardened host configuration procedures and use policy to mandate host deployment and change. There are many ingredients to creating a secure host, but the security practitioner should always remember that what is secure today might not be secure tomorrow, because conditions are ever changing. There are several areas to consider when securing a host or when evaluating its security. These are discussed in the following sections.
Disabling Unneeded Services
Services that are not critical to the role the host serves should be disabled or removed as appropriate for that platform. For the services the host does offer, make sure it is using server programs considered secure, make sure the security practitioner fully understands them, and tighten the configuration files to the highest degree possible. Unneeded services are often installed and left at their defaults, but since they are not needed, administrators ignore or forget about them. This may draw unwanted data traffic to the host from other hosts attempting connections, and it will leave the host vulnerable to weaknesses in the services. If a host does not need a particular host process for its operation, do not install it. If software is installed but not used or intended for use on the machine, it may not be remembered or documented that software is on the machine and therefore will likely not be patched. Port mapping programs use many techniques to discover services available on a host. These results should be compared with the policy that defines this host and its role. One must continually ask the critical questions, for the less a host offers as a service to the world while still maintaining its job, the better for its security (because there is less chance of subverting extraneous applications).
Disabling Insecure Services
Certain programs used on systems are known to be insecure, cannot be made secure, and are easily exploitable; therefore, only use secure alternatives. These applications were developed for private, secure LAN environments, but as connectivity proliferated worldwide, their use has been taken to insecure communication channels. Their weakness falls into three categories:
- They usually send authentication information unencrypted. For example, FTP and Telnet send username and passwords in the clear.
- They usually send data unencrypted. For example, HTTP sends data from client to server and back again entirely in the clear. For many applications, this is acceptable; however, for some it is not.
- SMTP also sends mail data in the clear unless it is secured by the application (e.g., the use of Pretty Good Privacy [PGP] within Outlook).
Common services are studied carefully for weaknesses by people motivated to attack the organization’s systems. Therefore, to protect hosts, one must understand the implications of using these and other services that are commonly hacked. Eliminate them when necessary or substitute them for more secure versions. For example:
- To ensure privacy of login information as well as the contents of client to server transactions, use SSH (secure shell) to log in to hosts remotely instead of Telnet.
- Use SSH as a secure way to send insecure data communications between hosts by redirecting the insecure data into an SSH wrapper. The details for doing this are different from system to system.
- Use SCP (Secure Copy) instead of FTP (file transfer protocol).
Ensuring Least Privilege File System Permissions
Least privilege is the concept that describes the minimum number of permissions required to perform a particular task. This applies to services/daemon processes as well as user permissions. Often systems installed out of the box are at minimum security levels. Make an effort to understand how secure newly installed configurations are, and take steps to lock down settings using vendor recommendations.
Making Sure File System Permissions Are as Tight as Possible
For UNIX-based systems, remove all unnecessary SUID (set used ID) and SGID (set group ID) programs that embed the ability for a program running in one user context to access another program. This ability becomes even more dangerous in the context of a program running with root user permissions as a part of its normal operation. For Windows-based systems, use the Microsoft Management Center (MMC) “security configuration and analysis” and “security templates” snap-ins to analyze and secure multiple features of the operation system, including audit and policy settings and the registry.
Establishing and Enforcing a Patching Policy
Patches are pieces of software code meant to fix a vulnerability or problem that has been identified in a portion of an operating system or in an application that runs on a host. Keep the following in mind regarding patching:
- Patches should be tested for functionality, stability, and security. You should also ensure that the patch does not change the security configuration of the organization's host. Some patches might reinstall a default account or change configuration settings back to a default mode. You need a way to test whether new patches will break a system or an application running on a system. When you are patching highly critical systems, it is advised to deploy the patch in a test environment that mimics the real environment. If the security practitioner does not have this luxury, only deploy patches at noncritical times, have a back-out plan, and apply patches in steps (meaning one by one) to ensure that each one was successful and the system is still operating.
- Use patch reporting systems that evaluate whether systems have patches installed completely and correctly and which patches are missing. Many vulnerability analysis tools have this function built into them, but be sure to understand how often the V/A tool vendor updates this list versus another vendor who specializes in patch analysis systems. Oftentimes, some vendors have better updating systems than others.
- Optimally, tools should test to see if once a patch has been applied to remove a vulnerability, the vulnerability does not still exist. Patch application sometimes includes a manual remediation component like a registry change or removing a user, and if the IT person applied the patch but did not perform the manual remediation component, the vulnerability may still exist.
Examining Applications for Weakness
In a perfect world, applications are built from the ground up with security in mind. Applications should prevent privilege escalation and buffer overflows and a myriad of other threatening problems. However, this is not always the case, and applications need to be evaluated for their ability not to compromise a host. Insecure services and daemons that run on hardened hosts may by nature weaken the host. Applications should come from trusted sources. Similarly, it is inadvisable to download executables from websites the security practitioner knows nothing about. Executables should be hashed and verified with the publisher. Signed executables also provide a level of assurance regarding the integrity of the file. Some programs can help evaluate a host’s applications for problems. In particular, these focus on web-based systems and database systems:
- Nikto (http://www.cirt.net) evaluates Web CGI systems for common and uncommon vulnerabilities in implementation.
- Web Inspect (http://www.purehacking.com.au) is an automated Web server scanning tool.
- Trustwave (https://www.trustwave.com) evaluates applications, especially various types of databases, for vulnerabilities.
The SSCP should do the following:
- Ensure that antivirus and antimalware software is installed and is up to date with the latest scan engine and pattern file offered by the vendor.
- Use products that encourage easy management and updates of signatures; otherwise, the systems may fail to be updated, rendering them ineffective to new exploits.
- Use products that centralize reporting of problems to spot problem areas and trends.
- Use system logging. Logging methods are advisable to ensure that system events are noted and securely stored, in the event they are needed later.
- Subscribe to vendor information. Vendors often publish information regularly, not only to keep their name in front of the security practitioner but also to inform the security practitioner of security updates and best practices for configuring their systems. Other organizations such as Security Focus (http://www.securityfocus.com) and CERT (http://www.cert.org) publish news of vulnerabilities. Some tools also specialize in determining when a system's software platform is out of compliance with the latest patches.
Firewall and Router Testing
Firewalls are designed to be points of data restriction (choke points) between security domains. They operate on a set of rules driven by a security policy to determine what types of data are allowed from one side to the other (point A to point B) and back again (point B to point A). Similarly, routers can also serve some of these functions when configured with access control lists (ACLs). Organizations deploy these devices to not only connect network segments together but also to restrict access to only those data flows that are required. This can help protect organizational data assets. Routers with ACLs, if used, are usually placed in front of the firewalls to reduce the noise and volume of traffic hitting the firewall. This allows the firewall to be more thorough in its analysis and handling of traffic. This strategy is also known as layering or defense in depth.
Changes to devices should be governed by change control processes that specify what types of changes can occur and when they can occur. This prevents haphazard and dangerous changes to devices that are designed to protect internal systems from other potentially hostile networks, such as the Internet or an extranet to which the organization’s internal network connects. Change control processes should include security testing to ensure the changes were implemented correctly and as expected.
Configuration of these devices should be reflected in security procedures, and the rules of the access control lists should be engendered by organizational policy. The point of testing is to ensure machine configurations match approved policy.
With this sample baseline in mind, port scanners and vulnerability scanners can be leveraged to test the choke point’s ability to filter as specified. If internal (trusted) systems are reachable from the external (untrusted) side in ways not specified by policy, a mismatch has occurred and should be assessed. Likewise, internal to external testing should conclude that only the allowed outbound traffic could occur. The test should compare a device’s logs with the tests dispatched from the test host.
Advanced firewall testing will test a device’s ability to perform the following (this is a partial list and is a function of the firewall’s capabilities):
- Limit TCP port scanning reconnaissance techniques (explained earlier in this domain) including SYN, FIN, XMAS, and NULL via the firewall.
- Limit ICMP and UDP port scanning reconnaissance techniques.
- Limit overlapping packet fragments.
- Limit half-open connections to trusted side devices. Attacks like these are called SYN attacks, when the attacker begins the process of opening many connections but never completes any of them, eventually exhausting the target host’s memory resources.
Advanced firewall testing can leverage a vulnerability or port scanner’s ability to dispatch denial-of-service and reconnaissance tests. A scanner can be configured to direct, for example, massive amounts of SYN packets at an internal host. If the firewall is operating properly and effectively, it will limit the number of these half-open attempts by intercepting them so that the internal host is not adversely affected. These tests must be used with care because there is always a chance that the firewall will not do what is expected and the internal hosts might be affected.
Security Monitoring Testing
IDS systems are technical security controls designed to monitor for and alert on the presence of suspicious or disallowed system activity within host processes and across networks. Device logging is used for recording many types of events that occur within hosts and network devices. Logs, whether generated by IDS or hosts, are used as audit trails and permanent records of what happened and when. Organizations have a responsibility to ensure that their monitoring systems are functioning correctly and alerting on the broad range of communications commonly in use. Documenting this testing can also be used to show due diligence. Likewise, the security practitioner can use testing to confirm that IDS detects traffic patterns as claimed by the vendor.
With regard to IDS testing, methods should include the ability to provide a stimulus (i.e., send data that simulate an exploitation of a particular vulnerability) and observe the appropriate response by the IDS. Testing can also uncover an IDS’s inability to detect purposeful evasion techniques that might be used by attackers. Under controlled conditions, stimulus can be crafted and sent from vulnerability scanners. Response can be observed in log files generated by the IDS or any other monitoring system used in conjunction with the IDS. If the appropriate response is not generated, investigation of the causes can be undertaken.
With regard to host logging tests, methods should also include the ability to provide a stimulus (i.e., send data that simulates a “log-able” event) and observe the appropriate response by the monitoring system. Under controlled conditions, stimulus can be crafted in many ways depending on the security practitioner's test. For example, if a host is configured to log an alert every time an administrator or equivalent logs on, the security practitioner can simply log on as the “root” user to the organization's UNIX system. In this example, the response can be observed in the system’s log files. If the appropriate log entry is not generated, investigation of the causes can be undertaken.
The overall goal is to make sure the monitoring is configured to the organization’s specifications and that it has all of the features needed.
The following traffic types and conditions are those the security practitioner should consider testing for in an IDS environment, as vulnerability exploits can be contained within any of them. If the monitoring systems the security practitioner uses do not cover all of them, the organization's systems are open to exploitation:
- Data Patterns That Are Contained within Single Packets—This is considered a minimum functionality because the IDS need only search through a single packet for an exploit.
- Data Patterns Contained within Multiple Packets—This is considered a desirable function because there is often more than one packet in a data stream between two hosts. This function, stateful pattern matching, requires the IDS to “remember” packets it saw in the past to reassemble them as well as perform analysis to determine if exploits are contained within the aggregate payload.
- Obfuscated Data—This refers to data that is converted from ASCII to Hexadecimal or Unicode characters and then sent in one or more packets. The IDS must be able to convert the code among all of these formats. If a signature that describes an exploit is written in ASCII but the exploit arrives at the organization’s system in Unicode, the IDS must convert it back to ASCII to recognize it as an exploit.
- Fragmented Data—IP data can be fragmented across many small packets, which are then reassembled by the receiving host. Fragmentation occasionally happens in normal communications. In contrast, overlapping fragments is a situation where portions of IP datagrams overwrite and supersede one another as they are reassembled on the receiving system (a teardrop attack). This can wreak havoc on a computer, which can become confused and overloaded during the reassembly process. IDS must understand how to reassemble fragmented data and overlapping fragmented data so it can analyze the resulting data. These techniques are employed by attackers to subvert systems and to evade detection.
- Protocol Embedded Attacks—IDS should be able to decode (i.e., break apart, understand, and process) commonly used applications (DNS, SSL, HTTP, FTP, SQL, etc.), just like a host would, to determine whether an attacker has manipulated code that might crash the application or host on which it runs. Therefore, testing should employ exploits embedded within application data.
- Flooding Detection—An IDS should be able to detect conditions indicative of a denial-of-service flood, when too many packets originate from one or more sources to one or more destinations. Thresholds are determined within the configuration. For example, an IDS should be able to detect if more than 10 half-open connections are opened within 2 seconds to any one host on the organization’s network.
Intrusion Prevention Systems (IPS) Security Monitoring
IPSs are technical security controls designed to monitor and alert for the presence of suspicious or disallowed system activity within host processes and across networks, and then take action on suspicious activities. Likewise, the security practitioner can use testing to confirm that IPS detects traffic patterns and reacts as claimed by the vendor. When one is auditing an IPS, its position in the architecture is slightly different from that of an IDS; an IPS needs to be positioned inline of the traffic flow so the appropriate action can be taken. Some of the other key differences are as follows: The IPS acts on issues and handles the problems, while an IDS only reports on the traffic and requires some other party to react to the situation. The negative consequence of the IPS is that it is possible to reject good traffic and there will only be the logs of the IPS to show why the good traffic is getting rejected. Many times, the networking staff may not have access to those logs and may find network troubleshooting more difficult.
Security Gateway Testing
Some organizations use security gateways or web proxies to intercept certain communications and examine them for validity. Gateways perform their analysis on these communications based on a set of rules supplied by the organization—rules driven by policy—and pass them along if they are deemed appropriate and exploitation-free, or block them if they are not. Security gateway types include the following:
- Antivirus Gateways—These systems monitor for viruses contained within communications of major application types like web traffic, email, and FTP.
- Java/ActiveX Filters—These systems screen communications for these components and block or limit their transmission.
- Web Traffic Screening—These systems block web traffic to and from specific sites or sites of a specific type (gambling, pornography, games, travel and leisure, etc.).
Security testing should encompass these gateway devices to ensure their proper operation. Depending on the device, the easiest way to test to ensure that it is working is try to perform the behavior that it is supposed to block. There are “standard” antivirus (AV) test files available on the Internet that do not contain a virus but have a signature that will be discovered by all major AV vendors. While this file will not ensure that the organization's AV will catch everything, it will at least confirm that the gateway is looking into the traffic for virus patterns.
Wireless Networking Testing
With the proliferation of wireless access devices comes the common situation where they are not configured for even minimal authentication and encryption because the people deploying them generally have no knowledge of the ramifications. Therefore, periodic wireless testing to spot unofficial access points is needed.
Adding 802.11-based wireless access points (AP) to networks increases overall convenience for users, mostly because of the new mobility that is possible. Whether using handheld wireless PDA devices, laptop computers, or the newly emerging wireless voice over IP telephones, users are now able to flexibly collaborate outside of the office confines—ordinarily within the building and within range of an AP—while still remaining connected to network-based resources. To enable wireless access, one can procure an inexpensive wireless access point and plug it into the network. Communication takes place from the unwired device to the AP. The AP serves (usually) as a bridge to the wired network.
The problem with this from a security perspective is that allowing the addition of one or more AP units onto the network infrastructure will likely open a large security hole. Therefore, no matter how secure the organization’s wired network is, adding one AP with no configured security is like adding a network connection to the parking lot, which allows anyone with the right tools and motivation to access the network. The implication here is that many APs as originally implemented in the 802.11b/g/n standard have easily breakable security. Security testers should have methods to detect rogue APs that have been added by employees or unauthorized persons so these wireless security holes can be examined. The following wireless networking high points discuss some of the issues surrounding security of these systems:
- Wireless-enabled devices (e.g., laptops) can associate with wireless access points or other wireless devices to form a bridged connection to the wired network.
- Without some form of authentication, rogue devices can attach to the wireless network.
- Without some form of encryption, data transferring between the wired and the wireless network can be captured.
With this information, a security tester can test for the effectiveness of wireless security in the environment using specialized tools and techniques as presented here.
To search for rogue (unauthorized) access points, the security practitioner can use some of the following techniques:
- Use a network vulnerability scanner with signatures that specifically scan for MAC addresses (of the wired port) of vendors that produce AP units, and then attempt to connect to that interface on an HTTP port. If the unit responds, analyze the web code to determine if it is a webpage related to the management of the AP device. This requires periodic scanning and will leave the server vulnerable until the next scan.
- Use a laptop or handheld unit loaded with software that analyzes 802.11x radio frequency (RF) transmissions for SSIDs and WAP wired side MAC addresses that do not belong to the company or are not authorized. Make sure discovery tools pick up all bands and 802.11x types; that is, if the security practitioner only tests for 802.11b, the security practitioner may miss rogue 802.11a units. This requires periodic scanning by physically walking through the organization’s grounds, and will leave the organization vulnerable until the next scan.
- Up and coming solutions allow for authorized APs and wireless clients to detect unauthorized RF transmissions and “squeal” on the rogue access point. This information can be used to automatically disable an infrastructure switch port to which a rogue has connected.
To lock down the enterprise from the possibility of rogue APs, the security practitioner can do the following:
- Enable MAC address filtering on the infrastructure switches. This technique matches each port to a known MAC address. If someone plugs in an unapproved MAC to a switch port expecting another MAC address, the AP will never be able to join the network from the wired side unless it has its MAC changed.
To gauge security effectiveness of authorized APs:
- Discover authorized APs using the tools described herein and ensure they require encryption.
- Ensure discovered APs meet other policy requirements such as the type of authentication (802.1x or other), SSID naming structure, and MAC address filtering.
- Ensure APs have appropriate layer 2 Ethernet type filters, layer 3 protocol filters, and layer 4 port filters (to match the organization’s configuration procedures) so that untrusted wireless traffic coming into the AP is limited to only that which is needed and required.
Wireless Tools
There are a variety of useful wireless tools available:
- Netstumbler (http://www.netstumbler.com)—Windows software that detects 802.11b information through RF detection including SSID, whether communication is encrypted, and signal strength.
- Kismet (http://www.kismetwireless.net)—Linux software that detects 802.11b and 802.11a information through RF detection including SSID, whether communication is encrypted, and signal strength. It features the ability to rewrite the MAC address on select wireless cards.
- Wellenreiter (http://sourceforge.net/projects/wellenreiter/?source=directory)—Linux software that detects wireless networks. It runs on Linux-based handheld PDA computers.
- Nessus (http://www.nessus.org)—Linux software for vulnerability assessment that includes 30-plus signatures to detect WAP units.
- Aircrack-NG (http://www.aircrack-ng.org/doku.php)—Aircrack-ng is an 802.11 WEP and WPA-PSK keys cracking program that can recover keys once enough data packets have been captured. It implements the standard FMS attack along with some optimizations like KoreK attacks, as well as the PTW attack, thus making the attack much faster compared to other WEP cracking tools. In fact, Aircrack-ng is a set of tools for auditing wireless networks.
War Dialing
War dialing attempts to locate unauthorized, also called rogue, modems connected to computers that are connected to networks. Attackers use tools to sequentially and automatically dial large blocks of numbers used by the organization in the hopes that rogue modems or modems used for out-of-band communication will answer and allow them to make a remote asynchronous connection to it. With weak or nonexistent authentication, these rogue modems may serve as a back door into the heart of a network, especially when connected to computers that host remote control applications with lax security. Security testers can use war dialing techniques as a preventative measure and attempt to discover these modems for subsequent elimination. Although modems and war dialing have fallen out of favor in the IT world, a security practitioner still needs to check for the presence of unauthorized modems connected to their network
War Driving
War driving is the wireless equivalent of war dialing. While war dialing involves checking banks of numbers for a modem, war driving involves traveling around with a wireless scanner looking for wireless access points. Netstumbler was one of the original products that people used for war driving. From the attacker perspective, war driving gives them a laundry list of access points where they can attach to a network and perform attacks. The best ones in a hacker’s eye are the unsecured wireless access points that allow unrestricted access to the corporate network. The hacker will not only compromise the corporate network but will then use the corporate Internet access to launch attacks at other targets that are then untraceable back to the hacker. From a security standpoint, war driving enables the security practitioner to detect rogue access points in and around the physical locations. Is an unsecured wireless access point that is not on the network a security threat to the network? It certainly is. If a user can connect their workstation to an unknown and unsecured network, they introduce a threat to the security of the network.
Penetration Testing
Penetration testing takes vulnerability assessment one step farther. It does not stop at identifying vulnerabilities; it also uses those vulnerabilities to expose other weaknesses in the network. Penetration testing consists of five different phases:
- Phase 1—Preparation
- Phase 2—Information gathering
- Phase 3—Information evaluation and risk analysis
- Phase 4—Active penetration
- Phase 5—Analysis and reporting
Penetration testing also has three different modes, which will be explored in more detail later in the domain. Those modes are:
- White box—Tester has complete knowledge of the systems and infrastructure being tested.
- Gray box—A hybrid between white and black box. This mode can vary greatly.
- Black box—Assumes no prior knowledge of the systems or infrastructure being tested.
White Box
These testers perform tests with the knowledge of the security and IT staff. They are given physical access to the network and sometimes even a normal username and password. Qualities include:
- Full cooperation of organization
- Planned test times
- Network diagrams and systems configurations are supplied
There are several pros and cons to consider with the white box approach:
- Pros—The security practitioner should get good reaction and support from the organization being tested, and fixes can occur more rapidly. It is also good to use as a dry run for testing the organization's incident response procedures.
- Cons—An inaccurate picture of the organization’s network response capabilities may appear because the organization is prepared for the “attack.”
Grey Box
Grey box testing involves giving some information to the penetration testing team. Sometimes this may involve publically discoverable information, and it may also include some information about systems inside the protective boundaries of the organization. Grey box testing allows the penetration testing team to focus on attacking the organization and trying to get access and reducing time on discovery. Organizations who feel they have a good grasp on what is publically available about them often use this approach to maximize the resources focused on specific system attacks.
There are several pros and cons to consider with the grey box approach:
- Pros—The gray box approach provides the combined benefits of white and black box testing techniques and allows for the creation of really focused testing scenarios.
- Cons—Test coverage may be limited due to the level of access granted.
Black Box
These testers generally perform unannounced tests that even the security and IT staff may not know about. Sometimes these tests are ordered by senior managers to test their staff and the systems for which the staff are responsible. Other times, the IT staff will hire covert testers under the agreement that the testers can and will test at any given time, such as four times per year. The objective is generally to see what they can see and get into whatever they can get into, without causing harm, of course. Qualities include:
- Play the role of hostile attacker
- Perform testing without warning
- Receive little to no guidance from the organization being tested
There are several pros and cons to consider with the black box approach:
- Pros—The security practitioner can get a better overall view of the network's real responses without someone being prepared for the testing.
- Cons—The staff may take the findings personally and show disdain to the testing team and management.
Phase 1: Penetration Testing Goals
Without defined goals, security testing can be a meaningless and costly exercise. The following are examples of some high-level goals for security testing, thereby providing value and meaning for the organization:
- Anyone directly or indirectly sanctioned by the organization’s management to perform testing should be doing so to identify vulnerabilities that can be quantified and placed in a ranking for subsequent mitigation.
- Since a security test is merely the evaluation of security on a system at a point in time, the results should be documented and compared to the results at other points in time. Analysis that compares results across times paints a picture of how well or poorly the systems are being protected across those periods (otherwise known as base lining).
- Security testing can be a form of self-audit by the IT staff to prepare them for the “real” audits performed by internal and external auditors.
- In the case of covert testing, testers aim to actually compromise security, penetrate systems, and determine if the IT staff notices the intrusion and an acceptable response has occurred.
It is extremely important as a security practitioner to ensure that the security practitioner has business support and authorization (in accordance with a penetration testing policy) before conducting a penetration test. It is advisable to get this support and permission in writing before conducting the testing.
Penetration Test Software Tools
Software tools exist to assist in the testing of systems from many angles. Tools help the security practitioner to interpret how a system functions for evaluating its security. This section presents some tools available on the commercial market and in the open source space as a means to the testing end. Do not interpret the listing of a tool as a recommendation for its use. Likewise, just because a tool is not listed does not mean it is not worth considering. Choosing a tool to test a particular aspect is a personal or organizational choice.
Some points to consider regarding the use of software tools in the security testing process:
- Do not let tools drive the security testing. Develop a strategy and pick the right tool mix for discovery and testing based on the overall testing plan.
- Use tools specific to the testing environment. For example, if the aim is to test the application of operating system patches on a particular platform, analyze the available ways the security practitioner might accomplish this process by seeing what the vendor offers and compare this against third-party tools. Pick tools that offer the best performance tempered with the budget constraints.
- Tool functions often overlap. The features found on one tool may be better than those on another.
- Security testing tools can make mistakes, especially network-based types that rely on circumstantial evidence of vulnerability. Further investigation is often necessary to determine if the tool interpreted an alleged vulnerability correctly.
- Placement of probes is critical. When possible, place them on the same segment the security practitioner is testing so that filtering devices and intrusion detection systems do not alter the results (unless the security practitioner is planning to test how intrusion detection systems react).
- Network tools sometimes negatively affect uptime; therefore, these tests should often be scheduled for off-hours execution due to the fact that they can potentially cause the following to occur:
- Increasing network traffic load
- Affecting unstable platforms that react poorly to unusual inputs
Be aware that the models for detection of vulnerabilities are inconsistent among different toolsets; therefore, results should be studied and made reasonably consistent among different tools.
Analyzing Testing Results
It is often easier to understand the testing results by creating a graphical depiction in a simple matrix of vulnerabilities, ratings for each, and an overall vulnerability index derived as the product of vulnerability and system criticality. More complicated matrices may include details describing each vulnerability and sometimes ways to mitigate it or ways to confirm the vulnerability.
Tests should conclude with a report and matrices detailing the following:
- Information derived publicly
- Information derived through social engineering or other covert ways
- Hosts tested and their addresses
- Services found
- Possible vulnerabilities
- Vulnerability ratings for each
- System criticality
- Overall vulnerability rating
- Vulnerabilities confirmation
- Mitigation suggestions
Testers often present findings matrices that list each system and the vulnerabilities found for each with a “high, medium, low” ranking. The intent is to provide the recipient a list of what should be fixed first. The problem with this method is that it does not take into account the criticality of the system in question. You need a way to differentiate among the urgency for fixing “high” vulnerabilities across systems. Therefore, reports should rank true vulnerabilities by seriousness, taking into account how the organization views the asset’s value. Systems of high value may have their medium and low vulnerabilities fixed before a system of medium value has any of its vulnerabilities fixed. This criticality is determined by the organization, and the reports and matrices should help reflect a suggested path to rectifying the situation. For example, the organization has received a testing report listing the same two high vulnerabilities for a print server and an accounting database server. The database server is certainly more critical to the organization; therefore, its problems should be mitigated before those of the print server.
As another example, assume the organization has assigned a high value to the database server that houses data for the web server. The web server itself has no data but is considered medium value. In contrast, the FTP server is merely for convenience and is assigned a low value. A security testing matrix may show several high vulnerabilities for the low-value FTP server. It may also list high vulnerabilities for both the database server and the web server. The organization will likely be interested in fixing the high vulnerabilities first on the database server, then the web server, and then the FTP server. This level of triage is further complicated by trust and access between systems. If the web server gets the new pages and content from the FTP server, this may increase the priority of the FTP server issues over that of the usually low-value FTP server issues.
Phase 2: Reconnaissance and Network Mapping Techniques
Basic security testing activities include reconnaissance and network mapping.
- Reconnaissance—Collecting information about the organization from publicly available sources, social engineering, and low-tech methods. This information forms the test attack basis by providing useful information to the tester.
- Network Mapping—Collecting information about the organization’s Internet connectivity and available hosts by (usually) using automated mapping software tools. In the case of internal studies, the internal network architecture of available systems is mapped. This information further solidifies the test attack basis by providing even more information to the tester about the services running on the network and is often the step before vulnerability testing, which is covered in the next section.
Penetration testing is an art. This means that different IT security practitioners have different methods for testing. This domain attempts to note the highlights to help the security practitioner differentiate among the various types and provides information on tools that assist in the endeavor. Security testing is an ethical responsibility. Testing must always be authorized, and the techniques should never be used for malice. This information on tools is presented for the purpose of helping the security practitioner spot weaknesses in the systems the security practitioner is authorized to test so that they may be improved.
Reconnaissance
Often reconnaissance is needed by a covert penetration tester who has not been granted regular access to perform a cooperative test. These testers are challenged with having little to no knowledge of the system and must collect it from other sources to form the basis of the test attack.
Reconnaissance is necessary for these testers because they likely have no idea what they will be testing at the commencement of the test. Their orders are usually “see what the security practitioner can find and get into but do not damage anything.”
Once the security practitioner thinks they know what should be tested based on the information collected, they must always check with the persons who have hired them to ensure that the systems the security practitioner intends to penetrate are actually owned by the organization. Doing otherwise may put delicate systems in harm’s way, or the tester may test something not owned by the organization ordering the test (leading to possible legal repercussions and financial exposure). These parameters should be defined before the test.
Social Engineering and Low-Tech Reconnaissance
Social engineering is an activity that involves the manipulation of persons or physical reconnaissance to get information for use in exploitation or testing activities. Low-tech reconnaissance uses simple technical means to obtain information.
Before attackers or testers make an attempt on the organization's systems, they can learn about the target using low-technology techniques such as:
- Directly visiting a target’s web server and searching through it for information.
- Viewing a webpage’s source for information about what tools might have been used to construct or run it.
- Accessing employee contact information.
- Obtaining corporate culture information to pick up internally used lingo and product names.
- Identifying business partners.
- Googling a target. Attackers perform reconnaissance activity by using search engines that have previously indexed a target site. The attacker can search for files of a particular type that may contain information they can use for further attacks. Google and other search engines can be very powerful tools to a cracker because of the volume of data the search engines are able to organize. Example: Search a particular website for spreadsheet files containing the word “employee” or “address” or “accounting.”
- Dumpster diving to retrieve improperly discarded computer media and paper records for gleaning private information about an organization. Besides paper, this can include the following hardware:
- Computer hard drives and removable media (floppies, USB drives, CDs, etc.) thrown away or sold without properly degaussing to remove all private information.
- Equipment (routers, switches, and specialized data processing devices) discarded without configuration data being removed without a trace.
- Shoulder surfing, which means furtively collecting information by standing within view of a person typing a password or sensitive information (e.g., someone else’s password).
- Engaging in social engineering using the telephone. Attackers often pose as an official technical support person or fellow employee and attempt to build a rapport with a user through small talk. The attacker may ask for the user’s assistance with (false) troubleshooting “tests” aimed at helping the attacker collect information about the system. If the attacker finds a particularly “helpful” user, he might be bold enough to ask for their username and password because “we’ve been having trouble with the router gateway products interfacing with the LDAP directories where the username and password are stored, and we think it is getting corrupted as it passes over the network… So if you could just tell me what it is, that would be great,” or some such nonsense aimed at gaining the user’s confidence. The other possible scenarios that can be used with social engineering to gain information are only limited by the security practitioner's imagination.
- Conducting Usenet searches. Usenet postings can give away information about a company’s internal system design and problems that exist within systems. For example: “I need advice on my firewall. It is an XYZ brand system and I have it configured to do this, that, and the other thing. Can anyone help me?—signed joe@big_company_everyone_knows.com”
Mid-Tech Reconnaissance
Mid-tech reconnaissance includes several ways to get information that can be used for testing.
- Whois Information—Whois is a system that records Internet registration information, including the company that owns the domain, administrative contacts, technical contacts, when the record of domain ownership expires, and DNS servers authoritative for maintaining host IP addresses and their associated friendly names for the domains the security practitioner is testing. With this information, the security practitioner can use other online tools to dig for information about the servers visible on the Internet without ever sending a single probing packet at the Internet connection. The contact information provided by Whois can also be used for social engineering and war dialing.
The following are example attacks:
- Using Whois, collect information about DNS servers authoritative for maintaining host IP addresses for a particular domain.
- Using Whois, identify the administrative contact and his telephone number. Use social engineering on that person or security-unaware staff at the main telephone number to obtain unauthorized information.
- Using Whois, identify the technical contact and her area code and exchange (telephone number). Using war dialing software against the block of phone numbers in that exchange, the security practitioner attempts to make an unauthorized connection with a modem for the purpose of gaining backdoor entry to the system.
There are many sources for Whois information and tools, including:
DNS Zone Transfers
In an effort to discover the names and types of servers operating inside or outside a network, attackers may attempt zone transfers from DNS servers. A zone transfer is a special type of query directed at a DNS server that asks the server for the entire contents of its zone (the domain that it serves). Information that is derived is only useful if the DNS server is authoritative for that domain. To find a DNS server authoritative for a domain, one can refer to the Whois search results, which often provide this information. Internet DNS servers will often restrict which servers are allowed to perform transfers, but internal DNS servers usually do not have these restrictions.
Secure systems should lock down DNS. Testers should see how the target does this by keeping the following in mind:
- Attackers will attempt zone transfers; therefore, configure DNS’s to restrict zone transfers to only approved hosts.
- Attackers will look for host names that may give out additional information—accountingserver.bigfinancialcompany.com.
- Avoid using Host Information Records (HINFO) when possible. HINFO is the Host Information Record of a DNS entry. It is strictly informational in nature and serves no function. It is often used to declare the computer type and operating system of a host.
- Use a split DNS model with internal DNS and external DNS servers. Combining internal and external functions on one server is potentially dangerous. Internal DNS will serve the internal network and can relay externally bound queries to the external DNS servers that will do the lookup work by proxy. Incoming Internet-based queries will only reveal external hosts because the external hosts only know these addresses.
There are varieties of free programs available that will resolve DNS names, attempt zone transfers, and perform a reverse lookup of a specified range of IPs. Major operating systems also include the “nslookup” program, which can also perform these operations.
Network Mapping
Network mapping is a process that paints the picture of which hosts are up and running externally or internally and what services are available on the system. Commonly, the security practitioner may see mapping in the context of external host testing and enumeration in the context of internal host testing, but this is not necessarily ironclad, and mapping and enumeration often seem to be used interchangeably. They essentially accomplish similar goals, and the terms can be used in similar ways.
When performing mapping of any kind, the tester should limit the mapping to the scope of the project. Testers may be given a range of IP addresses to map, so the testers should limit the query to that range. Overt and covert testing usually includes network mapping, which is the activity that involves techniques to discover the following:
- Which hosts are up and running or “alive”?
- What is the general topology of the network (how are things interconnected)?
- What ports are open and serviceable on those hosts?
- What applications are servicing those ports?
- What operating system is the host running?
Mapping is the precursor to vulnerability testing and usually defines what will be tested more deeply at that next stage. For example, consider a scenario where the security practitioner discovers that a host is listening on TCP port 143. This probably indicates the host is running application services for the IMAP mail service. Many IMAP implementations have vulnerabilities. During the network mapping phase, the security practitioner learns that host 10.1.2.8 is listening on this port. Network mapping may provide insight about the operating system the host is running, which may in turn narrow the possible IMAP applications. For example, it is unlikely that the Microsoft Exchange IMAP process will be running on a Solaris computer; therefore, if network mapping shows a host with telltale Solaris “fingerprints” as well as indications that the host is listening on TCP port 143, the IMAP server is probably not being provided by Microsoft Exchange. As such, when the security practitioner is later exploring vulnerabilities, they can likely eliminate Exchange IMAP vulnerabilities for this host.
Mapping results can be compared to security policy to discover rogue or unauthorized services that appear to be running. For example, an organization may periodically run mapping routines to match results with what should be expected. If more services are running than one would expect to be running, the systems may have been accidentally misconfigured (therefore opening up a service not approved in the security policy) or the host(s) may have been compromised.
When performing mapping, make sure the security practitioner is performing the mapping on a host range owned by the organization. For example, suppose an nslookup DNS domain transfer for bobs-italianbookstore.com showed a mail server at 10.2.3.70 and a Web server at 10.19.40.2. Assuming the security practitioner does not work for bobs-italianbookstore.com and does not have intimate knowledge of their systems, the security practitioner might assume that they have two Internet connections. In a cooperative test, the best course of action is to check with their administrative staff for clarification. They may tell the security practitioner that the mail is hosted by another company and that it is outside of the scope of the test. However, the web server is a host to be tested. You should ask which part of the 10.0.0.0 bobsbookstore.com controls. Let us assume they control the class-C 10.19.40.0 range. Therefore, network mapping of 10.19.40.1 through 10.19.40.254 is appropriate and will not interfere with anyone else’s operations. Even though only one host is listed in the DNS, there may be other hosts up and running.
Depending on the level of stealth required (i.e., to avoid detection by IDS systems or other systems that will “notice” suspected activity if a threshold for certain types of communication is exceeded), network mapping may be performed very slowly over long periods of time. Stealth may be required for covert penetration tests.
Network mapping can involve a variety of techniques for probing hosts and ports. Several common techniques are:
- ICMP Echo Requests (ping)—If the security practitioner pings a host and it replies, it is alive (i.e., up and running). This test does not show what individual services are running. Be aware that many networks block incoming echo requests. If the requests are blocked and the security practitioner pings a host and it does not reply, the security practitioner has no way of knowing if it is actually running or not because the request is blocked before it gets to the destination.
- TCP Connect Scan—A connect scan can be used to discover TCP services running on a host even if ICMP is blocked. This type of scan is considered “noisy” (noticeable to logging and intrusion detection systems) because it goes all the way through the connection process. This basic service discovery scan goes all the way through a TCP session setup by sending a SYN packet to a target, receiving the SYN/ACK from the target when the port is listening, then sending a final ACK back to the target to establish the connection. At this point, the test host is “connected” to the target. Eventually the connection is torn down because the tester’s goal is not to communicate with the port but only to discover whether it is available.
- TCP SYN Scan—SYN scanning can be used to discover TCP services running on a host even if ICMP is blocked. SYN scanning is considered less noisy than connect scans. It is referred to as “half-open” scanning because unlike a connect scan (above), the security practitioner does not open a full TCP connection. Your test host directs a TCP SYN packet on a particular port as if it were going to open a real TCP connection to the target host. A SYN/ACK from the target indicates the host is listening on that port. An RST from the target indicates that it is not listening on that port. If a SYN/ACK is received, the test host immediately sends an RST to tear down the connection to conserve resources on both the test and target host sides. Firewalls often detect and block these scan attempts.
- TCP FIN Scan—FIN scanning can be used to discover TCP services running on a host even if ICMP is blocked. FIN scanning is considered a stealthy way to discover if a service is running. The test host sends a TCP packet with the FIN bit on to a port on the target host. If the target responds with an RST packet, the security practitioner may assume that the target host is not using the port. If the host does not respond, it may be using the port that was probed. Caveats to this technique are Microsoft, Cisco, BSDI, HP/UX, MVS, and IRIX-based hosts that implement their TCP/IP software stack in ways not defined by the standard. These hosts may not respond with an RST when probed by a FIN. However, if the security practitioner follows up a nonreply to one of these systems with, for example, a SYN scan to that port and the host replies, the security practitioner has determined that the host is listening on the port being tested and a few possible operating systems (see OS fingerprinting).
- TCP XMAS Scan—XMAS scans are similar to a FIN scan (and similarly stealthy), but they additionally turn on the URG (urgent) and PSH (push) flags. The goal of this scan is the same as a TCP FIN scan. The additional flags might make a packet be handled differently than a standard packet, so the security practitioner might see different results.
- TCP NULL Scan—NULL scans are similar to a FIN scan (also stealthy), but they turn off all flags. The NULL scan is similar to the others noted above; however, by turning off all TCP flags (which should never occur naturally), the packet might be handled differently, and the security practitioner may see a different result.
- UDP Scans—A UDP scan determines which UDP service ports are opened on a host. The test machine sends a UDP packet on a port to the target. If the target sends back an ICMP port unreachable message, the target does not use that port. A potential problem with this methodology is the case where a router or firewall at the target network does not allow ICMP port unreachable messages to leave the network, making the target network appear as if all UDP ports are open (because no ICMP messages are getting back to the test host). Another problem is that many systems limit the number of ICMP messages allowed per second, which can make for a very slow scanning rate.
Available mapping tools include:
- Nmap—http://www.insecure.org
- Solarwinds—http://www.solarwinds.net
- Superscan—http://www.mcafee.com/us/downloads/free-tools/index.aspx
- Lanspy—http://lantricks.com/lanspy (only available for Windows 2000/XP/2003)
Another technique for mapping a network is commonly known as “firewalking,” which uses traceroute techniques to discover which services a filtering device like a router or firewall will allow through. These tools generally function by transmitting TCP and UDP packets on a particular port with a time to live (TTL) equal to at least one greater than the targeted router or firewall. If the target allows the traffic, it will forward the packets to the next hop. At that point, the traffic will expire as it reaches the next hop, and an ICMP_TIME_EXCEEDED message will be generated and sent back out of the gateway to the test host. If the target router or firewall does not allow the traffic, it will drop the packets and the test host will not see a response.
Available firewalking tools include:
- Hping—http://www.hping.org/
- Firewalk—http://www.tucows.com/preview/8046
By all means, do not forget about the use of basic built-in operating system commands for discovering hosts and routes. Basic built-in and other tools include:
- Traceroute (Windows calls this tracert)—Uses ICMP or TCP depending on the implementation of a path to a host or network.
- Ping—See if a host is alive using ICMP echo request messages.
- Telnet—Telnetting to a particular port is a quick way to find out if the host is servicing that port in some way.
- Whois—Command line Whois can provide similar information to the web-based Whois methods previously discussed.
Another useful technique is system fingerprinting. System fingerprinting refers to testing techniques used by port scanners and vulnerability analysis software that attempt to identify the operating system in use on a network device and the versions of services running on the host. Why is it important to identify a system? By doing so, the security practitioner knows what they are is dealing with and, later on, what vulnerabilities are likely for that system. As mentioned previously, Microsoft-centric vulnerabilities are (usually) not going to show up on Sun systems and vice versa.
One final resource to keep in mind is web repositories for vulnerabilities are extremely useful for the security practitioner. Websites such as shodan (www.shodanhq.com) actively compile vulnerable online devices in a searchable format. Additionally, organizations such as NIST compile centralized vulnerability databases such as the National Vulnerability Database (http://nvd.nist.gov/).
Phase 3: Information Evaluation and Risk Analysis
Before active penetration, the security practitioner needs to evaluate the findings and perform risk analysis on the results to determine which hosts or services the security assessor is going to try and actively penetrate. The security practitioner should not perform an active penetration on every host until the organization has fully completed Phase 2. The security practitioner must also identify the potential business risks associated with performing a penetration test against particular hosts. The security practitioner can and probably will interrupt normal business processes if they perform a penetration test on a production system. The business leaders need to be made aware of that fact, and they need to be involved in making the decision on which devices to actively penetrate.
Phase 4: Active Penetration
This bears repeating. Think twice before attempting to exploit a possible vulnerability that may harm the system. For instance, if the system might be susceptible to a buffer overflow attack, it might be enough to identify the vulnerability without actually exploiting it and bringing down the system. Weigh the benefits of succinctly identifying vulnerabilities against potentially crashing the system. Here are some samples:
- Vulnerability testing shows that a Web server may be vulnerable to crashing if it is issued a very long request with dots (i.e., ../../../../../../../../../ 1000 times). The security practitioner can either try to actually crash the server using the technique (although this may have productivity loss consequences), or alternatively and perhaps for the better they can note it for further investigation, perhaps on a test server. Make sure permission is explicitly granted before attempting this type of actual exploitation.
- Vulnerability testing shows that a UNIX host has a root account with the password set to root. You can easily test this find to determine whether this is a false positive.
- Vulnerability testing shows that a router may be susceptible to an SSH attack. You can either try the attack with permission or note it for further investigation.
Phase 5: Analysis and Reporting
As with any security testing, documentation of the test, analysis of the results, and reporting those results to the proper managers are imperative. Many different methods can be utilized when reporting the results of a vulnerability scan. A comprehensive report will have separate sections for each management/technical level involved in the test. An overview of the results with a summary of the findings might be ideal for management, while a technical review of specific findings with remediation recommendations would be appropriate for the device administrators. As with any report that outlines issues, it is always best to offer solutions for fixing the issues as well as reporting their existence.
Penetration Testing High-Level Steps
The following outline provides a high-level view of the steps that could be taken to exploit systems during a penetration test. It is similar in nature to a vulnerability test but goes further to perform an exploit.
- Obtain a network address (usually center on internal testing when the security practitioner is physically onsite). With the advent DHCP on the network, a tester can often plug in and get an IP address right away. DHCP assigned addresses usually come with gateway and name server addresses. If the tester does not get a DHCP address, the system may be setup for static addresses. You can sniff the network for communications that detail the segment the security practitioner is on and guess at an unused address.
- Reconnaissance—Verify target information:
- DNS information obtained via DHCP
- DNS zone transfer when allowed by the server
- Whois
- Browsing an internal domain
- Using Windows utilities to enumerate servers
- Pings sweeps
- Traceroute
- Port scans (TCP connect, SYN scans, etc.)
- OS fingerprinting
- Banner grabbing
- Unix RPC discovery
- Target vulnerability analysis and enumeration:
- Using techniques that are less likely to be logged or reported in an IDS system (i.e., less “noisy” techniques) evaluates the vulnerability of ports on a target.
- For Windows systems, gather user, group, and system information with null sessions (NT), “net” commands, nltest utility.
- For UNIX systems, gather RPC information.
- Exploitation—Identify and exploit the vulnerabilities:
- Buffer overflows
- Brute force
- Password cracking
- Vulnerability chaining
- Data access
Operating and Maintaining Monitoring Systems
Continuous monitoring represents the desire to have real-time risk information available at any time to make organizational decisions. Continuous monitoring systems are comprised of sensor networks, input from assessments, logging, and risk management. When implemented correctly, continuous monitoring systems can provide organizations with a sense of information security risk; when not configured correctly, they can lead an organization to false panic or a false sense of security.
Security Monitoring Concepts
The security practitioner should assume that all systems are susceptible to attack and at some point will be attacked. This mindset helps prepare for inevitable system compromises. Comprehensive policies and procedures and their effective use are excellent mitigation techniques for stemming the effectiveness of attacks. Security monitoring is a mitigation activity used to protect systems, identify network patterns, and identify potential attacks.
Monitoring Terminology
Monitoring terminology can seem arcane and confusing. The purpose of this list is to define by example and reinforce terminology commonly used when discussing monitoring technology.
- Safeguard—A built-in proactive security control implemented to provide protection against threats.
- Countermeasure—An added-on reactive security controls
- Vulnerability—A system weakness.
- Exploit—A particular attack. It is named this way because these attacks exploit system vulnerabilities.
- Signature—A string of characters or activities found within processes or data communications that describes a known system attack. Some monitoring systems identify attacks by means of a signature.
- False Positive—Monitoring triggered an event, but nothing was actually wrong, and in doing so, the monitoring has incorrectly identified benign communications as a danger.
- False Negative—The monitoring system missed reporting an exploit event by not firing an alarm. This is bad.
- True Positive—The monitoring system recognized an exploit event correctly.
- True Negative—The monitoring system has not recognized benign traffic as cause for concern. In other words, it does nothing when nothing needs to be done. This is good.
- Tuning—Customizing a monitoring system to your environment.
- Promiscuous Interface—A network interface that collects and processes all of the packets sent to it regardless of the destination MAC address.
IDS and IDPS
What is an IDS and an IDPS and how do they differ? IDS stands for intrusion detection system. It is a passive system that detects security events but has limited ability to intervene on the event. Intrusion prevention is the process of performing intrusion detection and attempting to stop detected possible incidents. Intrusion detection and prevention systems (IDPS) are primarily focused on identifying possible incidents, logging information about them, attempting to stop them, and reporting them to security administrators.4
There are two types of IDS/IDPS devices. Network-based IDS or NIDS generally connect to one or more network segments. It monitors and interprets traffic and identifies security events by anomaly detection or based on the signature of the event. Host-based IDS, or HIDS, usually reside as a software agent on the host. Most of the newer NIDS are IDPS devices and not IDS. Active HIDS can do a variety of activities to protect the host from intercepting system calls and examining them for validity to stopping application access to key system files or parameters. Active HIDS would be considered an IDP. Passive HIDS (IDS) take a snapshot of the file system in a known clean state and then compare that against the current file system on a regular basis. They can then flag alerts based on file changes.
Where Should HIDS and NIDS Be Deployed?
Business data flow diagrams and data classification policies are a good starting point. HIDS and NIDS need to be deployed where they can best protect critical organizational assets. Of course, in a perfect world with unlimited budget, all devices would be protected by HIDS and NIDS, but most IT security staff has to deal with limited personnel and limited budget. Protect critical assets first and protect the most possible with the fewest devices. A good starting point would be to place HIDS on all systems that contain financial data, HR data, PII, research, and any other data for which protection is mandated. NIDS should be placed on all ingress points into your network and on segments separating critical servers from the rest of the network. There used to be some debate among security practitioners as to whether NIDS should be placed outside your firewall to identify all attacks against your network or inside your firewall to only identify those that made it past your firewall rules. The general practice now appears to be to not worry if it is raining outside; only worry about what is dripping in your living room. In other words, keep the NIDS inside the firewall.
Both HIDS and NIDS are notoriously noisy out of the box and should be tuned for specific environments. They also need to be configured to notify the responsible people via the approved method if they identify a potential incident. These, like the alerts themselves, must be configured properly to ensure that when something really does happen, the designated people know to take action. For the most part, low-priority events can send alerts via email, while high-priority events should page or call the security personnel on call.
Implementation Issues for Monitoring
The security practitioner should remember the security tenets confidentiality, integrity, and availability. IDS can alert to these conditions by matching known conditions (signatures) with unknown but suspect conditions (anomalies).
- Confidentiality—Unauthorized access may breach confidentiality.
- Integrity—Corruption due to an attack destabilizes integrity.
- Availability—Denial of service keeps data from being available.
The security practitioner must make decisions concerning the deployment of monitoring systems. What types to deploy and where to deploy are functions of budget and system criticality. Implementation of monitoring should be supported by policy and justified by the risk assessment. The actual deployment of the sensors will depend on the value of the assets.
Monitoring control deployment considerations should include:
- Choose one or more monitoring technique types—HIDS, NIDS, or logging.
- Choose an analysis paradigm—statistical anomaly or signature.
- Choose a system that meets timeliness objectives—real-time or scheduled (non–real-time).
- Choose a reporting mechanism for incident response—push or pull; that is, does a management system query the monitoring devices for data or does the device push the data to a repository where it is stored or analyzed?
- Make the update mechanisms part of policy with well-defined procedures, especially for signature-based devices.
- Tune monitoring systems to reflect the environment they support.
- Choose automatic response mechanisms wisely.
- Maintenance and tuning—For the long-term use and effectiveness of the monitoring controls, systems should be cared for like any other mission critical component.
- Keep IDS signatures (if applicable) current—Signature-based IDS must be kept up to date as previously unknown vulnerabilities are revealed. Take, for example, the ineffectiveness of a host antivirus system with virus signatures that are a year old. Since several new viruses emerge each week, a system with old signatures may be effective for the old exploits, but the system is defenseless for new viruses. IDS systems operate on the same principle. IDS vendors often have notification systems to alert you about new signature definitions or the capability for automatic update.
- Keep IDS subsystems current—As new generations of IDS subsystems (the operating systems and software engines that drive the system) become available, consider testing then deploying these to know if they add to your capability to detect exploits, but do not introduce instability.
- Tune IDS—NIDS systems have limitations on how much processing they can handle; therefore, limit what the NIDS must monitor based on your environment. For example, if you do not have any Windows-based hosts, consider disabling monitoring for Windows-based exploits. Conversely, if you have a UNIX environment and UNIX-based signatures are not enabled, you will likely miss these events.
As system changes are made, the security systems that protect them should be considered. During the change control process, new changes should factor in how the security systems will handle them. Some sample questions that the security practitioner should consider are as follows:
- Will the host configuration change require a reconfiguration of the HIDS component?
- Will the addition of a database application of a host require the HIDS agent to be configured to screen database transactions for validity?
- Will the network change require alterations to the way the NIDS collects data?
- Will the new services offered on a host require the NIDS to be tuned to have the appropriate active or passive responses to exploits that target those new services?
- Will the DMZ to management network firewall rules need to be changed to accommodate the logging stream from the new web server placed on the DMZ?
Collecting Data for Incident Response
Organizations must have a policy and plan for dealing with events as they occur and the corresponding forensics of incidents.
The security practitioner should consider asking the following questions:
- How does the organization plan to collect event and forensic information from the IDS/IPS?—Organizations cannot expect IDS/IPS to be a “set it and forget it” technology. Human interaction is required to interpret events and high-level responses. IDS can organize events by priority and can even be set to react in a certain way to an observed event, but humans will periodically need to decide if the IDS is doing its job properly.
- How will the organization have the IDS/IPS respond to events?—Depending on the IDS/IPS capabilities, the organization will need to decide how it wants the IPS to react to an observed event. The next section discusses active versus passive IDS response.
- How will the organization respond to incidents?—What investigative actions will the security staff take based on singular or repeated incidents involving one or more observed events? This is a function of your security policy.
When organizations suffer attacks, logging information, whether generated by a host, network device, IDS/IPS, or other device, may be at some point considered evidence by law enforcement personnel. Preserving a chain of custody for law enforcement is important so as not to taint the evidence for use in criminal proceedings.
Monitoring Response Techniques
If unauthorized activity is detected, IDS/IPS systems can take one or both of the following actions:
- Passive Response—Notes the event at various levels but does not take any type of evasive action. The response is by definition passive because the event is merely noted.
- Active Response—Notes the event and performs a reaction to protect systems from further exploitation.
The following is a list of examples of passive IDS/IPS response:
- Logging the event to a log file.
- Displaying an alert on the console of an event viewer or security information management system.
- Logging the details of a packet flow that was identified to be associated with an unauthorized event for a specified period of time, for the purpose of subsequent forensic analysis.
- Sending an alert page, text message, or email to an administrator.
The following is a list of examples of active IPS response:
- In the case of an unauthorized TCP data flow on a network, initiate a NIDS reset of the connection (with a TCP reset) between an attacker and the host being attacked. This only works with TCP-based attacks because they are connection oriented.
- In the case of any IP data flow (TCP, UDP, ICMP), initiate a NIDS, and instruct a filtering device like a firewall or router to dynamically alter its access control list to preclude further communications with the attacker, either indefinitely or for a specified period.
- In the case of a disallowed system call or application-specific behavior, initiate the HIDS agent to block the transaction.
- With TCP resets, often the IDS will send a TCP packet with the FIN flag set in the TCP header to both the attacker and the attacked host to gracefully reset the connection from both hosts’ perspective. By resetting the attacker, the SSCP practitioner discourages future attacks (if they keep getting resets). By resetting the attacked host, the SSCP practitioner frees up system resources that may have been allocated because of the attack.
- With system calls, if a process that does not normally need to access the web server’s data tries to access the data, the HIDS agent can disallow this access.
Response Pitfalls
Active IDS response pitfalls include:
- Cutting off legitimate traffic due to false positives.
- Self-induced denial of service.
Many monitoring systems provide the means to specify some sort of response if a particular signature fires, although doing so may have unintended consequences.
Entertain the notion that a signature has been written that is too generic in nature. This means that it sometimes fires because of exploit traffic and is a true positive but sometimes fires because of innocent traffic and is a false positive. If the signature is configured to send TCP resets to an offending address and does so in a false-positive situation, the IDS may be cutting off legitimate traffic.
Self-induced denial of service can also be a problem with active response systems. If an attacker decided to spoof the IP address of a business partner and sends attacks with the partner’s IP address and the organization's IDS reacted by dynamically modifying the edge router configuration, it would cut off communications with the business partner.
Take note that active response mechanisms should be used carefully and be limited to the types of actions listed above. Some organizations take it upon themselves to implement systems that actively counter attack systems they believe have attacked them as a response. This is highly discouraged and may result in legal issues for the organization. It is irresponsible to counter attack any system for any reason.
Attackers
Attackers are threats generally thought of as persons who perform overt and covert intrusions or attacks on systems, which are often motivated a combination of motive, means, and opportunity. Motivations typically fall into one of the following types:
- Notoriety, Ego, or Sport—Exemplifies the attacker’s “power” to his or her audience, whether to just a few people or to the world. To the attacker, the inherent challenge is “I want to see if I can do it and I want everyone to know about it.”
- Greed and Profit—The attacker is attempting personal financial gain or financial gain of a client; that is, an attacker might have been hired by a business to furtively damage a competitor’s system or gain unauthorized access to the competitor’s data. An attacker may use or resell information found on systems, such as credit card numbers.
- Political Agenda—Attacking a political nemesis physically or electronically is seen as a way to further one’s own agenda or ideals or call attention to a cause.
- Revenge—The overriding motivation behind revenge in the attacker’s eyes is “I’ve been wronged, and I am going to get you back.” Revenge is often exacted by former employees or those who were at one point in time trusted by the organization that is now being attacked.
- Curiosity—They do not really want to do any damage. They just want to see how it works.
There is one category of “attacker” that is often overlooked by security professionals, and while it may seem unfair to some to lump them in with attackers, organizations avoid them at their peril. These are the individuals within an organization who either through ignorance, ego, or stress causes unintended intrusions to occur. They could be the IT system administrator that finds it easier to grant everyone administrative rights to a server rather than take the time to define access controls correctly, or they could be the administrative assistant who uses someone else’s login to get into the HR system just because it was already logged in. These individuals can cause as much damage to a company as someone who is trying to attack it, and the incidents they create need to be addressed like any other intrusion incident.
Intrusions
Intrusions are acts by persons, organizations, or systems that violate the security framework of the recipient. In some instances, it is easier to identify an intrusion as a violation. For example, you have a policy that prohibits users from using computing resources while logged in as someone else. While in the true sense of the definition, the event is an intrusion, it is more acceptable to refer to the event as a violation. Intrusions are considered attacks but are not just limited to computing systems. If something is classified as an intrusion, it will fall into one of following two categories:
- Intrusions can be overt and are generally noticeable immediately. Examples of overt intrusion include the following:
- Someone breaking into your building and stealing computing hardware
- Two people robbing a bank
- Someone stealing copper wiring out of the electrical closet
- Flooding an e-commerce site with too much data from too many sources, thereby rendering the site useless for legitimate customers
- Attackers defacing a website
- Intrusions can be covert and not always noticeable right away, if at all. These, by their nature, are the most difficult to identify. Examples of covert intrusions include the following:
- A waiter stealing a credit card number after the customer has paid his or her bill and using it on the Web that evening
- An accounting department employee manipulating financial accounts for illegal and unauthorized personal financial gain
- An authorized user who improperly obtains system administrator login credentials to access private company records to which he is not authorized
- An attacker who poses as an authorized computer support representative to gain the trust of an unknowing user, to obtain information for use in a computer attack
- A hacker who gets hired as IT staff so he can gain access to organizational systems
Events
An event is a single occurrence that may or may not indicate an intrusion. All intrusions contain events, but not all events are intrusions. For example, a user account is locked for bad password attempts. That is a security event. If it was just the user forgetting what she changed her password to last Friday, it is not an intrusion; however, if the user claims that they did not try to log in before their account was locked, it might be an intrusion.
Types of Monitoring
There are two basic classes of monitoring devices: real-time and non–real-time.
- Real-Time Monitoring—Real-time monitoring devices provide a means for immediately identifying and sometimes stopping (depending on the type of system used) overt and covert events. They include some types of network and host intrusion detection systems. These systems keep watch on systems and (can) alert administrators as unauthorized activity is happening. They can also log events for subsequent analysis if needed. A real-time monitor for computers is like the burglar alarm for your home. When someone breaks in, it sounds the alarm.
- Non–Real-Time Monitoring—Non–real-time monitoring systems provide a means for saving important information about system events and possibly monitoring the integrity of system configurations after the fact. These technologies include application logging, system logging, and integrity monitoring. Logging and integrity systems might tell you that a burglar was at your home, but he is likely gone by the time you find out. This does not mean that non–real-time systems are not as good as real-time systems. Each fulfills a different niche in monitoring. These system logs would be more like the footprints or fingerprints a burglar would leave behind.
Monitoring should be designed to positively identify actual attacks (true positive) but not identify regular communications as a threat (false positive), or do everything possible to increase the identification of actual attacks and decrease the false-positive notifications.
Monitoring event information can provide considerable insight about possible attacks perpetrated within your network. This information can help organizations make necessary modifications to security policies and the supporting safeguards and countermeasures for improved protection.
Monitoring technology needs to be “tuned,” which is the process of customizing the default configuration to the unique needs of your systems. To tune out alarms that are harmless (false positives), the organization must know what types of data traffic are considered acceptable. If security framework, data classification documentation, and business flow documentation exist, the organization should have a good idea of what information should be on its network and how it should be moving between devices.
Deploying monitoring systems is one part of a multilayer security strategy comprised of several types of security controls. By itself, it will not prevent intrusions or give an organization all the information it needs to analyze an intrusion.
File Integrity Checkers
When a system is compromised, an attacker will often alter certain key files to provide continued access and prevent detection. By applying a message digest (cryptographic hash) to key files and then checking the files periodically to ensure the hash has not altered, one can maintain a degree of assurance. On detecting a change, an alert will be triggered. Furthermore, following an attack, the same files can have their integrity checked to assess the extent of the compromise.
Some examples include:
- Cimtrak—http://www.cimcor.com/products
- Advanced Intrusion Detection Environment (AIDE)—http://sourceforge.net/projects/aide/
- Verisys—http://www.ionx.co.uk/
Continuous/Compliance Monitoring
Monitoring is the ongoing, near-time analysis of traditional and non-traditional data sources, related to targeted business activities and controls, to proactively identify, trend, and respond to potential compliance signals and to be predictive of user behavior. Monitoring is considered distinct from auditing, which is typically retrospective and often limited by time, frequency, and scope. Monitoring results inform corrective action plans, including full-scale compliance investigations, policy changes, enhanced training and communications, additional monitoring, focused audits, and other programmatic responses.
Continuous monitoring represents the desire to have real-time risk information available at any time to make organizational decisions. Continuous monitoring systems are comprised of sensor networks, input from assessments, logging, and risk management. When implemented correctly, continuous monitoring systems can provide organizations with a sense of information security risk; when not configured correctly, they can lead an organization to false panic or a false sense of security.
Log Files
Log files can be cumbersome and unwieldy. They can also contain critical information within them that can document compliance with an organization's security framework. Your security framework should have the policies and procedures to cover log files; namely, they need to spell out:
- What devices and hosts might contain critical log data
- What information gets logged
- Where and how the log files are going to be stored
- Retention schedule for log files
- What security measures are going to be employed to ensure the integrity of the log files in storage and in transit
- Who has access to modify or delete log files
Reviewing Host Logs
Auditors are going to want to review host logs as part of the audit process. Security practitioners regularly review host log files as part of the organization’s security program. As part of the organization’s log processes, guidelines must be established for log retention and followed. If the organizational policy states to retain standard log files for only six months, that is all the organization should have. During normal log reviews, it is acceptable to use live log files as long as the review does not disrupt the normal logging process.
Reviewing Incident Logs
Any time an incident occurs, the security practitioner should save the log files of all devices that have been affected or are along the network path the intruder took. These files need to be saved differently than your standard log retention policy. Since it is possible that these log files might be used in a court case against the intruder, the security practitioner must follow sound forensic chain of custody principles when obtaining and preserving the logs.
- Document who saved the files, where they were saved, and who has access to them.
- The data retention rules might change for potential legal evidence, so ensure the organization’s legal department has determined how long to retain incident logs.
- During an audit, auditors might want to review these files both to check on the organization’s incident response policy and to identify any trends in the intrusions.
Log Anomalies
Identifying log anomalies is often the first step in identifying security-related issues both during an audit and during routine monitoring. What constitutes an anomaly? A log anomaly is anything out of the ordinary. Some will be glaringly obvious, for example, gaps in date/time stamps or account lockouts. Others will be harder to detect, such as someone trying to write data to a protected directory. While it would seem logging everything so that you would not miss any important data is the best approach, most would soon drown under the amount of data collected.
Log Management
Log files can grow beyond the organization’s means to gather meaningful data from them if they are not managed properly. How can the organization ensure they are getting the data needed without overburdening the organization’s resources with excessive log events? The first thing to remember is start with the organization’s most critical resources. Then be selective in the amount of data received from each host. Finally, get the data somewhere easily accessible for analysis.
Clipping Levels
Clipping levels are a predefined criteria or threshold that sets off an event entry. For example, a security operations center does not want to be notified on every failed login attempt because everyone mistypes their password occasionally. Thus, set the clipping level to only create a log entry after two failed password attempts. Clipping levels usually have a time property associated with them. For the logging process to not have to keep track of every single failed password attempt in the off chance that the next time that account is logged in the password is mistyped, set the time limit to a reasonable amount of time; for example, 30 minutes. Now the system only has to keep track of an invalid login attempt on a particular account for 30 minutes. If another invalid attempt does not come in on that account, the system can disregard the first one. Clipping levels are great for reducing the amount of data accumulating in log files. Care must be taken to ensure important data is not skipped, and like everything else, the clipping levels need to be documented and protected because an attacker would gain an advantage knowing them.
Filtering
Log filtering usually takes place after the log files have been written. Clipping reduces the amount of data in the log; filtering reduces the amount of data viewed. Filters come in extremely handy when trying to isolate a particular host, user account, or event type. For example, you could filter a log file to only look at invalid login attempts or for all entries within a certain time window. Care must be taken when filtering so that you do not filter out too much information and miss what you are looking for.
Log Consolidation
Log consolidation gives one-stop shopping for log file analysis. Log file consolidation is usually done on a separate server from the one that actually generates the log files. These servers are called security information and event management (SIEM) systems. Most systems have the ability to forward log messages to another server. Thus, the entry not only appears in the log file of the server but it also appears in the consolidated log on the SIEM. Log consolidation is extremely useful when you are trying to track a user or event that reaches across multiple servers or devices. Log consolidation is discussed further below in the centralized versus distributed log management section.
Log Retention
Now that all the organization’s systems are being logged, and they are being reviewed for anomalies, how long is the organization required to keep the logs? How should they be storing the logs?
- Automated Log Tools Automation is one of the keys to successful log file management. There are many different tools, both commercial and open source, that can automate different phases of log file retention. Scripts are available on the Internet or can be written in-house, which can automate some of the processes needed in log management. Some key areas an organization might want to research for log file automation tools include:
- Log Consolidation Tools—Tools that automatically copy log entries to a central server.
- Log Retention Tools—Tools that will move old log files to separate folders for backup and purge old data from log files.
- Business and Legal Requirements Business and legal requirements for log retention will vary among economies, countries, and industries. Some businesses will have no requirements for data retention. Others are mandated by the nature of their business or by business partners to comply with certain retention data. For example, the Payment Card Industry (PCI) Data Security Standard requires that businesses retain one year of log data in support of PCI with a minimum of three months’ worth of data available online. Some federal regulations have requirements for data retention as well. If unsure if a business has any requirements for log file retention, check with auditors and the organization's legal team. They should know for sure. So, if a business has no business or legal requirements to retain log data, how long should the organization keep it? The first people asked should be the legal department. Most legal departments have very specific guidelines for data retention, and those guidelines may drive the log retention policy. If legal does not provide guidance on how long to keep logs, try this technique.
- Maintain three months’ worth of logs online. Once the three-month threshold has passed, move the log files off to tape or other backup media. Keep offline backup files for a year; at the end of the year, see how far back the longest time was required to look for data, add three months to that time, document as the organizational standard, and utilize it for the maximum length of time to retain offline log files.
Centralized Logging (Syslog and Log Aggregation)
Logs are a critical part of any system. They provide insight into what a system is doing, as well as what happened. Virtually every process running on a system generates logs in some form or another. Usually these logs are written to files on local disks. When your system grows to multiple hosts, managing the logs and accessing them can get complicated. Searching for a particular error across hundreds of log files on hundreds of servers is difficult without good tools. A common approach to this problem is to set up a centralized logging solution so that multiple logs can be aggregated in a central location.
Syslog
Another option that you probably already have installed is syslog. Most people use rsyslog or syslog-ng, which are two syslog implementations. These daemons allow processes to send log messages to them, and the syslog configuration determines how they are stored. In a centralized logging setup, a central syslog daemon is set up on your network, and the client logging daemons are set up to forward messages to the central daemon.
- Find syslog-ng at—http://www.balabit.com/network-security/syslog-ng
Distributed Log Collectors
All of these have their specific features and differences, but their architectures are fairly similar. They generally consist of logging clients and agents on each specific host. The agents forward logs to a cluster of collectors, which in turn forward the messages to a scalable storage tier. The idea is that the collection tier is horizontally scalable to grow with the increased number of logging hosts and messages. Similarly, the storage tier is also intended to scale horizontally to grow with increased volume. Some examples include:
- Scribe—Scribe is a scalable and reliable log aggregation server used and released by Facebook as open source. Scribe is written in C++ and uses Thrift for the protocol encoding. Since it uses Thrift, virtually any language can work with it. (https://github.com/facebookarchive/scribe)
- Flume—Flume is an Apache project for collecting, aggregating, and moving large amounts of log data. It stores all this data on HDFS. (https://cwiki.apache.org/confluence/display/FLUME/Home%3bjsessionid=611F9B1C12E6CD0ED777FD01A91C77DB)
- logstash—logstash lets you ship, parse, and index logs from any source. It works by defining inputs (files, syslog, etc.), filters (grep, split, multiline, etc.), and outputs (elasticsearch, mongodb, etc.). It also provides a UI for accessing and searching your logs. (http://logstash.net/)
- Chukwa—Chukwa is another Apache project that collects logs onto HDFS. (http://wiki.apache.org/hadoop/Chukwa)
- Graylog2—Graylog2 provides a UI for searching and analyzing logs. Logs are stored in MongoDB and elasticsearch. Graylog2 also provides the GELF logging format to overcome some issues with syslog message: 1024 byte limit and unstructured log messages. If you are logging long stacktraces, you may want to look into GELF. (https://www.graylog2.org/)
- Splunk—Splunk is a commercial product that has been around for several years. It provides a whole host of features for not only collecting logs but also analyzing and viewing them. (http://www.splunk.com/)
Hosted Logging Services
There are also several hosted “logging as a service” providers as well. The benefit of them is that you only need to configure your syslog forwarders or agents, and they manage the collection, storage, and access to the logs. All of the infrastructure that you have to set up and maintain is handled by them, freeing you up to focus on your application. Each service provides a simple setup (usually syslog forwarding based), an API, and a UI to support search and analysis. Some examples include:
- Loggly—https://www.loggly.com/
- Papertrail—https://papertrailapp.com/
- Logentries—https://logentries.com/
Configuring Event Sources (Cisco NetFlow and sFlow)
Both NetFlow and sFlow are used to provide visibility into an organization’s network. Typically, NetFlow and sFlow are used to:
- Analyze network and bandwidth usage by users and applications
- Measure WAN traffic and generate statistics for creating network policies
- Detect unauthorized network usage
- Diagnose and troubleshoot network problems
Cisco NetFlow
According to Cisco, NetFlow is an embedded instrumentation within Cisco IOS Software to characterize network operation. Netflow allows for the collection and monitoring of network traffic, which can then be analyzed to create a picture of the network traffic flow and its volume across the network. The netflow solution is implemented using a netflow collector, which is a centralized server used to gather up netflow Information from monitored systems and then allow for analysis of the data captured.5
sFlow
sFlow, short for “sampled flow,” is an industry standard for packet export at layer 2 of the OSI model. It provides a means for exporting truncated packets, together with interface counters. Maintenance of the protocol is performed by the sFlow.org consortium, the authoritative source of the sFlow protocol specifications.
sFlow is a technology for monitoring traffic in data networks containing switches and routers. It is described in RFC 3176 (https://www.ietf.org/rfc/rfc3176.txt).
The sFlow monitoring system consists of a sFlow Agent (embedded in a switch or router or in a standalone probe) and a central data collector, or sFlow Analyzer. The sFlow Agent uses sampling technology to capture traffic statistics from the device it is monitoring. sFlow Datagrams are used to immediately forward the sampled traffic statistics to an sFlow Analyzer for analysis.
Event Correlation Systems (Security Information and Event Management [SIEM])
SIEM technology is used in many enterprise organizations to provide real-time reporting and long-term analysis of security events. SIEM products evolved from two previously distinct product categories, namely security information management (SIM) and security event management (SEM).
- Security Event Management (SEM)—Analyzes log and event data in real time to provide threat monitoring, event correlation, and incident response. Data can be collected from security and network devices, systems, and applications.
- Security Information Management (SIM)—Collects, analyzes, and reports on log data (primarily from host systems and applications, but also from network and security devices) to support regulatory compliance initiatives, internal threat management, and security policy compliance management.
SIEM combines the essential functions of SIM and SEM products to provide a comprehensive view of the enterprise network using the following functions:
- Log collection of event records from sources throughout the organization provides important forensic tools and helps to address compliance reporting requirements.
- Normalization maps log messages from different systems into a common data model, enabling the organization to connect and analyze related events, even if they are initially logged in different source formats.
- Correlation links logs and events from disparate systems or applications, speeding detection of and reaction to security threats.
- Aggregation reduces the volume of event data by consolidating duplicate event records.
- Reporting presents the correlated, aggregated event data in real-time monitoring and long-term summaries.
The SIEM market is evolving towards integration with business management tools, internal fraud detection, geographical user activity monitoring, content monitoring, and business critical application monitoring. SIEM systems are implemented for compliance reporting, enhanced analytics, forensic discovery, automated risk assessment, and threat mitigation.
Compliance
Compliance with monitoring and reporting regulations is often a significant factor in the decision to deploy a SIEM system. Other policy requirements of a specific organization may also play a role. Examples of regulatory requirements include the Health Insurance Portability and Accountability Act (HIPAA) for healthcare providers in the United States, or the Payment Card Industry’s Data Security Standard (PCI-DSS) for organizations that handle payment card information. A SIEM can help the organization to comply with monitoring mandates and document their compliance to auditors.
Enhanced Network Security and Improved IT/Security Operations
Attacks against network assets are a daily occurrence for many organizations. Attack sources can be inside or outside the organization’s network. As the boundaries of the enterprise network expand, the role of network security infrastructure must expand as well. Typically, security operations staff deploys many security measures, such as firewalls, IDS sensors, IPS appliances, Web and email content protection, and network authentication services. All of these can generate significant amounts of information, which the security operations staff can use to identify threats that could harm network security and operations.
For example, when an employee’s laptop becomes infected by malware, it may discover other systems on the corporate network and then attempt to attack those systems, spreading the infection. Each system under attack can report the malicious activity to the SIEM. The SIEM system can correlate those individual reports into a single alert that identifies the original infected system and its attempted targets. In this case, the SIEM’s ability to collect and correlate logs of failed authentication attempts allows security operations personnel to determine which system is infected so that it can be isolated from the network until the malware is removed. In some cases, it may be possible to use information from a switch or other network access device to automatically disable the network connection until remediation takes place. The SIEM can provide this information in both real-time alerts and historical reports that summarize the security status of the enterprise network over a large data collection, typically on the order of months rather than days. This historical perspective enables the security administrators to establish a baseline for normal network operations, so they can focus their daily effort on any new or abnormal security events.
Full Packet Capture
Full packet capture devices typically sit at the ingress and egress points of an organization’s network. These devices capture every single information packet that flows across the border. These devices are indispensable tools for the security practitioner as they capture the raw packet data, which can be analyzed later should an incident occur. As full packet capture devices capture every packet, they require an organizational network architecture that consolidates traffic to as few points as possible for collection. Many organizations use VPN tunnels and mandatory routing configurations for hosts to ensure all traffic is sent through a full packet capture device.
Full packet capture devices can consume tremendous amounts of storage. As every packet that flows into or out of the organization is captured, the security practitioner must be mindful of the storage capacities needed to maintain a useful packet capture. Knowing a breach occurred three months ago and only having one month of packet capture is not going to be helpful.
Most full capture packet devices also come with the ability to do a packet dump or extract a certain cross-section of the traffic as defined by criteria such as IP, protocol, or time of day. This traffic can then be analyzed using specialized tools or even played in a simulated browser if the traffic is Web traffic. Full packet capture is indispensable in collecting evidence of workplace misconduct and understanding an attack. Often signatures for IDS/IPS systems come from the analysis and understanding of packet dumps from full packet capture systems.
While full packet capture systems are extremely useful, it is important to note what they do not do. Most if not all are not IDS or IPS systems. Additionally, they may not include the native ability to break encrypted transmissions such as SSL and HTTPS communications. Therefore, the security practitioner must understand how full packet capture fits with other information security technologies.
Source Systems
Monitoring of information and system state is one of the most important activities that the security practitioner can engage in to ensure that the infrastructure under their care is optimized and secured in a proactive manner. Monitoring can be focused on many different systems, from applications, to operating systems, to middleware and infrastructure.
Hyperic
According to VMware, VMware’s vRealize Hyperic monitors operating systems, middleware, and applications running in physical, virtual, and cloud environments. Hyperic provides proactive performance management with complete and constant visibility into applications and infrastructure. It produces more than 50,000 performance metrics on more than 75 technologies at every layer of the stack. At startup, Hyperic automatically discovers and adds new servers and VMs to inventory; configures monitoring parameters; and collects performance metrics and events. Hyperic helps reduce operations workload, increases a company's IT management maturity level, and drives improvements in availability and infrastructure health.6
Operations Manager
Microsoft also provides complete management and monitoring capabilities with their System Center Suite of products. Operations Manager, a component of Microsoft System Center 2012/2012 R2, is software that helps the security practitioner monitor services, devices, and operations for many computers from a single console.
Using Operations Manager in the environment makes it easier to monitor multiple computers, devices, services, and applications. The Operations Manager console, shown in Figure 3-7, enables you to check the health, performance, and availability for all monitored objects in the environment and helps you identify and resolve problems.
Figure 3-7 Microsoft System Center Operations Manager Console
Operations Manager will tell you which monitored objects are not healthy, send alerts when problems are identified, and provide information to help you identify the cause of a problem and possible solutions.7
Security Analytics, Metrics, and Trends
Effective network security demands an integrated defense-in-depth approach. The first layer of a defense-in-depth approach is the enforcement of the fundamental elements of network security. These fundamental security elements form a security baseline, creating a strong foundation on which more advanced methods and techniques can subsequently be built.
A security baseline defines a set of basic security objectives that must be met by any given service or system. The objectives are chosen to be pragmatic and complete, and do not impose technical means. Therefore, details on how these security objectives are fulfilled by a particular service/system must be documented in a separate security implementation document. These details depend on the operational environment a service/system is deployed into, and might, thus, creatively use and apply any relevant security measure. Derogations from the baseline are possible and expected, and must be explicitly marked.
Developing and deploying a security baseline can, however, be challenging due to the vast range of features available. For instance, a network security baseline is designed to assist in this endeavor by outlining those key security elements that should be addressed in the first phase of implementing defense-in-depth. The main focus of a network security baseline is to secure the network infrastructure itself: the control and management planes. The network security baseline presents the fundamental network security elements that are key to developing a strong network security baseline. The focus is primarily on securing the network infrastructure itself, as well as critical network services, and addresses the following key areas of baseline security:
- Infrastructure device access
- Routing infrastructure
- Device resiliency and survivability
- Network telemetry
- Network policy enforcement
- Switching infrastructure
Unless these baseline security elements are addressed, additional security technologies and features are typically useless. For example, if a default access account and password are active on a network infrastructure device, it is not necessary to mount a sophisticated attack because attackers can simply log in to the device and perform whatever actions they choose.
The use of metrics and analysis (MA) is a sophisticated practice in security management that takes advantage of data to produce usable, objective information and insights that guide decisions.
Analytics is the discovery and communication of meaningful patterns in data. Especially valuable in areas rich with recorded information, analytics relies on the simultaneous application of statistics, computer programming, and operations research to quantify performance. Risk analytics involves reporting on metrics from various areas that point out which businesses, processes, or systems are most at risk and require immediate attention.
Through MA, a CSO or other security professional can better understand risks and losses, discern trends, and manage performance. Software designed specifically for the security field can make the gathering of security and risk-significant data orderly, convenient, and accurate while holding the data in a format that facilitates analysis. Security and risk-focused incident management software offers both the standardization and consolidation of data. Such software also automates the task of analysis through trending and predictive analysis and the generation of customized statistical reports.
Carnegie Mellon University created the Systems Security Engineering Capability Maturity Model (SSE-CMM), which provides valuable metrics for security practitioners. Security metrics are a quantifiable measurement of actions that organizations take to manage and reduce security risks such as information theft, damage to reputation, financial theft, and business discontinuity. Administrators and other stakeholders use metrics to address concerns such as:
- Determining resources to allocate for security.
- Figuring out which system components to prioritize.
- Deciding how to effectively configure the system.
- Gauging return on investment for security expenditures.
- Identifying how to reduce exposure to risk.8
For example, the use of metrics and analysis at the Massachusetts Port Authority (Massport) to solve the specific problem of security door alarms is illustrative. Massport was able to greatly reduce such alarms through the analysis of alarm metrics. That analysis helped security management determine the cause of each type of alarm and develop solutions to eliminate or reduce them. Analysis of detailed door transaction data, including video, showed the causes of alarms. That understanding led to a variety of corrective actions, including maintenance and user training being implemented.
The security practitioner can use MA not only to identify security problems but also to gauge the effectiveness of the various security measures used to counteract those problems.
Visualization
Data visualization is a general term that describes any effort to help people understand the significance of data by placing it in a visual context. Patterns, trends, and correlations that might go undetected in text-based data can be exposed and recognized easier with data visualization software. Data visualization tools go beyond the standard charts and graphs used in Excel spreadsheets, displaying data in more sophisticated ways such as infographics, dials and gauges, geographic maps, sparklines, heat maps, and detailed bar, pie, and fever charts. The images may include interactive capabilities, enabling users to manipulate them or drill into the data for querying and analysis. Indicators designed to alert users when data has been updated or predefined conditions occur can also be included. Some examples of data visualization tools include:
- Dygraphs (http://dygraphs.com/)—A fast, flexible open source JavaScript charting library that allows users to explore and interpret dense data sets. It's highly customizable, works in all major browsers, and you can even pinch to zoom on mobile and tablet devices.
- ZingChart (http://www.zingchart.com/)—ZingChart is a JavaScript charting library and feature-rich API set that lets you build interactive Flash or HTML5 charts. It offers over 100 chart types to fit your data.
- InstantAtlas (http://www.instantatlas.com/)—Enables you to create highly interactive dynamic and profile reports that combine statistics and map data to create engaging data visualizations.
- Visual.ly (http://create.visual.ly/)—Visual.ly is a combined gallery and infographic generation tool. It offers a simple toolset for building stunning data representations, as well as a platform to share your creations.
Event Data Analysis
According to the NIST Guide to Computer Security Log Management (SP 800-92), a log is a record of the events that occur in a system. The challenge that security practitioners face today is the increasing complexity of the systems that we are asked to manage, and as a result of that complexity, the increasing volumes of information generated by these systems. In order to be able to make sense of the day-to-day, moment-to-moment operation of systems, the security practitioner needs to be able to balance the continuous flow of information being gathered in logs with the ability to monitor and manage. Implementing the following NIST security log management recommendations should assist the security practitioner in facilitating more efficient and effective log management for the organization:
- “A. Organizations should establish policies and procedures for log management.
- To establish and maintain successful log management activities, an organization should develop standard processes for performing log management. As part of the planning process, an organization should define its logging requirements and goals. Based on those, an organization should then develop policies that clearly define mandatory requirements and suggested recommendations for log management activities, including log generation, transmission, storage, analysis, and disposal. An organization should also ensure that related policies and procedures incorporate and support the log management requirements and recommendations. The organization’s management should provide the necessary support for the efforts involving log management planning, policy, and procedures development.
- Requirements and recommendations for logging should be created in conjunction with a detailed analysis of the technology and resources needed to implement and maintain them, their security implications and value, and the regulations and laws to which the organization is subject (e.g., HIPAA, SOX). Generally, organizations should require logging and analyzing the data that is of greatest importance, and they should also have non-mandatory recommendations for which other types and sources of data should be logged and analyzed if time and resources permit. In some cases, organizations choose to have all or nearly all log data generated and stored for at least a short period of time in case it is needed, which favors security considerations over usability and resource usage, and also allows for better decision-making in some cases. When establishing requirements and recommendations, organizations should strive to be flexible since each system is different and will log different amounts of data than other systems.
- The organization’s policies and procedures should also address the preservation of original logs. Many organizations send copies of network traffic logs to centralized devices as well as use tools that analyze and interpret network traffic. In cases where logs may be needed as evidence, organizations may wish to acquire copies of the original log files, the centralized log files, and interpreted log data in case there are any questions regarding the fidelity of the copying and interpretation processes. Retaining logs for evidence may involve the use of different forms of storage and different processes, such as additional restrictions on access to the records.
- B. Organizations should prioritize log management appropriately throughout the organization.
- After an organization defines its requirements and goals for the log management process, it should then prioritize the requirements and goals based on the organization’s perceived reduction of risk and the expected time and resources needed to perform log management functions. An organization should also define roles and responsibilities for log management for key personnel throughout the organization, including establishing log management duties at both the individual system level and the log management infrastructure level.
- C. Organizations should create and maintain a log management infrastructure.
- A log management infrastructure consists of the hardware, software, networks, and media used to generate, transmit, store, analyze, and dispose of log data. Log management infrastructures typically perform several functions that support the analysis and security of log data. After establishing an initial log management policy and identifying roles and responsibilities, an organization should next develop one or more log management infrastructures that effectively support the policy and roles. Organizations should consider implementing log management infrastructures that include centralized log servers and log data storage. When designing infrastructures, organizations should plan for both the current and future needs of the infrastructures and the individual log sources throughout the organization. Major factors to consider in the design include the volume of log data to be processed, network bandwidth, online and offline data storage, the security requirements for the data, and the time and resources needed for staff to analyze the logs.
- D. Organizations should provide proper support for all staff with log management responsibilities.
- To ensure that log management for individual systems is performed effectively throughout the organization, the administrators of those systems should receive adequate support. This should include disseminating information, providing training, designating points of contact to answer questions, providing specific technical guidance, and making tools and documentation available.
- E. Organizations should establish standard log management operational processes.
- The major log management operational processes typically include configuring log sources, performing log analysis, initiating responses to identified events, and managing long-term storage. Administrators have other responsibilities as well, such as the following:
- Monitoring the logging status of all log sources
- Monitoring log rotation and archival processes
- Checking for upgrades and patches to logging software, and acquiring, testing, and deploying them
- Ensuring that each logging host’s clock is synched to a common time source
- Reconfiguring logging as needed based on policy changes, technology changes, and other factors
- Documenting and reporting anomalies in log settings, configurations, and processes”9
Communication of Findings
Findings are most effectively communicated in reports embracing five key elements:
- Solid substance
- Sound logic
- Balanced tone
- Visual clarity
- Good mechanics
Going Hands-on—Risk Identification Exercise
This exercise will take the reader through the process of performing a basic vulnerability scan against a known vulnerable system using freely available tools. As part of risk identification, the security practitioner should be versed in using vulnerability detection and scanning tools. This exercise assumes the security practitioner has experience with virtual environments and basic networking.
Virtual Testing Environment
The security practitioner should never conduct testing on any system without authorization and without assurance they will not cause damage or undesired impacts. Therefore the security professional should be familiar with the operation of virtual test environments.
Setting Up VirtualBox
This exercise relies on virtual machines. VirtualBox will be the virtual environment used throughout this exercise. VirtualBox is freely available on the Internet at https://www.virtualbox.org/wiki/Downloads.
To install VirtualBox on a chosen system, ensure the downloaded software matches the target system’s specifications and follow the directions for the specific platform found at https://www.virtualbox.org/manual/ch01.html#intro-installing.
Once VirtualBox is installed, two virtual machines will be downloaded for this exercise. The first is Kali Linux. Kali Linux is a staple in the security practitioner’s toolkit and comes preloaded with numerous vulnerability scanning and exploitation tools.
Downloading Kali and Metasploitable
Download the Kali Virtual (i486) machine from http://www.offensive-security.com/kali-linux-vmware-arm-image-download/.
The root password for the images is toor.
Next, download the Metasploitable virtual machine available at https://information.rapid7.com/metasploitable-download.html?LS=1631875&CS=web.
The provider does request some marketing information.
default login/password is: msfadmin:msfadmin
Alternatively, to create a new Metasploitable VM, download the image from here and build: http://sourceforge.net/projects/metasploitable/files/Metasploitable2/
Both virtual machines will need to be unpacked since they have both been zipped. One of the files is packed using 7zip. 7zip can unzip both files and can be downloaded from http://www.7-zip.org/.
Creating the Environment
The goal in creating the virtual environment is to ensure all malicious activity is contained within the virtual environment. When one is creating this environment, it is vitally important the networks for all virtual machines be configured for a private subnet using the “host-only” option found in the network settings of the VirtualBox settings for each virtual machine. Next, the downloaded virtual machines need to be loaded.
Metasploitable Configuration
Follow these steps to configure Metasploitable:
- In VirtualBox, choose Machine then New.
- Choose Linux, Debian, and name the machine Metasploitable, as shown in Figure 3-8.

Figure 3-8: Setting up a new machine in VirtualBox
- Choose at least 2G of memory, as shown in Figure 3-9.

Figure 3-9 Selecting memory size for the new virtual machine
- Choose to use an existing hard drive and navigate to the downloaded and unpacked Metasploitable folder. Choose the
Metasploitable.vmdk file, as shown in Figure 3-10. - Choose Create and the VM will be created.
- Next, click on the Settings button to open the Metasploitable settings. Ensure under System, Processor the option for Enable PAE/NX is checked, as shown in Figure 3-11.

Figure 3-10 Setting up a hard drive on the new virtual machine
Figure 3-11 Verifying that PAE/NX (Physical Address Extension and Processor Bit) is enabled
- Now, click on Network and choose Host Only, as shown in Figure 3-12.
Figure 3-12: Enabling the network adapter
- Next, click OK and this will complete the configuration of the Metasploitable machine.
Kali Linux Configuration
Follow these steps to configure Kali Linux:
- Start VirtualBox and choose Machine and then New, as shown in Figure 3-13.
- Name the machine Kali and choose Linux and Debian (32bit), as shown in Figure 3-14.
Figure 3-13: Creating a new virtual machine in Kali Linux

Figure 3-14: Naming the new virtual machine in Kali Linux
- Next, set at least 4 gigs of memory, as shown in Figure 3-15.

Figure 3-15: Selecting memory size (Kali Linux)
- Next, choose the virtual hard drive from the unpacked Kali virtual machine files, as shown in Figure 3-16.
- Click Create and the Kali VM should be created.
- Next, click on Network and ensure Host-only is chosen for the adapter, as is shown in Figure 3-17.
- Click on OK to complete the configuration of the Kali virtual machine.
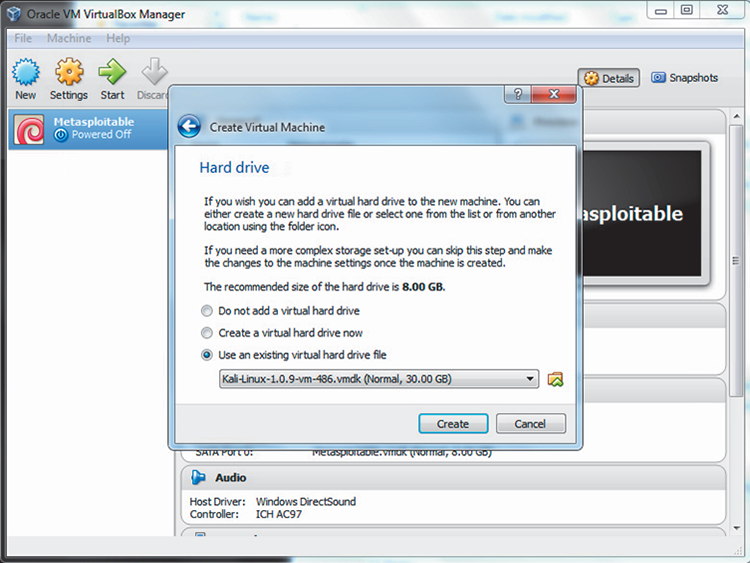
Figure 3-16: Setting up a hard drive (Kali Linux)

Figure 3-17: Enabling network adapter (Kali Linux)
Setting Up the Virtual Environment
Now that both virtual machines are created, they both need to be started.
- To start them, simply click on the desired virtual machine and then click on the green start arrow on the top of the screen. Start both the Kali and the Metasploitable virtual machines. A new window will open for each of the virtual machines.
- The IP addresses for each of the systems will be necessary for this exercise. First, log in to the Metasploitable virtual machine using the username and password combination of
msfadmin/msfadmin - Next, type ifconfig to get the IP address of the virtual machine. See Figure 3-18.

Figure 3-18: Discovering the target IP address
The IP address may be different than noted in Figure 3-18. Take note of the IP address listed. This is the target’s IP address.
Launching a Scan
Follow these steps to launch a scan:
- Go to the Kali virtual machine.
- Log in using
rootas the username andtooras the password. - Once in, start Zenmap by clicking on the following menus and submenus: Applications > Kali Linux > Information Gathering > Network Scanners > Zenmap. See Figure 3-19.

Figure 3-19 Starting Zenmap to launch a scan
- Zenmap will start. Zenmap is a graphical tool used to perform basic network scanning, system scanning, detection of open ports, open services, and possible vulnerabilities.
- Once started, type the IP address of the target identified above into the Target section of the Zenmap. See Figure 3-20.
Note that Zenmap automatically generates the command that a user would type should they decide to launch the scan from a terminal. Select Intense Scan from the profile drop down menu. The types of scans and their meanings can be found at http://www.securesolutions.no/zenmap-preset-scans/.
The intense scan selected scans the most common TCP ports and makes an attempt to identify the operating system and services of the target.

Figure 3-20: Auto-generated command in Zenmap
Reviewing the Results
Once the scan is complete, review Nmap Output and note that the scan discovered the following open ports:
- Scanning 192.168.56.101 [1000 ports]
- Discovered open port 3306/tcp on 192.168.56.101
- Discovered open port 23/tcp on 192.168.56.101
- Discovered open port 25/tcp on 192.168.56.101
- Discovered open port 80/tcp on 192.168.56.101
- Discovered open port 53/tcp on 192.168.56.101
- Discovered open port 5900/tcp on 192.168.56.101
- Discovered open port 445/tcp on 192.168.56.101
- Discovered open port 22/tcp on 192.168.56.101
- Discovered open port 139/tcp on 192.168.56.101
- Discovered open port 111/tcp on 192.168.56.101
- Discovered open port 21/tcp on 192.168.56.101
- Discovered open port 6000/tcp on 192.168.56.101
- Discovered open port 8009/tcp on 192.168.56.101
- Discovered open port 8180/tcp on 192.168.56.101
- Discovered open port 6667/tcp on 192.168.56.101
- Discovered open port 1524/tcp on 192.168.56.101
- Discovered open port 5432/tcp on 192.168.56.101
- Discovered open port 1099/tcp on 192.168.56.101
- Discovered open port 514/tcp on 192.168.56.101
- Discovered open port 2121/tcp on 192.168.56.101
- Discovered open port 512/tcp on 192.168.56.101
- Discovered open port 513/tcp on 192.168.56.101
- Discovered open port 2049/tcp on 192.168.56.101
Just because a port is listed as open doesn’t mean it is vulnerable. The next step is to determine what services may be available on each port. Scrolling down further through the results will yield information about services and basic information about vulnerable configurations. See Figure 3-21.

Figure 3-21 Ports recognized by Zenscan
Notice how Zenmap located services on port 21 and identified them as FTP services. Zenmap then attempted to log in with an anonymous account and was able to do so. Zenmap also identified the bind version the target is running as 9.4.2. There are also others, but for the sake of this exercise, the FTP and the BIND services are of interest.
Vulnerability to Risk
Having a vulnerability on the system does not equate to risk. If there is no actual sensitive information on the system and the system is in test, there is no risk because there is no risk when losing the information. For the sake of this exercise, assume the target system has sensitive information on it and is vital to the organization.
Risk must always be determined through the dimensions of impact, vulnerability, and threat. The scanner has provided vulnerability information. The last step is to determine the threat information. Threat information is sourced from a variety of services and systems. For the sake of this exercise, assume there is a highly motivated and capable threat.
The question the security professional must answer is “How would a threat exploit the vulnerabilities I’ve discovered to impact the organization?” In this scenario, the anonymous FTP access could allow access to sensitive information on the server if not properly secured and logically separated from the FTP server. Additionally, when researching the BIND service, the security professional discovers CVE-2014-3859 (http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2014-3859), which states this version of BIND used may be vulnerable to denial-of-service attacks. This information is combined with organizational risk information to determine the best mitigation approach.
Further Exercises
The virtual setup provided here can be used for numerous tests of attacking a vulnerable system. Several tutorials are available online for additional research and training.
Summary
An information security practitioner must have a thorough understanding of fundamental risk, response, and recovery concepts. By understanding each of these concepts, the security practitioner will have the knowledge required to protect the security practitioner’s organization and professionally execute the security practitioner’s job responsibilities.
Sample Questions
- Which of the following terms refers to a function of the likelihood of a given threat source exercising a potential vulnerability, and the resulting impact of that adverse event on the organization?
- Threat
- Risk
- Vulnerability
- Asset
- The process of an authorized user analyzing system security by attempting to exploit vulnerabilities to gain access to systems and data is referred to as:
- Vulnerability assessment
- Intrusion detection
- Risk management
- Penetration testing
- The process for assigning a dollar value to anticipated losses resulting from a threat source successfully exploiting a vulnerability is known as:
- Qualitative risk analysis
- Risk mitigation
- Quantitative risk analysis
- Business impact analysis
- When initially responding to an incident, it is critical for the SSCP to:
- Notify executive management.
- Restore affected data from backup.
- Follow organizational incident response procedures.
- Share information related to the incident with everyone in the organization.
- Which of the following are threat sources to information technology systems? (Choose all that apply.)
- Natural threats
- Human threats
- Environmental threats
- Software bugs
- The expected monetary loss to an organization from a threat to an asset is referred to as:
- Single loss expectancy
- Asset value
- Annualized rate of occurrence
- Exposure factor
- Which risk-mitigation strategy would be appropriate if an organization decided to implement additional controls to decrease organizational risk?
- Risk avoidance
- Risk reduction
- Risk transference
- Risk acceptance
- During which phase of the risk assessment process is technical settings and configuration documented?
- Risk determination
- Results documentation
- System characterization
- Control analysis
- What is the correct order of steps for the NIST risk assessment process?
- Communicate, prepare, conduct, and maintain
- Prepare, conduct, communicate, and maintain
- Conduct, communicate, prepare, and maintain
- Maintain, communicate, prepare, and conduct
- Cross-referencing and stimulus response algorithms are qualities of what associated with what activity?
- Vulnerability testing
- Penetration testing
- Static application security testing
- Dynamic application security testing
- What is the correct order for the phases of penetration testing?
- Information gathering, preparation, information evaluation and risk analysis, active penetration, and analysis and reporting
- b. Preparation, information gathering, active penetration and analysis, information evaluation, and risk analysis and reporting
- Preparation, active penetration and analysis, information gathering, information evaluation, and risk analysis and reporting
- Preparation, information gathering, information evaluation and risk analysis, active penetration, and analysis and reporting
- Where do the details as to how the security objectives of a security baseline are to be fulfilled come from?
- The system security plan
- A security implementation document
- The enterprise system architecture
- Authorization for the system to operate
- Shoulder surfing, Usenet searching and Dumpster diving are examples of what kind of activity?
- Risk analysis
- Social engineering
- Penetration testing
- Vulnerability assessment
- What is the most important reason to analyze event logs from multiple sources?
- They will help you obtain a more complete picture of what is happening on your network and how you go about addressing the problem.
- The log server could have been compromised.
- Because you cannot trust automated scripts to capture everything.
- To prosecute the attacker once he can be traced.
- Security testing includes which of the following activities? (Choose all that apply.)
- Performing a port scan to check for up-and-running services.
- Gathering publicly available information.
- Counterattacking systems determined to be hostile.
- Posing as technical support to gain unauthorized information.
- Why is system fingerprinting part of the security testing process?
- a. It is one of the easiest things to determine when performing a security test.
- It shows what vulnerabilities the system may be subject to.
- It tells an attacker that a system is automatically insecure.
- It shows the auditor whether a system has been hardened.