
Chapter 16
Handling Errors in Haskell
IN THIS CHAPTER
![]() Understanding Haskell bugs
Understanding Haskell bugs
![]() Locating and describing Haskell errors
Locating and describing Haskell errors
![]() Squashing Haskell bugs
Squashing Haskell bugs
Most application code contains errors. It’s a blanket statement that you may doubt, but the wealth of errors is obvious when you consider the number of security breaches and hacks that appear in the trade press, not to mention the odd results that sometimes occur from seemingly correct data analysis. If the code has no bugs, updates will occur less often. This chapter discusses errors from a pure functional language perspective; Chapter 17 looks at the same issue from an impure language perspective, which can differ because impure languages often rely on procedures.
After you identify an error, you can describe the error in detail and use that description to locate the error in the application code. At least, this process is the theory that most people go by when finding errors. Reality is different. Errors commonly hide in plain view because the developer isn’t squinting just the right way in order to see them. Bias, perspective, and lack of understanding all play a role in hiding errors from view. This chapter also describes how to locate and describe errors so that they become easier to deal with.
Knowing the source, location, and complete description of an error doesn’t fix the error. People want applications that provide a desired result based on specific inputs. If your application doesn’t provide this sort of service, people will stop using it. To keep people from discarding your application, you need to correct the error or handle the situation that creates the environment in which the error occurs. The final section of this chapter describes how to squash errors —for most of the time, at least.
Defining a Bug in Haskell
A bug occurs when an application either fails to run or produces an output other than the one expected. An infinite loop is an example of the first bug type, and obtaining a result of 5 when adding 1 and 1 is an example of the second bug type. Some people may try to convince you that other kinds of bugs exist, but these other bugs end up being subsets of the two just mentioned.
 Haskell and other functional languages don’t allow you to write applications that are bug free. Quite the contrary: You can find the same sorts of bugs in Haskell that you can find in other languages, such as Python. Chapter 17 explores some common Python issues and examines the conditions under which bugs occur in that language, but many of those issues also translate into Haskell. Bugs occur at compile time or runtime. In addition, they can be syntactical, semantic, or logical in nature.
Haskell and other functional languages don’t allow you to write applications that are bug free. Quite the contrary: You can find the same sorts of bugs in Haskell that you can find in other languages, such as Python. Chapter 17 explores some common Python issues and examines the conditions under which bugs occur in that language, but many of those issues also translate into Haskell. Bugs occur at compile time or runtime. In addition, they can be syntactical, semantic, or logical in nature.
However, functional languages tend to bring their own assortment of bugs into applications, and knowing what these bugs are is a good idea. They’re not necessarily new bugs, but they occur differently with functional languages. The following sections consider the specifics of bugs that occur with functional languages, using Haskell as an example. These sections provide an overview of the kinds of Haskell-specific bugs that you need to think about, but you can likely find others.
Considering recursion
Functional languages generally avoid mutable variables by using recursion. This difference in focus means that you’re less apt to see logic errors that occur when loops don’t execute the number of times expected or fail to stop because the condition that you expected doesn’t occur. However, it also means that stack-related errors from infinite recursion happen more often.
You may think that loops and recursion produce similar errors. However, unlike a loop, recursion can’t go on indefinitely because the stack uses memory for each call, which means that the application eventually runs out of memory. In fact, memory helps define the difference between functional and other languages that do rely on loops. When a functional language runs out of memory to perform recursion, the problem could simply be that the host machine lacks the required resources, rather than an actual code error.
Understanding laziness
Haskell is a lazy language for the most part, which means that it doesn’t perform actions until it actually needs to perform them. For example, it won’t evaluate an expression until it needs to use the output from that expression. The advantages of using a lazy language include (but aren’t limited to) the following:
- Faster execution speed because an expression doesn’t use processing cycles until needed
- Reduced errors because an error shows up only when the expression is evaluated
- Reduced resource usage because resources are used only when needed
- Enhanced ability to create data structures that other languages can’t support (such as a data structure of infinite size)
- Improved control flow because you can define some objects as abstractions rather than primitives
 However, lazy languages can also create strange bug scenarios. For example, the following code purports to open a file and then read its content:
However, lazy languages can also create strange bug scenarios. For example, the following code purports to open a file and then read its content:
withFile "MyData.txt" ReadMode handle >>= putStr
If you looked at the code from a procedural perspective, you would think that it should work. The problem is that lazy evaluation using withFile means that Haskell closes handle before it reads the data from MyData.txt. The solution to the problem is to perform the task as part of a do, like this:
main = withFile "MyData.txt" ReadMode $ handle -> do
myData <- hGetLine handle
putStrLn myData
However, by the time you create the code like this, it really isn't much different from the example found in the “Reading data” section of Chapter 13. The main advantage is that Haskell automatically closes the file handle for you. Offsetting this advantage is that the example in Chapter 13 is easier to read. Consequently, lazy evaluation can impose certain unexpected restrictions.
Using unsafe functions
Haskell generally provides safe means of performing tasks, as mentioned in several previous chapters. Not only is type safety ensured, but Haskell also checks for issues such as the correct number of inputs and even the correct usage of outputs. However, you may encounter extremely rare circumstances in which you need to perform tasks in an unsafe manner in Haskell, which means using unsafe functions of the sort described at https://wiki.haskell.org/Unsafe_functions. Most of these functions are fully described as part of the System.IO.Unsafe package at http://hackage.haskell.org/package/base-4.11.1.0/docs/System-IO-Unsafe.html. The problem is that these functions are, as described, unsafe and therefore the source of bugs in many cases.
You can find the rare exceptions for using unsafe functions in posts online. For example, you might want to access the functions in the C math library (as accessed through math.h). The discussion at https://stackoverflow.com/questions/10529284/is-there-ever-a-good-reason-to-use-unsafeperformio tells how to perform this task. However, you need to consider whether such access is really needed because Haskell provides such an extensive array of math functions.
The same discussion explores other uses for unsafePerformIO. For example, one of the code samples shows how to create global mutable variables in Haskell, which would seem counterproductive, given the reason you're using Haskell in the first place. Avoiding unsafe functions in the first place is a better idea because you open yourself to hours of debugging, unassisted by Haskell’s built-in functionality (after all, you marked the call as unsafe).
Considering implementation-specific issues
As with most language implementations, you can experience implementation-specific issues with Haskell. This book uses the Glasgow Haskell Compiler (GHC) version 8.2.2, which comes with its own set of incompatibilities as described at http://downloads.haskell.org/~ghc/8.2.2/docs/html/users_guide/bugs.html. Many of these issues will introduce subtle bugs into your code, so you need to be aware of them. When you run your code on other systems using other implementations, you may find that you need to rework the code to bring it into compliance with that implementation, which may not necessarily match the Haskell standard.
Understanding the Haskell-Related Errors
It’s essential to understand that the functional nature of Haskell and its use of expressions modifies how people commonly think about errors. For example, if you type x = 5/0 and press Enter in Python, you see a ZeroDivisionError as output. In fact, you expect to see this sort of error in any procedural language. On the other hand, if you type x = 5/0 in Haskell and press Enter, nothing seems to happen. However, x now has the value of Infinity. The fact that some pieces of code that define an error in a procedural language but may not define an error in a functional language means that you need to be aware of the consequences.
To see the consequences in this case, type :t x and press Enter. You find that the type of x is Fractional, not Float or Double as you might suppose. Actually, you can convert x to either Float or Double by typing y = x::Double or y = x::Float and pressing Enter.
The Fractional type is a superset of both Double and Float, which can lead to some interesting errors that you don't find in other languages. Consider the following code:
x = 5/2
:t x
y = (5/2)::Float
:t y
z = (5/2)::Double
:t z
x * y
:t (x * y)
x * z
:t (x * z)
y * z
The code assigns the same values to three variables, x, y, and z, but of different types: Fractional, Float, and Double. You verify this information using the :t command. The first two multiplications work as expected and produce the type of the subtype, rather than the host, Fractional. However, notice that trying to multiply a Float by a Double, something you could easily do in most procedural languages, doesn't work in Haskell, as shown in Figure 16-1. You can read about the reason for the lack of automatic type conversion in Haskell at https://wiki.haskell.org/Generic_number_type. To make this last multiplication work, you need to convert one of the two variables to Fractional first using code like this: realToFrac(y) * z.
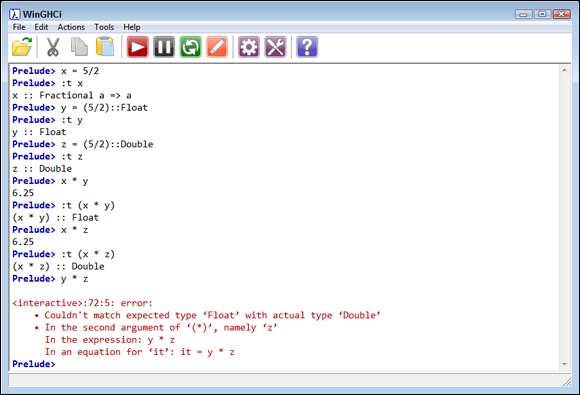
FIGURE 16-1: Automatic number conversion is unavailable in Haskell.
Some odd situations exist in which a Haskell application can enter an infinite loop because it works with expressions rather than relying on procedures. For example, the following code will execute fine in Python:
x = 5/2
x = x + 1
x
In Python, you see an output of 3.5, which is what anyone working with procedural code will expect. However, this same code causes Haskell to enter into an infinite loop because the information is evaluated as an expression, not as a procedure. The output, when working with compiled code, is <<loop>>, which you can read about in more detail at https://stackoverflow.com/questions/21505192/haskell-program-outputs-loop. When using WinGHCi (or another interpreter), the call will simply never return. You need to click the Pause button (which looks like the Pause button on a remote) instead. A message of Interrupted appears to tell you that the code, which will never finish its work, has been interrupted. The fact that Haskell actually detects many simpler infinite loops and tells you about them says a lot about its design.
 Haskell does prevent a wide variety of errors that you see in many other languages. For example, it doesn't have a global state. Therefore, one function can’t use a global variable to corrupt another function. The type system also prevents a broad range of errors that plague other languages, such as trying to stuff too much data into a variable that can’t hold it. You can read a discussion of other sorts of common errors that Haskell prevents at
Haskell does prevent a wide variety of errors that you see in many other languages. For example, it doesn't have a global state. Therefore, one function can’t use a global variable to corrupt another function. The type system also prevents a broad range of errors that plague other languages, such as trying to stuff too much data into a variable that can’t hold it. You can read a discussion of other sorts of common errors that Haskell prevents at https://www.quora.com/Exactly-what-kind-of-bugs-does-Haskell-prevent-from-introducing-compared-to-other-mainstream-languages.
Even though this section isn’t a complete list of all the potential kinds of errors that you see in Haskell, understand that functional languages have many similarities in the potential sources of errors but that the actual kinds of errors can differ.
Fixing Haskell Errors Quickly
Haskell, as you’ve seen in the error messages in this book, is good about providing you with trace information when it does encounter an error. Errors can occur in a number of ways, as described in Chapter 17. Of course, the previous sections have filled you in on Haskell exceptions to the general rules. The following sections give an overview of some of the ways to fix Haskell errors quickly.
Relying on standard debugging
Haskell provides the usual number of debugging tricks, and the IDE you use may provide others. Because of how Haskell works, your first line of defense against bugs is in the form of the messages, such as error and CallStack output, that Haskell provides. Figure 16-1 shows an example of an error output, and Figure 16-2 shows an example of CallStack output. Comparing the two, you can see that they’re quite similar. The point is that you can use this output to trace the origin of a bug in your code.
![Screen capture of WinGHCi window with code sum [1, 2, 3, undefined, 5, 6, 7] with error message output.](http://imgdetail.ebookreading.net/202009/02/9781119527503/9781119527503__functional-programming-for__9781119527503__images__9781119527503-fg1602.png)
FIGURE 16-2: Haskell provides you with reasonably useful messages in most cases.
During the debugging process, you can use the trace function to validate your assumptions. To use trace, you must import Debug.Trace. Figure 16-3 shows a quick example of this function at work.
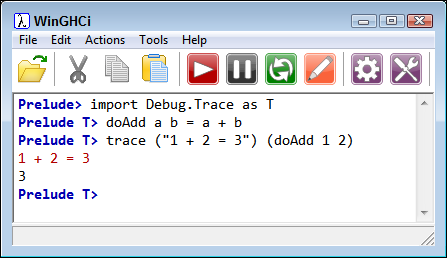
FIGURE 16-3: Use trace to validate your assumptions.
You provide the assumption as a string in the first argument and the function call as the second argument. The article at http://hackage.haskell.org/package/base-4.11.1.0/docs/Debug-Trace.html gives additional details on using trace. Note that with lazy execution, you see trace output only when Haskell actually executes your code. Consequently, in contrast to other development languages, you may not see all your trace statements every time you run the application. A specialized alternative to trace is htrace, which you can read about at http://hackage.haskell.org/package/htrace.
Haskell does provide other debugging functionality. For example, you gain full access to breakpoints. As with other languages, you have methods available for determining the status of variables when your code reaches a breakpoint (assuming that the breakpoint actually occurs with lazy execution). The article at https://wiki.haskell.org/Debugging offers additional details.
Understanding errors versus exceptions
For most programming languages, you can use the terms error and exception almost interchangeably because they both occur for about the same reasons. Some languages purport to provide a different perspective on the two but then fail to support the differences completely. However, Haskell actually does differentiate between the two:
- Error: An error always occurs as the result of a mistake in the code. The error is never expected and you must fix it to make the code run properly. The functions that support errors are
errorassertControl.Exception.catchDebug.Trace.trace
- Exception: An exception is an expected, but unusual, occurrence. In many cases, exceptions reflect conditions outside the application, such as a lack of drive space or an incapability to create a connection. You may not be able to fix an exception but you can sometimes compensate for it. The function that support exceptions are
Prelude.catchControl.Exception.catchControl.Exception.tryIOErrorControl.Monad.Error
As you can see, errors and exceptions fulfill completely different purposes and generally use different functions. The only repeat is Control.Exception.catch, and there are some caveats about using this function for an error versus an exception, as described at https://wiki.haskell.org/Error_vs._Exception. This article also gives you additional details about the precise differences between errors and exceptions.