
9
Offline Handwritten Numeral Recognition Using Convolution Neural Network
Abhisek Sethy1*, Prashanta Kumar Patra1 and Soumya Ranjan Nayak2
1 Department of Computer Science and Engineering, College of Engineering & Technology, BPUT, Odisha, India
2 Amity School of Engineering and Technology, Amity University, Uttar Pradesh, India
Abstract
In this current digital age of world, character recognition (CR) has been done through various machine learning algorithms. And it considered to be one the most challenging segment of pattern recognition. In addition to the above context, offline handwritten character is the most challenging one as compared with the printed one. Despite various algorithms that were harnessed on various handwritten scripts, it can be possible to have more feasibility solution and high recognition rate. Here, in this paper, we have focused on the handwritten numerals of Odia and Bangla scripts. To overcome the ambiguities that arise in handwritten, one has been resolved using the Convolutional Neural Network (CNN). Here we have suggested a state-of-the-art CNN-based approach for recognition of multiple handwritten numerals of both the scripts and clearly shown how effectively it has been used for evaluating the discriminate features from the original image and later leads to report high recognition rate. At the simulation level, we have listed up variance nature of the individual’s images, and through CNN, a high recognition rate is achieved, which is quite helpful in building the automatic recognition system for handwritten numerals to have solution for real-time problems.
Keywords: Character Recognition (CR), Handwritten Character Recognition (HCR), Convolutional Neural Network (CNN)
9.1 Introduction
Handwritten character recognition (HCR) has been one of the active research areas of pattern recognition [1]. Various conventional and latest machine learning approaches have been used in the recognition system. An automatic recognition system is one of the arts of conversion of differently sized character documents into digital formats and which may lead to various aspect of application, such as operation related to banking, postal, and so on. Despite various research being performed for handwritten and printed scripts [2], satisfactory recognition of various handwritten are yet to be reported. Among such scripts, English [3], Chinese [4], Arabic [5], and Japanese [6], and so on. These handwritten characters are considered more challenging compared with the printed one because of their similar orientation, shape, and size. Because of these varieties in writing skill of different individuals, it has added more complex to the structure of handwritten characters, which leads to confusion in proper recognition of characters. In the context of any automatic ideal OCR system, the crucial part is to have well-defined benchmark data sets along with a proper feature extraction procedure. This procedure must identify discriminant features from the characters, symbols, and words. Selection of classifier is another important aspect which has a significant impact on the recognition accuracy. Recognition of handwritten characters is quite challenging as on printed ones because of the following reasons:
- The handwritten characters of various writers were not only not identical but also most of them vary in different aspects, such as size and shape.
- Such a wide range of writing styles of individual character added more complexity in recognition task. In addition, some similarities among the character in shapes, the overlaps, and the interconnections of the neighboring characters further complicate the character recognition problem.
Here, this paper adopts a procedure to establish a recognition system for handwritten Odia and Bengali numerals. Usually, in the recognition system, handwriting recognition usually consists of various stages among the preprocessing, feature extraction, classification, and postprocessing included. Among feature extraction and classifier design, there are two major steps in any recognition system [7]. To have a proper recognition system, we have harnessed the convolutional neural networks (CNN) [8] to the handwritten Odia and Bangla numerals. The main advantage of implementation of CNN-based approach is that it does not require any feature hand-crafted feature vector. It has such architecture that it is capable to create the feature vector from the training sample of handwritten images. It is completely an unsupervised one. It is quite capable of extracting its own feature vector from the trained characters samples, and they had also provided additional advantage to skip the preprocessing of the image and was very much helpful in extracting the feature of handwritten characters of new scripts for which it is possible to collect at least some training samples with ground truth [9]. Usually, some approaches they have assumed may exist in CNN [10] trained data set for character problems, and we have to only forward the new samples to the train CNN one and perform the recognition task. In this paper, we have to perform multilingual script recognition of numerals, such as Odia and Bangla numerals. All simulations were done over benchmark database that were collected from various research institute across the globe. In the next section, we have listed up the literature survey and then proposed a model for recognition of handwritten numerals of both Bengali and Odia numerals [40].
9.2 Related Work Done
In such field of handwritten numerals, recognition of a good number of works has been reported in both printed and offline in the past years by various researcher across various corners of the globe [2, 6]. The Odia and Bangla scripts were generated from the Brahmi script and some part Devanagari script. These scripts are the official language of the state Odisha and West-Bengal and the most ancient regional language of India. Both of these are basically spoken in the eastern zone of India mainly in state Odisha, West-Bengal, Bihar, Gujarat, and so on. Chatterjee et al. [11] and Sinha et al. [12] have initially shown interest in the recognition system of Devanagari scripts. Pal et al. [13] have performed over Odia scripts and suggested a probabilistic approach for recognition system along with the importance of curvature feature of the individuals. And also received 94.6% as the recognition rate through the neural network classifier. Some writer identification was using neural network as was done by Desai [14]. They have listed up 94.6% recognition rate for Gujarati handwritten digits. Some researchers also make an application orient approach, such as Kundu & Chen [15], who have reported the HMM approaches for postal words recognition and they have listed 88.2% recognition accuracy over the data sets. Later on, some gradient-based approach was proposed by Roy et al. [16] and termed them as histogram approach. They have calculated feature vector along four directions, such as horizontal, 45-degree slant, vertical, and 135-degree slanted. In addition, they have shown the significance of neural network and quadratic classifier, and for those, they have achieved 90.38% and 94.81% recognition rate with a rejection of 1.84% and 1.31%, respectively, achieved. Apart for all, some Fourier transformation-based approaches were suggested by Mishra et al. [17]. They had considered the cosine transformation and wavelet transformation over the Odia numerals. Average recognition rates of 92% and 87.50% were noted.
An evolutionary-based approach was depicted by Dash et al. [18]. They had implemented a stock-well-based approach over the handwritten numerals. To validate what they proposed, they had adopted a 10-fold validation, and all simulation analyses were done in zone-based ones and 99.1% recognition rate reported. In following subsequent year again Dash et al. in [19] make an analysis over various transformation-based approaches and listed up their differences, such as Slantlet transform based, Stock-well transform based, and Gabor-wavelet-based transformation. Here, the main focus is on the nonredundant nature of the individuals and this has achieved a very good recognition rate over the handwritten samples. Some researchers mainly focused on the preprocessing steps, like Sethy et al. [20], who suggested Binarization of the individual digits and added some Fourier transformation analysis over the handwritten sets as cosine transformation to the handwritten numerals and successfully reported the desired feature vector. Later, they have reported that 80.2% and 90% recognition rates were achieved.
In addition to such methodologies, some orthogonal-based approach also listed up by Mohapatra et al. [21]. They have shown the variant and in-variant nature of the numerals and a recognition rate of 98.5% was achieved. In next years, some statistical-based feature, like Grey level Co-occurrence Matrix (GLCM), was introduced by Sethy et al. [22]. Here, they have shown decision-based classification through a random forest tree. Once again, Sethy et al. [23] proposed an improved version of histogram analysis, which included the rectangle components as R-HOG. These rectangle histograms were reported in the feature selection part, and dimensional reduction was performed through principal component analysis (PCA) [24] over high-dimensional feature vector. The highest Pc scores were reported as the key feature set, and the remaining work were done by SVM and Quadratic classifiers, respectively. An extreme learning-based approach was reported by Das et al. [25]. In this approach, they maintained a single hidden layer neural network for the recognition of handwritten numerals. Some work also reported on both the Bengali numerals and character by Das and Pramanik [26]. They have reported the significance on convex hull feature of the numerals. Rubby et al. [27] focused on the Bengali handwritten numerals and harnessed the CNN-based approach for recognition. Here, they have taken Ekush and CMATERdb data set and achieved 97.73% and 95.01%, respectively. Once again in the following year, Rubby et al. [28] have suggested a lightweight CNN for recognition of Bangla handwritten characters which consists vowels and consonants. Once again [41], Sethy et al. have also performed some feature reductional concept through PCA and Kernel PCA over various handwritten data sets. They have also shown the significance of radial basis function-based neural network and angular symmetric axis constellation [42, 43] for the recognition system. With regard to pattern recognition analysis, fractal dimension examination plays a prominent role in feature evaluation. This work has described the related factors, such as spatial resolution, region of interests, texture feature, color metric for similar texture, and so on [44–53].
9.3 Data Set Used for Simulation
In this paper, we implemented the recognition system for handwritten Odia and Bangla numerals. All the simulations were carried over with standard databases collected from various research institutes, such as Bangla numerals collected from NIT, Rourkela by Das et al. [25], the numeral database has been collected from IIT, BBSR by Puhan et al. [18] and another Odia numeral database collected from ISI Kolkata by Bhattacharya et al. [35]. In the abovementioned numeral data set, we have collected 10 numerals starting from 0 to 9, which are suggested in Figure 9.1, Figure 9.2, and Figure 9.3, respectively, representing handwritten character data set. In order to have proper setup for the data sets, we have categorized the level from 0 to 9. We have also mentioned a well-defined training and testing ratio of data for implementation of the recognition system as shown in Table 9.1.

Figure 9.1 Sample of handwritten Odia numeral database of IIT, BBSR.

Figure 9.2 Sample of handwritten Bangla numeral database of NIT, Rourkela.

Figure 9.3 Sample of handwritten Odia numeral database of ISI, Kolkata.
Table 9.1 Overall statistic of the handwritten numeral data set.
| Standard database collected | No. of categories of classes | Training count | Testing count | Total |
| Odia Numeral Database of IIT, BBSR | 10 | 4000 | 1000 | 5000 |
| Bangla Numeral Database of NIT, Rourkela. | 10 | 3345 | 1000 | 4345 |
| Odia Numeral Database of ISI, Kolkata. | 10 | 4970 | 1000 | 5970 |
All the handwritten numerals data sets are maintained with proper training and testing ratio so that it will in robust frame of implementation of the handwritten numerals as shown below in Table 9.1. All these handwritten samples were collected from various age groups, starting from 5 to 50 years, and all were presented into database format for research purpose.
9.4 Proposed Model
In any recognition system, it is important to have a well-defined data set and in addition, involved preprocessing criteria to get a less noisy image, leading to a high recognition rate. Meanwhile, CNN [31] is an effective architecture which has its own preprocessing steps and variations among the individuals. In this proposed CNN, an inherent methodology is provided and data for normalized one are given, before that we have made a standard size of 32 × 32 for each image size, which act as the input to the network. Basically, CNN is a widely used visual processing and it provides highest optimized way to process any 2-D image for which it is capable to train on its own and produce the desired feature vector. Moreover, it says the variation listed and it helps generate a connection which is sparse in nature and that has to connect with the weights. In another way, we can also suggest that though it follows a gradient-based approach and will produce a low error [32]. Mainly, this CNN architecture consists of many layers as one output layer acts to input the next layer and is quite helpful to predict the desired output. In addition, there is also some limitations to the network related to the parameters and variants, to over fit such situation, we have trained a single network at first with larger sample space along with various iteration values. Here, in the proposed work, we have taken three different benchmark data set where each have 10 categories that have already been discussed in Table 9.1. In this paper, we have used an architecture similar to the well-known LetNet-5 architecture and trained about 4000 for Odia IITBBSR, 3345 for Bangla numerals, and 4970 for ISI Kolkata numeral data set. We have made a constrain in the fine tuning to report a high recognition rate in this 10-class problem. The architecture explained in the study of LeCun et al. [34] have implemented a bangle numeral database and reported a 95.84% recognition rate through proper training CNN [33], where we have obtained about 87%. There are times that we have to avoid the overtraining issue because the characters deep learning can also be introduced, as suggested by Theano [35]. All these have been done in python library which was proposed in [36, 37]. It is quite helpful in optimizing and evaluating mathematical expressions effectively to multidimensional arrays.
The overall architecture of CNN that we have implemented is explained in Figure 9.4 and Figure 9.5, respectively. As an initial step, we have included various layers, and some feature map was also performed using some kernel functions. In this CNN approach, the first layer is C1 and the convolution layer having six feature maps which is calculated using 5*5 kernels upon input of image of size 32*32. In next two set of convolution along with some sampling done through single hidden layer and at last a perceptron is achieved represented in Figure 9.4(a). Layer C1 depicts 28×28 feature set maps to prevent connections of inputs from falling off the boundary. Layer S2, which is the first subsampling shown in Figure 9.4(b), provides six feature maps each with a size of 14×14, it also supports max pooling using a 2×2 kernel on the output of C1 layer. Net at C3 is the second convolution layer shown in Figure 9.5(a). Here, at this layer, a 12 × 12 feature map is retrieved by overlapping 5× 5 kernels at output layer of S2. Layer S4 is the second subsampling layer shown in Figure 9.5(b) and produces 2×12 feature map each with a size of 5 × 5 and used max pooling over 2×2 kernel on the output of C3 layer. Finally, we have obtained nearly 300 features at layer F5 each with a size of 5*% through 12 kernels shown in Figure 9.5(c), respectively. In a subsequent step, this CNN-based approach is helpful in producing higher levels of feature from each input image data set at layer F5 and used them for training purpose to support vector machine with RBF kernels. To have proper simulation setup, we used scikit-learn [29, 30] toolbox under python environment, and the values of certain parameters C and γ are also done based on grid values respectively.
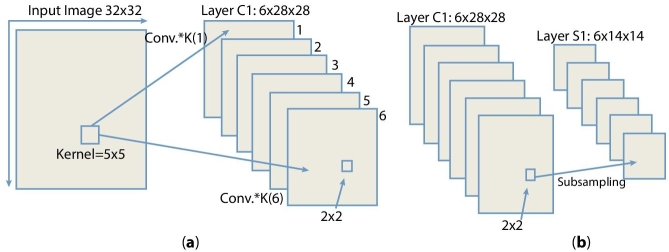
Figure 9.4 (a) Input an image to layer C1, (b) forwarding the value from layer C1 to layer S2.
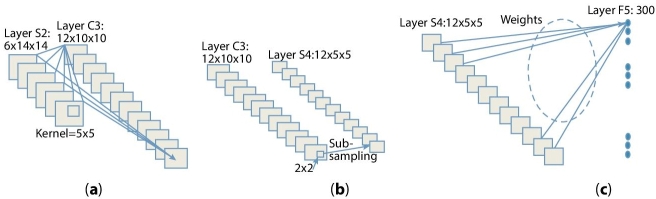
Figure 9.5 (a) Forwarding from layer S2 to layer C3, (b) forwarding from layer C3 to layer S4, (c) forwarding from layer S4 to layer F5.
9.5 Result Analysis
To have a proper implementation of the proposed system, the respective handwritten characters have listed the CNN-based approach over the images and reported the feature vector and introduced some Kernel function. Here, we have included two handwritten numeral data sets of Odia Numerals and one set of Bangla numerals; all these are of 10 classes, containing 5000, 4345, and 5970 overall of sample of data. The recognition accuracies obtained on the respective test sets are comparable with the state-of-the-art recognition accuracies on each of them, and numerals are processed with abovementioned algorithms perfectly. In overall basis, here, we have listed various training and testing accuracies, as shown in Table 9.2. It also shows the loss and recognition rate achieved through various stages of the model. In addition, we have listed up the recognition rate at various numbers of hidden neurons, such as 2000, 3000 up to 11000. By doing such, we are able to note down various changes in the recognition rate as depicted in Figure 9.6, Figure 9.7, and Figure 9.8 below.
Table 9.2 Training and Testing Accuracy over the three data sets.
| Handwritten data set name | Training loss | Val. loss | Training accuracy | Val. accuracy | Test data set | Test accuracy |
| Odia Numeral | 0.012 | .014 | 98.3 | 97.71 | Odia Numeral Database of IIT, BBSR | 98.3 |
| Bangla Numeral | 0.0814 | 0.01120 | 97.37% | 96.81% | Bangla Numeral Database of NIT, Rourkela. | 97.1% |
| Odia Numeral | 0.0138 | 0.01396 | 98.81% | 98.40% | Odia Numeral Database of ISI, Kolkata. | 98.6% |
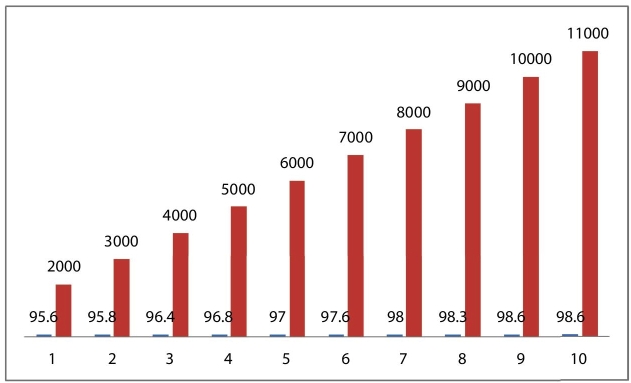
Figure 9.6 Various Recognition rate reported for IIT BBS Handwritten Odia Numeral Data set.
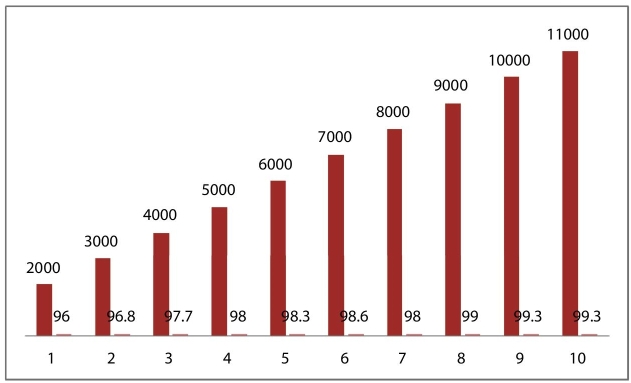
Figure 9.7 Various Recognition rate reported for ISI Kolkata Handwritten Odia Numeral Data set.
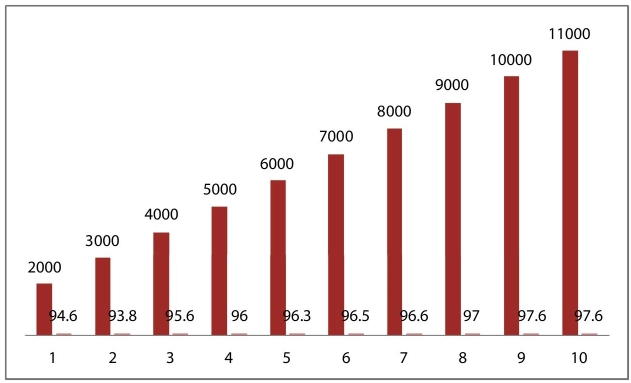
Figure 9.8 Various recognition rates reported for NIT Rourkela handwritten Bangla numeral data set.
9.6 Conclusion and Future Work
In this paper, we have attempted a new approach for handwritten numeral recognition. To achieve such, we had considered the CNN-based approach and depicted how effectively it helps in the recognition system. The main aim is that it is capable of creating its own feature for each individual and preprocessing is also achieved through it. Proper training and testing of the data are required to make the system robust. As CNN-based approach consists of multilayer, we have focused each and every input-output layer and maintained a well-defined training and test ratio among the data sets. We have also shown how the number of hidden neuron is helpful in calculating the complexity of the proposed model. As an outcome CNN-based approach, we have obtained 98.6% for IIT BBS handwritten numerals, 97.6% for NIT, RKL Bangla Numerals, and 99.3% for ISI Kolkata Odia numerals, respectively. Apart from it, we have also shown some details of recognition rate with respect to proposed work and inputted in tabular format as shown in Table 9.3 below. We have achieved very good recognition rate over benchmark handwritten data set. Apart from its various invented machine learning approaches, such as direction-based, extreme learning based can be applied to such problem domain. Further, other techniques are to be explored for better recognition accuracy. This convolution-based approach can also be very much helpful in fractal analysis [43].
Table 9.3 Recognition Rate reported by existing method with current method.
| Authors | Reported data set | Feature extraction techniques used | Reported classifier | Reported recognition rate (%) |
| In [13] Pal et al. | ISI Kolkata Handwritten Odia Characters | Curvature Feature values | Modified Quadratic Classifier | 94.6 % |
| In [17] Mishra | NIT, RKL | DCT and DWT | Support Vector Machine | 92%, 87.5 % |
| et al. | Handwritten Odia Characters | (SVM) | ||
| In [20] Sethy et al. | ISI Kolkata Handwritten Odia Numerals | Binarization and DCT | BPNN | 80.2%, 90% |
| In [24] Sethy et al. | NIT, RKL | DWT, PCA | BPNN | 94.8% |
| Handwritten Odia Characters | ||||
| In [40] Bhomik et al. | ISI Kolkata Handwritten Odia Numerals | Stroke calculation along Horizontal and Vertical | Neural Network (NN) | 95.89%, 90.50% |
| we author | IIT, BBS Odia Numeral | CNN | CNN | 98.6% |
| NIT, RKL Bangla Numeral | 97.6% | |||
| ISI KOL, Odia Numeral | 99.3% |
References
- 1. Mantas, J., An overview of character recognition methodologies. Pattern Recognit., 19, 6, 425–430, 1986. https://doi.org/10.1016/0031-3203(86)90040-3.
- 2. Arica, N. and Yarman-Vural, F.T., An overview of character recognition focused on off-line handwriting. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.), 31, 2, 216–233, 2001. https://doi.org/10.1016/0031-3203(86)90040-3.
- 3. Srihari, S.N., Cohen, E., Hull, J.J., Kuan, L., A system to locate and recognize ZIP codes in handwritten addresses. IJRE, 1, 37–45, 1989. https://digital.ijre. org/index.php/int_j_res_eng/article/view/311.
- 4. Tsukumo, J. and Tanaka, H., Classification of handprinted Chinese characters using nonlinear normalization and correlation methods, in: [1988 Proceedings] 9th International Conference on Pattern Recognition, May, Rome, Italy, IEEE, pp. 168–171, 1988.
- 5. Amin, A. and Al-Sadoun, H.B., Hand printed Arabic character recognition system, in: Proceedings of the 12th IAPR International Conference on Pattern Recognition, Vol. 3-Conference C: Signal Processing (Cat. No. 94CH3440-5), vol. 2, October, Jerusalem, Israel, IEEE, pp. 536–539, 1994, 10.1109/ ICPR.1994.577012.
- 6. Yamada, H., Yamamoto, K., Saito, T., A nonlinear normalization method for handprinted Kanji character recognition—line density equalization. Pattern Recognit., 23, 9, 1023–1029, 1990. https://doi.org/10.1016/ 0031-3203(90)90110-7.
- 7. Plamondon, R. and Srihari, S.N., Online and off-line handwriting recognition: a comprehensive survey. IEEE Trans. Pattern Anal. Mach. Intell., 22, 1, 63–84, 2000. 10.1109/34.824821.
- 8. Simard, P.Y., Steinkraus, D., Platt, J.C., Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis. Proceedings of International Conference on Document Analysis and Recognition, Edinburgh, UK, IEEE, pp. 958–962, 2003. 10.1109/ICDAR.2003.1227801.
- 9. LeCun, Y., Bottou, L., Bengio, Y., Haffner, P., Gradient-based learning applied to document recognition. Proc. IEEE, 86, 11, 2278–2324, 1998.
- 10. Ciresan, D. and Meier, U., Multi-column deep neural networks for offline handwritten Chinese character classification, in: International Joint Conference on Neural Networks (IJCNN), IEEE, pp. 1–6, 2015.
- 11. Sethi, I.K. and Chatterjee, B., Machine recognition of constrained hand printed Devanagari. Pattern Recognit., 9, 2, 69–75, 1977. https://doi.org/ 10.1016/0031-3203(77)90017-6.
- 12. Sinha, R.M.K. and Mahabala, H.N., Machine recognition of Devanagari script. IEEE Trans. Syst. Man Cybern., 9, 8, 435–441, 1979.
- 13. Pal, U., Wakabayashi, T., Kimura, F., A system for off-line Oriya handwritten character recognition using curvature feature, in: 10th international conference on information technology (ICIT), 2007 December, Orissa, India, IEEE, pp. 227–229, 2007.
- 14. Desai, A., Gujarati handwritten numeral optical character recognition through neural network. Pattern Recognit., 43, 2582–2589, 2010. https://doi. org/10.1016/j.patcog.2010.01.008.
- 15. Kundu, Y.H. and Chen, M., Alternatives to variable duration HMM in handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell., 20, 11, 1275–1280, 2002.
- 16. Roy, K., Pal, T., Pal, U., Kimura, F., Oriya handwritten numeral recognition system, in: Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, South Korea, IEEE, pp. 770–774, 2005.
- 17. Mishra, T.K., Majhi, B., Panda, S., A comparative analysis of image transformations for handwritten Odia numeral recognition, in: 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, IEEE, pp. 790–793, 2013.
- 18. Dash, K.S., Puhan, N.B., Panda, G., Handwritten numeral recognition using non-redundant Stock well transform and bio-inspired optimal zoning. IET Image Proc., 9, 10, 874–882, 2015.
- 19. Dash, K.S., Puhan, N.B., Panda, G., On extraction of features for handwritten Odia numeral recognition in transformed domain, in: 2015 Eighth International Conference on Advances in Pattern Recognition (ICAPR), Kolkata, India, IEEE, pp. 1–6, 2015.
- 20. Sethy, A. and Patra, P.K., Off-line Odia handwritten numeral recognition using neural network: a comparative analysis. International Conference on Computing, Communication and Automation (ICCCA), IEEE, pp. 1099–1103, 2016.
- 21. Mohapatra, R.K., Majhi, B., Jena, S.K., Classification of handwritten Odia basic character using Stock well transform. Int. J. Appl. Pattern Recognit., 2, 3, 235–254, 2015. https://doi.org/10.1504/IJAPR.2015.073854.
- 22. Sethy, A., Patra, P.K., Nayak, D.R., Gray-level co-occurrence matrix and random forest based off-line Odia handwritten character recognition. Recent Pat. Eng., 13, 2, 136–141, 2019. https://doi.org/10.2174/1872212112666180 601085544.
- 23. Sethy, A. and Patra, P.K., R-HOG Feature-Based Off-Line Odia Handwritten Character Recognition, in: Examining Fractal Image Processing and Analysis, IGI Global, pp. 196–210, 2020.
- 24. Sethy, A., Patra, P.K., Nayak, D.R., Off-line handwritten Odia character recognition using DWT and PCA, in: Progress in Advanced Computing and Intelligent Engineering, Springer, Singapore, pp. 187–195, 2018. https://doi. org/10.1007/978-981-10-6872-0_18.
- 25. Das, D., Nayak, D.R., Dash, R., Majhi, B., An empirical evaluation of extreme learning machine: application to handwritten character recognition. Multimed. Tools Appl., 1–29, 2019. https://doi.org/10.1007/s11042-019-7330-0
- 26. Das, N. and Pramanik, S., Recognition of Handwritten Bangla Basic Character and Digit Using Convex Hall Basic Feature. International Conference on Artificial Intelligence and Pattern Recognition (AIPR-09), 380–386, 2009.
- 27. Rabby, A.S.A., Haque, S., Abujar, S., Hossain, S.A., EkushNet: Using Convolutional Neural Network for Bangla Handwritten Recognition. Procedia Comput. Sci., 143, 603–610, 2018. https://doi.org/10.1016/j.procs.2018.10.437.
- 28. Rabby, A.S.A., Haque, S., Islam, S., Abujar, S., Hossain, S.A., BornoNet: Bangla Handwritten Characters Recognition Using Convolutional Neural Network. Procedia Comput. Sci., 143, 528–535, 2018. https://doi.org/10.1016/j. procs.2018.10.426.
- 29. Pizzi, N. J., Pedrycz, W., Aggregating multiple classification results using fuzzy integration and stochastic feature selection. Int. J. Approx. Reason., 51, 8, 883–894, 2010. https://doi.org/10.1016/j.ijar.2010.05.003.
- 30. Mishra, T.K., Majhi, B., Sa, P.K., Panda, S., Model Based Odia Numeral Recognition using Fuzzy Aggregated Features. Front. Comput. Sci. Springer, 916–922, 2014. https://doi.org/10.1007/s11704-014-3354-9.
- 31. Bhattacharya, U. and Chaudhuri, B.B., Databases for research on recognition of handwritten characters of Indian scripts, in: Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, South Korea, IEEE, pp. 789–793, 2005.
- 32. Hu, B., Lu, Z., Li, H., Chen, Q., Convolutional neural network architectures for matching natural language sentences, in: Advances in neural information processing systems, Springer, pp. 2042–2050, 2014.
- 33. Matsugu, M., Mori, K., Mitari, Y., Kaneda, Y., Subject independent facial expression recognition with robust face detection using a convolutional neural network. Neural Netw., 16, 5-6, 555–559, 2003. https://doi.org/10.1016/ S0893-6080(03)00115-1.
- 34. LeCun, Y., Bottou, L., Bengio, Y., Haffner, P., Gradient-based learning applied to document recognition. Proc. IEEE, 86, 11, 2278–2324, 1998.
- 35. Bhattacharya, U., Shridhar, M., Parui, S.K., Sen, P.K., Chaudhuri, B.B., Offline recognition of handwritten Bangla characters: an efficient two-stage approach. Pattern Anal. Appl., 15, 4, 445–458, 2012. https://doi.org/10.1007/ s10044-012-0278-6.
- 36. Torvalds, L., http://deeplearning.net/software/theano, 2015.
- 37. Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde-Farley, D., Bengio, Y., A CPU and GPU math expression compiler, in: Proceedings of the Python for scientific computing conference (SciPy), vol. 4, No. 3, 2010.
- 38. Bastien, F., Lamblin, P., Pascanu, R., Bergstra, J., Goodfellow, I., Bergeron, A., Bouchard, N., Warde-Farley, D., Bengio, Y., Theano: new features and speed improvements, 1–10, 2012. arXiv preprint arXiv:1211.5590.
- 39. http://scikit-learn.org/, 2010.
- 40. Bhowmik, T.K., Parui, S.K., Bhattacharya, U., Shaw, B., An HMM based recognition scheme for handwritten Oriya numerals, in: 9th International Conference on Information Technology (ICIT’06), Bhubaneswar, India, IEEE, pp. 105–110, 2006.
- 41. Sethy, A., Patra, P.K., Nayak, S.R., Jena, P.M., Symmetric Axis Based Off-Line Odia Handwritten Character and Numeral Recognition, in: 3rd International Conference on Computational Intelligence and Networks (CINE), Bhubaneswar, India, IEEE, pp. 83–87, 2017.
- 42. Sethy, A. and Patra, P.K., Off-line Odia Handwritten Character Recognition: An Axis Constellation Model Based Research. International Journal of Innovative Technology and Exploring Engineering (IJITEE), vol. 8, 9S2, 788–793, 2019.
- 43. Sethy, A., Patra, P.K., Nayak, S.R., Jena, P.M., Symmetric Axis Based Offline Odia Handwritten Character and Numeral Recognition. International Journal of Informatics and Communication Technology, vol. 07 (2), pp. 96–104, 2018.
- 44. Nayak, S.R., Mishra, J., Palai, G., Analysing Roughness of Surface through Fractal Dimension: A Review. Image Vision Comput., 89, 21–34, 2019. https://doi.org/10.1016/j.imavis.2019.06.015.
- 45. Nayak, S.R., Mishra, J., Khandual, A., Palai, G., Fractal Dimension of RGB Color Images. International Journal for Light and Electron Optics, vol. 162, pp. 196–205, 2018. https://doi.org/10.1016/j.ijleo.2018.02.066.
- 46. Nayak, S.R., Mishra, J., Palai, G., A modified approach to estimate fractal dimension of gray scale Images. International Journal for Light and Electron Optics, vol. 161, pp. 136–145, 2018. https://doi.org/10.1016/j.ijleo.2018.02.024.
- 47. Nayak, S.R., Khandual, A., Mishra, J., Ground truth study of fractal dimension of color images of similar textures. J. Text. Inst., 109, 1159–1167, 2018. https://doi.org/10.1080/00405000.2017.1418710.
- 48. Nayak, S.R. and Mishra, J., A Modified Triangle Box-Counting with precision in Error fit. J. Inf. Optim. Sci., 39, 1, 113–128, 2018. https://doi.org/10.1 080/02522667.2017.1372155.
- 49. Nayak, S.R., Mishra, J., Palai, G., An extended DBC approach by using maximum Euclidian distance for fractal dimension of color images. International Journal for Light and Electron Optics, vol. 166, pp. 110–115, 2018. https://doi. org/10.1016/j.ijleo.2018.03.106.
- 50. Nayak, S.R., Padhy, R., Mishra, J., A new extended differential box counting method by adopting unequal partitioning of grid for estimation of fractal dimension of digital images. Computational Signal Processing and Analysis, vol. 490, pp. 45–57, 2018. https://doi.org/10.1007/978-981-10-8354-9_5.
- 51. Nayak, S.R. and Mishra, J., Fractal Dimension of Gray Scale images, in: Progress in Computing, Analytics and Networking, vol. 710, pp. 225–234, 2018. https://doi.org/10.1007/978-981-10-7871-2_22.
- 52. Nayak, S.R. and Mishra, J., Analysis of Medical images using Fractal Geometry, in: Histopathological Image Analysis in Medical Decision Making, Chapter 8, pp. 181–201, 2018.
- 53. Nayak, S.R., Mishra, J., Mohan Jena, P., Fractal analysis of image sets using differential box counting techniques. Int. J. Inf. Technol., 10, 1, 39–47, 2018. https://doi.org/10.1007/s41870-017-0062-3.
Note
- * Corresponding author: [email protected]