
Chapter 4
Footprinting and Reconnaissance
 It's commonly believed that attackers do a lot of work up front before launching attacks. They get a sense of how large the attack surface is and where their targets are. This can take a lot of work, using a lot of different tool and skill sets. The process of getting the size and scope of the target is called footprinting—in other words, the attacker, or you, the ethical hacker, is trying to pick up the footprint of the target organization. When it comes to ethical hacking, you may have some help from the target, who would have employed you for your services. They may provide you with some footholds to get a sense of the scope and scale of what you should be doing. It's possible, though, that you are starting blind and you have to get your own footholds.
It's commonly believed that attackers do a lot of work up front before launching attacks. They get a sense of how large the attack surface is and where their targets are. This can take a lot of work, using a lot of different tool and skill sets. The process of getting the size and scope of the target is called footprinting—in other words, the attacker, or you, the ethical hacker, is trying to pick up the footprint of the target organization. When it comes to ethical hacking, you may have some help from the target, who would have employed you for your services. They may provide you with some footholds to get a sense of the scope and scale of what you should be doing. It's possible, though, that you are starting blind and you have to get your own footholds.
There are a lot of places you, as an ethical hacker, can get information about your targets, though. Open source intelligence is the term that describes identifying information about your target using freely available sources. There are other places where you can acquire information in other than legal ways, and of course, you could directly infiltrate a company's physical locations to get some information that you can use against your target. That's potentially illegal and definitely not open source.
The objective here is to acquire data that you need without tipping off your target that you are doing it. This is why you might use third-party sources to acquire the information you need. You can also gather a lot of details by interacting with services at the target in ways that would be expected. As an example, you might visit their website requesting pages, just as any other visitor to their site might do. Nothing special about what you are asking for or how you are asking for it. However, if you know where to look, you can gather a lot of information about systems and technology in use by your target.
One source of a lot of detail about your target is the Domain Name System (DNS). This isn't something a lot of people spend time thinking about. When it works, you have no idea because it happens quietly in the background. However, there is a lot of data stored in DNS servers about domains and even IP address blocks. This data can be mined, and you can get a better understanding about your target and systems and the IP address blocks that may be associated with your target.
It may be useful as you work through the different stages of a testing methodology to identify matches to the MITRE ATT&CK Framework. We're in luck on this phase. The ATT&CK Framework has a reconnaissance phase, and it covers scanning as well as gathering information from different sources about different aspects of the target. While it's common to think that attackers are looking for vulnerabilities and systems of interest, they are probably more likely to look for human targets. This may be identifying employees and email addresses but also, perhaps just as important, knowing what those employees do, which will tell the attacker how much access they have. More access means an attacker may be able to get to something that can easily be monetized.
Over the course of this chapter, we'll go over sources of information about your target as well as the tools you would use to gather that information. While much of it is quiet and there is at least one tool that is entirely passive, there is some active investigation as well. The first place to start, though, is how to use open sources of data to identify a jumping-off point for getting information about your target.
Open Source Intelligence
There are a couple of reasons you may want to use open source intelligence. The first is that you haven't been provided with any details about your target. You may be doing a true red team against the target company and systems. In that case, you need to locate as much information as you can so you know not only what your attack surface looks like but possible ways in. Additionally, you can find a lot of information about individuals within an organization. This is especially useful because social engineering attacks have a good possibility of success. Having contacts to go after is essential.
The second reason is that organizations aren't always aware of the amount of information they are leaking. As noted earlier, attackers can find footholds, as well as potential human targets for social engineering attacks. If you are working hand in hand with the company you are performing testing for (that is, you are doing white-box testing), you don't need to use open source intelligence for starting points, but you should still gather what information is available for the awareness of the company. They may be able to limit their exposure. Even if there isn't anything that could be pulled back, they could work on awareness so employees and the organization as a whole aren't leaking information unnecessarily.
There are a number of tools that can be used to automate the collection of information, and we'll cover their use as part of looking at how to gather open source intelligence about companies and people. We'll also take a look at social networking sites and some of the ways those websites can be used. Even in cases where privacy settings are locked down, there is still a lot of information that can be gathered. There are also sites that exist to be public, and those can definitely be used.
Companies
There are several starting points when it comes to acquiring open source intelligence about your target. The first is to look at the company overall. You'll want to gather information about locations the company has. There are instances where this can be easy. However, increasingly, it can be harder. The reason it can be harder is that companies recognize that the more information they provide, the more that information can be used against them. So, unless they are required to provide that information by regulations, they don't provide it. There are a few resources that can be used to gather information about companies.
Sometimes, these resources can be used to gather information that may be used for social engineering attacks. In some cases, you will be able to gather details about a company's network. Both types of information can be useful. Details about a company and its organizational and governance structure can come from a database maintained by the U.S. government, in the case of businesses registered here. Details about the business network may come from databases maintained by the organizations that are responsible for governance of the Internet.
EDGAR
Public companies are required to provide information about themselves. There are resources you can use to look up that information. In the process, you may gather information about a company's organizational structure. The organizational structure can tell you who has what position, so when you are working on sending out email messages to gather additional information later, you know who they should appear to be from. You can select the holder of an appropriate position.
The Securities and Exchange Commission (SEC) has a database that stores all public filings associated with a company. The Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system can be used to look up public filings such as the annual report in the form 10-K. Additionally, the quarterly reports, 10-Qs, are also submitted to EDGAR and stored there. These reports provide details about a company's finances. The 11-K, a form including details about employee stock option plans, is also filed with EDGAR. Accessing EDGAR is as easy as going to EDGAR at the SEC website. You can see the search field, part of the page, in Figure 4.1.
FIGURE 4.1 EDGAR site
One of the most useful forms you can find in EDGAR is Schedule 14-A, which is a proxy statement and will include the annual report to the shareholders, which may include a lot of useful information for you. As an example, Figure 4.2 shows a very small section of the annual report to the shareholders for Microsoft Corporation. Other sections that are not shown include Corporate Governance at Microsoft, Board of Directors, and Audit Committee Matters. While at a high level, what is included in these reports will be the same across all public companies, there may be some companies that present more in the way of specific details than other companies. Some companies will have more to report than others. For instance, the table of contents for the Microsoft report shows the page total in the 80s. The report for John Wiley & Sons shows a page count in the 50s. That's about 30 fewer pages between the two companies.

FIGURE 4.2 Portion of Schedule 14-A for Microsoft
Domain Registrars
EDGAR is only for public companies. Not every company is public. You don't get the same level of insight for a private company that you do for a public company. However, EDGAR is not the only resource that can be used to gather information about a company. Another source of information, related to the Internet itself, is the domain registrars. You won't get the same sort of information from the domain registrars as you would from EDGAR, but it's still sometimes a decent source of information. For a start, you can get the address of what is probably the company's headquarters.
This is not a guarantee, however. As mentioned, companies are starting to hide information provided to the registrars. Information is hidden behind the registrar. When you ask for information, you will get what the registrar has been asked to present and not necessarily the real details. There is nothing that says that the registrars have to be provided with real addresses, unless they are checking a billing address on a credit card for payment. In fact, there have been times I have had domains registered with bogus phone numbers and incorrect addresses. Since the data is public, it's important to be careful about what is shared. Anyone can mine the registries for this information and use it for any number of purposes.
Before we get too far down this road, though, it's probably useful for you to understand how the Internet is governed when it comes to domains and addresses. First, there is the Internet Corporation for Assigned Names and Numbers (ICANN). Underneath ICANN is the Internet Assigned Numbers Authority (IANA), which is responsible for managing IP addresses, ports, protocols, and other essential numbers associated with the functioning of the Internet. Prior to the establishment of ICANN in 1998, IANA's functions were managed by one man, Jon Postel, who also maintained the request for comments (RFC) documents.
In addition to ICANN, responsible for numbering, are the domain registrars. These organizations store information about addresses they are responsible for as well as contacts. There was a time when registering a domain and other data went through a single entity. Now, though, there are several companies that can perform registrant functions. If you want to register a domain, you go to a registrar company like DomainMonger or GoDaddy. Those companies can then be queried for details about the domains.
To grab information out of the regional Internet registry (RIR), you would use the whois program. This is a program that can be used on the command line on most Unix-like systems, including Linux and macOS. There are also websites that have implementations of whois if you don't have a Unix-like system handy. Here you can see a portion of the output from a whois query.
whois Query of wiley.com
$ whois wiley.com% IANA WHOIS server% for more information on IANA, visit http://www.iana.org% This query returned 1 objectrefer: whois.verisign-grs.comdomain: COMorganisation: VeriSign Global Registry Servicesaddress: 12061 Bluemont Wayaddress: Reston Virginia 20190address: United Statescontact: administrativename: Registry Customer Serviceorganisation: VeriSign Global Registry Servicesaddress: 12061 Bluemont Wayaddress: Reston Virginia 20190address: United Statesphone: +1 703 925-6999fax-no: +1 703 948 3978e-mail: [email protected]←- SNIP →Domain Name: wiley.comRegistry Domain ID: 936038_DOMAIN_COM-VRSNRegistrar WHOIS Server: whois.corporatedomains.comRegistrar URL: www.cscprotectsbrands.comUpdated Date: 2017-10-07T05:19:30ZCreation Date: 1994-10-12T04:00:00ZRegistrar Registration Expiration Date: 2019-10-11T04:00:00ZRegistrar: CSC CORPORATE DOMAINS, INC.Registrar IANA ID: 299Registrar Abuse Contact Email: [email protected]Registrar Abuse Contact Phone: +1.8887802723Domain Status: clientTransferProhibitedhttp://www.icann.org/epp#clientTransferProhibitedRegistry Registrant ID:Registrant Name: Domain AdministratorRegistrant Organization: John Wiley & Sons, IncRegistrant Street: 111 River StreetRegistrant City: HobokenRegistrant State/Province: NJPostal Code: 07030Registrant Country: USRegistrant Phone: +1.3175723355Registrant Phone Ext:Registrant Fax: +1.3175724355Registrant Fax Ext:Registrant Email: [email protected]Registry Admin ID:Admin Name: Domain AdministratorAdmin Organization: John Wiley & Sons, IncAdmin Street: 111 River StreetAdmin City: HobokenAdmin State/Province: NJPostal Code: 07030Admin Country: USAdmin Phone: +1.3175723355Admin Phone Ext:Admin Fax: +1.3175724355Admin Fax Ext:Admin Email: [email protected]
There is a lot of output there to look through, and I've snipped out a bunch of it to keep it to really relevant information. First, whois checks with IANA's whois server to figure out who it needs to check with about this specific domain. You can see that happen at the very top of the output. IANA indicates that VeriSign is the registrar for this domain. We get the details about the registrar VeriSign. After that, and a lot of information being snipped out, we finally get the details about the domain wiley.com. What you can see in the output is the address and phone number for the company. Additionally, you get information about a handful of contacts for the company. Registrars expect an administrative contact and a technical contact.
As indicated earlier, not all domains will provide this level of detail. An example of a domain that doesn't include any contact details is spamhaus.org. Here you can see that the contact information shows that the data has been redacted for privacy.
Details About spamhaus.org
Registry Registrant ID: REDACTED FOR PRIVACYRegistrant Name: REDACTED FOR PRIVACYRegistrant Organization: The Spamhaus ProjectRegistrant Street: REDACTED FOR PRIVACYRegistrant City: REDACTED FOR PRIVACYRegistrant State/Province:Registrant Postal Code: REDACTED FOR PRIVACYRegistrant Country: CHRegistrant Phone: REDACTED FOR PRIVACYRegistrant Phone Ext:Registrant Fax: REDACTED FOR PRIVACYRegistrant Fax Ext:Registrant Email: [email protected]Registry Admin ID: REDACTED FOR PRIVACYAdmin Name: REDACTED FOR PRIVACYAdmin Organization: REDACTED FOR PRIVACYAdmin Street: REDACTED FOR PRIVACYAdmin City: REDACTED FOR PRIVACYAdmin State/Province: REDACTED FOR PRIVACYAdmin Postal Code: REDACTED FOR PRIVACYAdmin Country: REDACTED FOR PRIVACYAdmin Phone: REDACTED FOR PRIVACYAdmin Phone Ext:Admin Fax: REDACTED FOR PRIVACYAdmin Fax Ext:Admin Email: [email protected]
Using a strategy like this will keep information private and out of the hands of the very people spamhaus.org seeks to protect against. The data provided can be used to create a mailing list for spammers. It can also be used to create a physical mailing list for traditional junk mail providers (sometimes called mail marketing companies).
Regional Internet Registries
Not all the useful information is stored with the domain registrars, however. There is other data that is important to be kept. Earlier, we discussed IANA. While the IANA server provided information about domain registrars, its purpose has long been to be a central clearinghouse for addresses. This includes not only port numbers for well-known services but also IP addresses. IANA, at a high level, owns all IP addresses. It hands out those IP addresses, based on need, to the RIRs. The RIRs then hand them out to organizations that fall into their geographic region.
There are five RIRs around the world. They are based in different geographic regions, and an organization would refer to the RIR where they are located for things like IP addresses. The RIRs and the geographic areas they are responsible for are listed here:
- African Network Information Center (AfriNIC) Africa
- American Registry for Internet Numbers (ARIN) North America (United States and Canada) as well as Antarctica and parts of the Caribbean
- Asia Pacific Network Information Centre (APNIC) Asia, Australia, New Zealand, and neighboring countries
- Latin America and Caribbean Network Information Centre (LACNIC) Latin America and parts of the Caribbean
- Réseaux IP Européens Network Coordination Centre (RIPE NCC) Europe, Russia, West Asia, and Central Asia
All of these RIRs have their own databases that can be queried using whois, just as we used whois to query information from the domain registrars. Typically, you would use whois against the RIRs to find out who owns a particular IP address. For example, in the output for wiley.com earlier, part of the output indicated which name servers the domain uses to resolve hostnames to IP addresses. One of those name servers is ns.wiley.co.uk. With a minimal amount of effort (we will cover the DNS later in the chapter), we can discover that the hostname ns.wiley.co.uk resolves to the IP address 193.130.68.19. Using whois, we can find out who owns that IP address. You can see the results of that query in the following code.
whois Query for IP Address
$ whois 193.130.68.19% IANA WHOIS server% for more information on IANA, visit http://www.iana.org% This query returned 1 objectrefer: whois.ripe.netinetnum: 193.0.0.0 - 193.255.255.255organisation: RIPE NCCstatus: ALLOCATEDwhois: whois.ripe.netchanged: 1993-05source: IANA% This is the RIPE Database query service.% The objects are in RPSL format.%% The RIPE Database is subject to Terms and Conditions.% See http://www.ripe.net/db/support/db-terms-conditions.pdf% Note: this output has been filtered.% To receive output for a database update, use the "-B" flag.% Information related to '193.130.68.0 - 193.130.69.255'% Abuse contact for '193.130.68.0 - 193.130.69.255' is '[email protected]'inetnum: 193.130.68.0 - 193.130.69.255netname: WILEY-UKdescr: John Wiley & Sons Ltdcountry: GBadmin-c: TW1873-RIPEtech-c: TW1873-RIPEstatus: ASSIGNED PAmnt-by: AS1849-MNTcreated: 1970-01-01T00:00:00Zlast-modified: 2010-12-29T09:52:04Zsource: RIPE # Filteredperson: Tony Withersaddress: John Wiley & Sons Ltdaddress: Baffins Laneaddress: Chichesteraddress: Sussexaddress: PO19 1UDaddress: England, GBphone: +44 243 770319fax-no: +44 243 775878nic-hdl: TW1873-RIPEcreated: 1970-01-01T00:00:00Zlast-modified: 2016-04-05T14:15:57Zmnt-by: RIPE-NCC-LOCKED-MNTsource: RIPE # Filtered% Information related to '193.130.64.0/18AS702'route: 193.130.64.0/18descr: UK PA routeorigin: AS702member-of: AS702:RS-UK,AS702:RS-UK-PAinject: upon staticaggr-mtd: outboundmnt-by: WCOM-EMEA-RICE-MNTcreated: 2018-04-16T14:25:12Zlast-modified: 2018-04-16T14:25:12Zsource: RIPE
This provides us with a lot of useful information. First, even though we provided a single IP address, addresses are allocated in blocks. The first thing we find is that the parent block was allocated to RIPE, the European RIR, in 1993. The specific block the IP address provided belongs to, though, is 192.130.68.0–255. That block, unsurprisingly, belongs to John Wiley & Sons. You can see that the address for John Wiley & Sons is in Great Britain, which matches up with the RIR being RIPE. The business is located in England, so the corresponding regional registry is the one responsible for Europe.
We've learned a couple of things about the business and the IP addresses that belong to it. Additionally, you can see we have a contact that came out of the response. This gives us a name and email address. If we were going to be testing against this business, we could make use of this information.
People
While systems and the IP addresses associated with them make good entry points for technical attacks—those against services that are available—contact information for people can be more useful. There are other places we can go to get lists of people who belong to a target organization. Again, there are utilities we can use to help us gather this information. One of them is theHarvester. This is a script that will search through different sources to locate contact information based on a domain name provided to the program. In the following code, you can see the output from theHarvester run against the domain wiley.com, using Google as the search source.
theHarvester Output
$ theharvester -d wiley.com -b google********************************************************************* ** | |_| |__ ___ / /\__ _ _ ____ _____ ___| |_ ___ _ __ ** | __| '_ / _ / /_/ / _` | '__ / / _ / __| __/ _ '__| ** | |_| | | | __/ / __ / (_| | | V / __/\__ || __/ | ** \__|_| |_|\___| / /_/ \__,_|_| \_/ \___||___/\__\___|_| ** ** TheHarvester Ver. 2.7.2 ** Coded by Christian Martorella ** Edge-Security Research ** [email protected] ********************************************************************[-] Starting harvesting process for domain: wiley.com[-] Searching in Google:Searching 0 results...Searching 100 results...Searching 200 results...Searching 300 results...Searching 400 results...Searching 500 results...Harvesting results[+] Emails found:------------------[email protected][email protected][email protected][email protected][email protected][+] Hosts found in search engines:------------------------------------Total hosts: 8[-] Resolving hostnames IPs...agupubs.onlinelibrary.wiley.com : 65.156.1.101authorservices.wiley.com : 216.137.41.119booksupport.wiley.com : 208.215.179.132eu.wiley.com : 216.137.41.74hub.wiley.com : 204.93.79.243newsroom.wiley.com : 204.8.173.169onlinelibrary.wiley.com : 65.156.1.101www.wiley.com : 216.137.41.21
Google is not the only source that can be used with theHarvester. Another source that can be used, which may not be considered a lot, is a Pretty Good Privacy (PGP) key server. PGP relies on public keys to be available in publicly available key servers. Without these, the public key has to be shared manually by anyone who wants to get an encrypted message from someone else. Because these keys have to be available to be used, they are stored and searchable on web servers. Since they are associated with email addresses, you can search for email addresses on the key server. This may not always be successful. People who have been around for a long time may be more likely to have PGP keys. As an example, you can see the run results of theHarvester against one of my own domains. Since some of my email addresses have been around for more than 20 years, and since I've generally had a habit of rebuilding machines without storing off encryption keys, I have a few PGP keys.
Interestingly, theHarvester wasn't able to locate any of my PGP keys. This leads us to other places to look for PGP keys. One of the older public key servers is hosted at the Massachusetts Institute of Technology (MIT). If you go to https://pgp.mit.edu, you can provide a search term, including a domain name. Searching using theHarvester didn't turn up any entries for wiley.com. Doing the same search at https://pgp.key-server.io (MIT's site was unresponsive for this search) resulted in a handful of results. However, because of the way the search in the database was conducted, the term wiley.com resulted in a number of people whose first name was Wiley, while the domain name their email address was in ended in .com.
Using the MIT site to search for my own keys, I turned up all the keys I have loaded into the key servers over the years. This is a way to look up information about individual people if you need to, since theHarvester requires that you provide a domain name. In my case, you can see the output from the search in Figure 4.3. My primary email address has three different keys associated with it. As I said, I had a habit of rebuilding or moving to different machines without ever storing my private key. This meant, if I wanted to do any PGP encrypted email, I had to regenerate a key and reupload. Since the key signature is different, it doesn't overwrite the other key. It's possible, after all, I could have a few legitimate keys that are all used on different systems.
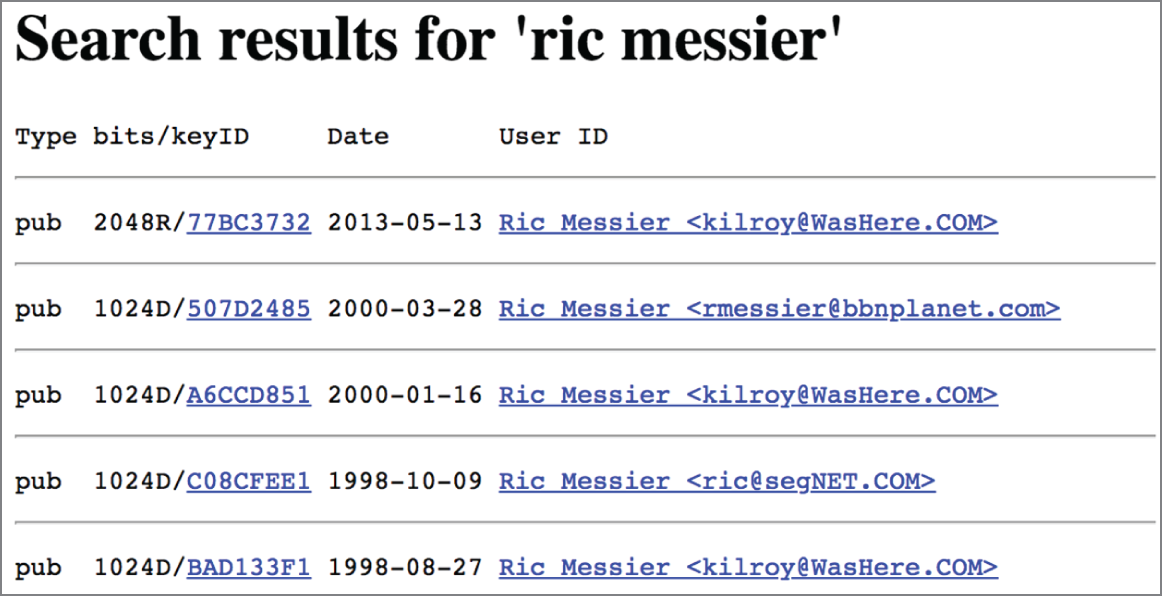
FIGURE 4.3 PGP key server search
While tools like theHarvester are good for identifying information about people at a company automatically, you may want or need to go deeper. This is where you might consider using a people search website, like Pipl, Wink, or Intelius. These sites can be used to search for people. A site like Pipl can be used to identify an online presence for someone. For example, using my name turns up a handful of posts to mailing lists, as well as a Twitter account I don't use. There are also a few other references that aren't me. You can see a sample of the output of Pipl in Figure 4.4.
There are other people search sites that are more focused on looking at social networking presence, and searches can be done using usernames. The website PeekYou will do people searches using real names, just as we did with Pipl. PeekYou also allows you to look for a username instead, though. This username could be found across multiple social network sites, as well as other locations where a username is exposed to the outside world. A search for a username I have used in the past turned up a few hits, though the information was badly out of date and inconsistent. An online presence, though, can be used for more than just finding people.

FIGURE 4.4 Pipl output
Social Networking
Social networking sites are how people connect. They come in a number of different flavors and have been around for more than two decades, with the first one, sixdegrees.com, launched in 1997. Sites like Myspace have allowed users to share music and personal information with others. Facebook has allowed users to create communities, share news and information, and get back in touch with people they have fallen away from. Twitter is often useful for news and updates, as well as marketing information—making announcements, for example. LinkedIn is useful for all sorts of business purposes. This includes sharing updates about company activities, personal achievements, and moves.
You can spend a lot of time looking for information by hand on these sites. There are also tools that you can use. One of them is one we've already looked at. In addition to using traditional search sites like Google and Bing, theHarvester will also search through some of the social network sites. There are also tools that are specific to some of the sites, such as LinkedIn. Finally, we have a tool like Maltego, which is good for open source intelligence in general, though there are ways it can be used to search social network sites for details about people and companies.
While sites that may primarily be thought of as personal sites may focus more on individuals, they are still useful for someone doing work as an ethical hacker. A site like Facebook is interesting because people seem to let their guard down there, posting a lot of details that perhaps they shouldn't. What they often fail to realize is how much of what they post is searchable. Over time, Facebook has vastly improved how much information can be acquired, though it's still not great. Several years ago, there was a website, www.weknowwhatyouredoing.com, that searched through Facebook posts that would fall into one of four categories—who wants to get fired, who is hungover, who is taking drugs, and who has a new phone number. Figure 4.5 shows some of the posts from the site before it got taken down because the application programming interface (API) it used is no longer available.
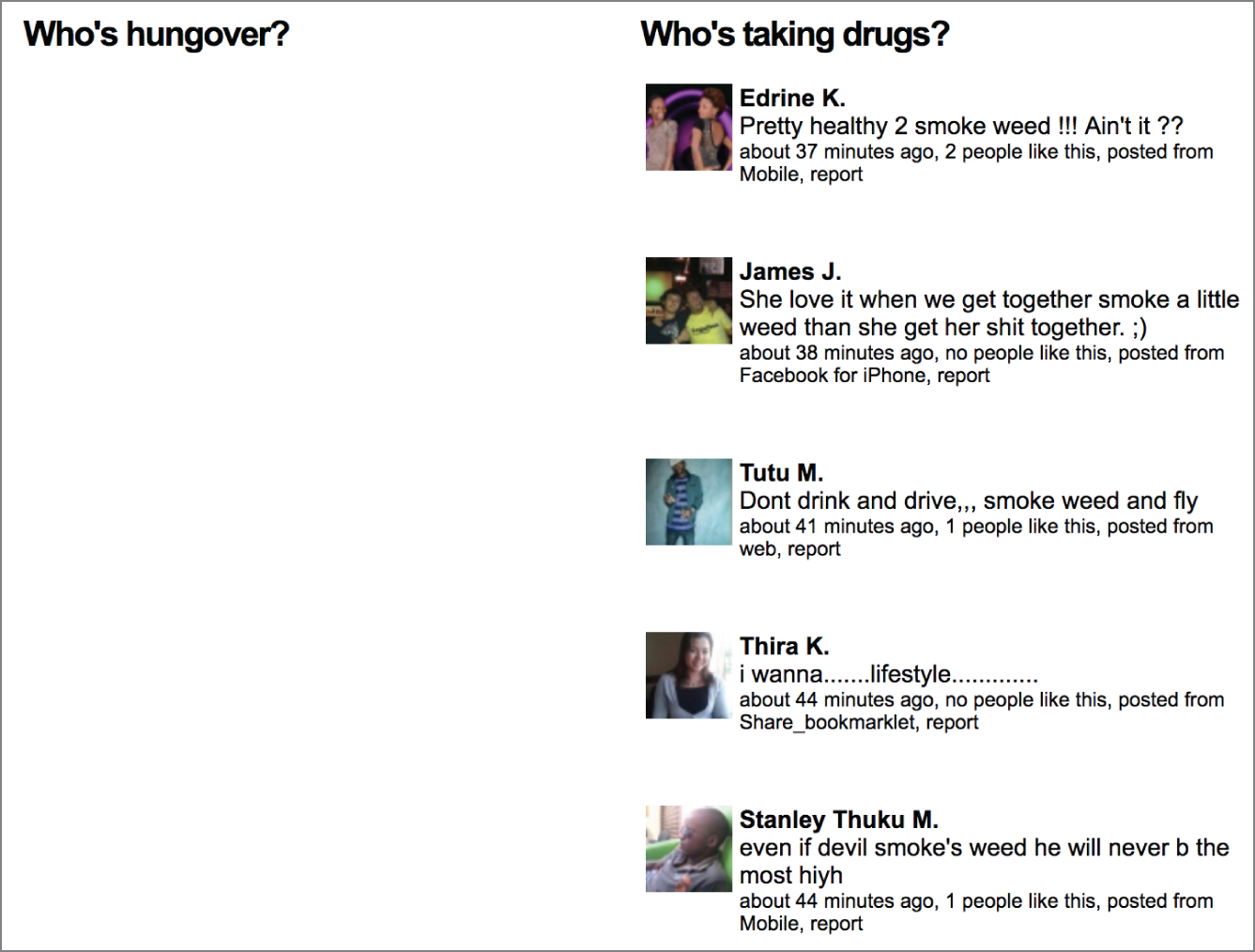
This is not to say that Facebook no longer has an API. The Facebook Graph API still exists. It just isn't as open as it once was. There is still a Graph API, and it can still be used in applications. In fact, Facebook provides a Graph API Explorer where queries to the API can be tested. Figure 4.6 shows the Graph API Explorer. Near the top, you can see there is an access token. This token is generated after a number of permissions are selected. The token is based on the user you are logged in as. Once you have a token, you can generate a query. The query shown is the default query, requesting the ID and name for the user. Of course, the name is mine since the access token was based on my login.
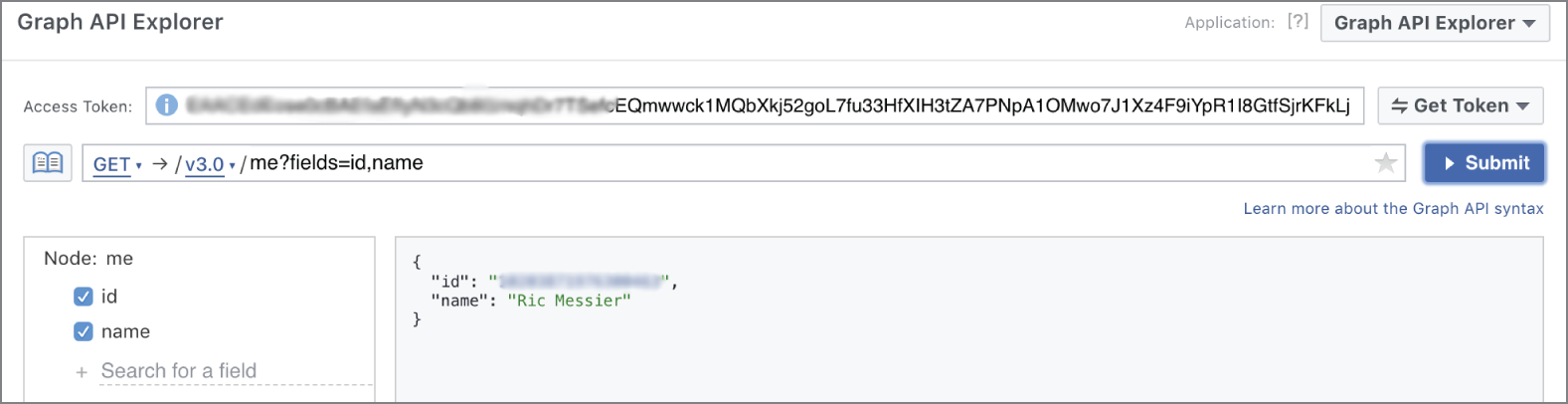
FIGURE 4.6 Facebook Graph API
You don't have to create an application, though, to generate searches. Searches can be done manually. Facebook is not only used by individuals. It is also, often, used by companies. Many companies create their own page where they can post specifics about their products and services. This is another location where you can gather information about the company. Figure 4.7 shows business details about John Wiley & Sons from its own page in Facebook. Besides the information you can see about its location, there are several other categories of information, such as Reviews, Posts, and Community. The reviews can sometimes provide enlightening information, and of course, there is the contact information provided.
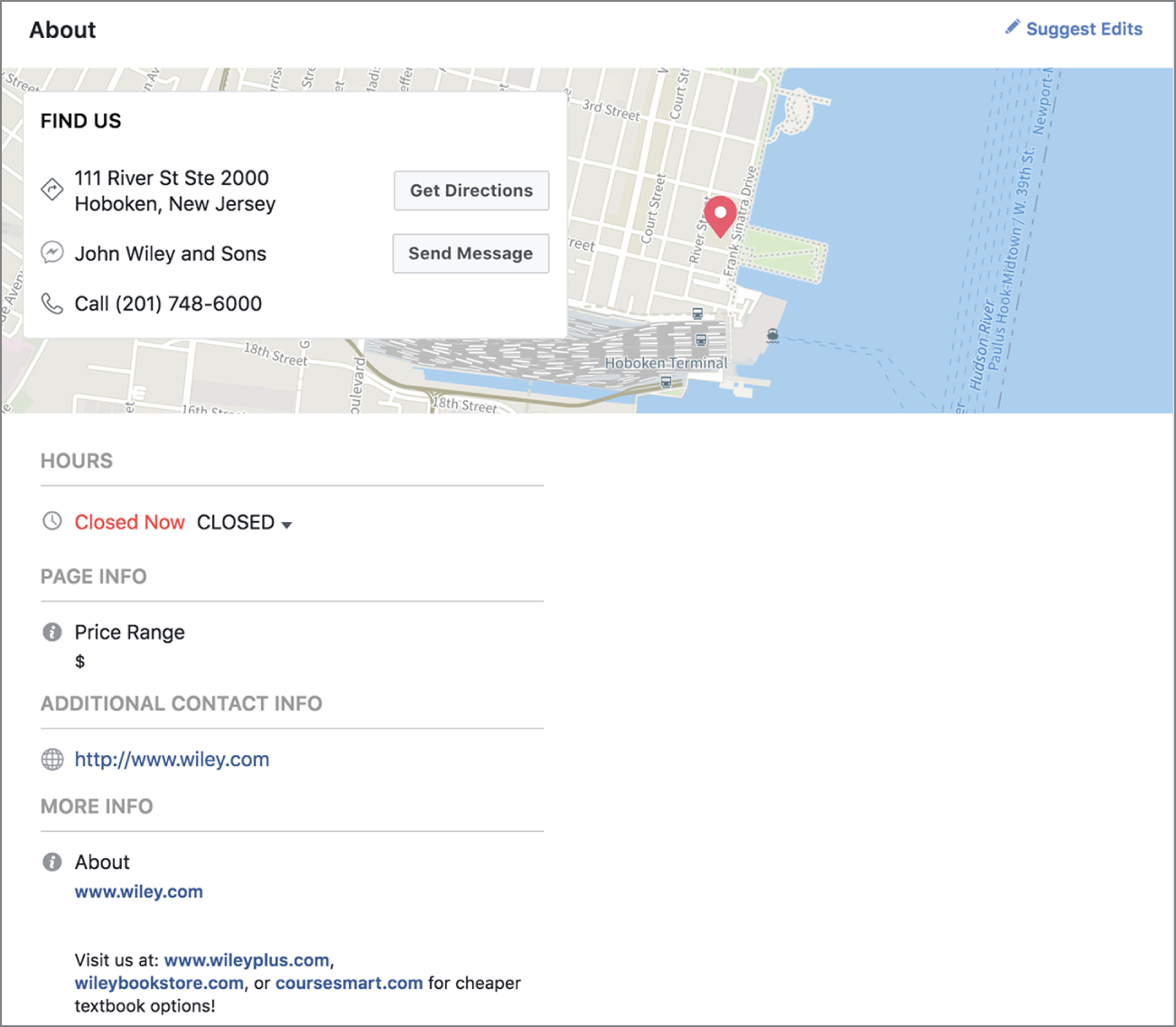
FIGURE 4.7 John Wiley & Sons information
You don't have to rely on just looking up business information in Facebook, though. People regularly post details about their employers on their personal pages. Unfortunately, this is where searching in Facebook can become challenging. You can't, after all, just search for all employees of a particular company using the usual search. However, if you have found some names of employees using other means, you can use those names to find their pages and read their status posts. Often, people will include details of their work situation—companies they do work for and have worked for—as part of their profile. This can help you to better distinguish the employees from other people with the same name.
Much of this relies on people setting their privacy options correctly. This is not always done, which means you can probably read the posts of a lot of people you are looking for. You can also likely look at their photos. In an age of social media and the expectation that you can find out just about anything you want about someone, people often don't think about who can potentially see their posts and photos. This gives us an advantage. However, it isn't always the case that you will be able to see what someone is doing and saying. Figure 4.8 shows the different privacy settings available to Facebook users. One of the challenges with this, though, is that it only pertains to what you do. This won't prevent other people from seeing when someone shares one of your posts or photos. Then it comes down to what their permissions are set to.
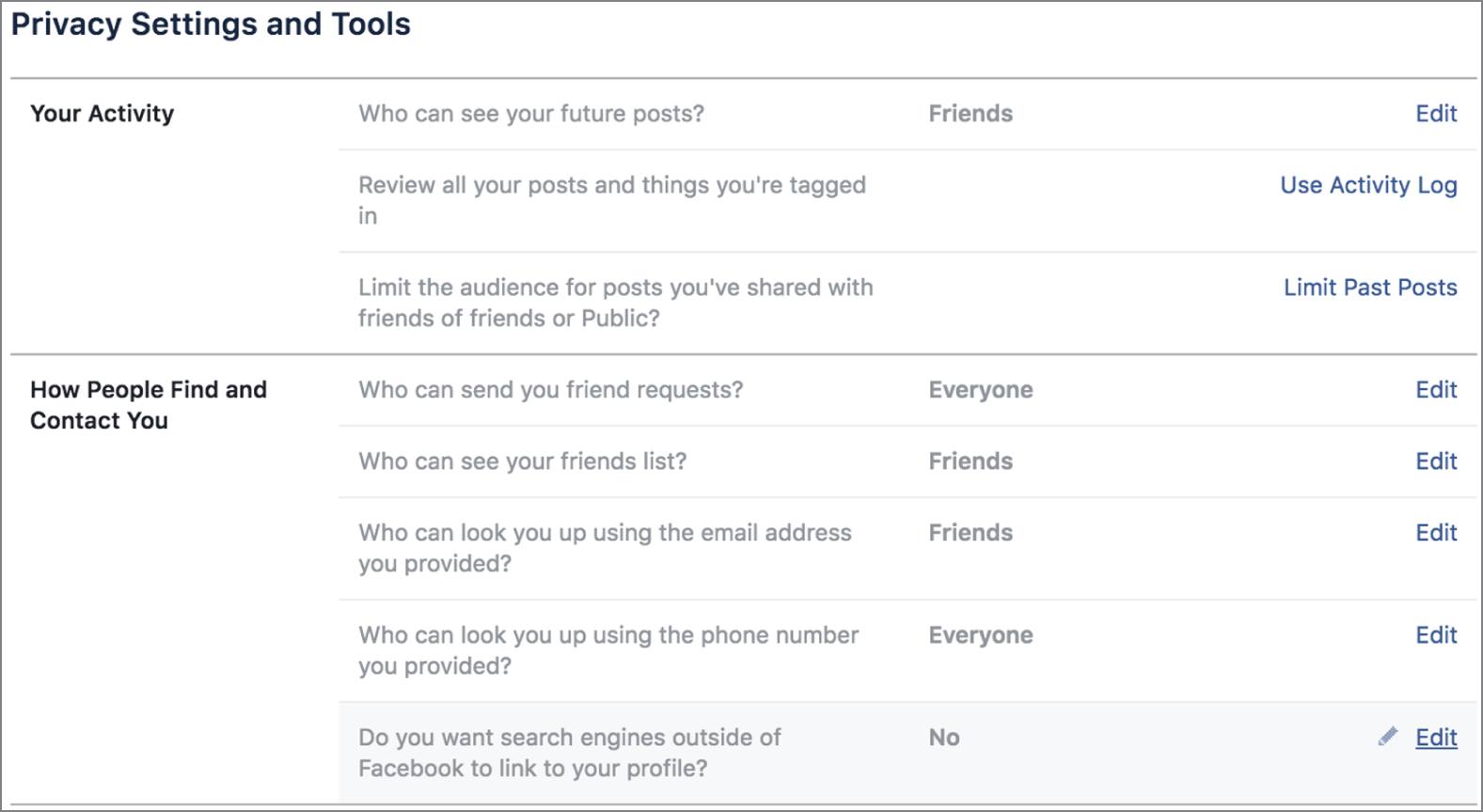
FIGURE 4.8 Facebook permissions settings
Sometimes, people will post a status about their job, including what they may have been doing that day, or they may check in at another job site. Any of this information could potentially be useful to you. However, sites like Facebook are not always the best place to get information about businesses and their employees. There are other social networking sites that can be a bit more productive for you.
LinkedIn has been around for about a decade and a half as of the time of this writing. In spite of a number of competitors (such as Plaxo) going out of business or just no longer being in the space, LinkedIn is still around. It continues to expand its offerings beyond the very early days, when it was basically a contact manager. These days, LinkedIn is a business networking opportunity, highly useful for those in sales. It is also a great source for identifying jobs you may be interested in. It seems like human resources people, specifically recruiters, commonly use LinkedIn to find people to fill positions, whether it's an internal recruiter or someone who works for a recruiting company.
Because of the amount of business information LinkedIn collects, we can make use of it as a hunting platform. Especially with the paid memberships, LinkedIn does a lot of analytics about the businesses that make use of it, as well as the people who are on the site. If you are looking for information about a target, LinkedIn provides a lot of detail. Just as one example, Figure 4.9 shows some statistics about applicants for a position that is open and advertised through the Jobs section of the website. We can see that the position attracts educated applicants. You can start to get a sense for the workforce by looking at these statistics across multiple positions.
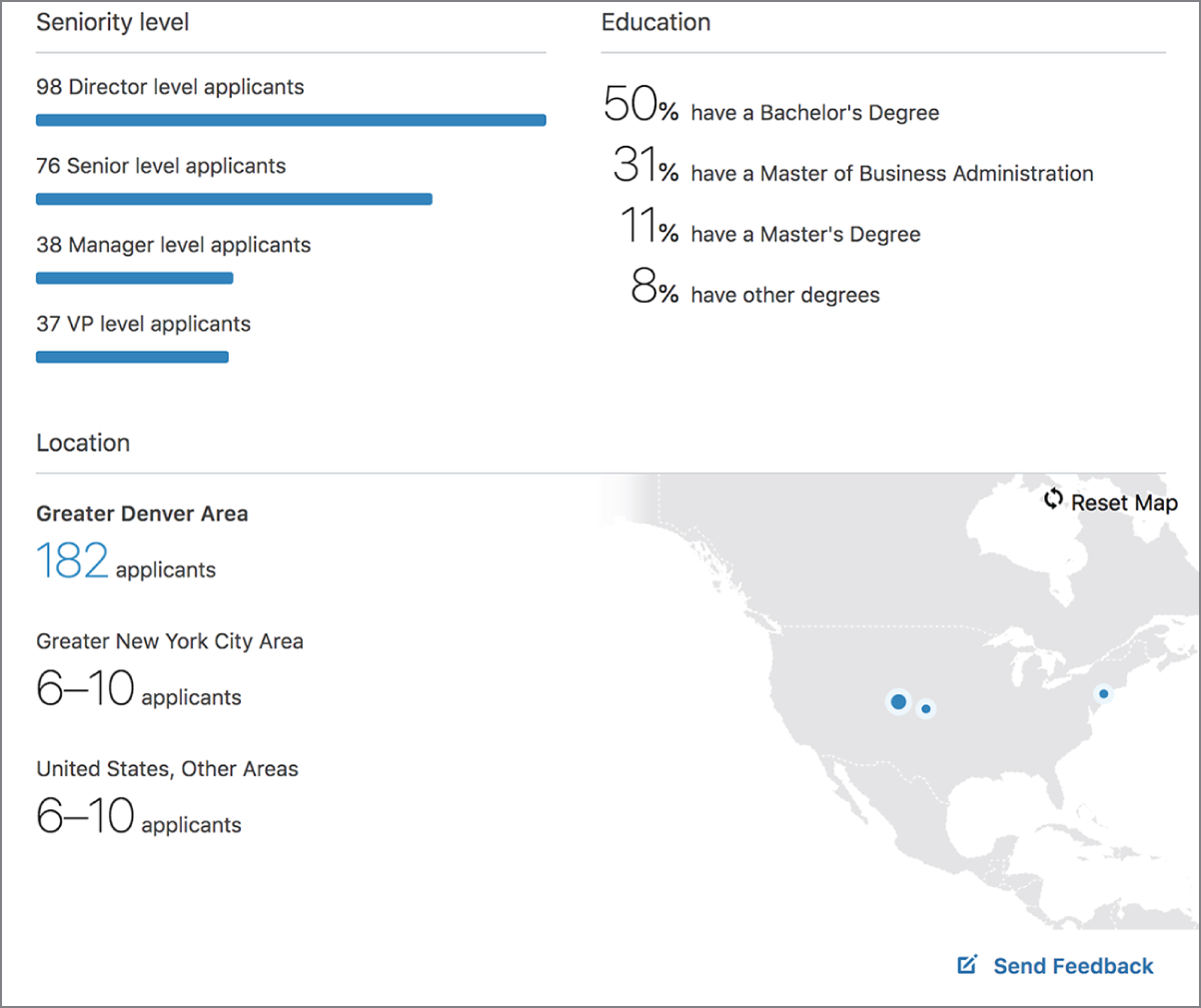
FIGURE 4.9 LinkedIn job statistics
Job listings are another place to look for details beyond the statistics about applicants and the workforce overall. What we can see from these listings is technology that may be in place within the organization. A listing for a network security engineer has requirements as shown in Figure 4.10. While some of these requirements are generic, there are also some that are very specific about the technology in use in the network. For example, it appears that the company may be using CheckPoint and Palo Alto Networks firewalls. Additionally, it has Cisco routers and switches in its network. This is a foothold. We can now start thinking about how to attack that sort of infrastructure. Cisco devices, for sure, have tools that can be run against them for various auditing and attack purposes.

FIGURE 4.10 Job requirements for a network security engineer
We don't have to limit ourselves to the web interface, though, since it can be tedious to keep typing things and flicking through pages. Instead, we can use the program InSpy. This is available as a package that can be installed on Kali Linux. It's a Python script, though, that can be run from anywhere if you want to download it to another system. Running InSpy, we can gather job listings based on a list of technology requirements. If you provide a text file with the technology you want to look for, InSpy will look for jobs at a company you specify that match those technologies.
Beyond jobs, though, we can use LinkedIn to harvest information about people. There are a couple of reasons to look up people. One is just to get some names and titles that you may use later. Another is that even if job descriptions don't have information about technology, when people post their job responsibilities, they very often do. You can also get details about their certifications. Someone with a load of Cisco certifications, for example, is probably employed at a company that has a lot of Cisco equipment. Don't overlook nontechnical roles either. Anyone may provide a little insight into what you may find in the organization. You may get information about telephone systems and document management systems that the company uses, even if the employee isn't an administrator.
Again, we turn to InSpy for a little help here. We provide a text file with titles in it. Providing partial titles works. The text file I am using for our little foray here just has the words engineer, editor, and analyst in it. You'll see in the following code that the titles returned include more words than just those. This means you don't have to be exact about the titles you are looking for. You do have to provide a file, though. InSpy won't just search blindly through LinkedIn for every person at a particular company. In addition to the text file, you tell InSpy what the company you are looking at is. You can see the command line used to call the program as well as a partial listing of people. This particular search returned 59 people, so only some of them are shown here just to give you a sense of the types of responses you can get.
InSpy Results from an Employee Search
$ inspy --empspy title-list-small.txt WileyInSpy 2.0.32018-07-02 16:00:52 59 Employees identified2018-07-02 16:00:52 Felix R Cabral Sr. Avaya Voice Engineer – Voice Infrastructure2018-07-02 16:00:52 Uta Goebel Deputy Editor at Wiley VCH2018-07-02 16:00:52 Janice Cruz (L.I.O.N.) Quality Assurance Analyst at Wiley Education Solut2018-07-02 16:00:52 Coral Nuñez Puras Financial Planning and Analyst in Wiley2018-07-02 16:00:52 Jamie Wielgus Editor at John Wiley and Sons2018-07-02 16:00:52 Stacy Gerhardt Engineer in Training at Wiley|Wilson2018-07-02 16:00:52 Martin Graf-Utzmann Editor at Wiley VCH2018-07-02 16:00:52 James Smith, EIT Mechanical Engineer at Wiley|Wilson2018-07-02 16:00:52 Mohammad Karazoun Software Test Engineer (Product Analyst) at John W2018-07-02 16:00:52 Robert Vocile Strategic Market Analyst at Wiley2018-07-02 16:00:52 Misha Davidof Senior Business Analyst Consultant at Wiley2018-07-02 16:00:52 Aleksandr Lukashevich Automation Testing Engineer at John Wiley and Sons2018-07-02 16:00:52 Ekaterina Perets, Ph.D. Assistant editor at Wiley2018-07-02 16:00:52 Guangchen Xu Editor @ Wiley2018-07-02 16:00:52 Ralf Henkel Editor In Chief at Wiley-Blackwell2018-07-02 16:00:52 sonal jain Wiley India2018-07-02 16:00:52 Abhinay Kanneti QA Automation Engineer at Wiley Publishing2018-07-02 16:00:52 Olga Roginkin, PMP Business Analyst at John Wiley and Sons2018-07-02 16:00:52 Razi Gharaybeh Senior Quality Assurance Engineer at John Wiley an2018-07-02 16:00:52 Daniel Bleyer Senior SCCM Systems Engineer at Wiley2018-07-02 16:00:52 John Coughlan Senior Project Engineer at Wiley2018-07-02 16:00:52 Stephanie Hill Production Editor at Wiley2018-07-02 16:00:52 Jörn Ritterbusch Editor-in-Chief bei Wiley-VCH2018-07-02 16:00:52 Alden Farrar Assistant Editor at Wiley2018-07-02 16:00:52 Gilat Mandelbaum Strategy Analyst Intern at Wiley2018-07-02 16:00:52 Chelsea Meade Pricing Analyst at Wiley2018-07-02 16:00:52 Babak Mostaghaci Associate Editor at Wiley-VCH2018-07-02 16:00:52 Vibhushita Misra Testing Analyst/Testing Team Lead at Wiley2018-07-02 16:00:52 Mohammed Mnayyes Quality Engineer at John Wiley and Sons2018-07-02 16:00:52 David Kim Associate Editor | Society Journals | Wiley2018-07-02 16:00:52 Lauren Elliss Project Engineer at Wiley2018-07-02 16:00:52 Amit Wawdhane Data Analyst at Wiley | Masters in Information Sys
InSpy is not the only utility we can use to do automatic searches in LinkedIn. We can also use theHarvester, just as we did earlier. Instead of search sites like Google or Bing, we can indicate LinkedIn as the data source to search in. Fortunately, this is something theHarvester will do without requiring an API key. Many sites will require API keys to access programmatically. It maintains some level of accountability and prevents the service from being overused or misused.
Another common social networking site or service is Twitter. There is a lot posted to Twitter that can be of some use. Again, programmatic access to Twitter is useful. You can search using the regular interface, but it's sometimes helpful to be able to use other tools. To gain access to Twitter programmatically, you need to get an API key. This means you need to tell Twitter you are creating an application. You can easily tell Twitter you are creating an application without any special credentials through the Twitter developer's website. When you go through the process to create an application, what you are doing is creating identification information that your app needs to interact with the Twitter service. In Figure 4.11, you can see keys and access tokens for an app.
What you may notice in Figure 4.11 is that the app is named recon-ng-me. The reason for this is that I created the app just to get the key and token so I could add it into recon-ng, a tool used for reconnaissance that includes many plugins. Some of these plugins require API keys or access tokens to be able to interact with the service being queried. That's the case with the Twitter plugin. In the following code, you can see the list of API keys that recon-ng uses and the API keys set for Twitter.
FIGURE 4.11 Twitter keys and access tokens
recon-ng Keys
[recon-ng][default] > keys list+———————————————————————––––––––––––––––––––––––––––––––––––––––––––––––+| Name | Value |+—————————————————––––––––––––––––––––––––––––––––––––––––––––––––––––––+| bing_api | || builtwith_api | || censysio_id | || censysio_secret | || flickr_api | || fullcontact_api | || github_api | || google_api | || google_cse | || hashes_api | || ipinfodb_api | || jigsaw_api | || jigsaw_password | || jigsaw_username | || pwnedlist_api | || pwnedlist_iv | || pwnedlist_secret | || shodan_api | || twitter_api | 0DE6bQv89M2AApxCvzfX7AIpd || twitter_secret | jxhcaFu9FS8AK9g4m6N9OrhkuCQoP6A5ppgSdckOIf3zhD3cMK |+—————————————————————–––––––––––––––––––––––––——–––––––––––––––––––––––+
Now that we have the API key in place for Twitter, we can run the module. To run the module, we have to “use” it, meaning we load the module with the use command. Once it's loaded, we have to set a source. In our case, the source is a text string, so it's in quotes, telling recon-ng that we are using a text string for the source. The text string expected here is a user handle. The word recon was selected somewhat randomly and it got results. Once that's done, all we need to do is run the module. You can see loading the module, setting the source, and running it in the following code. The results from the module are truncated because there were quite a few of them, and this is just to show you how to use the module.
Using Twitter Module in recon-ng
[recon-ng][default] > use recon/profiles-profiles/twitter_mentions[recon-ng][default][twitter_mentions] > show optionsName Current Value Required Description------ ------------- -------- -----------LIMIT True yes toggle rate limitingSOURCE default yes source of input (see 'show info' for details)[recon-ng][default][twitter_mentions]> set SOURCE 'recon'SOURCE => 'recon'[recon-ng][default][twitter_mentions]> run-------'RECON'-------[*] [profile] MattyVsTheWorld - Twitter (https://twitter.com/MattyVsTheWorld)[*] [profile] upthevilla76 - Twitter (https://twitter.com/upthevilla76)[*] [profile] davidsummers64 - Twitter (https://twitter.com/davidsummers64)[*] [profile] nastypig99 - Twitter (https://twitter.com/nastypig99)[*] [profile] rothschildmd - Twitter (https://twitter.com/rothschildmd)[*] [profile] CamillaPayne7 - Twitter (https://twitter.com/CamillaPayne7)[*] [profile] Matt5cott - Twitter (https://twitter.com/Matt5cott)[*] [profile] AVFCOfficial - Twitter (https://twitter.com/AVFCOfficial)[*] [profile] CamillaPayne7 - Twitter (https://twitter.com/CamillaPayne7)[*] [profile] Matt5cott - Twitter (https://twitter.com/Matt5cott)[*] [profile] AVFCOfficial - Twitter (https://twitter.com/AVFCOfficial)[*] [profile] yorkshireAVFC - Twitter (https://twitter.com/yorkshireAVFC)
Because we are running the twitter-mentions module, we are using the text string to search for mentions in Twitter. What we get back are profiles from users that were mentioned by a given handle. You could do the reverse of these results with the twitter_mentioned module, which returns profiles that mentioned the specified handle. Finally, we can look for tweets that happened in a given geographic area using the locations-pushpin/twitter module. We can specify a radius in kilometers within which we want to search using this module.
There is another tool that's useful for reconnaissance overall, but since it has Twitter abilities, we'll take a look at it here. Maltego uses a visual approach by creating graphs from the data that has been collected. It can be useful to have entity relationships identified, like parent-child relationships between pieces of data. Maltego uses transforms to pivot from one piece of information to another. A collection of transforms is called a machine, and it's a good place to start. Figure 4.12 shows part of the output from Twitter Digger X, which analyzes tweets from the username provided. As you can see, you get a graph that is structured like a tree. This is because every piece of data collected can potentially yield another piece, which would be a child.

FIGURE 4.12 Maltego graph from Twitter
Maltego can be a good tool to collect reconnaissance data, especially if you want a visual representation of it. While there are several other tools that can collect the same data Maltego does, Maltego does have the advantage of giving you a quick way to collect additional data by just selecting a node on the graph and running a transform on it to pivot to another data collection tool. You can start with a hostname, for instance, and collect an IP address from it by just running a transform.
There are additional Twitter machines and transforms aside from Twitter Digger X. You can also monitor Twitter for the use of hashtags, for example. This will provide a lot of capability, in addition to all of the other capabilities, to search Twitter from inside Maltego.
Job Sites
Earlier we looked at LinkedIn as a source of information. One area of information we were able to gather from LinkedIn was job descriptions, leading to some insights about what technology is being used at some organizations. For example, Figure 4.13 shows some qualifications for an open position. This is for a senior DevOps engineer, and the listing was on indeed.com. While the technologies are listed as examples, you certainly have some starting points. You know the company is using relational databases. This isn't surprising, perhaps, since so many companies are using them. It does tell you, though, that they aren't using NoSQL, which includes things like MongoDB and Redis. You also know that they are using Amazon Web Services. Since they are looking for someone certified there, this is a certainty.

FIGURE 4.13 Job listing with technologies
If you wanted to try to do something through the web application, you know they are using RESTful interfaces for the application. It's not much, but it's a starting point. As you look over job listings, you start to be able to read them with an eye toward picking out potential targets. After you've been reading them for a while, you will start to pick out some of the language of these listings. As an example, the listing uses the word like in several of the lines. While you can't get a complete line on what is used, you can certainly rule some things out, as we did earlier.
There are a lot of places to go looking for job listings. While in the old days, we used newspapers, and you'd have to get a newspaper in the region you wanted to look for a job in (or scare up information about a company you were trying to research), now job postings are everywhere online. Some of the big websites you might use are Monster, Indeed, Glassdoor, CareerBuilder, and Dice. You should also keep the company itself in mind. While many companies use the job posting sites, there may be some companies that post jobs on their own site, and they may not be available elsewhere. You may also check specialized sites like USAJobs and ClearanceJobs.
Any of these job postings may provide you with some insight into not only technology but also organizational structure. As I mentioned earlier, don't focus only on technology listings. You can gather additional information about the company using other job listings that aren't about technology.
Domain Name System
While you can gather a lot of information at a distance, at some point, you need to dive in. This still doesn't mean you are going fully active, but you're going to start gathering details about the scope of what we are dealing with. When you interact with systems on your target, and every other system as well, you need to communicate with an IP address. However, humans aren't good at remembering strings of numbers. Instead, we use hostnames, but that means we need something that will translate these hostnames into IP addresses for us. This is where the DNS comes in.
DNS is a tiered system, and it's tiered in a couple of ways. First is the hostnames we use. I can use an example here to help to demonstrate. www.labs.domain.com is a hostname because it refers to a specific host or system. It's best to read the hostname from right to left, because that's how DNS will read it when it comes time to resolving the hostname to an IP address. In the beginning were the top-level domains (TLDs), and they were .com, .org, and .edu, as well as all the ones for the different countries (.uk, .au, .ca, .sk, .us, and so on). Later, many more were added, but they are all still TLDs. They are considered top-level domains because you might graph DNS like a tree. All the TLDs would be at the top, and then everything grew out from those TLDs.
Second-level domains are where we start adding in organizations. The TLDs belong to the Internet at large, so to speak. They have organizations that manage them, but they don't “belong” to any one organization, at least not in the way the second-level domains can be said to. In our example, the second-level domain would be domain. When people refer to domains, they generally refer to the second-level domain along with the TLD, or domain.com in our example.
Under second-level domains are subdomains. Every domain can have as many levels of subdomains as they are willing to manage. We have a subdomain in the example. The subdomain is labs, and it belongs to the domain domain.com. When we add www, which is the hostname, to the subdomain, the second-level domain, and the TLD, we end up with something called a fully qualified domain name (FQDN). It's fully qualified because it's clear what domain the hostname belongs to (the hostname www, for instance, exists in countless domains) and it's also clear what hostname in the domain we are talking about.
Now that you have a basic understanding of the naming structure used within DNS and a basic understanding of what DNS is used for, we can start looking at how you might use DNS to gather information about your targets. First, we'll start with name lookups. This includes how a name lookup actually works, and then we'll look at some tools that can be used to perform the name lookups. After that, we'll look at doing zone transfers, which are essentially bulk name lookups.
Name Lookups
When you visit a website, you enter something called a Uniform Resource Locator (URL). The URL consists, commonly, of two parts. The first is the Uniform Resource Identifier (URI). This is the protocol used (e.g., http:// or ftp://). Following the URI is the FQDN. Your browser will issue a request to the operating system to open a connection to the FQDN at the port indicated by the URI. Before the connection can be opened, however, the system needs to have an IP address to put into the layer 3 headers. So, it issues a name resolution request. Each computer will have at least one name resolver configured. The name resolver is the system your computer goes to in order to accomplish the name resolution.
The name resolver is a DNS server. It takes in DNS requests and resolves them, based on what is being asked. Typically, the name resolver you will have configured will be what is called a caching name server. This means it gets requests from endpoints, resolves them, and caches the results for efficiency. This is distinct from what is known as an authoritative server, which holds the records for a given domain. We'll get to authoritative servers shortly. So, the first DNS request is the one from your system to the caching server, wherever it happens to be located. Figure 4.14 shows a basic flow of how a complete DNS name resolution would work, so you can follow along there.
We start with the request labeled A. This goes to the name resolver, labeled Caching DNS. The caching DNS server checks its cache and sees that it has no IP address stored, so it begins something called a recursive name query or recursive name resolution. It's called recursive because it will end up with multiple requests that keep getting narrower until we end up with what we want. The caching server will need to start with the TLD. It will have a hints file, indicating the IP addresses for the root name servers. For our example, the caching server will need to identify the server to use for the .com TLD. Once it has identified the server it needs to send a request to, request B goes out, asking the root server for the IP address of the name server for the domain.com domain.
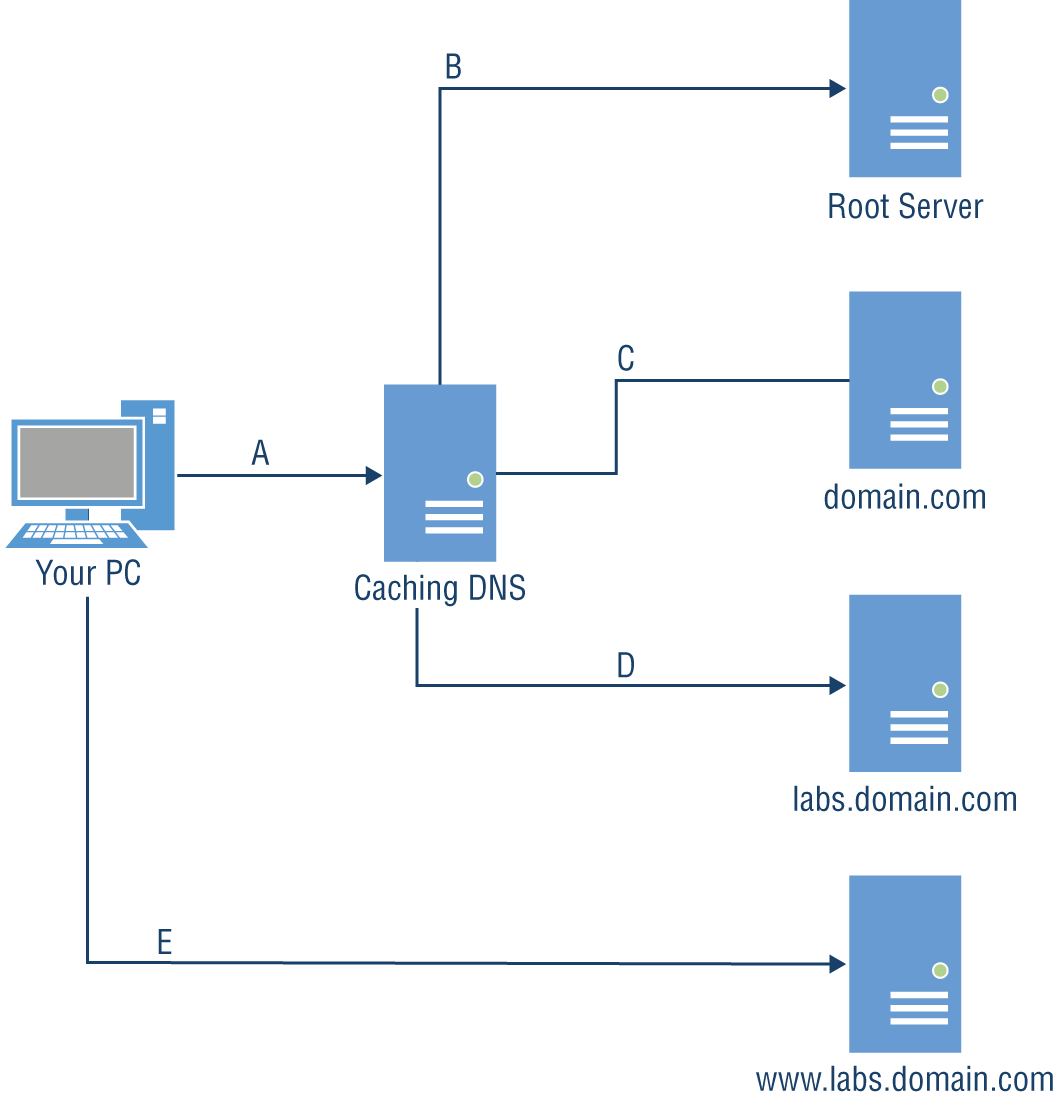
FIGURE 4.14 DNS name resolution
The root server has the name server details for all the domains that fall under the TLD it is responsible for. The root server will reply to our caching server with the IP address for the name server for domain.com. When we did the whois lookups earlier, at the end of a whois lookup on a domain will be the name servers for that domain, since the name servers are stored with the domain. This, though, is why what we are doing is called a recursive query. We can't just ask the root server for the IP address of the hostname, so we have to ask it for a pointer to who to ask next.
Request C is the DNS request asking the name server for domain.com about labs.domain.com. Since labs.domain.com is separate from domain.com, what our caching server gets back is another name server. This means one more request. We are now at the point where the FQDN is being asked for. Request D goes out asking for the IP address of www.labs.domain.com. The authoritative server, which is the one we are asking because it has the authoritative information about that domain, responds with the IP address. It may actually respond with multiple IP addresses, but for our purposes, we're going to just say it comes back with a single IP. Once the caching server has the IP, it sends the response back to our system, which can then issue request E, which isn't a DNS request but a connection request to the web server.
Now that you have a handle on the process we are going through to get IP addresses back from DNS servers, we can start looking at tools we can use to get those addresses.
Using Host
Perhaps the easiest tool to use is host. This is a program that you will find on most Unix-like systems, including Linux systems. It has no Windows analog, unfortunately. If you don't have it installed by default, you can probably get it installed. Using it is very straightforward. You just pass the hostname you want the IP address for to host and you will get a response. You can see an example of that in the following code.
DNS Lookup Using host
$ host www.sybex.comwww.sybex.com has address 208.215.179.132$ host www.sybex.com 4.2.2.1Using domain server:Name: 4.2.2.1Address: 4.2.2.1 # 53Aliases:www.sybex.com has address 208.215.179.132$ host 208.215.179.132132.179.215.208.in-addr.arpa domain name pointer motorfluctuations.net.132.179.215.208.in-addr.arpa domain name pointer managementencyclopedia.org.132.179.215.208.in-addr.arpa domain name pointer smdashboard.wiley.com.132.179.215.208.in-addr.arpa domain name pointer elansguides.com.132.179.215.208.in-addr.arpa domain name pointer currentprotocols.net.132.179.215.208.in-addr.arpa domain name pointer geographyencyclopedia.com.132.179.215.208.in-addr.arpa domain name pointer separationsnow.info.132.179.215.208.in-addr.arpa domain name pointer jcsm-journal.com.132.179.215.208.in-addr.arpa domain name pointer literature-compass.com.
In addition to just a straightforward lookup of a hostname to an IP address, we can use a different server than the one that is defined as our resolver. You can see in the second request, I added an IP address to the command line. This IP address is a caching server that is available for anyone to use. It was created by GTE Internetworking and has been around for at least the better part of a couple of decades at this point. Since it is also a caching server that is open for anyone to use, we can issue requests to it and it will go through the same process described earlier, just as if it were our own caching server.
You can also see from the example, where it says host 208.215.179.132, that you can look up a hostname from an IP address. Every address block will have a DNS server that belongs to it. This means that requests can be issued to the DNS server for an address block to do something called a reverse lookup, meaning that we have an IP address, and we want the hostname that's associated with it. As you can see, often an IP address will have several hostnames associated with it. This may be the case where a web server is hosting virtual servers—meaning the web server can determine what content to serve up based on the hostname in the request. The request for this IP address resulted in 197 responses, but they have been truncated for space.
Using nslookup
Another tool that can be used is nslookup. This can be used just like the program host, meaning you could just run nslookup www.sybex.com and get a response. An advantage to nslookup, however, is that you can issue many requests without having to keep running nslookup. When you run nslookup without any parameters, you will be placed into an nslookup shell, where you are interacting with the program, issuing requests. In the following code, you can see an exchange in nslookup. We are ultimately looking for the same information as we got earlier using host, but we are going about it in a different manner.
Using nslookup for Name Resolution
$ nslookup> set type=ns> sybex.comServer: 192.168.86.1Address: 192.168.86.1#53
Non-authoritative answer:
sybex.com nameserver = jws-edcp.wiley.com.sybex.com nameserver = ns.wiley.co.uk.sybex.com nameserver = ns2.wiley.co.uk.sybex.com nameserver = sg-ns01.wiley.com.sybex.com nameserver = bri-ns01.wiley.com.sybex.com nameserver = ns.wileypub.com.Authoritative answers can be found from:> set type=A> server ns.wileypub.com.Default server: ns.wileypub.com.Address: 12.165.240.53#53> www.sybex.comServer: ns.wileypub.com.Address: 12.165.240.53#53Name: www.sybex.comAddress: 208.215.179.132
Instead of just looking up the IP address from the hostname, I used resource records to start. DNS supports multiple resource records, though the most common is the address (A) record. When you see set type=ns, I'm telling nslookup to issue subsequent requests asking for name server (NS) records. This will tell us the authoritative name servers for the given domain. Once I had the list of NSs, I was able to set the server I was asking to one of the NSs. What this means is that instead of going to my caching server, nslookup is going to issue a DNS request directly to the authoritative server, which wouldn't have to do any recursive search since it has the information being requested.
Using dig
The program dig is another utility that can be used for name resolutions. It also supports the same things we have been doing, meaning we can indicate a different name server and also request different resource records. An example using dig can be seen in the following code. The command line has all the information for the request, including the resource record type, the request, and also the server dig should issue the request to.
Using dig for DNS Lookups
$ dig mx sybex.com @ns.wileypub.com; <<>> DiG 9.10.6 <<>> mx sybex.com @ns.wileypub.com;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37337;; WARNING: recursion requested but not available;; OPT PSEUDOSECTION:; EDNS: version: 0, flags:; udp: 4096;; QUESTION SECTION:;sybex.com. IN MX;; ANSWER SECTION:sybex.com. 900 IN MX 40 alt3.emea.email.fireeyecloud.com.sybex.com. 900 IN MX 10 primary.emea.email.fireeyecloud.com.sybex.com. 900 IN MX 20 alt1.emea.email.fireeyecloud.com.sybex.com. 900 IN MX 30 alt2.emea.email.fireeyecloud.com.;; Query time: 278 msec;; SERVER: 12.165.240.53#53(12.165.240.53);; WHEN: Wed Jul 04 21:03:11 MDT 2018;; MSG SIZE rcvd: 149
The response is quite a bit more detailed than we've seen so far. First, we can see the parameters dig used while it was running. These parameters can be changed as needed. After the parameters, you can see the question section. This makes it very clear what the request was. You can compare that to what you asked for, in case there is any confusion based on what you specified on the command line. Finally, we get the result.
In this example, the type is MX, which is the mail exchanger record. The DNS server will respond with a list of all the mail servers that have been configured in DNS for that domain. When you want to send email to someone, your mail server will issue a DNS request asking which mail server it should be sending mail to for the domain requested. The mail servers are listed with a number. The lowest number is the preferred mail server. If, for whatever reason, you can't reach that mail server, you move on to the next one and so on until you run out of mail servers and have to fail the message.
Using dig, we can do exactly what we did earlier with host and nslookup. On the command line, you indicate the resource record you want. In our command line (
dig mx sybex.com @ns.wileypub.com), mx is the resource record being requested, but it could just as easily be A or NS. It could also be PTR, if we wanted to get back an IP address from a hostname. After the record type is the request. Since we are looking for a mail exchanger record, this would be a domain name, though you could issue an FQDN here, and you would get the mail exchanger records for the last domain that's part of the FQDN. Finally, we indicate the server to ask using the @ sign.
Zone Transfers
Issuing single requests is fine, but it assumes you know some information. In most cases, applications are asking for the information about IP addresses from hostnames so the application can function correctly. In our case, as ethical hackers, we are sometimes looking for all the hostnames that belong to a domain. This can be done using something called a zone transfer. A zone transfer is legitimately used between multiple NSs in a domain to keep the servers in sync. You might have a primary server for a domain and then multiple secondary servers. The secondary servers would issue a zone transfer request to the primary and update their records accordingly.
We can use that capability, theoretically, to request all the records in a domain. Because of this capability, though, two things have happened. First, most domains you will run across won't allow zone transfers from anyone other than the secondary NSs that have been configured. Second, many companies use something called split DNS. Split DNS is where the outside world is given an authoritative server address to use for externally resolvable hosts, like the web server and the mail server. Any system inside the enterprise network would use the company resolver, which would be configured as authoritative for the corporate domain. This means it can have many other systems that are not known or available to the outside world but that internal systems can resolve and connect to.
To issue a zone transfer request, you can use the utilities we've already been using, though there are others. If you wanted to attempt a zone transfer using dig, for instance, the request type would be axfr. You can see an example of using dig to request a zone transfer in the following code.
Zone Transfer Using dig
$ dig axfr domain.com @192.168.86.51; <<>> DiG 9.10.6 <<>> axfr domain.com @192.168.86.51;; global options: +cmddomain.com. 86000 IN SOA ns.domain.com. root.domain.com. 1 604800 86400 24129200 604800domain.com. 86000 IN NS ns.domain.com.blagh.domain.com. 86000 IN A 172.16.56.10ftp.domain.com. 86000 IN A 10.5.6.10lab.domain.com. 86000 IN A 172.16.56.7ns.domain.com. 86000 IN A 192.168.86.51wubble.domain.com. 86000 IN A 172.30.42.19www.domain.com. 86000 IN A 192.168.75.24domain.com. 86000 IN SOA ns.domain.com. root.domain.com. 1 604800 86400 24129200 604800;; Query time: 20 msec;; SERVER: 192.168.86.51#53(192.168.86.51);; WHEN: Thu Jul 05 10:15:27 MDT 2018;; XFR size: 9 records (messages 1, bytes 243)
Brute Force
As zone transfers are generally disallowed, you may have to rely on less elegant solutions to gather information about your target. Fortunately, there are some tools that may be of help here. One is dnsrecon, which can be used to extract some of the common resource records in DNS. Additionally, it can be used to identify hostnames as a result of repeated requests based on a word list provided to the program. In the following code, dnsrecon is used to do a brute-force scan. The word list provided has a number of possible hostnames. These hostnames are prepended to the provided domain name, and then the resulting FQDN is checked. You can see a portion of the results from the scan.
Using dnsrecon to Acquire Hostnames
$ dnsrecon -d wiley.com -D /usr/share/wordlists/dnsmap.txt -t brt[*] Performing host and subdomain brute force against wiley.com[*] A act.wiley.com 209.172.193.49[*] A adc.wiley.com 192.168.5.1[*] A ags.wiley.com 209.172.193.49[*] A api.wiley.com 209.172.192.180[*] A bcs.wiley.com 209.172.193.216[*] CNAME bpa.wiley.com internal-bpa-private-app-prod-elb-405571586.us-east-1.elb.amazonaws.com[*] A internal-bpa-private-app-prod-elb-405571586.us-east-1.elb.amazonaws.com 10.223.11.111[*] A internal-bpa-private-app-prod-elb-405571586.us-east-1.elb.amazonaws.com 10.223.139.133[*] A bpm.wiley.com 10.6.1.241[*] A bps.wiley.com 10.6.2.91[*] A cct.wiley.com 209.172.194.98[*] CNAME cec.wiley.com d1hsh8hpdo3jj3.cloudfront.net
In some cases, looking up an IP address results in an alias. In the output, these show up as canonical name (CNAME) responses. The CNAME refers to another hostname, and that hostname is then resolved until there is an IP address. There can be multiple layers of CNAMEs that need to be resolved. Some of these IP addresses are private, but some others are public IP addresses. These IP addresses could be chased down.
Passive DNS
In practice, there are two different phases of reconnaissance. While there is a lot of focus on gathering information to launch attacks, there is a lot of reconnaissance that happens after exploitation as well. You can perform reconnaissance from the outside as well as from the inside. Once you are on the inside, some of this gets a little easier, or at least we open some other doors for reconnaissance. A technique of using cached DNS entries on a local system is called passive DNS reconnaissance.
Each time you perform a DNS lookup on some systems, the result will be cached locally. This caching of the address saves having to send a network request the next time you want to visit the same host. The length of time the entry will be cached is set by the time to live field in the DNS entry. This begins with the start of authority record (SOA). This indicates when the domain record itself expires. Effectively, this tells anyone looking for information about the domain when they need to check again to see who the authoritative domain name servers are. There are NS records associated with every domain indicating what servers to ask for answers about that domain. These authoritative servers should always be asked unless a record is cached locally, whether directly on the client requesting the information or the local caching server the client is asking.
In addition to the SOA record providing the timeout length for the domain itself, meaning the length of time you can rely on the name servers being valid before needing to check again, each individual record stored in DNS can have a time to live (TTL) value. This indicates how long any system can cache the result before checking again with the authoritative DNS server to ensure the value hasn't changed. According to the specification for DNS, you don't wait until the very end of the lifetime of an entry but instead use some value that is less than the full TTL. The TTL does provide guidance, though, on how long to hold on to a value in your local cache.
Windows systems will cache values, and you can dump the cache on them, as you can see in the partial dump that follows here. To dump the cache on a Windows system, you would use command-line access, either the old command line or, using a PowerShell-based command line, you would just run ipconfig /displaydns. On Linux systems, you can do the same thing only if your system is running a caching server. This may be a program like dnsmasq, which does DNS forwarding, or it could be the nscd service, which is the name server caching daemon. You'll see for each of the records here, there is a time to live (TTL) value.
PS C:UsersRic Messier> ipconfig /displaydnsWindows IP Configurationvortex.data.microsoft.com----------------------------------------Record Name . . . . . : vortex.data.microsoft.comRecord Type . . . . . : 5Time To Live . . . . : 24Data Length . . . . . : 8Section . . . . . . . : AnswerCNAME Record . . . . : asimov.vortex.data.trafficmanager.netRecord Name . . . . . : asimov.vortex.data.trafficmanager.netRecord Type . . . . . : 1Time To Live . . . . : 24Data Length . . . . . : 4Section . . . . . . . : AnswerA (Host) Record . . . : 64.4.54.254array511.prod.do.dsp.mp.microsoft.com----------------------------------------Record Name . . . . . : array511.prod.do.dsp.mp.microsoft.comRecord Type . . . . . : 1Time To Live . . . . : 1489Data Length . . . . . : 4Section . . . . . . . : AnswerA (Host) Record . . . : 52.184.213.211.0.0.127.in-addr.arpa----------------------------------------Record Name . . . . . : 1.0.0.127.in-addr.arpa.Record Type . . . . . : 12Time To Live . . . . : 541542Data Length . . . . . : 8Section . . . . . . . : AnswerPTR Record . . . . . : kubernetes.docker.internaldownload.visualstudio.microsoft.com----------------------------------------Record Name . . . . . : download.visualstudio.microsoft.comRecord Type . . . . . : 5Time To Live . . . . : 33Data Length . . . . . : 8Section . . . . . . . : AnswerCNAME Record . . . . : 2-01-5830-0005.cdx.cedexis.netRecord Name . . . . . : 2-01-5830-0005.cdx.cedexis.netRecord Type . . . . . : 5Time To Live . . . . : 33Data Length . . . . . : 8Section . . . . . . . : AnswerCNAME Record . . . . : 4316b.wpc.azureedge.netRecord Name . . . . . : 4316b.wpc.azureedge.netRecord Type . . . . . : 5Time To Live . . . . : 33Data Length . . . . . : 8Section . . . . . . . : AnswerCNAME Record . . . . : cs10.wpc.v0cdn.netRecord Name . . . . . : cs10.wpc.v0cdn.netRecord Type . . . . . : 28Time To Live . . . . : 33Data Length . . . . . : 16Section . . . . . . . : AnswerAAAA Record . . . . . : 2606:2800:11f:7de:d31:7db:168f:1225array513.prod.do.dsp.mp.microsoft.com----------------------------------------Record Name . . . . . : array513.prod.do.dsp.mp.microsoft.comRecord Type . . . . . : 1Time To Live . . . . : 1202Data Length . . . . . : 4Section . . . . . . . : AnswerA (Host) Record . . . : 52.184.214.53
If you are doing external reconnaissance, this technique is unlikely to be of much use to you. Once you gain access to the inside of the network, though, you want to know all of the systems and IP addresses. From the outside, you can query open sources for details about address blocks that may be owned by the organization. On the inside of the network, they are probably using private addresses. There is no record anywhere of the blocks being used, unless you happen to get access to a network management system that records all the address blocks. Instead, what you can do is dump the DNS cache on a system you have access to. What you will get is not only hostnames but also the IP addresses that resolve to those hostnames. If you see a lot of entries for the domain owned by the company in the cache dump, you may well be seeing internal DNS records. Another way you may know you have internal addresses is if you see something that ends in .local. This is a top-level domain that can't be used across the Internet, so it is sometimes used as a top-level domain (the last part of the fully qualified domain name that includes the hostname and the domain name) for internal DNS implementations.
It is common for companies to use an implementation called split DNS, where there is one server for the outside world, with a limited number of records. Typically, you'd have hostnames for any system that exposes essential services to the outside world. On top of the external DNS, there is probably an internal DNS. This is where all the systems inside the network get registered so you can use hostnames rather than IP addresses. Your own system on an enterprise network may register with the DNS server so someone trying to get to your system would just refer to the hostname of your system and be able to resolve that hostname to an IP address.
Passive Reconnaissance
There is a lot of information that can be collected in a passive manner. For example, watching the network headers as they go by, from the layer 3 headers to the application headers, can turn up some interesting information. While it can be time-consuming to capture packets and try to read through them manually, there is a program that will do a lot of that work for us. The program is p0f, and it will sit and watch network traffic as it passes by the interface, making observations as the traffic passes. Unfortunately, p0f isn't as useful as it once was. The reason for that has nothing to do with p0f but more to do with the fact that web servers are generally encrypting traffic by default, which means p0f can't watch the HTTP headers, identifying the server and other useful information. Here you can see some of the output from p0f.
Output from p0f
.-[ 192.168.86.45/46112 -> 8.43.72.22/443 (syn) ]-|| client = 192.168.86.45/46112| os = Linux 3.11 and newer| dist = 0| params = none| raw_sig = 4:64+0:0:1460:mss*20,7:mss,sok,ts,nop,ws:df,id+:0|`----.-[ 192.168.86.45/46112 -> 8.43.72.22/443 (mtu) ]-|| client = 192.168.86.45/46112| link = Ethernet or modem| raw_mtu = 1500|`----.-[ 192.168.86.45/46112 -> 8.43.72.22/443 (uptime) ]-|| client = 192.168.86.45/46112| uptime = 48 days 7 hrs 54 min (modulo 49 days)| raw_freq = 1000.00 Hz|`----.-[ 192.168.86.45/33498 -> 52.94.210.45/443 (syn) ]-|| client = 192.168.86.45/33498| os = Linux 3.11 and newer| dist = 0| params = none| raw_sig = 4:64+0:0:1460:mss*20,7:mss,sok,ts,nop,ws:df,id+:0|`----.-[ 192.168.86.45/33498 -> 52.94.210.45/443 (host change) ]-|| client = 192.168.86.45/33498| reason = tstamp port| raw_hits = 0,1,1,1|`----
Very little of what you see here is anything you wouldn't be able to determine yourself if you knew how to read packet headers. The packet capture and analysis program Wireshark could provide much of this information. Some of the interesting bits, though, include identifying system uptime. This is the uptime on systems on my local network, so it's less interesting, perhaps, than it would be if we could so easily identify uptime on remote systems. You can also see that p0f is able to identify the operating system type on some systems. It happens to be the system that p0f is running on, but it makes the determination based on the network headers since operating systems have different “signatures” that are based on how the IP identification number is generated, how the TCP sequence number is generated, how ephemeral port numbers are selected, and other pieces of information p0f can collect.
While we are talking about passive reconnaissance, we should look at some web-based tools that suggest they do passive reconnaissance. One of them was named Passive Recon, though it hasn't been updated in years and may not be available. It can be found as an add-on for Firefox, but only for certain versions of Firefox. One of the nice things about Passive Recon, though I'm not sure it could be properly called passive reconnaissance, is that it made DNS, whois, and related tools available as a context menu selection on any link. You could quickly get information about the site you had selected.
If Passive Recon isn't available, you can take a look at some other tools. One of them, though it doesn't behave quite the same, is R3con. This is a plugin for Firefox. When you activate it, a window that looks like what you see in Figure 4.15 opens. You will have multiple tabs with edit boxes on them, expecting input depending on what you want to look up. The tab shown is the whois tab, which expects a domain name or an IP address, just as when we used whois earlier.

FIGURE 4.15 Recon with R3con
You may not be using Firefox, though what you'll probably find is that the browser that has the majority of plugins that are useful for security testing is Firefox. I used to joke that Firefox was the browser that was insecure enough to allow plugins access to do all sorts of bad things. This isn't true, of course. Plugins have been around for Firefox much longer than for other browsers, so the development community has been around for a while. Other browsers, like Chrome, can be much more restrictive in what they will allow developers to do, though, which also makes Firefox more attractive.
One plugin or extension available in Chrome is Recon. This is much like Passive Recon in that it provides a context menu when you right-click a link in a page. The Recon menu gives you quick access to look up information about the link or word you have selected. You can do Google or Bing searches, for example, and Recon will open a new tab or window with the results of a search on what you have selected. You can also get translations of words, do package tracking, search video sites, and perform a number of other quick searches where your selection is passed into the site you have selected from the menu.
These sorts of tools can be invaluable to quickly search for answers, though they aren't passive reconnaissance in the same sense that watching network traffic is. However, this is not at all to say that the information you can get from these tools isn't valuable. Any tool that can save you time and maybe even expose you to a new technique you could add to your arsenal is very valuable. Even with all of this, there is still information we can look at that we haven't seen as yet.
Website Intelligence
It would be difficult to find a company that had no web presence at all. It's possible, of course, though it's unlikely. Even small companies probably have a page on Facebook to show the hours they are open. Companies that may be most prone to need the services of an ethical hacker to perform testing will likely have a website. It may even have programmatic elements. Any site that has programmatic elements has the potential to be compromised. Web applications are a common point of attack for adversaries. This is all to say that gathering intelligence about a website can end up bearing fruit.
Starting from the bottom of the stack, we can look at what the web server is as well as the operating system. One way to get some of this information is just to connect to the web server and issue a request to it. In the following code, you can see the HTTP headers returned from a request to a website. While we don't get the actual web server name, we do get some interesting information.
Gathering Website Intelligence
HTTP/1.1 301 Moved PermanentlyServer: CloudFrontDate: Fri, 06 Jul 2018 22:56:29 GMTContent-Type: text/htmlContent-Length: 183Connection: keep-aliveLocation: https://www.wiley.com/X-Cache: Redirect from cloudfrontVia: 1.1 3fed6f40ae58f485d8018b6d900fcc88.cloudfront.net (CloudFront)X-Amz-Cf-Id: S_FZ4mwkJ9wY_aW24hHF3yCVvnGNNrFu6t52DGNJyc74o0iswv7Suw==
There is actually an easier way to do this. The website netcraft.com will give hosting history for websites. This will provide the owner of the netblock that contains the IP address. It will also tell you the operating system the web server runs on. In some cases, you will get details about the web server version and other modules that have been enabled. One of the domains I have has been around for a long time, and Figure 4.16 shows the hosting history for that domain. In 2001, the site was hosted on an OpenBSD system (Netcraft says NetBSD/OpenBSD, but since I was hosting it myself, I know it was OpenBSD). You can also see that it was running on Apache at that time.
FIGURE 4.16 Netcraft hosting history
While the history is interesting, it's far more relevant to know what the technology for the website is now. The top line is the most recent. Currently, the site is hosted on IIS with the network block being owned by Microsoft. That suggests that Microsoft is hosting this site, and since it's IIS, the operating system would be Windows Server. What we don't know is what version of Windows Server. The reason this information is useful is that we may be able to get a leg up on vulnerabilities. If we have some hints about versions, we would have a much better idea what vulnerabilities exist on the system where the website is hosted.
This only gives us the operating system and the web server. These days there is far more technology being used in websites. Static pages are written in HTML, but it's far more likely that you'll be running up against a dynamic site. This means you may find a site written in the PHP or Java programming language. The language itself isn't enough to provide the deep functionality needed by a robust web application. Instead, website programmers are apt to use frameworks. The frameworks can have vulnerabilities, as exhibited by the Experian data breach, which used a vulnerability in the Spring framework used by Java-based applications.
Back to the land of web browser plugins we go. One that is really good is Wappalyzer. Wappalyzer can be added to both Chrome and Firefox. When you visit a website, Wappalyzer will provide a list of technologies it identifies. This may include the web server, programming frameworks, ad networks, and tracking technology. It's not always successful in identifying everything. Going to www.google.com turns up the Google web server and an analytics framework. However, visiting CNN turns up a lot of different technologies, some of which you can see in Figure 4.17. What we don't get there is the web server being used by CNN. We will take what we get, though, considering all the other technologies in use on the site.
FIGURE 4.17 Wappalyzer for technology
There are other ways you can dig into web pages and the technologies used. One of them is Firebug. It's available on Firefox, though there is also Firebug Lite that's available in Chrome. Firebug Lite doesn't have quite the same capabilities as the full Firebug. However, on Chrome, Google has provided the developer tools. Using either the Chrome developer tools or Firebug, you can perform a deep investigation of the page you are looking at. To begin with, you can look at the document object model (DOM) and all of its components. You can also select different HTML elements in the page and identify styles and properties applicable to that section. Figure 4.18 shows a portion of the information that you can get using the Chrome developer tools. The page being inspected here is a Google search page. Using a tool like this, you can get a better understanding of how the page operates by looking at all the elements of the page and how they relate to one another.
FIGURE 4.18 Chrome developer tools
Websites are complex creatures. The Chrome developer tools and Firebug are capable of looking at only a page at a time. You'd have to dig through every page, one at a time, to investigate them and their capabilities. You may find it easier to mirror the website so you could look at it offline. With it stored locally, you could look at the pages as many times as you would like without needing to issue repeated requests to the remote server. While the requests aren't likely to raise any eyebrows and aren't even likely to be noticed, you are leaving tracks behind. One tool you can use to mirror the website is HTTrack. In the following code, you can see the results of running HTTrack to mirror a website. The program will essentially perform a spider on the remote site, storing the results in the directory provided.
Mirroring Sites with httrack
$ httrackWelcome to HTTrack Website Copier (Offline Browser) 3.49-2Copyright (C) 1998-2017 Xavier Roche and other contributorsTo see the option list, enter a blank line or try httrack --helpEnter project name :MySiteBase path (return=/root/websites/) :Enter URLs (separated by commas or blank spaces) :http://www.domain.comAction:(enter) 1 Mirror Website(s)2 Mirror Website(s) with Wizard3 Just Get Files Indicated4 Mirror ALL links in URLs (Multiple Mirror)5 Test Links In URLs (Bookmark Test)0 Quit: 1Proxy (return=none) :You can define wildcards, like: -*.gif +www.*.com/*.zip -*img_*.zipWildcards (return=none) :You can define additional options, such as recurse level (-r<number>),separated by blank spacesTo see the option list, type helpAdditional options (return=none) :
Once you have the HTML, you can do anything you want with it. You can make changes, review all the scripts that are included in the pages, and review the pages as you need to. Not all technology is in the website, though. Organizations have a lot of other technology that can generally be mined using a variety of tools and techniques.
Technology Intelligence
Ultimately, your goal as an ethical hacker is to identify vulnerabilities within the organization you are working for. While web interfaces are an attractive place to play and look for vulnerabilities, considering how much sensitive data can be available through web interfaces, it's not the only place to look for vulnerabilities. However, you can still make use of websites to continue to explore the bounds of technology within your target company. So far, we've identified job sites and some social networking sites in order to gain intelligence about technology in use at a target. Beyond that, we can look at a couple of other areas. The first is to help really focus our web searches using Google dorks, also known as Google hacking. Additionally, we can look for devices that are part of the so-called Internet of Things (IoT).
Google Hacking
Google hacking is an important skill to have. It will improve the search responses, saving you a lot of time clicking through pages that aren't especially valuable. Once you know some of the keywords that can be used to really narrow your searches, you'll save time and become more efficient. The Google hacking techniques will help you to identify technology and vulnerabilities. In addition to Google hacking techniques, there is the Google hacking database, which is a collection of Google dorks that have been identified by someone as a way to search for a number of things. A dork is a string using Google keywords, designed to search for useful responses.
First, the Google keywords. If you've been using search engines for a long time, you may be familiar with the use of quotation marks and Boolean terms to help ensure that you are getting the right strings in your responses. In addition to those, Google uses positional keywords. You may, for instance, want to look only in the URL for a particular string. To search in the URL, you would use inurl as in the example, inurl:index. This example would find pages that included the word index anywhere in the URL. This might typically be a page like index.html, index.php, or index.jsp. If you wanted to ignore the URL and only search in the text, you could use the keyword intext.
Since you are working for an organization, you have one domain or maybe a small handful of domains. This means you will, at some point, want to search only within those domains. To do that, you can use the site keyword. You may also want to limit your results to a single filetype, such as a portable document format (PDF) file or a spreadsheet. To limit your results to just one filetype, you would use the filetype keyword. Perhaps you are looking for all PDF documents about Windows 10 on Microsoft's site. Figure 4.19 shows the search used for that (site:Microsoft.com filetype:pdf “Windows 10”) as well as a number of results.
A great place to look for examples of useful Google dorks is the Google Hacking Database (https://www.exploit-db.com/google-hacking-database/). The Google Hacking Database (GHDB) stores search terms in several categories, including footholds, vulnerable files, error messages, and sensitive directories. Creating these useful search strings requires that you know not only about the Google hacking keywords but also about what you are looking for. Some examples are in Figure 4.20, where the search strings are looking for network or vulnerability data. This means that someone would have had to know exactly what would be in a page or URL that would include this data. Figure 4.20 shows some of these.

FIGURE 4.19 Google hacking results
Spending time at the GHDB can provide you with a lot of ammunition for looking for possible issues within your target. Some of this will be blind, if you have no idea what to expect within your target. To make sure you are only searching within your target, of course, you would need to add site: and the domain name to your search parameters. One thing you may have noticed from the Microsoft search in Figure 4.20 is that when only the domain was used, every possible hostname came back. If you want to search only within a single hostname, such as www.microsoft.com, you would provide the hostname. Only providing the domain will be another way to catch additional hostnames that you may not have been able to get using DNS searching.
FIGURE 4.20 Google Hacking Database
Internet of Things (IoT)
You will likely have heard about the IoT. The IoT is made up of devices that may have little to no input or output capabilities, at least from a traditional standpoint. If a device can run general applications and also has a keyboard and a screen, such as a computer, tablet, or smartphone, it's not part of the IoT. Many other devices, like network-connected thermostats, light bulbs, fans, refrigerators, and a number of other essentially single-purpose devices, are IoT devices. Many companies are making use of this in different automation capacities.
These devices can be useful when it comes to infiltrating a system. Malware like Satori can infect multiple IoT devices, and once infected, those devices can be used to attack other systems. They may also be good starting points into the enterprise network, depending on the device. This is another area where search engines, though, can be helpful to us. Shodan (www.shodan.io) is a search engine specifically for IoT devices. Shodan keeps track of a large number of devices along with vendors, device types, and capabilities.
Shodan also requires understanding your target and what can be used to identify these devices. Figure 4.21 shows an example. The search term is port:20000 source address, which identifies Distributed Network Protocol (DNP) 3 devices. This is another area where the site can be a lot of help. The search for DNP3 devices came as a result of clicking a link for Industrial Control Systems (ICSs) and looking at different protocols that Shodan knows about. Shodan also associates with ICS the Factory Interface Network Service (FINS), Highway Addressable Remote Transducer Protocol, and many others. There are also searches for different vendors.
One thing you may notice in the statistics is the fact that the United States is on top of all countries with these devices. Shodan also identifies organizations where the devices are located. Clicking individual results provides more details, including where the device is located. Figure 4.22 shows some of those results, though it doesn't show the map that Shodan provides, presumably indicating exactly where the device is located.
FIGURE 4.21 Shodan search for DNP3
FIGURE 4.22 Shodan results
Shodan is an excellent resource when it comes to identifying devices that are considered part of the IoT. Using searches of the Shodan database, you can identify devices that may exist on the target network.
Summary
Footprinting and reconnaissance are important activities in an overall methodology when it comes to ethical hacking. This is the stage where you collect a lot of data that you will use later. It's also a stage where you don't want to make a lot of noise. You're sneaking up on someone to scare them. If you make noise, you get no startled reaction from your target. The same is true here. You want to do your work ahead of time so when you get started, you aren't registering a lot of activity that could get you detected and the next thing you know, you've been locked out.
If you are interested to see techniques, tactics, and procedures we know real-life attackers used, you can refer to the MITRE ATT&CK Framework and get some ideas of how those attackers may operate. This can help you ensure you are providing a full set of testing to the organization you are working with.
There are multiple sources of intelligence that are freely and openly available. Using sources like the SEC's EDGAR database, you can obtain information about companies. Job sites can also provide you with details about a company that may be useful later. This includes the technology they may be using, since when they hire people, they generally provide job requirements, including technology vendors like Microsoft, Red Hat, Cisco, and Palo Alto Networks. You can also read reviews from employees that may have useful data.
Social network sites can be used to gather information about people, as well as companies. The people sometimes post information about their jobs or the company in general. Social engineering is a common attack technique, and this attack technique can be more successful if you know how to target individuals. You can also gather information about the companies themselves. Often, companies will have a social network presence. Additionally, there are sites like LinkedIn that are focused on businesses and business interactions.
The Internet requires data to function. This includes who has been allocated addresses. These allocations go through RIRs. You can use tools like whois to gather some of this data from the RIRs. The program whois can also be used to gather registration details about domains. This would include addresses, phone numbers, and contact information. Not all domains will have this information since registrars will sometimes hide the details of the registrant. What you'll get is the registrar's contact information and address and not the organization. What you will also get out of this is the registered NSs for the domain. These are the NSs considered to be authoritative for the domain.
DNS contains a lot of detail about a company if you can find it. The quickest way to get all of the hosts is to do a zone transfer, but it would be unlikely for zone transfers to be allowed. Instead, you may have to resort to something like brute-forcing DNS requests to guess possible hostnames. From this, you will get hostnames that can become targets. You will also get IP addresses. These IP addresses can be run through whois to get the network block and the owner of the block. You may get ranges of IP addresses that belong to the company from doing that.
It's a common tactic for companies to have both internal and external DNS servers. This helps protect the company by not exposing internal systems to the outside world. Once you have access to the inside of the network by compromising some system, you can look at the DNS cache. This is done on Windows systems by running ipconfig /displaydns. This will show all of the cached DNS entries, meaning hostname/IP mappings that were resolved at some point and are being stored to help speed up the resolution the next time an application needs the IP address. A cached entry will mean a network request doesn't have to be made, which can save time.
Many attacks take place through web interfaces. While gathering details about a web server or the technologies used in a website isn't entirely passive, meaning using third-party sources, making common requests to a web server shouldn't be noticed much. As long as you aren't sending too many requests all at once or sending something unusual, you'll get lost in the noise of all the other regular requests.
Google hacking is a technique you can use to narrow your search and get results that are focused and relevant. Google hacking is a technique that makes use of keywords like site, inurl, intext, filetype, and link to get very specific results. One of the most useful will be the site keyword, which means you are searching within only one domain. This means you are only looking at results within the organization you are testing for. If you need help identifying search terms that may help you identify vulnerabilities, you can use the Google Hacking Database.
People and businesses are often using devices that have a network connection but don't have traditional means for users to interact with them. This often means these devices can be vulnerable to attack. All these devices are called the Internet of Things (IoT). There are sites like Shodan that can be used to identify these embedded devices. Shodan will provide a lot of details about a device, including the IP address and where the IP address is located. You should be able to narrow down whether the device belongs to your target company using a site like Shodan.
Review Questions
You can find the answers in the appendix.
- If you were checking on the IP addresses for a company in France, what RIR would you be checking with for details?
- ARIN
- RIPE
- AfriNIC
- LACNIC
- You need to identify all Excel spreadsheets available from the company Example, Inc., whose domain is
example.com. What search query would you use?- site:
example.comfiles:pdf - site:excel files:xls
- domain:
example.comfiletype:xls - site:
example.comfiletype:xls
- site:
- If you found a colleague searching at
pgp.mit.edu, what would they likely be looking for?- Email addresses
- Company keys
- Executive names
- Privacy policies
- What information could you get from running
p0f?- Local time
- Remote time
- Absolute time
- Uptime
- The DNS server where records for a domain belonging to an organization or enterprise reside is called the ____________ server.
- Caching
- Recursive
- Authoritative
- Local
- What strategy does a local, caching DNS server use to look up records when asked?
- Recursive
- Serial
- Combinatorics
- Bistromathics
- What would you use a job listing for when performing reconnaissance?
- Executive staff
- Technologies used
- Phishing targets
- Financial records
- What tool could be used to gather email addresses from PGP servers, Bing, Google, or LinkedIn?
-
whois -
dig -
netstat - theHarvester
-
- What social networking site would be most likely to be useful in gathering information about a company, including job titles?
- Foursquare
- You see the following text written down—port:502. What does that likely reference?
- Shodan search
- I/O search
-
p0fresults - RIR query
- What would you use Wappalyzer for?
- Analyzing web headers
- Analyzing application code
- Identifying web headers
- Identifying web technologies
- What technique would you ideally use to get all the hostnames associated with a domain?
- DNS query
- Zone copy
- Zone transfer
- Recursive request
- What information would you not expect to find in the response to a
whoisquery about an IP address?- IP address block
- Domain association
- Address block owner
- Technical contact
- What would you be looking for with the filetype:txt Administrator:500: Google query?
- Text files owned by the administrator
- Administrator login from file
- Text files including the text Administrator:500:
- 500 administrator files with text
- What command would you use to get the list of mail servers for a domain?
whois mx zone=domain.comnetstat zone=domain.commxdigdomain.com@mx-
dig mxdomain.com
- What would you get from running the command
dig nsdomain.com?- Mail exchanger records for
domain.com - Name server records for
domain.com - Caching name server for
domain.com - IP address for the hostname
ns
- Mail exchanger records for
- If you wanted to locate detailed information about a person using either their name or a username you have, which website would you use?
- If you were looking for detailed financial information on a target company, with what resource would you have the most success?
- EDGAR
- MORTIMER
- What financial filing is required for public companies and would provide you with the annual report?
- 10-Q
- 11-K
- 401(k)
- 14-A
- If you were looking up information about a company in New Zealand, which RIR would you be looking in for data?
- AfriNIC
- RIPE
- APNIC
- LACNIC