
CHAPTER SEVEN
Data Science, Machine Learning, and Artificial Intelligence
The purpose of data science is to enable better decision making. Data scientists develop techniques to systematically derive insights from data. As a data scientist, you want to quickly and interactively analyze large datasets, and then share your work, communicate your insights, and operationalize your models. This process involves several key steps that are performed by different functions in companies but that can be performed by one person end-to-end. The role depends on the size and maturity of the team.
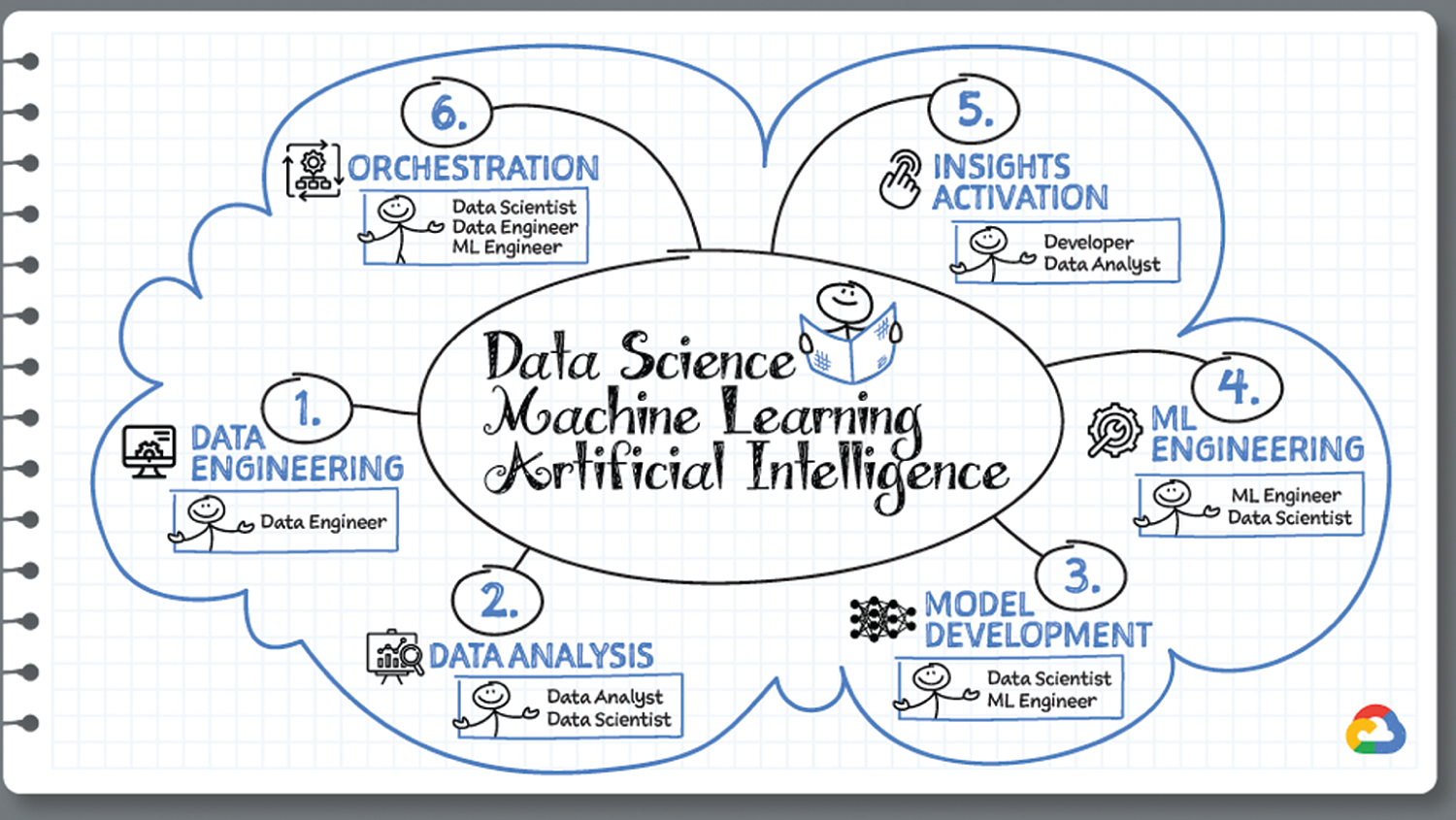
- Data Engineering — Ingest, process, and analyze real-time or batch data from a variety of sources to make data more useful and accessible. For this step, data lakes and data warehouses empower teams to securely and cost-effectively ingest, store, and analyze large volumes of diverse, full-fidelity data.
- Data Analysis — Perform data exploration, processing, and analysis in a consistent and shareable way.
- Model Development — After feature engineering, train your model and then evaluate it to see how well it is performing.
- ML Engineering — Deploy the model, serve it, and then monitor it continuously to make sure it consistently performs the way it needs to.
- Insights Activation — Use insights derived from your data to make better business decisions, influence consumer decisions, and power applications.
- Orchestration — Apply pipelines, scheduling, and CI/CD to your ML models.
In addition to offering solutions for these fundamental steps, Google Cloud offers prebuilt AI services for complex tasks (such as item matching and document form parsing) because you don't want to have to build absolutely everything from scratch. This chapter covers the Google Cloud ML and AI services that will help make your data science journey easier.
Data science is the practice of making data useful. Let's look at the most common stages in the data science workflow.
Data Engineering
The greatest missed opportunities in data science stem from data that hasn't been made accessible for use in further analysis. Laying the critical foundation for downstream systems, data engineering involves the transporting, shaping, and enriching of data for of making it available and accessible.
Data ingestion is moving data from one place to another, and data preparation is the process of transformation, augmentation, or enrichment before consumption. Global scalability, high throughput, real-time access, and robustness are common challenges in this stage.
Data engineering typically falls under the responsibility of data engineers is such a critical stage in the overall practice of making data useful.
Data Analysis
This step includes data exploration, processing, and analysis. From descriptive statistics to visualizations, data analysis is where the value of data starts to appear. Data exploration, a highly iterative process, involves slicing and dicing data via data preprocessing before data insights can start to manifest through visualizations or simple group-by, order-by operations.
One hallmark of this phase is that the data scientist may not yet know which questions to ask about the data. In this somewhat ephemeral phase, a data analyst or scientist has likely uncovered some aha moments but hasn't shared them yet. Once insights are shared, the flow enters the Insights Activation stage.
Typically, data analysis falls under the responsibility of the data analyst and data scientist, who are charged with the first phase of understanding the data and the potential insights to be gained.
Model Development
This stage is where machine learning (ML) starts to provide new ways of unlocking value from your data. Experimentation is a strong theme here, with data scientists looking to accelerate iteration speed between models without worrying about infrastructure overhead or context-switching between tools for data analysis and tools for productionizing models with MLOps.
MLOps is the industry term for modern, well-engineered ML services, with scalability, monitoring, reliability, automated CI/CD, and many other characteristics and functions. While model training is a big step in this stage, feature engineering, feature store, ML metadata, model registry, and model evaluation are the supplementary steps needed for an effective and continuous ML development.
Data scientists are typically responsible for this step, along with ML engineers.
ML Engineering
Once a satisfactory model is developed, the next step is to incorporate all the activities of a well-engineered application life cycle, including testing, deployment, and monitoring. All of those activities should be as automated and robust as possible. This is where ML engineers come in to deploy and scale the model, making sure the model can scale as the consumption increases.
Continuously monitoring the model becomes critical because after you deploy a model in production, the input data provided to the model for predictions often changes. When the prediction input data deviates from the data that the model was trained on, the performance of the model can deteriorate, even though the model itself hasn't changed.
Insights Activation
This is the step where your data becomes useful to different teams and processes. It can influence business decisions with charts, reports, and alerts. It can also influence customer decisions such as increasing usage, decreasing churn, and other such metrics. Other apps and API can also use this data for users.
Developers, business intelligence, and data analysts are all typically involved in insights activation depending on the use case.
Orchestration
All of the capabilities we have discussed provide the key building blocks to a modern data science solution, but a practical application of those capabilities requires orchestration to automatically manage the flow of data from one service to another. This is where a combination of data pipelines, ML pipelines, and MLOps comes into play. Effective orchestration reduces the amount of time that it takes to reliably go from data ingestion to deploying your model in production, in a way that lets you monitor and understand your ML system.
Many users within an organization play important roles in the machine learning (ML) life cycle. There are product managers, who can simply type natural language queries to pull necessary insights from BigQuery; data scientists, who work on different aspects of building and validating models; and ML engineers, who are responsible for keeping the models working well in production systems. Each of these roles involves different needs; this section covers the Google Cloud ML/AI services that are available to help meet those needs.
The services that will work best for you will depend on your specific use case and your team's level of expertise. Because it takes a lot of effort and ML expertise to build and maintain high-quality ML models, a general rule of thumb is to use pretrained models or AI solutions whenever possible — that is, when they fit your use case. If your data is structured, and it's in BigQuery, and your users are already comfortable with SQL, then choose BigQuery ML. If you realize that your use case requires writing your own model code, then use custom training options in Vertex AI. Let's look at your options in more detail.
Prepackaged AI Solutions
Both pretrained APIs and prepackaged AI solutions can be used without prior ML expertise. Here are some prepackaged solutions that can be used directly:
- Contact Center AI — Create rich and natural conversational experiences.
- Document AI — Tap into your unstructured data (such as images and PDFs) and make it accessible using Google computer vision (including OCR) and natural language processing (NLP).
- Recommendations AI — Use machine learning to deliver recommendations personalized for each customer's tendencies and preferences.
Pretrained APIs
If you don't have any training data to train a model and you have a generic unstructured data use case such as video, images, text, or natural language, then a pretrained API would be a great choice for your AI/ML project. Pretrained APIs are trained on a huge corpus of generic unstructured data that is built, tuned, and maintained by Google. This means you don't have to worry about creating and managing the models behind them.
BigQuery ML
If your training data is in BigQuery and your users are most comfortable with SQL, then it likely will make sense for your data analysts and data scientists to build ML models in BigQuery using BigQuery ML. You will have to make sure that the set of models available in BigQuery ML matches the problem you're trying to solve. BigQuery ML offers simple SQL statements to build, train, and make predictions within the BigQuery interface or via the API.
Vertex AI
Vertex AI offers a fully managed, end-to-end platform for data science and machine learning. If you need to create your own custom models with your own data, then use Vertex AI. Vertex AI offers two options to train models: AutoML and custom training. Here is how to choose between these two options:
- Use case: If your use case fits a supported AutoML offering, then starting with AutoML is a good choice. This includes use cases involving data types such as image, video, text, and tabular. But if your model takes a mixed input type such as images and tabular metadata, then it makes sense to use a custom model.
- Requirements: If you need control over your model architecture, framework, or exported model assets (for example, if your model needs to be built with TensorFlow or PyTorch), then use a custom model.
- Team expertise: How experienced is your team with ML/AI? If you have a team with limited experience in building custom models, then explore AutoML before you look into custom model development.
- Team size: If you have a small data science and ML team, then it may make more sense to work with AutoML because custom model code requires more time to develop and maintain.
- Prototyping: Use AutoML if you want to develop a quick initial model to use as a baseline. You can then decide if you want to use this baseline as your production model or look to improve upon it by developing your own custom model.
Many organizations have varying levels of machine learning (ML) expertise, ranging from novice to expert, so a platform that can help build expertise for the novice users while providing a seamless and flexible environment for the experts is a great way to accelerate AI innovation. This is where Vertex AI comes in! It provides tools for every step of the ML workflow across different model types for varying levels of ML expertise.
ML is an inherently experimental discipline. It's called data science for a reason — done properly, there's quite a bit of experimental method, hypothesis testing, and trial-and-error. As a science, then, experimental rigor should be baked into the processes (and therefore tools) that data scientists use. That is the fundamental principle that Vertex AI is built on.
End-to-End Model Creation in Vertex AI
The ML workflow starts with defining your prediction task, followed by ingesting data, analyzing it, and transforming it. Then you create and train a model, evaluate that model for efficiency, optimize it, and finally deploy it to make predictions. With Vertex AI you get a simplified ML workflow for all of these activities in one central place.
- Managed datasets — Helps streamline data preparation, including ingestion, analysis, and transformation. You can upload data from your own computer, Cloud Storage, or BigQuery. After uploading, you can label and annotate the data right from within the console.
- Model training — Vertex AI offers two options, AutoML and custom training. More on this in the next section.
- Model evaluation — Once your model is trained, you have the ability to assess it, optimize it, and even understand the signals behind your model's predictions with Explainable AI.
- Model deployment — When you're happy with the model, you can deploy it to an endpoint to serve online predictions and offline predictions in case of tabular and image models. This deployment includes all the physical resources needed by the model to serve with low latency and scale with increasing traffic. You can use the undeployed model for batch predictions on massive batch datasets and serve online endpoints for low-latency predictions.
- Predictions — After you've deployed the model, you can get predictions using the UI, CLI, or the SDK.
What Does Vertex AI Include?
- No-code/low-code ML workflow: The easiest way to create a custom model is by using AutoML in Vertex AI. If your use case falls under a supported prediction category (such as translation, vision, video, language, tables, and forecast), then use AutoML before writing your own custom model code. Simply upload your data and Vertex AI automatically finds the best model for the use case.
- Custom training ML workflow: If your team of ML experts and data scientists prefers to write custom training code, Vertex AI offers a set of tools for doing just that. Vertex AI supports both custom and prebuilt containers for running training code. Prebuilt containers support common ML frameworks such as PyTorch, TensorFlow, scikit-learn, and XGBoost. For use cases that are based on other dependencies, libraries, and binaries, Vertex AI supports custom containers. You provide the path to the training package in Artifact Registry and your model output artifacts are stored in the Cloud Storage bucket of your choice.
When running custom training jobs on Vertex AI, you can also make use of Vertex's hyperparameter tuning service. Hyperparameters are variables that govern the process of training a model, such as batch size or the number of hidden layers in a deep neural network. In a hyperparameter tuning job, Vertex AI creates trials of your training job with different sets of hyperparameters and searches for the best combination of hyperparameters across the series of trials.
To run the training you need compute resources — either a single node or multiple worker pools for distributed training. To do this with Vertex AI training, you select the machine types, CPU, disk type, disk size, and accelerators you want to use for your training job.
Once the training is done, you need the trained model as an endpoint to be served for prediction. In Vertex AI you can serve models for prediction using prebuilt containers for supported runtimes, or you can build your own custom container stored in the Artifact Registry.
- MLOps workflow and tools: ML workflows are complex, where each step in a multistage pipeline may execute in a different environment and pipelines vary considerably between use cases.
- Model Monitoring: Model Moderating enables proactive monitoring of model performance and lets you visualize drift over time, compare latest feature distributions with a baseline, and set alerting thresholds.
- ML Metadata: Maintaining a consistent, flexible approach to manage the life cycle of artifacts generated by all the various steps across these workloads is a considerable challenge. Vertex ML Metadata provides artifact, lineage, and execution tracking for your ML workflow.
- Explainable AI: Explainable AI is a fully managed service on Vertex AI that enables you to generate “feature attributions” or “feature importance” values for your model's predictions. Feature attributions are an explainability method that shows you how much each input feature contributed to your model's predictions, which can help improve confidence that your models are performing as expected.
- Feature Store: Reduce the cycle time of AI/ML development by building and organizing ML features for an entire organization, and making it easy to efficiently share, discover, and serve them at scale.
- Infrastructure services: Vertex AI offers preconfigured VMs for deep learning applications. Deep Learning VM images deliver a seamless notebook experience with integrated support for JupyterLab.
Deep Learning VMs are optimized for performance, accelerated model development, and training, enabling fast prototyping with common ML frameworks such as TensorFlow, PyTorch, and scikit-learn preinstalled. You can also easily add Cloud GPUs and Cloud TPU as needed.
AutoML in Vertex AI: AutoML enables developers — even those with limited machine learning (ML) expertise — to train high-quality models specific to their own data and business needs with minimal effort. AutoML in Vertex AI supports common data types such as image, tabular, text, and video. It provides a graphical interface that guides you through the end-to-end ML life cycle. Once your model is built and deployed, you can use it to make predictions using the API or client libraries.
AutoML Behind the Scenes
AutoML ensures that the model development and training tasks that used to take months can now be completed in weeks or even days. With significant automation, as well as guardrails at each step, AutoML helps you:
- Easily define your model's features and target label
- Generate statistics on your input data
- Automatically train your model with automated feature engineering, model selection, and hyperparameter tuning
- Evaluate your model's behavior before deploying to production
- Deploy your model with one click
AutoML automatically searches through Google's model zoo to find the best model to fit your use case. Vertex AI choreographs supervised learning tasks to achieve a desired outcome. The specifics of the algorithm and training methods change based on the data type and use case. There are many different subcategories of machine learning, all of which solve different problems and work within different constraints. For smaller/simpler datasets, it applies linear, logistic models, and for larger ones it selects advanced deep, ensemble methods.
How Do I Work with AutoML in Vertex AI?
- Assess your use case: What is the outcome you want to achieve? What type of data are you working with: text, video, tabular, image? How much data do you have? What is your prediction task: classification, regression, forecasting, object detection?
- Gather your data: Determine what data you need for training and testing your model based on the outcome you want to achieve.
- Include enough data. Although AutoML enables you to train models with less data, in general, more training data is always better for the accuracy of your resulting model.
- Your dataset should capture the diversity of your problem space. For example, if you're trying to classify photos of consumer electronics into categories, the wider a variety of consumer electronics the model is exposed to in training, the more likely it will be able to distinguish between a novel model of tablet, phone, or laptop, even if it's never seen that specific model before.
- Select relevant features. Features are how your model identifies patterns to make predictions, so they need to be relevant to your problem. For example, to build a model that predicts whether or not a credit card transaction is fraudulent, you'll need to build a dataset that contains transaction details like the buyer, seller, amount, date and time, and items purchased.
- Prepare your data: Make sure your data is properly formatted and labeled.
- You can add data in Vertex AI by either importing from your computer or from Cloud Storage in an available format (CSV or JSONL) with the labels inline.
- If your image or text data hasn't been annotated, you can upload unlabeled data and use the Google Cloud Console to apply annotations.
- Train: Set parameters and build your model. Your dataset contains training, validation, and testing sets. If you do not specify the splits, then Vertex AI automatically uses 80 percent of your data for training, 10 percent for validation, and 10 percent for testing. You can also define splits manually.
- Evaluate and test: In Vertex AI you can assess your custom model's performance using the model's output on test examples and common machine learning metrics. These metrics include:
- Model output: For image, text, and video classification datasets, the model outputs a series of numbers that communicate how strongly it associates each label with that example. For a regression dataset, the model output is a new predicted value, and for a tabular forecasting dataset, the model output is a new column with forecasted values.
- Performance metrics: Performance metrics also differ depending on the type of model you create.
Classification models show prediction outcomes in the form of true positives, true negatives, false positives, and false negatives.
Precision and recall refer to how well your model is capturing information. Precision tells you, from all the test examples that were assigned a label, how many actually were supposed to be categorized with that label. Recall tells you, from all the test examples that should have had the label assigned, how many were actually assigned the label. Depending on your use case, you may want to optimize for either precision or recall.
Regression and forecasting models show mean absolute error (MAE), which is the average of absolute differences between observed and predicted values. They also show root mean square error (RMSE), mean absolute percentage error (MAPE), root mean squared log error (RMSLE), and R squared (R^2), which is the square of the Pearson correlation coefficient between the observed and predicted values.
There's no one-size-fits-all answer on how to evaluate your model; consider evaluation metrics in context with your problem type and what you want to achieve with your model.
- Deploy and predict: When you're satisfied with your model's performance, it's time to get predictions. Perhaps that means production-scale usage, or maybe it's a one-time prediction request. Depending on your use case, you can use your model for batch or online predictions.
Many people think that the main challenge in building a machine learning (ML) application is getting the model working, but in practice that is only a small part of a much bigger picture. After you collect your data, verify it, analyze it, extract features, secure machine resources to train the model, and finally train your model, you face the challenge of moving to production, where you'll need the ability to scale the serving infrastructure, and monitor and manage all your models continuously. That's where the growing discipline of MLOps comes in!
What Is MLOps?
MLOps has a fairly straightforward goal: unify machine learning system development and operations, to guide teams through the challenges of doing production machine learning. It takes both its name as well as some of its core principles and tooling from DevOps. However, the development of ML applications comes with its own unique challenges — for example, it's necessary to manage the life cycle of data and models, as well as code — and that has led MLOps to evolve as a domain of its own.
Here are some high-level MLOps patterns and practices that help address the challenges of ML application development and deployment:
- Formalization — As you formalize your ML workflows for production, you can (and should) move away from stitched-together notebooks or monolithic scripts.
- Standardization — Standardized ML workflows behave in the same way across environments.
- Scalability — An efficient MLOps workflow will scale out resources when needed, and scale down when they're not.
- Reproducibility — Designing for composability, modularity, and reuse of ML workflow building blocks will ensure that you can reliably reproduce and rerun your workflows.
- Monitoring, versioning, and caching — Your infrastructure should support workflow monitoring, versioning, and caching. This typically requires making ML workflow metadata explicit.
- Productization — The data scientists on your team will likely prototype ML models in their own notebooks. You need well-defined processes to capture that work and move it out of notebooks for production use.
- Collaboration — Mechanisms for supporting collaboration and role-based access control also become important. Informal methods of providing team members access won't scale.
A typical machine learning workflow might include experimentation and prototyping stages as well as automation of training, model evaluation and deployment, and monitoring and retraining. Many steps and actions need to be coordinated and supported with particular capabilities (such as continuous monitoring). For a production environment, an ad hoc approach won't work. By formalizing and orchestrating these steps with Vertex AI Pipelines, you can automate, track, and reproduce workflows; more easily debug problems; and reuse subcomponents of a workflow elsewhere.
Vertex AI Pipelines
Vertex AI Pipelines is a managed ML service that enables you to increase the pace at which you experiment with and develop machine learning models and the pace at which you transition those models to production. Vertex AI Pipelines is serverless, which means that you don't need to deal with managing an underlying GKE cluster or infrastructure. It scales up when you need it to, and you pay only for what you use. In short, it lets you focus on building your pipelines.
Vertex AI Pipelines features data scientist–friendly Python SDKs that make it easy to build and run pipelines. You can use prebuilt components from the Vertex AI Pipelines SDKs, or use the SDKs to define your own custom components. You can add control flow to your pipelines, and the SDKs make it easy to experiment and prototype right from notebooks.
Vertex AI Pipelines also has a metadata layer that simplifies the process of tracking artifacts generated throughout your ML workflow. Artifact, lineage, and execution information is automatically logged to a metadata server when you run a pipeline, and you can explore all of this information in the UI. You can also query the underlying metadata server directly, which lets you compare run information and group artifacts by projects to track usage of datasets and models across your organization.
Vertex AI Pipelines workflows are secured with Google Cloud Platform standard enterprise security controls, including identity and access management as well as VPC Service Controls.
Vertex AI Pipelines Under the Hood
With Vertex AI Pipelines you don't have to worry about building, scaling, and maintaining your own Kubernetes clusters. Each step within a pipeline is completed either by a call to a Google Cloud managed service or through the execution of user code in a container. In both cases, Vertex AI Pipelines allocates the resources it needs at execution time. When you call a managed service, that service spins up the necessary resources. When the pipeline executes user code in a container, Vertex AI spins up the resources needed for that container.
Vertex AI Pipelines Open Source Support
Vertex AI Pipelines supports two open source Python SDKs: Kubeflow Pipelines (KFP) and TensorFlow Extended (TFX). You can use either of these SDKs with both Vertex AI Pipelines and open source Kubeflow Pipelines. If you use TensorFlow in an ML workflow that processes terabytes of structured data or text data, then it makes sense to build your pipeline using TFX.
For other use cases, you'll likely want to build your pipeline using the Kubeflow Pipelines SDK. With this SDK, you can implement your workflow by building custom components or by reusing prebuilt components, such as Google Cloud pipeline components, which make it easier to use Vertex AI services like AutoML in your pipeline.
A retailer needs to predict product demand or sales, a call center manager wants to predict the call volume to hire more representatives, a hotel chain requires hotel occupancy predictions for next season, and a hospital needs to forecast bed occupancy. Vertex Forecast provides accurate forecasts for these and many other business forecasting use cases.
Univariate vs. Multivariate Datasets
Forecasting datasets come in many shapes and sizes. In univariate datasets, a single variable is observed over a period of time — for example, in an airline passenger dataset with trend variations and seasonal patterns. More often, business forecasters are faced with the challenge of forecasting large groups of related time series at scale using multivariate datasets. A typical retail or supply chain demand planning team has to forecast demand for thousands of products across hundreds of locations or zip codes, leading to millions of individual forecasts. Similarly, financial planning teams often need to forecast revenue and cash flow from hundreds or thousands of individual customers and lines of business.
Forecasting Algorithms
The most popular forecasting methods today are statistical models. Autoregressive integrated moving average (ARIMA) models, for example, are widely used as a classical method for forecasting, and BigQuery ML offers an advanced ARIMA_PLUS model for univariate forecasting use cases. More recently, deep learning models have been gaining a lot of popularity for forecasting applications. There is ongoing debate on when to apply which methods, but it's becoming increasingly clear that neural networks are here to stay for forecasting applications.
Why Use Deep Learning Models for Forecasting?
Deep learning's recent success in the forecasting space is because they are global forecasting models (GFMs). Unlike univariate (i.e., local) forecasting models, for which a separate model is trained for each individual time series in a dataset, a deep learning time series forecasting model can be trained simultaneously across a large dataset of hundreds or thousands of unique time series. This allows the model to learn from correlations and metadata across related time series, such as demand for groups of related products or traffic to related websites or apps. While many types of ML models can be used as GFMs, deep learning architectures, such as the ones used for Vertex Forecast, are also able to ingest different types of features, such as text data, categorical features, and covariates that are not known in the future. These capabilities make Vertex Forecast ideal for situations where there are very large and varying numbers of time series, short life cycles, and cold-start forecasts.
What Is Vertex Forecast?
You can build forecasting models in Vertex Forecast using advanced AutoML algorithms for neural network architecture search. Vertex Forecast offers automated preprocessing of your time-series data, so instead of fumbling with data types and transformations you can just load your dataset into BigQuery or Vertex AI and AutoML will automatically apply common transformations and even engineer features required for modeling.
Most importantly it searches through a space of multiple deep learning layers and components, such as attention, dilated convolution, gating, and skip connections. It then evaluates hundreds of models in parallel to find the right architecture, or ensemble of architectures, for your particular dataset, using time series–specific cross-validation and hyperparameter tuning techniques (generic automated machine learning tools are not suitable for time series model search and tuning purposes, because they induce leakage into the model selection process, leading to significant overfitting).
This process requires lots of computational resources, but the trials are run in parallel, dramatically reducing the total time needed to find the model architecture for your specific dataset. In fact, it typically takes less time than setting up traditional methods.
Best of all, by integrating Vertex Forecast with Vertex AI Workbench and Vertex AI Pipelines, you can significantly speed up the experimentation and deployment process of GFM forecasting capabilities, reducing the time required from months to just a few weeks, and quickly augmenting your forecasting capabilities from being able to process just basic time series inputs to complex unstructured and multimodal signals.
BigQuery is a fully managed data warehouse for storing and running petabyte-scale analytics using SQL, without worrying about the underlying infrastructure. If your data scientist and analysts are already using SQL queries in BigQuery to analyze the data, they might want to go further and create ML models right there too. That's where BigQuery ML comes in!
BigQuery ML lets you create and execute machine learning models in BigQuery using standard SQL queries. BigQuery ML democratizes machine learning by letting SQL practitioners build models using existing SQL tools and skills. BigQuery ML increases development speed by eliminating the need to move data.
Benefits of BigQuery ML
BigQuery ML democratizes the use of ML by empowering data analysts, the primary data warehouse users, to build and run models using existing business intelligence tools and spreadsheets. BigQuery ML increases the speed of model development and innovation by removing the need to export data from the data warehouse. Instead, BigQuery ML brings ML to the data by providing these benefits:
- It is serverless, which means no instances to create and manage.
- In-place data means no data movement and ETL tasks.
- SQL means users don't need specialized skills like Python/Java.
- Governance and compliance is built in.
When You Should Use BigQuery ML over Vertex AI:
- Your data is already in BigQuery.
- You want to model on structured data.
- You want to do some model exploration right where the data is.
Additional Notable Features of BigQuery ML
- Explainable AI for predictive models in BigQuery ML helps make it easy to understand why your models made the predictions they made.
- Hyperparameter tuning helps you automatically optimize your hyperparameters when creating your models.
- Model export lets you export your BigQuery ML models to Cloud Storage, so you can host them anywhere you like, including Vertex AI.
Supported Models in BigQuery ML
In BigQuery ML, you can use a model with data from multiple BigQuery datasets for training and prediction. BigQuery ML supports the following types of models:
- Linear regression for forecasting; for example, the sales of an item on a given day.
- Binary logistic regression for classification; for example, determining whether a customer will make a purchase.
- Multiclass logistic regression for classification. These models can be used to predict multiple possible values such as whether an input is low-value, medium-value, or high-value.
- K-means clustering for data segmentation; for example, identifying customer segments. The models can also be used for anomaly detection.
- Matrix factorization for creating product recommendation systems using historical customer behavior, transactions, and product ratings.
- Time series for performing time-series forecasts. You can use this feature to create millions of time series models and use them for forecasting. The model automatically handles anomalies, seasonality, and holidays.
- Boosted tree for creating XGBoost-based classification and regression models.
- Deep Neural Network (DNN) for creating TensorFlow-based Deep Neural Networks for classification and regression models.
- AutoML Tables to create best-in-class models without feature engineering or model selection.
- TensorFlow model importing lets you create BigQuery ML models from previously trained TensorFlow models, then perform batch predictions on your data in BigQuery.
- Autoencoder for creating TensorFlow-based BigQuery ML models with the support of sparse data representations. The models can be used in BigQuery ML for tasks such as unsupervised anomaly detection and nonlinear dimensionality reduction.

Are you building an application that can benefit from image search; detection of products, logos, and landmarks; text extraction from images; or other image AI-related capabilities? If so, Vision AI may be just what you need. Vision AI enables you to easily integrate computer vision features within your applications to detect emotion, understand text, and much more. It includes image labeling, face and landmark detection, optical character recognition (OCR), and tagging of explicit content.
How to Use Vision AI
You can use Vision AI to derive insights from your images in different ways:
- Vision API — As the name suggests, Vision API provides access to a set of pretrained machine learning models for images through REST and RPC APIs. You just need to enable the API in Cloud Console or use the SDK and call the API. It assigns labels to images and quickly classifies them into millions of predefined categories such as landmarks, logos, text, emotions, and so on. It helps build valuable metadata into your image catalog.
- AutoML Vision in Vertex AI — You can automate the creation of your own custom machine learning models by simply uploading your image datasets using the graphical interface and training the model. Once you've trained your model, you can evaluate its accuracy, latency, and size, and export it to your application in the cloud. Furthermore, by using the AutoML Vision Edge capabilities, you can train and deploy low-latency, high-accuracy models optimized for edge devices.
What Can I Do with Vision API?
- Classify content using predefined labels — Provides a label for the supplied image based on millions of predefined categories.
- Detect brands and product logos — Provides a textual description of the logo or product entity identified, a confidence score, and a bounding polygon for the logo in the image.
- Find similar images on the web — Infers entities (labels/descriptions) from similar images on the web. Provides a list of URLs for fully matching images or cropped versions.
- Get crop hints — Provides a bounding polygon for the cropped image, a confidence score, and an importance fraction of this salient region with respect to the original image.
- Detect objects and retrieve object coordinates — Provides general label and bounding box annotations for multiple objects recognized in a single image.
- Detect faces and emotions — Locates faces with bounding polygons and identifies specific facial features such as eyes, ears, nose, and mouth along with their corresponding confidence values. Also returns likelihood ratings for emotion (joy, sorrow, anger, surprise) and general image properties (underexposed, blurred, headwear present).
- Moderate explicit content — Provides likelihood ratings for explicit content categories such as adult, spoof, medical, violence, and racy.
- Detect and extract printed and handwritten text — Performs optical character recognition (OCR) for an image, including text recognition and conversion to machine-coded text. Identifies and extracts UTF-8 text in an image.
- Detect popular places and landmarks — Provides the name of the landmark, a confidence score, and a bounding box in the image for the landmark. Gives coordinates for the detected entity.
- Identify dominant colors and other image properties — Returns dominant colors in an image.
- Identify products from your catalog — Matches entities identified in the image with items (such as a hat or a shirt) in your retail catalog.
If you deal with lots of video content, you likely have use cases for content moderation, video recommendations, media archiving, or contextual advertising. All such use cases depend on powerful content discovery. That's where Video AI comes in! Video AI offers precise video analysis that recognizes over 20,000 objects, places, and actions in video. You can get near-real-time insights with streaming video annotation and object-based event triggers. Video AI also enables you to extract rich metadata at the video, shot, or frame level, leading to more engaging experiences.
How to Use Video AI
There are a few ways to use Video AI to derive insights from your videos:
- Video Intelligence API — Offers pretrained machine learning models that automatically recognize a vast number of objects, places, and actions in stored and streaming video.
- AutoML for Video in Vertex AI — Automate the training of your own custom machine learning models by uploading your video datasets using the graphical interface and training the model.
What Can I Do with the Video Intelligence API?
- Explicit content detection: Detects adult content within a video. Annotates a video with explicit content annotations (tags) for entities that are detected in the input video.
- Face detection: Looks for faces in a video and returns segments in which a face is detected across all videos in the given request. It can also return bounding boxes defining the area of the video frame in which the face is detected, or the detected attributes of the face such as mouth, lips, smiling, and so on.
- Analyze videos for labels: Identify entities shown in video footage and annotate these entities with labels (tags). For example, for a video of a train at a crossing, the Video Intelligence API returns labels such as “train,” “transportation,” and “railroad crossing.” Each label includes a time segment with the time offset (timestamp) for the entity's appearance from the beginning of the video.
- Logo recognition : The Video Intelligence API automatically identifies 100, 000 logos, tracks the number of appearances of logos, and evaluates brand prominence by measuring how long a particular brand appears on screen.
- Object tracking : Tracks multiple objects detected in an input video or video segments and returns labels (tags) associated with the detected entities along with the location of the entity in the frame. For example, a video of vehicles crossing an intersection may produce labels such as “car,” “truck,” “bike,” “tires,” “lights,” “window,” and so on. Each label includes a series of bounding boxes showing the location of the object(s) in the frame. Each bounding box also has an associated time segment with a time offset (timestamp) that indicates the duration offset from the beginning of the video.
- Person detection: Detects the presence of humans, poses, and clothing attributes in a video file and tracks the bounding box of individual people across the video or video segment.
- Shot change: Annotates a video with video segments that are generated when detecting abrupt shot changes in the video.
- Speech transcription: Transcribes spoken audio in a video or video segment into text and returns blocks of text.
- Text detection: Performs OCR to detect visible text from frames in a video, or video segments, and returns the detected text along with information about the frame-level location and timestamp in the video for that text.
Use Case Scenarios
- Content moderation: You can identify when inappropriate content is being shown in a video and can instantly moderate content to quickly and efficiently filter content.
- Recommended content: To simplify content discovery for your users and to guide them to the most relevant content, you can build a content recommendation engine that uses labels generated by the Video Intelligence API and a user's viewing history and preferences.
- Media archives: For mass media companies, media archives are crucial. Using the metadata from the Video Intelligence API, you can create an indexed archive of your entire video library.
- Contextual advertisements: You can identify appropriate locations in videos to insert ads that are contextually relevant to the video content. This can be done by matching the timeframe-specific labels of your video content with the content of your advertisements.
As products and companies become more and more global, there is an increasing need to acquire and share information in many languages. Scaling translators to meet these needs is a challenge, however, and it is also expensive. Translation AI provides a cost-effective way to meet this challenge in the cloud, with machine learning models that enable rapid, efficient translation.
What Is Translation AI?
Translation AI offers real-time on-demand translations so that your end users can get content in their language in seconds. It can be used in three different ways: Translation API (Basic and Advanced), AutoML Translation, and Media Translation API.
Translation API's pretrained model supports more than 100 languages. It's easy to integrate with Google APIs via REST or with your mobile or browser app using gRPC. It scales seamlessly, comes with a generous daily quota, and lets you set lower limits.
Consider a multi-language chat support use case. When a chat request is made from a mobile app or browser to the Translation API, it detects the language and translates it to English, then sends the request to Dialogflow to understand the question. (Dialogflow is a natural language understanding platform that makes it easy to design and integrate conversational user interfaces.) Dialogflow replies back with a best answer and Google Translation API then converts it back to the user's source language.
What If Your Business Has Specific Terms?
Translation API does a great job with general-purpose text, and with its advanced glossary features, you can take it further by providing a dictionary of words or phrases. With Translation API's glossary feature, you can retain your brand names or other specific terms in translated content. Simply define the names and vocabulary in your source and target languages, then save the glossary file to your translation project in Cloud Storage, and those words and phrases will be included in your copy when you include the glossary in your translation request.
Translation API Advanced also offers a Document Translation API for directly translating documents in formats such as PDF and DOCX. Unlike simple plain-text translations, Document Translation preserves the original formatting and layout in your translated documents, helping you retain much of the original context.
AutoML Translation
There are times when you don't know exactly which word translations you want to control but you need the translations to be more relevant to the content domain, like manufacturing or medical. AutoML Translation shines in such use cases, which require a custom model to bridge the “last mile” between generic translation tasks and specific niche vocabularies and linguistic style. AutoML custom models are built on top of the generic Translation API model for domain-specific content that matters to you, which means you are taking advantage of the underlying pretrained model.
What Is the Media Translation API?
Translating audio files and streaming speech has long been a challenge. Because the data and files are not in the form of text, you first had to transcribe the original source into text, and then translate the resulting text into different languages. Friction in this process forced many organizations to make a trade-off between quality, speed, and ease-of-deployment. That's where the Media Translation API comes in!
The Media Translation API simplifies this process by abstracting away the transcription and translation behind a single API call, enabling you to perform real-time translation of video clips and audio data with higher translation accuracy. With the Media Translation API, you can enable real-time engagement for users by streaming translation from a microphone or prerecorded audio file. Or, you can power an interactive experience on your platform with video chat featuring translated captions or add subtitles to your videos in real time as they are played. You can probably think of numerous other use cases for this capability.
Text is everywhere: in emails, messages, comments, reviews, and documents. The ability to derive insights from unstructured text powers use cases such as sentiment analysis, content classification, moderation, and more. That's where Natural Language AI comes in! It offers insightful text analysis with machine learning for extracting and analyzing text. With Natural Language AI you can incorporate natural language understanding (NLU) into your apps.
How to Use Natural Language AI
There are a few ways to use Natural Language AI to derive insights from your unstructured text:
- Natural Language API — Offers pretrained machine learning models that empower developers to easily apply natural language understanding (NLU) to their applications with such features as sentiment analysis, entity analysis, entity sentiment analysis, content classification, and syntax analysis. You can use Natural Language AI to quickly perform analysis and annotation on your text using thousands of predefined labels through REST and RPC APIs. Simply enable the API in Cloud Console or use the SDK and then call the API.
- AutoML for Natural Language in Vertex AI — Train your own high-quality, custom machine learning models to classify, extract, and detect sentiment with minimum effort and machine learning expertise using Vertex AI for natural language, powered by AutoML. You can use the AutoML UI to upload your training data and test your custom model without writing a single line of code. Once it is trained, you can assess the model's accuracy, latency, and size, and export it to your application in the cloud. You can also choose to train and deploy low-latency, high-accuracy models optimized for edge devices.
- Healthcare Natural Language AI — Enables you to distill machine-readable medical insights from medical documents, while AutoML Entity Extraction for Healthcare makes it easy to build custom knowledge extraction models for healthcare and life sciences apps with no coding skills required.
What Can I Do with the Natural Language API?
The Natural Language API has several methods for performing analysis and annotation on your text:
- Sentiment analysis inspects the text and identifies the prevailing emotional opinion within the text as positive, negative, or neutral. This is useful in customer feedback and satisfaction use cases, where the API would identify “I had a bad experience,” for example, as a negative sentiment.
- Entity analysis inspects the given text for known entities (including proper nouns such as public figures, landmarks, and so on as well as common nouns such as “restaurant,” “stadium,” and so on) and returns information about those entities. You can use this capability to identify mentions of your brand along with other entities in reviews, social media, and other text.
- Entity sentiment analysis inspects the given text for known entities (proper nouns and common nouns), returns information about those entities, and identifies the prevailing emotional opinion of the writer about the entity. For example, an analysis of “I like this new mobile phone, but the battery life is poor” would return a positive sentiment on “phone,” but a negative sentiment on “battery.”
- Syntactic analysis extracts linguistic information, breaking up the given text into a series of sentences and tokens (generally, word boundaries) and providing further analysis on those tokens.
- Content classification analyzes text and returns a list of content categories found in that text, for example, “Internet & Telecom” or “Computers & Electronics.”
Each API call also detects and returns the language of the given text if a language is not specified by the caller in the initial request.
Fortunately Google has spent the last 20 years working on improving speech recognition across Google Assistant, Gboard voice typing on Android, YouTube captions, Google Meet, and more. The Speech-to-Text API, the result of that work, gives you access to Google's most advanced deep learning neural network algorithms for automatic speech recognition (ASR) and transcription. It offers high accuracy with no training or tuning in 73 languages in over 125 locales.
Speech use cases usually fall into one of two categories: human-consumed or machine-consumed for downstream processing. Human-consumed use cases include closed captions and subtitles in videos, whereas machine-consumed use cases include reading audio-based content, summarization, extraction, and customer service improvement. One thing that's common to all speech use cases is the accuracy of transcription. A number of issues can affect accuracy: audio quality, a need for domain-specific terms, multiple speakers/background noise, and speakers. The Speech-to-Text API helps with transcribing your speech content to text with high accuracy in a variety of environments.
What Can I Do with the Speech-to-Text API?
The Speech-to-Text API provides automatic speech recognition for real-time or prerecorded audio and supports a global user base with extensive language support in over 125 languages and variants. It also allows you to evaluate quality by iterating on your configuration. Some additional features are:
- Inappropriate content filtering: A profanity filter helps you detect inappropriate or unprofessional content in your audio data and filter out profane words in text results.
- Speech adaptation, custom recognition with specific words: Customize speech recognition to transcribe domain-specific terms and rare words by providing hints and boost your transcription accuracy of specific words or phrases. Automatically convert spoken numbers into addresses, years, currencies, and more using classes.
- Noise robustness: Speech-to-Text can handle noisy audio from many environments without requiring additional noise cancellation.
- Selection of prebuilt models: Choose from a selection of pretrained models for voice control, phone call, dictation, and video transcription optimized for domain-specific quality requirements.
- Multichannel recognition: Speech-to-Text can recognize distinct channels in multichannel situations (e.g., video conferences) and annotate the transcripts to preserve the order.
- Automatic punctuation: Speech-to-Text accurately punctuates transcriptions (e.g., commas, question marks, and periods).
- Speaker diarization: Know who said what by receiving automatic predictions about which of the speakers in a conversation spoke each utterance.
- Speech-to-Text On-Prem: Available on Google Cloud Marketplace to be deployed as a container on any Anthos GKE cluster. It provides more accurate, smaller in size models to run on-premises.
How to Use the Speech-to-Text API
- Synchronous Recognition (REST and gRPC) sends audio data to the Speech-to-Text API, performs recognition on that data, and returns results after all audio has been processed. Synchronous recognition requests are limited to audio data of one minute or less in duration. Note that a synchronous request is blocking, meaning that Speech-to-Text must return a response before processing the next request.
- Asynchronous Recognition (REST and gRPC) sends audio data to the Speech-to-Text API and initiates a long-running operation. Using this operation, you can periodically poll for recognition results. Use asynchronous requests for audio data of any duration up to 480 minutes.
- Streaming Recognition (gRPC only) performs recognition on audio data provided within a gRPC bi-directional stream. Streaming requests are designed for real-time recognition purposes, such as capturing live audio from a microphone. Streaming recognition provides interim results while audio is being captured, allowing results to appear while a user is still speaking.
As the volume of customer calls increases, it's becoming even more important to make the most of human agents' time to lower costs and improve customer experiences. Google Cloud Contact Center AI (CCAI) enables you to do just that by freeing human agents to concentrate on more complex calls while providing them with real-time information to better handle those calls.
- Single source of intelligence: Contact Center AI provides a consistent, high-quality conversational experience across all channels and platforms, both human and virtual.
- Ability to go off-script: Huge cost savings can be realized by having a virtual agent handle voice calls. CCAI has the ability to go “off script” — to let callers go down tangents or side paths to the main conversation, while still tracking toward the main objective of the call. With CCAI, your virtual agents can answer complex questions and complete complicated tasks, including allowing for unexpected stops and starts, unusual word choices, or implied meanings. Developers can define supplemental questions, and CCAI can easily retain the context, answer the supplemental question, and come back to the main flow.
- Versatile fulfillment: CCAI has the ability to handle multiple use cases for the customer with the same virtual agent, which enables you to fully automate routine tasks and deflect calls.
What Is Contact Center AI?
Contact Center AI is a conversational AI technology solution that automates simple interactions and enables agents to solve issues quickly, using AI. CCAI has four key components:
- Conversation Core: This is the central AI brain that underpins CCAI and its ability to understand, talk, and interact. It enables and orchestrates high-quality conversational experiences at scale, making it possible for customers to have conversations with a virtual agent that are as good as conversations with a human agent.
- Understand — Speech-to-Text speech recognition understands what customers are saying regardless of how they phrase things, what vocabulary they use, what accent they have, and so on.
- Talk — Text-to-Speech enables virtual agents to respond to customers in a natural, human-like manner that pushes the conversation along, rather than frustrate customers.
- Interact — Dialogflow identifies customer intent and determines the appropriate next step. You can build conversational flows in a point-and-click interface, and generate automated ML models for human-like conversational experiences.
- Virtual agents with Dialogflow: This component automates interactions with customers, using natural conversation to identify and address their issues. Virtual agents enable customers to get immediate help any time, day or night.
- Agent Assist: This component brings AI to human agents to increase the quality of their work, while decreasing their average handling time. Agent Assist shares initial context and provides real-time, turn-by-turn guidance to coach agents through business processes, as well as full call transcriptions that agents can edit and file quickly.
- CCAI Insights: CCAI Insights helps your contact center managers in making better data-driven decisions for their business by breaking down conversations using natural language processing and machine learning.
How Does Contact Center AI Work?
When a user initiates a chat or voice call and the contact center provider connects them with CCAI, a virtual agent engages with the user, understands their intent, and fulfills the request by connecting to the backend. If necessary, the call can be handed off to a human agent, who sees the transcript of the interaction with the virtual agent, gets feedback from the knowledge base to respond to queries in real time, and receives a summary of the call at the end. Insights help you understand what happened during the virtual agent and live agent sessions. The result is improved customer experiences and customer satisfaction scores, lower agent handling times, and more time for human agents to spend on more complicated customer issues.
Some of the most important data in companies isn't living in databases, but rather in documents. Transforming documents into structured data helps increase the speed of decision making, reduce costs related to manual data entry, and develop better experiences for customers. Documents include everything from PDFs, emails, images, and more. Think about all the contracts, patents, and business attachments you've worked with that are in difficult-to-parse formats. This is what is known as “dark data.” Dark data is information assets that organizations collect, process, and store during regular business activities but that is generally not used for other purposes such as analytics or directly monetizing. Document AI can help you safely and securely use this data.
What Is Document AI?
Document AI lets you tackle the end-to-end flow of extracting and classifying information from unstructured documents. Not only does it read and ingest your documents, it understands the spatial structure of the document. For example, if you run a form through a parser, it understands that there are questions and answers in your form, and you'll get those back in key-value pairs. This facilitates a way to incorporate documents into your existing app or service by using the API. If you're working on an on-premises or hybrid system, you can still use this API in your code from where it's running.
How to Use Document AI
There are three flavors of Document AI:
- General Document AI offers general models such as optical character recognition (OCR) and structured form parser capabilities. If you upload a multipage PDF that has several different form types present, the splitter can tell you where each individual form actually starts and ends.
- Specialized Document AI for several common business form types. These include models for tax forms such as W2s and W9s; high-variance document types, such as invoices and receipts; U.S. licenses; passports, and bank statements. Google trains and maintains these models so that you don't have to.
- Custom Document AI for training the model on your own documents. With the AutoML technology, you can upload your own document and create custom models with a no-code graphical user interface.
You can use the Document AI API synchronously for real-time document processing or asynchronously to batch process bulk documents from Cloud Storage.
Sample Document AI Architecture
You get your data into Cloud Storage, then split/classify it by calling Document AI API using Cloud Functions. You can integrate data loss prevention DLP for de-identification of documents to mask sensitive information. You could use Pub/Sub to effectively stream your data into your storage system of choice. If you are not using Google Cloud services and just using your own SQL or PostgreSQL database on-premises or on another cloud, that's fine! You can still call this API.
Vertical Solutions
In addition to the specialized parsers, the vertical solutions help make it easy to derive value from documents specific to procurement, lending, and contract. These vertical solutions help reduce processing time and streamline data capture so that you can optimize your development and usage. These solutions are enhanced by the Google Knowledge Graph technology to normalize and enrich entity extraction (certain fields are detected). To ensure accuracy, they provide a workflow and user interface for humans to review, validate, and correct the data extracted from documents by Human in the Loop (HITL) processors.
Recommendations are a huge part of discovering what your customers are interested in. Effective recommendations improve the customer experience by helping customers discover products that they are likely to need or want. Google has spent years delivering recommended content across Google Shopping, Google Search, and YouTube. Recommendations AI draws on that experience and Google's expertise in machine learning to deliver personalized recommendations in a managed solution that improves individual customer experiences.
What Is Recommendations AI?
Recommendations AI offers true personalization for each individual customer, using the complete history of the customer's shopping journey to serve them with real-time personalized product recommendations. It excels at generating recommendations in scenarios with long-tail products and cold-start users and items. Its context-hungry deep learning models use item and user metadata to draw insights across millions of items at scale and constantly iterate on those insights in real time — a pace that is impossible for manually curated rules to keep up with.
Sample Customer Journey with Recommendations AI
Recommendations AI works throughout the entire buying process, from initial product discovery to consideration, and through to purchase. And it doesn't stop there! It can be used for remarketing as well as email campaigns that deliver personalized recommendations for customers.
Let's meet a user who is browsing on one of her favorite apparel sites. She wants to replace some of her old workout gear, so she starts to browse the activewear section of the site. When she clicks through to the product page of a jacket that she's interested in, she's immediately served a recommendation for a pair of shoes that is often purchased with this jacket. She checks out the shoes and sees another item recommended for her: sunglasses.
She adds the sunglasses and shoes to the cart. She decides not to complete the purchase right at that moment, so a few days later the retailer sends her a reminder email with additional personalized recommendations, including one for a pair of shorts. She returns to the site to find a customized home page with her personalized recommendations. This sample flow illustrates not only the power of effective recommendations, but also the value of being able to easily re-engage the customer from where they left off and reduce shopping cart abandonments.
How Does Recommendations AI Work?
Recommendations AI uses the Retail API to power three essential functions:
- Collecting and ingesting the necessary data: There are two data sources for recommendations: your product catalog and the record of user-generated events on your website. This data can be processed using Dataflow, with the results stored in BigQuery or Cloud Storage. When the data is properly formatted, you can ingest it into the Retail API. Direct imports from data sources into the Retail API are also possible.
- Processing the data and building models to provide recommendations and search results: The Retail API supports two types of models: product recommendations and retail search. The API uses the same data for both, so there is no need to ingest data twice. Models are designed to optimize for click-through rate (CTR), revenue per order, and conversion rate (CVR). Recommendation AI offers models for frequently bought together, recently viewed, others you may like, and recommended items.
- Embedding the models in your website: The Retail API provides easy-to-integrate REST APIs and client libraries in popular programming languages to supply recommendations and search results.
Data Engineering
Data engineering involves the transporting, shaping, and enriching of data to make it available and accessible. Google Cloud offers multiple tools to ingest, prepare, store, and catalog data. We covered this topic in detail in the data analytics section of the book. Refresh the concepts there and continue on here.
Data Analysis
Data analysis is where the value of data starts to appear. On Google Cloud, there are many ways to explore, preprocess, and uncover insights in your data. If you are looking for a notebook-based end-to-end data science environment, use Vertex AI Workbench, which enables you to access, analyze, and visualize your entire data estate, from structured data at the petabyte scale in SQL with BigQuery, to process data with Spark on Google Cloud with serverless, autoscaling, and GPU acceleration capabilities. As a unified data science environment, Vertex AI Workbench also makes it easy to do machine learning.
If your focus is on analyzing structured data from data warehouses and insight activation for business intelligence, use Looker which helps accelerate your time-to-insight.
Model Development
Model development is where ML models are built using the data. Vertex AI Workbench makes it easy as the one-stop-shop for data science, combining analytics and machine learning, including Vertex AI services. It supports Spark, XGBoost, TensorFlow, PyTorch and more. As a Jupyter-based fully managed, scalable, and enterprise-ready environment, Vertex AI Workbench makes managing the underlying compute infrastructure needed for model training easy, with the ability to scale vertically and horizontally, and with idle timeouts and auto shutdown capabilities to reduce unnecessary costs. Notebooks themselves can be used for distributed training and hyperparameter optimization, and they include Git integration for version control.
For low-code model development, data analysts and data scientists can use BigQuery ML to train and deploy models directly using BigQuery's built-in serverless, autoscaling capabilities integrated with Vertex AI. For no-code model development, Vertex AI Training provides a point-and-click interface to train powerful models using AutoML.
ML Engineering
The next step is to incorporate all the activities of a well-engineered application life cycle, including testing, deployment, and monitoring. And all those activities should be as automated and robust as possible.
Vertex AI Managed Datasets and Feature Store provide shared repositories for datasets and engineered features, respectively, which provide a single source of truth for data and promote reuse and collaboration within and across teams. Vertex AI model serving enables deployment of models with multiple versions, automatic capacity scaling, and user-specified load balancing. Finally, Vertex AI Model Monitoring provides the ability to monitor prediction requests flowing into a deployed model and automatically alert model owners whenever the production traffic deviates beyond user-defined thresholds and previous historical prediction requests.
Insights Activation
The insights activation stage is where your data has become useful to other teams and processes. You can use Looker and Data Studio to enable use cases in which data is used to influence business decisions with charts, reports, and alerts.
Finally, the data can also be used by other services to drive insights; these services can run outside Google Cloud, inside Google Cloud on Cloud Run or Cloud Functions, and/or using Apigee API Management as an interface.
Orchestration
Effective orchestration reduces the amount of time that it takes to reliably go from data ingestion to deploying your model in production, in a way that lets you monitor and understand your ML system. For data pipeline orchestration, Cloud Composer and Cloud Scheduler are both used to kick off and maintain the pipeline. For ML pipeline orchestration, Vertex AI Pipeline is a managed machine learning service that enables you to increase the pace at which you experiment with and develop machine learning models and the pace at which you transition those models to production.