
CHAPTER ONE
Infrastructure
Cloud computing is the on-demand availability of computing resources—including servers, storage, databases, networking, software, analytics, and intelligence—over the Internet. It eliminates the need for enterprises to procure, configure, or manage these resources themselves, while enabling them to pay only for what they use. The benefits of cloud computing include:
- Flexibility: You can access cloud resources from anywhere and scale services up or down as needed.
- Efficiency: You can develop new applications and rapidly get them into production, without worrying about the underlying infrastructure.
- Strategic value: When you choose a cloud provider that stays on top of the latest innovations and offers them as services, it opens opportunities for you to seize competitive advantages and higher returns on investment.
- Security: The depth and breadth of the security mechanisms provided by cloud providers offer stronger security than many enterprise data centers. Plus, cloud providers also have top security experts working on their offerings.
- Cost-effectiveness: You only pay for the computing resources you use. Because you don't need to overbuild data center capacity to handle unexpected spikes in demand or sudden surges in business growth, you can deploy resources and IT staff on more strategic initiatives.
In this first chapter, you will learn about cloud computing models and dive into the various compute options that Google Cloud offers. The following chapters provide a closer look at specific cloud resources and topics, including storage, databases, data analytics, networking, and more.

Introduction
To understand the cloud and the different models you can choose from, let's map it with an everyday analogy of housing:
- On-Premises — If you decide to make your house from scratch, you do everything yourself: source the raw materials, tools, put them together, and run to the store every time you need anything. That is very close to running your application on-premises, where you own everything from the hardware to your applications and scaling.
- Infrastructure as a Service — Now, if you are busy you consider hiring a contractor to build a custom house. You tell them how you want the house to look and how many rooms you want. They take the instructions and make you a house. IaaS is the same for your applications; you rent the hardware to run your application on, but you are responsible for managing the OS, runtime, scale, and the data. Example: GCE.
- Containers as a Service — If you know that buying is just too much work due to the maintenance it comes with, then you decide to rent a house. The basic utilities are included, but you bring your own furniture and make the space yours. Containers are the same where you bring a containerized application so that you don't have to worry about the underlying operating system but you still have control over scale and runtime. Example: GKE.
- Platform as a Service — If you just want to enjoy the space without having to even worry about furnishing it, then you rent a furnished house. That is what PaaS is for; you can bring your own code and deploy it and leave the scale to the cloud provider. Example: App Engine & Cloud Run.
- Function as a Service — If you just need a small dedicated space in which to work that is away from your home, you rent a desk in a workspace. That is close to what FaaS offers; you deploy a piece of code or a function that performs a specific task, and every time a function executes, the cloud provider adds scale if needed. Example: Cloud Functions.
- Software as a Service — Now, you move into the house (rented or purchased), but you pay for upkeep such as cleaning or lawn care. SaaS is the same; you pay for the service, you are responsible for your data, but everything else is taken care of by the provider. Example: Google Drive.
What Is Compute Engine?
Compute Engine is a customizable compute service that lets you create and run virtual machines on Google's infrastructure. You can create a virtual machine (VM) that fits your needs. Predefined machine types are prebuilt and ready-to-go configurations of VMs with specific amounts of vCPU and memory to start running apps quickly. With Custom Machine Types, you can create virtual machines with the optimal amount of CPU and memory for your workloads. This allows you to tailor your infrastructure to your workload. If requirements change, using the stop/start feature you can move your workload to a smaller or larger Custom Machine Type instance, or to a predefined configuration.
Machine Types
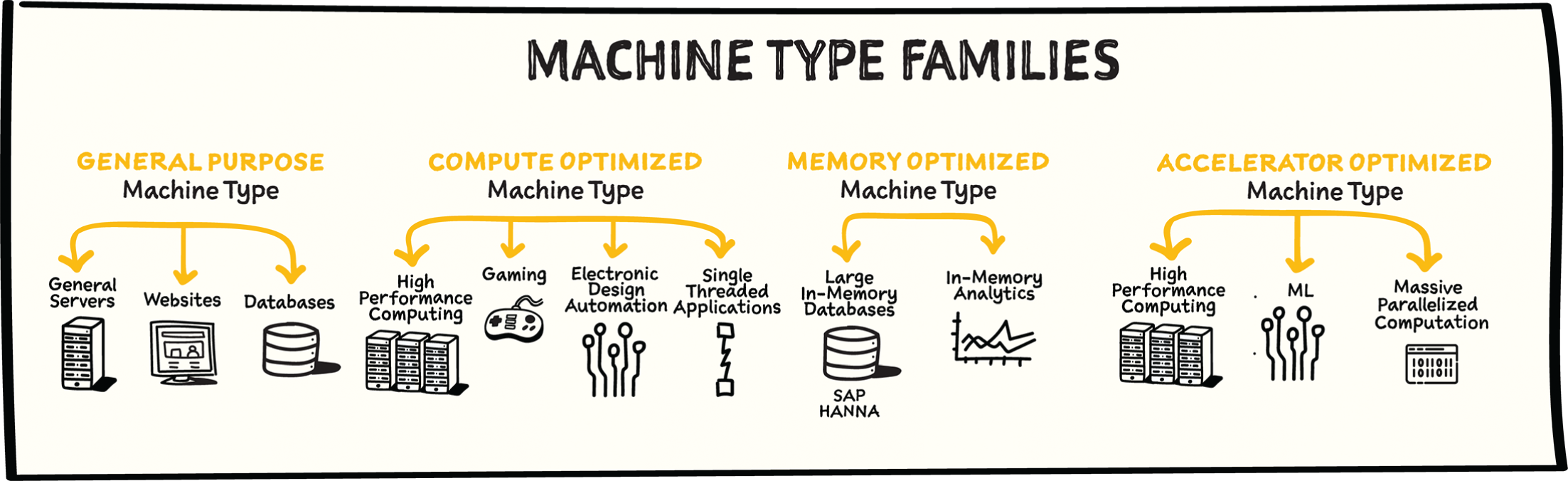
In Compute Engine, machine types are grouped and curated by families for different workloads. You can choose from general-purpose, memory-optimized, compute-optimized, and accelerator-optimized families.
- General-purpose machines are used for day-to-day computing at a lower cost and for balanced price/performance across a wide range of VM shapes. The use cases that best fit here are web serving, app serving, back office applications, databases, cache, media-streaming, microservices, virtual desktops, and development environments.
- Memory-optimized machines are recommended for ultra high-memory workloads such as in-memory analytics and large in-memory databases such as SAP HANA.
- Compute-optimized machines are recommended for ultra high-performance workloads such as High Performance Computing (HPC), Electronic Design Automation (EDA), gaming, video transcoding, and single-threaded applications.
- Accelerator-optimized machines are optimized for high-performance computing workloads such as machine learning (ML), massive parallelized computations, and High Performance Computing (HPC).
How Does It Work?
You can create a VM instance using a boot disk image, a boot disk snapshot, or a container image. The image can be a public operating system (OS) image or a custom one. Depending on where your users are, you can define the zone you want the virtual machine to be created in. By default all traffic from the Internet is blocked by the firewall, and you can enable the HTTP(s) traffic if needed.
Use snapshot schedules (hourly, daily, or weekly) as a best practice to back up your Compute Engine workloads. Compute Engine offers live migration by default to keep your virtual machine instances running even when software or hardware update occurs. Your running instances are migrated to another host in the same zone instead of requiring your VMs to be rebooted.
Availability
For High Availability (HA), Compute Engine offers automatic failover to other regions or zones in event of a failure. Managed instance groups (MIGs) help keep the instances running by automatically replicating instances from a predefined image. They also provide application-based auto-healing health checks. If an application is not responding on a VM, the auto-healer automatically re-creates that VM for you. Regional MIGs let you spread app load across multiple zones. This replication protects against zonal failures. MIGs work with load-balancing services to distribute traffic across all of the instances in the group.
Compute Engine offers autoscaling to automatically add or remove VM instances from a managed instance group based on increases or decreases in load. Autoscaling lets your apps gracefully handle increases in traffic, and it reduces cost when the need for resources is lower. You define the autoscaling policy for automatic scaling based on the measured load, CPU utilization, requests per second, or other metrics.
Active Assist's new feature, predictive autoscaling, helps improve response times for your applications. When you enable predictive autoscaling, Compute Engine forecasts future load based on your MIG's history and scales it out in advance of predicted load so that new instances are ready to serve when the load arrives. Without predictive autoscaling, an autoscaler can only scale a group reactively, based on observed changes in load in real time. With predictive autoscaling enabled, the autoscaler works with real-time data as well as with historical data to cover both the current and forecasted load. That makes predictive autoscaling ideal for those apps with long initialization times and whose workloads vary predictably with daily or weekly cycles. For more information, see How predictive autoscaling works or check if predictive autoscaling is suitable for your workload, and to learn more about other intelligent features, check out Active Assist.
Pricing
You pay for what you use. But you can save cost by taking advantage of some discounts! Sustained use savings are automatic discounts applied for running instances for a significant portion of the month. If you know your usage upfront, you can take advantage of committed use discounts, which can lead to significant savings without any upfront cost. And by using short-lived preemptive instances, you can save up to 80%; they are great for batch jobs and fault-tolerant workloads. You can also optimize resource utilization with automatic recommendations. For example, if you are using a bigger instance for a workload that can run on a smaller instance, you can save costs by applying these recommendations.
Security
Compute Engine provides you default hardware security. Using Identity and Access Management (IAM) you just have to ensure that proper permissions are given to control access to your VM resources. All the other basic security principles apply; if the resources are not related and don't require network communication among themselves, consider hosting them on different VPC networks. By default, users in a project can create persistent disks or copy images using any of the public images or any images that project members can access through IAM roles. You may want to restrict your project members so that they can create boot disks only from images that contain approved software that meet your policy or security requirements. You can define an organization policy that only allows Compute Engine VMs to be created from approved images. This can be done by using the Trusted Images Policy to enforce images that can be used in your organization.
By default all VM families are Shielded VMs. Shielded VMs are virtual machine instances that are hardened with a set of easily configurable security features to ensure that when your VM boots, it's running a verified bootloader and kernel — it's the default for everyone using Compute Engine, at no additional charge. For more details on Shielded VMs, refer to the documentation here.
For additional security, you also have the option to use Confidential VM to encrypt your data in use while it's being processed in Compute Engine. For more details on Confidential VM, refer to the documentation here.
Use Cases
There are many use cases Compute Engine can serve in addition to running websites and databases. You can also migrate your existing systems onto Google Cloud, with Migrate for Compute Engine, enabling you to run stateful workloads in the cloud within minutes rather than days or weeks. Windows, Oracle, and VMware applications have solution sets, enabling a smooth transition to Google Cloud. To run Windows applications, either bring your own license leveraging sole-tenant nodes or use the included licensed images.
Why Containers?
Containers are often compared with virtual machines (VMs). You might already be familiar with VMs: a guest operating system such as Linux or Windows runs on top of a host operating system with virtualized access to the underlying hardware. Like virtual machines, containers enable you to package your application together with libraries and other dependencies, providing isolated environments for running your software services. As you'll see, however, the similarities end here as containers offer a far more lightweight unit for developers and IT Ops teams to work with, bringing a myriad of benefits.
Instead of virtualizing the hardware stack as with the virtual machines approach, containers virtualize at the operating system level, with multiple containers running atop the OS kernel directly. This means that containers are far more lightweight: They share the OS kernel, start much faster, and use a fraction of the memory compared to booting an entire OS.
Containers help improve portability, shareability, deployment speed, reusability, and more. More importantly to the team, containers made it possible to solve the “it worked on my machine” problem.
Why Kubernetes?
The system administrator is usually responsible for more than just one developer. They have several considerations when rolling out software:
- Will it work on all the machines?
- If it doesn't work, then what?
- What happens if traffic spikes? (System admin decides to over-provision just in case…)
With lots of developers containerizing their apps, the system administrator needs a better way to orchestrate all the containers that developers ship. The solution: Kubernetes!
What Is So Cool about Kubernetes?
The Mindful Container team had a bunch of servers and used to make decisions on what ran on each manually based on what they knew would conflict if it were to run on the same machine. If they were lucky, they might have some sort of scripted system for rolling out software, but it usually involved SSHing into each machine. Now with containers — and the isolation they provide — they can trust that in most cases, any two applications can fairly share the resources of the same machine.
With Kubernetes, the team can now introduce a control plane that makes decisions for them on where to run applications. And even better, it doesn't just statically place them; it can continually monitor the state of each machine and make adjustments to the state to ensure that what is happening is what they've actually specified. Kubernetes runs with a control plane, and on a number of nodes. We install a piece of software called the kubelet on each node, which reports the state back to the primary.
Here is how it works:
- The primary controls the cluster.
- The worker nodes run pods.
- A pod holds a set of containers.
- Pods are bin-packed as efficiently as configuration and hardware allows.
- Controllers provide safeguards so that pods run according to specification (reconciliation loops).
- All components can be deployed in high-availability mode and spread across zones or data centers.
Kubernetes orchestrates containers across a fleet of machines, with support for:
- Automated deployment and replication of containers
- Online scale — in and scale — out of container clusters
- Load balancing over groups of containers
- Rolling upgrades of application containers
- Resiliency, with automated rescheduling of failed containers (i.e., self-healing of container instances)
- Controlled exposure of network ports to systems outside the cluster
A few more things to know about Kubernetes:
- Instead of flying a plane, you program an autopilot: declare a desired state, and Kubernetes will make it true — and continue to keep it true.
- It was inspired by Google's tools for running data centers efficiently.
- It has seen unprecedented community activity and is today one of the largest projects on GitHub. Google remains the top contributor.
The magic of Kubernetes starts happening when we don't require a sysadmin to make the decisions. Instead, we enable a build and deployment pipeline. When a build succeeds, passes all tests, and is signed off, it can automatically be deployed to the cluster gradually, blue/green, or immediately.
Kubernetes the Hard Way
By far, the single biggest obstacle to using Kubernetes (k8s) is learning how to install and manage your own cluster. Check out k8s the Hard Way, a step-by-step guide to install a k8s cluster. You have to think about tasks like:
- Choosing a cloud provider or bare metal
- Provisioning machines
- Picking an OS and container runtime
- Configuring networking (e.g., P ranges for pods, SDNs, LBs)
- Setting up security (e.g., generating certs and configuring encryption)
- Starting up cluster services such as DNS, logging, and monitoring
Once you have all these pieces together, you can finally start to use k8s and deploy your first application. And you're feeling great and happy and k8s is awesome! But then, you have to roll out an update…
Wouldn't it be great if Mindful Containers could start clusters with a single click, view all their clusters and workloads in a single pane of glass, and have Google continually manage their cluster to scale it and keep it healthy?
What Is GKE?
GKE is a secured and fully managed Kubernetes service. It provides an easy-to-use environment for deploying, managing, and scaling your containerized applications using Google infrastructure.
Mindful Containers decided to use GKE to enable development self-service by delegating release power to developers and software.
Why GKE?
- Production-ready with autopilot mode of operation for hands-off experience
- Best-in-class developer tooling with consistent support for first- and third-party tools
- Offers container-native networking with a unique BeyondProd security approach
- Most scalable Kubernetes service; only GKE can run 15,000 node clusters, outscaling competition up to 15X
- Industry-first to provide fully managed Kubernetes service that implements full Kubernetes API, 4-way autoscaling, release channels, and multicluster support
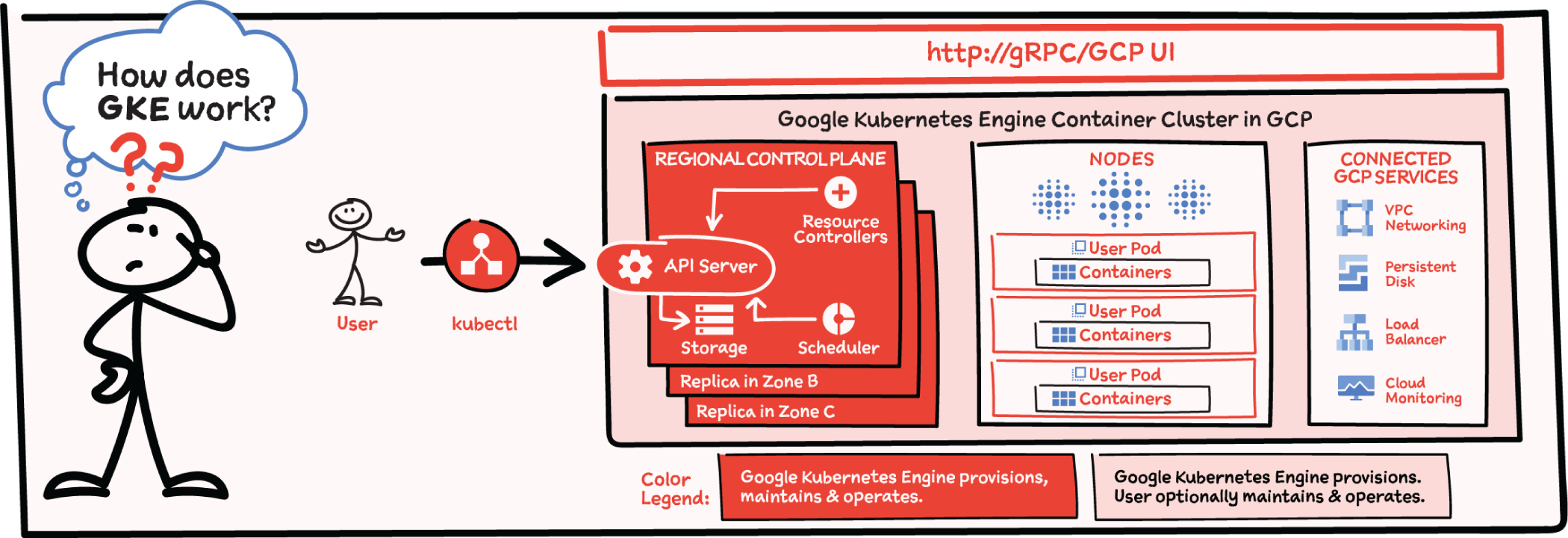
How Does GKE Work?
The GKE control plane is fully operated by the Google SRE (Site Reliability Engineering) team with managed availability, security patching, and upgrades. The Google SRE team not only has deep operational knowledge of k8s, but is also uniquely positioned to get early insights on any potential issues by managing a fleet of tens of thousands of clusters. That's something that is simply not possible to achieve with self-managed k8s. GKE also provides comprehensive management for nodes, including autoprovisioning, security patching, opt-in auto-upgrade, repair, and scaling. On top of that, GKE provides end-to-end container security, including private and hybrid networking.
How Does GKE Make Scaling Easy?
As the demand for Mindful Containers grows, they now need to scale their services. Manually scaling a Kubernetes cluster for availability and reliability can be complex and time consuming. GKE automatically scales the number of pods and nodes based on the resource consumption of services.
- Vertical Pod Autoscaler (VPA) watches resource utilization of your deployments and adjusts requested CPU and RAM to stabilize the workloads.
- Node Auto Provisioning optimizes cluster resources with an enhanced version of Cluster Autoscaling.
In addition to the fully managed control plane that GKE offers, using the Autopilot mode of operation automatically applies industry best practices and can eliminate all node management operations, maximizing your cluster efficiency and helping to provide a stronger security posture.
What Is Cloud Run?
Cloud Run is a fully managed compute environment for deploying and scaling serverless HTTP containers without worrying about provisioning machines, configuring clusters, or autoscaling.
- No vendor lock-in — Because Cloud Run takes standard OCI containers and implements the standard Knative Serving API, you can easily port over your applications to on-premises or any other cloud environment.
- Fast autoscaling — Microservices deployed in Cloud Run scale automatically based on the number of incoming requests, without you having to configure or manage a full-fledged Kubernetes cluster. Cloud Run scales to zero — that is, uses no resources — if there are no requests.
- Split traffic — Cloud Run enables you to split traffic between multiple revisions, so you can perform gradual rollouts such as canary deployments or blue/green deployments.
- Custom domains — You can set up custom domain mapping in Cloud Run, and it will provision a TLS certificate for your domain.
- Automatic redundancy — Cloud Run offers automatic redundancy so you don't have to worry about creating multiple instances for high availability.
How to Use Cloud Run
With Cloud Run, you write your code in your favorite language and/or use a binary library of your choice. Then push it to Cloud Build to create a container build. With a single command — gcloud run deploy — you go from a container image to a fully managed web application that runs on a domain with a TLS certificate and autoscales with requests.
How Does Cloud Run Work?
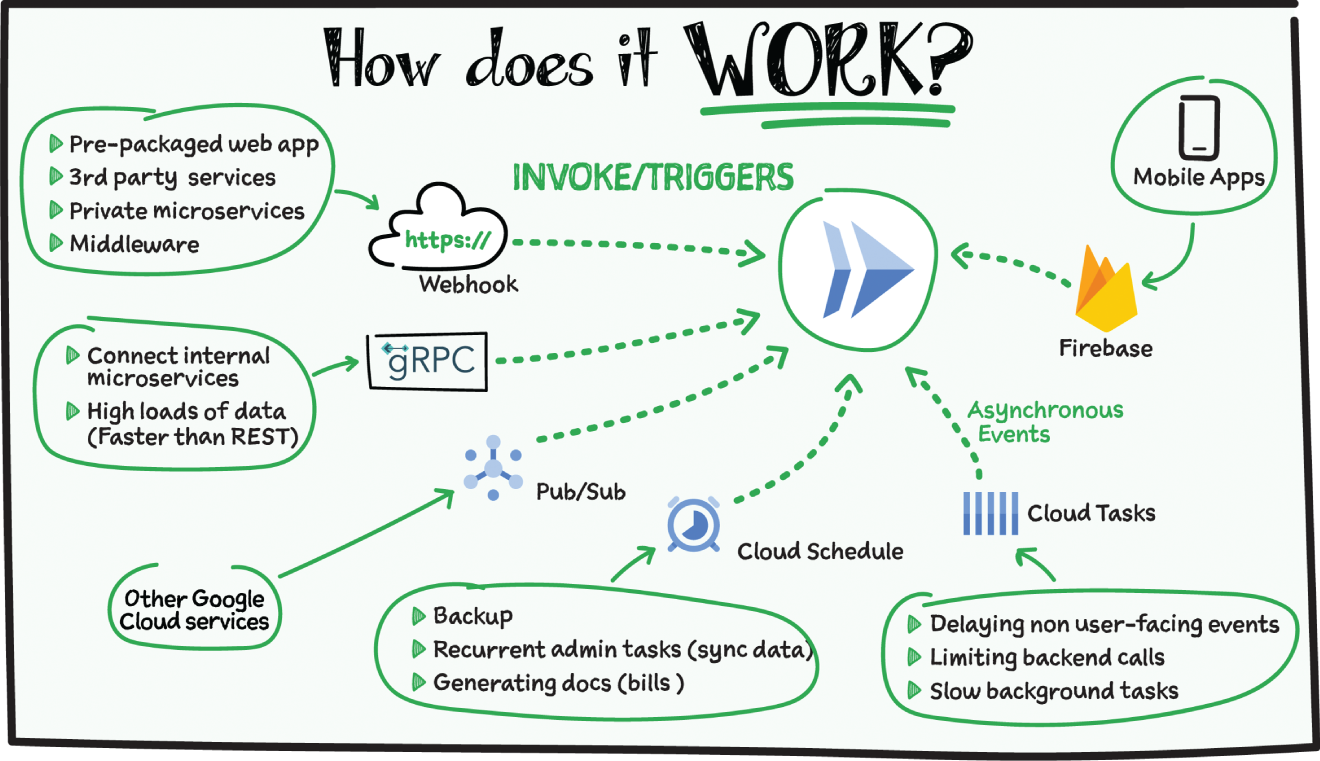
Cloud Run service can be invoked in the following ways:
- HTTPS: You can send HTTPS requests to trigger a Cloud Run-hosted service. Note that all Cloud Run services have a stable HTTPS URL. Some use cases include:
- Custom RESTful web API
- Private microservice
- HTTP middleware or reverse proxy for your web applications
- Prepackaged web application
- gRPC: You can use gRPC to connect Cloud Run services with other services — for example, to provide simple, high-performance communication between internal microservices. gRPC is a good option when you:
- Want to communicate between internal microservices
- Support high data loads (gRPC uses protocol buffers, which are up to seven times faster than REST calls)
- Need only a simple service definition and you don't want to write a full client library
- Use streaming gRPCs in your gRPC server to build more responsive applications and APIs
- WebSockets: WebSockets applications are supported on Cloud Run with no additional configuration required. Potential use cases include any application that requires a streaming service, such as a chat application.
- Trigger from Pub/Sub: You can use Pub/Sub to push messages to the endpoint of your Cloud Run service, where the messages are subsequently delivered to containers as HTTP requests. Possible use cases include:
- Transforming data after receiving an event upon a file upload to a Cloud Storage bucket
- Processing your Google Cloud operations suite logs with Cloud Run by exporting them to Pub/Sub
- Publishing and processing your own custom events from your Cloud Run services
- Transforming data after receiving an event upon a file upload to a Cloud Storage bucket
- Running services on a schedule: You can use Cloud Scheduler to securely trigger a Cloud Run service on a schedule. This is similar to using cron jobs. Possible use cases include:
- Performing backups on a regular basis
- Performing recurrent administration tasks, such as regenerating a sitemap or deleting old data, content, configurations, synchronizations, or revisions
- Generating bills or other documents
- Executing asynchronous tasks: You can use Cloud Tasks to securely enqueue a task to be asynchronously processed by a Cloud Run service. Typical use cases include:
- Handling requests through unexpected production incidents
- Smoothing traffic spikes by delaying work that is not user-facing
- Reducing user response time by delegating slow background operations, such as database updates or batch processing, to be handled by another service
- Limiting the call rate to backend services like databases and third-party APIs
- Events from Eventrac: You can trigger Cloud Run with events from more than 60 Google Cloud sources. For example:
- Use a Cloud Storage event (via Cloud Audit Logs) to trigger a data processing pipeline
- Use a BigQuery event (via Cloud Audit Logs) to initiate downstream processing in Cloud Run each time a job is completed

How Is Cloud Run Different from Cloud Functions?
Cloud Run and Cloud Functions are both fully managed services that run on Google Cloud's serverless infrastructure, auto-scale, and handle HTTP requests or events. They do, however, have some important differences:
- Cloud Functions lets you deploy snippets of code (functions) written in a limited set of programming languages, whereas Cloud Run lets you deploy container images using the programming language of your choice.
- Cloud Run also supports the use of any tool or system library from your application; Cloud Functions does not let you use custom executables.
- Cloud Run offers a longer request timeout duration of up to 60 minutes, whereas with Cloud Functions the request timeout can be set as high as 9 minutes.
- Cloud Functions only sends one request at a time to each function instance, whereas by default Cloud Run is configured to send multiple concurrent requests on each container instance. This is helpful to improve latency and reduce costs if you're expecting large volumes.
What Is App Engine?
App Engine is a fully managed serverless compute option in Google Cloud that you can use to build and deploy low-latency, highly scalable applications. App Engine makes it easy to host and run your applications. It scales them from zero to planet scale without you having to manage infrastructure. App Engine is recommended for a wide variety of applications, including web traffic that requires low-latency responses, web frameworks that support routes, HTTP methods, and APIs.
Environments
App Engine offers two environments; here's how to choose one for your application:
- App Engine Standard — Supports specific runtime environments where applications run in a sandbox. It is ideal for apps with sudden and extreme traffic spikes because it can scale from zero to many requests as needed. Applications deploy in a matter of seconds. If your required runtime is supported and it's an HTTP application, then App Engine Standard is the way to go.
- App Engine Flex — Is open and flexible and supports custom runtimes because the application instances run within Docker containers on Compute Engine. It is ideal for apps with consistent traffic and regular fluctuations because the instances scale from one to many. Along with HTTP applications, it supports applications requiring WebSockets. The max request timeout is 60 minutes.
How Does It Work?
No matter which App Engine environment you choose, the app creation and deployment process is the same. First write your code, next specify the app.yaml file with runtime configuration, and finally deploy the app on App Engine using a single command: gcloud app deploy.
Notable Features
- Developer friendly — A fully managed environment lets you focus on code while App Engine manages infrastructure.
- Fast responses — App Engine integrates seamlessly with Memorystore for Redis, enabling distributed in-memory data cache for your apps.
- Powerful application diagnostics — Cloud Monitoring and Cloud Logging help monitor the health and performance of your app, and Cloud Debugger and Error Reporting help diagnose and fix bugs quickly.
- Application versioning — Easily host different versions of your app, and easily create development, test, staging, and production environments.
- Traffic splitting — Route incoming requests to different app versions for A/B tests, incremental feature rollouts, and similar use cases.
- Application security — Helps safeguard your application by defining access rules with App Engine firewall and leverage managed SSL/TLS certificates by default on your custom domain at no additional cost.

What Is Cloud Functions?
Cloud Functions is a fully managed event-driven serverless function-as-a-service (FaaS). It is a serverless execution environment for building and connecting cloud services. With Cloud Functions you write simple, single-purpose functions that are attached to events emitted from your cloud infrastructure and services. Your function is a piece of code triggered when an event being watched is fired. Your code executes in a fully managed environment. There is no need to provision any infrastructure or worry about managing any servers in case of increase or decrease in traffic. Cloud Functions is also fully integrated with Cloud Operations for observability and diagnosis. Because Cloud Functions is based on an open source FaaS framework, it is easy to migrate.
How to Use Cloud Functions
To use Cloud Functions, just write the logic in any of the supported languages (Go, Python, Java, Node.js, PHP, Ruby, .NET); deploy it using the console, API, or Cloud Build; and then trigger it via HTTP(s) request from any service, file uploads to Cloud Storage, events in Pub/Sub, Firebase, or even a direct call through the command-line interface (CLI).
Cloud Functions augments existing cloud services and allows you to address an increasing number of use cases with arbitrary programming logic. It provides a connective layer of logic that lets you write code to connect and extend cloud services. Listen and respond to a file upload to Cloud Storage, a log change, or an incoming message on a Pub/Sub topic.
Pricing and Security
The pricing is based on number of events, compute time, memory, and ingress/egress requests and costs nothing if the function is idle. For security, using Identity and Access Management (IAM) you can define which services or personnel can access the function, and using the VPC controls, you can define network-based access.
Some Cloud Functions Use Cases
- Data processing/ETL — Listen and respond to Cloud Storage events such as when a file is created, changed, or removed. Process images, perform video transcoding, validate and transform data, and invoke any service on the Internet from your Cloud Functions.
- Webhooks — Via a simple HTTP trigger, respond to events originating from third-party systems like GitHub, Slack, Stripe, or from anywhere that can send HTTP requests.
- Lightweight APIs — Compose applications from lightweight, loosely coupled bits of logic that are quick to build and that scale instantly. Your functions can be event-driven or invoked directly over HTTP/S.
- Mobile backend — Use Google's mobile platform for app developers or Firebase, and write your mobile backend in Cloud Functions. Listen and respond to events from Firebase Analytics, Realtime Database, Authentication, and Storage.
- IoT — Imagine tens or hundreds of thousands of devices streaming data into Pub/Sub, thereby launching Cloud Functions to process, transform, and store data. Cloud Functions lets you do so in a way that's completely serverless.

What Is Google Cloud VMware Engine?
If you have VMware workloads and you want to modernize your application to take advantage of cloud services to increase agility and reduce total cost of ownership (TCO), then Google Cloud VMware Engine is the service for you. It is a managed VMware service with bare-metal infrastructure that runs the VMware software stack on Google Cloud — fully dedicated and physically isolated from other customers.
Benefits of Google Cloud VMware Engine
One benefit is operational continuity. Your team can continue to utilize their existing processes, and they can use their existing skills and knowledge. The infrastructure also scales on demand in minutes when you need it. You get built-in DDoS protection and security monitoring, and you can continue to use the VMware-based compliance and security policies. You get reliability, with fully redundant and dedicated 100 Gbps networking, providing up to 99.99 percent availability to meet the needs of your VMware stack. There is also infrastructure monitoring so that failed hardware automatically gets replaced. With the hybrid platform, you get the benefits of high speed, low latency, and access to other resources within Google Cloud such as BigQuery, AI Platform, GCS, and more. Because the service is highly engineered for automation, operational efficiency, and scale, it is also cost effective.
How Does Google Cloud VMware Engine Work?
Google Cloud VMware Engine makes it easy to migrate or extend your VMware environment to Google Cloud. Here is how it works. You can easily migrate your on-premises VMware instances to Google Cloud, using included HCX licenses, via a cloud VPN or interconnect. The service consists of VMware vCenter, the virtual machines, ESXi host, storage, and network on bare metal. You can easily connect from the service to other Google Cloud services such as Cloud SQL, BigQuery, and Memorystore. You can access the service UI, billing, and Identity and Access Management all from the Google Cloud console as well as connect to other third-party disaster recovery and storage services such as Zerto and Veeam.
Google Cloud VMware Engine Use Cases
- Retire or migrate data centers: Scale data center capacity in the cloud and stop managing hardware refreshes. Reduce risk and cost by migrating to the cloud while still using familiar VMware tools and skills. In the cloud, use Google Cloud services to modernize your applications at your pace.
- Expand on demand: Scale capacity to meet unanticipated needs, such as new development environments or seasonal capacity bursts, and keep it only as long as you need it. Reduce your up-front investment, accelerate speed of provisioning, and reduce complexity by using the same architecture and policies across both on-premises and the cloud.
- Disaster recovery and virtual desktops in Google Cloud: High-bandwidth connections let you quickly upload and download data to recover from incidents.
- Virtual desktops in Google Cloud: Create virtual desktops infrastructure (VDI) in Google Cloud for remote access to data, apps, and desktops. Low-latency networks give you fast response times — similar to those of a desktop app.
- Power high-performance applications and databases: In Google Cloud you have a hyper-converged architecture designed to run your most demanding VMware workloads such as Oracle, Microsoft SQL Server, middleware systems, and high-performance NoSQL databases.
- Unify DevOps across VMware and Google Cloud: Optimize VMware administration by using Google Cloud services that can be applied across all your workloads, without having to expand your data center or rearchitect your applications. You can centralize identities, access control policies, logging, and monitoring for VMware applications on Google Cloud.
What Is Bare Metal Solution?
Enterprises are migrating to the cloud to reduce management overhead and increase business agility. There are many workloads that are easy to lift and shift to the cloud, but there are also specialized workloads (such as Oracle) that are difficult to migrate to a cloud environment due to complicated licensing, hardware, and support requirements. Bare Metal Solution provides a path to modernize the application infrastructure landscape while maintaining the existing investments and architecture. It enables an easier and a faster migration path.
Features
Bare Metal Solution offers a reliable, secure, and high-performance database infrastructure for your Oracle workloads
- Seamlessly access all Oracle capabilities: Run Oracle databases the same way you do it on-premises. Install Oracle Real Application Clusters (RAC) on certified hardware for HA, use Oracle Data Guard for disaster recovery, and Oracle Recovery Manager (RMAN) for backups. Google Cloud’s service catalog provides analogous topologies to all Oracle Maximum Availability Architecture templates.
- Integrated support and billing: It offers a seamless experience with support for infrastructure, including defined SLAs for initial response, defined enterprise-grade SLA for infrastructure uptime and interconnect availability, 24/7 coverage for all Priority 1 and 2 issues, and unified billing across Google Cloud and Bare Metal Solution for Oracle.
- Data protection: Helps meet compliance requirements with certifications such as ISO, PCI DSS, and HIPAA, plus regional certifications where applicable. Copy data management and backups provided by Actifio, fully integrated into Bare Metal Solution for Oracle.
- Tools and services to simplify operations: Automate day-to-day operational database administrator tasks by either using Google’s open source Ansible based toolkit or Google Cloud’s Kubernetes operator for Oracle. You can integrate these tools with their existing automation framework of choice.
How Does It Work?
It provides purpose-built bare-metal machines in regional extensions that are connected to Google Cloud by a managed, high-performance connection with a low-latency network fabric. It supports Windows and Linux workloads. Google Cloud provides and manages the core infrastructure, the network, the physical and network security, and hardware monitoring capabilities in an environment from which you can access all of the Google Cloud services.
What Does the Bare Metal Solution Environment Include?
The core infrastructure includes secure, controlled-environment facilities, and power. Bare Metal Solution also includes the provisioning and maintenance of the custom, sole-tenancy hardware with local SAN, as well as smart hands support. The network, which is managed by Google Cloud, includes a low-latency Cloud Interconnect connection into your Bare Metal Solution environment. And you have access to other Google Cloud services such as private API access, management tools, support, and billing. When you use Google Cloud Bare Metal Solution, you can bring your own license of the specialized software such as Oracle, and you are responsible for your software, applications, and data. This includes maintenance, security, backups, and software monitoring.
Choosing the right infrastructure options to run your application is critical, both for the success of your application and for the team that is managing and developing it. This section breaks down some of the most important factors that you need to consider when deciding where you should run your stuff. Remember that no decision is necessarily final; you can always move from one option to another but it's important to consider all the relevant factors.
What Is the Level of Abstraction You Need?
You can run an application on VMs directly on Compute Engine, or build them for Serverless with Cloud Run or Cloud Functions, and in the middle is Kubernetes with Google Kubernetes Engine. As you move up the layers of abstraction from raw VMs (where you manage everything) → Kubernetes (container orchestration and management)→ Serverless (provide your code/container to run), your operations get easier as there's less for you to manage, but your deployment choices and flexibility are reduced at the same time. You're trading the flexibility to deploy things however you like, with the need to manage all that custom configuration.
- If you need more control over the underlying infrastructure (for example, the operating system/disk images, CPU, RAM, and disk) then it makes sense to use Compute Engine. This is a typical path for legacy application migrations and existing systems that require specific OS and underlying requirements.
- Containers provide a way to virtualize an OS so that multiple workloads can run on a single OS instance. They are fast and lightweight, and they provide portability. If your applications are containerized, then you have two main options. You can use Google Kubernetes Engine, or GKE, which gives you full control over the container down to the nodes with specific OS, CPU, GPU, disk, memory, and networking. GKE also offers Autopilot, when you need the flexibility and control but have limited ops and engineering support. If, on the other hand, you are just looking to run your application in containers without having to worry about scaling the infrastructure, then use Cloud Run: you can just write your application code, optionally package it into a container, and deploy it.
- Regardless of your chosen abstraction, Cloud Functions provides a simple, lightweight solution for extending the behavior of the services you use. Think of it as the scripting engine of the cloud. You can use it to connect two services together, or transform data in-flight between services.
What Is Your Use Case?
- If you are migrating a legacy application with specific licensing, OS, kernel, or networking requirements such as Windows-based applications, genomics processing, or SAP HANA, use Compute Engine.
- If you are building a cloud-native, microservices-based application then GKE or Cloud Run are both great options. Choice would depend on your focus. If developer productivity is the focus, then use a serverless containerization approach with Cloud Run, and if you are building your own platform and tooling on a cloud-native basis, then GKE is a good fit.
- If your application needs a specific OS or network protocols beyond HTTP, HTTP/2, or gRPC, use GKE.
- If you are building an application for hybrid and multi-cloud, then portability is top of mind. GKE is a great fit for this use case because it is based on open source Kubernetes, which helps with keeping all your on-premise and cloud environments consistent. Additionally, Anthos is a platform specifically designed for hybrid and multi-cloud deployments. It provides single-pane-of-glass visibility across all clusters from infrastructure to application performance and topology.
- For websites or APIs use Cloud Run. Cloud Run supports containerized deployment and scaling an application in a programming language of your choice with HTTP/s or WebSocket support.
- For data processing apps and webhooks use Cloud Run or Cloud Functions. Consider applications that transform lightweight data as it arrives and store it as structured data. You can trigger these transformations from Google Cloud sources or HTTP requests.
- If your application is kicking off a task based on an event, Cloud Functions is a great choice. Think of use cases such as video transcoding or image processing once an asset is stored in a Cloud Storage bucket. In this case your code just does one thing based on an event/trigger such as Cloud Storage, Pub/Sub, Firebase, HTTP, and others.
Need Portability with Open Source?
If your requirement is based on portability and open source support, take a look at GKE, Cloud Run, and Cloud Functions. They are all based on open source frameworks that help you avoid vendor lock-in and give you the freedom to expand your infrastructure into hybrid and multi-cloud environments. GKE clusters are powered by the Kubernetes open source cluster management system, which provides the mechanisms through which you interact with your cluster. Cloud Run supports Knative, an open source project that supports serverless workloads on Kubernetes. Cloud Functions uses open source frameworks to run functions across multiple environments.
What Are Your Team Dynamics Like?
If you have a team of developers and you want their attention focused on the code, then Cloud Run and Cloud Functions are good choices because you won't need the team managing the infrastructure, scale, and operations.
If you are building your own platform for your developers to use, or your developers are already familiar with Kubernetes, then GKE is a good choice as it offers a managed service that handles much of the operation of Kubernetes while still providing the full range of capabilities available in Kubernetes.
Both Cloud Run and GKE run containers, so there is a natural portability between these environments, and using both platforms in combination is also a common pattern.
What Type of Billing Model Do You Prefer?
Compute Engine and GKE billing models are based on resources, which means you pay for the duration that the resource is provisioned. You can also take advantage of sustained and committed use discounts based on your usage pattern.
Cloud Run, Cloud Functions, and GKE Autopilot are “pay as you go,” only charging for what you use, with a more granular pricing model.