

CHAPTER
1
Introduction to Multitenant
With Oracle Database 12c, Oracle introduced a major change to its database architecture. Before Oracle Database 12c, an instance could open only one database. If you had multiple databases, you would need to start multiple instances, because they were totally isolated structures, even when hosted on the same server. This differs from most other RDBMSs, where a single system can manage multiple databases.
With the release of Oracle Database 12c, one instance can open multiple pluggable databases or PDBs. Oracle has signaled that the new multitenant architecture is here to stay, with the deprecation of the old style. With or without the multitenant option, all future Oracle databases will run on the multitenant architecture, a fact that Oracle database administrators cannot ignore.
History Lesson: A New Era in IT
Let’s start by taking a brief look at the history of database use, before introducing the architecture of the future. As you can see in Figure 1-1, we will not refer to dates, but version numbers, going back to the time when the Oracle Database became predominant.

FIGURE 1-1. From IT consolidation to the cloud
When Oracle Database 8i and 9i were on the market, midrange computers became prevalent in data centers. We were moving from the mainframe era to a client/server era, and Oracle architecture was very well suited for that. Written in the C programming language, it was available on multiple platforms and with all user management contained within its data dictionary. It was ready for the client/server architecture, using the OS only to listen on a TCP/IP port and to store files. Furthermore, the architecture was scalable on minicomputers, thanks to the parallel server feature, which would later become RAC (Real Application Clusters).
These databases were growing along with the overall number of servers. It was common at that time to have a lot of physical servers with direct attached disks (DAS), each running one or two Oracle Database 8i or 9i instances.
With the number of databases increasing, it became a nightmare to maintain all those servers and disks. Having internal disks made capacity planning tremendously difficult when facing the exponential increase of data. By the time Oracle Database 10g was introduced, we needed to consolidate storage, so we put the database datafiles into a storage array, shared by all servers through a storage area network (SAN); that was storage consolidation.
By the time Oracle Database 11g rolled around, the prevailing thought was to do with servers what had been done with disks earlier. Instead of sizing and maintaining multiple servers, virtualization software brought us the possibility of putting our physical servers in a farm and provisioning virtual machines on top of them. That was the way in this previous era: application servers, SAN or network-attached storage (NAS), and virtual machines.
And now Oracle Database 12c accompanies a new day. Even organizations with consolidated storage and servers now realize that operating this infrastructure is not their core business, and instead, they now demand IT as a service, which is both scalable and flexible. Small companies want to provision their IT from a public cloud, and larger companies build their own private clouds. In both cases, virtualization can provide Infrastructure as a Service (IaaS). But we also want Application as a Service (AaaS) and need Database as a Service (DBaaS). This is a significant change in the technology ecosystem, similar in scale and importance to the earlier move from client/server to application servers. This new direction will not be immediate—it will take time. But it is safe to predict that over the next ten years, the hybrid mixed model (on-premise/cloud) will start strong, but be slowly supplanted by the cloud.
As is expected, a new era has different requirements, and the future of databases seems bound up with consolidation, agile development, and rapid provisioning. For Oracle, some such features came progressively from Oracle Database 9i to 11g, such as easy transport of data, cloning, and thin provisioning. But two core architectural foundations came from the previous era and were not ready to accommodate consolidation: the need to run one instance per database, and having one data dictionary per database. Oracle Database 12c provides the answer: multitenancy. Retaining its portability philosophy, Oracle has designed this architecture to enable you to run your application on the same database, with the same software running from small server to large cloud.
The Road to Multitenant
This new era is about consolidation. Some people can imagine it as a centralized system and centralized administration, recalling the time of mainframes. But there is another challenge that comes with it: we need more and more agility. Provisioning a database is not an easy operation today, and we cannot make it worse.
Consider an example. You are an Oracle DBA. A developer comes to your desk and asks for a new database; she is under the impression that this is a simple demand, merely requiring a few clicks of an administration interface. You look at her, wide eyed, and tell her she has to fill out a request with specifics related to storage, memory, CPU, and availability requirements. Furthermore, you explain, the request will have to be approved by management, and then it will take a few days or a week to set up. And here begins a pattern of misunderstanding between dev and ops.
The developer probably hasn’t worked with Oracle databases before, so she has some notion of a database as a lightweight container for her application tables—and in many other non-Oracle RDBMSs, this is actually what is referred to as a “database.”
In Oracle, however, we have lightweight containers—schemas at logical level and tablespaces at physical level—but a database is an entity that comprises much more than that. An Oracle database is a set of schemas and tablespaces, plus all the metadata required to manage them (the data dictionary), along with a significant amount of PL/SQL code to implement the features (the DBMS packages). Each database must have its own instance, including a number of background processes and shared memory. And each database also has a structure to protect the transactions, comprising undo tablespaces and redo logs.
For these reasons, provisioning a new database is not a trivial operation. To do so, you must interact with the system administrators and the storage teams, because you need server and disk resources for it. You don’t want to put too many instances on the same server, but you can’t have a dedicated physical server for each database. Because of this, today we often virtualize and have a dedicated virtual machine (VM) for each instance, but this is not possible for every application, for every environment, in any agile sort of way—there are just too many of them. Furthermore, you end up wasting a lot of resources when you have to allocate server, storage, and instance for each database.
Prior to Oracle Database 12c, the answer to the developer, in this scenario, probably was to create a new schema for her in an existing database. But this solution is not always possible or feasible. Let’s explain why.
Schema Consolidation
Schema was exactly the objective prior to 12c. Each application had one schema owner, or a set of schemas if you wanted to separate tables and procedures. They were logically independent of each other, and security was controlled by grants.
Physically, you dedicated tablespaces to each application. This meant that, in case of a datafile loss, only one application was offline during the restore, which would also be the case if you wanted to relocate the tablespace to another filesystem. However, everything else was shared to optimize resource usage: instance processes and memory, SYSTEM and SYSAUX tablespaces, with dictionary.
The backup strategy is common, and the high availability (HA) policy is common. One DBA administers one database, and several applications run on it. This is exactly what the Oracle Database was designed for from its first versions.
Transportable Tablespaces
A large number of operations in the Oracle Database can be performed at the tablespace level. This is especially true since the inception of the transportable tablespaces feature, which enables you to physically copy your application datafiles to another database, and even to a newer version. Transportable tablespaces are significant because they were a forerunner to, and an ancestor of, multitenant. The Oracle Corporation patent for Transportable Tablespaces published in 1997 was entitled “Pluggable tablespaces for database systems.” And the multitenant architecture is the foundation for pluggable databases.
In this context, pluggable means that you can directly plug a physical structure (datafile) into a database and have it become part of that database. The transportable tablespaces feature enabled user tablespace datafiles to be plugged into the database. Then only the metadata (dictionary entries) had to be imported so that the logical object definitions matched what was stored physically in the datafiles.
In 12c you can transport databases, which is nothing less than transporting all user tablespaces: a “FULL=Y” transportable tablespace. But metadata still has to be transferred logically, and that operation can be lengthy if you have thousands of tables, even if those tables are empty. For example, if you want to migrate a PeopleSoft database, which has 20,000+ tables, the metadata import alone can take hours to create all those empty tables.
As you will see, with the superior implementation in multitenant, the transport of pluggable databases is actually the transport of all datafiles, including SYSTEM and SYSAUX, which stores the data dictionary, and perhaps even the UNDO. This means that all metadata is also imported physically and, as such, is a relatively quick operation.
Schema Name Collision
Schema consolidation is in fact difficult to achieve in real life. You want to consolidate multiple applications into the same database, along with multiple test environments of the same application, but you are faced with a number of application constraints.
What do you do if the schema owner is hard-coded into the application and you cannot change it? We were once involved in installing a telco billing application that had to be deployed in a schema called PB, and we wanted to consolidate multiple environments into the test database, but that was forbidden. The reason was that the schema name was hard-coded into the application, and in packages, and so on. We better understood that strange schema name when we hosted a consultant from the application vendor. You may be able to guess what his initials were.
If the application design is under your control you can avoid this problem, and needless to say, you should never hard-code the schema name. You can connect with any user and then simply set ALTER SESSION SET CURRENT_SCHEMA to have all referenced objects prefixed by the application schema owner. And if you have multiple schemas? It’s not a bad idea to have multiple schemas for your application. For example, you can separate data (tables) from code (PL/SQL packages). That makes for good isolation and encapsulation of data. But even in that case, you don’t need to hard-code the table schema name into the package. Just create synonyms for them into the package schema, which will reference the objects from the table schemas. You reference them from your PL/SQL code without the schema name (synonyms are in the same schema), and they are resolved to the other schema. If a name changes, you have to re-create only those synonyms. That can be done very easily and automatically.
Public Synonyms and Database Links
With the above-mentioned synonyms, we were talking about private synonyms, of course. Don’t use public synonyms. They cannibalize the whole namespace. When an application creates public synonyms, you cannot consolidate anything else on it. That’s a limitation for schema consolidation: objects that do not belong to a specific schema can collide with other applications and other versions or environments of the same application.
Roles, Tablespace Names, and Directories
An application can define and reference other objects, which are in the database public namespace—such is the case for roles, directories, and tablespace names. An application for which several environments can be consolidated into the same database must have parameters in the Data Definition Language (DDL) scripts so that those database objects names can be personalized for each environment. If this is not the case, schema consolidation will be difficult.
Those public objects that do not pertain to a schema also make data movement more complex. For example, when you use Data Pump to import a schema, those objects may need to have been created earlier.
Cursor Sharing
Even with an application that is designed for schema consolidation, you may encounter performance issues when consolidating everything into the same database. We once had a database with 3000 identical schemas. They were data marts: same structure, different data.
And, obviously, the application code was the same. The user connected to one data mart and ran the queries that were coded into the applications. This meant that the same queries—exactly the same SQL text—were run on different schemas. If you know how cursor sharing works in Oracle, you can immediately see the problem: one cursor has thousands of child cursors. A parent cursor is shared by all identical SQL text, and child cursors are created when the objects are different, which is the case when you are not on the same schema. Parsing has to follow a long chained list of children cursors, holding latches during that time, and that means huge library cache contention.
In multitenant, the parent cursors are shared for consolidation purposes, but enhancements may be implemented in the child cursor search to alleviate this problem.
Table Consolidation
When you want to consolidate the data for multiple environments of the same application and same version of an application, which means that the tables have exactly the same structure, you can put everything into the same table. This is usually done by adding an environment identifier (company, country, market, and so on) into each primary key. The advantage of this is that you can manage everything at once. For example, when you want to add an index, you can add it for all environments.
For performance and maintenance reasons, you can separate the data physically by partitioning those tables on the environment ID and put the partitions into different tablespaces. However, the level of isolation is very low, and that affects performance, security, and availability.
Actually most of the applications that were designed like this usually store only one environment. In most cases, the ID that is added in front of each primary key has only one value, and this is why Oracle introduced the skip scan index optimization. You can build virtual private database policy to manage access on those environments. You can manage the partitions independently, even at physical level, with exchange partitions. If you want to see an example of that, look at the RMAN repository: information for all registered databases is stored in the same tables. However, the isolation is not sufficient to store different environments (test, development, production), or to store different versions (where the data model is different).
Server Consolidation
If you want several independent databases but don’t want to manage one server for each, you can consolidate several instances on the same server. If you go to Oracle’s Ask Tom site (asktom.oracle.com/) for questions about the recommended number of instances per server, Tom Kyte’s answer is this: “We recommend no more than ONE instance per host—a host can be a virtual machine, a real machine, we don’t care—but you want ONE HOST = ONE INSTANCE.” In real life, however, most database servers we have seen have several instances running on them. You can install multiple versions of Oracle (the ORACLE_HOME ), and you can have a lot of instances running on one server—and you often have to do it. We have seen servers running as many as 70 instances.
There are few ways to isolate the resources between instances. As for memory, you can divide the physical memory among instances by setting the shared memory with SGA_MAX_SIZE, and in 12c you can even limit the process memory with PGA_AGGREGATE_LIMIT. You can also limit the CPU used by each instance with instance caging, setting for each instance the maximum number of processes that can run in the CPU. And with the latest license, Standard Edition 2, you don’t even need Enterprise Edition to do instance caging. We will come back to this in Chapter 3.
Running a lot of instances on one server is still a problem, however. For example, when you reboot the server, you will have lot of processes to start and memory to allocate. A server outage, planned or not, will penalize a lot of applications. And you waste a lot of resources by multiplying the System Global Area (SGA) and database dictionaries.
Virtualization
Today, virtualization is a good way to run only one instance per server without having to manage a lot of physical servers. You have good isolation of environments, you can allocate CPU, memory, and I/O bandwidth, within limits. And you can even isolate them on different networks. However, even if those servers are virtual machines, you don’t solve the resource wastage of multiple OSs, Oracle software, memory, and the dictionary. And you still have multiple databases to manage—to back up, to put in high-availability, in Data Guard, and so on. And you have multiple OSs to patch and monitor.
In addition to that, virtualization can be a licensing nightmare. When Oracle software is licensed by the processors where the software is installed, Oracle considers that, on some virtualization technologies, the software is installed everywhere the VM can run. The rules depend on the hypervisor vendor and on the version of this hypervisor.
Multiple Databases Managed by One Instance
The idea, then, is to find the consolidation level that fits both the isolation of the environment and the consolidation of resources. This is at a higher level than schema consolidation, but at a lower level than the instance and the database as we know it today. It means you can have several databases managed by the same instance on the same server.
This did not exist in versions of Oracle Database prior to 12c, but it is now possible with multitenant architecture. Now, one consolidation database can manage multiple pluggable databases. In addition to a new level that can be seen as an independent database, the pluggable database architecture brings agility in provisioning, moving, and upgrading.
Summary of Consolidation Strategies
Table 1-1 briefly summarizes the different consolidation alternatives prior to multitenant.

TABLE 1-1. Consolidation Strategies Pros and Cons
The System Dictionary and Multitenant Architecture
The major change in the multitenant architecture regards the system dictionary. Let’s see how it was implemented in all previous versions and what changed in 12c.
The Past: Non-CDB
A database stores both data and metadata. For example, suppose you have the EMP table in the SCOTT schema. The description of the table—its name, columns, datatypes, and so on—are also stored within the database. This description—the metadata—is stored in a system table that is part of the dictionary.
The Dictionary
Codd’s rules (created by E. F. Codd, who invented the relational model) defines that a RDBMS must represent metadata in the same way as the data: you can query both using SQL queries. As a database administrator, you do that every day. You query the dictionary views, such as DBA_TABLES, to get information about your database objects. This rule is for logical representation only, and the dictionary views provide that. But Oracle went further by deciding to store physically the metadata information in relational tables—the same kind of tables as application tables, but they are owned by SYS schema and stored in the system’s tablespaces (SYSTEM and SYSAUX).
Without using the actual name and details of the Oracle dictionary, Figure 1-2 gives you the idea. Table SCOTT.DEPT stores user data. The definition of the table is stored in a dictionary table, SYS.COLUMNS, because it stores column information here. And because this table is itself a table, we have to store its definition in the same way.

FIGURE 1-2. Storing metadata with data
And there are not only table definitions in the dictionary. Until version 8i, even the physical description of the data storage (table extents) were stored in the dictionary. That changed with Locally Managed Tablespaces, however, when tablespace became more self-contained in preparation of pluggable features. On the other hand, at each new version, a lot of new information was added to the dictionary. In the current version, a large part of the Oracle Database software is implemented as PL/SQL packages, which are stored in the dictionary.
Oracle-Maintained Objects
The implementation choice we’ve described is specific to the Oracle RDBMS: The dictionary is stored in the database. Each database has its own dictionary. And if you used logical export/import (EXP/IMP or Data Pump) to move a database, you probably have seen how it is difficult to distinguish the dictionary objects belonging to the system from the user objects belonging to the applications. When you import a full database (FULL=Y in IMPDP options, as discussed in Chapter 8) into a newly created database, you don’t want to import the dictionary because it already exists in the target.
Of course, objects in the SYS schema are dictionary objects, and they are ignored by Data Pump. But if someone has created user objects, then they are lost. Grants on SYS objects are lost. And you can find system objects elsewhere, such as OUTLN, MDSYS, XDB, and so on. A lot of roles come from the system, and you can create your own role. It’s difficult to distinguish them easily.
Fortunately, 12c includes a flag in DBA_OBJECTS, DBA_USERS, and DBA_ROLES to identify the Oracle-maintained objects that are created with the database and that do not belong to your application. Let’s query the Oracle-maintained schemas list from a 12c database:
![]()

This is a big improvement in 12c. You can easily determine what belongs to your application and what belongs to the system itself. The ORACLE_MAINTAINED flag is present in DBA_OBJECTS, DBA_USERS, and DBA_ROLES views and it’s now easy to distinguish the objects created at database creation from those created by your application.

NOTE
Before 12c, you could try to list the objects from different views used by Oracle internally. There are the views used by the data movement, listing what they must ignore: EXU8USR for EXP/IMP, KU_NOEXP_TAB for Data Pump, and LOGSTDBY$SKIP_SUPPORT for Data Guard. There is also the DEFAULT_PWD$ table to identify some pre-created schemas. And you can also query the V$SYSAUX_OCCUPANTS or DBA_REGISTRY views.
System Metadata vs. Application Metadata
We described the metadata structures: schemas, objects, and roles. Let’s go inside them, into the data. You know that table definitions are stored in dictionary tables, and in Figure 1-2 we simplified this in a SYS.COLUMN table. But the dictionary data model is more complex than that. Actually, object names are in SYS.OBJ$, table information is in SYS.TAB$, column information is in SYS.COL$, and so on. Those are tables, and each has its own definition—the metadata—which is stored in that dictionary: SYS.TAB$, for example, has rows for your tables, but it also has rows for all dictionary tables.
SYS.TAB$ has a row to store the SYS.TAB$ definition itself. You may ask how that row is inserted at the table creation (which is database creation), because the table does not yet exist. Oracle has a special bootstrap code that is visible in the ORACLE_HOME. (It’s beyond the scope of this book, but you can look at the dcore.bsq file in ORACLE_HOME/rdbms/admin directory. You can also query the BOOTSTRAP$ table to see the code that creates those tables at startup in dictionary cache, so that basic metadata is available immediately to allow access to the remaining metadata.)
All metadata is stored in those tables, but this is a problem in non-multitenant databases: system information (which belongs to the RDBMS itself) is mixed with user information (which belongs to the application). Both of their metadata is stored in the same tables, and everything is stored into the same container: the database.
This is what has changed with multitenant architecture: we have now multiple containers to separate system information from application information.
Multitenant Containers
The multitenant database’s most important structure is the container. A container contains data and metadata. What is different in multitenant is that a container can itself contain several containers inside it in order to separate objects logically and physically. A container database contains several pluggable databases, and an additional one, the root, contains the common objects.
A multitenant database is a container database (CDB). The old architecture, in which a database is a single container that contains no subdivisions, is called a non-CDB. In 12c you can choose which one you want to create. You create a CDB, the multitenant one, by setting ENABLE_PLUGGABLE=true in the instance parameters and by adding the ENABLE PLUGGABLE to the CREATE DATABASE statement. (More details are in Chapter 2.)
This creates the CDB, which will contain other containers identified by a number, the container ID, and a name. It will contain at least a root container and a seed container, and you will be able to add your own containers, up to 252 in version 12.1, and thousands in 12.2.
Pluggable Database
The goal of multitenant is consolidation. Instead of having multiple databases on a server, we can now create only one consolidated database, the CDB, which contains multiple pluggable databases (PDBs). And each PDB will appear as a whole database to its users, with multiple schemas, public objects, system tablespaces, dictionary views, and so on.
The multitenant architecture will be used to consolidate on private or public clouds, with hundreds or thousands of pluggable databases. The goal is to provision those pluggable databases quickly and expose them as if they were a single database. By design, anyone connected to a pluggable database cannot distinguish it from a standalone database.
In addition, all commands used in previous Oracle Database versions are compatible. For example, you can run shutdown when you are connected to a PDB and it will close your PDB. It will not actually shut down the instance, however, because other PDBs are managed by that instance, but the user will see exactly what he would see if he shut down a standalone database.
Consider another example. We are connected to a pluggable database and we can’t have undo tablespaces because they are at CDB level only (we can change this in 12.2, but you’ll learn about that in Chapter 8). Let’s try to create one:
![]()

There are no errors, but the undo tablespaces are obviously not created. It’s impossible to create a 100-terabyte datafile. My statements have just been ignored. The idea is that a script made to run in a database can create an undo tablespace, so the syntax must be accepted in a pluggable database. It’s allowed because everything you can do in a non-CDB must be accepted in a PDB, but it is ignored because here the undo tablespace is at the CDB level only.
With multitenant, you have new commands, and all commands you know are accepted by a PDB. You can give the DBA role to a PDB user, and she will be able to do everything a DBA can do with regard to her database. And the PDB user will be isolated from the other pluggable databases and will not see what is at the CDB level.
CDB$ROOT
How big is your SYSTEM tablespace? Just after database creation, it’s already a few gigabytes. By database creation, we aren’t referring to the CREATE DATABASE statement, but running catalog.sql and catproc.sql. (Well, you don’t call those directly in multitenant; it’s catcdb.sql but it runs the same scripts.) The dictionary of an empty database holds gigabytes of dictionary structures and system packages that are part of the Oracle software—as the ORACLE_HOME binaries—but they are deployed as stored procedures and packages inside the database. And if you put 50 databases on a server, you have 50 SYSTEM tablespaces that hold the same thing (assuming that they are the same version and same patche level). If you want to consolidate hundreds or thousands of databases, as you can do with PDBs, you don’t want to store the same data in each one. Instead, you can put all the common data into only one container and share it with the others. This is exactly what CDB$ROOT is: it’s the only container in a CDB that is not a PDB but stores everything that is common to the PDBs.
Basically, CDB$ROOT will store all the dictionary tables, the dictionary views, the system packages (those that start with dbms_), and the system users (SYS, SYSTEM, and so on)—and nothing else. The user data should not go in CDB$ROOT. You can create your own users only if you need them on all PDBs. You will see more about common users in Chapter 6.
You can think of CDB$ROOT as an extension of the ORACLE_HOME. It’s the part of the software that is stored in the database. It’s specific to the version of the ORACLE_HOME, and it is the same in all CDBs that are in the same version. Our 12.2.0.1 CDB$ROOT is mostly the same as yours.
PDB$SEED
The goal of a multitenant database, a CDB, is to create a lot of PDBs. More than that, it should be easy and quick to create PDBs on demand. It’s the architecture focused on Database as a Service (DBaaS). How do you create a database quickly with the Database Configuration Assistant (DBCA)? You create it from a template that has all datafiles. No need to re-create everything (as catalog.sql and catproc.sql do) if you can clone an empty database that already exists. This is exactly what the PDB$SEED is: it’s an empty PDB that you can clone to create another PDB. You don’t change it, it is read-only, and you can use it only as the source of a new PDB.
A CDB has at minimum one CDB$ROOT container and one PDB$SEED container. You can’t change them; you can only use them. Their structure will change only if you upgrade or patch the CDB.
Multitenant Dictionaries
One goal of the multitenant architecture is to separate system metadata from application metadata. System metadata, common to all PDBs, is stored in the CDB$ROOT, as are all system objects. Consider, for example, the package definitions. They are stored in the dictionary table SOURCE$, which we can query through the DBA_SOURCE dictionary views. In a non-CDB, this table contains both the system packages and the packages that you create—the packages owned by SYS, as well as the packages owned by your application schema; let’s call it ERP. In multitenant, the CDB$ROOT contains only system metadata, so in our previous example, that means all the SYS packages.
In our PDB dedicated to the application, let’s call it PDBERP, the SOURCE$ contains only the packages of our application, the ERP ones. Let’s see an example. We are in the CDB$ROOT and we count the lines in SOURCE$. We join with the DBA_OBJECT that shows which are the Oracle-maintained objects (the system objects):
![]()

All the lines in SOURCE$ are for Oracle-maintained objects which are system packages.
Now let’s have a look in a PDB:
![]()

The lines here are not for system packages, but for our own application packages. You may have a different result, but basically this is how the dictionaries are separated in multitenant: the metadata that was stored in the same dictionary in non-CDBs is now stored in identical tables but in different containers, to keep the Oracle metadata separated from the application metadata. Note that this is not the same as partitioning; it’s more like these are actually different databases for the dictionaries.
Dictionary Views
Do you know why we’ve queried the SOURCE$ table and not the DBA_SOURCE, which is supposed to give the same rows? Check this out:
![]()

Same number of lines here in the CDB$ROOT. But when we connect to the PDB,
![]()

We see more rows here. Actually, we see the rows from CDB$ROOT. There are two reasons for this. First, we said that what is in the CDB$ROOT is common, so it makes sense to see this from the PDB. Second, we said that a user connected to a PDB must see everything as if she were on a standalone database. And on a standalone database, a query on DBA_SOURCE shows all sources from both the system and the application. It’s not the case when you query SOURCE$, but you’re not expected to do that. Only the views are documented, and you’re expected to query those ones.
The dictionary views in a PDB show information from the PDB and from the CDB$ROOT. It’s not partitioning, and it’s not a database link. We will see how Oracle does this in the next section.
When you are connected to CDB$ROOT, the DBA_SOURCE view shows only what is in your container. But new views starting with CDB_ can show what is in all containers, as you will see later in the chapter in the section “Dictionary Views from Containers.”
So, physically, the dictionaries are separated. Each container stores metadata for its user objects, and the root stores the common ones—mainly the system metadata. Logically, from the views, we see everything, because this is what we have always seen in non-CDBs, and PDBs are compatible with that.
Metadata Links
Oracle has introduced a new way to link objects from one container to another: metadata link. Each container has all the dictionary objects (stored in OBJ$ and visible through DBA_OBJECTS), such as the system package names in the example used earlier. But more definitions (such as the packages source text) are not stored in all of the containers, but only in the CDB$ROOT. Each container has a flag in OBJ$, visible as the SHARING column of DBA_OBJECTS, that tells Oracle to switch to the CDB$ROOT container when it needs to get the metadata for it.
Here is some information about one of those packages, which includes the same definition in all containers, from DBA_OBJECTS in the CDB$ROOT:
![]()

And this is from the PDB:
![]()

You can see the same object names and types, defined as Oracle maintained and with METADATA LINK sharing. They have different object IDs. Only the name and an internal signature is used to link them. From this, we know that those objects are system objects (Oracle maintained), and when we query one of them from a PDB, the Oracle code knows that it has to switch to the root container to get some of its information. This is the behavior of metadata links. The dictionary objects that are big are stored in only one place, the CDB$ROOT, but they can be seen from everywhere via dictionary views.
This concerns metadata. Metadata for your application is on your PDB. Metadata for Oracle-maintained objects is stored on the CDB$ROOT. The latter is static information: it’s updated only by upgrades and patches. You can see that the benefit is not only a reduction in duplication, but also the acceleration of the upgrades of the PDBs, as there are only links.
Figure 1-3 shows the expanded simplified dictionary from Figure 1-2 to reveal the dictionary separation.

FIGURE 1-3. Separating system and user metadata
Data Links (called Object Links in 12.1)
There is not only metadata in the dictionary. The multitenant database also contains some data to store at the CDB level. Here’s a simple example. Suppose the CDB must keep a list of its containers, which is stored in the system table CONTAINER$, which is exposed through the dictionary view DBA_PDBS. This data is updated to store the status of the containers. However, this data, which makes sense only at the CDB level, can be queried from all PDBs. Let’s see how this is shared.
This is from the CDB$ROOT:
![]()

And this is from the PDB:
![]()

You can see that the view that accesses CONTAINER$ is a data link, which means that the session that queries the view will read from the CDB$ROOT. Actually, the CONTAINER$ table is present in all containers, but it is always empty except in root.
Working with Containers
How do you work with so many PDBs? You begin by identifying them.
Identifying Containers by Name and ID
A consolidated CDB contains multiple containers that are identified by a name and a number, the CON_ID. All the V$ views that show what you have in an instance have an additional column in 12c to display the CON_ID to which the object is related. The CDB itself is a container, identified by container CON_ID=0. Objects that are at CDB level and not related to any container are identified by CON_ID=0.
For example, here’s what we get if we query V$DATABASE from the root:
![]()

![]()

The information may be different when viewed from different containers, but in all cases, the database information is located at the CDB level only. Information in that view comes from the control file, and you will see that it is in the common ground. So the CON_ID is 0. If you are in non-CDB, CON_ID=0 for all objects. But if you are in multitenant architecture, most of the objects pertain to a container.
The first container that you have in any CDB is the root, named CDB$ROOT and with CON_ID=1. All the other containers are PDBs.
The first PDB that is present in every CDB is the seed, named PDB$SEED, which is the second container, with CON_ID=2.
Then CON_ID>2 are your PDBs. In 12.1, you can create 252 additional PDBs. In 12.2, you can create 4,098 of them.
List of Containers
The dictionary view DBA_PDBS lists all PDBs (all containers except root) with their status:
![]()

The status is NEW when you create it and is changed to NORMAL at first open read/write, because some operations must be completed at first open. UNUSABLE is displayed when the creation failed and the only operation we can do is DROP it. UNPLUGGED is a way to transport it to another CDB, and the only operation that can be done on the source CDB is to DROP it.
Instead of NEW you can see the following in 12.1 only: NEED UPGRADE indicates it came from a different version, and CONVERTING indicates it came from a non-CDB. You’ll learn about three others, the RELOCATING, REFRESHING and RELOCATED statuses, in Chapter 9.
That was the information from the database dictionary. We can list the containers known by the instance, which show the open status:
![]()

In non-CDB, the MOUNTED state occurs when the control file is read but the datafiles are not yet opened by the instance processes. It’s the same idea here: a closed PDB does not yet open the datafiles. There is no NOMOUNT state for PDBs because the control file is common.
Note that SQL*Plus and SQL Developer have a shortcut you can use to show your PDBs or all PDBs when you are in the root container:
![]()

Identify Containers by CON_UID and DBID
You have seen that in addition to its name, a container is identified by an ID, the CON_ID within the CDB. The CON_ID can change when you move the PDB. For that reason, you also have a unique identifier, the CON_UID, which is a number that identifies the PDB even after it has been moved. The CDB$ROOT that is a container but not a PDB, and does not move, has a CON_UID=1.
Because of the compatibility with databases, each container has also a DBID. CDB$ROOT is the DBID of the CDB. The DBID of PDBs is the CON_UID.
In addition, each container has a GUID, a 16-byte RAW value that is assigned at PDB creation time and never changes after that. It is used as a unique identifier of the PDB in the directory structure when using Oracle Managed Files (OMF).
All those identifiers are in V$CONTAINER, but you can also use the functions CON_NAME_TO_ID, CON_DBID_TO_ID, CON_UID_TO_ID, and CON_GUID_TO_ID to get the ID of a container. A null is returned if a container is not there. Here are some examples:
![]()

Connecting to Containers
We talked about multitenant as a way to overcome the schema-based consolidation limitation. So how do you switch between schemas, other than connecting directly as the schema user? You ALTER SESSION SET CURRENT_SCHEMA.
Of course, you can connect directly to a PDB, but we will explain that in Chapter 5 about services, because that is the right way to connect from users or application. But when, as a CDB administrator, you are already connected to the CDB, you can simply switch your session to a new container with ALTER SESSION SET CONTAINER.
Here, we are connected to CDB$ROOT:
![]()

We change our current container:
![]()

And we are now in the PDB:
![]()

Transactions If you have started a transaction in a container, you cannot open another transaction in another container.
![]()

You can leave the transaction and change the container:
![]()

But you can’t run DML that requires a transaction:
![]()

First you must return to the previous container and finish your transaction:
![]()

And then you can open a new transaction in another container:
![]()

Cursors If you open a cursor in one container, you cannot fetch from it in another container. You need to go back to the cursor’s container to fetch from it:
![]()

Basically, it’s easy to switch from one container to another, but what we do to them is isolated. Nothing is shared with the previous container state.
For example, connected to PDB1, we set serveroutput to on and use dbms_output:
![]()

The dbms_output line was displayed. You can see that the USERENV context shows the current container name. Now we switch to PDB2:
![]()

Nothing is displayed here. serveroutput was set for PDB1, and we have to set it for PDB2:
![]()

Now we go back to PDB1:
![]()

No need to set serveroutput again. When switching back, we regained the state.
From JDBC or OCI My examples were run on SQL*Plus, but any client can do this. As long as you are connected with a user that is defined in the root (a common user) and that has been granted the SET CONTAINER system privilege on a PDB, you can switch the session to the PDB. You can do it from Java Database Connectivity (JDBC) or from the Oracle Call Interface (OCI). For example, you can have a connection pool from an application server that will switch to the required container when connections are grabbed. This is a way to have a common application server for multiple database tenants.
NOTE
If you want to use some container features that are new in 12.2, such as switching to a different character set PDB, you need to have a 12.2 client or you’ll get a ORA-24964: ALTER SESSION SET CONTAINER error.
Set Container Trigger If, for any reason, you want to run something when a session changes to another container, such as setting specific optimizer parameters, you can create a BEFORE SET CONTAINER and AFTER SET CONTAINER.
Here is how it works:
![]() The
The BEFORE SET CONTAINER created in PDB1 will be raised when you are in PDB1 and you execute an ALTER SESSION SET CONTAINER. If the trigger reads the container name, it will be PDB1.
![]() The
The AFTER SET CONTAINER created in PDB2 will be raised when you have executed an ALTER SESSION SET CONTAINER=PDB2.
This means that if both PDB1 and PDB2 have before and after triggers, changing from PDB1 to PDB2 will raise a BEFORE SET CONTAINER in PDB1 and an AFTER SET CONTAINER in PDB2.
There are two ways to work in a PDB. You can connect to it through its services, which is described in Chapter 5, and then AFTER LOGON ON PLUGGABLE DATABASE can be used to run some code at the beginning of the session. Or you can SET CONTAINER, and then use the AFTER SET CONTAINER ON PLUGGABLE DATABASE. If you want to be sure to set some sessions settings for a user working on a PDB, you will probably define both. Note that the word PLUGGABLE is not mandatory because of the syntax compatibility with database behavior.
Dictionary Views from Containers
A PDB includes everything that you expect from a database, which means that the queries on the dictionary views have the same behavior. You have all the DBA_/ALL_/USER_ views to show metadata for the PDB objects, or those you have access to, or those that you own. The fact that system objects are stored elsewhere is transparent: you see system objects in DBA_OBJECTS, system tables in DBA_TABLES, and instance information in the V$ views, but only the rows that are of concern in your PDB.
When you are in CDB$ROOT, you have additional CDB_ views that are like a UNION ALL of all opened containers’ DBA_ views. It’s a way for a CDB database administrator to view all objects. For this CDB$ROOT user, the V$ views show information about all containers.
Finally, you may want to know if you are in non-CDB or in multitenant. The CDB column in V$DATABASE provides the answer:
![]()

What Is Consolidated at CDB Level
Sharing resources that can be common is the main goal of consolidation. Beyond the instance and the dictionary, many database structures are managed at the CDB level. We are not talking about datafiles here, because they are specific to each container, and the only commonality among them is that they must have the same character set (except when a container is transported from another CDB, but that’s a topic for Chapter 9). Several other files are common to all containers in a container database.
SPFILE
The database instance is common to all containers, and the SPFILE holds the instance parameters, storing these settings for the entire CDB. The SPFILE contains the configuration elements that cannot be stored within the database or the control file, because they must be available before the database is mounted.
Some parameters can be set at the PDB level (those with ISPDB_MODIFIABLE=TRUE in V$PARAMETER). These changes can also be persisted, but even if the syntax for such an operation is SCOPE=SPFILE, this is for syntax compatibility only, as PDB level parameters are actually stored in the CDB dictionary (PDB_SPFILE$). They are not stored in the PDB itself because the parameter must be accessed before opening the PDB. We will see later that when moving pluggable databases (unplug/plug), these parameters are extracted into an XML file that you ship with the PDB datafiles.
Control Files
The control file references all other structures in the database. For example, this is the only location in which the datafile names are actually stored, and in the dictionary it is the FILE_ID alone that is used to reference them. In multitenant, the control file resides at the CDB level and holds records for all pluggable database datafiles. You will see in Chapter 9 that information relating to pluggable databases that is stored in the control file will also be exported to an XML file when a pluggable database is moved by unplug/plug.
NOTE
When we refer to the “control file,” we are actually referring to the control files (plural), because you can, and must, multiplex them to protect your database. This fundamental best practice does not change, and, if anything, the importance of database availability is even higher in multitenant, because an outage will have impact on multiple tenants.
While on the subject of database files, there is a parameter that controls the maximum number of files opened by an instance, DB_FILES, which defaults to 200. Be aware that if you create hundreds of pluggable databases, you will very quickly reach this limit, and you will then be unable to create new tablespaces or new pluggable databases until you restart the instance. In multitenant, restarting the instance may mean an outage for a large number of applications, so you want to avoid this. So don’t forget to size DB_FILES properly when you expect your container to house several pluggable databases.
UNDO
In 12.1, the first release with multitenant architecture, the UNDO tablespace, is common and implemented at the CDB level. However, in 12.2, we now also have the choice to run the CDB in local UNDO mode. If LOCAL UNDO is ON, each pluggable database has its own UNDO tablespace and all sessions writing data into PDB data blocks will place UNDO record information in this local tablespace. Only the changes performed on CDB$ROOT will put the UNDO record in the root UNDO tablespace.
In short, it is better to run in local UNDO mode if possible. UNDO contains application data, and we don’t achieve pluggable database isolation if we then store this in common UNDO datafiles. One reason for this preference is that local UNDO is required for efficient flashback pluggable database and point-in-time-recovery. We will explain this in Chapter 8.
Temporary Tablespaces
Temporary tablespaces can be created at both the CDB and PDB levels. If a user is not assigned a temporary tablespace within the PDB in which the session is running, and the PDB does not have a default temporary tablespace, the session will use the CDB temporary tablespace—but this is not recommended. A quota (MAX_SHARED_TEMP_SIZE) can be set on pluggable database usage of the root temporary tablespace.
The CDB$ROOT temporary tablespace is normally used by sessions connected to the root container, or from a pluggable database, when a work area needs to be allocated for a recursive query on object linked views.
Once a temporary tablespace has been defined as the default, you can change it to another that you have created in that PDB, but you cannot reinstate the CDB temporary tablespace as a default after this point.
Redo Logs
The redo logs protect the instance, and because of this, they are also common. Their main objective is to record all changes made in the buffer cache and to ensure that those changes are persisted for committed transactions.
The redo stream in multitenant is similar to the stream in previous versions, except for additional information in each redo record to identify the container. Redo format is crucial for recovery operations, and, as such, Oracle changes this code very infrequently.
Having the redo thread cover all pluggable databases brings more multitenant benefits to the DBA managing the CDB. In non-CDB contexts, when you provision a new database, it takes a lot of effort and time to size the recovery area, establish the backups, and build and configure the Data Guard physical standby, when used. With multitenant, you do it only once, for your CDB, because this is where functionality related to availability runs from: your backups, your Data Guard, and your RAC configuration. Simply create a new pluggable database and it will benefit from the same already-configured availability: it is automatically backed-up with the CDB, automatically created on the physical standby (note that you need Active Data Guard for this), and automatically accessible from all RAC instances. Again, this is because the main structure used for availability, the redo stream, operates at the CDB level.
However, having only one redo stream may be a concern in terms of performance. If you have ever encountered log writer performance issues, such as long waits on “log file sync” events, then you can imagine what happens when the Log Writer (LGWR) has to write the redo from all pluggable databases. And the upshot is that if the LGWR cannot keep up with the redo rate, users will be forced to wait when committing.
So, for the purpose of LGWR scalability, Oracle introduced multiple LGWRs in 12c. LGWR is the coordinator process, and multiple slaves (LG00, LG01, and so on) are associated with this, so that the instance redo stream is written in parallel. Of course, RAC is still another means of implementing parallel threads of redo. What you must keep in mind is that tuning the LGWR and the amount of redo written is of crucial importance in multitenant. When you consolidate, pay special attention to the performance of the disks on which you put the redo logs.
Datafiles
The datafiles, which store the tablespace data blocks, belong to each container, but they are also managed by the CDB. They have a unique identifier for the CDB, which is the FILE_ID:
![]()

The concept of a relative file number was introduced along with transportable tablespaces, so this aspect of the architecture of Oracle was ready long before 12c. In multitenant, within a pluggable database, the datafiles are identified by the tablespace number and the file number relative to the tablespace (RELATIVE_FNO). Furthermore, these do not have to be changed when you move, clone, or plug in the pluggable database, and it is only the absolute file number (FILE_ID) that will be renumbered to ensure that it is unique within the CDB—but that is a very quick change in the control file and datafile headers.
Data and Metadata at CDB Level
We have explained that the dictionary related to system objects, stored in the CDB$ROOT SYSTEM and SYSAUX tablespaces, is common and can be accessed by the PDBs. Beyond the basic database objects (created by catalog.sql and catproc.sql) more common information can be stored in the root.
APEX
By default, if you install APEX (in 12.2, you can choose the components), it is placed at the CDB level. The idea is that APEX, like the system dictionary, houses metadata that does not need to be installed in PDB$SEED or in all pluggable databases created. However, there is a big drawback in this approach: you have only one APEX version in your CDB and you will have problems if you want to plug a non-CDB running APEX 5.0, for example, into Oracle Cloud Services, where the CDB is installed with APEX 4.2.
NOTE
This issue has been detailed by Mike Dietrich on his blog, blogs.oracle.com/UPGRADE/entry/apex_in_pdb_does_not. The APEX 5.0 documentation states, “Oracle recommends removing Oracle Application Express from the root container database for the majority of use cases, except for hosting companies or installations where all pluggable databases (PDBs) utilize Oracle Application Express and they all need to run the exact same release and patch set of Oracle Application Express.”
Automatic Workload Repository
Automatic Workload Repository (AWR) collects a large amount of instance information (statistics, wait events, and so on) from the instance views, and in multitenant, this is done at the CDB level. Only one job collects all statistics for all containers, and they are stored in the CDB$ROOT. This is actually the main use case for object-link views: AWR views (those that start with DBA_HIST) can be queried from each pluggable database but actually read data that is stored in root.
There are two important consequences relating to this. The first is that if you move a pluggable database, the AWR history does not follow along with the container; instead, it remains in the original CDB. You can read the views from the original database, or export it elsewhere. But the CON_ID that is stored in AWR should be the container ID at the time the snapshot was taken, so you need to check the CON_DBID to identify a specific pluggable database. There are actually three different identifiers in each of the DBA_HIST views:
![]() DBID is the DBID of the CDB, same as in a non-CDB environment. This uniquely identifies the snapshot, along with the SNAP_ID and INSTANCE_NUMBER.
DBID is the DBID of the CDB, same as in a non-CDB environment. This uniquely identifies the snapshot, along with the SNAP_ID and INSTANCE_NUMBER.
![]() CON_ID is the container ID that comes from the
CON_ID is the container ID that comes from the V$ views queried to take the snapshot. Some rows are not related to any container, and so have CON_ID=0, while others record statistics for a container object and so take the related CON_ID at the time of the snapshot.
![]() CON_DBID uniquely identifies a pluggable database, in the same way that
CON_DBID uniquely identifies a pluggable database, in the same way that DBID uniquely identifies a database.
The second consequence of having AWR collected at the CDB level is that, when you run an AWR report at PDB level, it will filter only the statistics relevant to your container, and this is exactly the same as querying V$ views from a PDB. But you must keep in mind that you still see some statistics that are at CDB level (those that have CON_ID=0) in the same report. This means that, for example, you will see the amount of logical reads done by the instance in the instance statistics section, but the details (in SQL sections or Segment section) reveal only what is relevant to your pluggable database. Let’s take a look at an example.
Before reading an AWR report details, we always check that most of the SQL statements are captured, because there is no point in continuing if we cannot go down to the statement-level detail. Here is the SQL ordered by Gets header from an AWR report:
![]()

This shows that 89 percent of the SQL statements were captured, and we know that we will have the detail we need when we investigate the high logical reads issue. When the percentage is low, that usually means that we are analyzing a report that covers a time window that is too large, and most of the SQL statements have been aged out of the shared pool before the end snapshot. But you can see another reason for low percentages when you run the AWR report from a pluggable database:
![]()

You don’t see anything different here, except that only 21 percent of the statements have been captured. You have to check the AWR report header to see that it covers only one PDB. Actually we had two PDBs active at that time, and here is the other one:
![]()
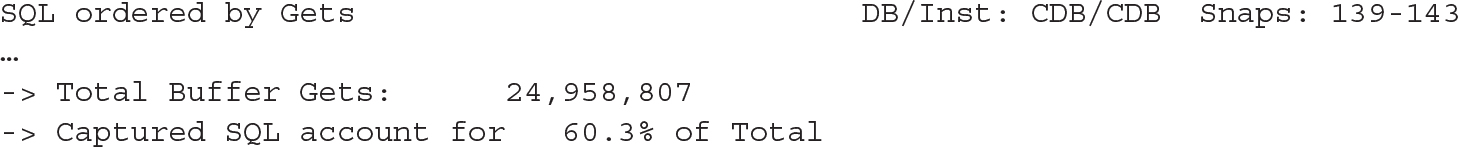
From one PDB, you have no way to see if all statements for that PDB have been captured. There are no statistics such as total logical reads for that pluggable database.
NOTE
This is the behavior in 12.1, where per-PDB instance statistics are available in V$CON_SYSSTAT but not collected by AWR. In 12.2, they are collected in DBA_HIST_CON_SYSSTAT, and you have similar views from time model (DBA_HIST_CON_SYS_TIME_MODEL) and system events (DBA_HIST_CON_SYSTEM_EVENT). In 12.2 the AWR report uses them and the inconsistency above does not appear.
Statspack If you don’t have the Diagnostic Pack, you can’t use AWR and you will probably install Statspack. According to the documentation (spdoc.txt), Statspack can be installed only at the PDB level. We think that it makes sense to install it at the CDB level as well, because you may want to analyze CDB$ROOT activity. Each PDB from which you want to collect snapshots will store its own statistics. Because statistics are now collected at PDB level, the behavior is different from the behavior with AWR. We’ve taken Statspack snapshots at the same time as the AWR snapshots in the preceding example. The session logical reads from spreport.sql show 24,956,570 logical reads when the report is run on CDB$ROOT, and 5,709,168 (22 percent) for one PDB and 17,138,586 (68 percent) for the other. Statspack collects statistics related with the CDB when run from root and with the container when run from a PDB.
Summary
In this long introduction, we have explained why multitenant was introduced by Oracle 12c in 2013. We have seen the different consolidation alternatives, and perhaps you think that you don’t need to run in multitenant. However, this new architecture will eventually become the only one supported, the non-CDB being already deprecated. So even if you don’t want multiple pluggable databases per instance now, you will have to run what we will call “single-tenant” in Chapter 3, and you will have to administer container databases.
In addition to consolidation, the new architecture separates the application data and metadata from the system dictionary, bringing more agility for data movement and location transparency. This will be covered in Chapter 9.
The next chapter will start from the beginning by creating a consolidated database.
