

CHAPTER
8
Flashback and Point-in-time Recovery
In previous chapters you have learned that most of the backup and recovery tasks are performed at the container database (CDB) level, and this is perfect in terms of protecting all your pluggable databases (PDBs) from media failure. Simply create a new PDB in the CDB, and the PDB will be automatically protected in the same way.
However, a PDB administrator may have different requirements. Rarely in production, but frequently in test environments, we may need to do point-in-time recovery (PITR), so we appreciate a smart alternative: Flashback Database. Release 12.1 brought us multitenant, and although Flashback Database was not available in this release, in 12.2 this has changed thanks to the introduction of the local UNDO mode.
Pluggable Database Point-in-Time
Recall that we said that the ancestor of PDBs was the transportable tablespace. Here (whether you are using PDBs or not), we’ll take a look at how you restore a tablespace to a previous state.
A tablespace has its own datafiles, so the first step is easy: Restore the datafiles from the previous backup. Then you have to apply REDO to bring the files forward, up to the desired point-in-time you are working to; but that’s not enough. Datafiles by themselves are just a bunch of bits without the metadata that details what is stored within. This information is contained in the dictionary, so this is why you cannot do a tablespace point-in-time recovery (TSPITR) in place. Instead, you must also recover the SYSTEM and SYSAUX tablespaces to the same point-in-time, which has to be done into an auxiliary database.
With PDBs, you don’t expect to encounter the same problem, because they have their own SYSTEM and SYSAUX tablespaces that can be recovered to the same point-in-time. This means that you can bring your PDB to a specific point-in-time. But that’s not enough, because you still can’t open it in this state. As a refresher, look back at the section “Accessing Database Files at the CDB Level” in Chapter 1 and you will see what is missing.
When you recover a database, the final step is to roll back all the ongoing transactions that did not complete at that point-in-time. This is the “A” from the ACID property: atomicity of transactions. The principle holds that you need to apply the UNDO for the transactions that were there at that time, which is why you require a PITR of the UNDO tablespace as well.
In Figure 8-1, you can see the restore, roll-forward, and rollback phases of recovery illustrated. All files are brought up to the required point-in-time state by applying REDO to them. Uncommitted transactions are cleaned out by applying UNDO to roll them back.

FIGURE 8-1. The roll-forward and rollback phases of recovery over the transaction timeline
Let’s see how it works in 12.1 Multitenant. With PDBs, you don’t need to restore everything into an auxiliary instance as you do for tablespace PITR. It is now possible to restore the complete PDB tablespaces in place because they contain their system tablespaces. However, you still need to restore UNDO, and for this you need an auxiliary instance. You cannot overwrite the common UNDO which is also used by the current transactions running on the other containers.
Recover PDB Until Time
Here is an example of the Recovery Manager (RMAN) commands you can run to restore and recover a PDB, specifying the point-in-time with a system change number, as of SCN 1610254, and using /var/tmp for the auxiliary instance:

In the RMAN output you can see the operations that it is performing. RMAN is verbose here, so we only show those sections of output that help you understand how it works.
First, all the PDB datafiles, those of SYSTEM, SYSAUX, and USERS tablespaces, are restored in place:

Then recovery must start, and RMAN needs to determine the tablespaces that may contain UNDO:

Notice the warning, which we will explain later. Here RMAN is making a reasonable guess that those tablespaces that contain UNDO currently are the same as those that contained UNDO at the point-in-time you want to recover to, and RMAN lists them out.
Those tablespaces that contain UNDO cannot be restored in place, because they would override the CDB tablespaces that are used by the other containers, so for this purpose we need an auxiliary instance:

As you can see, RMAN takes responsibility for creating an instance, using Oracle Managed Files (OMF) file naming with destination set to /var/tmp, which we defined earlier as an auxiliary destination. So let’s review the parameters that are used. It is possible to define additional options, but the following are mandatory:
![]()
db_name and compatible must be the same.
![]()
SID and db_unique_name must be unique.
![]()
_clone_one_pdb_recovery specifies that only CDB$ROOT and one PDB will be recovered.
![]()
_system_trig_enabled disables the system triggers to be sure that the auxiliary instance does not have any unintended impact outside of itself.
Then this instance must use the files from the PDB that have been restored in place:
![]()

And the CDB datafiles for SYSTEM, SYSAUX, and UNDO will be restored to the OMF destination:
![]()

At this point, we have an auxiliary instance with access to all the necessary CDB$ROOT and PDB files, which have been restored to the specific point-in-time of interest. Next, it’s time to recover them:
![]()

The rollback phase of the recovery, which rolls back the transactions that were opened at the system change number (SCN) 1610254, reads the temporarily restored UNDO, but it actually updates the datafiles that were restored in place. At the end, the auxiliary instance and temporarily restored datafiles are automatically removed.
Where Is the UNDO?
In the previous example, the following warning was generated:
![]()

RMAN needs to restore all tablespaces that may contain UNDO segments or the recovery will fail, so it lists the current tablespaces which contain UNDO. But we need the UNDO from the point-in-time we want to recover. And this may differ if we have changed the UNDO tablespace in the meantime.
In the following example, we alter the UNDO tablespace to UNDO2, dropping UNDO1, which existed as the prior default. The “recover PDB to a point-in-time” process then presents the following warning:
![]()

And finally it fails, because that tablespace did not exist at the point-in-time we want to recover to:
![]()

Datafile 17 was from the UNDO2 tablespace, but we can’t restore it, and we don’t need it in any case; but we do need the datafile from UNDO1.
Here the syntax of the RECOVER command is useful because it allows us to specify the specific tablespaces to restore when we know which one holds UNDO:
![]()

We have seen cases in which RMAN does not know how to restore these datafiles, but it’s probably not a good idea to rely solely on the fact that you know the name of the tablespace that was present at a previous point-in-time either.
But no need to worry, because the solution is to have the PDBPITR operation automatically restore the correct UNDO tablespace using an RMAN catalog. Then there will be no warnings or errors, and RMAN will restore the correct UNDO tablespace itself.
Summary of 12.1 PDBPITR
From what we have discussed so far, two recommendations follow: First, to be fully automated, even in those instances when the UNDO tablespace has changed, you need an RMAN catalog. If you anticipate running PITR, you should have an RMAN catalog to facilitate a large retention period. In fact, there are no irrefutable reasons not to use an RMAN catalog! Remember that you can put this anywhere, even on a virtual machine, because you don’t have to license it separately. Second, even if the auxiliary instance is supposed to be removed automatically by RMAN, if a failure occurs, you may have to clean it up manually. You can find its ORACLE_SID in the RMAN log and use this to connect and shutdown abort if needed.
Figure 8-2 shows the CDB that is at the current SCN, where PDB2 has been restored to a point-in-time SCN, and an auxiliary instance is able to undo the uncommitted transactions because it has restored the CDB level UNDO at that SCN.
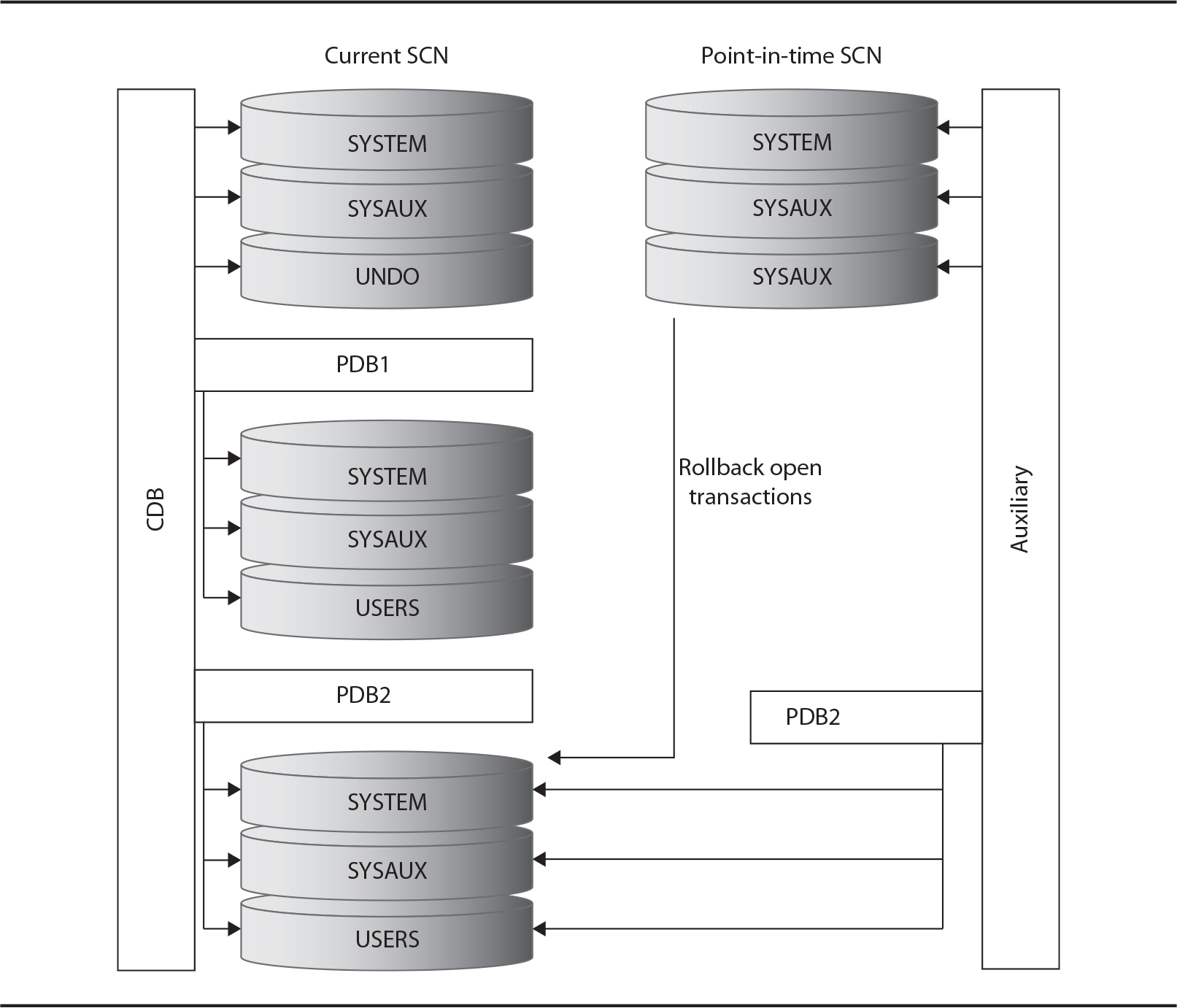
FIGURE 8-2. Point-in-time recovery using auxiliary instance
The creation and cleaning of the auxiliary instance is automated by RMAN, but this still takes time. You need to restore and recover all tablespaces that may contain UNDO, even though you may need only a few UNDO records—specifically those that cover the open transactions for your PDB. Perhaps there is a better way, so let’s imagine that UNDO was stored at the PDB level.
Local UNDO in 12.2
In 12.1 the UNDO tablespace is common, meaning that it is shared among the entire CDB, to store information about all transactions. Furthermore, only the CDB administrator can create the UNDO tablespace. So in working with a PDB, the statement to create the UNDO tablespace is simply ignored.
The problem with shared UNDO is that it stores data from all other containers. As mentioned, UNDO contains information relating to transactions, which is necessary to clean up any uncommitted transactions as required. This means that PDBs on a shared UNDO CDB are essentially not self-contained, except for a closed PDB that has been shut down cleanly.
This is why it was impossible to flashback a PDB in 12.1. And in older versions, the only way to affect a PITR of part of the database was to use TSPITR, which could not be done in place. It was, in fact, necessary to restore the SYSTEM, SYSAUX, and UNDO tablespaces, in addition to the tablespace that you specifically wanted to restore, because the metadata from the system tablespace is required, along with UNDO record information, to roll back the transactions.
When 12c was introduced, each PDB had its own system tablespaces but UNDO was shared, which again meant that PDBs were not isolated enough for particular types of operations, such as those that shift tablespaces to another time or location.
However, beginning with 12.2, you can define the UNDO mode to local, which means that each PDB stores its own UNDO records in a local UNDO tablespace pertaining solely to that PDB. This enables many operations on an open PDB that were previously impossible, such as relocating, plugging, and flashback of a PDB. Furthermore, it improves the PITR of PDBs because the need for an auxiliary instance has been removed.
In 12.2, you can still use the shared UNDO mode if you prefer, as in 12.1, but certain operations will not be available or will require the PDB to be cleanly closed so that there are no active transactions, and no need for any UNDO records.
In short, having the UNDO local to the tablespace improves the efficiency of unplugging and PITR of PDBs, and it is mandatory for online relocate or clone. (Note: in shared mode these operations require the source to be open read-only to ensure that there are no ongoing, open transactions.) Local UNDO is also mandatory for the referenced PDB when creating a proxy database.
Database Properties
If you have a CDB already created, you can check the UNDO mode from the database properties:
![]()

The LOCAL_UNDO_ENABLED property is set to TRUE when you are in local UNDO mode, and it is set to FALSE in shared UNDO mode. Be careful if you don’t see anything, because this means that the database was created with shared UNDO, either when UNDO mode was not specified in the CREATE DATABASE statement or if it was upgraded from 12.1
Create Database
You choose the local UNDO mode when you create the database. You can check the option on the Database Configuration Assistant (DBCA), or add LOCAL UNDO ON to the ENABLE PLUGGABLE DATABASE clause of the CREATE DATABASE statement.
When you create the database in local UNDO mode, in addition to the UNDO tablespace of the CDB$ROOT container, you have an UNDO tablespace in PDB$SEED and in any PDB that you create. Here is an example, noting again that in the report schema the tablespace names are prefixed with the PDB name:
![]()

Changing UNDO Tablespace
The default UNDO tablespace that is created with a PDB may not suit your needs. It is generated based on PDB$SEED, or from the CDB$ROOT if PDB$SEED has no UNDO tablespace. If you want to change the UNDO tablespace, you can drop it and re-create as you want. Let’s look at an example:
![]()

We have the UNDOTBS1 UNDO tablespace that has been created with our PDB. As we are in local UNDO mode, we can’t drop it:
![]()

This tablespace is the one defined for our PDB:
![]()

So, first, we have to create a new UNDO tablespace, then switch to it, and then drop the old one when there are no transactions in it. As an example, we want to define an UNDO tablespace as a bigfile tablespace, with guaranteed retention.
![]()

Once the UNDO tablespace is created, we can then switch to it:
![]()

And then we can drop the old one:
![]()

Of course, you may want to wait for the UNDO retention time to elapse before dropping the old tablespace; otherwise, you may risk having some queries fail with the infamous ORA-1555 error.
Changing UNDO Mode
If you have created the database in shared UNDO mode, you can change it later, but this requires downtime on the CDB because you need to be in upgrade mode to do so.
In the following example, we have no rows in our database properties relating to UNDO mode, which means that LOCAL_UNDO_ENABLED is set to off.
![]()

If you try to change this property you get the following error:
![]()

However, once you have a maintenance window, you can work this through with the following commands:
![]()

And we now see this change reflected in the UNDO mode property setting:
![]()

At that point, the local UNDO tablespaces will be created when you open the PDBs.
If you want to create the UNDO tablespace yourself, you have to open the PDB, then create your UNDO tablespace, and then drop the UNDO tablespace that was created at open.
If you want to come back to shared UNDO mode, the opposite operation can be done: start upgrade, ALTER DATABASE LOCAL UNDO OFF, and then drop the UNDO tablespaces in PDBs because they are no longer used.
PDB$SEED
If you changed to local UNDO and you want to have the same behavior as though the database was created in local UNDO from the get-go, you have to create an UNDO tablespace in the PDB$SEED. Then new PDBs created from SEED will have it as a template.
For that, you need to open the SEED read/write:
![]()


NOTE
No error results when you open the PDB$SEED read/write because customization of PDB$SEED is allowed when you are in local UNDO for the goal of UNDO tablespace creation. If you try to open the seed in read/write mode when you are in shared UNDO, you get an error (ORA-65017: seed pluggable database may not be dropped or altered). Only sessions with "_oracle_script"=true can open the PDB$SEED when in shared UNDO mode.
When using OMF, the UNDO tablespace of PDB$SEED is automatically created, based on the CDB$ROOT tablespace attributes.
Shared or Local UNDO?
We see no reason to use shared UNDO mode in 12.2, and our recommendation is to set LOCAL UNDO ON. You want multitenant for PDB isolation and easy operations, so you probably want local UNDO.
Note that even in local UNDO, some UNDO records can be generated in the CDB$ROOT if they are done by internal transactions that switched temporarily to CDB$ROOT.
PDB Point-in-Time Recovery in 12.2
We have explained the complex operations that have to be done when recovering a PDB at a different time than the CDB. The reason was to get the UNDO records necessary to clean the transactions that were not completed at the point-in-time we restore to. Now let’s see what is different in 12.2.
PDBPITR in Shared UNDO Mode
If you are in shared UNDO mode, the LOCAL UNDO OFF state, you are in exactly the same situation you were in with 12.1. The UNDO for all transactions is stored in the CDB$ROOT tablespace and shared by all PDBs. As a consequence, we cannot recover it to another point-in-time there; we need an auxiliary instance for this, along with a place for it.
When a fast recovery area (FRA) is defined, you can run RECOVER PLUGGABLE DATABASE without the AUXILIARY DESTINATION and the auxiliary instance will be created in the FRA. While it runs, you can see those files listed as AUXILIARY DATAFILE COPY in V$RECOVERY_AREA_USAGE:
![]()

If no FRA is defined and you try the same operation, you will get the following error:
![]()

Without an FRA, you need to specify a location as per the following:
![]()

So you have a choice: put it in FRA or choose a destination.
PDBPITR in Local UNDO Mode
With the introduction of local UNDO mode in 12.2, you have all required UNDO in the local UNDO tablespace that is restored in place, so there is no need for an auxiliary instance, and the PDB PITR is simpler and faster.
You run the same command, RECOVER PLUGGABLE DATABASE, without specifying an auxiliary location since the auxiliary instance is no longer needed. The best practice is to put the restore and recover commands in a RUN block with a SET UNTIL:
![]()

The point-in-time can be specified with a restore point as above, a timestamp, an SCN, or a log sequence and thread number. This is no different from the database PITR you know from versions prior to multitenant. A restore point here is used only to associate a convenient name to an SCN and can be created at CDB or PDB level, but we will discuss that later when we describe other functionalities of restore points.
Flashback PDB
When you want to revert a database to a recent point-in-time, you can use a smart alternative that does not require restoring any datafiles. Flashback PDB was one of the most important features missing in 12.1, but it is now possible in 12.2, enabled by the addition of local UNDO. Be aware that flashback requires additional logging. Conventional recovery starts from a previous state of the datafiles and uses the REDO stream to roll them forward. In contrast, Flashback Database begins from the current state of the datafiles and applies flashback logs to bring them back to a previous state.
Flashback Logging
By default, a database does not generate the flashback logs, which means that you cannot run Flashback Database operations. There are two ways to generate a flashback log: set FLASHBACK ON and guaranteed restore point.
FLASHBACK ON
You can set FLASHBACK ON even when the database is opened. It is performed at the CDB level:
![]()

From this time on, the database will store flashback logs in the FRA:
![]()

Flashback logging has a very small overhead by itself, but there are some side effects on sessions that format new blocks, such as direct-path inserts or any UNDO generation. Usually there is no need to read those blocks before writing them, because they are new. However, with FLASHBACK ON, these sessions have to read the blocks in order to write the previous image to the flashback logs. So with FLASHBACK ON, you may see more reads from disks (physical reads for flashback new) in session statistics.
You don’t want to keep the flashback logs forever, because Flashback Database is best used to go to a recent point-in-time only. Going weeks or months prior is more efficient with PITR. So when you set the database in FLASHBACK ON mode you also define a flashback log retention period:
![]()

This value is in minutes and the default is 1440, which translates to 24 hours. Note that this is a target only, so in the case of space pressure, the database will give priority to generating the ARCHIVELOG rather than guaranteeing the flashback retention.
Even if the flashback logs contain all the information to bring datafiles back to a past image, it still requires REDO to bring them to a consistent point-in-time, so enabling FLASHBACK ON can be done only on an ARCHIVELOG mode database.
Guaranteed Restore Point
With FLASHBACK ON, you can flashback to any point-in-time in the past that fits within the retention period. That point-in-time is defined by timestamp, an SCN, or a restore point. Even when you are not in flashback mode, you can enable the possibility to flashback to a restore point when you declare that restore point with guarantee flashback database:
![]()

Besides the V$RESTORE_POINT view, the easiest way to list these restore points is from RMAN:
![]()

A guaranteed restore point ensures that you can flashback to that specific point. The flashback logs and archived logs required for that point are kept in the FRA, but only a minimal set specifically for that point-in-time alone.
For example, here we’ve deleted all backups and will try to delete all archived logs:
![]()

And you can see that the ARCHIVELOG sequence that covers a guaranteed restore point is protected, because it is needed to make the datafiles consistent in case of flashback to that point. We also keep the flashback logs that contain the image of all blocks that have changed since that restore point:
![]()

This means that you don’t want to keep old guaranteed restore points for too long, because you can’t get rid of the flashback log generated since your oldest restore point.
If you want to keep a snapshot of the database for a long time and go back to it frequently, our recommendation is to drop and re-create the snapshot once you have flashed back to it. It’s logically the same snapshot, and earlier flashback logs can be reclaimed.
In multitenant, flashback logging is done at the CDB level, but starting from 12.2 you can flashback individual PDBs as an alternative to PITR.
Flashback with Local UNDO
When your CDB runs with LOCAL UNDO ON, you can flashback a PDB alone without any side effects on the other PDBs, in the same way that you can do a PITR in place. Of course, this is possible if you have FLASHBACK ON and the point-in-time is within the flashback log retention target, but it is also possible with FLASHBACK OFF if you have a guaranteed restore point. This is achievable because
![]() flashback logs have all previous images of blocks that have changed
flashback logs have all previous images of blocks that have changed
![]() UNDO tablespace is flashed back to the same point-in-time and then can be used to clean the transactions that were ongoing at that point-in-time
UNDO tablespace is flashed back to the same point-in-time and then can be used to clean the transactions that were ongoing at that point-in-time
Flashback in Shared UNDO
When your CDB runs with LOCAL UNDO OFF, the UNDO cannot be flashed back in the UNDO tablespace because it’s shared at CDB level. You are in exactly the same place as with PITR and the solution is the same: an auxiliary instance. You can add the AUXILIARY DESTINATION to the FLASHBACK PLUGGABLE DATABASE clause, or it will be created, implicitly, in the FRA.
Restore Points at the CDB and PDB Levels
You can create restore points at the CDB level, and then use them to flashback PDBs. In addition, it is also possible to create a restore point at the PDB level.
Here is an example in which we create a restore point at the CDB level:
![]()

And here’s one at the PDB level, with guaranteed Flashback Database:
![]()

While still in the same PDB, PDB1, we can see and use both these restore points:
![]()

But when we use the same query from another PDB, we can’t see the restore points defined under PDB1. We can see only the restore points defined under the root container:
![]()

NOTE
In multitenant, CON_ID=0 displays information that is at the CDB level and not related to any specific container, neither CDB$ROOT nor any PDB.
We can also create restore points with the same name in different containers. In the following we are still in PDB2 (CON_ID=5):
![]()

Those restore points have the same name. However, the CON_ID and PDB_RESTORE_POINT columns let you know which one is at the PDB level.
Here is the result when running the same query from CDB$ROOT:
![]()

For those of you who would like to see this information listed in RMAN, unfortunately, at the time of writing, this functionality is missing, but we have filed an enhancement request for it:
![]()

Another piece of information lacking in RMAN is the CLEAN_PDB_RESTORE_POINT. It is another addition in 12.2, and we will get to this shortly.
PDB Level and Flashback Logging
Related to this topic, you should be aware of an important point. Using our example, with FLASHBACK OFF and a guaranteed restore point only at the PDB level for PDB1 (CON_ID=4), it seems that flashback logging is actually enabled for all CDB datafiles.
From the CDB$ROOT, we check the flashback mode:
![]()

As expected, this is what we have when flashback logging is off, but we have a guaranteed restore point.
So let’s connect to PDB2 and check that we see no guaranteed restore points from there:
![]()

Then insert 1000 rows into an existing table:
![]()

Now we check the session’s statistics related to flashback:
![]()

This output reveals that these blocks have to be written into the flashback logs—proof that flashback logging occurs for changes in all containers, as long as one container has a guaranteed restore point.
In the current version, 12.2, you can enable flashback logging only at the CDB level, but the error message when trying it at the PDB level gives the impression that flashback logging will be a possibility at the PDB level in the future:
![]()

Clean Restore Point
We have seen that in a shared undo CDB, the flashback PDB needs an auxiliary instance to restore the undo tablespace to clean ongoing transactions. This makes the flashback less efficient, in both time and required space. The preferable solution is to run in local UNDO mode.
However, even when in shared UNDO mode, you don’t need to restore the UNDO when you know that you have no ongoing transactions at all. If you want to create a restore point in production before applying a patch or an application release, or in a test before a run of regression tests, you can close the database. And when it’s closed cleanly, there are no outgoing transactions. In this scenario, we can create a clean restore point that can be used to flashback efficiently, even in shared UNDO mode.
The following example affects a database with shared UNDO, created without a LOCAL UNDO clause:
![]()

As you have seen before, no property for LOCAL_UNDO_ENABLED means that it is false. We connect to PDB1, which is currently opened, and try to create a clean restore point:
![]()

But to be sure it’s a clean restore point, we need to close the PDB:
![]()

Note that we have created a guaranteed restore point here because we do not have FLASHBACK ON, and we want to be able to flashback to it.
At this point, we can open back the PDB. Any blocks written to the datafiles will have their previous image written to flashback logs, so you can quickly flashback to the initial state, without the need of an auxiliary instance thanks to the clean restore point:
![]()

The concept of a clean restore point applies to shared UNDO mode only. It makes no sense in local UNDO mode, and if you try to use the same syntax, you will get the following error:
![]()

Resetlogs
This chapter is all about bringing a PDB to a point-in-time in the past. When you do that on a CDB or a non-CDB, you have to OPEN RESETLOGS. This operation resets the REDO stream because it is interrupted: the REDO that was generated before the recovery or the flashback cannot be used on that new incarnation of the database. When you open a non-CDB or a CDB with resetlogs, the online redo logs are re-created and the old ones are discarded.
The REDO stream is at the CDB level, so the “resetlogs” term may be misleading when dealing with a PDB. The redo logs are not re-created, and in this case, they just continue to log all changes for all modifications that occur in the instance. But it’s the same idea: mark the REDO stream so that the REDO from that point on is known to protect a new incarnation of the PDB.
In the following example, we flashback PDB1 and try to open it without the resetlogs clause:
![]()

The message is not explicit here, because we have two possibilities with the current state of the datafiles: we can choose to revert our flashback and apply recovery to bring it up to the latest state, or we can open it in that state, because this is what we wanted to do with the flashback operation:
![]()

Each PDB’s open resetlogs operation creates a new incarnation of the PDB, which is a subset of the CDB incarnation. You can list the history of all incarnations by querying the V$PDB_INCARNATION view. Here is an example, where we have flashed back the PDB to the same restore point several times:
![]()
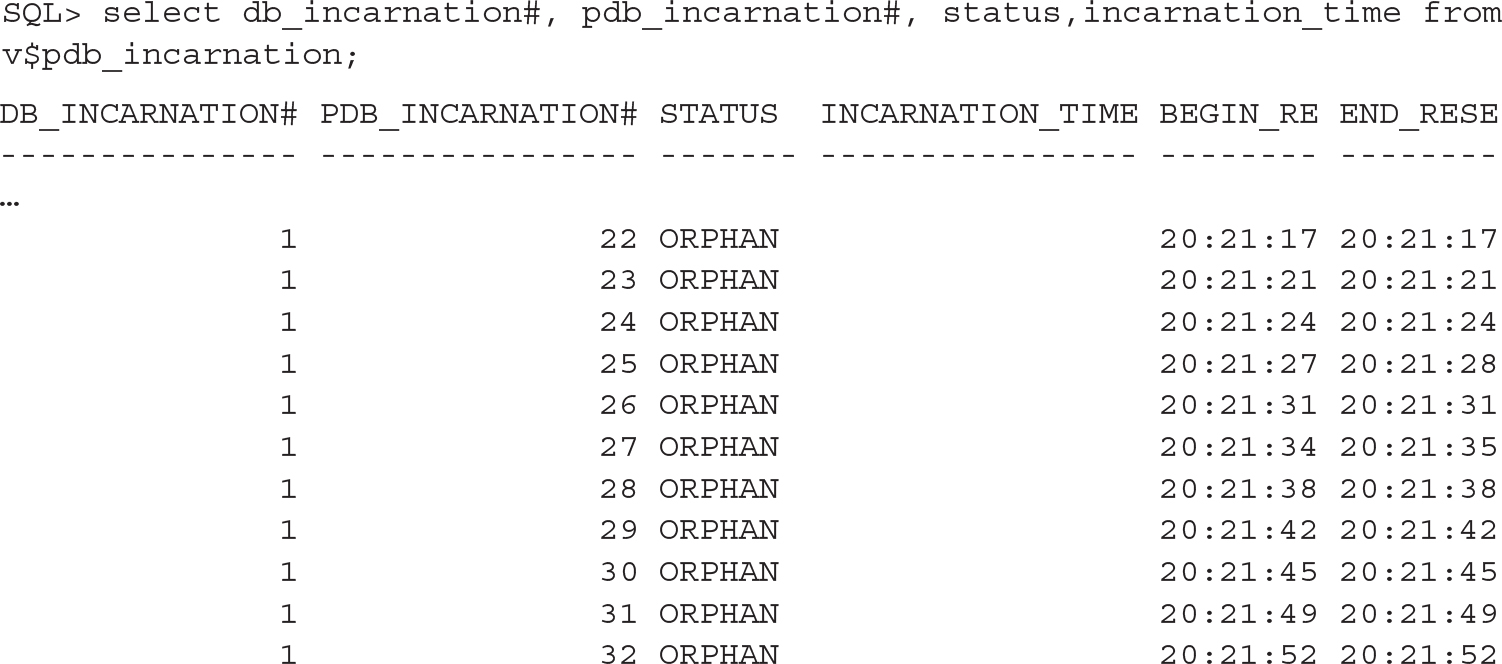
This is a massive advantage of the multitenant architecture: you don’t need to restart the instance when you flashback a PDB. This makes the flashback operation very fast—in fact, just a few seconds. It can be used for test databases where, for example, a number of tests must run on the same data. This is much faster than reimporting from a dump file, and it’s even faster than reattaching a transportable tablespace.
Flashback and PITR
This chapter covers two ways to bring a PDB back to a previous state. They have some common effects, but are used for different situations.
When Do You Need PITR or Flashback?
Taking a production database back to a point in the past is rare, because you will lose all transactions that have happened since that point. If you encounter a logical or physical corruption, Flashback Database is considered only on those occasions where the corruption is database-wide and occurred in the last few seconds. But in other cases, you can benefit a lot from restore points and flashback. For example, before any maintenance operation, such as an application release or database upgrade, you can take a guaranteed restore point, and if anything goes wrong, your fallback scenario takes only few minutes to enact. And because you flashback before reopening the service, you don’t lose any transactions. Just don’t forget to drop the restore point when maintenance is completed and validated.
The benefit of flashback shows up every day in test environments, especially in continuous integration environments. If you have several runs of tests that need the same data set, without flashback, rerunning all DDL and DML simply takes too long, and a dump import is also probably not quick enough. A solution is potentially found in the transportable tablespace functionality, but even that takes too long to import all metadata. Flashback is the best solution to revert back to a previous state, but before multitenant this required an instance restart. In multitenant, the flashback PDB takes only a few seconds, so it can be run hundreds of times during a batch of nonregression tests.
TIP
A PDB administrator can flashback a PDB as long as the admin has the SYSDBA privilege granted on that PDB. There’s no need for a common user for that. So it’s possible to give that right to a trusted application DBA so that he or she can interact with this PDB only.
Impact on the Standby Database
We will detail the Data Guard configuration in multitenant in Chapter 11, but you already know that the REDO is at CDB level, and that what you do in a primary database, especially when changing the structure or in case of OPEN RESETLOGS, can have consequences on the physical standby.
Changing UNDO Mode
When changing from shared UNDO to local UNDO, you have to startup upgrade. If you are using real-time query (Active Data Guard), you need to stop it while the primary is in startup upgrade: the REDO from upgrade mode cannot be applied when a physical standby is open read-only. The second point is that new UNDO tablespaces will be created, so be sure that StandbyFileManagement = ’AUTO’.
Flashback or PITR on Primary
After a PDBPITR or a flashback PDB, you have to open the PDB with RESETLOGS. The managed recovery process (MRP) on the physical standby stops when it encounters the RESETLOGS marker because the datafiles are at the same state as the primary before the flashback, and current REDO cannot be applied on the previous incarnation. Here is what you can see in the alert.log:
![]()

The message is clear: You must do a PITR on the physical standby as well, to the same point-in-time. If the physical standby is in FLASHBACK ON mode, it’s easy. Stop APPLY, flashback to the SCN given in the alert.log, and restart APPLY:
![]()

An alternative if you are not in flashback mode is to recover from service, which is a 12c feature:
![]()

Disable Recovery on Standby
In multitenant, you don’t want the standby to stop the APPLY, because one PDB has been flashed back. So instead of waiting for the message shown previously, you should disable recovery for that PDB before the OPEN RESETLOGS on the primary. In the standby database, you suspend APPLY just for the time it takes to disable recovery. Here are the commands from the Data Guard command line interface (DGMGRL) and SQL*Plus:
![]()

Then recovery occurs for the CDB except for this PDB. You can flashback or point-in-time restore the PDB1 on the primary and open it with resetlogs. Then re-enable its synchronization on standby:
![]()

From there, the PDB1 is synchronized again with the primary.
Auxiliary Instance Cleanup
When an auxiliary instance is created automatically, it is supposed to be cleaned up at the end of the operation. But our recommendation, after lots of testing, is to check that nothing is left over, especially when something has failed in the process. Check AUXILIARY DATAFILE COPY in V$RECOVERY_AREA_USAGE that no unreclaimable file is left over. It’s also a good idea to have a look at FLASHBACK LOG to be sure that you removed the unnecessary guaranteed restore points.
You may see other traces from the auxiliary instance that remain, such as in the DIAG directory. Here is ours after a few PITRs in shared UNDO:
![]()

With this in mind, if you have automated PITR in shared UNDO, you should adapt your housekeeping scripts to clean up appropriately.
Summary
The PITR and flashback features that were missing in 12.1 have been implemented in 12.2, thanks to the introduction of local UNDO mode. On production databases, it provides a safety net for your application releases or maintenance operations, giving you an instantaneous fallback plan. But it’s in development environments that the feature will bring more agility. How often do you have to refresh environments, restore the previous state of a test database, or revert a change made by a test that touched more data than required? PITR and flashback, plus the moving and cloning features we will cover in the next chapter, truly make multitenant the agile environment for modern development.
