

CHAPTER
12
Sharing Data Across PDBs
Is a multitenant database one database, or is it many? This is a question that runs like a silver thread throughout this entire book, and, as you have seen so far, the answer is, “it depends.” For some operations, we need to think of multitenant as a single database; for others, we have to think at the pluggable database (PDB) level and treat each PDB independently.
In this chapter, we investigate how to access the data stored in one PDB from data stored in another PDB, and we will show that, again, we can address the problem from both of the angles described. Furthermore, we will discuss how Oracle introduces a completely new point of view.
At a very basic level, on one hand, we can completely ignore all the new multitenant features, treat all PDBs as completely separate databases, and, as ordinary users, log into a PDB and create a database link to another database, regardless of whether this is part of the same container database (CDB) or not. Or we can tunnel through the wall constructed by Oracle between the PDBs, asking for data from another PDB directly, although this can get very complex and elaborate, as you will see. Let’s take a look at the various options in detail.
Database Links
A database link is a tried-and-tested feature, proven over time, that has been with us since Oracle Database 5.1. That’s 30 years! This is a proven solution, one that DBAs and users are familiar with, and it is congruent with the Oracle message that nothing changes for users when the multitenant architecture is adopted.
Of course, there are some limitations on what type of operations are possible over a database link, but even those are being addressed. For example, Oracle Database 12.2 fills in one long-standing gap, which is support for large object (LOB)–based datatypes.
In addition to the familiarity of this functionality, there is one more major advantage, and this is the opacity of the link to the user. The user does not need to know where the target PDB actually resides. So when a DBA moves the PDB to a new CDB, only the resolution of the connection string has to change, by editing tnsnames.ora, for example. Again, a database link behaves in the same way as it always did, multitenant or not.
In a non-CDB, database links can be split into two basic categories: a remote database link connecting to an external database, and a so-called “loopback” database link connecting to the same database. We can think of the loopback link as an aberrant case, but there are times when it has its place—for example, when two applications are consolidated to the same database, and a database link is required between them for use by the applications. Oracle Database recognizes this special case and introduces some optimizations, such as having only one single transaction on the database shared by both ends of the link. And Oracle Database 12c promises even more performance optimizations, as Oracle expects more links pointing back to the same (container) database.
Multitenant also brings a new distinction to database links, in conjunction with the remote/loopback connection, so that a database link can now connect either to the root container or to a PDB. Note that there is no way to change the current container of the remote end of a database link, because there is no alter session set container for it.
Because of this, a root container database link is useful for administration only. As you saw in Chapter 9, remote clones can use such a link, and we don’t have to create a new one for every single PDB we want to clone. But for accessing data in PDBs, we need to create links connecting directly to the desired PDBs. Although some of the techniques described later in this chapter make user data visible even in the root container, in some cases a CDB link may make sense to access data, too.
As you can see in Figure 12-1, Enterprise Manager offers all the usual options to create a database link. There is no special option to specify whether the target is a PDB or a CDB, because this is implied by the Net Service Name.

Figure 12-1. Creating a database link in Enterprise Manager Cloud Control
Sharing Common Read-Only Data
A special case of data sharing is sharing of the same read-only data by multiple databases. For example, if we want to provide multiple development databases and include large historical data—data that is only queried and no longer modified—it would be ineffective to copy such data multiple times, both in terms of the time taken to perform this operation and in respect to the storage consumed. In a sense, this is a poor man’s solution to making database cloning less storage demanding.

NOTE
Some of the options described here will also work with read/write data, although the options’ usefulness shines in cases when the data is seldom modified.
Transportable Tablespaces
In 8i, Oracle introduced the transportable tablespaces feature. Its prominent use case is to copy data from a production online transaction-processing database into a data warehouse, removing the need for import/export, or for an alternative data extraction and load process. Instead, entire datafiles are copied, with only the metadata imported. For the basic scenario, Enterprise Manager has a nice step-by-step wizard that starts with the screen shown in Figure 12-2.
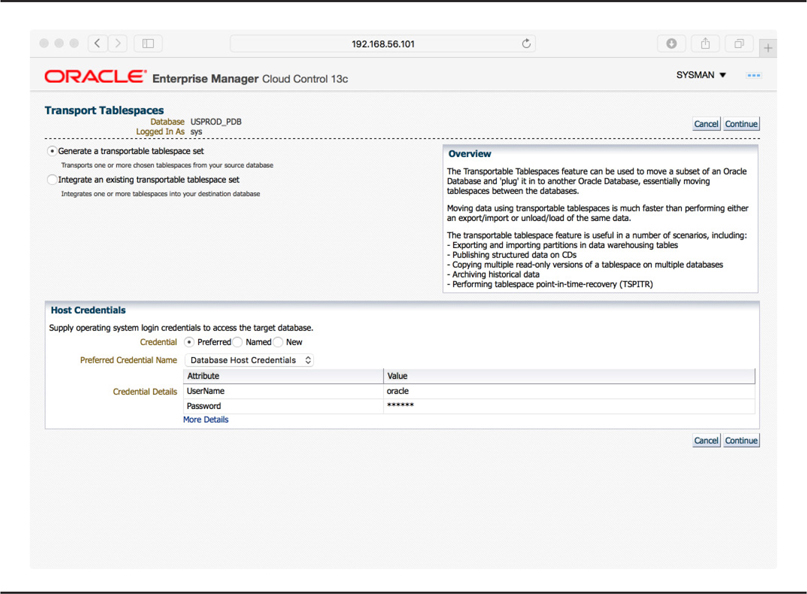
Figure 12-2. Transportable tablespaces in Enterprise Manager Cloud Control
First, we make the source tablespaces read-only and then export the metadata. If our users and applications preclude us from setting the tablespaces to read-only, we can use Recovery Manager (RMAN) to do this export (using the TRANSPORT TABLESPACE command). There is no magic technology used by RMAN; it simply does a partial restore into a new database and runs the export there.
Next, we copy the datafiles to the target server and import the metadata into the target database. This step also makes the datafiles part of the target database.
At this point, the usual next step is to set the tablespaces to read/write and let users modify them. However, this is not mandatory, as the data is already accessible and the datafiles are still not modified. This means that we can also import the same metadata and tablespaces into another database—one or many more databases, as we wish.
It’s the DBA’s responsibility to ensure that none of the databases will modify the tablespaces and that nobody opens them read/write. The databases are oblivious to the fact that the file is used by other databases at the same time, so it won’t prevent us from enacting such changes. However, they will detect such modifications should they happen and will complain loudly.
Of course, because the files are not modified at all, it isn’t necessary for us to copy them from the source database, and even the source database itself can be one of the sharing databases. Whether we want to do this depends a lot on our use case and environment. Such sharing is not appropriate on a production database, which is probably on separate storage and should not bear the penalty of I/O generated by test and development, but in other cases it might be a very useful option.
Storage Snapshots and Copy on Write
A simple extension of the same idea is to leverage storage to provide copies of the tablespaces. This enables us to have multiple copies of the same tablespace, but as of different points in time, or even read/write copies. Of course, this is then more of a “copy-provisioning” option than sharing, but it still has its use cases. After all, when using such tablespaces to provision read-only copies of a production database for testing, having the copy as of multiple points in time is a very beneficial facility.
So when and where might we find use for tablespace copies? In some cases, a test has to be done with multiple copies of the data, while in others we can just build new test environments as we go and update data over time.
To achieve the former, we would create a database that is a copy of the source database and run the transportable tablespace export from there. This copy can be a Data Guard physical standby, making the task of keeping it up-to-date very easy. Alternatively, we could make use of a simple restore and incremental backups if we want to decouple the databases more.
Then, every time we want to make a new copy, we make the tablespace read-only, run the export, and create a new file system snapshot. The clone database can continue to receive redo or incremental backups, and the file system has the copy of the tablespace for us to use. Thanks to the snapshot and copy-on-write facilities, only blocks modified by the clone database after the snapshot was created will take up any extra disk space.
Delphix
Another option is Delphix (www.delphix.com), which provides both fast and cheap cloning as well as storage de-duplication. In this case, we might do well to rethink our entire approach, because this tool excels in the provisioning of entire databases for testing and development. This means that the building of such databases is considerably faster, more flexible, and less painful than we can achieve with a simplistic solution such as sharing one or a few tablespaces.
Cross-PDB Views
As we discussed in previous chapters, Oracle introduced CDB_% dictionary views that display information collected from all open PDBs. In version 12.1.0.1, Oracle used a trick with an internal function called CDB$VIEW to achieve this. This was not documented, and some scenarios caused internal Oracle errors instead of proper results or appropriate error messages.
Fortunately, that version is now a relic of the past, and as of version 12.1.0.2, Oracle Database switched to using the CONTAINERS() clause, which is properly documented and supported.
Delving into this a little deeper, here’s the definition of CDB_USERS in Oracle Database 12.1.0.2:
![]()

In other words, the DBA_USERS view is wrapped in the CONTAINERS() clause and references one new column created by this clause, con_id, obviously referencing the container ID of the PDB.
The CONTAINERS() clause causes Oracle to execute the same query on each of the open PDBs, but skipping PDB$SEED. It is valid to query such a view even from a PDB, but in that case only data for the current PDB is returned.
Let’s have a look at the same view in Oracle Database 12.2.0.1:
![]()

You can see that Oracle started using a table alias (k) in the query. For this particular view, it also added three new columns. What interests us here, in particular, are the two new columns generated by the CONTAINERS() clause: CON$NAME and CDB$NAME.
The first is the name of the PDB where the records come from, essentially translating the con_id into the PDB name. The second new column is the name of the CDB itself, and you will see later in this chapter when this might be useful.
We already noted that querying from the PDB will show us data from the PDB only, while querying from CDB$ROOT gives us data from all the PDBs except the seed. If we run the query from an application container root, we get data from the application root and all its application PDBs, except the application seed.
Simple User Tables
Because the CONTAINERS() clause is documented and supported, Oracle allows us to query our own user tables as well as build views on top of them, aggregating data from multiple PDBs.
Simple Status Query
Let’s start with a simple example query, supposing that we want to monitor multiple PDBs. For this, we will assume that each has a user table called ERRORLOG, and we want to query for all error messages inserted there. We are interested in only the single table, and we want to query across all the PDBs.
First of all, we need a common user to query the data, as a local user would always see data from its PDB only:
![]()

The ERORRLOG table must be present in all of the PDBs (actually, only in those PDBs we want to query, as you’ll see later) and in the root, too, and the Data Definition Language (DDL) of all these copies must match. Because the table must also be in the root, we have to create it under a common user schema, or we can create it under local users in the PDBs and let the common user have views or synonyms. In these examples, we don’t use application containers, so the common user is created in CDB$ROOT; this mandates that the user’s name is prefixed by the COMMON_USER_PREFIX, which defaults to c##.
We run this create DDL in the CDB, then in all the PDBs:
![]()

As simple test data, let’s insert one row in each of the PDBs:
![]()

Now we can query the data:
![]()

As noted, the DDL must match. If, for example, we generate a new PDB and create the table differently, like this (same would happen if the table is not there at all):
![]()

Oracle silently ignores this table:
![]()

However, there is some leeway for allowed differences. Oracle takes the metadata from the table in the root, so if the PDB tables have extra columns, that’s fine, because they will be ignored.
So, let’s fix the missing column and add one more:
![]()
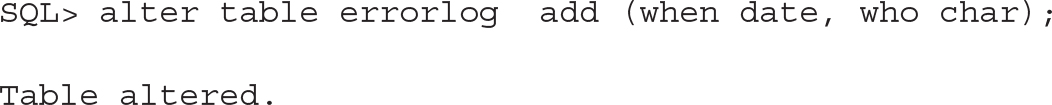
Now the query from the root works again—ignoring the extra column:
![]()

Querying Only Some of the PDBs
Oracle runs the query only in the containers where it makes sense to do so. So if we specify a condition such as con_id, to choose only some of the PDBs, Oracle will look in these PDBs only:
![]()

And we can use CON$NAME, too:
![]()

For another, more sophisticated, approach to this problem, see the “Container Map” section later in this chapter.
Query Hint
In some cases, we might want or need to add a hint to a query that uses the CONTAINERS() clause. But if we put it in the usual syntax, it will apply only to the last aggregation step, not to the queries that are run in each of the PDBs.
Fortunately, Oracle introduced a way for us to “push down” such hints into the queries. The CONTAINERS(DEFAULT_PDB_HINT=’… ’) syntax specifies these hints:
![]()

Querying the Data from a PDB
As already noted, accessing the CONTAINERS() query from within a PDB gives us data only for that particular PDB.
In the previous examples, we had a logging table, and the query collected errors from all the PDBs. So what if one of the PDBs is a monitoring application that actually needs to access and process all these error logs?
Well, the solution is trivial: we can just create a database link pointing to the common user in the CDB, and query the data over the database link. We can’t put the CONTAINERS() clause around a remote object, but we can work around this simply by creating a view.
![]()

Consolidated Data
One of the use cases of multitenant that really fits its features and advantages, and perhaps the one that Oracle had in mind when designing this feature, is consolidation of instances of the same application. Imagine a service provider that sells an SaaS application to its customers and needs multiple copies of the same application running on the same hardware. Or perhaps a company IT department provides the same application for multiple branches or franchisees; the application is the same and the users need data separation, but the head office wants to access the data from all of the PDBs at the same time to run various reports. These types of companies can benefit from consolidated access to their data.
In the pre-multitenant world, we could either do schema consolidation and put all the users into the same database if the application supported such an approach, or we could build one consolidated staging/data warehouse and load the necessary data into it, and then run reports from there. However, as you have seen in the previous section, multitenant enables us to access all the PDBs at the same time and thus build queries that run consolidated reports on the data directly (although with imposed limitations such as having the same table names and structure). The approach described in the previous section can achieve this, but it could be a bit cumbersome should we do it for more than a handful of tables.
Oracle Database 12.2 unleashes a number of features that make this consolidation a much more prominent citizen of the database ecosystem. Oracle promotes application containers as one of the key pieces of the solution for these scenarios, although many of the features don’t actually require them. Still, if we find that working with consolidated PDB data is an important piece in our application, it might be a good time to dig deeper into the application containers and consider whether building the application using them would be a good fit.
Linking Tables Across Containers
You have already seen in Chapter 1 how Oracle links the dictionary objects between the CDB and the PDBs using metadata and object links. Oracle now enables us to do the same with our objects and data—well, kind of.
This implies storing data in the root container, and Oracle is strict here in that it does not want us to enter into the bad practice of creating user objects in the CDB root. It thus mandates that we create an application container instead and store the data in its container root.
So let’s create an application container with a couple of application PDBs in it, with a common user. In this simple example, we won’t create an application seed in the application container.
![]()

Metadata-Linked Objects As the application common user in the application container root, we can now create a metadata-linked table. The table definition, or metadata, is in the container root; the actual data segments are private to each application PDB. The following illustration shows such arrangement of data:

Note that we are modifying the application root, and Oracle requires us to mark any such modifications as “application install,” to be able to replay the changes in the containers.
![]()

As you can see, any objects and data created during the application install are synchronized to the PDB from the application root. However, no changes done after the install are reflected, and the rowid shows that these are really distinct rows; the sync does a one-time copy, and from then on the rows are not linked in any way.
However, there is some value to these oversimplified nonlinked tables. Oracle knows which containers have this particular version installed and thus contain the table; it does not complain that some of the containers don’t have the table present yet, and we don’t need to limit the query manually on con_id.
![]()

Extended Data Metadata-Linked Objects A special flavor of metadata-linked objects is an extended data object. In this case, the data is stored in both the application root (common data, visible by all PDBs) and in the application PDBs (data private to each of the PDBs), as shown in the following illustration:

The steps are similar to those in the previous example, with the notable inclusion of the EXTENDED DATA clause in the DDL.
In this example, the application is already installed, thanks to the example we ran in the previous section, and we now add a new table there in a patch:
![]()

We observe that the application PDB sees current values of objects in the root, including any changes done out of the application action. (Note that we can’t use ROWID in the query in a PDB, however, because it will fail with an ORA error.) And it can also add new records, private to the application PDB:
![]()

However, we cannot modify records inherited from the root; an update command does not see these rows, even if a select query at the same time does.
![]()

Although the root can, of course, modify the row:
![]()

One caveat, as you have seen, is that each PDB shows its own copy of the common rows, and the parallel slaves executing a CONTAINERS() query across the PDBs do not remove these duplicates.
Data-Linked Objects An object-linked object exists in one place only: in the application container root. We are not allowed to modify the data the PDBs.
As the next illustration reveals, this is really common data shared by all PDBs, modified only during maintenance:

Or, looking at it from a completely different point of view, this could be considered read-only data shared by all PDBs—very similar to that which was achieved with transportable tablespaces.
![]()

The root container can modify these contents even if not in the special application patch or upgrade mode:
![]()

Now let’s switch to the application PDB:
![]()

The application PDB cannot modify the table. There is really only one copy of the data, the PDBs can access it read-only, seeing all changes done in the CDB.
A minor limitation is that it is not possible to query rowid of the table while in a PDB - such query fails with ORA-02031: no ROWID for fixed tables or for external-organized tables.
Cross-PDB DML
In Oracle Database 12.2, and not limited to application containers, we can actually issue DML on a table wrapped in the CONTAINERS() clause. In other words, we can change data in multiple PDBs with a single operation, from a single transaction.
![]()

We can even specify the con_id to limit the execution to selected PDBs.
![]()

Oracle introduces a new setting that we can use to specify which PDBs should be affected by this DML. This way, we don’t have to specify the con_id condition in each DML, which means we don’t have to modify the scripts every time we want to run it on a different set of PDBs.
To get the current setting, we can look at DATABASE_PROPERTIES:
![]()

And we can change the values with this:
![]()
![]()
The pluggable keyword is to be used when we issue the statement in the application root (which is a kind of PDB itself), although we omit the keyword if we execute it in CDB$ROOT. As for the target specification, we can use <a list of PDBs>, ALL, ALL EXCEPT <a list of PDBs>, or NONE.
Note that the default is NONE, which, contrary to its name, actually contains all (application) containers, except the seed and root.
Containers Default
If we find that we are using the CONTAINERS() clause heavily, we might realize it’s too much work, and too error-prone, to add the clause dutifully to every reference for the tables we want to query this way. Or perhaps we want to reuse existing code and queries and want to minimize the changes needed to update the code to use the clause. Fortunately, Oracle had introduced a new table setting, which, if enabled, will result in every query and DML on that table or view being automatically wrapped in the CONTAINERS() clause.
![]()

The setting can be easily checked in the data dictionary:
![]()

Container Map
When we have multiple PDBs with the same tables but different data (such as data for different customers or branches) and we run queries on this data, all these PDBs are interrogated, unless we specify con_id in the where condition.
In a sense, this is a partitioning schema; data for a single customer or branch resides in a single PDB only—it doesn’t overlap—and if we search for a single branch, only one PDB will contain data for it, as shown in the illustration:

Therefore, it stands to reason that Oracle should have a method for selectively pruning these queries, like it does with ordinary partitions. Indeed, Oracle now enables us to declare the mapping, such that the optimizer then knows how to respond accordingly. This is called a container map. In it we create a dummy table with no data, which describes just the partitioning schema, with the requirement that the names of the partitions must match the names of the PDBs.
So let’s create an example table in the CDB$ROOT and a few PDBs:
![]()

We can now check that there is a row in each of the containers:
![]()

Now let’s create the container map and set it. Note that the container map is global for the root or application container root.
![]()

The last step is to enable the table(s) to declare that they should be handled in this special way:
![]()

In this example, we used a list-partitioning schema, but Oracle also allows RANGE and HASH. The inclusion of a HASH schema points to the idea that dividing a large application database into PDBs may be done to split the amount of data and user load, with no further attempt to determine the allocation based on any human-defined condition; HASH would simply split the data into PDBs of more or less the same size.
Location Independence
We have seen in Chapter 9 that it’s easy to copy and move PDBs from one CDB to another. Usually we just update the Transparent Network Substrate (TNS) connection string after the move to a different server, and the clients will connect to the new location. We mentioned that Oracle can also create a proxy PDB, and you might wonder whether a proxy PDB is really such a big deal. The answer, once we begin working with consolidation queries, is a resolute yes.
The CONTAINERS() clause can work on one CDB only; it cannot reference remote PDBs, and there is no syntax to specify such PDBs or database links. However, there is one notable exception: proxy PDB. From the view of the queries, a proxy PDB is a pluggable database like any other, sitting locally on the CDB. The queries are not aware that their requests are actually passed on further, to a remote PDB. In other words, the CONTAINERS() clause will gather data from both regular, local PDBs as well as from proxy PDBs.
If we add the fact that the limit of PDBs in a single CDB has been raised to 4096, we can now run queries across many, many PDBs, even if having so many PDBs on a single machine would be practically untenable because of resource requirements.
Cross-Database Replication
Another option for data sharing is to look at solutions that work across databases. They also usually allow the target to be the same database as source (have it loop back), or at least a different PDB than the source. We discuss this in further detail in Chapter 13.
Summary
We have discovered that the gamut of the options for data sharing is vast. We can stay entrenched in current thinking and use proven features, such as database links or transportable tablespaces, or we can begin to rethink our approach completely and build our applications on application containers, shared objects, and container maps.
Oracle DBAs are typically conservative, so whether these ideas gain significant traction within this community (let alone among users in general) is yet to be seen apart from a few obvious types for whom these features of multitenant specifically appeal, such as cloud and SaaS providers.
