Business Continuity, Disaster Recovery, and Change Management
Business Continuity, Disaster Recovery, and Change Management
In this chapter, you will learn how to
![]() Operational disruptions can and will occur in systems
Operational disruptions can and will occur in systems
![]() Describe the various ways backups are conducted and stored
Describe the various ways backups are conducted and stored
![]() Use change management as an important enterprise management tool
Use change management as an important enterprise management tool
![]() Institute the key concept of separation of duties
Institute the key concept of separation of duties
![]() Identify the essential elements of change management
Identify the essential elements of change management
![]() Implement change management
Implement change management
![]() Use the concepts of the Capability Maturity Model Integration
Use the concepts of the Capability Maturity Model Integration
![]() Implement secure systems design for a given scenario
Implement secure systems design for a given scenario
It is well recognized that today’s computer systems are extremely complex, and it is obvious that inventory management systems for large international enterprises such as Walmart and Home Depot are probably as complex as an aircraft or skyscraper. Prominent operating systems such as Windows and UNIX/Linux are also very complex, as are computer processors on a chip. Many of today’s web-based applications are extremely complex as well. For example, today’s web-based applications typically consist of flash content on web sites interacting with remote databases through a variety of services or service-oriented architectures hosted on web servers located anywhere in the world.
You wouldn’t think of constructing an aircraft, large building, computer chip, or automobile in the informal manner sometimes used to develop and operate computer systems of equal complexity. Computer systems have grown to be so complex and mission-critical that enterprises cannot afford to develop and maintain them in an ad hoc manner.
Change management procedures can add structure and control to the development and management of large software systems as they move from development to implementation and during operation. In this chapter, change management refers to a standard methodology for performing and recording changes during software development and system operation. The methodology defines steps that ensure that system changes are required by the organization and are properly authorized, documented, tested, and approved by management. In many conversations, the term configuration management is considered synonymous with change management and, in a more limited manner, version control or release control.
The term change management is often applied to the management of changes in the business environment, typically as a result of business process reengineering or quality enhancement efforts. The term change management as used in this chapter is directly related to managing and controlling software development, maintenance, and system operation. Configuration management is the application of change management principles to the configuration of both software and hardware.
The objective of all systems is to perform for a specific purpose, and IT systems are no different. By design, IT systems support a wide range of business functions. These business functions change over time, requiring the necessary adjustment to the IT system, and these changes are carefully orchestrated via change control. But how do you handle a unplanned change to the system? A disaster, an outage from a supplier, a pandemic that keeps workers at home? These business interruptions call for a flexible system that has the ability to change in a responsive way. This is the basis of business continuity planning, disaster recovery plans, and continuity of operations planning.
 Business Continuity
Business Continuity
Keeping an organization running when an event occurs that disrupts operations is not accomplished spontaneously but requires advance planning and periodically exercising those plans to ensure they will work. A term that is often used when discussing the issue of continued organizational operations is business continuity (BC).
![]()
Although the terms disaster recovery plan (DRP) and business continuity plan (BCP) may be used synonymously in small firms, in large firms there is a difference in focus between the two plans. The focus of the BCP is on continued operation of a business, albeit at a reduced level or through different means during some period of time. The DRP is focused specifically on recovering from a disaster. In many cases, both of these functions happen at the same time, and hence they are frequently combined in small firms and in many discussions. The DRP is part of the larger BCP process.
There are many risk management best practices associated with business continuity. The topics of planning, business impact analysis, identification of critical systems and components, single points of failure, and more are detailed in the following sections.
Business Continuity Plans
As with most operational issues, planning is a foundational element to success. This is true in business continuity, and the business continuity plan (BCP) represents the planning and advance policy decisions to ensure the business continuity objectives are achieved during a time of obvious turmoil. You might wonder what the difference is between a disaster recovery plan and a business continuity plan. After all, isn’t the purpose of disaster recovery the continued operation of the organization or business during a period of disruption? Many times, these two terms are used synonymously, and for many organizations there may be no major difference between them. There are, however, real differences between a BCP and a DRP, one of which is the focus.
The focus of a BCP is the continued operation of the essential elements of the business or organization. Business continuity is not about operations as normal but rather about trimmed-down, essential operations only. In a BCP, you will see a more significant emphasis placed on the limited number of critical systems the organization needs to operate. The BCP will describe the functions that are most critical, based on a previously conducted business impact analysis (BIA), and will describe the order in which functions should be returned to operation. The BCP describes what is needed in order for the business to continue to operate in the short term, even if all requirements are not met and risk profiles are changed.
The focus of a DRP is on recovering and rebuilding the organization after a disaster has occurred. The recovery’s goal is the complete operation of all elements of the business. The DRP is part of the larger picture, while the BCP is a tactical necessity until operations can be restored. A major focus of the DRP is the protection of human life, meaning evacuation plans and system shutdown procedures should be addressed. In fact, the safety of employees should be a theme throughout a DRP.
Business Impact Analysis
Business impact analysis (BIA) is the term used to describe the document that details the specific impact of elements on a business operation (this may also be referred to as a business impact assessment). A BIA outlines what the loss of any of your critical functions will mean to the organization. The BIA is a foundational document used to establish a wide range of priorities, including the system backups and restoration that are needed to maintain continuity of operation. While each person may consider their individual tasks to be important, the BIA is a business-level analysis of the criticality of all elements with respect to the business as a whole. The BIA will take into account the increased risk from minimal operations and is designed to determine and justify what is essentially critical for a business to survive versus what someone may state or wish.
![]()
Conducting a BIA is a critical part of developing your BCP. This assessment will allow you to focus on the most critical elements of your organization. These critical elements are the ones that you want to ensure are recovered first, and this priority should be reflected in your BCP and subset DRP.
Identification of Critical Systems and Components
A foundational element of a security plan is an understanding of the criticality of systems, the data, and the components. Identifying the critical systems and components is one of the first steps an organization needs to undertake in designing the set of security controls. As the systems evolve and change, the continued identification of the critical systems needs to occur, keeping the information up to date and current.
Removing Single Points of Failure
A key security methodology is to attempt to avoid a single point of failure in critical functions within an organization. When developing your BCP, you should be on the lookout for areas in which a critical function relies on a single item (such as switches, routers, firewalls, power supplies, software, or data) that if lost would stop this critical function. When these points are identified, think about how each of these possible single points of failure can be eliminated (or mitigated).
In addition to the internal resources you need to consider when evaluating your business functions, there are many resources external to your organization that can impact the operation of your business. You must look beyond hardware, software, and data to consider how the loss of various critical infrastructures can also impact business operations.
Risk Assessment
The principles of risk assessment can be applied to business continuity planning. Determining the sources and magnitudes of risks is necessary in all business operations, including business continuity planning. More detailed analysis of risk is presented in Chapter 20.
Succession Planning
Business continuity planning is more than just ensuring that hardware is available and operational. The people who operate and maintain the system are also important, and in the event of a disruptive event, the availability of key personnel is as important as hardware for successful business continuity operations. The development of a succession plan that identifies key personnel and develops qualified personnel for key functions is a critical part of a successful BCP.
![]()
Business continuity is not only about hardware; plans need to include people as well. Succession planning is a proactive plan for personnel substitutions in the event that the primary person is not available to fulfill their assigned duties.
After-Action Reports
Just as lessons learned are a key element of incident response processes, the after-action reports associated with invoking continuity of operations provide insight into two functions. First is the level of operations upon transfer. Is all of the desired capability up and running? The second question addresses how the actual change from normal operations to those supported by the continuity systems occurred.
Failover
Failover is the process of moving from a normal operational capability to the continuity of operations version of the business. The speed and flexibility depend on the business type—from seamless for a lot of financial sites, to one where A is turned off and someone goes and turns B on, with some period of no service between. Simple transparent failovers can be achieved through architecture and technology choices, but they must be designed into the system.
Separate from failover, which occurs whenever the problem occurs, is the switch back to the original system. Once a system is fixed, resolving whatever caused the outage, there is a need to move back to the original production system. This “failback” mechanism, by definition, is harder to perform as primary keys and indexes are not easily transferred back. The return to operations is a complicated process, but the good news is that it can be performed at a time of the organization’s choosing, unlike the problem that initiated the initial shift of operations to continuity procedures.
Backups
A key element in any business continuity/disaster recovery plan is the availability of backups. This is true not only because of the possibility of a disaster but also because hardware and storage media will periodically fail, resulting in the loss or corruption of critical data. An organization might also find backups critical when security measures have failed and an individual has gained access to important information that may have become corrupted or at the very least can’t be trusted. Data backup is thus a critical element in these plans, as well as in normal operation. The following are several factors to consider in an organization’s data backup strategy:
![]() How frequently should backups be conducted?
How frequently should backups be conducted?
![]() How extensive do the backups need to be?
How extensive do the backups need to be?
![]() What is the process for conducting backups?
What is the process for conducting backups?
![]() Who is responsible for ensuring backups are created?
Who is responsible for ensuring backups are created?
![]() Where will the backups be stored?
Where will the backups be stored?
![]() How long will backups be kept?
How long will backups be kept?
![]() How many copies will be maintained?
How many copies will be maintained?
Keep in mind that the purpose of a backup is to provide valid, uncorrupted data in the event of corruption or loss of the original file or the media where the data was stored. Depending on the type of organization, legal requirements for maintaining backups can also affect how it is accomplished.

Tech Tip
Backups Are a Key Responsibility for Administrators
One of the most important tools a security administrator has is a backup. While backups will not prevent a security event (or natural disaster) from occurring, they often can save an organization from a catastrophe by allowing it to quickly return to full operation after an event occurs. Conducting frequent backups and having a viable backup and recovery plan are two of the most important responsibilities of a security administrator.
What Needs to Be Backed Up
Backups commonly comprise the data that an organization relies on to conduct its daily operations. While this is certainly essential, a good backup plan will consider more than just the data; it will include any application programs needed to process the data and the operating system and utilities that the hardware platform requires to run the applications. Obviously, the application programs and operating system will change much less frequently than the data itself, so the frequency with which these items need to be backed up is considerably different. This should be reflected in the organization’s backup plan and strategy.
The business continuity/disaster recovery plan should also address other items related to backups. Personnel, equipment, and electrical power must also be part of the plan. Somebody needs to understand the operation of the critical hardware and software used by the organization. If the disaster that destroyed the original copy of the data and the original systems also results in the loss of the only personnel who know how to process the data, having backup data will not be enough to restore normal operations for the organization. Similarly, if the data requires specific software to be run on a specific hardware platform, then having the data without the application program or required hardware will also not be sufficient.
Tech Tip
Implementing the Right Type of Backup
Carefully consider the type of backup that you want to conduct. With the size of today’s PC hard drives, a complete backup of the entire hard drive can take a considerable amount of time. Implement the type of backup you need and check for software tools that can help you in establishing a viable backup schedule.
Strategies for Backups
The process for creating a backup copy of data and software requires more thought than simply stating “copy all required files.” The size of the resulting backup must be considered, as well as the time required to conduct the backup. Both of these will affect details such as how frequently the backup will occur and the type of storage medium that will be used for the backup. Other considerations include who will be responsible for conducting the backup, where the backups will be stored, and how long they should be maintained. Short-term storage for accidentally deleted files that users need to have restored should probably be close at hand. Longer-term storage for backups that may be several months or even years old should occur in a different facility. It should be evident by now that even something that sounds as simple as maintaining backup copies of essential data requires careful consideration and planning.
Types of Backups
The amount of data that will be backed up, and the time it takes to accomplish this, has a direct bearing on the type of backup that should be performed. Table 21.1 outlines the four basic types of backups that can be conducted, the amount of space required for each, and the ease of restoration using each strategy.
Table 21.1 Backup Types and Characteristics

The values for each of the strategies in Table 21.1 are highly variable depending on your specific environment. The more frequently files are changed between backups, the more these strategies will look alike. What each strategy entails bears further explanation.
Tech Tip
The Archive Bit
The archive bit is used to indicate whether a file has (1) or has not (0) changed since the last backup. The bit is set (changed to 1) if the file is modified, or in some cases, if the file is copied, the new copy of the file has its archive bit set. The bit is reset (changed to 0) when the file is backed up. The archive bit can be used to determine which files need to be backed up when using a method such as the differential backup method.
Full
The easiest type of backup to understand is the full backup. In a full backup, all files and software are copied onto the storage media. Restoration from a full backup is similarly straightforward—you must copy all the files back onto the system. This process can take a considerable amount of time. Consider the size of even the average home PC today, for which storage is measured in tens or hundreds of gigabytes. Copying this amount of data takes time. In a full backup, the archive bit is cleared.
Differential
In a differential backup, only the files that have changed since the last full backup was completed are backed up. This also implies that periodically a full backup needs to be accomplished. The frequency of the full backup versus the interim differential backups depends on your organization and needs to be part of your defined strategy. Restoration from a differential backup requires two steps: the last full backup first needs to be loaded, and then the last differential backup performed can be applied to update the files that have been changed since the full backup was conducted. Again, this is not a difficult process, but it does take some time. The amount of time to accomplish the periodic differential backup, however, is much less than that for a full backup, and this is one of the advantages of this method. Obviously, if a lot of time has passed between differential backups or if most files in your environment change frequently, then the differential backup does not differ much from a full backup. It should also be obvious that to accomplish the differential backup, the system needs to have a method to determine which files have been changed since some given point in time. The archive bit is not cleared in a differential backup since the key for a differential is to back up all files that have changed since the last full backup.
Tech Tip
Incremental vs. Differential Backups
Both incremental and differential backups begin with a full backup. An incremental backup only includes the data that has changed since the previous backup, including the last incremental. A differential backup contains all of the data that has changed since the last full backup. The advantage that differential backups have over incremental is shorter restore times. The advantage of the incremental backup is shorter backup times. To restore a differential backup, you restore the full backup and the latest differential backup: two events. To restore an incremental system, you restore the full and then all the incremental backups in order.
Delta
Finally, the goal of the delta backup is to back up as little information as possible each time you perform a backup. As with the other strategies, an occasional full backup must be accomplished. After that, when a delta backup is conducted at specific intervals, only the portions of the files that have been changed will be stored. The advantage of this is easy to illustrate. If your organization maintains a large database with thousands of records comprising several hundred megabytes of data, the entire database would be copied in the previous backup types even if only one record has changed. For a delta backup, only the actual record that changed would be stored. The disadvantage of this method is that restoration is a complex process because it requires more than just loading a file (or several files). It requires that application software be run to update the records in the files that have been changed.
There are some newer backup methods that are similar to delta backups in that they minimize what is backed up. There are real-time and near-real-time backup strategies, such as journaling, transactional backups, and electronic vaulting, that can provide protection against loss in real-time environments. Implementing these methods into an overall backup strategy can increase options and flexibility during times of recovery.
Snapshots
Snapshots refer to copies of virtual machines. One of the advantages of a virtual machine over a physical machine is the ease with which the virtual machine can be backed up and restored. A snapshot is a copy of a virtual machine at a specific point in time. This is done by copying the files that store the VM. The ability to revert to an earlier snapshot is as easy as pushing a button and waiting for the machine to be restored via a change of the files.
Each type of backup has advantages and disadvantages. Which type is best for your organization depends on the amount of data you routinely process and store, how frequently the data changes, how often you expect to have to restore from a backup, and a number of other factors. The type you select will shape your overall backup strategy and processes.
Backup Frequency and Retention
The type of backup strategy an organization employs is often affected by how frequently the organization conducts the backup activity. The usefulness of a backup is directly related to how many changes have occurred since the backup was created, and this is obviously affected by how often backups are created. The longer it has been since the backup was created, the more changes that likely will have occurred. There is no easy answer, however, to how frequently an organization should perform backups. Every organization should consider how long it can survive without current data from which to operate. It can then determine how long it will take to restore from backups, using various methods, and decide how frequently backups need to occur. This sounds simple, but it is a serious, complex decision to make.
Tech Tip
Determining How Long to Maintain Backups
Determining the length of time that you retain your backups should not be based on the frequency of your backups. The more often you conduct backup operations, the more data you will have. You might be tempted to trim the number of backups retained to keep storage costs down, but you need to evaluate how long you need to retain backups based on your operational environment and then keep the appropriate number of backups.
Related to the frequency question is the issue of how long backups should be maintained. Is it sufficient to simply maintain a single backup from which to restore data? Security professionals will tell you no; multiple backups should be maintained for a variety of reasons. If the reason for restoring from the backup is the discovery of an intruder in the system, it is important to restore the system to its pre-intrusion state. If the intruder has been in the system for several months before being discovered and backups are taken weekly, it will not be possible to restore to a pre-intrusion state if only one backup is maintained. This would mean that all data and system files would be suspect and may not be reliable. If multiple backups were maintained, at various intervals, then it is easier to return to a point before the intrusion (or before the security or operational event that is necessitating the restoration) occurred.
There are several strategies or approaches to backup retention. One common and easy-to-remember strategy is the “rule of three,” in which the three most recent backups are kept. When a new backup is created, the oldest backup is overwritten. Another strategy is to keep the most recent copy of backups for various time intervals. For example, you might keep the latest daily, weekly, monthly, quarterly, and yearly backups. Note that in certain environments, regulatory issues may prescribe a specific frequency and retention period, so it is important to know your organization’s requirements when determining how often you will create a backup and how long you will keep it.
If you are not in an environment for which regulatory issues dictate the frequency and retention for backups, your goal will be to optimize the frequency. In determining the optimal backup frequency, two major costs need to be considered: the cost of the backup strategy you choose and the cost of recovery if you do not implement this backup strategy (that is, if no backups were created). You must also factor into this equation the probability that the backup will be needed on any given day. The two figures to consider then are these:
Alternative 1: (probability the backup is needed) × (cost of restoring with no backup)
Alternative 2: (probability the backup isn’t needed) × (cost of the backup strategy)
The first of these two figures, alternative 1, can be considered the probable loss you can expect if your organization has no backup. The second figure, alternative 2, can be considered the amount you are willing to spend to ensure that you can restore, should a problem occur (think of this as backup insurance—the cost of an insurance policy that may never be used but that you are willing to pay for, just in case). For example, if the probability of a backup being needed is 10 percent and the cost of restoring with no backup is $100,000, then the first equation would yield a figure of $10,000. This can be compared with the alternative, which would be a 90 percent chance the backup is not needed multiplied by the cost of implementing your backup strategy (of taking and maintaining the backups), which is, say, $10,000 annually. The second equation yields a figure of $9,000. In this example, the cost of maintaining the backup is less than the cost of not having backups, so the former would be the better choice. While conceptually this is an easy trade-off to understand, in reality it is often difficult to accurately determine the probability of a backup being needed.
Fortunately, the figures for the potential loss if there is no backup are generally so much greater than the cost of maintaining a backup that a mistake in judging the probability will not matter—it just makes too much sense to maintain backups. This example also uses a straight comparison based solely on the cost of the process of restoring with and without a backup strategy. What needs to be included in the cost of both of these is the loss that occurs while the asset is not available as it is being restored—in essence, a measurement of the value of the asset itself.
To optimize your backup strategy, you need to determine the correct balance between these two figures. Obviously, you do not want to spend more in your backup strategy than you face losing should you not have a backup plan at all. When working with these two calculations, you have to remember that this is a cost-avoidance exercise. The organization is not going to increase revenues with its backup strategy. The goal is to minimize the potential loss due to some catastrophic event by creating a backup strategy that will address your organization’s needs.
When you’re calculating the cost of the backup strategy, consider the following:
![]() The cost of the backup media required for a single backup
The cost of the backup media required for a single backup
![]() The storage costs for the backup media based on the retention policy
The storage costs for the backup media based on the retention policy
![]() The labor costs associated with performing a single backup
The labor costs associated with performing a single backup
![]() The frequency with which backups are created
The frequency with which backups are created
All of these considerations can be used to arrive at an annual cost for implementing your chosen backup strategy, and this figure can then be used as previously described.
Tech Tip
Onsite Backup Storage
One of the most frequent errors committed with backups is to store all backups onsite. While this greatly simplifies the process, it means that all data is stored in the same facility. Should a natural disaster occur (such as a fire or hurricane), you could lose not only your primary data storage devices but your backups as well. You need to use an offsite location to store at least some of your backups.
Storage of Backups
An important element to factor into the cost of the backup strategy is the expense of storing the backups. This is affected by many variables, including the number and size of the backups as well as the need for quick restoration. This can be further complicated by keeping hot, warm, and cold sites synchronized. Backup storage is more than just figuring out where to keep tapes, but rather becomes part of business continuity, disaster recovery, and overall risk strategies.
Tech Tip
Long-Term Backup Storage
An easy factor to overlook when upgrading systems is whether long-term backups will still be usable. You need to ensure that the type of media utilized for your long-term storage is compatible with the hardware you are upgrading to. Otherwise, you may find yourself in a situation in which you need to restore data, and you have the data, but you don’t have any way to restore it.
Issues with Long-Term Storage of Backups
Depending on the media used for an organization’s backups, degradation of the media is a distinct possibility and needs to be considered. Magnetic media degrades over time (measured in years). In addition, tapes can be used a limited number of times before the surface begins to flake off. Magnetic media should thus be rotated and tested to ensure that it is still usable.
You should also consider advances in technology. The media you used to store your data years ago may now be considered obsolete (floppy disks, for example). Software applications also evolve, and the media may be present but may not be compatible with current versions of the software. This may mean that you need to maintain backup copies of both hardware and software in order to recover from older backup media.
Another issue is security related. If the file you stored was encrypted for security purposes, does anybody in the company remember the password to decrypt the file to restore the data? More than one employee in the company should know the key to decrypt the files, and this information should be passed along to another person when a critical employee with that information leaves, is terminated, or dies.
Geographic Considerations
An important element to factor into the cost of the backup strategy is the location of storing the backups. A simple strategy might be to store all your backups together for quick and easy recovery actions. This is not, however, a good idea. Suppose the catastrophic event that necessitated the restoration of backed-up data was a fire that destroyed the computer system the data was processed on. In this case, any backups that were stored in the same facility might also be lost in the same fire.
The solution is to keep copies of backups in separate locations. The most recent copy can be stored locally because it is the most likely to be needed, while other copies can be kept at other locations. Depending on the level of security your organization desires, the storage facility itself could be reinforced against possible threats in your area (such as tornados or floods). A more recent advance is online backup services. A number of third-party companies offer high-speed connections for storing data in a separate facility. Transmitting the backup data via network connections alleviates some other issues with the physical movement of more traditional storage media, such as the care during transportation (tapes do not fare well in direct sunlight, for example) or the time that it takes to transport the tapes.
Location Selection Picking a storage location has several key considerations. First is physical safety. Because of the importance of maintaining proper environmental conditions that are safe from outside harm, this can limit locations. Heating, ventilating, and air conditioning (HVAC) can be a consideration, as well as issues such as potential flooding and theft. The ability to move the backups in and out of storage is also a concern. Again, the cloud and modern-day networks come to the rescue; with today’s high-speed networks, reasonably priced storage, encryption technologies, and the ability to store backups in a redundant array across multiple sites, the cloud is an ideal solution.
Offsite Backups Offsite backups are just that—backups that are stored in a separate location from the system being backed up. This can be important when an issue affects a larger area than a single room. A building fire, a hurricane, or a tornado could occur and typically affect a larger area than a single room or building. Having backups offsite alleviates the risk of losing them. In today’s high-speed network world with cloud services, storing backups in the cloud is an option that can resolve many of the risks associated with backup availability.
Distance The distance associated with an offsite backup is a logistic problem. If you need to restore a system and the backup is stored hours away by car, this can increase the recovery time. The physical movement of backup tapes has been alleviated in many systems through networks that move the data at the speed of the network.
Legal Implications When planning an offsite backup, you must consider the legal implications of where the data is being stored. Different jurisdictions have different laws, rules, and regulations concerning core tools such as encryption. Understanding how these affect data backup storage plans is critical to prevent downstream problems.
Data Sovereignty Data sovereignty is a relatively new phenomenon, but in the past couple of years several countries have enacted laws stating that certain types of data must be stored within their boundaries. In today’s multinational economy, with the Internet not knowing borders, this has become a problem. Several high-tech firms have changed their business strategies and offerings in order to comply with data sovereignty rules and regulations. For example, LinkedIn, a business social network site, recently was told by Russian authorities that all data on Russian citizens needed to be kept on servers in Russia. LinkedIn made the business decision that the cost was not worth the benefit and has since abandoned the Russian market.
Alternative Sites
An issue related to the location of backup storage is where the restoration services will be conducted. Determining when or if an alternative site is needed should be included in recovery and continuity plans. If the organization has suffered physical damage to a facility, having offsite storage of data is only part of the solution. This data will need to be processed somewhere, which means that computing facilities similar to those used in normal operations are required. There are a number of ways to approach this problem, including hot sites, warm sites, cold sites, and mobile backup sites.
![]()
Try This!
Research Alternative Processing Sites
There is an industry built upon providing alternative processing sites in case of a disaster of some sort. Using the Internet or other resources, determine what resources are available in your area for hot, warm, and cold sites. Do you live in an area in which a lot of these services are offered? Do other areas of the country have more alternative processing sites available? What makes where you live a better or worse place for alternative sites?
Hot Site
A hot site is a fully configured environment, similar to the normal operating environment, that can be operational immediately or within a few hours, depending on its configuration and the needs of the organization.
Warm Site
A warm site is partially configured, usually having the peripherals and software but perhaps not the more expensive main processing computer. It is designed to be operational within a few days.
Cold Site
A cold site will have the basic environmental controls necessary to operate but few of the computing components necessary for processing. Getting a cold site operational may take weeks.
![]()
Alternative sites are differentiated in whether data is available or not at each location. For example, a hot site has duplicate data or a near-ready backup of the original site. A cold site has no current or backup copies of the original site data. A warm site has backups, but they are typically several days or weeks old.
Table 21.2 compares hot, warm, and cold sites.
Table 21.2 Comparison of Hot, Warm, and Cold Sites

Shared alternate sites may also be considered. These sites can be designed to handle the needs of different organizations in the event of an emergency. The hope is that the disaster will affect only one organization at a time. The benefit of this method is that the cost of the site can be shared among organizations. Two similar organizations located close to each other should not share the same alternative site because there is a greater chance that they would both need it at the same time.
All of these options can come with a considerable price tag, which makes another option, mutual aid agreements, a possible alternative. With a mutual aid agreement, similar organizations agree to assume the processing for the other party in the event a disaster occurs. This is sometimes referred to as a reciprocal site. The obvious assumptions here are that both organizations will not be hit by the same disaster and both have similar processing environments. If these two assumptions are correct, then a mutual aid agreement should be considered. Such an arrangement may not be legally enforceable, even if it is in writing, and organizations must consider this when developing their disaster plans. In addition, if the organization that the mutual aid agreement is made with is hit by the same disaster, then both organizations will be in trouble. Additional contingencies need to be planned for, even if a mutual aid agreement is made with another organization. There are also the obvious security concerns that must be considered when having another organization assume your organization’s processing.
Order of Restoration
When restoring more than a single machine, you have multiple considerations in the order of restoration. Part of the planning is to decide on the order of restoration—in other words, which systems go first, second, and ultimately last. There are a couple of distinct factors to consider. First are dependencies. Any system that is dependent on another for proper operation might as well wait until the prerequisite services are up and running. The second factor is criticality to the enterprise. The most critical service should be brought back up first.
Utilities
The interruption of power is a common issue during a disaster. Computers and networks obviously require power to operate, so emergency power must be available in the event of any disruption of operations. For short-term interruptions, such as what might occur as the result of an electrical storm, uninterruptible power supplies (UPSs) may suffice. These devices contain a battery that provides steady power for short periods of time—enough to keep a system running should power be lost for only a few minutes and enough time to allow administrators to gracefully halt the system or network. For continued operations that extend beyond a few minutes, another source of power will be required. Generally this is provided by a backup emergency generator.
While backup generators are frequently used to provide power during an emergency, they are not a simple, maintenance-free solution. Generators need to be tested on a regular basis, and they can easily become strained if they are required to power too much equipment. If your organization is going to rely on an emergency generator for backup power, you must ensure that the system has reserve capacity beyond the anticipated load for the unanticipated loads that will undoubtedly be placed on it.
Generators also take time to start up, so power to your organization will most likely be lost, even if only briefly, until the generators kick in. This means you should also use a UPS to allow for a smooth transition to backup power. Generators are also expensive and require fuel. Be sure to locate the generator high if flooding is possible, and don’t forget the need to deliver fuel to it; otherwise, you may find yourself hauling cans of fuel up a number of stairs.
When determining the need for backup power, don’t forget to factor in environmental conditions. Running computer systems in a room with no air conditioning in the middle of the summer can result in an extremely uncomfortable environment for all to work in. Mobile backup sites, generally using trailers, often rely on generators for their power but also factor in the requirement for environmental controls.
Power is not the only essential utility for operations. Depending on the type of disaster that has occurred, telephone and Internet communication may also be lost, and wireless services may not be available. Planning for redundant means of communication (such as using both land lines and wireless) can help with most outages, but for large disasters, your backup plans should include the option to continue operations from a completely different location while waiting for communications in your area to be restored. Telecommunication carriers have their own emergency equipment and are fairly efficient at restoring communications, but it may take a few days.
Secure Recovery
Several companies offer recovery services, including power, communications, and technical support that your organization may need if its operations are disrupted. These companies advertise secure recovery sites or offices from which your organization can again begin to operate in a secure environment. Secure recovery is also advertised by other organizations that provide services that can remotely (over the Internet, for example) provide restoration services for critical files and data.
In both cases—the actual physical suites and the remote service—security is an important element. During a disaster, your data does not become any less important, and you will want to make sure you maintain the security (in terms of confidentiality and integrity, for example) of your data. As in other aspects of security, the decision to employ these services should be made based on a calculation of the benefits weighed against the potential loss if alternative means are used.
Continuity of Operations Planning (COOP)
Ensuring continuity of operations is a business imperative, as it has been shown that businesses that cannot quickly recover from a disruption have a real chance of never recovering and going out of business. The overall goal of continuity of operations planning (COOP) is to determine which subset of normal operations needs to be continued during periods of disruption. Continuity of operations planning involves developing a comprehensive plan to enact during a situation where normal operations are interrupted. This includes identifying critical assets (including key personnel), critical systems, and interdependencies as well as ensuring their availability during a disruption.
Developing a continuity of operations plan is a joint effort between the business and the IT team. The business understands which functions are critical for continuity of operations and which functions can be suspended. The IT team understands how this translates into equipment, data, and services and can establish the correct IT functions. Senior management will have to make the major decisions as to balancing risk versus cost versus criticality when examining hot, warm, or cold site strategies.
![]()
The COOP is focused on continuing business operations, whereas the BCP is focused on returning a business to functioning profitably, even if at a reduced level or capacity. Government agencies, where service is essential and costs can be dealt with later, focus on COOP, whereas many businesses have to focus on DRP and BCP.
Disaster Recovery
Many types of disasters, whether natural or caused by people, can disrupt your organization’s operations for some length of time. Such disasters are unlike threats that intentionally target your computer systems and networks, such as industrial espionage, hacking, attacks from disgruntled employees, and insider threats, because the events that cause the disruption are not specifically aimed at your organization. Although both disasters and intentional threats must be considered important in planning for disaster recovery, the purpose of this section is to focus on recovering from disasters.
How long your organization’s operations are disrupted depends in part on how prepared it is for a disaster and what plans are in place to mitigate the effects of a disaster. Any of the events in Table 21.3 could cause a disruption in operations.
Table 21.3 Common Causes of Disasters

Fortunately, these types of events do not happen frequently in any one location. It is more likely that business operations will be interrupted because of employee error (such as accidental corruption of a database or unplugging a system to plug in a vacuum cleaner—an event that has occurred at more than one organization). A good disaster recovery plan will prepare your organization for any type of organizational disruption.
![]()
Disasters can be caused by nature (for example, fires, earthquakes, and floods) or can be the result of some manmade event (such as war or a terrorist attack). The plans an organization develops to address a disaster need to recognize both of these possibilities. While many of the elements in a disaster recovery plan will be similar for both natural and manmade events, some differences might exist. For example, the most recent backup tapes available can be used to recover data after a natural disaster. If, on the other hand, the event was a loss of all data as a result of a computer virus that wiped your system, restoring from the most recent backup tapes might result in the reinfection of your system if the virus had been dormant for a planned period of time. In this case, recovery might entail restoring some files from earlier backups.
Disaster Recovery Plans/Process
No matter what event you are worried about—whether natural or manmade and whether targeted at your organization or more random—you can make preparations to lessen the impact on your organization and the length of time that your organization will be out of operation. A disaster recovery plan (DRP) is critical for effective disaster recovery efforts. A DRP defines the data and resources necessary and the steps required to restore critical organizational processes.
Consider what your organization needs to perform its mission. This information provides the beginning of a DRP since it tells you what needs to be quickly restored. When considering resources, don’t forget to include both the physical resources (such as computer hardware and software) and the personnel (the people who know how to run the systems that process your critical data).
To begin creating your DRP, first identify all critical functions for your organization and then answer the following questions for each of these critical functions:
![]() Who is responsible for the operation of this function?
Who is responsible for the operation of this function?
![]() What do these individuals need to perform the function?
What do these individuals need to perform the function?
![]() When should this function be accomplished relative to other functions?
When should this function be accomplished relative to other functions?
![]() Where will this function be performed?
Where will this function be performed?
![]() How is this function performed (what is the process)?
How is this function performed (what is the process)?
![]() Why is this function so important or critical to the organization?
Why is this function so important or critical to the organization?
By answering these questions, you can create an initial draft of your organization’s DRP. The name often used to describe the document created by addressing these questions is a business impact analysis (BIA). Both the disaster recovery plan and the business impact analysis, of course, will need to be approved by management, and it is essential that they buy into the plan—otherwise your efforts will more than likely fail. The old adage “Those who fail to plan, plan to fail” certainly applies in this situation.
![]()
The terms business impact assessment and business impact analysis are used interchangeably in the industry.
A good DRP must include the processes and procedures needed to restore your organization to proper functioning and to ensure continued operation. What specific steps will be required to restore operations? These processes should be documented and, where possible and feasible, reviewed and exercised on a periodic basis. Having a plan with step-by-step procedures that nobody knows how to follow does nothing to ensure the continued operation of the organization. Exercising your DRP and processes before a disaster occurs provides you with the opportunity to discover flaws or weaknesses in the plan when there is still time to modify and correct them. It also provides an opportunity for key figures in the plan to practice what they will be expected to accomplish.
![]()
It is often informative to determine what category your various business functions fall into. You may find that certain functions currently being conducted are not essential to your operations and could be eliminated. In this way, preparing for a security event may actually help you streamline your operational processes.
Categories of Business Functions
In developing your disaster recovery plan or the business impact analysis, you may find it useful to categorize the various functions your organization performs, such as shown in Table 21.4. This categorization is based on how critical or important the function is to your business operation and how long your organization can last without the function. Those functions that are the most critical will be restored first, and your DRP should reflect this. If the function doesn’t fall into any of the first four categories, then it is not really needed, and the organization should seriously consider whether it can be eliminated altogether.
Table 21.4 DRP Considerations

If a disaster has occurred and has destroyed all or part of your facility, the DRP portion of the business continuity plan will address the building or acquisition of a new facility. The DRP can also include details related to the long-term recovery of the organization.
![]()
The difference between a disaster recovery plan and business continuity plan is that the business continuity plan will be used to ensure that your operations continue in the face of whatever event has occurred that has caused a disruption in operations.
However you view these two plans, an organization that is not able to quickly restore business functions after an operational interruption is an organization that will most likely suffer an unrecoverable loss and may cease to exist.
IT Contingency Planning
Important parts of any organization today are the information technology (IT) processes and assets. Without computers and networks, most organizations could not operate. As a result, it is imperative that a business continuity plan include IT contingency planning. Because of the nature of the Internet and the threats that come from it, an organization’s IT assets will likely face some level of disruption before the organization suffers from a disruption due to a natural disaster. Events such as viruses, worms, computer intruders, and denial-of-service attacks could result in an organization losing part or all of its computing resources without warning. Consequently, the IT contingency plans are more likely to be needed than the other aspects of a business continuity plan. These plans should account for disruptions caused by any of the security threats discussed throughout this book as well as disasters or simple system failures.
Test, Exercise, and Rehearse
An organization should practice its DRP periodically. The time to find out whether it has flaws is not when an actual event occurs and the recovery of data and information means the continued existence of the organization. The DRP should be tested to ensure that it is sufficient and that all key individuals know their roles in the specific plan. The security plan determines whether the organization’s plan and the individuals involved perform as they should during a simulated security incident.
A test implies a “grade” will be applied to the outcome. Did the organization’s plan and the individuals involved perform as they should? Was the organization able to recover and continue to operate within the predefined tolerances set by management? If the answer is no, then during the follow-up evaluation of the exercise, the failures should be identified and addressed. Was it simply a matter of untrained or uninformed individuals, or was there a technological failure that necessitates a change in hardware, software, and procedures?
Whereas a test implies a “grade,” an exercise can be conducted without the stigma of a pass/fail grade being attached. Security exercises are conducted to provide the opportunity for all parties to practice the procedures that have been established to respond to a security incident. It is important to perform as many of the recovery functions as possible, without impacting ongoing operations, to ensure that the procedures and technologies will work in a real incident. You may want to periodically rehearse portions of the recovery plan, particularly those aspects that either are potentially more disruptive to actual operations or require more frequent practice because of their importance or degree of difficulty.
Additionally, there are different formats for exercises with varying degrees of impact on the organization. The most basic is a checklist walkthrough in which individuals go through a recovery checklist to ensure that they understand what to do should the plan be invoked and confirm that all necessary equipment (hardware and software) is available. This type of exercise normally does not reveal “holes” in a plan but will show where discrepancies exist in the preparation for the plan. To examine the completeness of a plan, a different type of exercise needs to be conducted. The simplest is a tabletop exercise in which participants sit around a table with a facilitator who supplies information related to the “incident” and the processes that are being examined. Another type of exercise is a functional test in which certain aspects of a plan are tested to see how well they work (and how well prepared personnel are). At the most extreme are full operational exercises designed to actually interrupt services in order to verify that all aspects of a plan are in place and sufficient to respond to the type of incident being simulated.
![]()
Exercises are an often-overlooked aspect of security. Many organizations do not believe that they have the time to spend on such events, but the question to ask is whether they can afford to not conduct these exercises, as they ensure the organization has a viable plan to recover from disasters and that operations can continue. Make sure you understand what is involved in these critical tests of your organization’s plans.
Tabletop Exercises
Exercising operational plans is an effort that can take on many different forms. For senior decision-makers, the point of action is more typically a desk or a conference room, with their method being meetings and decisions. A common form of exercising operational plans for senior management is the tabletop exercise. Members of the senior management team, or elements of it, are gathered together and presented a scenario. They can walk through their decision-making steps, communicate with others, and go through the motions of the exercise in the pattern in which they would likely be involved. The scenario is presented at a level to test the responsiveness of their decisions and decision-making process. Because the event is frequently run in a conference room, around a table, the name tabletop exercise has come to define this form of exercise.
Recovery Time Objective and Recovery Point Objective
The term recovery time objective (RTO) is used to describe the target time that is set for resuming operations after an incident. This is a period of time that is defined by the business, based on the needs of the enterprise. A shorter RTO results in higher costs because it requires greater coordination and resources. This term is commonly used in business continuity and disaster recovery operations.
Recovery point objective (RPO), a totally different concept from RTO, is the time period representing the maximum period of acceptable data loss. The RPO determines the frequency of backup operations necessary to prevent unacceptable levels of data loss. A simple example of establishing an RPO is to answer the following questions: How much data can you afford to lose? How much rework is tolerable?
RTP and RPO are seemingly related but in actuality measure different things entirely. The RTO serves the purpose of defining the requirements for business continuity, whereas the RPO deals with backup frequency. It is possible to have an RTO of 1 day and an RPO of 1 hour or to have an RTO of 1 hour and an RPO of 1 day. The determining factors are the needs of the business.
![]()
Although recovery time objective and recovery point objective seem to be the same or similar, they are very different. The RTO serves the purpose of defining the requirements for business continuity, whereas the RPO deals with backup frequency.
Why Change Management?
To manage the system development and maintenance processes effectively, you need discipline and structure to help conserve resources and enhance effectiveness. Change management, like risk management, is often considered expensive, nonproductive, unnecessary, and confusing—an impediment to progress. However, like risk management, change management can be scaled to control and manage the development and maintenance of systems effectively.
![]()
Cross Check
Risk Management and Change Management Are Essential Business Processes
Chapter 20 presented risk management as an essential decision-making process. In much the same way, change management is an essential practice for managing a system during its entire lifecycle, from development through deployment and operation, until it is taken out of service. What security-specific risk-based questions should be asked during change management reviews?
Change management should be used in all phases of a system’s life: development, testing, quality assurance (QA), and production. Short development cycles have not changed the need for an appropriate amount of management control over software development, maintenance, and operation. In fact, short turnaround times make change management more necessary, because once a system goes active in today’s services-based environments, it often cannot be taken offline to correct errors—it must stay up and online, or else business will be lost and brand recognition damaged. In today’s volatile stock market, for example, even small indicators of lagging performance can have dramatic impacts on a company’s stock value.
The following scenarios exemplify the need for appropriate change management policy and for procedures over software, hardware, and data:
![]() The developers can’t find the latest version of the production source code. Change management practices support versioning of software changes.
The developers can’t find the latest version of the production source code. Change management practices support versioning of software changes.
![]() A bug corrected a few months ago mysteriously reappears. Proper change management ensures developers always use the most recently changed source code.
A bug corrected a few months ago mysteriously reappears. Proper change management ensures developers always use the most recently changed source code.
![]() Fielded software was working fine yesterday but does not work properly today. Good change management controls have access to previously modified modules so that previously corrected errors aren’t reintroduced into the system.
Fielded software was working fine yesterday but does not work properly today. Good change management controls have access to previously modified modules so that previously corrected errors aren’t reintroduced into the system.
![]() Development team members overwrote each other’s changes. Today’s change management tools support collaborative development.
Development team members overwrote each other’s changes. Today’s change management tools support collaborative development.
![]() A programmer spent several hours changing the wrong version of the software. Change management tools support viable management of previous software versions.
A programmer spent several hours changing the wrong version of the software. Change management tools support viable management of previous software versions.
![]() New tax rates stored in a table have been overwritten with last year’s tax rates. Change control prevents inadvertent overwriting of critical reference data.
New tax rates stored in a table have been overwritten with last year’s tax rates. Change control prevents inadvertent overwriting of critical reference data.
![]() A network administrator inadvertently brought down a server because he incorrectly punched down the wrong wires. Just like a blueprint shows key electrical paths, data center connection paths can be version controlled.
A network administrator inadvertently brought down a server because he incorrectly punched down the wrong wires. Just like a blueprint shows key electrical paths, data center connection paths can be version controlled.
![]() A newly installed server is hacked soon after installation because it was improperly configured. Network and system administrators use change management to ensure configurations consistently meet security standards.
A newly installed server is hacked soon after installation because it was improperly configured. Network and system administrators use change management to ensure configurations consistently meet security standards.
Tech Tip
Types of Changes
The ITIL v3 Glossary of Terms, Definitions and Acronyms (www.axelos.com/glossaries-of-terms) defines the following types of changes (with examples added in parentheses):
![]() Change “The addition, modification or removal of anything that could have an effect on IT Services.” (For example, modification to a module to implement a new capability.)
Change “The addition, modification or removal of anything that could have an effect on IT Services.” (For example, modification to a module to implement a new capability.)
![]() Standard change “A preapproved change that is low risk, relatively common and follows a procedure or work instruction.” (For example, each month Finance must make a small rounding adjustment to reconcile the General Ledger to account for foreign currency calculations.)
Standard change “A preapproved change that is low risk, relatively common and follows a procedure or work instruction.” (For example, each month Finance must make a small rounding adjustment to reconcile the General Ledger to account for foreign currency calculations.)
![]() Emergency change “A change that must be introduced as soon as possible.” (For example, to resolve a major incident or implement a security patch. The change management process will normally have a specific procedure for handling emergency changes.)
Emergency change “A change that must be introduced as soon as possible.” (For example, to resolve a major incident or implement a security patch. The change management process will normally have a specific procedure for handling emergency changes.)
See www.axelos.com/best-practice-solutions/itil.aspxformoreinformation.
![]()
Try This!
Scope of Change Management
See if you can explain why each of the following should be placed under an appropriate change management process:
![]() Web pages
Web pages
![]() Service packs
Service packs
![]() Security patches
Security patches
![]() Third-party software releases
Third-party software releases
![]() Test data and test scripts
Test data and test scripts
![]() Parameter files
Parameter files
![]() Scripts, stored procedures, or job control language–type programs
Scripts, stored procedures, or job control language–type programs
![]() Customized vendor code
Customized vendor code
![]() Source code of any kind
Source code of any kind
![]() Applications
Applications
Just about anyone with more than a year’s experience in software development or system operations can relate to at least one of the preceding scenarios. However, each of these scenarios can be controlled, and impacts mitigated, through proper change management procedures.
The Sarbanes-Oxley Act of 2002, officially titled the Public Company Accounting Reform and Investor Protection Act of 2002, was enacted July 30, 2002, to help ensure management establishes viable governance environments and control structures to ensure accuracy of financial reporting. Section 404 outlines the requirements most applicable to information technology. Change management is an essential part of creating a viable governance and control structure and is critical to compliance with the Sarbanes-Oxley Act.
The Key Concept: Separation of Duties
A foundation for change management is the recognition that involving more than one individual in a process can reduce risk. Good business control practices require that duties be assigned to individuals in such a way that no one individual can control all phases of a process or the processing and recording of a transaction. This is called separation of duties (also called segregation of duties). It is an important means by which errors and fraudulent or malicious acts can be discouraged and prevented. Separation of duties can be applied in many organizational scenarios because it establishes a basis for accountability and control. Proper separation of duties can safeguard enterprise assets and protect against risks. The specific segregation of duties should be documented, monitored, and enforced.
A well-understood business example of separation of duties is in the management and payment of vendor invoices. If a person can create a vendor in the finance system, enter invoices for payment, and then authorize a payment check to be written, it is apparent that fraud could be perpetrated because the person could write a check to himself for services never performed. Separating duties by requiring one person to create the vendors and another person to enter invoices and write checks makes it more difficult for someone to defraud an employer.
Information technology (IT) organizations should design, implement, monitor, and enforce appropriate separation of duties for the enterprise’s information systems and processes. Today’s computer systems are rapidly evolving into an increasingly decentralized and networked computer infrastructure. In the absence of adequate IT controls, such rapid growth may allow exploitation of large amounts of enterprise information in a short time. Further, the knowledge of computer operations held by IT staff is significantly greater than that of an average user, and this knowledge could be abused for malicious purposes.
Some of the best practices for ensuring proper separation of duties in an IT organization are as follows:
![]() Separation of duties between development, testing, QA, and production should be documented in written procedures and implemented by software or manual processes.
Separation of duties between development, testing, QA, and production should be documented in written procedures and implemented by software or manual processes.
![]() The activities of program developers and program testers should be conducted on “test” data only. They should be restricted from accessing “live” production data. This will assist in ensuring an independent and objective testing environment without jeopardizing the confidentiality and integrity of production data.
The activities of program developers and program testers should be conducted on “test” data only. They should be restricted from accessing “live” production data. This will assist in ensuring an independent and objective testing environment without jeopardizing the confidentiality and integrity of production data.
![]() End users or computer operations personnel should not have direct access to program source code. This control helps lessen the opportunity of exploiting software weaknesses or introducing malicious code (or code that has not been properly tested) into the production environment either intentionally or unintentionally.
End users or computer operations personnel should not have direct access to program source code. This control helps lessen the opportunity of exploiting software weaknesses or introducing malicious code (or code that has not been properly tested) into the production environment either intentionally or unintentionally.
![]() Functions of creating, installing, and administrating software programs should be assigned to different individuals. For example, since developers create and enhance programs, they should not be able to install these programs on the production system. Likewise, database administrators should not be program developers on database systems they administer.
Functions of creating, installing, and administrating software programs should be assigned to different individuals. For example, since developers create and enhance programs, they should not be able to install these programs on the production system. Likewise, database administrators should not be program developers on database systems they administer.
![]() All accesses and privileges to systems, software, or data should be granted based on the principle of least privilege, which gives users no more privileges than are necessary to perform their jobs. Access privileges should be reviewed regularly to ensure that individuals who no longer require access have had their access removed.
All accesses and privileges to systems, software, or data should be granted based on the principle of least privilege, which gives users no more privileges than are necessary to perform their jobs. Access privileges should be reviewed regularly to ensure that individuals who no longer require access have had their access removed.
![]() Formal change management policy and procedures should be enforced throughout the enterprise. Any changes in hardware and software components (including emergency changes) that are implemented after the system has been placed into production must go through the approved formal change management mechanism.
Formal change management policy and procedures should be enforced throughout the enterprise. Any changes in hardware and software components (including emergency changes) that are implemented after the system has been placed into production must go through the approved formal change management mechanism.
Tech Tip
Steps to Implement Separation of Duties
1. Identify an indispensable function that is potentially subject to abuse.
2. Divide the function into separate steps, each containing a small part of the power that enables the function to be abused.
3. Assign each step to a different person or organization.
Managers at all levels should review existing and planned processes and systems to ensure proper separation of duties. Smaller business entities may not have the resources to implement all of the preceding practices fully, but other control mechanisms, including hiring qualified personnel, bonding contractors, and using training, monitoring, and evaluation practices, can reduce any organization’s exposure to risk. The establishment of such practices can ensure that enterprise assets are properly safeguarded and can also greatly reduce error and the potential for fraudulent or malicious activities.
Change management practices implement and enforce separation of duties by adding structure and management oversight to the software development and system operation processes. Change management techniques can ensure that only correct and authorized changes, as approved by management or other authorities, are allowed to be made, following a defined process.
Elements of Change Management
Change management has its roots in system engineering, where it is commonly referred to as configuration management. Most of today’s software and hardware change management practices derive from long-standing system engineering configuration management practices. Computer hardware and software development have evolved to the point that proper management structure and controls must exist to ensure the products operate as planned. Issues such as the Heartbleed and Shellshock incidents, as detailed in Chapter 15, illustrate the need to understand configurations and change.
Change management and configuration management use different terms for their various phases, but they all fit into the four general phases defined under configuration management:
![]() Configuration identification
Configuration identification
![]() Configuration control
Configuration control
![]() Configuration status accounting
Configuration status accounting
![]() Configuration auditing
Configuration auditing
Tech Tip
Change Management
The ITIL v3 Glossary defines change management as “The process responsible for controlling the lifecycle of all changes. The primary objective of change management is to enable beneficial changes to be made, with minimum disruption to IT services.” See www.axelos.com/glossaries-of-terms.
Configuration identification is the process of identifying which assets need to be managed and controlled. These assets could be software modules, test cases or scripts, table or parameter values, servers, major subsystems, or entire systems. The idea is that, depending on the size and complexity of the system, an appropriate set of data and software (or other assets) must be identified and properly managed. These identified assets are called configuration items or computer software configuration items.
Related to configuration identification, and the result of it, is the definition of a baseline. A baseline serves as a foundation for comparison or measurement. It provides the necessary visibility to control change. For example, a software baseline defines the software system as it is built and running at a point in time. As another example, network security best practices clearly state that any large organization should build its servers to a standard build configuration to enhance overall network security. The servers are the configuration items, and the standard build is the server baseline.
Configuration control is the process of controlling changes to items that have been baselined. Configuration control ensures that only approved changes to a baseline are allowed to be implemented. It is easy to understand why a software system, such as a web-based order entry system, should not be changed without proper testing and control—otherwise, the system might stop functioning at a critical time. Configuration control is a key step that provides valuable insight to managers. If a system is being changed, and configuration control is being observed, managers and others concerned will be better informed. This ensures proper use of assets and avoids unnecessary downtime due to the installation of unapproved changes.
![]()
Large enterprise application systems require viable change management systems. For example, SAP has its own change management system called the Transport Management System (TMS). Third-party software such as Phire Architect (https://phireinc.com/) and Stat for PeopleSoft (www.quest.com/products/stat-peoplesoft/) provide change management applications for Oracle’s PeopleSoft and E-Business Suite.
Configuration status accounting consists of the procedures for tracking and maintaining data relative to each configuration item in the baseline. It is closely related to configuration control. Status accounting involves gathering and maintaining information relative to each configuration item. For example, it documents what changes have been requested; what changes have been made, when, and for what reason; who authorized those changes; who performed the changes; and what other configuration items or systems were affected by the changes.

It is important that you understand that even though all servers may be initially configured to the same baseline, individual applications might require a system-specific configuration to run properly. Change management actually facilitates system-specific configuration in that all exceptions from the standard configuration are documented. All people involved in managing and operating these systems will have documentation to help them quickly understand why a particular system is configured in a unique way.
Returning to our example of servers being baselined, if the operating system of those servers is found to have a security flaw, then the baseline can be consulted to determine which servers are vulnerable to this particular security flaw. Those systems with this weakness can be updated (and only those that need to be updated). Configuration control and configuration status accounting help ensure that systems are more consistently managed and, ultimately in this case, the organization’s network security is maintained. It is easy to imagine the state of an organization that has not built all servers to a common baseline and has not properly controlled its systems’ configurations. It would be very difficult to know the configuration of individual servers, and security could quickly become weak.
Configuration auditing is the process of verifying that the configuration items are built and maintained according to the requirements, standards, or contractual agreements. It is similar to how audits in the financial world are used to ensure that generally accepted accounting principles and practices are adhered to and that financial statements properly reflect the financial status of the enterprise. Configuration audits ensure that policies and procedures are being followed, that all configuration items (including hardware and software) are being properly maintained, and that existing documentation accurately reflects the status of the systems in operation.
Configuration auditing takes on two forms: functional and physical. A functional configuration audit verifies that the configuration item performs as defined by the documentation of the system requirements. A physical configuration audit confirms that all configuration items to be included in a release, install, change, or upgrade are actually included, and that no additional items are included—no more, no less.
Implementing Change Management
Change management requires some structure and discipline in order to be effective. The change management function is scalable from small to enterprise-level projects. Figure 21.1 illustrates a sample software change management flow appropriate for medium to large projects. It can be adapted to small organizations by having the developer perform work only on their workstation (never on the production system) and having the system administrator serve in the buildmaster function. The buildmaster is usually an independent person responsible for compiling and incorporating changed software into an executable image.
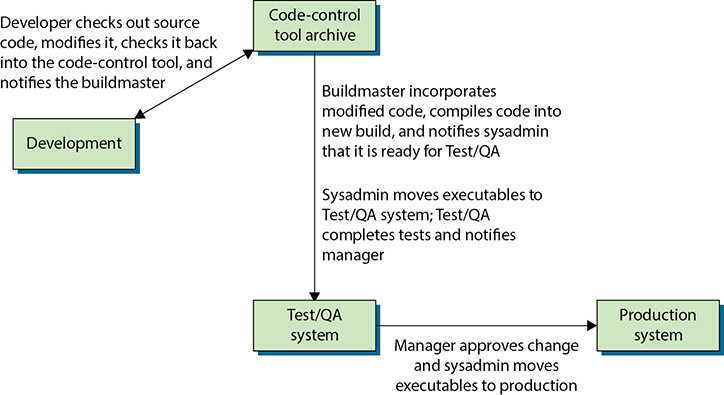
• Figure 21.1 Software change control workflow
Tech Tip
Release Management
The ITIL v3 Glossary defines release management as “The process responsible for planning, scheduling and controlling the movement of releases to test and live environments. The primary objective of release management is to ensure that the integrity of the live environment is protected and that the correct components are released.” See www.axelos.com/glossaries-of-terms.
Figure 21.1 shows that developers never have access to the production system or data. It also demonstrates proper separation of duties between developers, QA and test personnel, and production. It implies that a distinct separation exists between the development, testing and QA, and production environments. This workflow is for changes that have a major impact on production or the customer’s business process. For minor changes that have minimal risk or impact on business processes, some of the steps may be omitted.
The change management workflow proceeds as follows:
1. The developer checks out source code from the code-control tool archive to the development system.
2. The developer modifies the code and conducts unit testing of the changed modules.
3. The developer checks the modified code into the code-control tool archive.
4. The developer notifies the buildmaster that changes are ready for a new build and testing/QA.
5. The buildmaster creates a build incorporating the modified code and compiles the code.
6. The buildmaster notifies the system administrator that the executable image is ready for testing/QA.
7. The system administrator moves the executables to the test/QA system.
8. QA tests the new executables. If the tests are passed, test/QA notifies the manager. If tests fail, the process starts over.
9. Upon manager approval, the system administrator moves the executable to the production system.
Tech Tip
Identifying Separation of Duties
Using Figure 21.1, observe the separation of duties between development, test/QA, and production. The functions of creating, installing, and administrating are assigned to different individuals. Note also appropriate management review and approval. This implementation also ensures that no compiler is necessary on the production system. Indeed, compilers should not be allowed to exist on the production system.
Backout Plan
One of the key elements of a change plan is a comprehensive backout plan. If, in the course of a planned change activity in production, a problem occurs that prevents going forward, it is essential to have a backout plan to restore the system to its previous operating condition. A common element in many operating system updates is the inability to go back to a previous version. This is fine provided that the update goes perfectly, but if for some reason it fails, what then? For a personal device, there may be some inconvenience. For a server in production, this can have significant business implications. The ultimate in backout plans is the restoration of a complete backup of the system. Backups can be time consuming and difficult in some environments, but the spread of virtualization into the enterprise provides many more options in configuration management and backout plans.
The Purpose of a Change Control Board
To oversee the change management process, most organizations establish a change control board (CCB). In practice, a CCB not only facilitates adequate management oversight but also facilitates better coordination between projects. The CCB convenes on a regular basis, usually weekly or monthly, and can meet on an emergency or as-needed basis as well. Figure 21.2 shows the process for implementing and properly controlling hardware or software during changes. The CCB uses standard documents, such as change requests, in concert with business schedules and other elements of operational data, with a focus on system stability. The CCB also ensures that all elements of the change policy have been complied with before approving changes to production systems.

• Figure 21.2 Change control board process
The CCB’s membership should consist of development project managers, network administrators, system administrators, test/QA managers, an information security manager, an operations center manager, and a help desk manager. Others can be added as necessary, depending on the size and complexity of the organization.
Tech Tip
Incident Management
The ITIL v3 Glossary defines incident management as “The process responsible for managing the lifecycle of all incidents. The primary objective of incident management is to return the IT service to users as quickly as possible.”
A system problem report (SPR) is used to track changes through the CCB. The SPR documents changes or corrections to a system. It reflects who requested the change and why, what analysis must be done and by whom, and how the change was corrected or implemented. Figure 21.3 shows a sample SPR. Most large enterprises cannot rely on a paper-based SPR process and instead use one of the many software systems available to perform change management functions. Although this example shows a paper-based SPR, it contains all the elements of change management: it describes the problem and who reported it, it outlines resolution of the problem, and it documents approval of the change.

• Figure 21.3 Sample system problem report
Figure 21.4 shows the entire change management process and its relationship to incident management and release management.
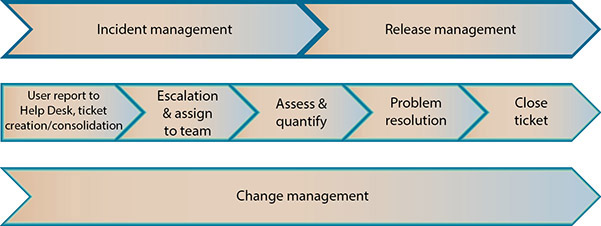
• Figure 21.4 Change, incident, and release management
Code Integrity
One key benefit of adequate change management is the assurance of code consistency and integrity. Whenever a modified program is moved to the production source-code library, the executable version should also be moved to the production system. Automated change management systems greatly simplify this process and are therefore better controls for ensuring executable and source-code integrity. Remember that at no time should the user or application developer have access to production source and executable code libraries in the production environment.
Finally, in today’s networked environment, the integrity of the executable code is critical. A common hacking technique is to replace key system executable code with modified code that contains backdoors, allowing unauthorized access or functions to be performed. Executable code integrity can be verified using host-based intrusion detection systems (HIDSs). These systems create and maintain a database of the size and content of executable modules. Conceptually, this is usually done by performing some kind of hashing or sophisticated checksum operation on the executable modules and storing the results in a database. The operation is performed on a regular schedule against the executable modules, and the results are compared to the database to identify any unauthorized changes that may have occurred to the executable modules.
The Capability Maturity Model Integration
An important set of process models is the Capability Maturity Model Integration (CMMI) series developed at Carnegie Mellon University’s Software Engineering Institute (SEI). SEI has created three capability maturity model integrations that replace the older Capability Maturity Model (CMM): the Capability Maturity Model Integration for Acquisition (CMMI-ACQ), the Capability Maturity Model Integration for Development (CMMI-DEV), and the Capability Maturity Model Integration for Services (CMMI-SVC). CMMI-DEV is representative of the three models. One of the fundamental concepts of CMMI-DEV is configuration or change management, which provides organizations with the ability to improve their software and other processes by providing an evolutionary path from ad hoc processes to disciplined management processes.
The CMMI-DEV defines five maturity levels:
![]() Level 1: Initial At maturity level 1, processes are generally ad hoc and chaotic. The organization does not provide a stable environment to support processes.
Level 1: Initial At maturity level 1, processes are generally ad hoc and chaotic. The organization does not provide a stable environment to support processes.
![]() Level 2: Managed At maturity level 2, processes are planned and executed in accordance with policy. The projects employ skilled people who have adequate resources to produce controlled outputs; involve relevant stakeholders; are monitored, controlled, and reviewed; and are evaluated for adherence to their process descriptions.
Level 2: Managed At maturity level 2, processes are planned and executed in accordance with policy. The projects employ skilled people who have adequate resources to produce controlled outputs; involve relevant stakeholders; are monitored, controlled, and reviewed; and are evaluated for adherence to their process descriptions.
![]() Level 3: Defined At maturity level 3, processes are well characterized and understood, and they are described in standards, procedures, tools, and methods. These standard processes are used to establish consistency across the organization.
Level 3: Defined At maturity level 3, processes are well characterized and understood, and they are described in standards, procedures, tools, and methods. These standard processes are used to establish consistency across the organization.
![]() Level 4: Quantitatively Managed At maturity level 4, the organization establishes quantitative objectives for quality and process performance and uses them as criteria in managing projects. Quantitative objectives are based on the needs of the customer, end users, organization, and process implementers. Quality and process performance is understood in statistical terms and is managed throughout the life of projects.
Level 4: Quantitatively Managed At maturity level 4, the organization establishes quantitative objectives for quality and process performance and uses them as criteria in managing projects. Quantitative objectives are based on the needs of the customer, end users, organization, and process implementers. Quality and process performance is understood in statistical terms and is managed throughout the life of projects.
![]() Level 5: Optimizing At maturity level 5, an organization continually improves its processes based on a quantitative understanding of its business objectives and performance needs. The organization uses a quantitative approach to understanding the variation inherent in the process and the causes of process outcomes.
Level 5: Optimizing At maturity level 5, an organization continually improves its processes based on a quantitative understanding of its business objectives and performance needs. The organization uses a quantitative approach to understanding the variation inherent in the process and the causes of process outcomes.
Change management is a key process to implementing the CMMI-DEV in an organization. For example, if an organization is at CMMI-DEV level 1, it probably has minimal formal change management processes in place. At level 3, an organization has a defined change management process that is followed consistently. At level 5, the change management process is a routine, quantitatively evaluated part of improving software products and implementing innovative ideas across the organization. For an organization to manage software development, operation, and maintenance, it should have effective change management processes in place.
Change management is an essential management tool and control mechanism. The concept of segregation of duties ensures that no single individual or organization possesses too much control in a process, thus helping to prevent errors and fraudulent or malicious acts. The elements of change management—configuration identification, configuration control, configuration status accounting, and configuration auditing—coupled with a defined process and a change control board, will provide management with proper oversight of the software lifecycle. Once such a process and management oversight exist, the company can use CMMI-DEV to move from ad hoc activities to a disciplined software management process.
Environment
Within a modern environment, there are multiple, separate environments designed to isolate the functions of development, test, and production. These are primarily to prevent accidents arising from untested code ending up in production. These environments are segregated by access control list as well as hardware, preventing users from accessing multiple different levels of the environment. For moving the code between environments, special accounts that can access both are used, thus eliminating issues of crosstalk.
Development
The development system is one that is sized, configured, and set up for developers to develop applications and systems. The development hardware does not have to scale like production, and it probably does not need to be as responsive for given transactions. The development platform does need to be of the same type of system, because developing on Windows and then deploying to Linux is fraught with difficulties that can be avoided by matching development environments to production in terms of OS type and version. After code is successfully developed, it is moved to a test system.
Test
The test environment is one that fairly closely mimics the production environment, with the same versions of software, down to patch levels, and the same sets of permissions, file structures, and so on. The purpose of the test environment is to enable a system to be fully tested prior to being deployed into production. The test environment may not scale like production, but from the perspective of the software/hardware footprint, it will look exactly like production.
Staging
The staging environment is an optional environment, but it is commonly found when there are multiple production environments. After passing testing, the system moves into staging, from where it can be deployed to the different production systems. The primary purpose of staging is as a sandbox after testing so the test system can test the next set while the current set is deployed across the enterprise. One method of deployment is a staged deployment, where software is deployed to part of the enterprise and then the process is paused to watch for unforeseen problems. If none occur, the deployment process continues, stage by stage, until all of the production systems are changed. By moving software in this manner, you never lose the old production system until the end of the move, giving you time to judge and catch any unforeseen problems. This also prevents the total loss of production to a failed update.
Production
Production is the environment where the systems work with real data, doing the business that the system is supposed to perform. This is an environment where there are by design virtually no changes, except as approved and tested via the system’s change management process.
Secure Baseline
To secure the software on a system effectively and consistently, you must take a structured and logical approach. This starts with an examination of the system’s intended functions and capabilities to determine what processes and applications will be housed on the system. As a best practice, anything that is not required for operations should be removed or disabled on the system; then, all the appropriate patches, hotfixes, and settings should be applied to protect and secure it. This becomes the system’s secure baseline.
This process of establishing software’s base security state is called baselining, and the resulting product is a security baseline that allows the software to run safely and securely. Software and hardware can be tied integrally when it comes to security, so they must be considered together. Once the process has been completed for a particular hardware and software combination, any similar systems can be configured with the same baseline to achieve the same level and depth of security and protection. Uniform software baselines are critical in large-scale operations, because maintaining separate configurations and security levels for hundreds or thousands of systems is far too costly.
After administrators have finished patching, securing, and preparing a system, they often create an initial baseline configuration. This represents a secure state for the system or network device and a reference point for the software and its configuration. This information establishes a reference that can be used to help keep the system secure by establishing a known-safe configuration. If this initial baseline can be replicated, it can also be used as a template when similar systems and network devices are deployed.
Sandboxing
Sandboxing refers to the quarantine or isolation of a system from its surroundings. It has become standard practice for some programs with an increased risk surface to operate within a sandbox, limiting the interaction with the CPU and other processes such as memory. This works as a means of quarantine, preventing problems from getting out of the sandbox and onto the OS and other applications on a system.
Virtualization can be used as a form of sandboxing with respect to an entire system. You can build a VM, test something inside the VM, and, based on the results, make a decision with regard to stability or whatever concern was present.
Integrity Measurement
Integrity measurement is the measuring and identification of changes to a specific system away from an expected value. From the simple changing of data as measured by a hash value to the TPM-based integrity measurement of the system boot process and attestation of trust, the concept is the same. Take a known value, perform a storage of a hash or other keyed value, and then at the time of concern, recalculate and compare the two values.
In the case of a TPM-mediated system, where the Trusted Platform Module (TPM) chip provides a hardware-based root of trust anchor, the system is specifically designed to calculate hashes of a system and store them in a Platform Configuration Register (PRC). This register can be read later and compared to a known, or expected, value, and if they differ, there is a trust violation. Certain BIOSs, UEFIs, and boot loaders can all work with the TPM chip in this manner, providing a means of establishing a trust chain during system boot.
Chapter 21 Review
 Chapter Summary
Chapter Summary
After reading this chapter and completing the exercises, you should understand the following about change management.
Operational disruptions can and will occur in systems
![]() A business continuity plan (BCP) involves planning and advanced policy decisions to ensure the business continuity objectives are achieved during a time of disruption.
A business continuity plan (BCP) involves planning and advanced policy decisions to ensure the business continuity objectives are achieved during a time of disruption.
![]() Continuity of operations planning (COOP) involves the steps taken to determine which subset of normal operations needs to be continued during periods of disruption.
Continuity of operations planning (COOP) involves the steps taken to determine which subset of normal operations needs to be continued during periods of disruption.
![]() The disaster recovery plan (DRP) defines the data and resources necessary and the steps required to restore critical organizational processes.
The disaster recovery plan (DRP) defines the data and resources necessary and the steps required to restore critical organizational processes.
Describe the various ways backups are conducted and stored
![]() Backups should include not only the organization’s critical data but critical software as well.
Backups should include not only the organization’s critical data but critical software as well.
![]() Backups may be conducted by backing up all files (full backup), only the files that have changed since the last full backup (differential backup), only the files that have changed since the last full or differential backup (incremental backup), or only the portion of the files that has changed since the last delta or full backup (delta backup).
Backups may be conducted by backing up all files (full backup), only the files that have changed since the last full backup (differential backup), only the files that have changed since the last full or differential backup (incremental backup), or only the portion of the files that has changed since the last delta or full backup (delta backup).
![]() Backups should be stored onsite for quick access, if needed, as well as offsite in case a disaster destroys the primary facility, its processing equipment, and the backups that are stored onsite.
Backups should be stored onsite for quick access, if needed, as well as offsite in case a disaster destroys the primary facility, its processing equipment, and the backups that are stored onsite.
Use change management as an important enterprise management tool
![]() Change management should be used in all phases of the software lifecycle.
Change management should be used in all phases of the software lifecycle.
![]() Change management can be scaled to effectively control and manage software development and maintenance.
Change management can be scaled to effectively control and manage software development and maintenance.
![]() Change management can prevent some of the most common software development and maintenance problems.
Change management can prevent some of the most common software development and maintenance problems.
Institute the key concept of separation of duties
![]() Separation of duties ensures that no single individual or organization possesses too much control in a process.
Separation of duties ensures that no single individual or organization possesses too much control in a process.
![]() Separation of duties helps prevent errors and fraudulent or malicious acts.
Separation of duties helps prevent errors and fraudulent or malicious acts.
![]() Separation of duties establishes a basis for accountability and control.
Separation of duties establishes a basis for accountability and control.
![]() Separation of duties can help safeguard enterprise assets and protect against risks.
Separation of duties can help safeguard enterprise assets and protect against risks.
Identify the essential elements of change management
![]() Configuration identification identifies assets that need to be controlled.
Configuration identification identifies assets that need to be controlled.
![]() Configuration control keeps track of changes to configuration items that have been baselined.
Configuration control keeps track of changes to configuration items that have been baselined.
![]() Configuration status accounting tracks each configuration item in the baseline.
Configuration status accounting tracks each configuration item in the baseline.
![]() Configuration auditing verifies that the configuration items are built and maintained appropriately.
Configuration auditing verifies that the configuration items are built and maintained appropriately.
Implement change management
![]() A standardized process and a change control board provide management with proper oversight and control of the software development lifecycle.
A standardized process and a change control board provide management with proper oversight and control of the software development lifecycle.
![]() A good change management process will exhibit good separation of duties and have clearly defined roles, responsibilities, and approvals.
A good change management process will exhibit good separation of duties and have clearly defined roles, responsibilities, and approvals.
![]() An effective change control board facilitates good management oversight and coordination between projects.
An effective change control board facilitates good management oversight and coordination between projects.
Use the concepts of the Capability Maturity Model Integration
![]() Once proper management oversight exists, the company will be able to use CMMI in order to move from ad hoc activities to a disciplined software management process.
Once proper management oversight exists, the company will be able to use CMMI in order to move from ad hoc activities to a disciplined software management process.
![]() CMMI relies heavily on change management to provide organizations with the capability to improve their software processes.
CMMI relies heavily on change management to provide organizations with the capability to improve their software processes.
Implement secure systems design for a given scenario
![]() Examine the environments of development, test, staging, and production and how they are used to build out secure environments.
Examine the environments of development, test, staging, and production and how they are used to build out secure environments.
![]() Sandboxing is a means of separating a system from the surrounding environment.
Sandboxing is a means of separating a system from the surrounding environment.
Key Terms
backout plan (824)
baseline (821)
business continuity plan (BCP) (801)
business impact analysis (BIA) (802)
Capability Maturity Model Integration (CMMI) (826)
change control board (CCB) (824)
change management (801)
cold site (811)
computer software configuration items (821)
configuration auditing (822)
configuration control (822)
configuration identification (821)
configuration items (821)
configuration management (801)
configuration status accounting (822)
continuity of operations planning (COOP) (813)
delta backup (806)
differential backup (805)
disaster recovery plan (DRP) (814)
full backup (805)
hot site (810)
mutual aid agreement (811)
recovery point objective (RPO) (817)
recovery time objective (RTO) (817)
separation of duties (819)
system problem report (SPR) (825)
warm site (811)
Key Terms Quiz
Use terms from the Key Terms list to complete the sentences that follow. Don’t use the same term more than once. Not all terms will be used.
1. _______________ is the maximum period of time in terms of data loss that is acceptable during an outage.
2. A _______________ is a partially configured backup processing facility that usually has the peripherals and software but perhaps not the more expensive main processing computer.
3. _______________ is the process of assigning responsibilities to different individuals such that no single individual can commit fraudulent or malicious actions.
4. Determining what data and processes are needed to restore critical processes is called a _______________.
5. A _______________ describes a system as it is built and functioning at a point in time.
6. A backup that includes only the files that have changed since the last full backup was completed is called a _______________.
7. The process of verifying that configuration items are built and maintained according to requirements, standards, or contractual agreements is called a _______________.
8. The document used by the change control board to track changes to software is called a _______________.
9. When you identify which assets need to be managed and controlled, you are performing _______________.
10. _______________ is the process of controlling changes to items that have been baselined.
Multiple-Choice Quiz
1. Why should developers and testers avoid using “live” production data to perform various testing activities?
A. The use of “live” production data ensures a full and realistic test database.
B. The use of “live” production data can jeopardize the confidentiality and integrity of the production data.
C. The use of “live” production data ensures an independent and objective test environment.
D. Developers and testers should be allowed to use “live” production data for reasons of efficiency.
2. What is the purpose of establishing software change management procedures?
A. To ensure continuity of business operations in the event of a natural disaster
B. To add structure and control to the development of software systems
C. To ensure changes in business operations caused by a management restructuring are properly controlled
D. To identify threats, vulnerabilities, and mitigating actions that could impact an enterprise
3. A good backup plan will include which of the following?
A. The critical data needed for the organization to operate
B. Any software that is required to process the organization’s data
C. Specific hardware to run the software or to process the data
D. All of the above
4. Which of the following does not adhere to the principle of separation of duties?
A. Software development, testing, quality assurance, and production should be assigned to the same individuals.
B. Software developers should not have access to production data and source-code files.
C. Software developers and testers should be restricted from accessing “live” production data.
D. The functions of creating, installing, and administrating software programs should be assigned to different individuals.
5. What is configuration auditing?
A. The process of controlling changes to items that have been baselined
B. The process of identifying which assets need to be managed and controlled
C. The process of verifying that the configuration items are built and maintained properly
D. The procedures for tracking and maintaining data relative to each configuration item in the baseline
6. In which backup strategy are only those portions of the files and software that have changed since the last backup backed up?
A. Full
B. Differential
C. Incremental
D. Delta
7. What is configuration control?
A. The process of controlling changes to items that have been baselined
B. The process of identifying which assets need to be managed and controlled
C. The process of verifying that the configuration items are built and maintained properly
D. The procedures for tracking and maintaining data relative to each configuration item in the baseline
8. What is configuration identification?
A. The process of verifying that the configuration items are built and maintained properly
B. The procedure for tracking and maintaining data relative to each configuration item in the baseline
C. The process of controlling changes to items that have been baselined
D. The process of identifying which assets need to be managed and controlled
9. Which of the following is the name for a partially configured environment that has the peripherals and software that the normal processing facility contains and that can be operational within a few days?
A. Hot site
B. Warm site
C. Online storage system
D. Backup storage facility
10. What is the purpose of a change control board (CCB)?
A. To facilitate management oversight and better project coordination
B. To identify which assets need to be managed and controlled
C. To establish software processes that are structured enough that success with one project can be repeated for another similar project
D. To track and maintain data relative to each configuration item in the baseline
Essay Quiz
1. Write a paragraph outlining the differences between a disaster recovery plan and a business continuity plan. Is one more important than the other?
2. Write a brief description of the different backup strategies. Include a discussion of which of these strategies requires the greatest amount of storage space to conduct and which of the strategies involves the most complicated restoration scheme.
3. Explain why the change management principles discussed in this chapter should be used when managing operating system patches.
Lab Projects
• Lab Project 21.1
Using a typical IT organization from a medium-sized company (100 developers, managers, and support personnel), describe the purpose, organization, and responsibilities of a change control board appropriate for this organization.
• Lab Project 21.2
You are the IT staff auditor for the company mentioned in the first lab project. You have reviewed the change control board processes and found they have instituted the following change management process. Describe two major control weaknesses in this particular change management process. What would you do to correct these control weaknesses?