
CHAPTER 9
Performance Tuning
In this chapter, you will learn about
• Host resource allocation
• Guest resource allocation
• Optimizing performance
• Common performance issues
Appropriately distributing compute resources is one of the most important aspects of a virtualized cloud environment. Planning for future growth and the ability to adjust compute resources on demand is one of the many benefits of a virtualized environment. This chapter explains how to configure compute resources on a host computer and a guest VM and how to optimize the performance of a virtualized environment.
Host Resource Allocation
Building a virtualization host requires careful consideration and planning. First, you must identify which resources the host requires and plan how to distribute those resources to a VM. Next, you must plan the configuration of the guest VM that the host computer will serve.
You must attend to the configuration of resources and the licensing of the host in the process of moving to a virtualized environment or virtual cloud environment. This consists of the following:
• Compute resources
• Quotas and limits
• Licensing
• Reservations
• Resource pools
Compute Resources
Adequate compute resources are key to the successful operation of a virtualization host. Proper planning of the compute resources for the host computer ensures that the host can deliver the performance needed to support the virtualization environment.
Compute resources can best be defined as the resources that are required for the delivery of VMs. They are the disk, processor, memory, and networking resources that are shared across pools of VMs and underpin their ability to deliver the value of the cloud models, as covered in Chapter 1.
As a host is a physical entity, the compute resources that the host utilizes are naturally physical, too. However, cloud providers may allocate a subset of their available physical resources to cloud consumers to allocate to their own VMs. Compute resources are displayed in Figure 9-1.

Figure 9-1 Host compute resources: processor, disk, memory, and network
For disk resources, physical rotational disks and solid state hard drives are utilized, as well as their controller cards, disk arrays, host bus adapters, and networked storage transmission media. For network resources, network interface cards (NICs) and physical transmission media such as Ethernet cables are employed. Central processing units (CPUs) are employed for the processor, and physical banks of RAM are used to supply memory.
Quotas and Limits
Because compute resources are limited, cloud providers must protect them and make certain that their customers only have access to the amount that the cloud providers are contracted to provide. Two methods used to deliver no more than the contracted amount of resources are quotas and limits.
Limits are a defined floor or ceiling on the amount of resources that can be used, and quotas are limits that are defined for a system on the total amount of resources that can be utilized. When defining limits on host resources, cloud providers have the option of setting a soft or hard limit. A soft limit will allow the user to save a file even if the drive reaches 100GB, but will still log an alert and notify the user. A hard limit, on the other hand, is the maximum amount of resources that can be utilized. For example, a hard limit of 100GB for a storage partition will not allow anything to be added to that partition once it reaches 100GB, and the system will log an event to note the occurrence and notify the user.
The quotas that are typically defined for host systems have to do with the allocation of the host compute resources to the host’s guest machines. These quotas are established according to service level agreements (SLAs) that are created between the cloud provider and cloud consumers to indicate a specific level of capacity.
Capacity management is essentially the practice of allocating the correct amount of resources in order to deliver a business service. The resources that these quotas enforce limits upon may be physical disks, disk arrays, host bus adapters, RAM chips, physical processors, and network adapters. They are allocated from the total pool of resources available to individual guests based on their SLA.
Quotas and limits on hosts can be compared to speed limits on the highway; very often, there are both minimum and maximum speeds defined for all traffic on the roads. A quota can be defined as the top speed, and a limit can be defined as the slowest speed for all vehicles using that road’s resources.
Licensing
After designing the host computer’s resources and storage limits, an organization or cloud provider needs to identify which vendor it will use for its virtualization software. Each virtualization software vendor has its own way of licensing products. Some of them have a free version of their product and only require a license for advanced feature sets that enable functionality, like high availability, performance optimization, and systems management. Others offer an utterly free virtualization platform but might not offer some of the more advanced features with their product.
Choosing the virtualization platform is a critical step, and licensing is a factor in that decision. Before deploying a virtualization host and choosing a virtualization vendor, the organization must be sure to read the license agreements and determine exactly which features it needs and how those features are licensed. In addition to licensing the virtualization host, the guest requires a software license.
Reservations
Reservations work similarly to quotas. Whereas quotas are designed to ensure the correct capacity gets delivered to customers by defining an upper limit for resource usage, reservations are designed to operate at the other end of the capacity spectrum by ensuring that a lower limit is enforced for the amount of resources guaranteed to a cloud consumer for their guest VM or machines.
A reservation for host resources is important to understand because it ensures certain VMs always have a defined baseline level of resources available to them regardless of the demands placed on them by other VMs. The reason these guest reservations are so important is that they enable cloud service providers to deliver against their SLAs.

CAUTION Reserving resources makes them unavailable to other machines and may result in less efficient utilization of resources.
Resource Pools
Resource pools are slices or portions of overall compute resources on the host or those allocated from the cloud provider to consumers. These pools include CPU, memory, and storage, and they can be provided from a single host or a cluster of hosts. Resources can be partitioned off in resource pools to provide different levels of resources to specific groups or organizations, and they can be nested within a hierarchy for organizational alignment.
Resource pools provide a flexible mechanism with which to organize the sum total of the compute resources in a virtual environment and link them back to their underlying physical resources.
Guest Resource Allocation
Before creating a guest VM, an organization needs to consider several factors. A guest VM should be configured based on the intended application or task that the guest will support. For example, a guest running a database server may require special performance considerations, such as more CPUs or memory based on the VM’s designated role and the overall system load. In addition to CPUs and memory, a guest may require higher-priority access to certain storage or disk types.
An organization must consider not only the role of the VM, the load of the machine, and the number of clients it is intended to support but also the performance of ongoing monitoring and assessment based on these factors. The amount of disk space the guest is using should be monitored and considered when deploying and maintaining storage.
The allocation of resources to VMs must be attended to in the process of moving to a virtualized environment or virtual cloud environment because the organization will either be allocating these resources from its available host resources or paying for them from a cloud provider. Organizations should evaluate each of the following resources:
• Compute resources
• Quotas and limits
• Licensing
• Physical resource redirection
• Resource pools
• Dynamic resource allocation
Compute Resources
The compute resources for VMs enable service delivery in the same way that compute resources for hosts do. However, the resources themselves are different in that they are virtualized components instead of physical components that can be held in your hand or plugged into a motherboard.
Guest compute resources are still made up of disk, network, processor, and memory components, but these components are made available to VMs not as physical resources but as abstractions of physical components presented by a hypervisor that emulates those physical resources for the VM.
Physical hosts have a Basic Input/Output System (BIOS) that presents physical compute resources to a host so they can be utilized to provide computing services, such as running an operating system and its component software applications. With VMs, the BIOS is emulated by the hypervisor to provide the same functions. When the BIOS is emulated and these physical resources are abstracted, administrators have the ability to divide the virtual compute resources from their physical providers and distribute those subdivided resources across multiple VMs. This ability to subdivide physical resources is one of the key elements that make cloud computing and virtualization so powerful.
When splitting resources among multiple VMs, vendor-specific algorithms can help the hypervisor make decisions about which resources are available for each request from its specific VM. There are requirements of the host resources for performing these activities, including small amounts of processor, memory, and disk. These resources are utilized by the hypervisor for carrying out the algorithmic calculations to determine which resources will be granted to which VMs.
Quotas and Limits
As with host resources, VMs utilize quotas and limits to constrain the ability of users to consume compute resources and thereby prevent users from either monopolizing or completely depleting those resources. Quotas can be defined either as hard or soft. Hard quotas set limits that users and applications are barred from exceeding. If an attempt to use resources beyond the set limit is registered, the request is rejected, and an alert is logged that can be acted upon by a user, administrator, or management system. The difference with a soft quota is that the request is granted instead of rejected, and the resources are made available to service the request. However, the same alert is still logged so that action can be taken to either address the issue with the requester for noncompliance with the quota or charge the appropriate party for the extra usage of the materials.
Licensing
Managing hardware resources can be less of a challenge than managing license agreements. Successfully tracking and managing software license agreements in a virtual environment is a tricky proposition. The software application must support licensing a virtual instance of the application.
Some software vendors still require the use of a dongle or a hardware key when licensing their software. Others have adopted their licensing agreements to coexist with a virtual environment. A guest requires a license to operate just as a physical server does. Some vendors have moved to a per-CPU-core type of license agreement to adapt to virtualization. No matter if the application is installed on a physical server or a virtual server, it still requires a license.
Organizations have invested heavily in software licenses. Moving to the cloud does not always mean that those licenses are lost. Bring Your Own License (BYOL), for example, is a feature for Azure migrations that allows existing supported licenses to be migrated to Azure so that companies do not need to pay for the licenses twice. Software assurance with license mobility allows for licenses to be brought into other cloud platforms such as Amazon Web Services (AWS) or VMware vCloud.
Physical Resource Redirection
There are so many things that VMs can do that sometimes we forget that they even exist on physical hardware. However, there are occasions when you need a guest to interface with physical hardware components. Some physical hardware components that are often mapped to VMs include USB drives, parallel ports, serial ports, and USB ports.
In some cases, you may want to utilize USB storage exclusively for a VM. You can add a USB drive to a VM by first adding a USB controller. When a USB drive is attached to a host computer, the host will typically mount that drive automatically. However, only one device can access the drive simultaneously without corrupting the data, so the host must release access to the drive before it can be mapped to a VM. Unmount the drive from the host, and then you will be ready to assign the drive to the VM.
Parallel and serial ports are interfaces that allow for the connection of peripherals to computers. There are times when it is useful to have a VM connect its virtual serial port to a physical serial port on the host computer. For example, a user might want to install an external modem or another form of a handheld device on the VM, and this would require the guest to use a physical serial port on the host computer. It might also be useful to connect a virtual serial port to a file on a host computer and then have the guest VM send output to a file on the host computer. An example of this would be to send data that was captured from a program running on the guest via the virtual serial port and transfer the information from the guest to the host computer.
In addition to using a virtual serial port, it is helpful in certain instances to connect to a virtual parallel port. Parallel ports are used for a variety of devices, including printers, scanners, and dongles. Much like the virtual serial port, a virtual parallel port allows for connecting the guest to a physical parallel port on the host computer.
Besides supporting serial and parallel port emulation for VMs, some virtualization vendors support USB device pass-through from a host computer to a VM. USB pass-through allows a USB device plugged directly into a host computer to be passed through to a VM. USB pass-through allows for multiple USB devices such as security tokens, software dongles, temperature sensors, or webcams that are physically attached to a host computer to be added to a VM.
The process of adding a USB device to the VM usually consists of adding a USB controller to the VM, removing the device from the host configuration, and then assigning the USB device to the VM. When a USB device is attached to a host computer, that device is available only to the VMs that are running on that host computer and only to one VM at a time.
Resource Pools
A resource pool is a hierarchical abstraction of compute resources that can give relative importance, or weight, to a defined set of virtualized resources. Pools at the higher level in the hierarchy are called parent pools; these parents can contain either child pools or individual VMs. Each pool can have a defined weight assigned to it based on either the business rules of the organization or the SLAs of a customer.
Resource pools also allow administrators to define a flexible hierarchy that can be adapted at each pool level as required by the business. This hierarchical structure comes with several advantages, as follows:
• Efficiently maintain access control and delegation of the administration of each pool and its resources.
• Establish isolation between pools.
• Enable resource sharing within the pools.
• Separates the compute resources from discrete host hardware.
The hardware abstraction offered through resource pools frees administrators from the typical constraints of managing the available resources from the host they originated from. Instead, resources are bubbled up to a higher level for management and administration when utilizing pools.

EXAM TIP Understanding the advantages and usage of resource pools is key for the test. You need to know when to use a resource pool and why it provides value.
Dynamic Resource Allocation
Just because administrators can manage their compute resources at a higher level with resource pools, it does not mean they want to spend their precious time doing it. Enter dynamic resource allocation. Instead of relying on administrators to evaluate resource utilization and apply changes to the environment that result in the best performance, availability, and capacity arrangements, a computer can do it for them based on business logic that has been predefined by either the management software’s default values or the administrator’s modification to those values.
Management platforms can manage compute resources for performance, availability, and capacity reasons and realize more cost-effective implementation of those resources in a data center, employing only the hosts required at the given time and shutting down any resources that are not needed. By employing dynamic resource allocation, providers can reduce power costs and go greener by shrinking their power footprint and waste.
Optimizing Performance
Utilization of the allocation mechanisms we have talked about thus far in this chapter allows administrators to achieve the configuration states that they seek within their environment. The next step is to begin optimizing that performance. Optimization includes the following:
• Configuration best practices
• Common issues
• Scalability
• Performance concepts
• Performance automation
Configuration Best Practices
There are some best practices for the configuration of each of the compute resources within a cloud environment. The best practices for these configurations are the focus for the remainder of this section. These best practices center on those allocation mechanisms that allow for the maximum value to be realized by service providers. To best understand their use cases and potential impact, we investigate common configuration options for memory, processor, and disk.
Memory
Memory may be the most critical of all computer resources, as it is usually the limiting factor on the number of guests that can run on a given host, and performance issues appear when too many guests are fighting for enough memory to perform their functions. Two configuration options available for addressing shared memory concerns are memory ballooning and swap disk space.
Memory Ballooning Hypervisors have device drivers that they build into the host virtualization layer from within the guest operating system. Part of this installed toolset is a balloon driver, which can be observed inside the guest. The balloon driver communicates to the hypervisor to reclaim memory inside the guest when it is no longer valuable to the operating system. If the hypervisor host begins to run low on memory due to memory demands from other VM guests, it will invoke (inflate) the balloon driver in VMs requiring less memory. Hypervisors such VMware use a balloon driver installed in the guest VM; Microsoft Hyper-V calls this setting “Dynamic memory.” This reduces the chance that the physical host will start to utilize virtualized memory from a defined paging file on its available disk resource, which causes performance degradation. An illustration of the way this ballooning works can be found in Figure 9-2.
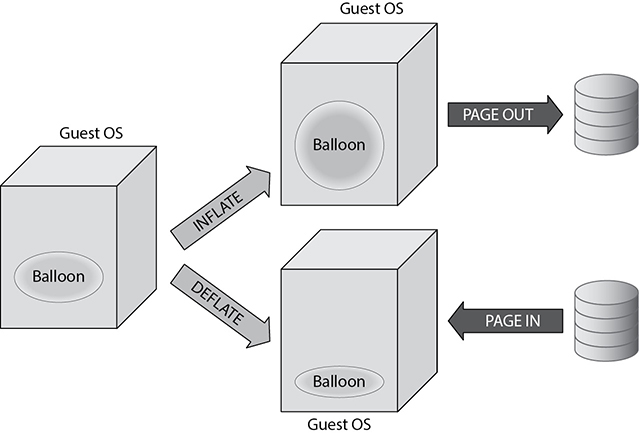
Figure 9-2 How memory ballooning works
Swap Disk Space Swap space is disk space allocated to service memory requests when the physical memory capacity limit has been reached. When virtualizing and overcommitting memory resources to VMs, administrators must make sure to reserve enough swap space for the host to balloon memory in addition to reserving disk space within the guest operating system for it to perform its swap operations.
VMs and the applications that run on them will take a significant performance hit when memory is swapped out to disk. However, you do not need that large of a disk for swap space, so it is a good practice to keep a solid state drive in the host that can be used for swap space if necessary. This will ensure that those pages moved to swap space are transferred to high-speed storage, reducing the impact of memory paging operations.
Processor
CPU time is the amount of time a process or thread spends executing on a processor core. For multiple threads, the CPU time of the threads is additive. The application CPU time is the sum of the CPU time of all the threads that run the application. Wait time is the amount of time that a given thread waits to be processed; it could be processed but must wait on other factors such as synchronization waits and I/O waits.
High CPU wait times signal that there are too many requests for a given queue on a core to handle, and performance degradation will occur. While high CPU wait time can be alleviated in some situations by adding processors, these additions sometimes hurt performance.
CAUTION Be careful when adding processors, as there is a potential for causing even further performance degradation if the applications using them are not designed to be run on multiple CPUs.
Another solution for alleviating CPU wait times is to scale out instead of scaling up, two concepts that we explore in more detail later in this chapter.
CPU Affinity It is also important to properly configure CPU affinity, also known as processor affinity. CPU affinity is where threads from a specific VM are tied to a specific processor or core, and all subsequent requests from that process or thread are executed by that same processor or core. CPU affinity overrides the built-in processor scheduling mechanisms so that threads are bound to specific processor cores.
• Benefits The primary benefit of CPU affinity is to optimize cache performance. Processor cache is local to that processor, so if operations are executed on another processor, they cannot take advantage of the cache on the first processor. Furthermore, the same data cannot be kept in more than one processor cache. When the second processor caches new content, it must first invalidate the cache from the first processor. This can happen when a performance-heavy thread moves from one processor to another. This process of invalidating the cache can be prevented by assigning the VM thread to a processor so that its cache never moves. CPU affinity can also ensure that the cache that has been created for that processor is utilized more often for that VM thread.
Another benefit is preventing two CPU-intensive VMs from operating on the same vCPU. Since many vCPUs are oversubscribed or are mapped to hyperthreaded CPU cores, these cores end up being mapped back to the same physical core. This is fine when the load is minimal because the oversubscription and hyperthreading allow for the hypervisor to make better use of CPU resources. However, when two processor-intensive VMs are operating on the same vCPU, they can easily cause contention.
• Caveats Assigning CPU affinity can cause many problems and should be used sparingly. In many cases, the best configuration will be not to configure CPU affinity and to let the hypervisor choose the best processor for the task at hand. This is primarily because CPU affinity does not prevent other VMs from using the processor core, but it restricts the configured VM from using other cores; thus, the preferred CPU could be overburdened with other work. Also, where the host would generally assign the virtual machine’s thread to another available CPU, CPU affinity would require the VM to wait until the CPU became available before its thread would be processed.
Test CPU affinity before implementing it in production. You may need to create CPU affinity rules for all other VMs to ensure that they do not contend for CPU cores. Document affinity settings so that other administrators will be aware of them when migrating VMs or performing other changes to the environment.
CPU Anti-Affinity CPU anti-affinity ensures that threads from a specific VM will not execute on a particular processor or core, and all subsequent requests from that process or thread are executed by processors other than the excluded one. Similar to CPU affinity, CPU anti-affinity overrides the built-in processor scheduling mechanisms.
CPU anti-affinity is often used in conjunction with CPU affinity, such as when trying to isolate the processes of CPU-intensive VMs. When one machine has affinity for the CPU, the other one can be given anti-affinity for it. Similarly, suppose you have a VM that needs very predictable performance. In that case, you may dedicate a vCPU to it with CPU affinity and then use CPU anti-affinity rules to ensure that other machines are not allocated time on that vCPU when the dedicated VM is not using it.
Exercise 9-1: Setting CPU Affinity and Anti-Affinity Rules in VMWare Cloud
In this exercise, we will set CPU affinity and nonaffinity rules within VMWare Cloud.
1. Log into VMWare Cloud Service Manager and then click on Clouds to select your cloud, as shown here:
2. Click on the Inventory tab, and you will see a breakdown of the machines, services, and groups that you have in your cloud.
3. Select the VM button on the left side, as shown next.
4. You will see your VMs presented. Select the one you wish to change the CPU affinity on and then select Edit Settings.
5. Select CPU under Virtual Hardware.
6. There is a section called Scheduling Affinity. Under this, select Physical Processor Affinity.
7. You can now enter which processors you want this VM to use. The VM will be given affinity for the processors you enter here and will be given anti-affinity for any that you do not enter here. Each processor you wish to add should be added by a number separated by a comma. You can also reference them by range. For example, if you want the processor to run only on processors 17 through 32, you would enter “17-32” in the field. For this example, let’s have the VM run on processors 25 through 32, so we will enter 25-32 and then select Save Settings.
Disk
Poor disk performance, or poorly designed disk solutions, can have performance ramifications in traditional infrastructures, slowing users down as they wait to read or write data for the server they are accessing. In a cloud model, however, disk performance issues can limit access to all organization resources because multiple virtualized servers in a networked storage environment might be competing for the same storage resources, thereby crippling their entire deployment of virtualized servers or desktops. The following sections describe some typical configurations and measurements that assist in designing a high-performance storage solution. These consist of the following:
• Disk performance
• Disk tuning
• Disk latency
• I/O throttling
• I/O tuning
Disk Performance Disk performance can be configured with several different configuration options. The media type can affect performance, and administrators can choose between the most standard types of traditional rotational media or chip-based solid state drives. Solid state drives, while becoming more economical in the last few years, are still much more expensive than rotational media and are not utilized except where only the highest performance standards are required.
The next consideration for disk performance is the speed of the rotational media, should that be the media of choice. Server-class disks start at 7200 RPM and go up to 15,000 RPM, with seek times for the physical arm reading the platters being considerably lower on the high-end drives. In enterprise configurations, the price point per gigabyte is primarily driven by the rotation speed and only marginally by storage space per gigabyte. When considering enterprise storage, the adage is that you pay for performance, not space.
Once the media type and speed have been determined, the next consideration is the type of RAID array that the disks are placed in to meet the service needs. Different levels of RAID can be employed based on the deployment purpose. These RAID levels should be evaluated and configured based on the type of I/O and on the need to read, write, or a combination of both.
Disk Tuning Disk tuning is the activity of analyzing what type of I/O traffic is taking place across the defined disk resources and moving it to the most appropriate set of resources. Virtualization management platforms enable the movement of storage, without interrupting current operations, to other disk resources within their control.
Virtualization management platforms allow either administrators or dynamic resource allocation programs to move applications, storage, databases, and even entire VMs among disk arrays with no downtime to ensure that those virtualized entities get the performance they require based on either business rules or SLAs.
Disk Latency Disk latency is a counter that provides administrators with the best indicator of when a resource is experiencing degradation due to a disk bottleneck and needs to have action taken against it. If high-latency counters are experienced, a move to either another disk array with quicker response times or a different configuration, such as higher rotational speeds or a different array configuration, is warranted. Another option is to configure I/O throttling.
I/O Throttling I/O throttling does not eliminate disk I/O as a bottleneck for performance, but it can alleviate performance problems for specific VMs based on a priority assigned by the administrator. I/O throttling defines limits that can be utilized specifically for disk resources allocated to VMs to ensure that they are not performance or availability constrained when working in an environment that has more demand than the availability of disk resources.
I/O throttling may be a valuable option when an environment contains both development and production resources. The production I/O can be given a higher priority than the development resources, allowing the production environment to perform better for end users.
Prioritization does not eliminate the bottleneck. Rather, prioritizing production machines just passes the bottleneck on to the development environment, which becomes even further degraded in performance while it waits for all production I/O requests when the disk is already overallocated. Administrators can then assign a priority or pecking order for the essential components that need higher priority.
I/O Tuning When designing systems, administrators need to analyze I/O needs from the top-down, determining which resources are necessary to achieve the required performance levels. In order to perform this top-down evaluation, administrators first need to evaluate the application I/O requirements to understand how many reads and writes are required by each transaction and how many transactions take place each second.
Once administrators understand the application requirements, they can build the disk configuration. Configurations elements that will need to be considered to support the application requirements include some of the following:
• Type of media
• Array configuration
• RAID type
• The number of disks in a RAID set
• Access methods
Scalability
Most applications will see increases in workloads in their life cycles. For this reason, the systems supporting those applications must be able to scale to meet increased demand. Scalability is the ability of a system or network to manage a growing workload in a proficient manner or its ability to be expanded to accommodate the workload growth. All cloud environments need to be scalable, as one of the chief tenets of cloud computing is elasticity, or the ability to quickly adapt to growing workloads.
Scalability can be handled either vertically or horizontally, more commonly referred to as “scaling up” or “scaling out,” respectively.
Vertical Scaling (Scaling Up)
To scale vertically means to add resources to a single node, thereby making that node capable of handling more of a load within itself. This type of scaling is most often seen in virtualization environments where individual hosts add more processors or more memory with the objective of adding more VMs to each host.
Horizontal Scaling (Scaling Out)
More nodes are added to a configuration to scale horizontally instead of increasing the resources for any particular node. Horizontal scaling is often used in application farms. In such cases, more web servers are added to a farm to handle distributed application delivery better. The third type of scaling, diagonal scaling, is a combination of both, increasing resources for individual nodes and adding more of those nodes to the system. Diagonal scaling allows for the best configuration to be achieved for a quickly growing, elastic solution.
EXAM TIP Know the difference between scaling up and scaling out.
Performance Concepts
There are some performance concepts that underlie each of the failure types and the allocation mechanisms discussed in this chapter. As we did with the failure mechanisms, let’s look at each of these according to their associated compute resources.
Disk
The configuration of disk resources is an integral part of a well-designed cloud system. Based on the user and application requirements and usage patterns, numerous design choices need to be made to implement a storage system that cost-effectively meets an organization’s needs. Some of the considerations for disk performance include
• IOPS
• Read and write operations
• File system performance
• Metadata performance
• Caching
IOPS IOPS, or input/output operations per second, are the standard measurement for disk performance. They are usually gathered as read IOPS, write IOPS, and total IOPS to distinguish between the types of requests that are being received.
Read and Write Operations As just mentioned, two types of operations can take place: reading and writing. As their names suggest, reads occur when a resource requests data from a disk resource, and writes occur when a resource requests new data be recorded on a disk resource. Different configuration options exist both for troubleshooting and performance tuning based on which type of operation occurs.
File System Performance File system performance is debated as a selling point among different technology providers. File systems can be formatted and cataloged differently based on the proprietary technologies of their associated vendors. There is little to do in the configuration of file system performance outside of evaluating the properties of each planned operation in the environment.
Metadata Performance Metadata performance refers to how quickly files and directories can be created, removed, or checked. Applications exist now that produce millions of files in a single directory and create very deep and wide directory structures, and this rapid growth of items within a file system can have a significant impact on performance. The ability to create, remove, and check their status efficiently grows in direct proportion to the number of items in use on any file system.
Caching To improve performance, hard drives are architected with a disk cache mechanism that reduces both read and write times. On a physical hard drive, the disk cache is usually a RAM chip that is built in and holds data that is likely to be accessed again soon. On virtual hard drives, the same caching mechanism can be employed by using a specified portion of a memory resource.
Network
Similar to disk resources, the configuration of network resources is critical. Based on the user and application requirements and usage patterns, numerous design choices need to be made to implement a network that cost-effectively meets an organization’s needs. Some of the considerations for network performance include
• Bandwidth
• Throughput
• Jumbo frames
• Network latency
• Hop counts
• Quality of service (QoS)
• Multipathing
• Load balancing
Bandwidth Bandwidth is the measurement of available or consumed data communication resources on a network. The performance of all networks is dependent on having available bandwidth.
Throughput Throughput is the amount of data that can be realized between two network resources. Throughput can be substantially increased through bonding or teaming of network adapters, which allows resources to see multiple interfaces as one single interface with aggregated resources.
Jumbo Frames Jumbo frames are Ethernet frames with more than 1500 bytes of payload. These frames can carry up to 9000 bytes of payload, but depending on the vendor and the environment they are deployed in, there may be some deviation. Jumbo frames are utilized because they are much less processor-intensive to consume than a large number of smaller frames, thereby freeing up expensive processor cycles for more business-related functions.
Network Latency Network latency refers to any performance delays experienced during the processing of any network data. A low-latency network connection is one that experiences short delay times, such as a dedicated T-1, while a high-latency connection frequently suffers from long delays, like DSL or a cable modem.
Hop Counts A hop count represents the total number of devices a packet passes through to reach its intended network target. The more hops data must pass through to reach its destination, the greater the delay is for the transmission. Network utilities like ping can be used to determine the hop count to an intended destination.
Ping generates packets that include a field reserved for the hop count, typically referred to as the Time to Live (TTL). Each time a capable device, usually a router, along the path to the target receives one of these packets, that device modifies the packet, decrementing the TTL by one. Each packet is sent out with a particular TTL value, ranging from 1 to 254. The TTL count is decremented for every router (hop) that the packet traverses on its way to the destination.
The hop count is also decremented by one each second that the packet resides in the memory of a routing device at a hop along the path to its destination. The receiving device compares the hop count against a predetermined limit. It discards the packet if its hop count is too high. If the TTL is decremented to zero at any point during its transmission, an “ICMP port unreachable” message is generated, with the IP of the source router or device included, and sent back to the originator. The finite TTL is used as it counts down to zero to prevent packets from endlessly bouncing around the network due to routing errors.
Quality of Service QoS is a set of technologies that can identify the type of data in data packets and divide those packets into specific traffic classes that can be prioritized according to defined service levels. QoS technologies enable administrators to meet their service requirements for a workload or an application by measuring network bandwidth, detecting changing network conditions, and prioritizing the network traffic accordingly. QoS can be targeted at a network interface, toward a given server’s or router’s performance, or regarding specific applications. A network monitoring system is typically deployed as part of a QoS solution to ensure that networks perform at the desired level.
Multipathing Multipathing is the practice of defining and controlling redundant physical paths to I/O devices. When an active path to a device becomes unavailable, the multipathing configuration can automatically switch to an alternative path to maintain service availability. The capability of performing this operation without intervention from an administrator is known as automatic failover.
EXAM TIP Remember that multipathing is almost always an architectural component of redundant solutions.
A prerequisite for taking advantage of multipathing capabilities is to design and configure the multipathed resource with redundant hardware, such as redundant network interfaces or host bus adapters.
Load Balancing A load balancer is a networking solution that distributes incoming traffic among multiple servers hosting the same application content. Load balancers improve overall application availability and performance by preventing any application server from becoming a single point of failure.
If deployed alone, however, the load balancer becomes a single point of failure by itself. Therefore, it is always recommended to deploy multiple load balancers in parallel. In addition to improving availability and performance, load balancers add to the security profile of a configuration by the typical usage of network address translation, which obfuscates the back-end application server’s IP address.
Performance Automation
Various tasks can be performed to improve performance on machines. It is typical for these tasks to be performed at regular intervals to maintain consistent performance levels. However, it can be quite a job to maintain a large number of systems, and organizational IT departments are supporting more devices per person than ever before. They accomplish this through automation. Automation uses scripting, scheduled tasks, and automation tools to do the routine tasks so that IT staff can spend more time solving the real problems and proactively looking for ways to make things better and even more efficient.
PowerShell commands are provided in many examples because these commands can be used with the AWS Command Line Interface (CLI) or the Microsoft Azure Cloud Shell. PowerShell was chosen for its versatility. However, other scripting languages can also be used, depending on the platform. Scripts can be combined into tasks using AWS Systems Manager or Microsoft Azure runbooks.
This section discusses different performance-enhancing activities that can be automated to save time and standardize. They include the following:
• Archiving logs
• Clearing logs
• Compressing drives
• Scavenging stale DNS entries
• Purging orphaned resources
• Reclaiming resources
Archiving Logs
Logs can take up a lot of space on servers, but you will want to keep logs around for a long time in case they are needed to investigate a problem or a security issue. For this reason, you might want to archive logs to a logging server and then clear the log from the server.
A wide variety of cloud logging and archiving services are available that can be leveraged instead of setting up a dedicated logging server. Some services include Logentries, OpenStack, Sumo Logic, Syslog, Amazon S3, Amazon CloudWatch, and Papertrail. Cloud backup services can also be used to archive logs. Services such as AWS Glacier can be configured to pull log directories and store them safely on another system, so they are not lost. These systems can consolidate logs, then correlate and deduplicate them to save space and gain network intelligence.
Clearing Logs
There is very little reason to clear logs unless you have first archived them to another service or server. The previous section outlined how to archive logs to a local logging server or to cloud services. Ensure that these are configured and that they have been fully tested before clearing logs that could contain valuable data. Logs are there for a reason. They show the activity that took place on a device, and they can be very valuable in retracing the steps of an attacker or in troubleshooting errors. You do not want to be the person who is asked, “How long has this been going on?” and you have to answer, “I don’t know because we cleared the logs last night.” Attackers will often clear log files to cover their tracks after committing some malicious deed, such as compromising a server or stealing data.
Here is a PowerShell function to clear the logs from computers 1 through 4 called ClearComputer1-4Logs. You first provide the function with a list of computers. It then puts together a list of all logs, goes through each, and clears the log.

Compressing Drives
Compressing drives can reduce the amount of space consumed. However, accessing files on the drives will require a bit more CPU power to decompress before the file can be opened. Here is the command you can use to compress an entire drive. You can place this in a Windows group policy to encrypt the data drives (D:) of various machines, depending on how you apply the group policy. The following command specifies that the D: directory and everything below it should be compressed. The –recurse command is what causes the compression to take place on all subfolders.
Enable-NtfsCompression -Path D: -Recurse
Scavenging Stale DNS Entries
As mentioned in Chapter 4, DNS distributes the responsibility for both the assignment of domain names and the mapping of those names to IP addresses to the authoritative name servers within each domain. DNS servers register IP address assignments as host records in their database. Sometimes a record is created and then that host is removed or it is assigned a new address. The DNS server would retain a bogus record in the former case and redundant addresses in the latter case.
Scavenging is the process of removing DNS entries for hosts that no longer respond on that address. You can configure automatic scavenging on DNS servers. All you have to do is enable the scavenging feature and set the age for when DNS records will be removed. If a host cannot be reached for the specified number of days, its host record in DNS will automatically be deleted.
Purging Orphaned Resources
Applications, hypervisors included, do not always clean up after themselves. Sometimes child objects or resources from deleted or moved objects still remain on systems. These are known as orphaned resources.
In Microsoft System Center Virtual Machine Manager (SCVMM), you can view orphaned resources by opening the Library workspace and clicking Orphaned Resources. You can right-click the object to delete it, but we want to automate the task. A script to remove all orphaned resources from SCVMM would take many pages of this book, so we will point you to a resource where you can obtain an up-to-date script for free: https://www.altaro.com/hyper-v/free-script-find-orphaned-hyper-v-vm-files/
Orphaned resources show up in the VMware vSphere web client with “(Orphaned)” after their name. You can remove them with this script after logging into the command line on the host:

Reclaiming Resources
Many companies have inactive VMs that continue to consume valuable resources while providing no business value. Metrics can identify machines that might not be used. At this point, a standard message can be sent to the VM owner, notifying them that their system has been flagged for reclamation unless they confirm that the VM is still providing business value. Alternatively, you can give the owner the option of keeping or reclaiming the resources themselves rather than automatically doing it. However, if the owner of the VM does not respond in a timely manner, the organization may decide to have the machine reclaimed automatically.
If reclamation is chosen, the machine can be archived and removed from the system, and the resources can be freed up for other machines. The automation can be initiated whenever metrics indicate an inactive machine. VMware vRealize has this capability built-in for vCenter, and similar automation can be created for other tools. In Microsoft Azure, the Resource Manager can be configured to reclaim resources.

NOTE Do not enable reclamation functions until you have a good idea of how they will operate. Double-check settings to avoid reclaiming too much.
Common Performance Issues
Some failures can occur within a cloud environment, and the system must be configured to be tolerant of those failures and provide availability in accordance with the organization’s SLA or other contractual agreements.
Mechanical components in an environment will experience failure at some point. It is just a matter of time. Higher-quality equipment may last longer than cheaper equipment, but it will still break down someday. This is something you should be prepared for.
Failures occur mainly on each of the four primary compute resources: disk, memory, network, and processor. This section examines each of these resources in turn.
Common Disk Issues
Disk-related issues can happen for a variety of reasons, but disks fail more frequently than the other compute resources because they are the only compute resource that has a mechanical component. Due to the moving parts, failure rates are typically quite high. Some common disk failures include
• Physical hard disk failures
• Controller card failures
• Disk corruption
• HBA failures
• Fabric and network failures
Physical Hard Disk Failures
Physical hard disks frequently fail because they are mechanical, moving devices. In enterprise configurations, they are deployed as components of drive arrays, and single failures do not affect array availability.
Controller Card Failures
Controller cards are the elements that control arrays and their configurations. Like all components, they fail from time to time. Redundant controllers are costly to run in parallel, as they require double the amount of drives to become operational, and that capacity is lost because it is never in use until failure. Therefore, an organization should do a return-on-investment analysis to determine the feasibility of making such devices redundant.
Disk Corruption
Disk corruption occurs when the structured data on the disk is no longer accessible. This can happen due to malicious acts or programs, skewing of the mechanics of the drive, or even a lack of proper maintenance. Disk corruption is hard to repair, as the full contents of the disks often need to be reindexed or restored from backups. Backups can also be unreliable for these failures if the corruption began before its identification, as the available backup sets may also be corrupted.
Host Bus Adapter Failures
While not as common as physical disk failures, host bus adapter (HBA) failures need to be expected, and storage solutions need to be designed with them in mind. HBAs have the option of being multipathed, which prevents a loss of storage accessibility in the event of a failure.
Fabric and Network Failures
Similar to controller card failure, fabric or network failures can be relatively expensive to design around, as they happen when a storage networking switch or switch port fails. The design principles to protect against such a failure are similar to those for HBAs, as multipathing needs to be in place to make sure all hosts that depend on the fabric or network have access to their disk resources through another channel.
Common Memory Issues
Memory-related issues, while not as common as disk failures, can be just as disruptive. Good system design in cloud environments will take RAM failure into account as a risk and ensure that there is always some RAM available to run mission-critical systems in case of memory failure on one of their hosts. The following are some types of memory failures:
• Memory chip failures
• Motherboard failures
• Swap files that run out of space
Memory Chip Failures
Memory chip failures happen less frequently than physical device failures, since memory chips have no moving parts and mechanical wear does not play a role. They will, however, break from time to time and need to be replaced.
Motherboard Failures
Similar to memory chips, motherboards have no moving parts, and because of this, they fail less frequently than mechanical devices. When they do fail, however, VMs are unable to operate, as they have no processor, memory, or networking resources that they can access. In this situation, they must be moved immediately to another host or go offline.
Swap Files Out of Space
Swap space failures often occur in conjunction with a disk failure, when disks run out of available space to allocate to swap files for memory overallocation. They do, however, result in out-of-memory errors for VMs and hosts alike.
Network Issues
Similar to memory components, network components are relatively reliable because they do not have moving parts. Unlike memory, network resources are highly configurable and prone to errors based on human mistakes during implementation. Network redundancy, such as redundant links to a CSP, can help mitigate the risk of some network issues. This is important because network communication is the foundation for using cloud services. Some common types of network failures include
• Physical NIC failures
• Speed or duplex mismatches
• Switch failures
• Physical transmission media failures
Physical NIC Failures
Network interface cards can fail in a similar fashion to other printed circuit board components like motherboards, controller cards, and memory chips. Because they fail from time to time, redundancy needs to be built into the host through multiple physical NICs and into the virtualization through designing multiple network paths using virtual NICs for the VMs.
Speed or Duplex Mismatches
Mismatch failures happen only on physical NICs and switches, as virtual networks negotiate these automatically. Speed and duplex mismatches result in dropped packets between the two connected devices and can be identified through getting a significant number of cyclical redundancy check (CRC) errors on the devices.
Switch Failures
Similar to fabric and network failures, network switch failures are expensive to plan for, as they require duplicate hardware and cabling. Switches fail only a small percentage of the time, but more frequently have individual ports fail. When these individual ports do fail, the resources that are connected to them need to have another path available, or their service will be interrupted.
Physical Transmission Media Failures
Cables break from time to time when their wires inside are crimped or cut. This can happen either when they are moved, when they are stretched too far, or when they become old, and the connector breaks loose from its associated wires. As with other types of network failures, multiple paths to the resource using that cable is the way to prevent a failure from interrupting operations.
Physical Processor Issues
Processors fail for one of three main reasons: they get broken while getting installed, they are damaged by voltage spikes, or they are damaged due to overheating from failed or ineffective fans. Damaged processors either take hosts completely offline or degrade performance based on the damage and the availability of a standby or alternative processor in some models.
Chapter Review
When building a virtualization host, special consideration needs to be given to adequately planning the resources to ensure that the host can support the virtualized environment. Creating a VM requires thorough planning regarding the role the VM will play in the environment and the VM’s resources to accomplish that role. Planning carefully for the VM and the primary resources of memory, processor, disk, and network can help prevent common failures.
Questions
The following questions will help you gauge your understanding of the material in this chapter. Read all the answers carefully because there might be more than one correct answer. Choose the best response(s) for each question.
1. Which of the following would be considered a host compute resource?
A. Cores
B. Power supply
C. Processor
D. Bandwidth
2. Quotas are a mechanism for enforcing what?
A. Limits
B. Rules
C. Access restrictions
D. Virtualization
3. How are quotas defined?
A. By management systems
B. According to service level agreements that are defined between providers and their customers
C. Through trend analysis and its results
D. With spreadsheets and reports
4. When would a reservation be used?
A. When a maximum amount of resources needs to be allocated to a specific resource
B. When a minimum amount of capacity needs to be available at all times to a specific resource
C. When capacity needs to be measured and controlled
D. When planning a dinner date
5. How does the hypervisor enable access for VMs to the physical hardware resources on a host?
A. Over Ethernet cables
B. By using USB 3.0
C. Through the system bus
D. By emulating a BIOS that abstracts the hardware
6. What mechanism allows one core to handle all requests from a specific thread on a specific processor core?
A. V2V
B. CPU affinity
C. V2P
D. P2V
7. In a scenario where an entity exceeds its defined quota but is granted access to the resources anyway, what must be in place?
A. Penalty
B. Hard quota
C. Soft quota
D. Alerts
8. Which of the following must be licensed when running a virtualized infrastructure?
A. Hosts
B. VMs
C. Both
D. Neither
9. What do you need to employ if you have a serial device that needs to be utilized by a VM?
A. Network isolation
B. Physical resource redirection
C. V2V
D. Storage migration
10. You need to divide your virtualized environment into groups that can be managed by separate groups of administrators. Which of these tools can you use?
A. Quotas
B. CPU affinity
C. Resource pools
D. Licensing
11. Which tool allows guest operating systems to share noncritical memory pages with the host?
A. CPU affinity
B. Memory ballooning
C. Swap file configuration
D. Network attached storage
12. Which of these options is not a valid mechanism for improving disk performance?
A. Replacing rotational media with solid state media
B. Replacing rotational media with higher-speed rotational media
C. Decreasing disk quotas
D. Employing a different configuration for the RAID array
Answers
1. C. The four compute resources used in virtualization are disk, memory, processor, and network. On a host, these are available as the physical entities of hard disks, memory chips, processors, and network interface cards (NICs).
2. A. Quotas are limits on the resources that can be utilized for a specific entity on a system. For example, a user could be limited to storing up to 10GB of data on a server or a VM limited to 500GB of bandwidth each month.
3. B. Quotas are defined according to service level agreements that are negotiated between a provider and its customers.
4. B. A reservation should be used when there is a minimum amount of resources that need to have guaranteed capacity.
5. D. The host computer BIOS is emulated by the hypervisor to provide compute resources for a VM.
6. B. CPU affinity allows all requests from a specific thread or process to be handled by the same processor core.
7. C. Soft quotas enforce limits on resources, but do not restrict access to the requested resources when the quota has been exceeded.
8. C. Both hosts and guests must be licensed in a virtual environment.
9. B. Physical resource redirection enables VMs to utilize physical hardware as if they were physical hosts that could connect to the hardware directly.
10. C. Resource pools allow the creation of a hierarchy of guest VM groups that can have different administrative privileges assigned to them.
11. B. Memory ballooning allows guest operating systems to share noncritical memory pages with the host.
12. C. Decreasing disk quotas helps with capacity issues, but not with performance.