
CHAPTER 15
Troubleshooting
In this chapter, you will learn about
• Troubleshooting methodology
• Troubleshooting steps
• Documentation and analysis
• Troubleshooting tools
Service and maintenance availability must be a priority when choosing a cloud provider. Having the ability to test and troubleshoot the cloud environment is a critical step in providing the service availability an organization requires. This chapter introduces you to troubleshooting tools, discusses documentation and its importance to company and cloud operations, and presents a troubleshooting methodology with various sample scenarios and issues that you might face in your career and on the CompTIA Cloud+ exam.
Troubleshooting Methodology
CompTIA has established a troubleshooting methodology consisting of six steps, as shown in Figure 15-1. They are as follows: First, identify the problem. This is followed by establishing a theory of probable causes. Next, you test the theory to determine the cause. Fourth, establish a plan of action to resolve the problem and implement the solution. Fifth, verify full system functionality and, if applicable, implement preventative measures. Last, document your findings, actions, and outcomes.
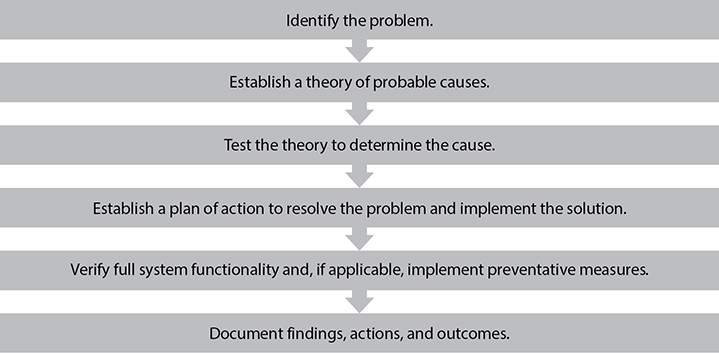
Figure 15-1 CompTIA troubleshooting methodology
Step 1: Identify the problem. The first step in the CompTIA troubleshooting methodology is to identify the problem. There are four parts to this, as follows:
1. Interview the user
2. Reproduce the issue
3. Preserve the state
4. Identify changes precipitating the issue
Interview the User Talk with the user experiencing the issue to understand it. Identify the problem’s scope, including which machines and network devices, subnets, sites, or domains are affected. Identifying the scope may involve interviewing others in the department or company. You will also need to find out when the issue first began. Did this occur last week, earlier in the day, or is this a chronic issue that they are finally reporting? Try to get as precise a time as possible because this will make it easier to isolate changes and conditions that occurred surrounding that time.
Since both of these steps require asking the user or others questions, it is important to be courteous and respectful. Show the user that you are concerned about the problem by actively listening to what they have to say. All too often, IT professionals want to run off as soon as a problem is mentioned so that they can begin fixing it. However, in a rush to fix the problem, they may not truly understand the problem and give the user the impression that their situation is not important.
Reproduce the Issue A critical step in identifying the problem is to ask the user to demonstrate what is not working for them. If they say the Internet is not working on their cloud virtual desktop, ask them to demonstrate. In this way, both you and the user can better understand the scope of the problem, and the user might be able to do more while you troubleshoot.
Sometimes a user will describe a scenario that you cannot reproduce. For example, they may have trouble visiting a site, and you can get there fine until they show you and you see they are using a different, out-of-date browser. Similarly, they may show you that a particular site does not come up, but when you ask them to go to another site, it loads correctly.
It can be frustrating if you cannot reproduce the error with the user. If this happens, be patient and try several more times. If you still cannot reproduce it, ask them to notify you when it happens again and to note other things that happen around that time. It could be that the issue only occurs when certain conditions are met, such as a high load on the network, a specific time of day, or when other applications are open.
Preserve the State Before moving to further steps, ensure that a backup is taken of the system. You want to preserve the state the machine is in so that you can get back to this state later, if necessary. This allows you to revert back if changes make the problem worse as you are troubleshooting.
Identify Changes Precipitating the Issue Lastly, determine what has changed recently. Evaluate whether those changes could have contributed to the issue. Some things to consider include
• New software installations.
• Applying patches or updates.
• New users logging on.
• The machine was moved to a new location.
• Connections to new Wi-Fi networks.
• Operating system changes were made.
• New hardware was added, or hardware was removed. This could include something as simple as plugging in a portable hard drive or flash drive or removing a webcam.
• Connections to new network resources, such as network shares or printers.
• The system was damaged in some way, or the user noticed signs of damage.
• The user noticed signs of tampering or tampering alarms were triggered.
Step 2: Establish a theory of probable causes. The second step in the CompTIA troubleshooting methodology is to establish a theory of probable causes. There are three parts to this, as follows:
1. List and prioritize possible causes
2. Question the obvious
3. Conduct research based on symptoms
List and Prioritize Possible Causes The information gathered in step 1 should help in generating possible causes. Ask yourself what is common between devices that are experiencing the issue. Do they share a common connection or resource?
Question the Obvious Be sure to question the obvious (the simple things). Sometimes, problems can be solved by something relatively simple such as plugging in an Ethernet cable, verifying that users are typing a URL or UNC correctly, or verifying that target systems are turned on. Don’t spend your time working out potential complex solutions until you have eliminated the simple solutions.
Conduct Research Based on Symptoms Next, research the symptoms the user is experiencing. Documentation comes in very handy when performing this research. Be sure to review records on how systems should be configured and compare these with the actual configuration.
Depending on the issue, you may need to review vendor manuals as well. For example, if this is an issue with a software application, check the vendor manual for that application. It is essential to know where to find this information. For this reason, keep manuals and other documentation in a central location, typically on a network share or a shared cloud folder that can be easily updated and accessed.

NOTE Make sure you identify the product version number that the user is running so that you can refer to the correct vendor document.
Step 3: Test the theory to determine the cause. At this point, you will likely have multiple theories on what might be the problem. Only one of those theories will be correct, so you will need to test the theories to identify which one it is. Systematically go through the theories, testing them to either confirm or reject them. Figure 15-2 shows the process.
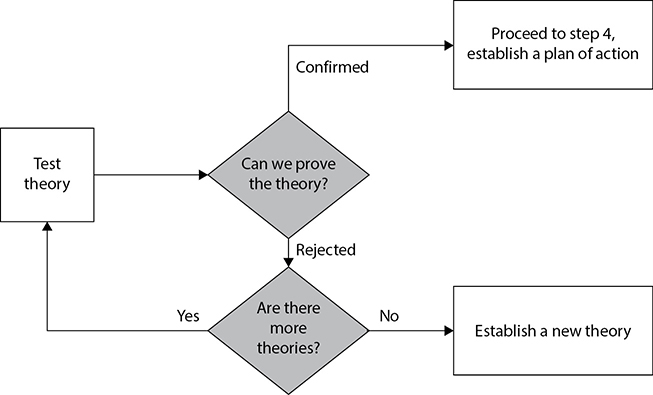
Figure 15-2 Testing the theory
Start by testing the simplest theories before thinking through the complex ones. As mentioned in the previous step, most issues are caused by simple things, and simple things are easier to test. Ensure that the system you use for testing is similar enough to the one experiencing issues, and ensure that you can replicate the issue on the test system before attempting a fix. Some IT professionals have worked hard to deploy a solution to a system that was not experiencing the problem. They then falsely believe they fixed the issue when they later test. For each theory, determine if you can confirm or reject it. If you reject the theory, move on to the next one. If you confirm it, move on to step 4.
If you need to have the user test some things, be sure to ask politely. Phrase your request so as not to cause the user to think that you are blaming them for the problem, even if you believe it is a user error. If you are incorrect and it is not a user error, you will look foolish, and the user might be offended.
If you end up rejecting all the theories, you will need to establish a new theory. Go back to step 2 and consider the situation from angles that you did not consider before. If you are unable to think of new theories, solicit help from others.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Document the steps that you want to take to resolve the problem. Ensure that you can demonstrate that your tests confirmed a nonworking condition and then a working condition following the proposed actions’ implementation. Review the plan with others and ensure that change controls are followed. The change management process was discussed in Chapter 14. Lastly, after approval has been given to implement the change, perform the outlined steps to fix the problem.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Check with all users who were experiencing the issue to ensure that they are no longer experiencing the problem. Also, check with others around them to ensure that you have not created other issues by implementing the fix. Lastly, implement restrictions or additional controls to prevent the problem from occurring in the future. This could involve retraining the user or placing technical controls on the system to prevent such actions from happening again. In some cases, permissions may need to be changed or system configurations updated. System changes should follow the same change control process as the troubleshooting change did.
Step 6: Document findings, actions, and outcomes. This last step is critical to ensure that you or others at your company do not continue to solve the same problems from scratch over and over. If you are anything like us, you will need to write down what you did so that you can remember it again later. IT professionals lead busy lives, and there never seems to be time to document. However, if you do not document, you will find that you spend time performing the same research when you could have simply consulted your documentation.
The CompTIA troubleshooting steps provided here will be demonstrated in the scenarios that follow to help you understand better how the troubleshooting methodology is applied to real-world problems.
In the course of your career, you will run into a wide variety of issues that you will need to troubleshoot. No book could be comprehensive enough to cover all of them, so I have selected a few problems that you are likely to see. The issues are also ones that you are likely to see on the CompTIA Cloud+ exam.
Troubleshooting Steps
Troubleshooting is a broad subject because there are so many things that can go wrong. This is complicated with the many complex systems in use today. No matter the issue, remember to try to break the problem down to the smallest parts so that you can work on just those. This is why it is crucial to identify the issue as precisely as possible.
This section discusses some of the potential issues you might face in the following main areas:
• Security
• Deployment
• Connectivity
• Performance
• Capacity
• Automation and orchestration
Security Issues
Security issues can cause significant problems for system availability and data confidentiality or integrity. Some security issues you should be aware of are as follows:
• Federations, domain trusts, and single sign-on Federations, domain trusts, and single sign-on (SSO) are each technologies that extend authentication and authorization functions across multiple interdependent systems.
• External attacks External attacks can be minimized using firewalls, intrusion detection systems, hardening, and other concepts discussed in Chapter 11.
• Internal attacks Separation of duties and least privilege can help reduce the likelihood of internal attacks.
• Privilege escalation System vulnerabilities, incorrectly configured roles, or software bugs can result in situations where malicious code or an attacker can escalate their privileges to gain access to resources that they are unauthorized to access.
• External role change Role change policies should extend out to procedures and practices employed to change authorizations for users to match changes in job roles for employees.
• Incorrect hardening settings Hardening, discussed in Chapter 11, reduces the risk to devices.
• Weak or obsolete security technologies Security technologies age quickly. Those technologies that are out of support may not receive vendor patches and will be unsafe to use in the protection of corporate assets.
This section explores three common security topics in more detail, along with scenarios that utilize CompTIA’s troubleshooting methodology to help you become familiar with the process in practice. These topics include authorization and authentication issues, malware, and certificate issues. Lastly, certificates are used to secure communication between devices and verify the identity of communication partners. When certificates or the systems around them fail, communication failures are sure to follow, significantly affecting business operations.
Insufficient Security Controls and Processes
Security controls are technologies, procedures, or services that reduce security risk. As you can imagine, there are a wide variety of security controls. They are generally divided into three types as follows:
• Preventative controls
• Detective controls
• Corrective controls
Preventative Controls Preventative controls are designed to stop harmful activity from occurring. Some examples include firewalls that block malicious traffic from entering the network, encryption that prevents other parties from viewing data or a communication stream, hardening that closes unused ports and disables unused services, or patch management that keeps systems up-to-date with fixes for discovered vulnerabilities in software.
Insufficient preventative controls increase the likelihood that an attacker will exploit the area the control is designed to protect against. Table 15-1 shows the example preventative controls, action they perform, and potential results of insufficient controls. Some controls perform actions that fit into multiple categories, such as antimalware software that both detects and corrects malware by identifying it and then removing it.
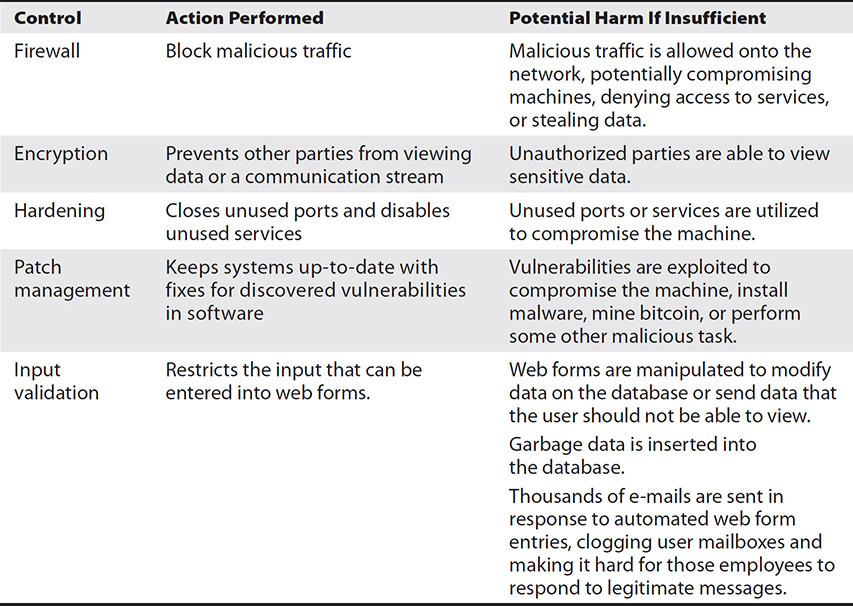
Table 15-1 Preventative Controls and the Harm They Prevent
Detective Controls Detective controls are designed to identify and alert on harmful activity. For example, DLP would alert on activity that violates policies. It could also be configured to block such activity, so it would fall into a preventative control as well. Similarly, Internet filtering can detect attempts to access restricted Internet content that could contain harmful material, but it can also be configured to block that access. The mode that each of these runs in can be audit only or audit and protect.
Insufficient preventative controls result in the company being unaware of ongoing attacks or misuse of company resources. Table 15-2 shows the example preventative controls, the action they perform, and the potential results of insufficient controls.

Table 15-2 Detective Controls and the Harm They Prevent
Corrective Controls Corrective controls are designed to bring systems or data back to a normal operating state following a security event. Some corrective controls include antivirus software that removes malware for which it has a signature, backup software that restores data or systems, and patch management that applies fixes for known vulnerabilities.
Insufficient corrective controls increase the harm of a security event, including loss of data, extended system outages, or more expensive recovery. Table 15-3 shows the example corrective controls, the action they perform, and the potential results of insufficient controls.
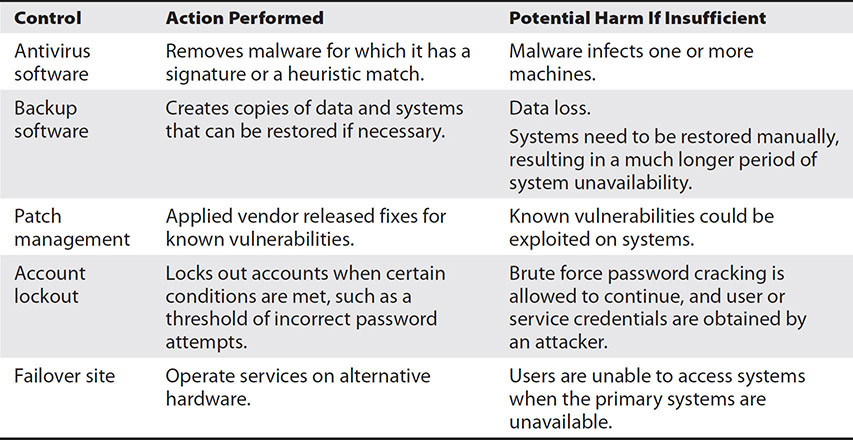
Table 15-3 Corrective Controls and the Harm They Prevent
Privilege Issues
Privileges are the rights to perform actions on an information system. Privileges can be assigned to users or other entities, such as service accounts. These privileges may allow users to access files, run programs, or use services.
Privilege issues can sometimes arise when employees change positions and their privileges are not correctly updated. It could also happen when files are restored and older permissions are restored with them, or permissions are not carried along with the restored files. Whatever the cause, permission issues result in a lack of access to resources that affect authorized user or system activities.
Privilege issues may reveal themselves when a user or service attempts to perform an action that they are authorized to perform, but they cannot do so. For example, a user may try to access a share that they are supposed to be able to access, but they are given an access denied error. Service accounts can also cause issues. Service accounts are created for very specific uses, and their permissions are usually granularly defined. However, as needs change, so must the permissions. These privileges would need to be updated to grant the permissions to resources a service account can access and what the service can do with that resource.
Let’s demonstrate the CompTIA troubleshooting methodology with a scenario: A service account is used to log into a database server. It issues queries to three databases. The service can add data to the tables of one database but cannot modify the table structure. This account works fine for operating the application, but upgrading the application results in an error stating that tables could not be updated.
Step 1: Identify the problem. The application upgrade fails when updating tables.
Step 2: Establish a theory of probable causes. You theorize that this could be due to a permissions issue with the person running the upgrade or with the service account. You run a trace on the database as the application is upgraded. You identify the account used to perform the upgrade and the queries that fail. The queries are related to adding new fields.
Step 3: Test the theory to determine the cause. You review the permissions for the account and find that it does not have permission to modify the table structure, and adding new fields is a change to the structure.
Step 4: Establish a plan of action to resolve the problem and implement the solution. ou recommend that an account with permission to modify the table structure should be used to install the application. Management agrees, and you put in a service ticket to have an account created with the appropriate permissions and roles. Once the account is created, you provide the credentials to the application team.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. The application team reports that the application installs correctly with the new credentials. You confirm that the application upgrade is complete and then submit a ticket to have the account disabled until the application team needs it again.
Step 6: Document findings, actions, and outcomes. You document the account that needs to be used for application updates and the process that must be followed to enable the account.

EXAM TIP In this example, you could add the permissions to the account that runs the application, but this would not be the best approach. The application does not need that permission regularly, and something that exploited the application or service could use that to modify the table structure and do more harm to the application. It is best to exercise the principle of least privilege in both user and service accounts.
Security Groups Permissions are typically assigned to a group associated with a role rather than giving permissions directly to a user account. This makes it easier to add others to a role because they can just be added to the group, rather than copying all the permissions assigned to another user. Similarly, making changes to the permissions can be done in one place, rather than for each user that has access. However, security groups can become complex to troubleshoot when users are members of many groups and those groups have overlapping permissions.
In most systems, permissions are cumulative unless a deny permission is applied. Let’s look at an example. You will likely find that as systems grow over time, some convoluted data organization methods can evolve that result in some cumbersome privileges. Consider a situation where Todd is unable to access the R&D share. Todd is a member of the employees and management groups. Figure 15-3 shows the folder structure for the company data.

Figure 15-3 Shared folder structure
This data is stored within OneDrive, and permissions to the folders are assigned to groups. The folder permissions for each group are shown in Figure 15-4.

Figure 15-4 Folder permissions
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Todd is a member of the employees and management groups, but he would not be able to access the R&D share because the deny read and write permission from his membership in the employees group would override his read permission as a member of the management group. You could resolve this by removing Todd from the employees group, but this could cause issues with other resources he needs to access. The best thing to do would be to move the R&D folder out from under the general share. The employees group could then be removed from the permissions on the R&D folder so that a deny permission would not be required there.
Authorization and Authentication Issues
Authentication is the process of validating an identity, and authorization validates that the identity has the required privileges to perform the requested action. Authorization and authentication issues include scenarios such as systems that are deployed without proper service accounts or account lockouts.
Authentication issues can be as simple as users locking their accounts by entering their credentials incorrectly several times consecutively. The user’s account will need to be unlocked before they can access network resources. If many users report permission problems, check services like DNS and Active Directory, or LDAP on Linux servers, to verify that they are functioning. Problems with these services can prevent users from authenticating to domain services.
Consider a scenario where a user reports that they are unable to log into their Office 365 mailbox and their OneDrive but they can access other resources.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Malware
Another security issue you might face is the presence of malware. Malware impact can range from low, such as malware that slows a machine, to high-risk malware that results in a data breach. Malware infects machines through infected media that is plugged into a computer or other device, through website downloads or drive-by malware that executes from infected websites, or malicious ads known as malvertizing. Malware is also distributed through a variety of methods, as shown in Figure 15-5.
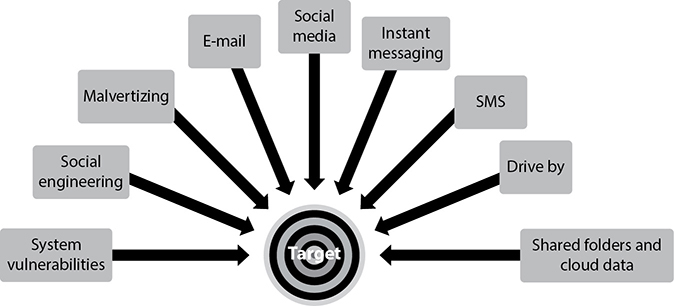
Figure 15-5 Malware distribution methods
Computers infected with malware might run slowly or encounter regular problems. Ransomware, a particularly troublesome form of malware, encrypts data on the user’s machine and on network drives the machine has write access to.
Let’s demonstrate the CompTIA troubleshooting methodology with a scenario: Aimee, a cloud security engineer, receives reports that user files are being encrypted on the network.
Step 1: Identify the problem. Files are being encrypted on the company NAS. Access logs from the NAS around the time of the encryption show connections from a computer called LAB1014. LAB1014 has many encrypted files on its local drive. No other users report encrypted files on their machines, and a spot check by another administrator confirms no encrypted files on a sample of other devices.
Step 2: Establish a theory of probable causes. This could be due to a rogue script or ransomware running on LAB1014.
Step 3: Test the theory to determine the cause. Both theories have the same response. LAB1014 needs to be quarantined immediately so that the problem does not spread and continue. If it is the cause of a rogue script, the activity will cease after LAB1014 is quarantined. If it is the result of ransomware, the LAB1014 will continue encrypting files on its local drive, but uninfected machines on the network and the NAS will continue operating normally.
Step 4: Establish a plan of action to resolve the problem and implement the solution. The first step is to isolate LAB1014 from the network so that it cannot infect any other machines. Next, check other computers, starting with devices that were connected to the infected machine, such as file servers or departmental servers and surrounding workstations. Isolate all machines that have malware on them.
Next, make a forensic copy of LAB1014 in case an investigation is required. Once the forensic image is verified, you can begin identifying the malware through virus scanning and removing the malware using virus scanning tools or specific malware removal tools. It is best to scan the LAB1014 computer with installed antivirus tools and with bootable media that can scan the machine from outside the context of the installed operating system. Sometimes malware tricks the operating system into thinking parts of its code are legitimate. It might even tell the operating system that its files do not exist. Virus scanning tools installed on the operating system rely on the operating system to provide them with accurate information, but this is not always the case. Bootable antivirus tools work independently from the operating system, so they do not suffer from these potential limitations.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Verify that the ransomware has been removed from LAB1014 and any other machines that may have been identified as containing ransomware in the course of troubleshooting and that new devices are not being infected. Next, restore data to the machines where data was encrypted.
Step 6: Document findings, actions, and outcomes. Create a report of the impact and actions taken.
Key and Certificate Issues
Certificates are used to encrypt and decrypt data, as well as to digitally sign and verify the integrity of data. Each certificate contains a unique, mathematically related public and private key pair. During the standard authentication process to a website, a client is presented with a certificate from a website. It then verifies that the certificate is in its trusted root store, thus trusting the certificate was signed by a trusted certificate authority. Afterward, the client confirms that the certificate is coming from the correct web server.
When the certificate is issued, it has an expiration date; certificates must be renewed before the expiration date. Otherwise, they are not usable. Expired certificates or certificates that are misconfigured can make sites unavailable or available with errors for end users.
Misconfigured certificates include sites that have a different name from their certificate, such as a site with the URL www.example.com configured with a certificate, for example.com. The missing “www” in the certificate name would result in certificate errors for site visitors.
Consider a scenario with a certificate issue and how the CompTIA troubleshooting methodology could be applied to resolve the issue: Users report that the company website shows security errors and customers are afraid to go to the website. Some customers on Twitter are saying that the company site has been hacked.
Step 1: Identify the problem. You open the site and see that the site is displaying a certificate error.
Step 2: Establish a theory of probable causes. The certificate either is expired or has been revoked.
Step 3: Test the theory to determine the cause. View the certificate on the web server to see if it is expired. If it is not expired, check the certificate revocation list (CRL) to see if it has been revoked. In this case, the certificate expired.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Discuss renewal of the certificate and receive approval to perform the renewal and a purchase order to purchase the certificate renewal. Complete the renewal of the server certificate.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Log onto the site to confirm that certificate errors are no longer displayed.
Step 6: Document findings, actions, and outcomes. Identify all certificates in use at the company and when they expire. Discuss which ones are still required and establish a process to review certificates needed at least annually. Next, create a schedule with alerts so that certificates are renewed before they expire. Share the schedule with management so that they can budget for the certificate renewal cost.
Misconfigured or Misapplied Policies
In this context, policies do not refer to documents, but to rules given to security systems. Some of these include
• DLP Data loss prevention (DLP) uses policies to define acceptable and unacceptable ways of working with data.
• IAM Identity access management (IAM) systems have policies that define how resources can be accessed.
• IDS/IPS IDS/IPS systems have policies that define the actions taken when traffic matches a signature.
• Remote access VPN and other remote access technologies, such as Microsoft’s Remote Desktop Gateway, have policies that define conditions that allow access, such as group membership, location, or time.
Table 15-4 shows each of these systems and some of the issues that could arise with misconfiguration or misapplication of policies.
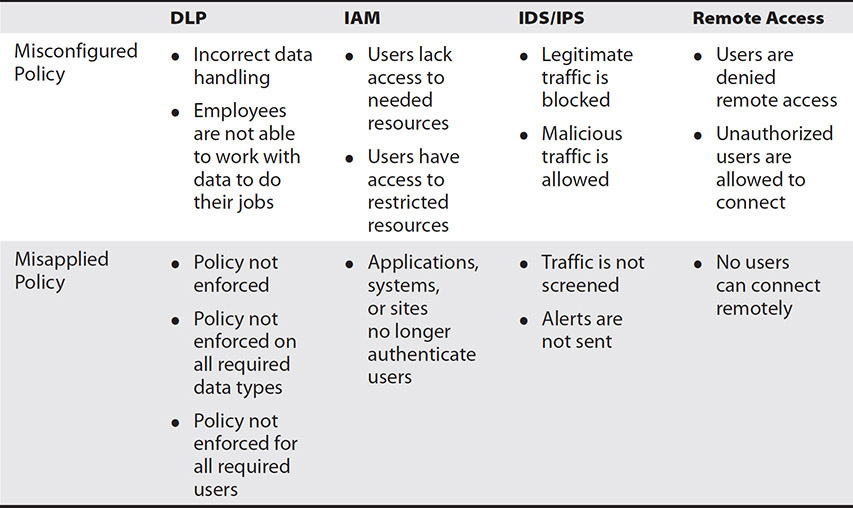
Table 15-4 Misconfigured or Misapplied Policies
Exercise 15-1: Using the Google Cloud Policy Troubleshooter
In this exercise, we will create the Google Cloud Policy Troubleshooter to determine if an account has the required permissions for a resource under the current IAM policies. The tool will show whether the user can perform the selected action and which policies give them that right. If they do not have permission, it will state that access is denied and then specify the required role the user would need to be able to perform the action.
1. Log in to your Google Cloud Platform and then click the menu button in the upper left. Select IAM & Admin and then Policy Troubleshooter.

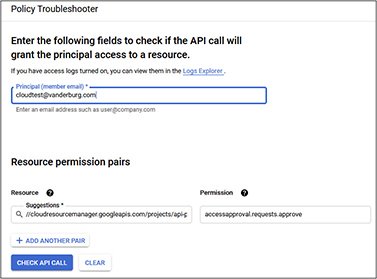
2. The Policy Troubleshooter screen will load. Type in a user account to test and then select the resource and the desired permission. This will test to see if the user account entered can perform that action on the resource. For this example, I have selected a sample account [email protected]. We will see if the account has the ability to approve requests through the cloud resource manager API. To do this, we entered the e-mail shown and then selected the cloud resource manager API and the accessapproval.requests.approve permission.
3. Click Check API Call. The troubleshooter will then assess whether that account has the selected access. In this example, the account does not have access. It shows that the role required for that permission is the owner role and that there is currently only one member of that role. The member has been blurred to protect privacy, but it is the value following “user:,” shown here.
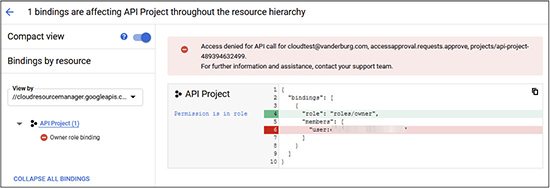
If we were having difficulty with this account performing approvals using the API, one solution would be to add them to the owner’s role. However, this role likely contains permissions that the user does not need, so the best solution would be to create a new role and then assign the permissions to that role and grant the user that role.
Data Security Issues
A major component of security is protecting the data on systems from compromise, including unauthorized access, deletion, or corruption. Data security issues are those that result in some compromise of the data. Some data security issues you should be aware of are as follows:
• Unencrypted data Sensitive data transmitted or stored in an unencrypted format could potentially be exposed to unauthorized parties. For example, a backup tape containing sensitive information is lost, and the tape is not encrypted.
• Data breach When data is stolen from a company, it is known as a data breach. Data breaches require an investigation to determine the scope and impact of the breach and root causes so that those can be remediated. For example, a customer service rep opens a phishing e-mail containing a malicious attachment that provides access to an attacker. The attacker then uses the customer service rep’s credentials to retrieve the personal information on customers from the company database.
• Misclassification Data classifications are used to properly handle data. However, if the data is misclassified, incorrect handling rules and procedures will be applied to it. For example, controlled unclassified information (CUI) is received and misclassified as normal data. DLP policies based on the data classification tags are then not applied to it.
• Unencrypted protocols We have covered a wide variety of protocols used for communication over the Internet, on a local network, over VPNs, and back-end storage networks. Some of these protocols used encryption to protect the data in transit, while others were unencrypted. A data security issue could arise when an unencrypted protocol is used to send sensitive data over a public Internet link or a shared medium.
• Insecure ciphers A cipher is a mathematical formula used to convert plaintext (unencrypted) data into ciphertext (encrypted data). As ciphers age, weaknesses in their implementation are sometimes discovered that render them unsafe to use. In other cases, the power of computing renders them obsolete because faster computers may break the encryption using brute force methods.
Exposed Endpoints
Endpoints can be exposed to security threats if they are misconfigured, lack security updates, or lack essential security software such as host-based firewalls and antivirus protection. An exposed endpoint can lead to the compromise of the credentials of users on the machine or data that resides on the endpoint.
Misconfigured or Failed Security Appliances
Security appliances are hardware or virtual appliances that are used to secure the network infrastructure and systems. Misconfigured devices may not provide the level of security needed, or they could prevent legitimate services from operating correctly. This section discusses issues that could be seen with IDS/IPS, NAC, and WAF.
• IDS/IPS A misconfigured intrusion prevention system (IPS) or intrusion detection system (IDS) could result in blocked traffic or false alarms on traffic.
• NAC Misconfigured network access control (NAC) could result in machines that do not meet the NAC policy to connect, or it may block legitimate connections that do meet the NAC policy.
• WAF Web application firewalls (WAFs) screen traffic destined for web applications. A misconfigured WAF could block legitimate traffic or allow unauthorized traffic to the site. For example, suppose an administrator wants to remove encrypted HTTP access for a website used to accept customer orders. They log into the firewall and remove the access control list (ACL) that allows HTTPS traffic rather than the one for HTTP.
Deployment Issues
Application deployment issues are relatively commonplace. Most applications will be deployed without issue, but you will deploy so many apps that deployment issues will be something that you see quite often.
Missing or Incorrect Tags
Tags can be used to represent resources in the cloud. Policy rules can be defined on the tags to more efficiently manage the resources. For example, you could tag each IP that represents a web server. Then, you could deploy a new version of Apache to each system with the web server tag. However, you can run into a real mess if tags are missing or if the wrong devices are tagged.
Imagine deploying the wrong software or code to machines. You could have servers with completely different roles running software that serves no purpose. This creates an attack surface on those machines that would likely not be protected by appropriate controls. The machines that really do need the software would not have it, resulting in services that would not work properly.
Troubleshooting this would require verifying tags against system documentation to ensure that the correct machines are tagged. You would also want to check the change management system to see which changes were made recently to the tags and cross-reference this with the logs. The system might show that 192.168.1.60 was added to the web servers, but the logs show that 192.168.1.50 was added. You could then remove 50 and add 60 to correct the problem.
Application Container Issues
When deploying containers, there are a wide range of issues you might encounter. One issue you might face is incompatible host and container images. The base image version of a container must match the OS of the system you are deploying it to. If the versions do not match, the deployment will fail or will not operate correctly. Failed deployments will have the following error code: 0xc0370101.
Host and container image versions must match because the host and the container share a single kernel. On Windows, the versions must match at the build level. You can check the version of the container and the host to compare. You can query the version of a system with the ver command at the command prompt, as shown in Figure 15-6.

Figure 15-6 Querying the Windows version
Windows build numbers are divided into four sections, as shown in Figure 15-7. The first three sections must match. These are the major, minor, and build numbers. The revision numbers can differ.
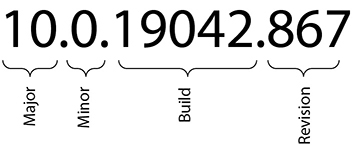
Figure 15-7 Windows version breakdown
Another issue you might see is attempting to deploy a container from a missing or mistyped image. If you encounter this, verify that the specified image exists at the location specified and that you typed the name correctly.
You will need to have enough resources available to deploy the image. If you lack sufficient CPU or memory, the container deployment will fail. If you encounter errors related to resource availability, try one of the following:
• Deploy the container to a different host
• Reduce the CPU or memory specified for the container
• Reduce the CPU or memory of other containers on the host
• Migrate other containers to a different host
Incompatible or Missing Dependencies
Missing or incompatible dependencies can make an application fail to install or not work correctly. They can also cause software upgrades to fail. For example, you may want to upgrade the version of WordPress running on your hosted site, but the upgrade fails because it requires an upgrade to PHP and MySQL first.
When deploying a web application, ensure that programming libraries are installed first. Windows applications written in a .NET programming language such as C# will require a particular version of .NET on the machine. Other applications may require PHP or Java to be installed. Read through deployment documentation carefully to ensure that you meet all the requirements. Of course, you will also need Internet Information Services (IIS) and any other operating system roles and features. Ensure that all this is in place before application installation.
The Java Runtime Environment (JRE) can be particularly troublesome when running multiple Java-based applications on the same machine because they might not all support the same version. For example, three applications are installed on the server, and you upgrade the first one. You read through the documentation before upgrading and find that you need to update the Java version first. The Java upgrade completes successfully, and then you deploy the new version of the application. Testing confirms that the new app works fine, but a short time later, users report that the other two applications are no longer working. Upon troubleshooting, you find that they do not support the new version of Java that was deployed.
The most straightforward fix to this issue is to deploy dedicated VMs for each application. You can also use application containers to host each application so that dependencies can be handled individually for each container. Containers are more lightweight, quicker to deploy (less disk space, since OS is generally not in the container), and start up much more quickly than VMs.
Now that you understand the potential problem, let’s try a scenario: You have been asked to set up a new website for your company. You purchase a hosted cloud solution and create a host record in your company’s hosted DNS server to point to the hosted cloud server’s IP address. You test the URL and see the default setup page. You then use the cloud marketplace to install some website applications and themes. However, when you navigate to your website, you now receive the following error message:
Warning: Creating default object from empty value in customizer.php
Step 1: Identify the problem. New applications and themes were installed since the site last came up correctly, so the error is most likely related to the latest software and themes.
Step 2: Establish a theory of probable causes. You research the error online and see issues relating to missing PHP files. You theorize that PHP is installed incorrectly or that the PHP dependency is missing.
Step 3: Test the theory to determine the cause. To test these theories, you can reinstall PHP on the server or install it if it is missing. You first identify the required level of PHP from the software that you installed earlier. Then you log onto the cloud server and check the PHP version. You find that PHP is not installed, so it seems like installing the required PHP version will solve the problem.
Step 4: Establish a plan of action to resolve the problem and implement the solution. You log into the cloud management portal and go to the marketplace. After locating the PHP version required by the software, you review the release notes to determine if it is compatible with your other software and system. You find that your cloud vendor maintains a database of compatible applications and software, and it has already queried your systems and noted that this version of PHP is compatible with your cloud installation.
You place a change request to install PHP and include relevant documentation on why the software is needed. Once the change request is approved, you proceed to install the software from the marketplace and then verify that the software installs correctly.
Note that because this is a new installation, no users are accessing the site. If this were a production site, installing a significant dependency like PHP would take the site down, so you would need to perform the install in a downtime.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. You open a web browser, navigate to the company website URL, and verify that you can access the site. The installation of the PHP dependency solved the problem. Additionally, you find that you can enable the system to automatically install dependencies in the future so that you can avoid such a situation. You create another change request to enable this feature and wait for the approval. Once approval is provided, you enable the feature.
Step 6: Document findings, actions, and outcomes. You update both change request tickets to indicate that the work was completed successfully and that no other changes were required. Additionally, you send a memo to the other team members noting the issue and what was done to resolve it and that dependencies will be installed automatically moving forward.
Integration Issues with Different Cloud Platforms
Cloud applications typically do not reside on their own. They are often integrated with other cloud systems with APIs. A vendor will create an API for its application and then release documentation so that developers and integrators know how to utilize that API. For example, Office 365, a cloud-based productivity suite that includes an e-mail application, has an API for importing and exporting contacts. Salesforce, a cloud-based customer relationship management (CRM) application, could integrate with Office 365 through that API so that contacts could be updated based on interactions in the CRM tool. However, APIs must be implemented correctly, or the integration will not work.
Let’s try the CompTIA troubleshooting methodology with a scenario: You receive an e-mail from Microsoft informing you of a new API that works with Salesforce. You log into Salesforce and configure Salesforce to talk to Office 365. You educate users on the new integration and that contacts created in Salesforce will be added to Office 365 and that tasks in Salesforce will be synchronized with Office 365 tasks. However, a user reports that their contacts are not being updated and that tasks are not being created. You also find when opening your tasks that there are hundreds of new tasks that should belong to other users.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Script Misconfiguration
Deployment scripts need to be absolutely correct, or they will deploy the wrong thing or fail altogether. Scripts can be developed for a wide variety of applications, but it is a best practice to build in checks so that changes can be validated as the script executes. If a step in the process fails, the script should be able to roll back the changes and send notifications to appropriate personnel to investigate. Developing scripts like this takes much more time, but it can help avoid many headaches in the future and provide additional details when troubleshooting. Ensure the following to help avoid or prevent script misconfiguration issues:
• Referencing the right objects Ensure that object names are correctly spelled and that they exist.
• Using accounts with the necessary privileges The script will need to use accounts that have sufficient privileges to perform the operation.
• Referencing the right resources Ensure that the resource names are correctly spelled, that they exist, and that there are sufficient resources for the operation. Some resources include storage locations, network security groups, or virtual networks.
• Correct networking Ensure that the script configures the correct networking settings for the desired deployment location. This is easier if you are using DHCP, but in many cases, servers will not use DHCP so you will need to ensure the IP address, subnet mask, and default gateway work on the deployment network.
• Deploying resources in the correct order Ensure that you create each resource so that dependencies are met.
If your script fails, check your logs to see which step in the process failed. For example, you may find that a step for creating the database fails, so you would then check the logs on the database. If those logs show that the database drive is full, you could correct that issue and then try the script again.

CAUTION Be sure to clean up or roll back changes your script may have made if it fails before fully completing. These changes, if not rolled back, could prevent the script from running in the future.
Consider a scenario where you attempt to run a deployment script but encounter an AuthorizationFailed error. For this scenario, use the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Incorrect Configuration
Computer programs need to be configured perfectly for them to run. There is really no margin for error. An extra character in a UNC path or a mistyped password is all that is required for the program to crash and burn. It is important to double-check all configuration values to ensure that they are correct. If you run into issues, go back to the configuration and recheck it, maybe with another person who can offer some objectivity. Compare configuration values to software documentation and ensure that the required services on each server supporting the system are running.
Let’s look at this in a scenario and consider how the CompTIA troubleshooting methodology would help in solving a configuration issue: Your company is consolidating servers from two cloud environments into one for easier manageability. The transition team is responsible for moving the servers and the shares. The transition team successfully moves the servers to the new location and consolidates the shares onto a single server. A web application retrieves files from one of the shares, but users of the site report that they can no longer access files within the system. You are part of the troubleshooting team, and you are assigned the trouble ticket.
Step 1: Identify the problem. The problem is that users cannot access files in the application. You send a message to the user base informing them of the problem and that you are actively working to resolve it.
Step 2: Establish a theory of probable causes. Several changes were made when the servers were moved over from one cloud to another. The servers were exported into files and then imported into the new system. Each server was tested, and they worked following the migration. You check the testing notes and verify that the website was working correctly following the migration. The shares were consolidated after that. However, you do not see testing validation following the share consolidation. It is possible that the application is pointing to a share that no longer exists.
Step 3: Test the theory to determine the cause. You log into the server hosting the application and review the configuration. The configuration for the files points to a UNC path. You attempt to contact the UNC path but receive an error. You then message the transition team, asking them if the UNC referenced in the application still exists or if it changed. They send you a message stating that the UNC path has changed, and they provide you with the new path.
Step 4: Establish a plan of action to resolve the problem and implement the solution. You plan to change the application configuration to point to the new path. You put in a change request to modify the application configuration, and the change request is approved. You then adjust the application settings, replacing the old UNC path with the new one.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. You log into the site and verify that files are accessible through the application. You then reach out to several users and request they test as well. Each user reports that they can access the files successfully. Finally, you message the users and let them know that the issue has been resolved.
Step 6: Document findings, actions, and outcomes. You update the change request ticket to indicate that the work was completed successfully and that no other changes were required. Additionally, you send a memo to the transition team members noting the issue and what was done to resolve it. Management then creates a checklist for application transitions that includes a line item for updating the UNC path in the application if the back-end share path changes.
Template Misconfiguration
When an organization is migrating its environment to the cloud, it requires a standardized installation policy or profile for its virtual servers. The VMs need to have a similar base installation of the operating system, so all the devices have the same security patches, service packs, and base applications installed.
VM templates provide a streamlined approach to deploying a fully configured base server image or even an entirely configured application server. VM templates help decrease the installation and configuration costs when deploying VMs and lower ongoing maintenance costs, allowing for faster deploy times and lower operational costs. However, incorrectly configuring templates can result in a large number of computers that all have the same flaw.
Now that you understand the potential problems, let’s try a scenario: Karen is creating VM templates for common server roles, including a web server with network load balancing (NLB), a database server, an application server, and a terminal server. Each server will be running Windows Server 2016 Standard. She installs the operating system on a VM, assigns the machine a license key, and then installs updates to the device in offline mode.
Karen applies the standard security configuration to the machine, including locking down the local administrator account, adding local certificates to the trusted store, and configuring default firewall rules for remote administration. She then shuts down the VM and makes three copies of it using built-in tools in her cloud portal. She renames the machines and starts each up.
She then installs the server roles for web services and NLB on the web server, SQL Server 2016 on the database server along with Microsoft Message Queuing (MSMQ), SharePoint on the application server, and Remote Desktop Session Host services on the terminal server. She applies application updates to each machine and then saves the virtual hard disks to be used as a template.
A month later, Karen is asked to set up an environment consisting of a database server and a web server. She uses the built-in tools in her cloud portal to make copies of her database and web server templates. She gives the new machines new names and starts them up. She then assigns IP addresses to them. Both are joined to the company domain under their assigned names. However, server administrators report that the servers are receiving a large number of authentication errors.
Step 1: Identify the problem. The servers are receiving a large number of authentication errors.
Step 2: Establish a theory of probable causes. Karen theorizes that the authentication errors could be caused by incorrect licensing on the machines or by duplicate security identifiers.
Step 3: Test the theory to determine the cause. Karen issues unique license keys to both machines and activates them. However, the authentication errors still continue. She then clones another web server and runs Sysprep on it. She adds it to the domain and observes its behavior. The new machine does not exhibit the authentication errors.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Karen proposes to remove faulty machines from the domain, run Sysprep on the defective machines to regenerate their security identifiers, and then add them back in. She puts change requests in for each activity and waits for approval. Upon receiving authorization, Karen implements the proposed changes.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Server administrators confirm that the authentication errors have ceased after the changes were made.
Step 6: Document findings, actions, and outcomes. Karen updates the change management requests and creates a process document outlining how to create templates with the Sysprep step included.
CSP/ISP Outage
An outage with a cloud service provider (CSP) or an Internet service provider (ISP) may result in some of your systems being unavailable to users. Check the website of the CSP or ISP to see if they are experiencing an outage. Sometimes downed limbs in bad weather or construction mistakes can break buried or hanging network cabling. Similarly, power outages at your ISP could prevent them from operating. If you do not see a notice, create a trouble ticket with them, describing the outage and any other details you have, such as subscriber ID or site ID.
If you have a business continuity plan, this is the time to enact it. You may need to fail resources over to a different region or availability zone. If you have redundant services running on multiple clouds, switch to an alternative cloud to continue service. Internal users may need to use another method for accessing the Internet, such as hotspots. Enact these measures while staying in contact with the CSP or ISP so that you can switch back to normal operations once service has been restored.
Vendor Issues
You could have issues that arise from vendor-supported systems. Not all issues are under your control. The issues could be related to a configuration you have applied, or they could be the result of some issue on the provider’s systems. If so, you will need to be able to accurately describe the issues to the vendor so that they can fix them. It is also helpful to have documentation on what responses your application expects from standard input. Companies will routinely provide testing teams with sheets that show what results should be expected from test searches or transactions involving specific items or users. You may have automated this testing process. If so, check your workflow to identify which parts are failing to provide this information to the vendor.
Some vendor issues you might experience include vendor or platform misconfiguration, integration issues, API request limits, or cost or billing issues.
Vendor or Platform Misconfiguration Vendor or platform misconfigurations can be a big headache for teams deploying new systems or software. If you experience this, start by analyzing log files and monitoring systems to determine where the problem lies. If you suspect that the configuration may be at fault, go back to vendor documentation to verify that you have the system configured properly. Vendors often supply best practice guides for different implementation types, so consider these when deploying and troubleshooting systems. If you do not find your solution on the documentation, consider the following additional resources:
• Reviewing the vendor’s FAQ.
• Checking forums on the vendor or platform. Vendors sometimes have their own official forums, or you can seek out forums where other professionals discuss their systems, problems, and resolutions.
• Create a trouble ticket.
Vendor or Platform Integration Issues Cloud services increasingly are part of a much larger enterprise ecosystem, consisting of multiple clouds and on-premise equipment. This requires a high degree of interoperability between the systems. An upgrade of one cloud or component can sometimes break the integration between these systems.
Stay on top of release notes and updates from vendors on the changes they are making and those they plan to make so that you can ensure that updates are made to other systems that integrate with them. It is also a good idea to try to stick to vendor best practices when configuring the integration. If the vendor has gone through the process of developing a best practice document for the solution, they are invested enough to keep you informed on how those best practices change with updates and additions to their service offering. It can also be much easier to troubleshoot down the road.
Ensure that you are using the same standard on both ends of a connection between clouds. CSPs often support many protocols for communication, but you will need to choose the same one on both ends. Also, make sure that you keep keys and secrets up to date. Expired keys or secrets will not work for encrypting the communication between systems, so those communication sessions will fail. Effective secret management can help keep these up to date with no or minimal effort on your part.
API Request Limits Your cloud provider may set limits on the number of application programming interface (API) requests that will be serviced over time, such as 100 per second or 10 million per month. Requests that exceed these limits will not be processed.
If you are experiencing an API issue, a reasonable place to look is at the request capacity to see if you have hit the limit. You should increase the limit if this is something that you expect to happen again. Alternatively, you could balance requests across multiple APIs. It is a good practice to monitor API usage and capacity to avoid these issues before they happen.
Cost or Billing Issues It is an unfortunate fact that you can have a fine-running solution come to a crashing halt with something as simple as an expired credit card. Make sure you keep billing information up to date in cloud systems so that you can avoid such issues. CSPs often process payments shortly before the renewal date and will notify you of issues or retry payment methods. However, if you do not address the issue before the renewal period, these services may become unavailable.
System Clock Differences
Networked computer systems rely on time synchronization to communicate. When computers have different times, some may not be able to authenticate to network resources, they may not trust one another, or they may reject data sent to them.
Using the CompTIA troubleshooting methodology, let’s consider a scenario: Eddie is a cloud administrator managing over 40 servers in a hosted cloud. His monitoring system frequently sends out alerts that servers are unavailable. He restarts the machines, and the problem goes away, but the problem comes back a few days later. He scripts restarts for each of the servers but realizes that this is a short-term fix at best.
Step 1: Identify the problem. Servers lose connectivity periodically.
Step 2: Establish a theory of probable causes. Eddie theorizes that there could be connectivity issues on the cloud backend. There also could be an issue with the template that each of the machines was produced from. Lastly, the machines could be losing time synchronization.
Step 3: Test the theory to determine the cause. Eddie creates a support ticket with the cloud provider and provides the necessary details. The cloud provider runs several tests and reports no issues. Eddie creates another machine from the template and finds that it also exhibits the same problems. However, he is not sure where the problem might lie in the template. Lastly, he configures a scheduled job to run three times a day that sends him the system time for each of the servers.
As he reviews the output from the scheduled job, it becomes clear that the domain controller is getting out of sync with most of the network every few hours. Upon analyzing the configuration of the servers that go out of sync and the others, he finds that some are configured to obtain their time from the cloud provider NTP server, while others are set to obtain their time from a different server.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Eddie proposes to set all servers to the same time server. He creates a change request documenting the proposed change and receives approval to move forward with the change during a scheduled downtime. He makes the change.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Eddie monitors the output from the scheduled task and confirms that each server remains in sync.
Step 6: Document findings, actions, and outcomes. Eddie documents the NTP server settings on a standard setup configuration document. He mentions the issue in a standup IT meeting the following Friday, and the document is circulated around and placed on the company intranet for reference.
Connectivity Issues
Connectivity issues can create a broad range of problems, since most systems do not operate in isolation. There is a myriad of interdependencies on the modern issues of networking, and connectivity can be a digital monkey wrench that breaks a plethora of systems.
The first indicator that there is a connectivity problem will be the scope of the issue. Because everything is connected, connectivity issues usually affect a large number of devices. Ensure that affected devices have an IP address using the ipconfig (Windows) or ifconfig (Linux) command described later in this chapter. Suppose they do not have an IP address. In that case, it could be a problem with DHCP or with DHCP forwarders or cloud-based virtual network IP address ranges, firewall ACLs, and routing tables.
For example, the DHCP scope could be full, so the administrator might need to expand the scope or reduce the lease interval so that computers do not keep their addresses for as much time. A user may reside in a different subnet from the DHCP server, and no forwarder exists on the subnet to direct DHCP requests to the DHCP server. The connection may be on a different cloud-based virtual network IP address range from the servers it wishes to contact, and there are no rules defined to allow traffic between these ranges. There could be firewall ACLs that need to be defined to allow traffic between two nodes that are not communicating. Lastly, the default gateway or VPN concentrator, if the issue is with a VPN connection, may not have the correct information on the destination network in its routing table.
When identifying the problem, determine the scope by using the ping command described earlier in this chapter. Ping devices on the network starting with your default gateway. If the default gateway pings, try another hop closer to the Internet or to where others are experiencing issues. Try to connect to other devices that report problems as well. If the default gateway will not ping, attempt to ping something else on the same network. If neither will ping, it is likely an issue with the switch that connects both devices. If you can ping the other machine but not the gateway, it might be a problem with the gateway.
Connectivity issues could be part of the CSP’s responsibility, but determining whether it is the CSP’s responsibility or yours requires that you accurately determine the source of the connectivity issue.
Network Security Group Misconfiguration
Users may not be able to connect to resources if they lack the required membership in security groups. For example, suppose users cannot connect to the Azure VPN. You could check the groups the user belongs to and then check the settings in Azure to see if those groups are allowed access. Figure 15-8 shows the Azure VPN compliance policy.
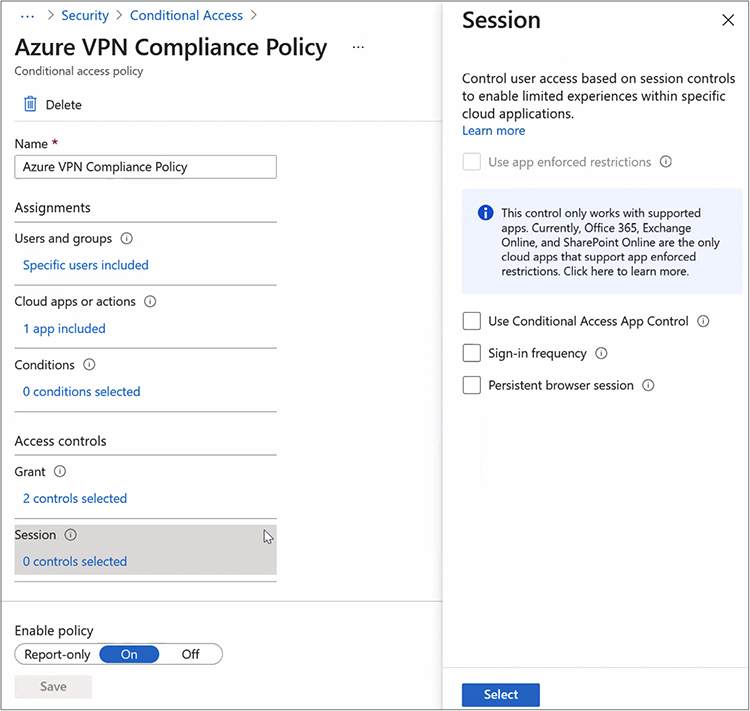
Figure 15-8 Azure VPN compliance policy
ACL Firewalls screen traffic using ACLs. A misconfigured ACL could create a connectivity issue by blocking legitimate traffic. For example, suppose an administrator sees a large number of new connections coming from an IP address, so they block that address. Later, in an IT staff meeting, they find that the DevOps team deployed a new application that started working and then failed for some reason. Upon investigation, the administrator realizes that the IP they blocked was the new application.
Inheritance Inheritance issues can prevent connectivity to files and folders. Inheritance is when the permissions of a higher-level folder are applied to subfolders or files. Permissions on subfolders are inherited by default until different permissions are assigned to those subfolders. However, the subfolders can be changed to inherit permissions again of higher-level folders and overwrite permissions of subfolders.
Sometimes changes to higher-level folders on a file system will be propagated down to subfolders, overwriting more granular permissions. For example, you might have a marketing folder that is only available to the marketing team under a general shared folder. If someone changes the permissions on the general shared folder and forces those permissions to be applied to all subfolders and files, the custom permissions for the marketing folder would be lost.
Network Configuration Issues
Network configuration issues may cause connectivity loss, slowness, or excessive latency in applications. Some network configuration issues to be aware of include
• Peering Incorrect peering will result in a loss of communication between VPCs.
• Incorrect subnet An incorrect subnet will either result in communication over the wrong network if the nearest routing device has connectivity to that subnet or a lack of communication entirely if there is no connectivity to that subnet.
• Incorrect IP address You may accidentally assign a duplicate IP address where either the newly configured machine or an existing machine will lose connectivity. You might also assign an IP address that does not have the correct mappings. For example, firewall rules or other ACLs may be defined for a specific IP address or IP address range. If you assign a different one, these rules will not be triggered for traffic going to and from that system. The same case would occur if tagging has been applied for one IP address, but you assigned a different one.
• Incorrect IP space You may be managing multiple IP address spaces for different sites and subnets. Some administrators use systems like IP Address Management (IPAM) to help manage these IP address spaces. If you assign an IP address for the wrong IP address space, it will not communicate with its network peers.
• Incorrect routing The most common routing mistake is to assign the wrong default gateway. This will result in the computer being able to communicate with its local peers, but not with any external systems. Another issue is the misconfiguration of routing information on routers or firewalls. This will result in packets not being delivered to certain networks.
Firewall Issues
Some firewall issues to be aware of include
• Incorrectly administered micro-segmentation Micro-segmentation isolates application communication by implementing specific rules governing application traffic. Incorrect micro-segmentation configurations can result in a loss of connectivity to the application or to portions of the application. Review the Syslog for blocked connections, or review the application log on the application server for failed connections to troubleshoot or identify such issues.
• NAT issues Network address translation (NAT) allows one or more public IP addresses to be used to service internal addresses. NAT issues could prevent connectivity between internal systems and the Internet. Test NAT for the internal IP address scope and test for source or destination connectivity issues by verifying communication from the outside in and from the inside out. The firewall should show a hit on the NAT rule when connecting. You may need to enable enhanced logging on the NAT rule in testing to ensure that you get this information.
• VPN Issues with a virtual private network (VPN) can result in a loss of connectivity between cloud sites or between users and a cloud. Review the VPN log or console to identify VPN issues. Verify that users or sites have the correct VPN configuration. Ensure also that secrets or keys are updated on both ends.
Load Balancer Issues
Load balancer issues could be the result of misconfiguration of one of the following components:
• Methods Load balancers use a variety of methods to perform their balancing. Some methods differ based on the way they distribute traffic, and others differ based on the services they can offer. Some methods include DNS, database, round robin, SIP, and link load balancing. You will want to pair the method you use with the resources you are load balancing. For example, round robin is often used for load balancing connections between web servers. SIP load balancing would most likely be used for messaging services, and link load balancing would be used for optimizing traffic between multiple ISP links. Database load balancing would be used for distributing traffic across nodes in a database cluster.
• Headers The IP address headers are changed when packets are processed by the load balancers and then sent on to their destination system. Load balancing modifies the X-Forwarded-For, X-Forwarded-Proto, and X-Forwarded-Port portion of the header. Ensure that your end systems are configured to work with this data.
• Protocols There is a wide range of load balancing protocols. Some protocols include Direct Routing (DR), NAT-based, layer 4 tunneling, Source Network Address Translation (SNAT), or HAProxy. You may experience issues with an application if the wrong load balancing protocol is used. For example, simple DR load balancing would not allow for cookie persistence over HTTPS, so an application relying on cookies would not function properly.
• Encryption If you are using encryption, such as SSL/TLS, ensure that load balancers will be able to process this traffic. Load balancing will fail if the load balancers are not configured to handle the decryption of such traffic. Load balancers will need to be able to decrypt the data to properly direct it. They can then be configured to re-encrypt the data on its way to the destination or send data to the back-end systems unencrypted.
• Backends The load balancers need to be configured to send traffic to a set of systems that will receive and process the information. If this is not configured, the load balancer will not be able to properly direct traffic.
• Frontends Firewalls or WAFs will need to be configured to send traffic to the load balancers, not the end machines. If this is not configured, traffic will not be delivered to the load balancers. Similarly, the load balancers will need to be configured to accept the desired traffic. Otherwise, they will reject the traffic.
DNS Record Issues
Domain Name System (DNS) is used to translate the name of a system to its IP address so that devices can communicate with one another. As IP addresses change, DNS will need to be updated to reflect that. Some systems are configured to automatically update DNS entries when DHCP leases change. Others require manual updates. Also, you may advertise some services through DNS, and these will need to be kept up to date if you make changes to the IP addresses of those services.
Another issue you could face is the resolution of stale entries. Stale entries are records for systems that no longer exist. Automated processes can be enabled to remove stale entries from DNS to avoid this issue.
VLAN or VXLAN Misconfiguration
VLANs and VXLANs were discussed back in Chapter 4. Both the VLAN and VXLAN partition a network to create logical separation between subnetworks. Connectivity problems can appear when VLANs or VXLANs are misconfigured. For example, machines must be on the same VLAN or have inter-VLAN routing configured for the two machines to communicate. It is common to configure virtual networks with specific VLANs or to add VLAN tagging to virtual networks. Incorrectly setting these values could allow devices to talk to machines they are not supposed to talk to, and they would be unable to communicate with others. Subnets are usually assigned per VLAN, so if the IP address is configured manually for one subnet on the machine and it is placed on the wrong VLAN, it will not be able to communicate with any of its neighbors.
Let’s demonstrate the CompTIA troubleshooting methodology with a scenario: Geoff configures three VLANs named VLAN1, VLAN2, and VLAN3. He has four servers that are running on a virtual network, and he plans on cloning those servers several times and then assigning the servers to each of the VLANs for use. He performs the clones and then assigns the machines to the appropriate VLANs but finds that they are unable to communicate with one another.
Step 1: Identify the problem. The cloned servers cannot communicate with each other.
Step 2: Establish a theory of probable causes. Geoff determines that the VLANs could be misconfigured, the tagging could be incorrectly set, the virtual switches could be misconfigured, or the IP addresses could be incorrectly assigned.
Step 3: Test the theory to determine the cause. Geoff tries to ping a single server called VM-DC1 from each of the other machines. None of the computers can communicate with the server. Geoff then creates a testing strategy where he will rotate VLANs and test. He explains the strategy to his manager and receives approval to proceed. Geoff then rotates the VLAN that is assigned to VM_DC1 and tries the tests again. He is unable to connect to the machine on any of the three VLANs. Geoff then removes VLAN tagging from the virtual switch configuration on VM_DC1 and receives an IP address conflict on the main VM_DC1 computer. Geoff suddenly realizes that the IP addresses are hard-coded into each of the machines and that they do not correspond to their assigned VLAN.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Geoff documents IP addresses to assign to each of the machines in each VLAN. He then creates a change request to modify the IP addresses for each of the computers and explains why the change needs to be made. Once approval is given, Geoff modifies the IP addresses on each machine as planned.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Geoff verifies that each machine can talk to other devices on the same VLAN and that computers cannot talk to those on other VLANs.
Step 6: Document findings, actions, and outcomes. Geoff notifies his manager that the machines are now functioning. He also updates the change control ticket to note that the change corrected the issue.
Incorrect Routing and Misconfigured Proxies
Internetwork traffic, traffic that moves from one network to another, requires routers to direct the traffic to the next leg of its journey toward its destination. Routers do this because they have an understanding of where different networks reside and the possible paths to reach those networks. Incorrect routing can result in a loss of connectivity between one or more devices. In some cases, a proxy will be used to manage communications between nodes on behalf of one or more members.
Let’s now consider a routing/proxy issue and how it can be resolved using the CompTIA troubleshooting methodology: Pam is responsible for the network infrastructure, but her company recently moved many of the company servers to Amazon Web Services (AWS). A consultant configured VLANs and routing, but cloud administrators report that machines cannot communicate with devices on the Internet. Pam is asked to troubleshoot AWS routing for the VLANs. Pam confirms that devices can communicate with other devices on the same VLAN and that computers cannot communicate with the Internet.
Step 1: Identify the problem. Traffic from VLANs is not being routed externally to the Internet.
Step 2: Establish a theory of probable causes. Pam considers the possible causes and comes up with several theories. The problem could be that routing is not configured for the VLANs. It might also be possible that the default route was removed. Pam also theorizes that access lists could be preventing inside traffic from exiting the network.
Step 3: Test the theory to determine the cause. Pam uses the traceroute command from one of the machines exhibiting the problem to test the path from that machine to google.com, as shown in this example:
C:UsersPam>tracert google.com
Unable to resolve target system name google.com.
Pam issues the nslookup command on google.com to see if she can resolve the name to an IP address. She receives a nonauthoritative answer with an IP address, shown here:
She then issues the traceroute command again with the IP address instead of the name. The traceroute command shows a hop to the local proxy called box.local and then a connection to the default gateway 192.168.1.1, but the connection times out:

Pam disables the proxy to test whether that is the issue and runs tracert again, but the request times out immediately after hitting the default gateway. Pam then logs into the AWS Virtual Private Cloud (VPC) console and observes the Route Tables page. She finds that the main route table was modified to include routes between the subnets, but the route to the virtual private gateway was replaced when these changes were made.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Pam believes the problem lies with the missing route to the virtual private gateway, so she submits a change request to add this route.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Pam’s change request is approved, so she makes the change and then issues a traceroute along with the –d switch to skip resolving host names so that the trace will run faster. She issues the command from the same machine she was using to test and receives this output:

Step 6: Document findings, actions, and outcomes. Pam notifies her manager that the machines are now functional. She then updates the change control ticket to note that the change corrected the issue. See Chapter 4 for more information on routing.
QoS Issues
Quality of service (QoS) is a set of technologies that can identify the type of data in data packets and divide those packets into specific traffic classes that can be prioritized according to defined service levels. QoS was introduced back in Chapter 9. QoS technologies enable administrators to meet their service requirements for a workload or an application by measuring network bandwidth, detecting changing network conditions, and prioritizing the network traffic accordingly. QoS can be targeted at a network interface, toward a given server’s or router’s performance, or regarding specific applications. Incorrectly configured QoS can result in performance degradation for specific services and, consequently, irate users.
Let’s demonstrate how the CompTIA troubleshooting methodology can help resolve QoS issues: Marco is a cloud administrator for Big Top Training, a company that produces fireworks safety videos that are streamed by subscribers from the company’s cloud. Marco has been reading about QoS, and he thinks it can significantly improve the cloud network’s performance. He discusses it with his boss and receives approval to test QoS settings in a lab environment set up on another cloud segment. Marco configures QoS priorities and tests several types of content, including streaming video, data transfers, active directory replication, and DNS resolution. He shows the results of his tests to Dominick, his manager, and they agree to roll the changes out to the rest of the network. A couple of weeks later, the backup administrator, Teresa, mentions that some backup jobs have been failing because they cannot complete in their scheduled time window and are terminated. She suggests that QoS might be the problem because the timeouts started happening the day after the QoS changes were put in place. Dominick tells Marco to look into the problem.
Step 1: Identify the problem. Marco identifies the problem as backups are unable to complete in scheduled time windows.
Step 2: Establish a theory of probable causes. Marco theorizes that the backup issues could be caused by a lack of a backup profile since the lab environment he worked in did not have any backups scheduled for it.
Step 3: Test the theory to determine the cause. Marco walks Dominick through his theory. Dominick suggests that he collect baseline data on traffic from the production network and then use that to build additional QoS rules. Marco collects the data for the baseline and then reviews the data with Teresa and Dominick.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Marco, Teresa, and Dominick find that backup traffic communicates over a port that does not have a QoS rule, as Marco theorized. They also identify five other services that have no QoS rules defined. Hence, they map out priorities for those items as well. The planned changes are put into the change management system, and Dominick schedules a downtime in the evening for the changes to be made. Dominick informs stakeholders of the downtime, and Marco implements the new QoS rules during the planned downtime.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Marco notifies Teresa when the work has been completed, and Teresa manually executes the failing backup jobs to confirm that they do run within the normal time allotted. Marco and Teresa inform Dominick that the jobs now work, and the downtime is concluded.
Step 6: Document findings, actions, and outcomes. Marco creates a QoS document outlining each of the priorities and the traffic that fits into each priority. He also schedules a time to collect a more intensive baseline to confirm that all critical services have been accounted for.
For more information on baselines, see Chapter 10, and for more information on QoS, see Chapter 9.
Time Synchronization Issues
Many network protocols rely on timestamps in order to communicate. They use timestamps to ensure the orderly delivery of packets and to prevent replay attacks. For this reason, computers need to have consistent time so that packets are not rejected.
Computers get their time from the system clock. Administrators can ensure that system clocks are kept in sync on VMs by installing hypervisor guest tools and then enabling time synchronization between host and guest. Virtual, physical, and cloud servers can synchronize time by configuring them to point to an external Network Time Protocol (NTP) server. Each computer will set its time to the time specified by the NTP server. The servers will poll the NTP server periodically to verify that their clocks are still in sync and avoid time synchronization issues.
Proxy Issues
Proxies make connections to resources on behalf of other machines to obscure the source of the connection. Proxied communication may fail if the destination system has blacklisted proxy addresses or proxy communication.
Latency
Latency is the time delay encountered while data is being sent from one point to another. It takes time for the physical impulses that comprise communication over a medium, such as copper or fiber cabling, to travel down the line—latency increases in accordance with the distance between source and destination.
Latency is generally associated with performance, but it can cause connectivity issues if the latency is so high that it exceeds thresholds on either end of the communication. In this case, the communication sessions will time out, and the connection will not be established.
Latency metrics are essential for ensuring responsive services and applications and avoiding performance or availability problems. One way to see the latency between your device and another is to use the ping command, discussed later in this chapter. As you can see in Figure 15-9, each of the pings shows a time in milliseconds (ms). This time is the latency, or how long it took for the ping. There is a summary following all of the pings that shows the minimum, maximum, and average latency for each of the pings.
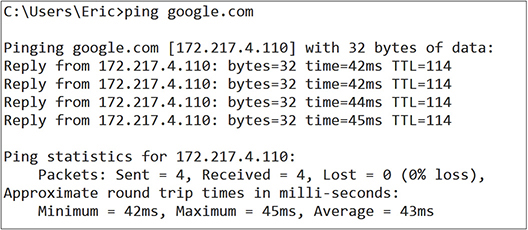
Figure 15-9 Measuring latency with the ping command
Misconfigured MTU/MSS
The maximum transmission unit (MTU) is the largest packet or frame that can be sent over the network. Frames operate at the data link layer, while packets operate at the network layer. Segments also have a maximum size. Segments operate at the transport layer, and their maximum size is specified as the maximum segment size (MSS). MTU and MSS are typically measured in bytes.
Higher-level protocols may create packets larger than a particular link supports, so the TCP divides the packets into several pieces in a process known as fragmentation. Each fragment is given an ID so that the fragments can be pieced back together in the correct order. However, not all applications support fragmentation. When this routinely happens, the solution is to adjust the MSS so that packets are not fragmented. MSS is adjusted because it operates at a higher layer than the frames and packets. Hence, the data provided to the lower-level protocols ends up an appropriate size and does not need to be fragmented.
Let’s look at this in a scenario and use the CompTIA troubleshooting methodology to resolve the situation: You configure a new VPN for your company using L2TP over IPSec. However, performance over the VPN is much slower than expected. You run a packet capture on the data over the network link using the tcpdump tool. You capture packets less than 64 bytes with the following command:
tcpdump < 64
You then you capture packets greater than 60,000 bytes (the max packet size is 65,535 bytes) with this command:
tcpdump > 60000
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Performance Issues
Performance issues can be a nightmare for users and administrators alike. No administrator appreciates receiving tickets for slow systems because it can be challenging to identify which components are contributing to the slowness and what the user means by slow, as some users report slowness when application performance is within normal tolerances. When troubleshooting issues, attention needs to be paid to replication, scaling, applications, and latency.
Replication
Slow replication can cause systems to process requests inconsistently. For example, Active Directory uses replication to keep user, service, and computer account information synchronized between domain controllers. When replication is slow, users who change their password will not be able to log in with their new credentials on all systems until the new credentials have been replicated to all sites.
In transactional systems, such as banking, replication needs to occur before a transaction can be marked complete. Slow replication can result in slow application performance for users. To troubleshoot replication, look at replication logs and test connectivity between replication partners.
Scaling
Applications and systems should scale appropriately with demand. However, suppose an application does not scale or does not scale in a timely manner. In that case, the application will underperform, resulting in a poor experience for users.
Application Issues
Application issues can also result in poor performance. Some application issues include memory management and service overload.
Memory Management Memory management is concerned with providing the required memory to applications and reclaiming memory when the application no longer needs it. Poorly written applications may suffer from one of these issues:
• Memory leaks Memory leaks occur when a program allocates memory for tasks and never releases that memory. This slowly consumes more and more memory as the application runs, and the system will eventually run out of memory. This can cause the application and potentially other applications to crash.
• Memory fragmentation Ideally, a program will release memory before memory allocation processes so that new memory needs can be allocated from the same memory address space. Memory fragmentation occurs when memory is not released quickly enough, so new memory is allocated from a different memory address space. This is less efficient for the application and results in slower application performance.
• Memory corruption Memory corruption occurs when reference variables are not reset. This leaves dangling memory pointers to memory locations that have already been freed.
Depending on the programming language, software developers may be able to use resource management mechanisms so that they do not need to code specific memory allocation and release processes. Monitor memory usage for applications to detect such behavior.
Service Overload Services can become overloaded when they receive more requests than they are equipped to handle. This results in the slow processing of new requests or dropping new requests entirely. Service overload can be prevented by properly sizing resources and properly scaling systems.
You may also experience service overload in a distributed denial of service (DDoS) attack. These can be prevented with DDoS mitigation services. Such services absorb junk traffic and send legitimate traffic on to the application servers.
Latency
As mentioned earlier, latency is the time delay encountered while data is being sent from one point to another. When it is excessive, network latency can create bottlenecks that prevent data from using the maximum capacity of the network bandwidth, resulting in slower cloud application performance.
EXAM TIP Pay close attention to latency metrics to identify latency issues. Many tools will provide latency values, but you can also use the ping command to determine latency between two systems.
Let’s consider a scenario: You recently configured synchronous replication of a key ERP database to another site 2000 miles away. However, the ERP system is now running extremely slowly. Performance metrics on the servers that make up the ERP system show plenty of capacity and very low utilization of system resources. Management is upset and demands a resolution ASAP.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
See Chapter 4 for more information on latency.
Capacity Issues
Capacity issues can be found with compute, storage, networking, and licensing. Considerable attention needs to be paid to the design of compute, storage, and networking systems. The design phase must ensure that all service levels are understood and that the capacity to fulfill them is incorporated into its configurations. Once those configurations have been adequately designed and documented, operations can establish a baseline. This baseline is a measuring stick against which capacity can be monitored to understand both the current demand and trend for future needs.
Capacity issues can result in system or application slowdowns or complete unavailability of systems. Alerts should be configured on devices to inform cloud administrators when capacity reaches thresholds (often 80 percent or so). Define thresholds low enough that you will be able to correct the capacity issue before the available capacity is fully consumed.
Compute
Appropriately distributing compute resources is an integral part of managing a cloud environment. Planning for future growth and the ability to adjust compute resources on demand is key to avoiding compute capacity issues. One potential capacity issue is overconsumption by customers. Because compute resources are limited, cloud providers must protect them and make sure that their customers only have access to the amount that they are contracted to provide. Two methods used to deliver no more than the contracted amount of resources are quotas and limits.
Now that you understand the potential problem, try a scenario: Tim manages the cloud infrastructure for hundreds of cloud consumers. He notices that some of the consumers are utilizing far more resources than they should be allocated.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Storage
Companies are producing data at a rate never seen before. Keeping up with data growth can be quite a challenge. It is best to set thresholds and alerts on storage volumes so that you can proactively expand the storage when they reach a threshold (often 80 percent or so). Set more aggressive thresholds and alerts on physical storage because physical storage cannot be extended as easily on the fly. Physical storage expansion requires the purchase of additional hardware, approval, and other red tape associated with the purchase, shipping time, and installation. You want to make sure that you have enough of a buffer so that you do not run out of space while additional storage is on order.
Let’s demonstrate the CompTIA troubleshooting methodology with a scenario: Sharon, a cloud administrator, receives reports that users are experiencing sluggish performance and slow response times when accessing the company ERP systems that reside in their hybrid cloud.
Step 1: Identify the problem. Sharon identifies the problem as unacceptable application performance.
Step 2: Establish a theory of probable causes. Sharon collects metrics while users experience the issues. She then compares the metrics to the baseline to see if performance is within normal tolerances. The anomalies not only confirm that there is a problem but they tell where the problem might lie. The baseline comparison indicates that disk input/output operations per second (IOPS) are well below the baseline for several LUNs.
Step 3: Test the theory to determine the cause. Sharon isolates the LUNs that are outside of their normal IOPS range. Each of the LUNs was created from the same RAID group, and an analysis of the disk IOPS shows that a RAID group is rebuilding, causing the performance issues.
Step 4: Establish a plan of action to resolve the problem and implement the solution. Sharon discusses the risks and performance hit the rebuild is causing, and her manager agrees that the rebuild can be paused for the two hours that remain in the workday and that they should resume at 5:00 P.M. Sharon pauses the rebuild.
Step 5: Verify full system functionality and, if applicable, implement preventative measures. Sharon confirms that application performance has returned to normal. At 5:00 P.M., she resumes the rebuild, and performance drops for the next few hours until the rebuild completes.
Step 6: Document findings, actions, and outcomes. Sharon documents the experience in the company’s knowledge management system.
Networking
Each device that is attached to the network is capable of generating traffic. A single user used to have only one or two devices attached to the network, but now, many users have a desktop, laptop, multiple tablets, phones, and other devices that may connect through wired or wireless connections. Many of these devices connect to cloud services and request data from them. Some cloud services may be used to keep such systems in sync. The rapid growth of devices and increasing use of cloud services can result in contention for valuable network resources.
Now that you understand some potential network contention problems, let’s try a scenario: You work in the company’s operations center. Metrics show that nodes on a particular network segment are consuming a high amount of network bandwidth. You also receive alerts for many network collisions on the segment, and the network switch for the segment shows spanning tree errors.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Bandwidth
Bandwidth is the network’s speed, measured as how much data can be sent or received over a period of time, such as megabits per second (Mbps). Ensure that your bandwidth is sufficient for the number of concurrent connections you expect to your application and the amount of data that will be sent, on average, to and from these connections.
Oversubscription
If you recall from Chapter 5, oversubscription is where you assign more resources to VMs than are physically available to the system. Oversubscription is possible because not all VMs will require full utilization of these resources simultaneously, so you can make better use of resources through oversubscription.
However, oversubscription can result in contention for CPU resources when multiple machines attempt to utilize all their vCPUs at the same time. This results in reduced performance for the virtual machines and the applications that run on them. For this reason, it is essential to understand what a reasonable oversubscription ratio is. Some of the resources you can oversubscribe include the CPU, GPU, memory, and NIC.
• CPU It is generally safe to maintain an oversubscription ratio of 5:1, with three vCPUs for each physical CPU, so a server with four physical CPU cores could assign up to 20 vCPUs.
• GPU There is no standard oversubscription ratio for GPU. The ratio depends on the GPU model, so you will need to determine the maximum vGPUs supported for the GPUs you are considering.
• Memory It is generally safe to maintain an oversubscription ratio of 1.25:1, with 125 percent of physical memory allocated to virtual machines. Thus, a server with 256GB of memory could assign up to 320GB of memory to virtual machines.
• NIC It is generally safe to maintain an oversubscription ratio of 10:1, but as with other resources, pay attention to network utilization metrics and tweak this if utilization stays consistently high so that you can avoid contention.
Licensing
Purchased software and cloud services operate based on a license. The license grants specific uses of the software for a period. Software typically checks for compliance with licensing and may revoke access to service when the software vendor or cloud provider deems that compliance has not been met. Additionally, groups such as BSA | The Software Alliance (www.bsa.org) can perform license investigations and assess fines for companies that are not in compliance. Hence, companies need to ensure that they are adhering to license requirements.
Software licenses may be per user of the software, or they could be based on the physical or virtual resources that are allocated to the software. For example, some products are licensed based on the number of CPU cores or vCPUs. It is important to know how many CPU cores you are licensed for when assigning resources so that you do not violate your license or cause a program to fail activation checks.
Let’s demonstrate the CompTIA troubleshooting methodology with a scenario: Your organization has a self-service portal where administrators can create new VMs based on VM templates. The portal has been very popular, but now over 500 VMs have been deployed to the environment, and the machines deployed over the last 30 days are unable to activate Windows.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario. We have provided step 1 for you.
Step 1. Identify the problem.
Systems are unable to activate, and the organization may have exceeded available licenses. The company has ten hypervisors in a cluster and 10 Server 2016 data center edition licenses, as well as 100 Server 2016 standard edition licenses. An assessment of the VMs shows that there are 200 CentOS Linux servers and 312 Server 2016 Standard edition servers.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
API Request Limits
In order to guard against abuse or malicious use of APIs, companies set request limits, usually per IP address or subnet. This limits the ability of a single client to utilize too much of the service. Some misuse of API calls might be an attempt to scrape resources, input malformed content to trigger buffer overflows, or disrupt API availability.
Let’s look at this in a scenario and consider how the CompTIA troubleshooting methodology would help in solving a configuration issue: You work for a consulting company as a developer on the DevOps team. Senior leadership has expressed concerns that some consultants may not be billing out all their time. They assume that this is just due to forgetfulness, since many do not enter their time each day, but wait until the weekend to enter most of it. You have developed an application that tracks e-mail usage against calendar entries and time entries to confirm that employees do not forget to put in billable time. The application ties into several APIs designed by the e-mail and time entry software companies. Your application works fine in testing. However, when you deploy it to production, the application works for about 30 minutes and then it ceases functioning. You need to figure out why the application ceases functioning and correct it.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario.
Step 1. Identify the problem.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Automation and Orchestration Issues
Automation and orchestration can be incredibly complex. The advantage of automation and orchestration over manual processes is that automation performs the task the exact same way every time. Unfortunately, things do not stay the same, and processes will need to be updated from time to time.
When automation or orchestration changes, evaluate the process and run a change management report to identify all changes made recently to the resources the automation depends on. Usually, something has changed in the environment that is not reflected in the automation workflow. Some issues that can arise in automation and orchestration include
• Account mismatches
• Change management failures
• Server name changes
• IP address changes
• Location changes
• Version or feature mismatch or deprecation
• Automation tool incompatibility
• API version incompatibility
• Job validation issues
• Patching failure
• Batch job scheduling issues
Account Mismatches
The actions taken in automation and orchestration will require credentials to be performed. Account mismatches happen when the specified service account in the automation or orchestration does not exist or does not have the appropriate privileges to perform the action.
If you receive an account mismatch error, verify all credentials used in the automation to first ensure that they are named correctly; second, ensure that they have the correct permissions; third, check that you have specified the correct password; and fourth, verify that they are not locked out.
Change Management Failures
Change management failures occur when unauthorized changes are made to systems or when authorized changes are not performed. There can be legitimate reasons for why some authorized changes are not made. Several changes could be authorized to be performed in a downtime, but one change may make it impossible for the other change to be made concurrently. For example, assume that a SQL Server version upgrade and a storage LUN expansion on the database server were scheduled for the same downtime. Once the storage team takes the LUN offline for expansion, the database team cannot perform the upgrade because they have no access to the disks.
Unauthorized changes should be avoided if at all possible. The most common occurrence of unauthorized changes occurs when there is an urgent issue that the team is trying to fix. For example, consider a situation where users cannot access the file shares because the DFS root is unavailable. A systems engineer restarts the DFS server and then updates the DFS server’s DNS record to correct the issue. However, neither of these changes were submitted into the change management system, nor were they approved before they were performed. In this situation, the emergency change advisory board should have been called to approve the changes once they were put into the system. In this way, the changes could still be made relatively quickly, but the change management process would still be followed. This helps avoid issues where an urgent issue causes an even greater problem when mistakes are made in the heat of the moment. The change advisory team is better equipped to offer more objective, tactical, and objective feedback.
Server Name Changes
Server name changes can cause problems with automation and orchestration if the related automation and orchestration steps are not also updated. These steps will fail if the named server is not available, or they could perform the steps on the wrong server if another server has been created with the same name as the previous server that was set up for automation.
Be sure to document places where the server name exists so that you can properly update such workflow.
IP Address Changes
IP address changes sometimes happen when the IP addressing scheme changes or when you expand subnets or add more subnets. It is important to update DNS following these changes so that automation and orchestration retrieve the latest IP address for the system. If DNS is not updated following these changes, the automation steps will likely fail.
Location Changes
Changing the location of resources can affect automation and orchestration because the pointers to the resource will no longer be valid. Ensure that you also update the automation steps to point to the correct resource or to point to a new resource in the same region or zone if resources have been moved elsewhere.
You can also run into issues if you move an automation to a new location. The resources and systems there may differ, and the orchestration or automation will likely need to be modified for it to work properly there. It helps to have environments that were configured using Infrastructure as Code (IaC) so that you have greater assurance of the configuration parameters and naming conventions of a site.
Version or Feature Mismatch or Deprecation
Some automation and orchestration steps are dependent upon a specific software version. They may use functionality that is in place in one version but deprecated in a newer version. If that software is upgraded to the point where the functionality is deprecated, the orchestration or automation will fail. You will then need to update the orchestration to use a newer supported function.
It is important to document the automation and orchestration used and to review release notes for new software versions before deploying them to ensure that you update such steps. The change advisory board should help identify items like this before they are approved and implemented.
Automation Tool Incompatibility
Sometimes updates and patches will break automation or orchestration. When this happens, the first place you should look is at the change management system to find out what was changed. If patches were applied, review the release notes for those patches to see if changes were made to functions utilized by automation or orchestration.
API Version Incompatibility
API version incompatibilities result when the CSP or API provider updates their API, but you have not yet updated the automation or orchestration interfacing with that API. If you find that an API suddenly is not working, check the vendor or CSP’s API notes to see if they made changes to it. They should have documentation on what changes are necessary to update your automation or orchestration to continue using it. If you cannot find information on how to update your system, consider contacting the vendor or opening a ticket with them to get more information.
Job Validation Issue
Job validation is the last step in an automation or orchestration. The validation step runs checks on the system to ensure that it is operating as expected. If you are deploying updated software, verify that the current version matches that of the deployed software. If you are updating records, take the number of additional records added and the previous value and compare it to the current number of records to ensure that all were added. If you are manipulating data, check the values to ensure that they are correct.
It is a best practice to build in functions to roll back the changes and send notifications to appropriate personnel to investigate if a step in the validation process fails. Developing automation and orchestration like this will help you avoid many headaches in the future and provide additional details when troubleshooting.
Patching Failure
The application of patches is a commonly automated activity. However, sometimes patch deployments will fail. Since patches often address vulnerabilities, it is important to check to make sure that patches were applied correctly and to all machines that were scheduled for patching.
If a patch fails, try to run the patch again. You may need to roll back other patches or revert to a snapshot before trying the patch again. If it still fails, check the log to see where it is erroring out. A third-party dependency could be causing the issue, or it could be related to resource constraints or contention with running processes. If so, you can update the third-party software, add more resources, or stop contenting processes before performing the upgrade again.
Batch Job Scheduling Issues
Batch jobs can sometimes encounter scheduling issues as data volumes grow, utilization increases, or new jobs are added. These issues can be avoided through proper capacity planning and forecasting.
Now that you understand the potential problems let us try a scenario to see how the CompTIA troubleshooting methodology can help: John is working for a small company that heavily uses cloud services. He has been working for the company for about a month after the previous IT administrator left. The previous administrator automated a number of tasks. John has been receiving an e-mail each morning stating that space has been added to several VMs based on their usage. However, this morning, he received a message that stated the job has failed. When he checked the orchestration, no error trapping was present.
For this scenario, consider the troubleshooting methodology and walk through it on your own. Think through each step. You may need to make some assumptions as you move through the process since this is a sample scenario. We have provided step 1 for you.
Step 1. Identify the problem.
John investigates the hypervisor cluster that the VMs reside on and finds that the virtual disks have been expanded using a large pool on a shared storage device. The logs on the device show expansions corresponding to the e-mails he has been receiving. He also finds alerts in the logs showing that the storage pool is full. John sees that the machines that were expanded each have 25 percent free space. He also finds that there is an additional 2.3TB available on the SAN that hosts the shared storage.
Step 2. Establish a theory of probable causes.
Step 3. Test the theory to determine the cause.
Step 4. Establish a plan of action to resolve the problem and implement the solution.
Step 5. Verify full system functionality and, if applicable, implement preventative measures.
Step 6. Document findings, actions, and outcomes.
Documentation and Analysis
Being able to use the proper tools is a good start when troubleshooting cloud computing issues. Correctly creating and maintaining the correct documentation makes the troubleshooting process quicker and easier. It is important for the cloud administrator to document every aspect of the cloud environment, including its setup and configuration and which applications are running on which host computer or VM. Also, the cloud administrator should assign responsibility for each application and its server platform to a specific support person, who can respond quickly if an issue should arise that affects the application.
When issues come up, cloud professionals need to know where to look to find the data they need to solve the problem. The primary place they look is in log files. Operating systems, services, and applications create log files that track certain events as they occur on the computer. Log files can store a variety of information, including device changes, device driver loading and unloading, system changes, events, and much more.
Documentation
Documentation needs to be clear and easy to understand for anyone who may need to use it and should be regularly reviewed to ensure that it is up to date and accurate. I was once asked to create documentation for an application that was going to be monitored in a distributed application diagram within Microsoft SharePoint. To have a satisfactory diagram to display inside Microsoft SharePoint for the entire organization to view, I needed to collect as much information as possible. The company wanted to monitor the application from end to end, so I needed to know which server the application used for the web server, which server it used for the database server, which network devices and switches the servers connected to, the location of the end users who used the application, and so on.
The information-gathering process took me from the developer who created the application to the database administrator who could explain the back-end infrastructure to the server administrator and then the network administrator and so on. As you can see, to truly document and monitor an application, you need to talk to everyone who is involved in keeping that application operational.
From the documentation, the organization was given a clear picture of precisely what systems were involved with keeping that application operational and functioning at peak performance. It made it easier to troubleshoot and monitor the application and set performance metrics. It also allowed for an accurate diagram of the application with true alerting and reporting of any disruptions. As new administrators joined the organization, they could use the documentation to understand better how the application and the environment work together and which systems support each other.
Documentation should include the application owner, application locations, and device configurations.
Application Owner
Documenting the person responsible for creating and maintaining the application, otherwise known as the application owner, is the first step. This person should be able to tell you the details of the application, such as where it is hosted. The application owner may also be the person who provisions accounts for new users. These are all things that should be included in the documentation. Documenting these items is a good process that saves valuable time when troubleshooting any potential issues with the cloud environment.
Device Configurations
In addition to documenting the person responsible for the application and hosting the computer, an organization needs to record device configurations. This provides a quick and easy way to recover a device in case of failure. By utilizing a document to swap a faulty device and mimic its configuration quickly, the company can immediately replace the failed device.
When documenting device configuration, it is imperative that the document is updated every time a significant change is made to that device. Otherwise, coworkers, auditors, or other employees might operate off out-of-date information. For example, let’s say you are working on a firewall that has been in place and running for the last three years. After making the required changes, you then update or re-create the documentation so that there is a current document listing all the device settings and configurations for that firewall. This makes it easier to manage the device if there are problems later on, and it gives you a hard copy of the settings that can be stored and used for future changes.
Also, the firewall administrator would likely rely on your documented configuration to design new configuration changes. If you failed to update the documentation after making a change, the firewall administrator would be operating off old information and wouldn’t factor in the changes that you made to the configuration.
Configuration management tools are available that can automatically log changes to rule sets. These, along with orchestration tools and runbooks, can be used to update documentation programmatically following an approved change.
Log Files
Logs files are extremely important in troubleshooting problems. Operating systems, services, and applications create log files that track certain events as they occur on the computer. Log files can store a variety of information, including device changes, device drivers, system changes, events, and much more.
Log files allow for closer examination of events that have occurred on the system over a more extended period. Some logs keep information for months at a time, allowing a cloud administrator to go back and see when an issue started and if any issues seem to coincide with a software installation or a hardware configuration change.
Figure 15-10 shows the Event Viewer application for a Microsoft Windows system. The Event Viewer application in this screenshot is displaying the application log, and an error is highlighted for the Microsoft Photos application that failed due to a problem with a .NET module.
Figure 15-10 An error in the application event log
A variety of software applications can be used to gather the system logs from a group of machines and send those records to a central administration console, making it possible for the administrator to view the logs of multiple servers from a single console.
Logs can take up much space on servers, but you will want to keep logs around for a long time in case they are needed to investigate a problem or a security issue. Logs are set by default to grow to a specific size and then roll over. Rolling over overwrites the oldest log entries with new ones. This can cause considerable problems when you need to research what has been happening to a server because rollover can cause valuable log data to be overwritten.
For this reason, you might want to archive logs to a cloud logging and archiving service such as Logentries, OpenStack, Sumo Logic, Syslog-ng, Amazon S3, Amazon CloudWatch, or Papertrail. These services will allow you to free up space on your cloud servers while still retaining access to the log files when needed. Some of these services also allow for event correlation, or they can tie into event correlation services.
Event correlation can combine authentication requests from domain controllers, incoming packets from perimeter devices, and data requests from application servers to gain a more complete picture of what is going on. Software exists to automate much of the process. Such software, called security information and event management (SIEM), archives logs and reviews them in real time against correlation rules to identify possible threats or problems.
Network Device and IoT Logs
Log files are not restricted to servers. Network devices, even IoT devices, have log files that can contain helpful information in troubleshooting issues. These devices usually have a smaller set of logs. These logs may have settings for how much data is logged.
If the standard log settings do not seem to provide enough information when troubleshooting an issue, you can enable verbose logging. Verbose logging records more detailed information than standard logging but is recommended only for troubleshooting a particular problem, since it tends to fill up the limited space on network and IoT devices. To conserve space and prevent essential events from being overwritten, verbose logging should be disabled after the issue is resolved so that it does not affect the performance of the application or the computer.
Syslog
Network devices can generate events in different formats, and they often have very little space to store logs. Most devices only have room for system and configuration data. This means that if you want to store the logs somewhere, you will need to use Syslog. The Syslog protocol is supported by a wide range of devices and can log different types of events.
A Syslog server receives messages sent by various devices and collects those. Each machine is configured with the Syslog collector’s location, and each sends his or her logs to that server for collection. Syslog can be analyzed in place, or it can be archived to a cloud logging and archiving service, just like other logs.
Troubleshooting Tools
An organization needs to be able to troubleshoot the cloud environment when there are issues or connectivity problems. A variety of tools are available to troubleshoot the cloud environment. Understanding how to use those tools makes it easier for a company to maintain its service level agreements. This section explains the common usage of those tools.
There are many tools to choose from when troubleshooting a cloud environment. Sometimes a single tool is all that is required to troubleshoot the issue; other times, a combination of tools might be needed. Knowing when to use a particular tool makes the troubleshooting process easier and faster. As with anything, the more you use a particular troubleshooting tool, the more familiar you become with the tool and its capabilities and limitations.
Connectivity Tools
Connectivity tools are used to verify if devices can talk to one another on a network. These include ping, traceroute, and nslookup. Ping verifies that a node is talking on the network, traceroute displays the connections between source and destination, and nslookup performs DNS queries to resolve names to IP addresses.
Ping
One of the most common and previously most utilized troubleshooting tools is the ping utility. Ping is used to troubleshoot the lack of reachability of a host on an IP network. Ping sends an Internet Control Message Protocol (ICMP) echo request packet to a specified IP address or host and waits for an ICMP reply.
Ping can also be used to measure the round-trip time for messages sent from the originating workstation to the destination and to record packet loss. Ping generates a summary of the information it has gathered, including packets sent, packets received and lost, and the amount of time taken to receive the responses. Starting with Microsoft Windows XP Service Pack 2, Windows Firewall was enabled by default and blocks ICMP traffic and ping requests. Figure 15-11 shows an example of the output received when you use the ping utility to ping comptia.org.
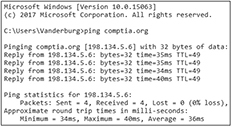
Figure 15-11 Ping command output
EXAM TIP Ping allows an administrator to test the availability of a single host.
Traceroute
Traceroute is a troubleshooting tool that is used to determine the path that an IP packet has to take to reach a destination. Unlike the ping utility, traceroute displays the path and measures the transit delays of packets across the network to reach a target host.
The command in Microsoft Windows is written as tracert. Issuing the traceroute command followed by an FQDN or IP address will print the list of hops from source to destination. Some switches that can be used with traceroute include the following:
• –d Disables host name resolution
• –h Specifies the maximum number of hops to trace
• –j Specifies an alternative source address, so traceroute executes from that node instead of the one from which you are issuing commands
• –w Specifies the timeout to use for each reply
Traceroute sends packets with gradually increasing time-to-live (TTL) values, starting with a TTL value of 1. The first router receives the packet, decreases the TTL value, and drops the packet because it now has a value of zero. The router then sends an ICMP “time exceeded” message back to the source, and the next set of packets is given a TTL value of 2, which means the first router forwards the packets and the second router drops them and replies with its own ICMP “time exceeded” message. Traceroute then uses the returned ICMP “time exceeded” messages with the source IP address of the expired intermediate device to create a list of routers until the destination device is reached and returns an ICMP echo reply.
Most modern operating systems support some form of the traceroute tool: as mentioned, on a Microsoft Windows operating system, it is named tracert; Linux has a version named trace; on Internet protocol version 6 (IPv6), the tool is called traceroute6. Figure 15-12 displays an example of the tracert command being used to trace the path to comptia.org.
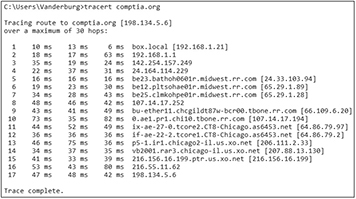
Figure 15-12 Tracert command output
Nslookup and Dig
Another tool that can be used to troubleshoot network connection issues is the nslookup command. With nslookup, it is possible to obtain domain name or IP address mappings for a specified DNS record. Nslookup uses the computer’s local DNS server to perform the queries. Using the nslookup command requires at least one valid DNS server, which can be verified by using the ipconfig /all command.
The domain information groper (dig) command can also be used to query DNS name servers and can operate in interactive command-line mode or be used in batch query mode on Linux-based systems. The host utility can also be used to perform DNS lookups. Figure 15-13 shows an example of the output using nslookup to query comptia.org.
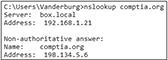
Figure 15-13 Nslookup query
Configuration Tools
Configuration tools are used to modify the configuration of network settings such as the IP address, DHCP, DNS, gateway, or routing settings. Three important configuration tools you should know are ifconfig, ipconfig, and route.
ifconfig
ifconfig is a Linux command used to configure the TCP/IP network interface from the command line, which allows for setting the interface’s IP address and netmask or even disabling the interface. ifconfig displays the current TCP/IP network configuration settings for a network interface.
Figure 15-14 shows the ifconfig command standard output, which contains information on the system’s network interfaces. The system this command was executed on has an Ethernet adapter called enp2s0 and a wireless adapter called wlp3s0. The item labeled “lo” is the loopback address. The loopback address is used to test networking functions and does not rely on physical hardware.
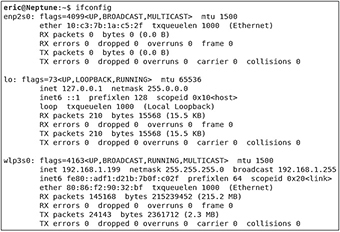
Figure 15-14 Viewing interfaces using ipconfig
EXAM TIP ifconfig lacks some command-line switches that ipconfig has that allow you to perform more advanced tasks, like clearing the DNS cache and obtaining a new IP address from DHCP, rather than just displaying TCP/IP configuration information.
Ipconfig
Ipconfig is a Microsoft Windows command used to configure a network interface from the command line. Ipconfig can display the network interface configuration, release or renew IP version 4 and 6 addresses from DHCP, flush the cache of DNS queries, display DNS queries, register a DHCP address in DNS, and display class IDs for IP versions 4 and 6. Figure 15-15 shows the command-line switch options available with the ipconfig command.

Figure 15-15 Ipconfig options
Route
The route command can be used to view and manipulate the TCP/IP routing tables of Windows operating systems. The routes displayed show how to get from one network to another. A computer connects to another over a series of devices, and each step from source to destination is called a hop. The route command can display the routing tables so that you can troubleshoot connectivity issues between devices or configure routing on a device that is serving that function.
Modification of a route requires modifying a routing table. A routing table is a data table stored on a system that connects two networks together. It is used to determine the destination of network packets it is responsible for routing. A routing table is a database that is stored in memory. It contains information about the network topology that is located adjacent to the router hosting the routing table.
When using earlier versions of Linux, the route command and the ifconfig command can be used together to connect a computer to a network and define the routes between the networks; later versions of Linux have replaced the ifconfig and route commands with the iproute2 command, which adds functionality such as traffic shaping. Figure 15-16 shows the route command using the print switch to display the current IP versions 4 and 6 routing tables.

Figure 15-16 The route command displaying current routing tables
Query Tools
Query tools are used to view the status of network services. The two commands you should be familiar with are netstat and arp. Netstat displays network connections, routing tables, and network protocol statistics. Arp displays the MAC addresses that a computer or network devices know about.
Netstat
If you want to display all active network connections, routing tables, and network protocol statistics, you can use the netstat command. Available in most operating systems, the netstat command can be used to detect problems with the network and determine how much network traffic there is. It can also display protocol and Ethernet statistics and all the currently active TCP/IP network connections. Figure 15-17 shows the options available with the netstat command.

Figure 15-17 The netstat command displaying the active connections
Arp Command
Another helpful troubleshooting tool is the arp command. The arp command uses the Address Resolution Protocol (ARP) to resolve an IP address to either a physical address or a media access control (MAC) address. The arp command makes it possible to display the current ARP entries or the ARP table and to add a static entry. Figure 15-18 uses the arp –a command to view the ARP cache of a computer.

Figure 15-18 The ARP cache with the Internet and the physical addresses displayed
Remote Administration Tools
Remote administration tools allow connectivity to systems or network devices. The two tools you should know about for troubleshooting are used to connect to network devices such as switches and routers. They include Telnet and Secure Shell (SSH).
Telnet
If a user wants to connect their computer to another computer or server running the Telnet service over the network, they can enter commands via the Telnet program, and the commands are executed as if they were being entered directly on the server console. Telnet enables the user to control a server and communicate with other servers over the network.
A valid username and password are required to activate a Telnet session; nonetheless, Telnet has security risks when it is used over any network because credentials and data are exchanged in plaintext. Figure 15-19 shows an example of a Telnet session established with a remote server.

Figure 15-19 A telnet session
EXAM TIP Telnet and SSH both allow an administrator to connect to a server remotely, the primary difference being that SSH offers security mechanisms to protect against malicious intent.
SSH
SSH is another protocol that enables the user to securely control a server and communicate with other servers over the network. Secure Shell and its most recent version, Secure Shell version 2 (SSHv2), have become a more popular option for providing a secure remote command-line interface than Telnet because they encrypt credentials and data.
Figure 15-20 shows an example of an SSH session established with a remote server 192.168.254.254. In this screenshot, a connection has been established, and the remote server is asking for a username to log in. After a username is provided, the system will ask for a password.

Figure 15-20 SSH session
Chapter Review
This chapter introduced you to troubleshooting tools, described documentation and its importance to company and cloud operations, and explained CompTIA’s troubleshooting methodology. Troubleshooting tools can be used to help identify issues, validate troubleshooting theories, and refine theories. Some tools include ping, traceroute, nslookup, ifconfig, ipconfig, route, netstat, arp, Telnet, and SSH. Understanding which tools are best suited to troubleshoot different issues as they arise with a cloud deployment model saves an administrator time and helps maintain service level agreements set forth by the organization.
Documentation is another important concept for cloud and systems administrators. Documentation needs to be clear and easy to understand for anyone who may need to use it and should be regularly reviewed to ensure that it is up to date and accurate. Documenting the person responsible for creating and maintaining the application and where it is hosted is a good process that saves valuable time when troubleshooting any potential issues with the cloud environment.
Lastly, the CompTIA troubleshooting methodology provides an effective means for evaluating problems, identifying potential solutions, testing those solutions, and putting them into practice. The methodology is broken down into six steps as follows: Step 1: Identify the problem. Step 2: Establish a theory of probable causes. Step 3: Test the theory to determine the cause. Step 4: Establish a plan of action to resolve the problem and implement the solution. Step 5: Verify full system functionality and, if applicable, implement preventative measures. Step 6: Document findings, actions, and outcomes.
Questions
The following questions will help you gauge your understanding of the material in this chapter. Read all the answers carefully because there might be more than one correct answer. Choose the best response(s) for each question.
1. Which of the following command-line tools allows for the display of all active network connections and network protocol statistics?
A. Netstat
B. Ping
C. Traceroute
D. Ipconfig and ifconfig
2. You need to verify the TCP/IP configuration settings of a network adapter on a VM running Microsoft Windows. Which of the following tools should you use?
A. Ping
B. ARP
C. Tracert
D. Ipconfig
3. Which of the following tools can be used to verify if a host is available on the network?
A. Ping
B. ARP
C. Ipconfig
D. Ipconfig and ifconfig
4. Which tool allows you to query DNS to obtain domain name or IP address mappings for a specified DNS record?
A. Ping
B. Ipconfig
C. Nslookup
D. Route
5. You need a way to remotely execute commands against a server that is located on the internal network. Which tool can be used to accomplish this objective?
A. Ping
B. Dig
C. Traceroute
D. Telnet
6. You need to modify a routing table and create a static route. Which command-line tool can you use to accomplish this task?
A. Ping
B. Traceroute
C. Route
D. Host
7. Users are complaining that an application is taking longer than normal to load. You need to troubleshoot why the application is experiencing startup issues. You want to gather detailed information while the application is loading. What should you enable?
A. System logs
B. Verbose logging
C. Telnet
D. ARP
8. How often should documentation be updated?
A. Annually
B. Quarterly
C. It depends on how many people are working on the project
D. Whenever significant changes are made
9. Fred manages 50 cloud servers in Amazon Web Services. Each cloud server is thin provisioned, and Fred pays for the amount of space his servers consume. He finds that the logs on the servers are rolling over and that each server has only about six days of logs. He would like to retain 18 months of logs. What should Fred do to retain the logs while conserving space on local hard disks?
A. Compress the log files
B. Request that the cloud provider deduplicate his cloud data
C. Purchase and configure a cloud log archiving service
D. Log in to the server every five days and copy the log files to his desktop
10. Which is not the name of a step in the CompTIA troubleshooting methodology?
A. Seek approval for the requested change
B. Identify the problem
C. Document findings, actions, and outcomes
D. Seek approval for change requests
11. Which step in the CompTIA troubleshooting methodology implements the solution?
A. Step 1
B. Step 2
C. Step 3
D. Step 4
E. Step 5
F. Step 6
Answers
1. A. The netstat command can be used to display protocol statistics and all of the currently active TCP/IP network connections, along with Ethernet statistics.
2. D. Ipconfig is a Microsoft Windows command that displays the current TCP/IP network configuration settings for a network interface.
3. A. The ping utility is used to troubleshoot the reachability of a host on an IP network. Ping sends an ICMP echo request packet to a specified IP address or host and waits for an ICMP reply.
4. C. Using the nslookup command, it is possible to query the Domain Name System to obtain domain name or IP address mappings for a specified DNS record.
5. D. Telnet allows you to connect to another computer and enter commands via the Telnet program. The commands will be executed as if you were entering them directly on the server console.
6. C. You can use the route command to view and manipulate the TCP/IP routing tables and create static routes.
7. B. Verbose logging records more detailed information than standard logging and is recommended to troubleshoot a specific problem.
8. D. Each time a significant change is made, the documentation should be updated to reflect the change. Otherwise, coworkers, auditors, or other employees might operate off out-of-date information.
9. C. A cloud log archiving service would allow Fred to retain the logs on the archiving service while freeing up space on the local disks. The log archival space would likely be cheaper than the production space, and log archiving services offer additional analytical and searching tools to make reviewing the logs easier.
10. D. Change requests were discussed in the previous chapter, and it is important to seek approval for changes before making them. However, this is not the name of a step in the CompTIA troubleshooting methodology.
11. D. Step 4 implements the solution. The steps in the CompTIA troubleshooting methodology are as follows: Step 1: Identify the problem. Step 2: Establish a theory of probable causes. Step 3: Test the theory to determine the cause. Step 4: Establish a plan of action to resolve the problem and implement the solution. Step 5: Verify full system functionality and, if applicable, implement preventative measures. Step 6: Document findings, actions, and outcomes.