
11.2 Need for Concurrency Control
One of the major objectives in developing an enterprise database is to create an information resource that can be shared by many users. If transactions execute one at a time, serially, with each transaction doing a commit before the next one begins, there is no problem of interference with one another’s transactions. However, users often need to access data simultaneously. The objective of a concurrency control system is to allow as much simultaneous processing as possible, without having transactions interfere with one another. If all users are only reading data, there is no way they can interfere with one another and there is no need for concurrency control. If users are accessing different parts of the database, their transactions can run concurrently without a problem. However, when two users try to make updates simultaneously to the same data, or one updates while another reads the same data, there may be conflicts.
Multiprogramming means having two or more programs or transactions processing at the same time. For example, I/O control systems can handle I/O operations independently, while the main processor performs other operations. Such systems can allow two or more transactions to execute simultaneously. The system begins executing the first transaction until it reaches an input or output operation. While the I/O is being performed, the main processor, which would otherwise be idle during I/O, switches over to the second transaction and performs whatever operations it can on the second one. Control then returns to the first transaction and its operations are performed until it again reaches an I/O operation. In this way, operations of the two transactions are interleaved, with some operations from one transaction performed, then some from the other, and so forth, until all operations for both transactions are completed. Even though both transactions may be correct in themselves, the interleaving of operations may produce an incorrect outcome.
Some examples of potential problems caused by concurrency are the lost update problem, the uncommitted update problem, the problem of inconsistent analysis, the nonrepeatable read problem, and the phantom data problem.
We illustrate the first three potential problems using schedules to show the chronological order in which operations are performed. A schedule is a list of the actions that a set of transactions performs, showing the order in which they are performed. In a schedule, we have a column showing time points, a column for each transaction showing the steps of that transaction that are executed at each time point, and columns for database attributes whose values are being read or written. The order of operations in each transaction is preserved, but steps from another transaction can be performed during its execution, resulting in an interleaving of operations.
11.2.1 The Lost Update Problem
Suppose Jack and Jill have a joint savings account with a balance of 1000. Jill gets paid and decides to deposit 100 to the account, using a branch office near her job. Meanwhile, Jack finds that he needs some spending money and decides to withdraw 50 from the joint account, using a different branch office. If these transactions were executed serially, one after the other with no interleaving of operations, the final balance would be 1050 regardless of which was performed first. However, if they are performed concurrently, the final balance may be incorrect.
FIGURE 11.3 shows a schedule for a concurrent execution that results in a final balance of 1100. The first column of schedule shows sequential units of time as t1, t2, etc., to show the chronological order for operations. The only operations that involve the database are explicitly shown as read <attribute_name> or write <attribute_name>. As shown in Figure 11.1, these operations involve either reading a value from the database into the buffer (read) or writing a new value to the database page in the buffer (write) and later copying the modified page out to the database. The transaction variables, which we assume for the sake of simplicity have the same name as the database attributes they correspond to, are separate from the database attributes. Updating a transaction variable (i.e., assigning a value to a program variable) has no effect on the database until a write <attribute_name> command for the corresponding database attribute is encountered.
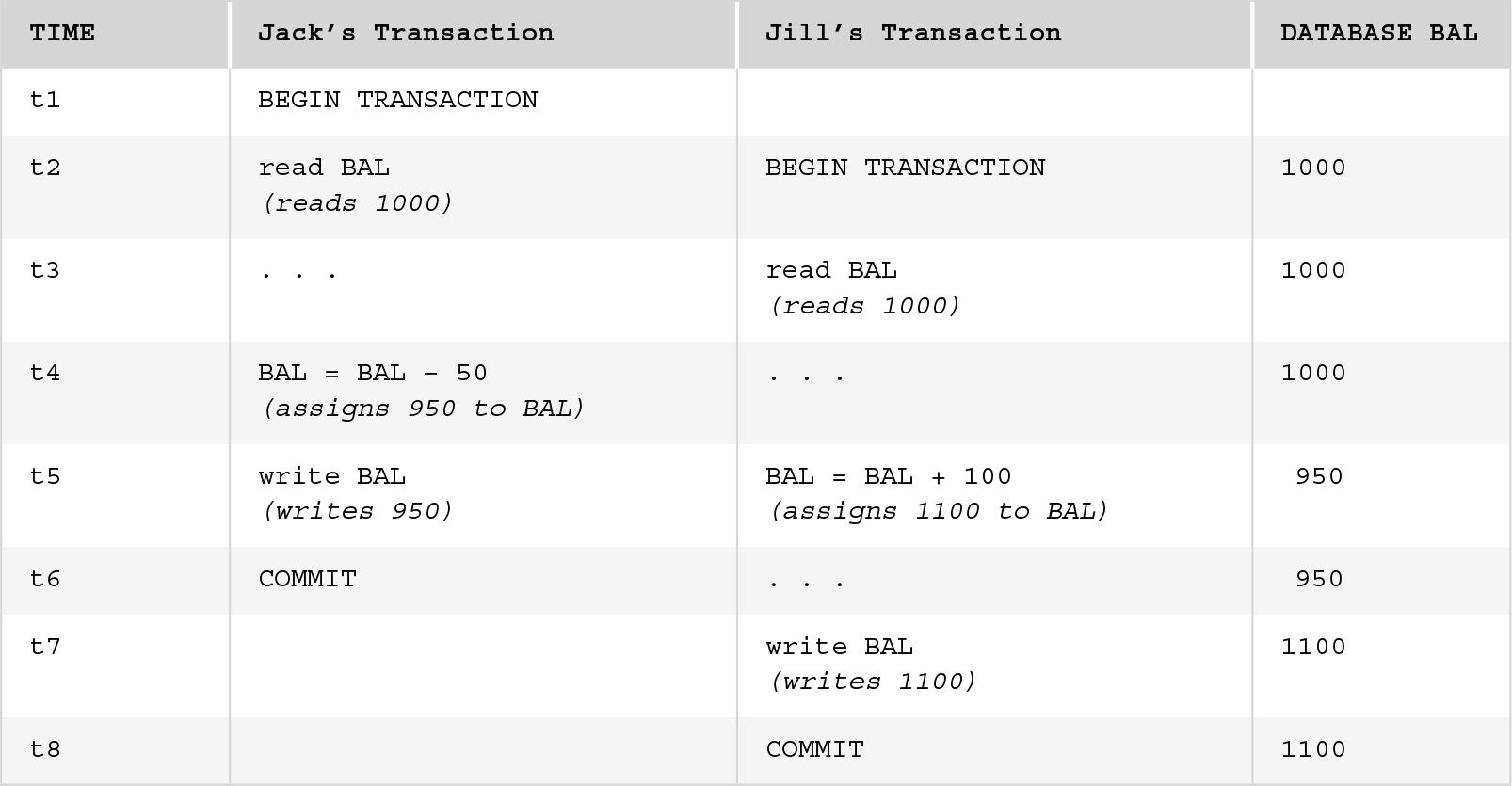
FIGURE 11.3 The Lost Update Problem
The value that a transaction reads for a variable is the one it uses for calculations. Each transaction is unaware of any changes made to the database other than its own changes. As shown on the schedule, Jack’s transaction reads a value of 1000 from the database attribute named BAL into the program variable for BAL at time t2. Jill’s transaction does the same slightly later at t3. Jack’s transaction subtracts 50 from the program variable BAL and then issues a write to the database at t5, as reflected in the database BAL column. At time t5, Jill’s transaction still uses the value it read for BAL, not the new value, which it has not read. Her transaction adds 100 and then writes a new value of 1100 to the database, overwriting Jack’s update. According to the schedule, Jack’s update is lost. If we had delayed Jill’s reading until Jack’s update had finished, we would have avoided this problem because Jill’s transaction would have read the updated value.
11.2.2 The Uncommitted Update Problem
The uncommitted update problem occurs with concurrent transactions when the first transaction is permitted to modify a value, which is then read by the second transaction, and the first transaction subsequently rolls back its update, invalidating the data that the second transaction is using. This is also called the dirty read problem because it is caused by the reading of dirty data, values that are intermediate results of an uncommitted transaction.
FIGURE 11.4 shows a schedule containing an example of an uncommitted update that causes an error. For this example, we are assuming a simplified, if unlikely, version of banking activities just to illustrate the concurrency problem. Here, transaction INTEREST calculates the interest for a savings account, using a rate of 1%, while transaction DEPOSIT deposits 1000 in the account but is rolled back. The starting balance in the account is 1000. If DEPOSIT updates the value of the balance to 2000 before INTEREST reads the balance, the amount that INTEREST will store is 2020. However, DEPOSIT is rolled back, which means the database state should show no effect due to DEPOSIT, so at time t7 the original value, 1000, is restored as part of the rollback. Note that DEPOSIT is unaware that INTEREST has read its write, nor is INTEREST aware that DEPOSIT has rolled back. The reason for the rollback may be that the transaction itself was an error, or it may be the result of some other event. At t8, the value calculated by INTEREST is written. Because the INTEREST was calculated on the incorrect balance, the final balance will be incorrect. If we had delayed reading the balance for the INTEREST transaction until after the DEPOSIT transaction had rolled back (or committed), we would have avoided the error.
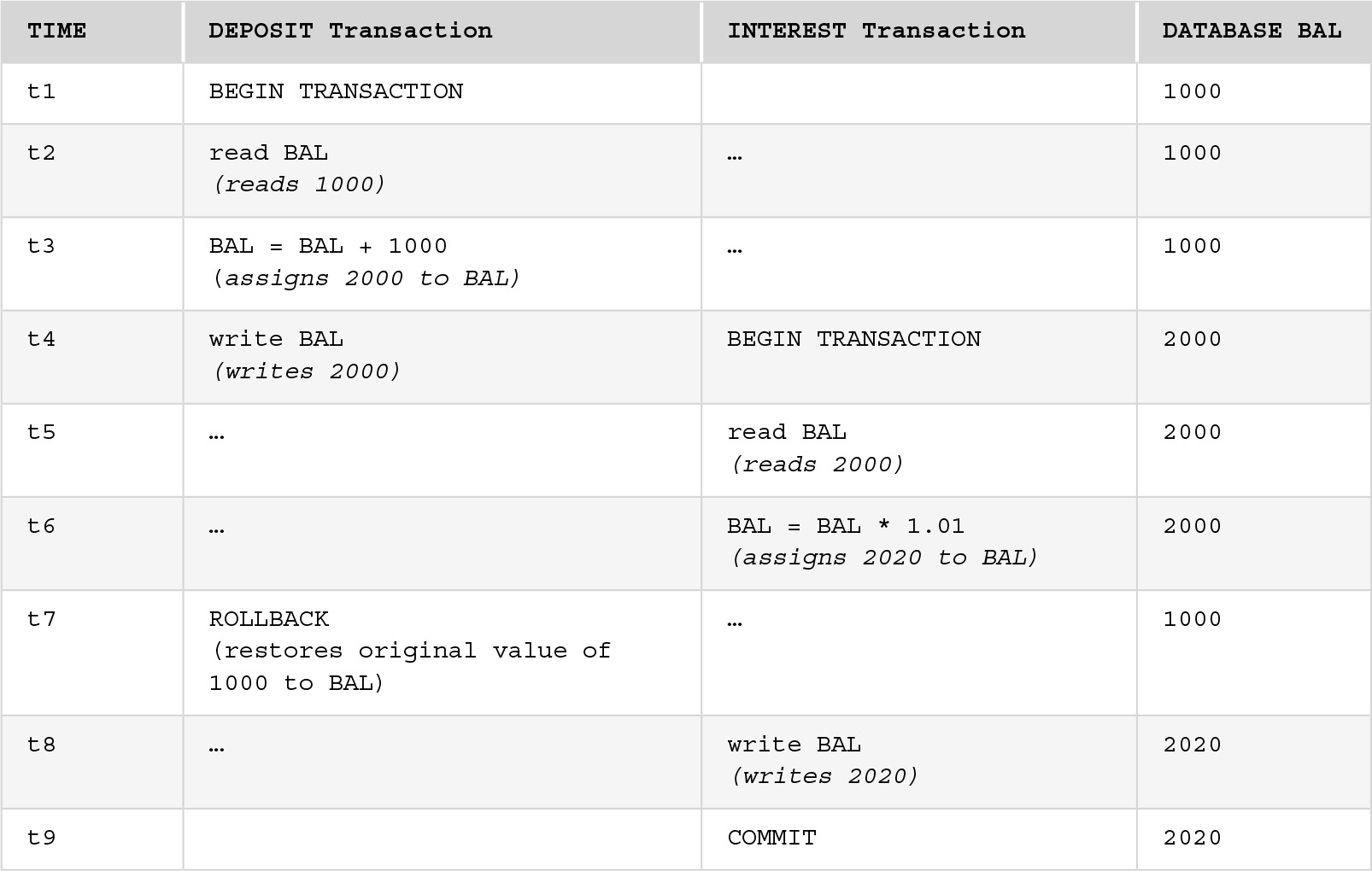
FIGURE 11.4 The Uncommitted Update Problem
11.2.3 The Problem of Inconsistent Analysis
The problem of inconsistent analysis occurs when a transaction reads several values but a second transaction updates some of the values during the execution of the first. Suppose we want to find the total balance of all savings accounts, but we allow deposits, withdrawals, and transfers to be performed during this transaction. FIGURE 11.5 contains a schedule that shows how an incorrect result could be produced. Transaction SUMBAL finds the sum of the balance on all accounts. To keep the example small, we assume there are only three accounts. Notice that this transaction does not update the accounts, but only reads them. Meanwhile, transaction TRANSFER transfers 1000 from account A to account C. The TRANSFER transaction executes correctly and commits. However, it interferes with the SUMBAL transaction, which adds the same 1000 twice—once while it is in account A and again when it reaches account C.
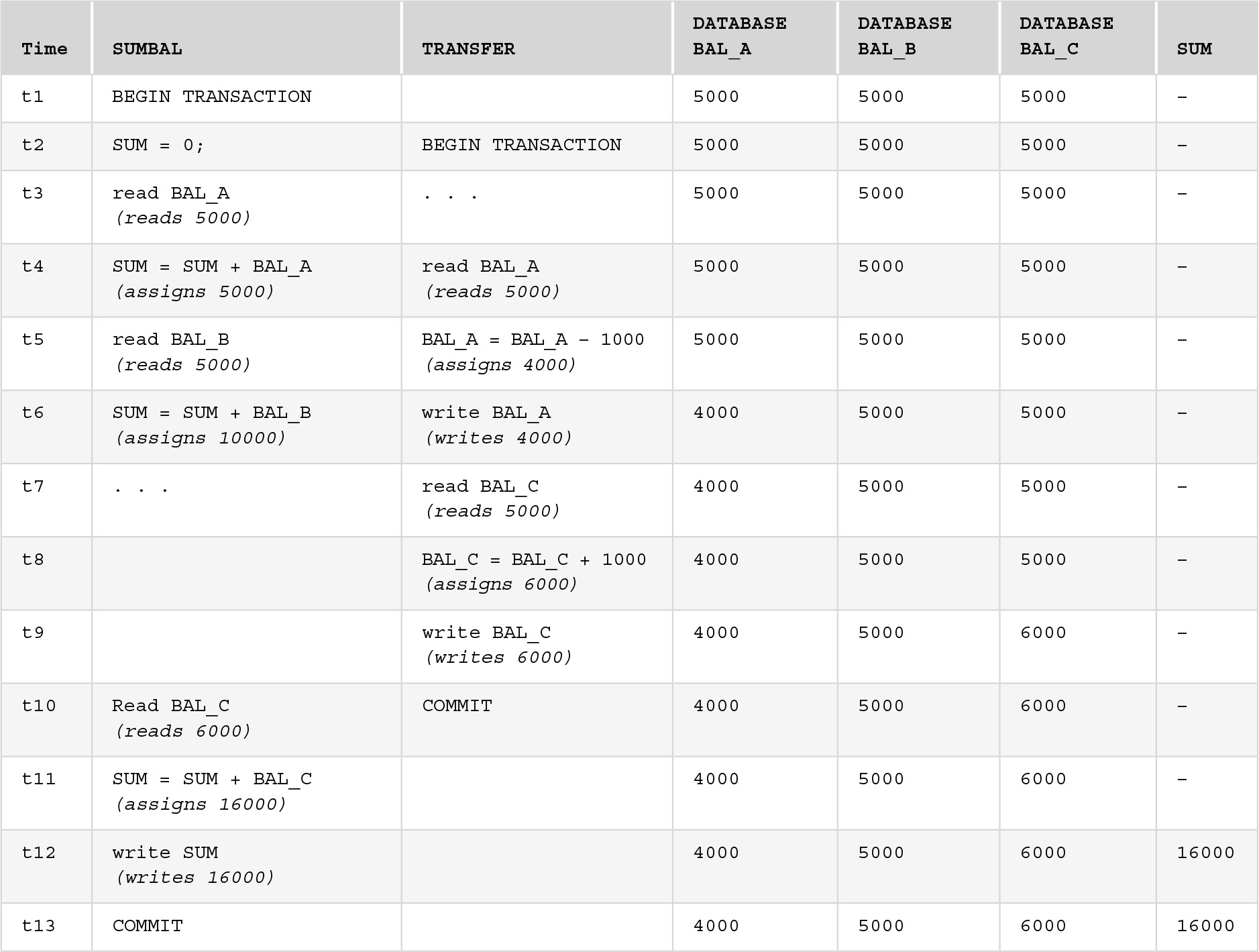
FIGURE 11.5 The Inconsistent Analysis Problem
The following are two other well-known inconsistencies that can arise from concurrency:
Nonrepeatable read problem. This occurs when a first transaction reads an item, another transaction writes a new value for the item, and the first transaction then rereads the item and gets a value that is different from its first one.
Phantom data problem. This occurs when a first transaction reads a set of rows (e.g., the tuples of a query), another transaction inserts a row, and then the first transaction reads the rows again and sees the new row.