
11.8 Recovery Techniques
Transactions are used as the basic unit for recovery for a database. The DBMS has a recovery manager that is responsible for ensuring atomicity and durability for transactions in the event of failure. Atomicity requires that all operations of a transaction be performed successfully or none, so the recovery manager must ensure that all the effects of committed transactions reach the database, and that the effects of any uncommitted transactions are undone as part of recovery. Durability requires that the effects of a committed transaction be permanent, so they must survive the loss of main memory, loss of disk storage, and failures during data transfers to disk.
The possible loss of disk data is handled by doing frequent backups, making copies of the database as it appears at a certain point in time. In the event of a disk failure, the database can be recovered to a correct state by starting with the backup copy and bringing the backup copy up to date using a log of transactions, which will be described. It is desirable to have one or more copies of the database stored in some form of stable storage, a nonvolatile form of storage that is, in theory, completely safe from destruction. In practice, stable storage can be created by having mirrored disks, a version of RAID (Redundant Arrays of Independent Disks) technology in which two independent disks both contain complete copies of the database. Whenever a database page is modified, both copies are updated. Another method is to have a live backup copy of the database at a remote site, and to send a copy of each modified database page to the remote disk whenever the local disk is modified. These methods help in recovery both in the event of database failure and in the event of a data transfer failure. To ensure against errors when database writes occur, the modified pages are written first to the local disk and then to the mirror or remote disk. Only after both writes are completed is the output considered to have been done. If a data transfer error is detected, both copies are examined. If they are identical, the data is correct. If one has an error condition, the other copy can be used to replace the faulty data. If neither has an error condition but they have different values, the write is essentially undone by replacing the first copy with the second. If a system failure occurs and the database buffers are lost, the disk copy of the database survives, but it may be incorrect due to partially completed database updates.
A transaction can commit once its writes are made to the database buffers, but there might be a delay between the commit and the actual disk writing. Because updates made to buffer pages are not immediately written to disk, even for committed transactions, if there is a system failure during this delay, the system must be able to ensure that these updates reach the disk copy of the database. For some protocols, writes made while a transaction is active, even before it commits, can reach the disk copy of the database. If there is a system failure before the transaction completes, these writes need to be undone.
To keep track of database transactions, the system maintains a log, a file that contains information about all updates to the database. The log can contain data transaction records, giving the transaction identifier and some information about it.
11.8.1 Deferred Update Protocol
Using the deferred update recovery protocol, the DBMS records all database writes in the log, and does not write to the database until the transaction is ready to commit.
We can use the log to protect against system failures in the following way:
When a transaction starts, write a record of the form <T starts> to the log.
When any write operation is performed, do not actually write the update to the database buffers or the database itself. Instead, write a log record of the form <T,x,newValue> showing the new value for attribute x.
When a transaction is about to commit, write a log record of the form <T commits>, write all the log records for the transaction to disk, and then commit the transaction. Use the log records to perform the actual updates to the database.
If the transaction aborts, simply ignore the log records for the transaction and do not perform the writes.
Note that we write the log records to disk before the transaction is actually committed, so that if a system failure occurs while the actual database updates are in progress, the log records will survive and the updates can be applied later.
FIGURE 11.17 illustrates a short transaction, the corresponding log transaction entries, and the database data items involved. Note that the database is not updated until after the commit. In the event of a system failure, we examine the log to identify the transactions that may be affected by the failure. Any transaction with log records <T starts> and <T commits> should be redone in the order in which they appear in the log. The transaction itself does not have to be executed again. Instead, the redo procedure will perform all the writes to the database, using the write log records for the transactions. Recall that all log records will have the form <T,x,newValue>, which means the procedure will write the value newValue to the attribute x. If this writing has been done already, prior to the failure, the write will have no effect on the attribute, so there is no damage done if we write unnecessarily. However, this method guarantees that we will update any attribute that was not properly updated prior to the failure. For any transaction with log records <S starts> and <S aborts>, or any transaction with <S starts> but neither a commit nor an abort, we do nothing, as no actual writing was done to the database using the incremental log with deferred updates technique, so these transactions do not have to be undone. This protocol is called a redo/no undo method because we redo committed transactions and we do not undo any transactions. If a second system crash occurs during recovery, the log records are used again the second time the system is restored. Because of the form of the write log records, it does not matter how many times we redo the writes.
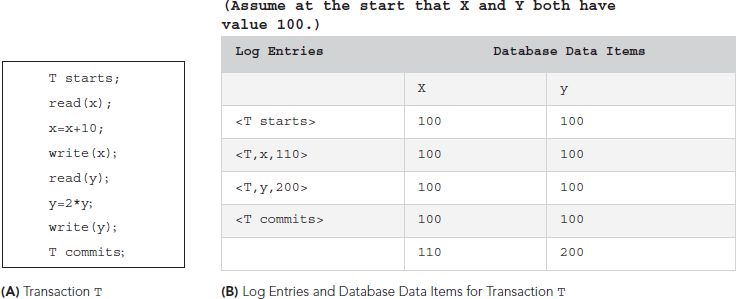
FIGURE 11.17 A Transaction and Its Log
If a system failure occurs while the log records themselves are being written to disk, no database updates have yet been made by the transaction. If the log contains a <T starts> but no <T commits>, or it contains <T starts> followed by <T aborts>, we do nothing. If the log contains both <T starts> and <T commits>, we perform the redo procedure as described earlier.
11.8.2 Checkpoints
One difficulty with the deferred update scheme is that when a failure occurs, we may not know how far back in the log to search. For example, we would like to avoid redoing a whole day’s transactions, especially if most of them have already been safely written to the database. To put some limit on the log searching we need to do, we can use a technique called a checkpoint. Checkpoints are scheduled at predetermined intervals and involve the following operations:
Writing the modified pages in the database buffers out to disk, a process called force writing
Writing all log records now in main memory out to disk
Writing a checkpoint record to the log; that is, a record that contains the names of all transactions that are active at the time of the checkpoint
Having checkpoints allows us to limit the log search. If all transactions are performed serially, when a failure occurs, we can check the log to find the last transaction that started before the last checkpoint. In serial execution, any earlier transaction would have committed previously and would have been written to the database at the checkpoint. Therefore, we need only redo the one that was active at the checkpoint, provided it has a commit log record after the checkpoint but before the failure, and any subsequent transactions for which both start and commit records appear in the log. If transactions are performed concurrently, the scheme is only slightly more complicated. Recall that the checkpoint record contains the names of all transactions that were active at checkpoint time. Therefore, we redo all those active transactions that have committed and all subsequent ones that have committed.
11.8.3 Immediate Update Protocol
A slightly different recovery technique uses a log with immediate updates. In this scheme, updates are applied to the database buffers as they occur and are written to the database itself when convenient. However, a log record is written first because this is a write-ahead log protocol. The scheme for successful transactions is as follows:
When a transaction starts, write a record of the form <T starts> to the log.
When a write operation is performed, write a log record containing the name of the transaction, the attribute name, the old value, and the new value of the attribute. This has the form <T,x,oldValue,newValue>.
After the log record is written, write the update to the database buffers.
When convenient, write the log records to disk and then write updates to the database itself.
When the transaction commits, write a record of the form <T commits> to the log.
If a transaction aborts, the log can be used to undo the transaction because the log contains all the old values for the updated attributes. Because a transaction might have performed several changes to an item, the writes are undone in reverse order. Regardless of whether the transaction’s writes have been applied to the database, writing the old values guarantees that the database will be restored to its state prior to the start of the transaction.
If the system fails, recovery involves using the log to undo or redo transactions, making this a redo/undo protocol. For any transaction, T, for which both <T starts> and <T commits> records appear in the log, we redo by using the log records to write the new values of updated items. Note that if the new values have already been written to the database, these writes, though unnecessary, will have no effect. However, any write that did not actually reach the database will now be performed. For any transaction, S, for which the log contains an <S starts> record but not an <S commits> record, we will need to undo that transaction. This time the log records are used to write the old values of the affected items and thus restore the database to its state prior to the transaction’s start.
11.8.4 Shadow Paging
Shadow paging is an alternative to log-based recovery techniques. The DBMS keeps a page table that contains pointers to all current database pages on disk. With shadow paging, two page tables are kept, a current page table and a shadow page table. Initially these tables are identical. All modifications are made to the current page table, and the shadow table is left unchanged. When a transaction needs to make a change to a database page, the system finds an unused page on disk, copies the old database page to the new one, and makes changes to the new page. It also updates the current page table to point to the new page. If the transaction completes successfully, the current page table becomes the shadow page table. If the transaction fails, the new pages are ignored, and the shadow page table becomes the current page table. The commit operation requires that the system do the following:
Write all modified pages from the database buffer out to disk.
Copy the current page table to disk.
In the disk location where the address of the shadow page table is recorded, write the address of the current page table, making it the new shadow page table.
11.8.5 Overview of the ARIES Recovery Algorithm
The ARIES recovery algorithm is a very flexible and efficient method for database recovery. It uses a log, in which each log record is given a unique log sequence number (LSN), which is assigned in increasing order. Each log record records the LSN of the previous log record for the same transaction, forming a linked list. Each database page also has a pageLSN, which is the LSN of the last log record that updated the page.
The recovery manager keeps a transaction table with an entry for each active transaction, giving the transaction identifier, the status (active, committed, or aborted), and the lastLSN, which is the LSN of the latest log record for the transaction. It also keeps a dirty page table with an entry for each page in the buffer that has been updated but not yet written to disk, along with the recLSN, the LSN of the oldest log record that represented an update to the buffer page.
The protocol uses write-ahead logging, which requires that the log record be written to disk before any database disk update. It also does checkpointing to limit log searching in recovery. Unlike other protocols, ARIES tries to repeat history during recovery by attempting to repeat all database actions done before the crash, even those of incomplete transactions. It then does redo and undo as needed. Recovery after a crash is done in three phases.
Analysis. The DBMS begins with the most recent checkpoint record and reads forward in the log to identify which transactions were active at the time of failure. The system also uses the transaction table and the dirty page table to determine which buffer pages contain updates that were not yet written to disk. It also determines how far back in the log it needs to go to recover, using the linked lists of LSNs.
Redo. From the starting point in the log identified during analysis, which is the smallest recLSN found in the dirty page table during the analysis phase, the recovery manager goes forward in the log and applies all the unapplied updates from the log records.
Undo. Going backward from the end of the log, the recovery manager will undo updates done by uncommitted transactions, ending at the oldest log record of any transaction that was active at the time of the crash.
This algorithm is more efficient than the ones discussed previously because it can avoid unnecessary redo and undo operations, as it knows which updates have already been performed.