
12.6 Transaction Control for Distributed Databases
In a DDBS, if the database is either centralized or partitioned so that there is only one copy of each item, and all requests are either local (can be filled at the local site) or remote (can be filled completely at one other site), then the usual locking and timestamping mechanisms are sufficient. More difficult concurrency problems arise when there are multiple copies of data items spread across the system. To solve this multiple-copy consistency problem, we must be sure that each location receives and performs the updates to the common data items. We must also manage compound transactions that require updates to different data items located at different sites. These issues are dealt with using protocols that employ transaction management techniques on a more global level.
Whereas traditional databases use the ACID properties as the standard for transaction management, distributed systems usually adhere to a slightly relaxed model that sacrifices immediate consistency to ensure availability of data, even in the case of network partitioning. Network partitioning occurs when a node or link between parts of the network fails, resulting in splitting the network into separate groups in such a way that nodes within a group can communicate among themselves, but there is no communication between the groups.
In 2000, Eric Brewer first proposed that a distributed system cannot simultaneously satisfy all three of the following properties:
Consistency. All users see the same data, despite replication.
Availability. The system is available for queries at all times.
Partition tolerance. The system can continue to operate even in the presence of network partitions.
Gilbert and Lynch proved this property in 2002, which has become known as the CAP (Consistency, Availability, Partition tolerance) theorem. Most distributed systems choose to satisfy availability and partition tolerance over consistency. As a result, distributed systems settle for eventual consistency, which means that when updates are done, they are not immediately performed at all nodes, but they are gradually replicated throughout the system, so the system is not in a consistent state for a short time, but it will eventually be consistent. Brewer defined this as the BASE model, which stands for Basically Available all the time, in a Soft state (does not have to be consistent all the time), and Eventually consistent (will eventually be in some known, consistent state)
Each LDBMS in a DDBS has a local transaction manager, including a concurrency controller and a recovery manager that function in the usual manner. Each site that initiates transactions also has a transaction coordinator, whose function is to manage all transactions—whether local, remote, or global—that originate at that site. For local or remote transactions, the transaction manager at the data site itself takes over. For global transactions, a typical sequence of events when such a transaction is entered at a site requires the transaction coordinator at that particular site to do the following:
Start executing the transaction.
Consult the global data dictionary to divide the transaction into subtransactions and identify where each subtransaction will be executed.
Send the subtransactions to the target sites, using the communications system.
Receive the results of the subtransactions back from the target sites.
Manage the completion of the transaction, which is either a commit at all sites or an abort at all sites.
The transaction coordinator is responsible for ensuring distributed concurrency control and distributed recovery using the BASE model. It follows a global concurrency control protocol to ensure serializability of global transactions and maintains a log for recovery.
12.6.1 Concurrency Control
We have already considered problems of concurrency control can exist in a centralized system (these were considered in Chapter 11). The lost update problem, the uncommitted update problem, the problem of inconsistent analysis, the nonrepeatable read problem, and the phantom data problem, well-known issues that are addressed by concurrency control protocols using locking and timestamping in traditional database systems, which we discussed in that chapter, can all occur in a distributed database as well.
We must consider serializability of transactions, extending that notion for the distributed environment. We consider locking as the first solution, and we then examine the problem of deadlock, the situation in which two transactions each wait for data items being held by the other. We also look at deadlock detection methods, using a wait-for graph, and we then examine timestamping as a second method for concurrency control.
Locking Protocols
In Chapter 11, we discussed the two-phase locking protocol that guarantees serializability for transactions in a centralized database. Using this protocol, each transaction acquires all the required locks during its growing phase and releases its locks during its shrinking phase. The transaction cannot acquire any new locks once it releases any lock. We can extend the solution to a distributed environment by managing locks in one of several ways:
Single-site lock manager. In this design, there is a central lock manager site to which all requests for locks are sent. Regardless of which site originates a transaction, the locking site determines whether the necessary locks can be granted, using the rules of the two-phase locking protocol. The requesting site can read data from any site that has a replica of an item. However, updates must be performed at all the sites where the item is replicated. This is referred to as Read-One-Write-All replica handling. The single-site lock manager scheme is relatively simple and easy to implement. Deadlock detection and recovery are also simple because only one site manages locking information. However, the site might become a bottleneck because it must process all lock requests. Another disadvantage is that the failure of the lock manager site stops all processing. This can be avoided by having a backup site take over lock management in the event of failure.
Distributed lock manager. In this scheme, several sites (possibly all sites) have a local lock manager that handles locks for data items at that site. If a transaction requests a lock on a data item that resides only at a given site, that site’s lock manager is sent a request for an appropriate lock, and the lock site proceeds as in standard two-phase locking. The situation is more complicated if the item is replicated because several sites might have copies. Using the Read-One-Write-All rule, the requesting site requires only a shared lock at one site for reading, but it needs exclusive locks at all sites where a replica is stored for updates. There are several techniques for determining whether the locks have been granted, the simplest being that the requesting site waits for each of the other sites to inform it that the locks have been granted. Another scheme requires that the requesting site wait until a majority of the other sites grant the locks. The distributed manager scheme eliminates the bottleneck problem, but deadlock is more difficult to determine because it involves multiple sites. If the data item to be updated is heavily replicated, communications costs are higher than for the previous method.
Primary copy. This method can be used with replicated or hybrid data distribution where locality of reference is high, updates are infrequent, and nodes do not always need the very latest version of data. For each replicated data item, one copy is chosen as the primary copy, and the node where it is stored is the dominant node. Normally, different nodes are dominant for different parts of the data. The global data dictionary must show which copy is the primary copy of each data item. When an update is entered at any node, the DDBMS determines where the primary copy is located and sends the update there first, even before doing any local update. To begin the update, the dominant node locks its local copy of the data item(s), but no other node does so. If the dominant node is unable to obtain a lock, then another transaction has already locked the item, so the update must wait for that transaction to complete. This ensures serializability for each item. Once the lock has been obtained, the dominant node performs its update and then controls updates of all other copies, usually starting at the node where the request was entered. The user at that node can be notified when the local copy is updated, even though there might be some remote nodes where the new values have not yet been entered. Alternatively, the notification might not be done until all copies have been updated. To improve reliability in the event of dominant node failure, a backup node can be chosen for the dominant node. In that case, before the dominant node does an update, it should send a copy of the request to its backup. If the dominant node does not send notification of update completion shortly after this message, the backup node uses a time-out to determine whether the dominant node has failed. If a failure occurs, the backup node then acts as the dominant node. It notifies all other nodes that it is now dominant, sends a copy of the request to its own backup node, locks data and performs its own update, and supervises the updates at the other nodes. It is also responsible for supplying data needed when the original dominant node recovers. If nondominant nodes fail, the system continues to function, and the dominant node is responsible for keeping a log of changes made while the node was down, to be used in recovery. The primary copy approach has lower communications costs and better performance than distributed locking.
Majority locking protocol. In this scheme, lock managers exist at all sites where data items are stored. If a data item is replicated at several sites, a transaction requiring a lock on the item sends its request to at least half of the sites having a replica. Each of these sites grants the local lock if possible or delays the grant if necessary. When the transaction has received grants from at least half of the replica sites, it can proceed. Note that while several transactions can hold a majority of the shared locks on an item, only one transaction can have the majority of the exclusive locks on a particular item. This protocol is more complex than the previous protocols and requires more messages. Deadlock between sites is also difficult to determine.
Regardless of how the locks are managed, the two-phase locking protocol is applied. The transaction must obtain all locks before releasing any lock. Once it releases any lock, no further locks can be obtained.
Global Deadlock Detection
Locking mechanisms can result in deadlock, a situation in which transactions wait for each other indefinitely (as discussed in Chapter 11). Deadlock detection in a centralized database involves constructing a wait-for graph, with transactions represented by nodes and an edge from node T1 to node T2 indicating that transaction T1 is waiting for a resource held by transaction T2. A cycle in the graph indicates that deadlock has occurred.
In a distributed environment, each site can construct its local wait-for graph. Nodes on the graph can represent both local transactions using local data and nonlocal transactions that are using the data at that site. Any transaction that is using a site’s data is therefore represented by a node on the graph, even if the transaction is executing at another site. If a cycle occurs on a local wait-for graph, deadlock has occurred at that site, and it is detected and broken in the usual way: by choosing a victim and rolling it back. However, distributed deadlock can occur without showing up as a cycle in any local wait-for graph.
FIGURE 12.9(A) shows a global schedule with four sites executing transactions concurrently. At site 1, transaction T2 is waiting for a shared lock on data item a, currently locked exclusively by T1. In FIGURE 12.9(B), the local wait-for graph for site 1 shows an edge from T2 to T1, but no cycle. Similarly, sites 2 through 4 have wait-for graphs, each of which has no cycle, indicating no deadlock at that site. However, when we take the union of the graphs, FIGURE 12.9(C), we see that the global wait-for graph has a cycle. At site 4, T1 is waiting for T4, which is waiting at site 3 for T3, which is waiting at site 2 for T2, which is waiting at site 1 for T1. Therefore, we have a cycle indicating distributed deadlock. No single site could detect that deadlock by using its local graph alone. Therefore, the system needs to maintain a global wait-for graph as well as the local ones. A single site can be identified as the deadlock detection coordinator that maintains the graph, or the responsibility could be shared by several sites to avoid bottlenecks and improve reliability.
FIGURE 12.9 Wait-for Graphs for Deadlock Detection
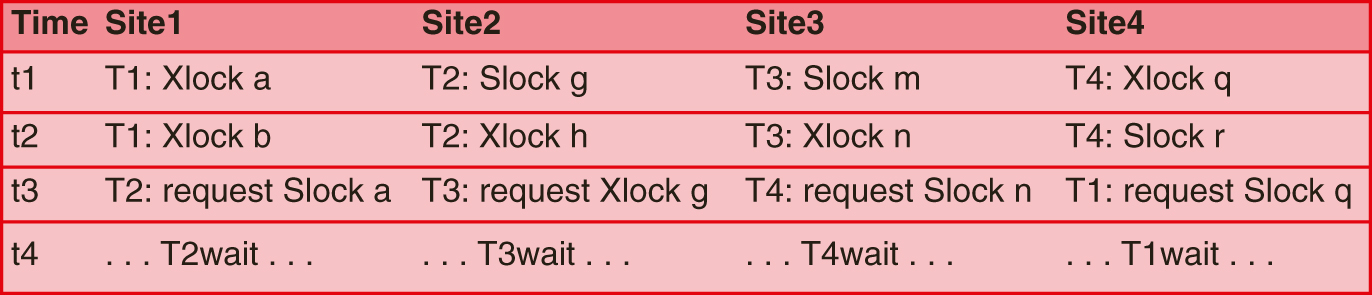
(A) Global Schedule of Transactions T1, T2, T3, T4

(B) Local Wait-for Graphs with No Cycle
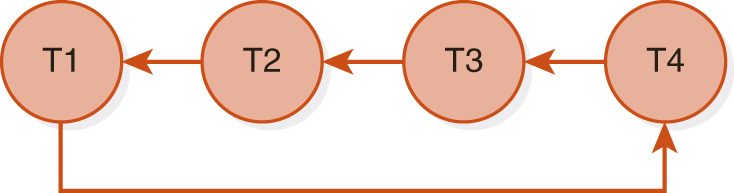
(C) Global Wait-for Graph with Cycle
The deadlock detection coordinator is responsible for constructing a global graph using information from the lock managers at all sites. These managers transmit messages informing the coordinator whenever an edge is added to or deleted from their local graphs. The coordinator continuously checks for cycles in the global graph and, if one is detected, the coordinator is responsible for selecting a victim and informing all participating sites that they must roll back that transaction.
Timestamping Protocols
In Chapter 11, we discussed timestamping in a centralized system and following protocols that guarantee that transactions are executed as if in timestamp order. We can apply essentially the same protocols to distributed systems if we can guarantee unique timestamps. This can be done either by issuing timestamps from only one site or by specifying that timestamps will have two parts. The first part is the usual timestamp generated by the local clock or logical counter, and the second part is the node identifier. Because the clock or counter is advanced at each node for each transaction, this guarantees that every transaction will have a unique timestamp, although two transaction timestamps can have the same first part. It would be desirable to have some type of global clock, so we can determine the order of two transactions entered at different sites, but it is virtually impossible to fully synchronize all the local clocks involved. Instead, there is usually a scheme to prevent local timestamps from diverging too much. For example, there can be a rule that if a node receives a timestamp with the first part, t, greater than its current clock reading, it automatically advances its clock to t + l. This prevents nodes that have frequent transactions from getting too far ahead of less active nodes. As in the centralized case, the protocol includes resolution procedures to follow in the case of conflicting transactions. The basic timestamping protocol, Thomas’s Write Rule, and multiversion timestamping can all be applied directly to the distributed environment using the unique timestamps. Chapter 11 discusses these protocols for centralized databases.
12.6.2 Recovery
As with a centralized database, a DDBMS must ensure that its transactions are atomic and durable, despite system failures. If the transaction aborts, its effects must be completely undone throughout all the sites it affected. If it commits, its effects must persist at all the sites where the data was modified.
Failures and Recovery
In addition to the types of failures that can occur in a centralized database, such as disk crashes or system failures, distributed databases can suffer from failures due to loss of messages, loss of a site, or failure of a communications line. They must also be able to deal with network partitioning.
It is difficult to tell whether one of the nodes or links has failed. If a site is unable to communicate with a node, it may be because the node is busy, that the node itself has failed, that the communications link has failed, or that the network is partitioned due to the failure of a different node or another link. In the case of a link failure, rerouting may be used, and the system could continue as before. If no other link exists, the node is isolated, and the link failure is treated as a node failure. The system can recognize a node failure either by self-reporting of the failed node or, if that is not possible, by a timeout method. In that case, if a node fails to respond to a message within a prespecified time, it is assumed to have failed, and recovery procedures are started. It is essential that the timeout be sufficiently long that recovery procedures are not triggered unnecessarily. The following steps are used to allow the system to continue following the failure of a node:
The system should flag the node or link as failed, to prevent any other node from trying to use it and thus generating a second recovery procedure.
The system should abort and roll back any transactions affected by the failure.
The system should check periodically to see if the node has recovered or, alternatively, the node should report when it has recovered.
Once restarted, the failed node must do local recovery, rolling back any partial transactions that were active at the time of failure and redoing transactions as needed.
After local recovery, the failed node must update its copy of the data so that it matches the current state of the database. The system keeps a log of changes made during the node’s failure for this purpose.
Commit Protocols
The transaction coordinator is responsible for determining whether a transaction commits or aborts. If the transaction involves several sites as participants, it must commit at all of them or abort at all of them. The coordinator must use a protocol to determine the outcome of a transaction and to handle any failure. The most commonly used protocol is the two-phase commit protocol. The three-phase commit protocol is an enhanced version of the two-phase commit protocol that resolves issues with blocking.
Two-phase commit protocol. This protocol consists of a voting phase and a resolution phase. At the end of a transaction’s execution, the transaction coordinator asks the participant sites whether they can commit the transaction T. If all agree to commit, the coordinator commits; otherwise, it aborts the transaction. The phases consist of the following activities:
Phase 1—voting phase. The coordinator writes a <begin commit T> record to its log, and force-writes the log to disk. The coordinator sends a <prepare T> message to all participant sites. Each site determines whether it can commit its portion of T. If it can, it adds a <ready T> message to its own log, force-writes the log to disk, and returns a <ready T> message to the coordinator. If a site cannot commit, it adds an <abort T> to its log, force-writes the log, and returns an <abort T> vote to the coordinator.
Phase 2—resolution phase. The coordinator resolves the fate of the transaction according to the responses it receives.
If the coordinator receives an <abort T> message from any site, it writes an <abort T> message to its log and force-writes the log. It sends an <abort T> message to all participant sites. Each site records the message in its own log and aborts the transaction.
If a site fails to vote within a specified time (the timeout period), the coordinator assumes a vote of <abort T> from that site and proceeds to abort as described in Phase 1.
If the coordinator receives <ready T> messages from all participating sites, it writes a <commit T> record to its log, force-writes the log, and sends a <commit T> message to all participants. Each site records the message in its own log and responds to the coordinator. When all acknowledgments are received, the coordinator writes an <end T> message to its log. If any acknowledgment is not received during the timeout, the coordinator assumes that the site has failed. In the event of failure of either the coordinator or a participating site, the protocol determines the actions to be taken.
(1) Failure of a participating site. As described earlier, if the coordinator does not receive a vote from a site within the timeout, it assumes an <abort T> vote and aborts the transaction. If the site votes to accept the commit and fails afterward, the coordinator continues executing the protocol for the other sites. When the failed site recovers, the site consults its log to determine what it should do for each transaction that was active at the time of failure.
If the log has a <commit T> record, it does a redo(T).
If the log has an <abort T> record, it does an undo(T).
If the log does not have a ready, abort, or commit record for T, then it must have failed before responding with a vote, so it knows the coordinator had to abort the transaction. Therefore, it does an undo(T).
If the log has a <ready T> record, the site tries to determine the fate of the transaction. It consults the coordinator, and if the coordinator responds that the transaction committed, the site does a redo(T). If the coordinator responds that the transaction was aborted, the site does an undo(T). If the coordinator does not respond, the site assumes the coordinator has failed, and the site may attempt to determine the transaction’s fate by consulting other participant sites. If it cannot determine the fate, the site is blocked and must wait until the coordinator has recovered.
(2) Failure of the coordinator. If the coordinator fails during the commit protocol, the participating sites try to determine the fate of the transaction. Several possibilities exist:
If one of the sites has an <abort T> in its log, T is aborted.
If one of the sites has a <commit T> in its log, T is committed.
If a site exists without a <ready T> in its log, that site cannot have voted to commit T, so the coordinator cannot have decided to do a commit. Therefore, T can now be aborted.
In all other cases (all active sites have a <ready T> but no site has either <abort T> or <commit T>), it is impossible to tell whether the coordinator has made a decision about the fate of T. T is blocked until the coordinator recovers.
Three-Phase Commit Protocol. As discussed, the two-phase commit protocol can result in blocking under certain conditions. The three-phase commit protocol is a nonblocking protocol unless all of the sites fail. Conditions for the protocol to work are:
At least one site has not failed.
There is no network partitioning.
For some predetermined number k, no more than k sites can fail simultaneously.
The protocol adds a third phase after the voting phase but before the resolution phase. The coordinator first notifies at least k other sites that it intends to commit, even before it force-writes its own commit log record. If the coordinator fails before issuing the global commit, the remaining sites elect a new coordinator, which checks with the other sites to determine the status of T. Because no more than k sites can fail, and k sites have the “intend to commit” message, those sites can ensure that T commits. Therefore, blocking does not occur unless k sites fail. However, network partitioning can make it appear that more than k sites have failed, and unless the protocol is carefully managed, it is possible that the transaction will appear to be committed in one partition and aborted in another.