
13.2 A Semistructured Data Model
Techniques for searching text documents were originally developed in the field of information retrieval, which was the domain of information scientists rather than database researchers and practitioners. However, with the development of the web, the creation of collections of documents and the searching of those documents became an activity that was done by ordinary computer users rather than just by information specialists. Because of the availability of the rich information resources the web provides, the fields of information science and database management have converged to search and store semistructured data. In the database field, the documents on the web are viewed as data sources similar to other databases, and the process of searching them is akin to querying a database. Unlike data stored in a database, however, data on the web is often less structured, requiring documents to be marked up with metadata that can include tags that give partial structure to documents. This chapter presents a semistructured data model as a method of describing such a partial structure. A semistructured model contains a collection of nodes, each containing data, possibly with different schemas. Each node itself contains information about the structure of its contents.
Semistructured data can be represented using a graph consisting of nodes and edges. Although other types of semistructured data can be modeled by more complex graphs, a document can often be represented as a tree, having a single root node at the top and a sequence of child nodes below the root. Each child node can itself have child nodes, which, in turn, can have child nodes. A strict rule for trees is that every node, except the root, has exactly one parent node, which is at the level above it in the tree. The nodes can represent either complex objects or atomic values. An edge can represent either the relationship between an object and its subobject, or the relationship between an object and its value. Leaf nodes, which have no subobjects, represent values. There may or may not be a separate schema because the graph is self-describing.
As an example of a tree structure for semistructured data, FIGURE 13.1 shows a hierarchical representation of customer data, which we will refer to as CUSTOMERLIST. The entire document, CUSTOMERLIST, becomes the root of the tree. Each CUSTOMER element is represented as a child of the root. The subelements of CUSTOMER, namely NAME, ADDRESS, TELEPHONE, TYPE, and STATUS, are represented as children of CUSTOMER. The subelements of ADDRESS and TELEPHONE are represented as their children.
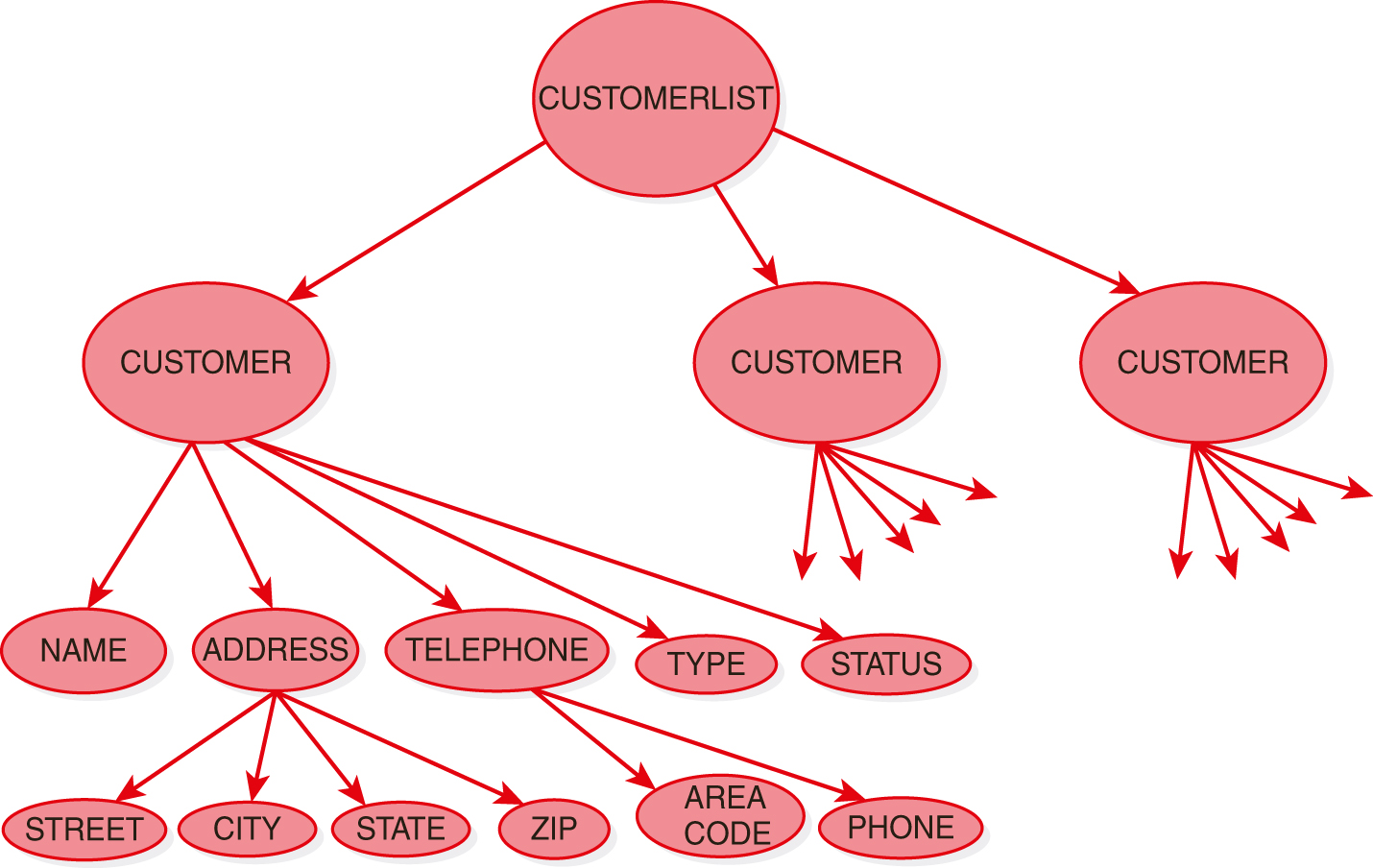
FIGURE 13.1 Hierarchical Representation of CUSTOMERLIST
Two main techniques for self-description of semistructured data such as that shown in Figure 13.1 have evolved over the years. Those techniques are JSON and XML.
JSON was proposed by Douglas Crockford in 2001 and became an internet standard in 2017. JSON is a flexible format that allows objects to be represented as text strings that express names of fields (keys) and values (basic and constructed, such as embedded objects and arrays). JSON became prevalent with the rise of web services because applications can exchange complex data in a single transfer. A string representing an object (which could contain many nested objects) can be parsed by a JavaScript function to create an object in an application program. Many web browsers (e.g., Chrome, Safari, Edge, and Firefox) contain JSON parsers; JSON can be parsed by many programming languages as well. XML was created in 1996 by the World Wide Web Consortium XML Special InterestGroup with the objective of retaining the flexibility of the Standard Generalized Markup Language (SGML) and the simplicity of HTML. SGML is a meta-language that allows users to define their own markup languages. HTML is an application of SGML that works well for displaying text but uses a limited set of tags with fixed meanings, making it relatively inflexible. XML allows users to define their own markup language. For example, users can create tags that describe the data items for the CUSTOMERLIST data in Figure 13.1.
The database community has a great interest in JSON and XML as a means of describing documents of all types, including databases. Using either format, it is possible to represent heterogeneous, semistructured data, facilitating translation of data between different databases. XML is frequently used in applications for ensuring data integrity.
The remainder of this chapter explores the fundamentals of JSON and XML for the representation of semistructured data.