
5.3 Defining the Database: SQL Data Definition Language (DDL)
The most used SQL data definition language (DDL) commands are the following:
CREATE DATABASE
CREATE SCHEMA
CREATE TABLE
CREATE INDEX
ALTER TABLE
RENAME TABLE
DROP TABLE
DROP INDEX
These statements are used to create, change, and destroy the structures that make up the logical model. These commands can be used at any time to make changes to the database structure. Additional commands are available to specify physical details of storage, but we will not discuss them here because they are specific to the system. There are also commands to create and destroy views, which we will discuss in Section 5.5.
5.3.1 CREATE DATABASE, CREATE SCHEMA
In SQL, the command to create a new database has the form
![]()
For example, to create a database called University, we write
![]()
The new database should be immediately available for creating objects. It should open automatically after the creation in the current session, but if the user returns in a new session, he or she will have to open the database again, using a command such as
![]()
For some systems, the word CONNECT is used instead of USE. It is also possible to create separate schemas within a database, using the command
![]()
If we wished to create different schemas within the same database, we would write commands such as
![]()
This command would permit user JoeBlack to use the SampleDB1 schema, provided he is an authorized user.
5.3.2 CREATE TABLE
The CREATE TABLE command is used to create the base tables that form the heart of a relational database. Because it can be used at any time during the life cycle of the system, the database developer can start with a small number of tables and add to them as additional applications are planned and developed.
A base table is close to the abstract notion of a relational table. It consists of one or more column headings, which give the column name and data type, and zero or more data rows, which contain one data value of the specified data type for each of the columns. As in the abstract relational model, the rows are considered unordered. However, the columns are ordered left to right, to match the order of column definitions in the CREATE TABLE command. A simple form of the command is

Here, base-table-name is a user-supplied name (an identifier) for the table. No SQL keywords may be used as the table name, and the table name must be unique within the database. For each column, the user must specify a name that is unique within the table, and a data type. In Oracle, identifiers must be at most 128 bytes long, begin with an alphabetic character, and contain only alphanumeric characters or underscores. Either uppercase or lowercase letters may be used, but Oracle will always display them as uppercase. Although various character sets can be used for the database, it is wise to use the ASCII set for identifiers for platform portability. The maximum number of columns for an Oracle table is 1,000. Note that each line ends with a comma, except the last, which ends with a semicolon. The optional storage specifications section allows the DBA to name the tablespace where the table will be stored. If the tablespace is not specified, the DBMS will create a default space for the table.
FIGURE 5.2 shows the commands to create the base tables for a database for the University example and to insert records into each table. Oracle’s SQL*Plus facility can be used to execute these commands. They can be keyed in at the SQL*Plus prompt, or they can be written using a text editor such as Notepad and copied into SQL*Plus for execution. The schema is
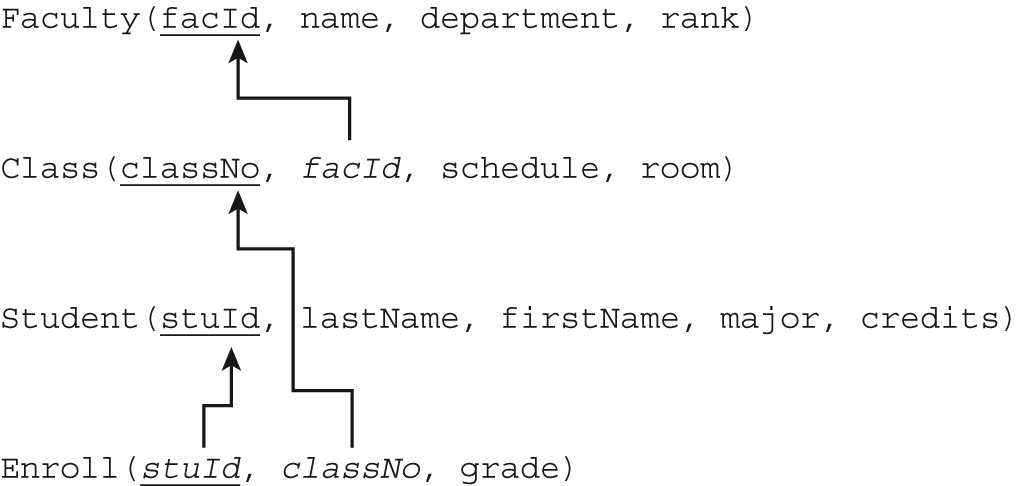
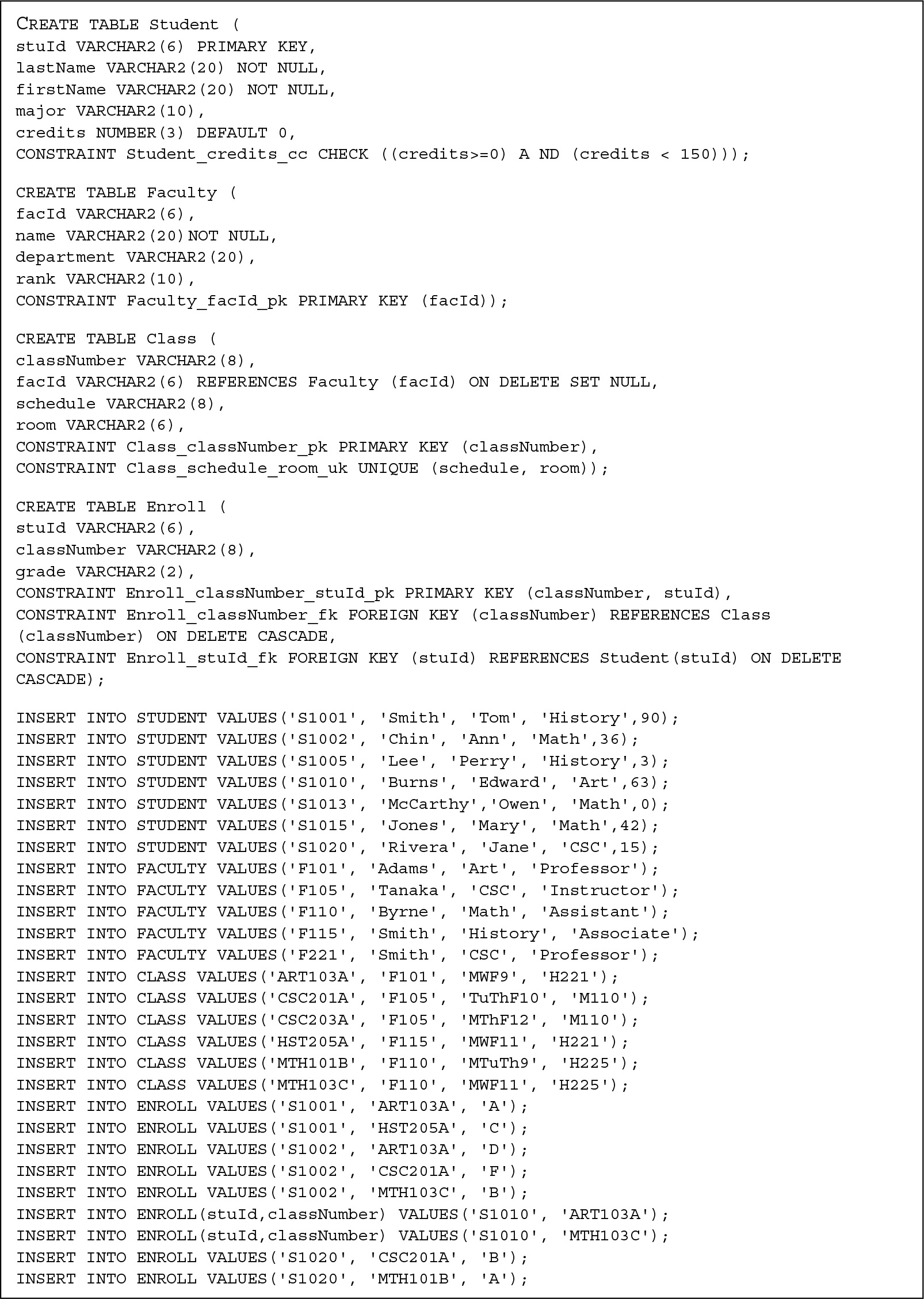
FIGURE 5.2 DDL and INSERTS for University Example
Data Types
The available data types vary from DBMS to DBMS. Built-in data types for strictly relational tables in Oracle include various numeric types, fixed-length and varying-length character strings, date-time and timestamp types, large object types, and others. One of the most common data types in a strictly relational Oracle database is VARCHAR2(n), which stores varying length strings of maximum size n bytes. The user must specify a size n up to 4,000 bytes. For fixed-length strings, the type CHAR(n) can be used, with the maximum allowable size of 2,000 bytes.
For fixed-point numbers, the data type NUMBER(p,s) is used, where p is the precision (the maximum number of significant digits) and s is the scale. In most cases, p is the total number of digits and s is the number of digits to the right of the decimal point, if any. For integers, the s is omitted. Floating-point numbers can also be specified as NUMBER, with no precision or scale specified, or as FLOAT(p), where p, which is optional, is the precision measured in binary digits.
The DATE type is used to store dates and times. In Oracle, values of dates can be entered using the default format 'dd-mon-yy', as in '02-DEC-22', where the month is represented using a three-letter abbreviation.
Microsoft Access supports several types of NUMBER, as well as TEXT, MEMO, DATE/TIME, HYPERLINK, YES/NO, and others. MySQL has several variations of INTEGER, NUMERIC, FLOAT, DATE/TIME, CHAR, VARCHAR, BLOB, and others.
Column and Table Constraints
The DBMS has facilities to enforce data correctness, which the DBA should make use of when creating tables. The relational model uses integrity constraints to protect the correctness of the database, allowing only legal instances to be created. These constraints protect the system from data entry errors that would create inconsistent data. Although the table name, column names, and data types are the only parts required in a CREATE TABLE command, optional constraints can and should be added, both at the column level and at the table level.
The column constraints (also called in-line constraints because they are defined on the same line as the column) include options to specify NULL/NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK, DEFAULT, and REF for any column, immediately after the specification of the column name and data type.
If we do not specify NOT NULL, the system will allow the column to have null values, meaning the user can insert records that have no values for those columns. When a null value appears in a column of a record, the system distinguishes it from a blank string or zero value and treats it differently in computations and logical comparisons. It is desirable to be able to insert null values in certain situations; for example, when a college student has not yet declared a major, we might want to set the major column to NULL. However, the use of null values can create complications, especially in operations such as joins, so we should use NOT NULL when it is appropriate. In Figure 5.2, we specified the NOT NULL constraint for student and faculty names.
We can optionally specify that a given column is to have unique values by writing the UNIQUE constraint. In that case, the system will reject the insertion of a new record that has the same value in that column as a record that is already in the database.
If the primary key is not composite, it is also possible to specify PRIMARY KEY as a column constraint simply by adding the words PRIMARY KEY after the data type for the column. For example, for the stuId column specification in the Student table, we wrote
![]()
which is an in-line constraint.
Clearly, no duplicate values are permitted for the primary key. Neither are null values because we could not distinguish between two different records if they both had null key values, so the specification of PRIMARY KEY in SQL carries an implicit NOT NULL constraint as well as a UNIQUE constraint. However, we may wish to ensure uniqueness for candidate keys as well, and we should specify UNIQUE for them when we create the table. It is also desirable to specify a NOT NULL constraint for candidate keys when it is possible to ensure that values for these columns will always be available. For example, if we wanted to include Social Security numbers for all faculty members, we could ensure that all faculty records contain unique Social Security numbers by specifying in the Faculty table
![]()
Oracle provides IDENTITY-based columns to create system-generated numeric sequences that can be used as primary keys, or for other uses. The line
![]()
would create a primary key called id that starts at value 1 and is automatically incremented whenever a new row is inserted in the table. You can change both the starting value and the increment by adding START WITH m INCREMENT BY n, where both m and n are integers. An IDENTITY column is useful when you do not want to enter your own values for the primary key, but you want the system to supply a unique value whenever you enter a record. Only one such column is permitted per table. Note that the IDENTITY column is not automatically the primary key, so you must still add the primary key constraint.
Foreign keys that consist of a single column can also be defined by in-line constraints, as shown in the creation of the Class table, where facId is defined as a foreign key that references the Faculty table in the line
![]()
The foreign key constraint requires that we identify the referenced table where the column appears as the primary key, and that we name the corresponding column in that table. This is necessary because it is possible the column has a different name in the home relation. The home table must be created prior to the creation of the table that references it.
The CHECK constraint can be used to specify a condition that the rows of the table are not permitted to violate to ensure that values provided for attributes are appropriate. The DEFAULT constraint allows us to provide a default value for the column. Every record that is inserted without a value for that column is then given the default value automatically. We can optionally provide a name for any constraint. If we do not specify a name, the system will automatically assign one. However, a user-defined name is preferable because it provides an opportunity to choose a meaningful name, which is useful if we wish to modify the constraint later. We precede the constraint name with the keyword CONSTRAINT.
For example, in defining the credits column in the Student table, we could specify a default value of 0 and a CHECK constraint called Student_credits_cc by writing directly in the column definition line
![]()
Here, we gave the CHECK constraint the name Student_credits_cc, using the form of identifying the table, the column(s), and the type of constraint (cc), The abbreviations pk (primary key), fk (foreign key), nn (not null), uk (unique), and cc (check constraint) are often used in constraint names to refer to the type of constraint defined.
Oracle also has an option to provide a default value whenever a null value is entered for a column. For example, if we had specified
![]()
then any student row entered without a major would be assigned an Arts major.
A REF constraint is used when a column references an object and is not a strictly relational feature, so we will defer discussion of it. We can also specify a default value for a column.
Table constraints, also called out-of-line constraints, appear after all the columns have been declared and can include the specification of a primary key, foreign keys, uniqueness, references, checks, and general constraints that can be expressed as conditions to be checked, with the exception of NOT NULL, which is always a column constraint. In an out-of-line constraint, we must use the keyword CONSTRAINT, which can be optionally followed by an identifier. Then we specify the type of constraint and the column or columns for the constraint. In Figure 5.2, we made the CHECK constraint on credits in the Student table an out-of-line constraint.
If the primary key is a composite key, it must be identified using a table constraint rather than a column constraint. For the Enroll table in Figure 5.2, we specified that the combination of stuId and classNumber is the primary key in the line
![]()
We also used a table constraint to specify that stuId is a foreign key for which the Student table is the home table by writing
![]()
If a foreign key is composite, we must use a table constraint to identify it. For example, if we had a Customer table with a composite primary key, and an Order table with a foreign key as in
![]()
then in the Order table we would identify the composite foreign key using a table constraint, as in
![]()
SQL allows us to specify what is to be done with records containing foreign key values when the records they relate to are deleted in their home table. For the University example, what should happen to a Class record when the record of the faculty member assigned to teach the class is deleted? The DBMS could automatically do the following:
Delete all Class records for that faculty member, an action performed when we specify ON DELETE CASCADE in the foreign key specification in SQL.
Set the facId in the Class record to a null value, an action performed when we write ON DELETE SET NULL in SQL.
Not allow the deletion of a Faculty record if there is a Class record that refers to it, a default action performed when we do not explicitly specify an action. Some DBMSs use ON DELETE NO ACTION for this choice.
As shown in Figure 5.2, for the Class table we have chosen ON DELETE SET NULL. Also note the choices we made for the Enroll table for changes made to both classNumber and stuId.
The table uniqueness constraint mechanism can be used to specify that the values in a combination of columns must be unique. For example, to ensure that no two classes have the same schedule and room, we wrote
![]()
There are SQL commands to disable, enable, defer checking, alter, or drop constraints, provided we know the constraint names.
5.3.3 CREATE INDEX
We can optionally create indexes for tables to facilitate fast retrieval of records with specific values in a column. An index keeps track of which values exist for the indexed column and which records have those values. For example, if we have an index on the lastName column of the Student table, and we write a query asking for all students with the last name of Smith, the system will not have to scan all Student records to pick out the desired ones. Instead, it will read the index, which will indicate the physical address of the records with the desired name.
A table can have any number of indexes, which are stored as B trees or B+ trees in separate index files, usually close to the tables they index. Indexes can be created on single columns or combinations of columns. However, because indexes must be updated by the system every time the underlying tables are updated, additional overhead is required. Aside from choosing which indexes will exist, users have no control over the use or maintenance of indexes. The system chooses which, if any, index to use in searching for records. A simple form of the command for creating an index is
![]()
If the UNIQUE specification is used, uniqueness of the indexed column or combination of columns will be enforced by the system. Although indexes can be created at any time, we may have a problem if we try to create a unique index after the table has records stored in it because the values stored for the indexed column or columns may already contain duplicates. In this case, the system will not allow the unique index to be created.
To create an index on lastName for the Student table, we would write
![]()
The name of the index should be chosen to indicate the table and the column(s) used in the index. Up to 32 columns, regardless of where they appear in the table, may be used in an index. The first column named determines major order, the second gives minor order, and so on. For each column, we may specify that the order is ascending, ASC, or descending, DESC. If we choose not to specify order, ASC is the default. If we write
![]()
then an index file called Fac_dept_name_ix will be created for the Faculty table. Entries will be in alphabetical order by department. Within each department, entries will be in alphabetical order by faculty name.
By default, Oracle creates an index on the primary key of each table that is created. The user should create additional indexes on any column(s) that are often used in queries, to speed up execution of those queries. Foreign key columns, which are often used in joins, are good candidates for indexing. In addition to the usual type of indexes described here, Oracle allows more advanced indexes to be created.
5.3.4 Alter Table, Rename Table
Once a table has been created, users might find it more useful if the table contained an additional data item, did not have a particular column, had different data types, or had other constraints. The dynamic nature of a relational database structure makes it possible to change existing base tables. For example, to add a new column on the right of the table, we use a command of the form
![]()
An ALTER TABLE ...ADD command causes the new column to be added to all records already stored in the table, and null values to be assigned to that column in all existing records. Notice we cannot use the NOT NULL specification for the column unless we also specify a DEFAULT value.
If we want to add a new column, cTitle, to our Class table, we can do so by writing
![]()
The schema of the Class table would then be
![]()
All old Class records would then have null values for cTitle, but we could provide a title for any new Class records we insert and update old Class records by adding titles to them.
We can also drop columns from existing tables with the command
![]()
To drop the cTitle column and return to our original structure for the Class table, we would write
![]()
We can also modify the properties of columns in a table, changing the data type, size, default value, or constraints, using the command
![]()
The new specifications for the column use the same wording as they would in a CREATE TABLE command. The data type can be changed only if all rows of the table contain null values for the column being modified. The size or precision can always be increased even if there are non-null values stored, but they can be decreased only if no existing rows violate the new specifications.
If we want to add, drop, or change a constraint, we can use the same ALTER TABLE command, using the same wording for the constraint clause as in the CREATE TABLE command. For example, if we created the Class table and neglected to make facId a foreign key in Class, we could add the constraint at any time by writing
![]()
We could drop an existing named constraint using the ALTER TABLE command. For example, to drop the check condition on the credits attribute of Student that we created earlier, we could write
![]()
We can change the name of an existing table easily by the command
![]()
To rename a column, use the ALTER TABLE command, as in
![]()
5.3.5 DROP Statements
Tables can be dropped at any time by the SQL command
![]()
When this statement is executed, the table itself and all records contained in it are removed. In addition, all indexes and, as we will see later, all views that depend on it are dropped. Naturally, the DBA confers with potential users of the table before taking such a drastic step. Note that if the table is referred to by foreign keys, it may not be possible to drop the table until the references to it have been resolved.
Any existing index can be destroyed by the command
![]()
When an index is dropped, any access plans for applications that depend on it are marked as invalid. When an application calls them, a new access plan is devised to replace the old one.
5.3.6 Additional SQL Data Definition Language (DDL) Example
FIGURE 5.3 shows the DDL to create a Workers and Projects database, as well as INSERT statements to add records. The relational schema is
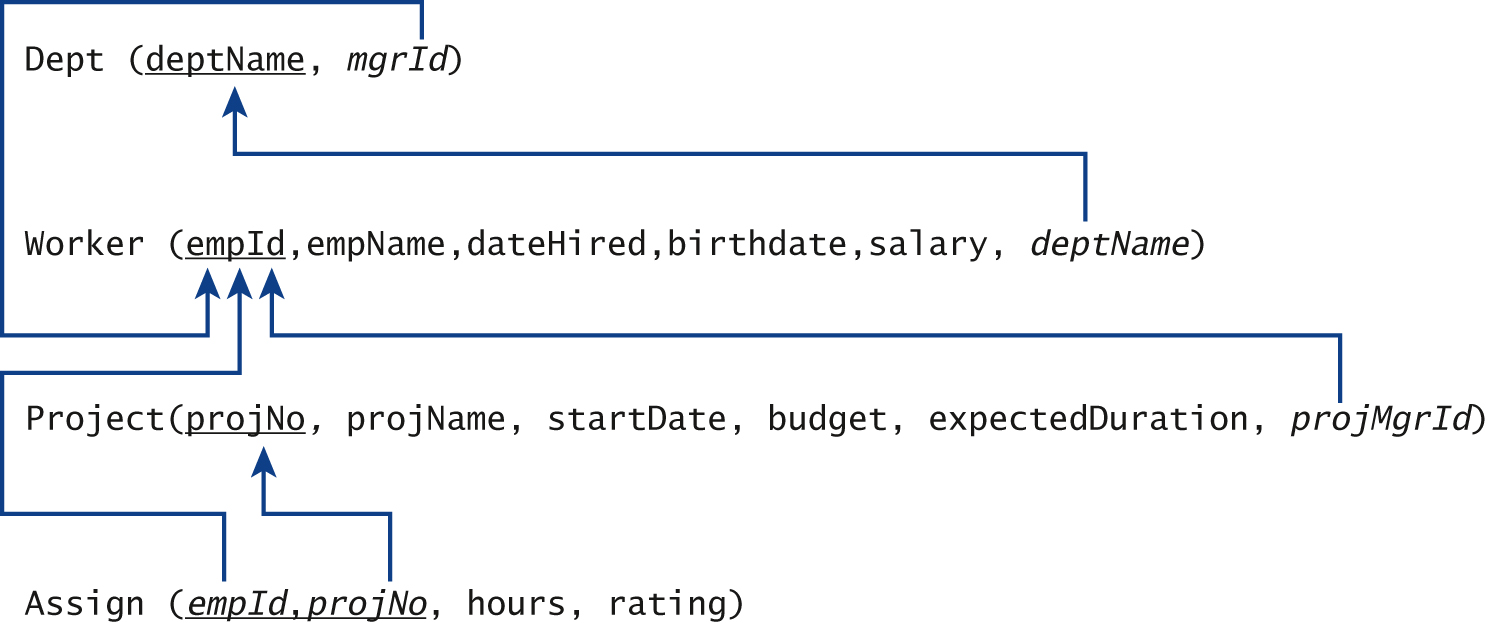
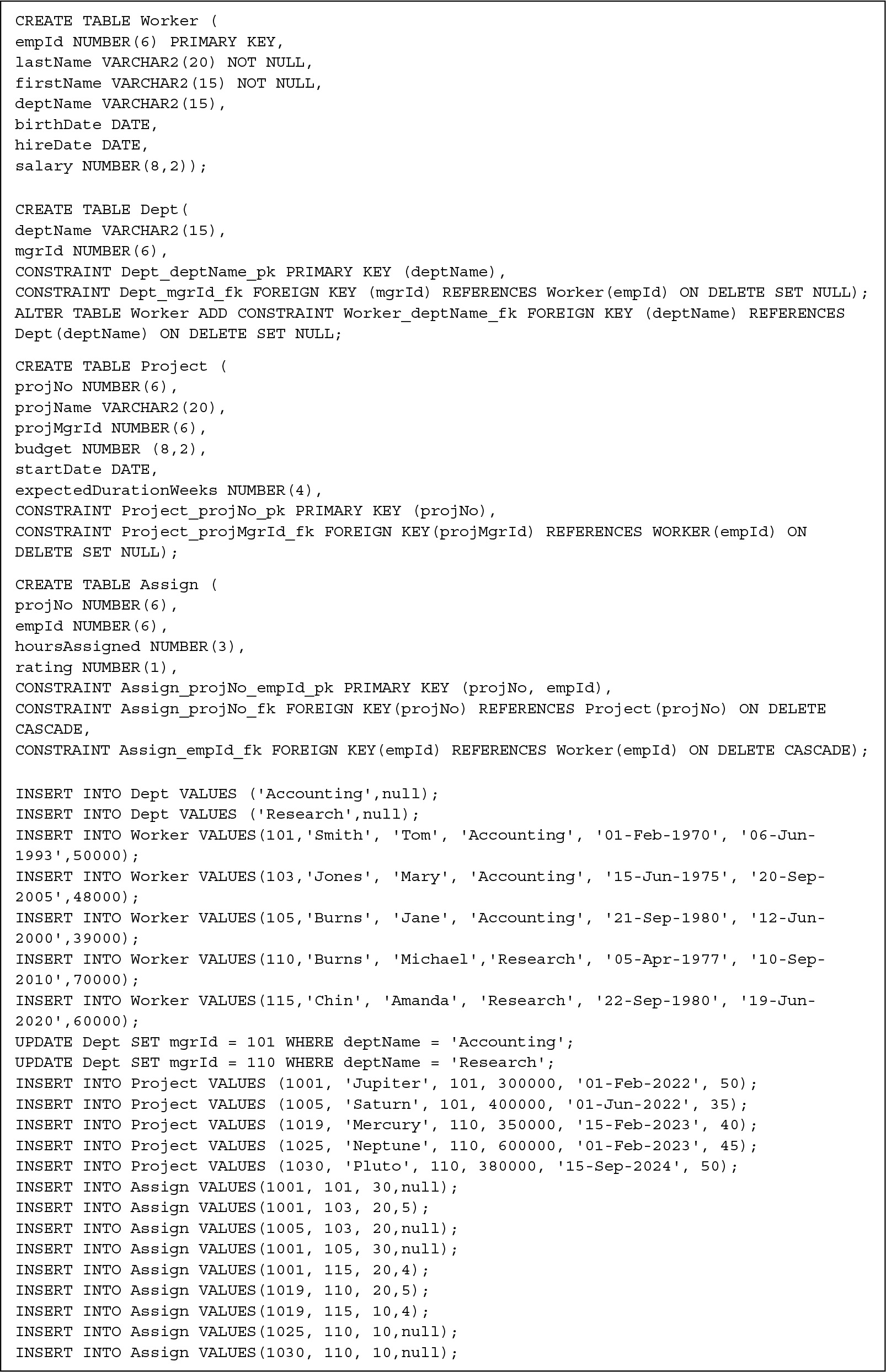
FIGURE 5.3 DDL and Inserts for Workers and Projects Example
In this schema, the foreign key mgrId in Dept references the Worker table, which in turn contains a foreign key, deptName, that refers to the Dept table. Because the home table for a foreign key must exist before the table that references it, it appears difficult to create both tables with their corresponding foreign keys because each requires that the home table referenced has been previously defined. One solution is to create the Worker table without the foreign key constraint, create the Dept table referencing the Worker table, and then use the ALTER TABLE command to add the foreign key constraint to the Worker table, as shown in Figure 5.3.
Examining the INSERT commands to enter records into the tables, we also see that care must be taken to avoid violating these foreign key constraints when we enter rows. The value of mgrId in a Dept record must refer to an actual manager’s record in the Worker table or be null, but the Worker record must contain a deptName value. We solve this problem by initially putting in a null value for the mgrId when inserting a Dept record, then inserting the manager’s Worker record, and finally updating the Dept record with the manager’s empId.