
Today’s trend is for modern hardware architectures to offer increasing numbers of processors and cores. Sutter [2005] wrote, ‘The free lunch is over’ as many of the traditional approaches to improving performance ran out of steam. Energy costs, and the difficulty of dissipating that energy, have led hardware manufacturers away from increasing clock speeds (power consumption is a cubic function of clock frequency) towards placing multiple processor cores on a single chip (where the increase in energy consumption is linear in the number of cores). As there is no reason to expect this trend to change, designing and implementing applications to exploit the parallelism offered by hardware will become more and more important. On the contrary, heterogeneous and other non-uniform memory architectures will only increase the need for programmers to take the particular characteristics of the underlying platform into account.
Up to now we have assumed that, although there may be many mutator threads there is only a single collector thread. This is clearly a poor use of resources on modern multicore or multiprocessor hardware. In this chapter we consider how to parallelise garbage collection, although we continue to assume that no mutators run while garbage collection proceeds and that each collection cycle terminates before the mutators can continue. Terminology is important. Early papers used terms like ‘concurrent’, ‘parallel’, ‘on-the-fly’ and ‘real-time’ interchangeably or inconsistently. We shall be more consistent, in keeping with most usage today.
Figure 14.1a represents execution on a single processor as a horizontal bar, with time proceeding from left to right, and shows mutator execution in white while different collection cycles are represented as by distinct non-white shades. Thus grey boxes represent actions of one garbage collection cycle and black boxes those of the next. On a multiprocessor, suspension of the mutator means stopping all the mutator threads. Figure 14.1b shows the general scenario we have considered so far: multiple mutator threads are suspended while a single processor performs garbage collection work. This is clearly a poor use of resources. An obvious way to reduce pause times is to have all processors cooperate to collect garbage (while still stopping all mutator threads), as illustrated in Figure 14.1c. This parallel collection is the topic of this chapter.
These scenarios, where collection cycles are completed while the mutators are halted, are called stop-the-world collection. We note in passing that pause times can be further diminished either by interleaving mutator and collector actions (incremental collection) or by allowing mutator and collector threads to execute in parallel (concurrent collection), but we defer discussion of these styles of collection to later chapters. In this chapter, we focus on parallelising tracing garbage collection algorithms. Reference counting is also a naturally parallel and concurrent technique which we discussed in Chapter 5; again, we defer consideration of how this can be improved for a multiprocessor setting until Chapter 18. Here we consider how parallel techniques can be applied to each of the four major components of tracing garbage collection: marking, sweeping, copying and compaction techniques.
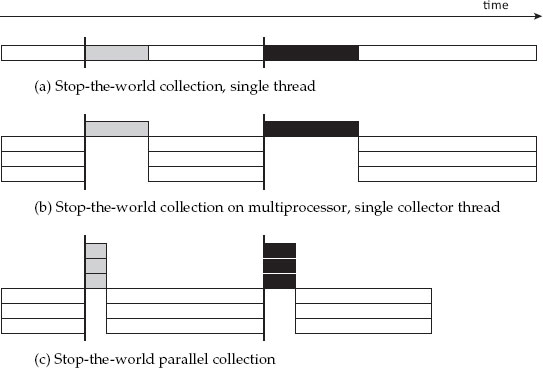
Figure 14.1: Stop-the-world garbage collection: each bar represents an execution on a single processor. The coloured regions represent different garbage collection cycles.
14.1 Is there sufficient work to parallelise?
The goal of parallelising collection is to reduce the time overhead of garbage collection by making better use of available hardware resources. In the case of stop-the-world collection, parallel garbage collection will reduce pause times; in the case of incremental or concurrent collection, it will shorten garbage collection cycle times. As with parallelising any problem, the first requirement is to ensure that there is sufficient work to make a parallel solution worthwhile. Inevitably, parallel collection will require some synchronisation between cooperating garbage collection threads, and this will incur overhead. Different solutions may require the use of locks, or atomic primitive operations such as Compare-AndSwap, and careful design of auxiliary data structures. No matter how careful we are to optimise these mechanisms, they cannot be as efficient as uniprocessor solutions. The question therefore arises, is there sufficient garbage collection work available for the gains offered by a parallel solution to more than offset these costs?
Some garbage collection problems appear inimical to parallelising. For example, a mark-sweep collector may need to trace a list, but this is an inherently sequential activity: at each tracing step, the marking stack will contain only a single item, the next item in the list to be traced. In this case, only one collector thread will do work and all others will stall, waiting for work. Siebert [2008] shows that the number of times n that a processor stalls for lack of work during a parallel mark phase on a p-processor system is limited by the maximum depth of any reachable object o:
This formulation depends on the unrealistic assumption that all marking steps take the same amount of time. Of course, these steps are not uniform but depend on the kind of object being scanned. Although most objects in most programming languages are typically small — in particular they contain only a few pointers — arrays may be larger and often very much larger than the common case (unless they are implemented as a contiguous ‘spine’ which contains pointers to fixed-size arraylets that hold the array elements).
Fortunately, typical applications comprise a richer set of data structures than a single list. For example, tracing a branching data structure such as a tree will generate more work at each step than it consumes until the trace reaches the leaves. Furthermore, there are typically multiple sources from which tracing can be initiated. These include global variables, the stacks of mutator threads and, in the case of generational or concurrent collectors, remembered sets. In a study of small Java benchmarks, Siebert finds that not only do many programs have a fairly shallow maximum depth but, more significantly, that the ratio between the maximum depth and the number of reachable objects is very small: stalls would occur on less than 4% of the objects marked, indicating a high degree of potential parallelism, with all the benchmarks scaling well up to 32 processors (or even more in some cases).
Tracing is the garbage collection component that is most problematic for identifying potential parallelism. The opportunities for parallelising other components, such as sweeping or fixing up references to compacted objects, are more straightforward, at least in principle. An obvious way to proceed is to split those parts of the heap that need to be processed into a number of non-overlapping regions, each of which is managed in parallel by a separate processor. Of course, the devil is in the details.
The second requirement of a parallel solution is that work is distributed across available hardware resources in a way that minimises the coordination necessary yet keeps all processors as busy as possible. Without load balancing, naïve parallelisation may lead to little speedup on multiprocessors [Endo et al, 1997]. Unfortunately, the goals of load balancing and minimal coordination typically conflict. A static balance of work might be determined in advance of execution, at the startup of the memory manager or, at the latest, before a collection cycle. It may require no coordination of work between garbage collection threads other than to reach a consensus on when their tasks are complete. However, static partitioning may not always lead to an even distribution of work amongst threads. For example, a contiguous mark-compact space on an N-processor system might be divided into N regions, with each processor responsible for fixing up references in its own region. This is a comparatively simple task yet its cost is dependent on the number of objects in the region and the number of references they contain, and so on. Unless these characteristics are broadly similar across regions, some processors are likely to have more work to do than others. Notice also that as well as balancing the amount of work across processors, it is also important to balance other resources given to those processors. In a parallel implementation of Baker’s copying collector [1978], Halstead [1984, 1985] gave each processor its own fixed fromspace and tospace. Unfortunately, this static organisation frequently led to one processor exhausting its tospace while there was room in other processors’ spaces.
Many collection tasks require dynamic load balancing to distribute work approximately evenly. For jobs where it is possible to obtain a good estimate of the amount of work to be done in advance of performing it, even if this estimate will vary from collection to collection, the division of labour may be done quite simply, and in such a way that no further cooperation is required between parallel garbage collector threads. For example, in the compaction phase of a parallel mark-compact collector, after the marking phase has identified live objects, Flood et al [2001] divide the heap into N regions, each containing approximately equal volumes of live data, and assign a processor to compact each region separately and in parallel.
More often it is not possible to estimate, and hence divide, the work to be done in advance of carrying out that work. In this case, the usual solution is to over-partition the work into more sub-tasks than there are threads or processors, and then have each compete to claim one task at a time to execute. Over-partitioning has several advantages. It is more resilient to changes in the number of processors available to the collector due to load from other processes on the machine, since smaller sub-tasks can more easily be redistributed across the remaining processors. If one task takes longer than expected to complete, any further work can be carried out by threads that have completed their smaller tasks. For example, Flood et al also over-partition the heap into M object-aligned areas of approximately equal size before installing forwarding pointers; M was typical chosen to be four times the number of collection threads. Each thread then competes to claim an area, counting the volume of live data in it and coalescing adjacent unmarked objects into a single garbage block. Notice how different load balancing strategies are used in different phases of this collector (which we discuss in more detail later).
We simplify the algorithms we present later in this chapter by concentrating on the three key sub-tasks of acquiring, performing and generating collection work. We abstract this by assuming in most cases that each collector thread t executes the following loop:
while not terminated()
acquireWork()
performWork()
generateWork()
Here, acquireWork attempts to obtain one, or possibly more than one, unit of work; performWork does the work; and generateWork may take one or more new work units discovered by performWork and place them in the general pool for collector threads to acquire.
It might seem that the best possible load balancing would be to divide the work to be done into the smallest possible independent tasks, such as marking a single object. However, while such fine granularity might lead to a perfect balancing of tasks between processors since whenever a task was available any processor wanting work could claim it, the cost of coordinating processors makes this impractical. Synchronisation is needed both for correctness and to avoid, or at least minimise, repeating work. There are two aspects to correctness. It is essential to prevent parallel execution of garbage collector threads from corrupting either the heap or a collector’s own data structures. Consider two examples. Any moving collector must ensure that only a single thread copies an object. If two threads were to copy it simultaneously, in the best case (where the object is immutable) space would be wasted but the worst case risks the two replicas being updated later with conflicting values. Safeguarding the collector’s own data structures is also essential. If all threads share a single marking stack, then all push and pop operations must be synchronised in order to avoid losing work when more than one thread manipulates the stack pointer or adds/removes entries.
Synchronisation between collector threads has time and space overheads. Mechanisms to ensure exclusive access may use locks or wait-free data structures. Well-designed algorithms minimise the occasions on which synchronisation operations are needed, for example by using thread-local data structures. Where synchronisation is required, the fast case should be the common case: locks should be rarely contended and atomic operations like CompareAndSwap should be expected to succeed. If they don’t succeed, it is often preferable that they are allowed to compete for other work in a wait-free manner rather than having to retry. However, sometimes exclusive access is not essential for correctness and so some synchronisation actions can be omitted. For example, setting a mark bit in an object’s header word is an idempotent operation. The only consequence of two threads setting the same bit is the risk of some unnecessary work, but this may be cheaper than the cost of making the action synchronised.
Implementations trade load balancing against coordination costs. Modern parallel collectors typically have worker threads compete to acquire larger tasks, that they expect to complete without further synchronisation. These tasks may be organised in a variety of ways: as thread-local marking stacks, as heap regions to scan or as other pools of (usually fixed-size) buffers of work. Of course, employing such data structures also incurs a space cost on account of their metadata and fragmentation, but these costs tend to be small.
In the rest of this chapter we will consider particular solutions to the problems of parallelising marking, sweeping, copying and compaction. Throughout we assume that all mutator threads are halted at GC-safe points while the collector threads run to completion. As far as possible, we situate these case studies within a consistent framework. In all cases, we shall be interested in how the algorithms acquire, perform and generate collection work. The design and implementation of these three activities determines what synchronisation is necessary, the granularity of the workloads for individual collector threads and how these loads are balanced between processors.
Parallel garbage collection algorithms can be broadly categorised as either processor-centric or memory-centric. Processor-centric algorithms tend to have threads acquire work quanta that vary in size, typically by stealing work from other threads. Little regard is given to the location of the objects that are to be processed. However, as we have seen in earlier chapters, locality has significant effects on performance, even in the context of a uniprocessor. Its importance is even greater for non-uniform memory or heterogeneous architectures. Memory-centric algorithms, on the other hand, take locality into greater account. They typically operate on contiguous blocks of heap memory and acquire/release work from/to shared pools of buffers of work; these buffers are likely to be of a fixed size. These are most likely to be used by parallel copying collectors.
Finally, we are concerned with the termination of parallel collection. Threads not only acquire work to do but also generate further work dynamically. Thus it is usually insufficient to detect termination of a collection cycle by, say, simply checking that a shared pool of work is empty, since an active thread may be about to add further tasks to that pool.
Marking comprises three activities: acquisition of an object to process from a work list, testing and setting one or more marks, generating further marking work by adding the object’s children to a work list. All known parallel marking algorithms are processor-centric. No synchronisation is necessary to acquire an object to trace if the work list is thread-local and non-empty. Otherwise the thread must acquire work (one or more objects) atomically, either from some other thread’s work list or from some global list. Atomicity is chiefly necessary to maintain the integrity of the list from which the work is acquired. Marking an object more than once or adding its children to more than one work list affects only performance rather than correctness in a non-moving collector. Although the worst case is that another thread might redundantly process an entire data structure in lock step with the first collector thread, such scheduling is unlikely to occur in practice. Thus, if an object’s mark is represented by a bit in its header or by a byte in a byte map, it can be tested and set with a non-atomic load and store. However, if marks are stored in a bitmap that is shared between marking threads, then the bit must be set with an atomic operation. The object’s children can be added to the marking list without synchronisation if the list is private and unbounded. Synchronisation is necessary if the list is shared or if it is bounded. In the latter case, some marking work must be transferred to a global list whenever the local list is filled. If the object is a very large array of pointers, pushing all its children onto a work list as a single task may induce some load imbalance. Some collectors, especially those for real-time systems, process the slots of large objects incrementally, often by representing a large object as a linked data structure rather than a single contiguous array of elements.
Work stealing. Endo et al [1997], Flood et al [2001] and Siebert [2010] use work stealing to balance loads. Whenever a thread runs out of marking work, it steals work belonging to another thread. In a parallel implementation of the Boehm and Weiser [1988] conservative mark-sweep collector, Endo et al provide each marker thread with its own local mark stack and a stealable work queue (Algorithm 14.1). Periodically, each thread checks its own stealable mark queue and, if it is empty, transfers all its private mark stack (apart from local roots) to the queue. An idle thread acquires marking work by first examining its own stealable queue and then other threads’ queues. When a thread finds a non-empty queue, it steals half of the queue’s entries into its own mark stack. Multiple threads may seek work to steal at the same time, so the stealable queues are protected by locks. Endo et al found that a claim-lock-then-steal approach led to processors spending considerable time trying to acquire locks so they replaced it by a try-lock-then-steal-else-skip strategy. If a thread observes that a queue is locked or if it fails to lock the queue, it gives up on that queue and skips to the next one. This sequence is ‘lock-free’.
Any parallel collector needs to take care with how mark bitmaps are treated and how large arrays are processed. Bits in a mark bitmap word must be set atomically. Rather than locking the word then testing the bit, Endo et al use a simple load to test the bit and, only if it is not set, attempt to set it atomically, retrying if the set fails (because bits are only set in this phase, only a limited number of retries are needed), illustrated in Algorithm 14.2. Collectors like that of Flood et al [2001], which store the mark bit in the object header, can of course mark without atomic operations, though.
Processing large arrays of pointers has been observed to be a source of problems. For example, Boehm and Weiser [1988] tried to avoid mark stack overflow by pushing large objects in smaller (128 word) portions. Similarly, Endo et al split a large object into 512 byte sections before adding them to a stack or queue in order to improve load balancing; here, the stack or queue holds ⟨address, size⟩ pairs.
The Flood et al [2001] parallel generational collector manages its young generation by copying and its old generation by mark-compact collection. In this section, we consider only parallel marking. Whereas Endo et al used a stack and a stealable queue per processor, Flood et al use just a single deque per collector thread. Their lock-free, work stealing algorithm is based on Arora et al [1998]; its low overhead allows work to be balanced at the level of individual objects. The algorithm works as follows; see also the detailed presentation in Section 13.8. A thread treats the bottom of its deque as its mark stack; its push does not require synchronisation and its pop operation requires synchronisation only to claim the last element of the deque. Threads without work steal an object from the top of other threads’ deques using the synchronised remove operation. One advantage of this work stealing design is that the synchronisation mechanism, with its concomitant overheads, is activated only when it is needed to balance loads. In contrast, other approaches (such as grey packets, which we discuss below) may have their load balancing mechanism permanently ‘turned on’.
Algorithm 14.1: The Endo et al [1997] parallel mark-sweep algorithm.
1 shared stealableWorkQueue[N] | /* one per thread */ |
2 me ← myThreadId
3
4 acquireWork():
5 if not isEmpty(myMarkStack) | /* my mark stack has work to do */ |
6 return
7 lock(stealableWorkQueue[me])
8 /* grab half of my stealable work queue */
9 n ← size(stealableWorkQueue[me]) / 2
10 transfer(stealableWorkQueue[me], n, myMarkStack)
11 unlock(stealableWorkQueue[me])
12
13 if isEmpty(myMarkStack)
14 for each j in Threads
15 if not locked(stealableWorkQueue[j])
16 if lock(stealableWorkQueue[j])
17 /* grab half of his stealable work queue */
18 n ← size(stealableWorkQueue[j]) / 2
19 transfer(stealableWorkQueue[j], n, myMarkStack)
20 unlock(stealableWorkQueue[ j])
21 return
22
23 performWork():
24 while pop(myMarkStack, ref)
25 for each fld in Pointers(ref)
26 child ← *fld
27 if child ≠ null && not isMarked(child)
28 setMarked(child)
29 push(myMarkStack, child)
30
31
32 generateWork(): | /* transfer all my stack to my stealable work queue */ |
33 if isEmpty(stealableWorkQueue[me])
34 n ← size(markStack)
35 lock(stealableWorkQueue[me])
36 transfer(myMarkStack, n, stealableWorkQueue[me])
37 unlock(stealableWorkQueue[me])
Algorithm 14.2: Parallel marking with a bitmap
1 setMarked(ref):
2 oldByte ← markByte(ref)
3 bitPosition ← markBit(ref)
4 loop
5 if isMarked(oldByte, bitPosition)
6 return
7 newByte ← mark(oldByte, bitPosition)
8 if CompareAndSet(&markByte(ref), oldByte, newByte)
9 return

Figure 14.2: Global overflow set implemented as a list of lists [Flood et al, 2001]. The class structure for each Java class holds the head of a list of overflow objects of that type, linked through the class pointer field in their header.
The Flood et al thread deques are fixed size in order to avoid having to allocate during a collection. However, this risks overflow, so they provide a global overflow set with just a small, per class, overhead. The class structure for each Java class C is made to hold a list of all the overflow objects of this class, linked together through their type fields (illustrated in Figure 14.2). Although the overflow link overwrites the object’s type — making this design inappropriate for a concurrent collector where mutators need quick access to the object’s type — it can be recovered as the object is removed from the overflow list. Overflow is handled as follows. Whenever pushing an item onto the bottom of a thread’s deque would cause it to overflow, items in the bottom half of the deque are moved into the overflow sets of their classes. Conversely, threads looking for work try to fill half of their deque from the overflow set before trying to steal from other threads’ deques.
Siebert [2010] also uses work stealing for a parallel and concurrent implementation of the Jamaica real-time Java virtual machine. Jamaica breaks objects into linked blocks in order to bound the time of any mark step; thus, the collector works with blocks rather than objects. One consequence is that colours are associated with blocks. As we shall see in Chapter 15, concurrent mutators and collectors may both need to access lists of grey blocks. In order to avoid having to synchronise such accesses, the Jamaica VM uses processor-local grey lists. The cost of this design is that a block’s colour is represented by a word rather than a few bits. A thread marks a block grey by using a CompareAndSwap operation to link it through this colour word into a local grey list of the processor on which the thread is running. To balance loads, Siebert steals other threads’ work lists wholesale: a thread without work attempts to steal all of another thread’s grey list. To prevent two threads from working on the same grey block, a new colour anthracite is introduced for blocks while they are being scanned in a mark step. Thief threads also steal by attempting to change the colour of the head of the grey list of another processor to anthracite. This mechanism is very coarse, and best suited to the case that the victim thread is not performing any collection work but maybe only adding blocks to its grey list as it executes write barriers. This is a plausible scenario for a real-time, concurrent collector. However, if all threads are collecting garbage, it may degrade to a situation where all threads compete for a single remaining list of grey blocks. Siebert writes that this does not occur often in practice.
Algorithm 14.3: The Flood et al [2001] parallel mark-sweep algorithm
1 shared overflowSet
2 shared deque [N] | /* one per thread */ |
3 me ← myThreadId
4
5 acquireWork():
6 if not isEmpty(deque[me])
7 return
8 n ← size(overflowSet) / 2
9 if transfer(overflowSet, n, deque[me])
10 return
11 for each j in Threads
12 ref ← remove(deque[j]) | /* try to steal from |
13 if ref ≠ null
14 push(deque[me], ref)
15 return
16
17 performWork():
18 loop
19 ref ← pop(deque[me])
20 if ref = null
21 return
22 for each fld in Pointers(ref)
23 child ← *fld
24 if child ≠ null && not isMarked(child)
25 setMarked(child)
26 if not push(deque[me], child)
27 n ← size(deque[me]) / 2
28 transfer(deque[me], n, overflowSet)
29
30 generateWork():
31 /* nop */
Termination with work stealing. Finally, the collector must be able to determine when a phase is complete, that is, when all the cooperating threads have completed their activities. Endo et al [1997] originally tried to detect termination with a single global count of the number of mark stacks and stealable mark queues that were empty. However, contention to update this counter atomically serialised termination, with large systems (32 processors or more) spending a significant amount of time acquiring the lock. Their solution, presented in detail in Algorithm 13.18, was to provide each processor with two flags indicating whether their mark stack or queue was empty: no locks are necessary to set or clear these flags. To detect termination, a processor clears a global detection-interrupted flag and checks through all the other processors’ flags. Finally, it checks the detection-interrupted flag again in case any other processor has reset it and started work. If not, termination is complete. This method required a strict protocol to be followed when a processor A steals all the tasks of processor B. First, A must clear its stack-empty flag, then set the detection-interrupted flag and finally B’s queue-empty flag. Unfortunately, as Petrank and Kolodner [2004] point out, this protocol is flawed if more than one thread is allowed to detect termination since a second detector thread may clear the detection-interrupted flag after the first detector thread has set it, thus fooling the first detector thread into believing that the flag remained clear throughout.

Figure 14.3: Grey packets. Each thread exchanges an empty packet for a packet of references to trace. Marking fills an empty packet with new references to trace; when it is full, the thread exchanges it with the global pool for another empty packet.
Petrank and Kolodner [2004] employ a solution common to many concurrency problems. They ensure that only one thread at a time can try to detect termination by introducing a lock: a synchronised, global, detector-identity word. Before attempting to detect termination, a thread must check that the detector-identity’s is -1 (meaning that no thread is currently trying to detect termination) and, if so, try to set its own identity into the word atomically, or else wait.
Flood et al detect termination through a status word, with one bit for each participating thread, which must be updated atomically. Initially, all threads’ statuses are active. When a thread has no work to do (and has not been able to steal any), it sets its status bit to be inactive and loops, checking whether all the status word’s bits are off. If so, all threads have offered to terminate and the collection phase is complete. Otherwise, the thread peeks at other threads’ queues, looking for work to steal. If it finds stealable work, it sets its status bit to active and tries to steal. If it fails to steal, it reverts the bit to inactive and loops again. This technique clearly does not scale to a number of threads beyond the number of bits in a word. Peter Kessler suggested using a count of active threads instead [Flood et al, 2001].
Grey packets. Ossia et al observe that mark stacks with work stealing is a technique best employed when the number of threads participating in a collection is known in advance [Ossia et al, 2002; Barabash et al, 2005]. This will not be the case if each mutator thread also helps by performing a small increment of work, say at each allocation. They also note that it may be difficult both for a thread to choose the best queue from which to steal, and to detect termination. Instead, they balance work loads by having each thread compete for packets of marking work to perform. Their system had a fixed number (1000) of packets available and each packet was a fixed size (512 entries).
Each thread uses two packets; it processes entries in its input packet and adds work to be done to its output packet. Under the tricolour abstraction, the entries in both packets are grey, hence, we adopt the name grey packets originally coined by Thomas et al [1998] for Insignia’s Jeode Java virtual machine.1 A thread competes to acquire a new packet of work from the global pool. After processing all the entries in the packet, it returns that packet to the pool. When its output packet is full, it returns it to the pool and obtains a fresh packet. Ossia et al maintain three linked lists of packets: a pool of empty packets, a pool of less than half full packets, and a pool of nearly full packets, as illustrated in Figure 14.3. Threads prefer to obtain their input packet from the highest occupancy, non-empty list (procedure getlnPacket in Algorithm 14.4), and their output packet from the lowest occupancy, non-empty list (procedure getOutPacket).
Grey packets offer a number of advantages. By separating input from output — Ossia et al avoid swapping the roles of a thread’s packets — work is distributed evenly between processors as a processor will tend not to consume its own output. Since a grey packet contains a queue of objects that will be processed in sequence, grey packets naturally support prefetching the next objects to be marked.
Grey packets require synchronisation only when packets are acquired from or returned to the global lists. These operations are non-blocking if we use a CompareAndSwap operation (with the thread’s identifier added to the head of the list to avoid an ABA problem). They also reduce the number of fences that have to be inserted on architectures with weakly-ordered memory consistency. Rather than having to fence after marking and pushing each object, a fence is required only when a thread acquires or returns packets. Ossia et al use a vector of allocation bits when they conservatively scan thread stacks in order to determine whether a putative reference really does point to an allocated object. Their allocation bits are also used for synchronisation between mutators and collectors. Their allocators use local allocation buffers. On local allocation buffer-overflow, the allocator performs a fence and then sets the allocation bits for all the objects in that local allocation buffer, thus ensuring that the stores to allocate and initialise new objects cannot precede the stores to set their allocation bits (Algorithm 14.5). Two further fences are needed. First, when a tracing thread acquires a new input packet, it tests the allocation bits of every object in the new packet, recording in a private data structure whether an object is safe to trace — its allocation bit has been set — or not. The thread then fences before continuing to trace all the safe objects in the input packet. Tracing unsafe objects is deferred; instead, they are added to a third, deferred, packet. At some point, this packet may be returned to a global pool of deferred packets. This protocol ensures that an object cannot be traced before its allocation bit has been loaded and found to be set. A tracing thread also fences when it returns its output packet to the global pool (in order to prevent the stores to the packet being reordered with respect to adding the packet back to the global pool). A fence is not needed for this purpose when getting an input packet since there is a data dependency between loading the pointer to the packet and accessing its contents, an ordering that most hardware hardware respects.
Grey packets make it comparatively easy to track state. Each global pool has an associated count of the number of packets it contains, updated by an atomic operation after a packet is acquired or returned. Counting the number of packets is only approximate since the count may be read after a packet has been returned but before the counter has been incremented. However, the termination condition is simply that the size of the empty packet pool is same as the total number of packets available. It is not necessary to make acquisition/return of a packet and the update of the counter a single, indivisible operation provided that threads observe the following discipline. In order to ensure that the empty count cannot drop to zero temporarily, each thread must obtain a new packet before it replaces the old one. Requiring a thread to obtain its input packet before its output packet at the start of a collection will ensure that attempts to acquire work packets when no tracing work remains will not prevent termination detection.
Algorithm 14.4: Grey packet management
1 shared fullPool | /* global pool of full packets */ |
2 shared halfFullPool | /* global pool of half full packets */ |
3 shared emptyPool | /* global pool of empty packets */ |
4
5 getInPacket():
6 atomic
7 inPacket ← remove(fullPool)
8 if isEmpty(inPacket)
9 atomic
10 inPacket ← remove(halfFullPool)
11 if isEmpty(inPacket)
12 inPacket, outPacket ← outPacket, inPacket
13 return not isEmpty(inPacket)
14
15 testAndMarkSafe(packet) :
16 for each ref in packet
17 safe(ref) ← allocBit(ref ) = true | /* private data structure */ |
18
19
20 getOutPacket():
21 if isFull(outPacket)
22 generateWork()
23 if outPacket = null
24 atomic
25 outPacket ← remove(emptyPool)
26 if outPacket = null
27 atomic
28 outPacket ← remove(halfFullPool)
29 if outPacket = null
30 if not isFull(inPacket)
31 inPacket, outPacket ← outPacket, inPacket
32 return
33
34 addOutPacket(ref):
35 getOutPacket()
36 if outPacket = null || isFull(outPacket)
37 dirtyCard(ref)
38 else
39 add(outPacket, ref)
Algorithm 14.5: Parallel allocation with grey packets
1 sequentialAllocate(n):
2 result ← free
3 newFree ← result + n
4 if newFree ≤ labLimit
5 free ← newFree
6 return result
7
8 /* LAB overflow */
9 fence | $ |
10 for each obj in lab
11 allocBit(obj) ← true
12 lab, labLimit ← newLab()
13 if lab = null
14 return null | /* signal |
15 sequentialAllocate(n)
Algorithm 14.6: Parallel tracing with grey packets
1 shared fullPool | /* global pool of full packets */ |
2
3 acquireWork() :
4 if isEmpty(inPacket)
5 if getInPacket()
6 testAndMarkSafe(inPacket)
7 fence | $ |
8
9 performWork() :
10 for each ref in inPacket
11 if safe(ref)
12 for each fld in Pointers(ref)
13 child ← *fld
14 if child = null && not isMarked(child)
15 setMarked(child)
16 addOutPacket(child)
17 else
18 addDeferredPacket(ref ) | /* defer tracing unsafe objects */ |
19
20 generateWork() :
21 fence | $ |
22 add(fullPool, outPacket)
23 outPacket ← null
Algorithm 14.7: Parallel tracing with channels
1 shared channel [N,N] | /* |
2 me ← myThreadId
3
4 acquireWork() :
5 for each k in Threads
6 if not isEmpty(channel[k,me]) | /* |
7 ref remove(channel[k,me])
8 push(myMarkStack, ref) | /* onto my mark stack */ |
9 return
10
11 performWork() :
12 loop
13 if isEmpty(myMarkStack)
14 return
15 ref ← pop(myMarkStack)
16 for each fld in Pointers(ref)
17 child ← *fld
18 if child = null && not isMarked(child)
19 if not generateWork(child) | /* drip a task to another processor */ |
20 push(myMarkStack, child)
21
22 generateWork(ref) :
23 for each j in Threads
24 if needsWork(j) && not isFull(channel[me,j])
25 add(channel[me,j], ref)
26 return true
27 return false
Grey packets limit the depth of the total mark queue, making it possible that marking may overflow. If a thread cannot obtain an output packet with vacant entries, it may swap the roles of its input and output packets. If both are full, some overflow mechanism is required. Ossia et al continue to mark objects without adding them to an output packet but when this happens they dirty the card table slots corresponding to these objects. Later, they scan the card table and continue marking from any marked objects with unmarked children. An alternative would be to link overflow objects to the class structures corresponding to their type, as Flood et al [2001] did.
Channels. Wu and Li [2007] suggest an architecture for load balancing on large-scale servers that does not require expensive atomic operations. Instead, threads exchange marking tasks through single writer, single reader channels (recall Algorithm 13.34), as shown in Algorithm 14.7. In a system with P marking threads, each thread has an array of P – 1 queues, implemented as circular buffers; null indicates that a slot in the buffer is empty. It is the restriction to one reader and one writer that allows this architecture to avoid the expense of atomic operations. It performed better than the Flood et al [2001] work stealing algorithm on servers with a large number of processors.
Similar to the strategy used by Endo et al [1997], threads proactively give up tasks to other threads. When a thread i generates a new task, it first checks whether any other thread j needs work and, if so, adds the task to the output channel ⟨i → j⟩]. Otherwise, it pushes the task onto its own marking stack. If its stack is empty, it takes a task from some input channel ⟨j → i⟩. Unfortunately, a thread that is not generating any new marking tasks will not be able to keep other threads busy. In this case, the thread drips a task from the bottom (oldest end) of its local stack into the channel. Wu and Li report that this load-balancing strategy can keep all threads busy. The choice of queue length will depend on how busily threads use their local mark stacks or whether they have to seek tasks. If tasks do not often have to seek work, then shorter queues will be preferred. On a machine with 16 Intel Xeon processors, queues of length one or two were found to scale best. They use a termination detection solution similar to that of Petrank and Kolodner [2004], but select a fixed detector thread in order to avoid the conflicting detector problem.
Parallelisation of copying algorithms faces many of the same issues faced by parallelisation of marking algorithms. However, as we noted earlier, it is essential that an object is copied only once whereas marking an object two or more times is often benign. We consider processor-centric and then memory-centric techniques.
Dividing work among processors. Blelloch and Cheng parallelise copying in the context of replicating collection [Blelloch and Cheng, 1999; Cheng and Blelloch, 2001; Cheng, 2001]. We discuss replicating collection in detail in Chapter 17 but, in brief, replicating collectors are incremental or concurrent collectors that copy live objects while the mutators are running, taking special care to fix up the values of any fields that a mutator might have changed during the course of a collection cycle. In this chapter, we discuss only the parallelism aspects of their design.
Each copying thread is given its own stack of work to do. Blelloch and Cheng claim that stacks offer easier synchronisation between copying threads and less fragmentation than Cheney queues (but we examine Cheney-style parallel copying collectors below). Load is balanced by having threads periodically transfer work between their local stacks and a shared stack (see Algorithm 14.8). As we noted earlier, a simple shared stack requires synchronisation between threads pushing and popping entries. Unfortunately, there is no way to increment or decrement a stack pointer and insert or remove a stack element atomically using primitive operations like FetchAndAdd. A lock or use of LoadLinked/StoreConditionally operations would sequentialise access to the shared stack, as shown in Section 13.8. However, we can use these instructions either to allow multiple threads to push elements or to allow multiple threads to pop elements, since these operations either all advance or all retreat the stack pointer. Once a thread has succeeded in moving the stack pointer (possibly by several slots), it can read from or write to those stack slots without risk of any races.
Blelloch and Cheng [1999] enforce such a discipline on access to the shared stack using what they later called ‘rooms’: at any time, at least one of the pushing room and the popping room must be empty. The algorithm is shown in Algorithm 14.9. At each iteration of the collection loop, a thread first enters the pop room and performs a fixed amount of work. It obtains slots to scan either from its own local stack or from the shared stack with a FetchAndAdd. Any new work generated is added to its stack. The thread then leaves the pop room and waits until all other threads have also left the room before it tries to enter the push room. The first thread to enter the push room closes the gate to prevent any other thread entering the pop room. Once in the push room, the thread empties its local stack entirely onto the shared stack, again using FetchAndAdd to reserve space on the stack. The last thread to leave the push room opens the gate.
Algorithm 14.8: Parallel copying in Cheng and Blelloch [2001]
1 shared sharedStack | /* the shared stack of work */ |
2 myCopyStack[k] | /* local stack has k slots max.*/ |
3 sp ← 0 | /* local stack pointer */ |
4
5 while not terminated()
6 enterRoom() | /* enter pop room */ |
7 for i ← 1 to k
8 if isLocalStackEmpty()
9 acquireWork()
10 if isLocalStackEmpty()
11 break
12 performWork()
13 transitionRooms()
14 generateWork()
15 if exitRoom() | /* leave push room */ |
16 terminate()
17
18 acquireWork() :
19 sharedPop() | /* move work from shared stack */ |
20
21 performWork() :
22 ref ← localPop()
23 scan(ref) | /* see Algorithm 4.2 */ |
24
25 generateWork() :
26 sharedPush() | /* move work to shared stack */ |
27
28 isLocalStackEmpty()
29 return sp = 0
30
31 localPush(ref):
32 myCopyStack[sp++] ← ref
33
34 localPop() :
35 return myCopyStack[--sp]
36
37 sharedPop(): | /* move work from shared stack */ |
38 cursor ← FetchAndAdd(&sharedStack, 1) | /* try to grab from shared stack */ |
39 if cursor ≥ stackLimit | /* shared stack empty */ |
40 FetchAndAdd(&sharedStack, −1) | /* readjust stack */ |
41 else
42 myCopyStack[sp++] ← cursor [0] | /* move work to local stack */ |
43
44 sharedPush(): | /* move work to shared stack */ |
45 cursor ← FetchAndAdd(&sharedStack, –sp) – sp
46 for i ← 0 to sp−1
47 cursor[i] ← myCopyStack[i]
48 sp ← 0
Algorithm 14.9: Push/pop synchronisation with rooms
1 shared gate ← OPEN
2 shared popClients | /* number of clients currently in the pop room */ |
3 shared pushClients | /* number of clients currently in the push room */ |
4
5 enterRoom():
6 while gate ≠ OPEN
7 /* do nothing: wait */
8 FetchAndAdd(&popClients, 1) | /* try to start popping */ |
9 while gate ≠ OPEN
10 FetchAndAdd(&popClients, −1) | /* back out since did not succeed */ |
11 while gate ≠ OPEN
12 /* do nothing: wait */
13 FetchAndAdd(&popClients, 1) | /* try again */ |
14
15
16 transitionRooms():
17 gate ← CLOSED
18 FetchAndAdd(&pushClients, 1) | /* move from popping to pushing */ |
19 FetchAndAdd(&popClients, −1)
20 while popClients > 0
21 /* do nothing: cannot start pushing until none other popping */
22
23 exitRoom():
24 pushers ← FetchAndAdd(&pushClients, −1) – 1 | /* stop pushing */ |
25 if pushers = 0 | /* I was last in push room: check termination */ |
26 if isEmpty(sharedStack) | /* no grey objects left */ |
27 gate ← OPEN
28 return true
29 else
30 gate ← OPEN
31 return false
The problem with this mechanism is that any processor waiting to enter the push room must wait until all processors in the pop room have finished greying their objects. The time to grey objects is considerable compared to fetching or depositing new work, and a processor trying to transition to the push phase must wait for all other processors already in the pop phase to finish greying their objects. Large variations in the time for different processors to grey their objects makes this idle time significant. A more relaxed abstraction would allow processors to leave the pop room without going into the push room. Since greying objects is not related to the shared stack, that work can be done outside the rooms. This greatly increases the likelihood that the pop room is empty and so a thread can move to the push room.
The original Blelloch and Cheng room abstraction allows straightforward termination detection. Each thread’s local tracing stack will be empty when it leaves the push room so the last thread to leave should detect whether the shared stack is also empty. However, the relaxed definition means that collection threads may be working outside the rooms. With this abstraction, the shared stack must maintain a global counter of how many threads have borrowed objects from it. The last thread to leave the push room must check whether this counter is zero as well as whether the shared stack is empty.
Copying objects in parallel. To ensure that only one thread copies an object, threads must race to copy an object and install a forwarding address in the old version’s header. How threads copy an object depends on whether or not they share a single allocation region. By sharing a single region, threads avoid some wastage but at the cost of having to use an atomic operation to allocate. In this case, Blelloch and Cheng [1999] have threads race to write a ‘busy’ value in the object’s forwarding pointer slot. The winning thread copies the object before overwriting the slot with the address of the replica; losing threads must spin until they observe a valid pointer value in the slot. An alternative, if each thread knows where it will copy an object (for example, because it will copy into its own local allocation buffer), is for threads to attempt to write the forwarding address atomically into the slot before they copy the object.
Marlow et al [2008] compared two approaches in the context of the GHC Haskell system. In the first approach, a thread trying to copy an object first tests whether it has been forwarded. If it has it simply returns the forwarding address. Otherwise, it attempts to CompareAndSwap a busy value into the forwarding address word; this value should be distinguishable from either a ‘normal’ value to be expected in that slot (such as a lock or a hash code) or a valid forwarding address. If the operation succeeds, the thread copies the object, writes the address of its tospace replica into the slot and then returns this address. If the busy CompareAndSwap fails, the thread spins until the winning thread has completed copying the object. In their second approach, they avoid spinning by having threads optimistically copy the object and then CompareAndSwap the forwarding address. If the CompareAndSwap fails, the copy must be retracted (for example, by returning the thread’s free pointer to its original value). They found that this latter approach offered little benefit since collisions were rare. However, they suggest that in this case, it may be worthwhile, in the case of immutable objects, to replace the atomic write with an unsynchronised write and accept occasional duplication.
The collector built by Flood et al [2001] that we discussed earlier in this chapter is generational. Its old generation was managed by mark-compact and its young generation by copying; both algorithms are parallel. Above, we discussed how they parallelised marking; here, we consider how they parallelise copying collection. The same work stealing queues are used once again to hold the list of objects to be scanned. However, parallel copying collection faces two challenges that parallel marking does not. First, it is desirable to minimise contention to allocate space for the copy and, second, it is essential that a live object is copied only once. Contention for space is minimised through the use of thread-local allocation buffers (see Section 7.7), both for copying to survivor spaces in the young generation and for promoting to the old generation. To copy an object, a thread makes a speculative allocation in its local allocation buffer and then attempts to CompareAndSwap the forwarding pointer. If it succeeds, the thread copies the object. If the CompareAndSwap fails, it will return the forwarding pointer that the winning thread installed.

Figure 14.4: Dominant-thread tracing. Threads 0 to 2, coloured grey, white and black respectively, have traced a graph of objects. Each object is coloured to indicate the processor to which it will be copied. The first field of each object is its header. Thread T0 was the last to lock object X.
As we have seen throughout this book, locality has a significant impact on performance. This is likely to become increasingly important for multiprocessors with nonuniform memory architectures. Here, the ideal is to place objects close to the processor that will use them most. Modern operating systems support standard memory affinity policies, used to determine the processor from which memory will be reserved. Typically, a policy may be first-touch or local, in which case memory is allocated from the processor running the thread that requested it, or round-robin, where memory allocation is striped across all processors. A processor-affinity thread scheduler will help preserve locality properties by attempting to schedule a thread to the last processor on which it ran. Ogasawara [2009] observes that, even with a local-processor policy, a memory manager that is unaware of a non-uniform memory architecture may not place objects appropriately. If local allocation buffers are smaller than a page and are handed out to threads linearly, then some threads will have to allocate in remote memory, particularly if the system is configured to use the operating system’s large page (16 megabytes) feature to reduce the cost of local to physical address translation. Further, collectors that move objects will not respect their affinity.
In contrast, Ogasawara’s memory manager is aware of non-uniform memory access and so splits the heap into segments of one or more pages. Each segment is mapped to a single processor. The allocator, used by both mutator and collector threads, preferentially obtains blocks of memory from the preferred processor. For the mutator, this will be the processor on which the thread is running. The collector threads always try to evacuate live objects to memory associated with their preferred processor. Since the thread that allocated an object may not be the one that accesses it most frequently, the collector also uses dominant-thread information to determine each object’s preferred processor. First, for objects directly referred to from the stack of a mutator thread, this will be the processor on which that mutator thread was running; it may be necessary for mutator threads to update the identity of their preferred processor periodically. Second, the collector can use object locking information to identify the dominant thread. Locking schemes often leave the locking thread’s identity in a word in the object’s header. Although this only identifies the thread, and hence the preferred processor, that last locked the object, this is likely to be a sufficient approximation, especially as many objects never escape their allocating thread (although they may still be locked). Finally, the collector can propagate the preferred processor from parent objects to their children. In the example in Figure 14.4, three threads are marking. For simplicity, we assume they are all running on their preferred processor, identified in the figure by different colours. Thread T0 has at some time locked object X, indicated by writing its thread number in X’s header. Each object has been coloured to indicate the processor to which a collector thread will copy it.

Figure 14.5: Chunk management in the Imai and Tick [1993] parallel copying collector, showing selection of a scan block before (above) and after (below) overflow. Hatching denotes blocks that have been added to the global pool.
Per-thread fromspace and tospace. Copying collection lends itself naturally to a division of labour based on objects’ locations. A simple solution to parallelising copying collection is to give each Cheney-style collector its own fromspace and tospace [Halstead, 1984]. In this way, each thread has its own contiguous chunk of memory to scan, but still competes with other threads to copy objects and install forwarding pointers. However, this very simple design not only risks poor load balancing as one processor may run out of work while others are still busy, but also requires some mechanism to handle the case that one thread’s tospace overflows although there is unused space in other tospaces.
Block structured heaps. An obvious solution is to over-partition tospace and then allow threads to compete to claim both blocks to scan and blocks for copying allocation. Imai and Tick [1993] divided the heap into small, fixed-size chunks, giving each copying thread its own chunks to scan and into which to copy survivors. Copying used Cheney pointers rather than explicit work lists. When a thread’s copy chunk was full, it was transferred to a global pool where idle threads competed to scan it, and a fresh, empty chunk was obtained from a free-chunk manager. Two mechanisms were used to ensure good load balancing. First, the chunks acquired for copying (which they called ‘heap extension units’) were comparatively small (only 256 words). The problem with using small chunks for linear allocation is that it may lead to excessive fragmentation since, on average, we can expect to waste half an object’s worth of space at the end of each chunk. To solve this, Imai and Tick used big bag of pages allocation (see Chapter 7) for small objects; consequently each thread owned N chunks for copying. Larger objects and chunks were both allocated from the shared heap using a lock.
Second, they balanced load at a granularity finer than a chunk. Each chunk was divided into smaller blocks (which they called ‘load distribution units’). These were maybe as small as 32 words — smaller blocks led to better speed ups. In this algorithm, each thread offered to give up some of its unscanned blocks whenever it needed a new scan block. After scanning a slot and incrementing its scan pointer, the thread checked whether it had reached the block boundary. If so, and the next object was smaller than a block, the thread advanced its scan pointer to the start of its current copy block. This helps reduce contention on the global pool since the thread does not have to compete to acquire a scan block. It also avoids a situation whereby the only blocks containing grey objects to scan are copy blocks. If there were any unscanned blocks between the old scan block and the copy block, these were given up to the global pool for other threads to claim. Figure 14.5 shows two example scenarios. In Figure 14.5a, a thread’s scan and copy blocks are in the same chunk; in Figure 14.5b, they are in different chunks. Either way, all but one of the unscanned blocks in the thread’s copy and scan blocks are given up to the global pool.

Figure 14.6: Block states and transitions in the Imai and Tick [1993] collector. Blocks in states with thick borders are part of the global pool, those with thin borders are owned by a thread.
copy |
scan |
||
aliased |
|
|
|
|
(continue scanning) |
(continue scanning) |
scan → done |
|
aliased → copy |
(continue scanning) |
scan → done |
|
aliased → scan |
(cannot happen) |
(cannot happen) |
|
aliased → scan |
copy → scanlist |
scan → done |
|
aliased → scan |
(cannot happen) |
(cannot happen) |
|
aliased → copy |
(cannot happen) |
(cannot happen) |
Table 14.1: State transition logic for the Imai and Tick collector
If the object was larger than a block but smaller than a chunk, the scan pointer was advanced to the start of the thread’s current copy chunk. If the object was large, the thread continued to scan it. Any large objects copied were immediately added to the global pool.
Figure 14.6 shows the states of blocks and their transitions.2 Blocks in the states freelist, scanlist and done are in the global pool; blocks in the other states are local to a thread. The transitions are labelled with the possible colourings of a block when it changes state. Under the Imai and Tick scheme, a block’s state can change only when the scan pointer reaches the end of a scan block, the copy pointer reaches the end of a copy block, or scan reaches free (the scan block is the same as the copy block — they are aliased). For example, a block must contain at least some empty space in order to be a copy block so all transitions into the state copy are at least partially empty. Table 14.1 shows the actions taken, depending on the state of the copy and scan blocks. For example, if the copy block contains both grey slots and empty space (![]() ) and the unaliased scan block is completely black (
) and the unaliased scan block is completely black (![]() ), then we are finished with the scan block and continue scanning in the copy block — the copy and scan blocks are now aliases of one another.
), then we are finished with the scan block and continue scanning in the copy block — the copy and scan blocks are now aliases of one another.
Marlow et al [2008] found this block-at-a-time load-balancing over-sequentialised the collector when work was scarce in GHC Haskell. For example, if a thread evacuates its roots into a single block, it will export work to other threads only when its scan and free pointers are separated by more than a block. Their solution is to export partially full blocks to the global pool whenever (i) the size of the pool is below some threshold, (ii) the thread’s copy block has a sufficient work to be worth exporting, and (iii) its scan block has enough unscanned slots to process before it has to claim a new block to scan. The optimum minimum quantum of work to export was 128 words (for most of their benchmarks, though some benefited from much smaller quanta). This design could be expected to suffer badly from fragmentation if threads were to acquire only empty blocks for copying while exporting partially filled ones. To avoid this, they have threads prefer to acquire blocks that are partly filled rather than empty. Despite the potential for exacerbating fragmentation through objects being too large to fit in the current block and also by dividing each generation of their collector into separate steps (see Chapter 9), Marlow et al found the level of fragmentation was never more than 1% of total memory.
The algorithms above provide breadth-first copying. Breadth-first copying leads to poor mutator locality as it tends to separate parents from their children, tending to colocate distant cousins instead (see Section 4.2). Depth-first copying, on the other hand, offers better locality but at the cost of an auxiliary stack to control tracing. Moon [1984] and Wilson et al [1991] introduced hierarchical copying algorithms that led to mostly depth-first traversal but without the cost of a stack. However, their algorithms were sequential. Siegwart and Hirzel [2006] add hierarchical decomposition to the Imai and Tick parallel copying collector to manage the young generation of IBM’s J9 Java virtual machine.3
In the sequential hierarchical decomposition collector [Wilson et al, 1991] incompletely scanned blocks were associated with two pointers, a partial scan pointer and a free space pointer. Similarly, Imai and Tick used pairs of scan and free pointers for their blocks. The trick to obtaining a hierarchical traversal of the object graph with the parallel algorithm is therefore for threads to select the ‘right’ blocks to use next. Like both of these collectors, Siegwart and Hirzel prefer to alias copy and scan blocks,4 in contrast to the approach that Ossia et al [2002] used where they strove to have threads hold distinct input and output packets. Unlike Imai and Tick, who defer checking whether the copy and scan blocks can be aliased until the end of a block, Siegwart and Hirzel make the check immediately after scanning a grey slot. It is this immediacy that leads to the hierarchical decomposition order of traversal of the object graph.
Figure 14.7 shows the states of blocks and their transitions under this scheme. As before, blocks in the states freelist, scanlist and done are in the global pool; blocks in the other states are local to a thread. The transitions are labelled with the possible colourings of a block when it changes state. Table 14.2 shows the actions taken, depending on the state of the copy and scan blocks. For example, if the copy block contains both grey slots and empty space (![]() or
or ![]() ) and the unaliased scan block also has grey slots, then we return the scan block to the scan list and continue scanning the copy block — the copy and scan blocks are now aliases of one another. Thus, the state transition system for Siegwart and Hirzel is a superset of that for Imai and Tick [1993].
) and the unaliased scan block also has grey slots, then we return the scan block to the scan list and continue scanning the copy block — the copy and scan blocks are now aliases of one another. Thus, the state transition system for Siegwart and Hirzel is a superset of that for Imai and Tick [1993].

Figure 14.7: Block states and transitions in the Siegwart and Hirzel collector. Blocks in states with thick borders are part of the global pool, those with thin borders are local to a thread. A thread may retain one block of the scanlist in its local cache.
Siegwart and Hirzel [2006], doi: 10.1145/1133956.1133964. © 2006 Association for Computing Machinery, Inc. Reprinted by permission.
copy |
scan |
||
aliased |
|
|
|
|
(continue scanning) |
scan → scanlist |
scan → done |
|
aliased → copy |
(continue scanning) |
scan → done |
|
aliased → scan |
copy → scanlist |
scan → done |
|
aliased → done |
(cannot happen) |
(cannot happen) |
Table 14.2: State transition logic for the Siegwart and Hirzel collector.
Siegwart and Hirzel [2006], doi: 10.1145/1133956.1133964. © 2006 Association for Computing Machinery, Inc. Reprinted by permission.
Parallelising the algorithm places pressure on the global pool to acquire blocks to scan. For this reason, Siegwart and Hirzel have threads cache an extra scan block locally. Their blocks are also larger (128 kilobytes) than those of Imai and Tick. Thus, the transition scanlist → scan really obtains the cached block (if any), and scan → scanlist caches the block, possibly returning in its stead the previously cached block to the shared pool of blocks to be scanned. Parallel hierarchical copying is very effective in improving the spatial locality of connected objects. Most parents and children were within a page (four kilobytes) of each other. In particular, it offers a promise of reduced translation lookaside buffer and cache miss rates. Thus, it can trade mutator speedup for collector slowdown. Whether or not this is effective depends on application, implementation and platform.
Channels. Like Wu and Li [2007], Oancea et al [2009] use channels to eliminate the need for atomic synchronisation operations. However, their architecture is memory-centric rather than processor-centric. It was designed to improve performance on non-uniform memory architectures although it also performs well on typical multicore platforms. The heap is divided into many more partitions than the number of processors. Each partition has its own work list, containing only references to tospace objects in that partition that need to be scanned. At any given time, at most one processor can own a given work list. The authors argue that binding work lists to memory-space semantics is likely to become increasingly hardware-friendly as the cost of inter-processor communication grows.
As usual, a processor traces slots in its work lists. If it finds a reference to an object in its partition, it adds the reference to its work list. If the reference is to an object in another partition, the reference is sent to that partition. Processors exchange work through single-reader, single-writer channels. These are again implemented as fixed-size, circular buffers (see Algorithm 13.34). On Intel or AMD x86 architectures, no locks or expensive memory barriers are required to insert or remove a slot from a channel. However, architectures like the PowerPC that do not enforce strong access ordering require fences or a protocol where each slot alternates between null and non-null values. Atomic operations are required only to acquire a partition/work list. The partitions used here are larger at 32 kilobytes than those we have seen before. While a larger granularity reduces communication costs, it is less effective at load balancing than finer grained approaches.
While there is work left, each thread processes work in its incoming channels and its work list. The termination condition for a collector thread is that (i) it does not own any work list, (ii) all its input and output channels are empty, and (iii) all work lists (of all threads) are empty. On exit, each thread sets a globally visible flag. Oancea et al take a pragmatic approach to the management of this collector. They use an initialisation phase that processes in parallel a number (30,000) of objects under a classical tracing algorithm and then places the resulting grey objects in their corresponding work lists, locking the partitions to do so, before distributing the work lists among the processors, and switching to the channel-based algorithm.
Card tables. Often a generational collector will use parallel copying to manage its young generation. This raises the additional question of how to deal with roots of that generation held in the remembered set. The set may be implemented with a linked list of buffers, with a hash table or with a card table. The first two cases can be handled by one of the techniques we discussed above. For example, if the set is a linked list of buffers then loads can be balanced by having threads compete to claim the next buffer in the same way as block structured algorithms. It is more difficult to balance load effectively with card tables. When a younger generation is collected, the parts of the heap corresponding to cards marked in the table must be scanned for possible inter-generational references. The obvious approach to parallelising card scanning would be to divide the heap into consecutive, equally sized blocks, either statically assigned to processors or which collector threads would compete to claim. However, the distribution of live objects among blocks tends to be uneven, with some blocks very densely populated and others very sparsely. Flood et al [2001] found that this straightforward division of work led to uneven load balancing, as scanning the dense blocks dominated collection time. To address this, they over-partitioned the card table into N strides, each a set of cards separated by intervals of N cards. Thus, cards {0, N, 2N,…} comprise one stride, cards {1, N + 1, 2N + 1,…} comprise the next, and so on. This causes dense areas to be spread across strides. Instead of competing for blocks, threads compete to claim strides.
We conclude this chapter by considering how to parallelise sweeping and compaction phases. Both share the property that the tracing work has been done, the live objects in the heap have been identified, and that this last phase is ‘embarrassingly’ parallel.
In principle, parallelising the sweep phase is straightforward: either statically partition the heap into contiguous blocks or over-partition it and have threads compete for a block to sweep to a free-list. However, the effect of such a simple strategy is likely to be that the free-list becomes a bottleneck, sequentialising the collection. Fortunately, in any such parallel system, processors will have their own free-lists and most likely use segregated-fits allocation (see Chapter 7), so the issue of contention reduces to that of handling the return of completely free blocks to a global block allocator. Furthermore, lazy sweeping (see Chapter 2) is a naturally parallel solution to the problem of sweeping partially full blocks that balances loads according to the allocation rates of mutator threads.
The first and only step in the sweep phase of lazy sweeping is to identify completely empty blocks and return them to the block allocator. In order to reduce contention, Endo et al [1997] gave each sweep thread several (for example, 64) consecutive blocks to process locally. His collector used bitmap marking, with the bitmaps held in block headers, stored separately from the blocks themselves. This makes it easy to determine whether a block is complete empty or not. Empty ones are sorted and coalesced, and added to a local freeblock list. Partially full blocks are add to local reclaim lists (for example, one for each size class if segregated-fits allocation is being used) for subsequent lazy sweeping by mutator threads. Once a processor has finished with its sweep set, it merges its free-block list into the global free-block list. One remaining question is, what should a mutator thread do if it has run out of blocks on its local reclaim list and the global pool of blocks is empty? One solution is that it should steal a block from another thread. This requires synchronising the acquisition of the next block to sweep, but this is a reasonable cost to pay since acquiring a new block to sweep is less frequent than allocating a slot in a block, and we can expect contention for a block to sweep to be uncommon.
Parallelising mark-compact algorithms shares much of the issues discussed above. Live objects must be marked in parallel and then moved in parallel. However, parallel sliding compaction is simpler than parallel copying in some respects, at least in contiguous heaps. For example, once all the live objects have been marked, the destination of objects to be moved is fixed: races affect only performance rather than correctness. After marking is complete, all compacting collectors require two or more further phases to determine the forwarding address of each object, to update references and to move objects. As we saw in Chapter 3, different algorithms may perform these tasks in different orders or even combine two tasks in a single pass over the heap.
Crammond [1988] implemented a locality-aware parallel collector for Parlog, a concurrent logic programming language. Logic programming languages benefit from preserving the order of objects in the heap. In particular, backtracking to ‘choice points’ is made more efficient by preserving the allocation order of objects in memory, since all memory allocated after the choice point can simply be discarded. Sliding compaction preserves the order. Crammond’s collector parallelised the Morris [1978] threaded collector, which we discussed in Section 3.3; in this section, we consider only the parallelism aspects of the algorithm. Crammond reduced the cost by dividing the heap into regions associated with processors. A processor encountering an object in its own region marked and counted it without synchronisation. However, if the object was a ‘remote’ one, a reference to it was added to that processor’s stack of indirect references and a global counter was incremented. The remote processor was responsible for processing the object and decrementing the global counter (which was used to detect termination). Thus, synchronisation (using locks) was only required for remote objects since the indirect stacks were single reader, multiple writer structures. Crammond found that indirect references typically comprised less than 1% of the objects marked.
Flood et al [2001] use parallel mark-compact to manage the old generation of their Java virtual machine. The collector uses three further phases after parallel marking (which we discussed above) to (i) calculate forwarding addresses, (ii) update references, and (iii) move objects. An interesting aspect of their design is that they use different load balancing strategies for different phases of compaction. Uniprocessor compaction algorithms typically slide all live data to one end of the heap space. If multiple threads move data in parallel, then it is essential to prevent one thread from overwriting live data before another thread has moved it. For this reason, Flood et al do not compact all objects into a single, dense end of the heap but instead divide the space into several regions, one for each compacting thread. Each thread slides objects in its region only. To reduce the (limited) fragmentation that this partitioning might incur, they also have threads alternate the direction in which they move objects in even and odd numbered regions (see Figure 14.8).

Figure 14.8: Flood et al [2001] divide the heap into one region per thread and alternate the direction in which compacting threads slide live objects (shown in grey).
The first step is to install a forwarding pointer into the header of each live object. This will hold the address to which the object is to be moved. In this phase, they over-partition the space in order to improve load balancing. The space is split into M object-aligned units, each of roughly the same size; they found that a good choice on their eight-way UltraSPARC server was to use four times as many units as garbage collection threads, M = 4N. Threads compete to claim units and then count the volume of live data in each unit; to improve subsequent passes, they also coalesce adjacent garbage objects into single quasi-objects. Once they know the volume of live objects in each unit, they can partition the space into N unevenly sized regions that contain approximately the same amount of live data. These regions are aligned with the units of the previous pass. They also calculate the destination address of the first live object in each unit, being careful to take into account the direction in which objects in a region will slide. Collection threads then compete once again to claim units in order to install forwarding pointers in each live object of their units.
The next pass updates references to point to objects’ new locations. As usual, this requires scanning mutator threads’ stacks, references to objects in this heap space that are held in objects stored outside that space, as well as live objects in this space (for example, the old generation). Any suitable load balancing scheme can be used. Flood et al reuse the unit partitions for scanning the space to be compacted (their old generation) although they scan the young generation as a single task. Their last phase moves the objects. Here they give each thread a region of objects to move. This balances effort between threads since these regions were chosen to contain roughly equal volumes of live data.

Figure 14.9: Inter-block compaction. Rather than sliding object by object, Abuaiadh et al [2004] slide only complete blocks: free space within each block is not squeezed out.
There are two disadvantages to the way this algorithm compacts objects. First, it makes 3 passes over the heap. As we saw in Chapter 3, other algorithms make fewer passes. Second, rather than compacting all live objects to one end of the heap, Flood et al compact into N dense piles, leaving ⌈(N + 1)/2⌉ gaps for allocation. Each pile is compacted densely, in the sense that space need only be wasted in a pile due to object alignment requirements. However, it is possible that if a very large number of threads/regions were to be used, it may be difficult for mutators to allocate very large objects.
Abuaiadh et al [2004] address the first problem by calculating rather than storing forwarding addresses, using the mark bitmap and an offset vector that holds the new address of the first live object in each small block of the heap, as we described in Section 3.4. Their solution to the second problem is to over-partition the heap into a number of fairly large areas. For example, they suggest that a typical choice may be to have 16 times as many areas as processors, while ensuring that each area is at least four megabytes. The heap areas are compacted in order. Threads race to claim an area, using an atomic operation to increment a global area index (or pointer). If the operation is successful, the thread has obtained this area to compact. If it was not successful, then another thread must have claimed it and the first thread tries again for the next area; thus, acquisition of areas is wait-free. A table holds pointers to the beginning of the free space for each area. After winning an area to compact, the thread competes to acquire an area into which it can move objects. A thread claims an area by trying to write null atomically into its corresponding table slot. Threads never try to compact from a source area nor into a target area whose table entry is null, and objects are never moved from a lower to a higher numbered area. Progress is guaranteed since a thread can always compact an area into itself. Once a thread has finished with an area, it updates the area’s free space pointer in the table. If an area is full, its free space pointer will remain null.
Abuaiadh et al explored two ways in which objects could be moved. The best compaction, with the least fragmentation, is obtained by moving individual live objects to their destination, as we described above. Note that because every object in a block is moved to a location partly determined by the offset vector for that block, a block’s objects are never split between two destination areas. They also tried trading quality of compaction for reduced compaction time by moving whole blocks at a time (256 bytes in their implementation), illustrated in Figure 14.9. Because objects in a linearly allocated space tend to live and die in clumps, they found that this technique could reduce compaction time by a fifth at the cost of increasing the size of the compaction area by only a few percent. On the other hand, it is not hard to invent a worst case that would lead to no compaction at all.
The calculate-rather-than-store the forwarding address mechanism was later adopted by Compressor [Kermany and Petrank, 2006]. However, Compressor introduced some changes. First, as the second phase of the collector passes over the mark bitmap, it calculates a first-object vector as well as the offset vector.5 The first-object table is a vector indexed by the pages that will hold the relocated objects. Each slot in the table holds the address in fromspace of the first object that will be moved into that page. Compaction itself starts by updating the roots (using the information held in the mark and offset vectors).
The second difference is that each thread then competes to claim a tospace page from the first-object table. A successful thread maps a new physical page for its virtual page, and copies objects starting from the location specified in this slot of the first-object table, using the offset and mark vectors. Acquisition of a fresh page to which to evacuate objects allows Compressor to use parallel collector threads whereas the description we gave in Chapter 3 sequentialised sliding of objects. At first sight, this may look as if it is a copying algorithm rather than a mark-compact one. However, Compressor truly is a sliding mark-compact collector. It manages fromspace and tospace pages at a cost in physical memory of typically only one page per collector thread, in stark contrast to a traditional semispace collector which requires twice as much heap space. The trick is that, although Compressor needs to map fresh tospace pages, it can also unmap each fromspace page as soon as it has evacuated all the live objects from it.
This design minimises overheads for synchronisation between compacting threads. A thread needs to synchronise only to claim a slot in the first-object table corresponding to a tospace page into which it can evacuate objects. This process is wait-free since a thread never needs to retry a page: if it fails to claim it, then another thread is evacuating to it so this thread can try the next slot in the table. Termination is equally simple: a thread exits when it reaches the end of the table. One subtlety is how to handle objects that span pages. In a stop-the-world implementation, one can arbitrarily decide that such an object is associated with the first tospace page on which it will be placed. However, this solution will not work for a concurrent implementation (which we discuss in Section 17.7), so we copy precisely the data that belongs to a single tospace page, including the end of the object that starts on the previous page and the beginning of one that ends on the next page.
Earlier work was often inconsistent in the terminology it used to describe parallel garbage collection. Papers in the twentieth century often used ‘parallel’, ‘concurrent’ and even ‘real-time’ interchangeably. Fortunately, since around 2000, authors have adopted a consistent usage. Thus, a parallel collector is now one that uses multiple garbage collector threads, running in parallel. The world may or may not be stopped while parallel collection threads run. It seems clear that it is sensible to allow parallel collection if the underlying platform has the capability to support this, in the same way that it is desirable to allow mutator threads to use all available parallel resources.
Is parallel collection worthwhile?
The first question to ask is, recalling Amdahl’s law,6 is there sufficient work available to parallelise? It is easy to imagine scenarios that offer no opportunity for parallel execution: a common example might be tracing a list. Fortunately, there is evidence that real applications use a richer set of data structures and that these do indeed offer a high degree of potential parallelism [Siebert, 2008]. Garbage collection activities other than tracing offer much more obvious opportunities to exploit parallel hardware. For example, sweeping and compaction are eminently parallelisable (even if a little care needs to be taken with the latter). Even in the tracing phase, thread stacks and remembered sets can be scanned in parallel and with little synchronisation overhead; completing the trace in parallel requires more careful handling of work lists in order to limit the synchronisation costs while at the same time using parallel hardware resources as efficiently as possible.
Strategies for balancing loads
It should be clear that parallelising collection effectively requires carefully trading off the need to balance loads between processors and limiting the amount of synchronisation necessary to do so safely. We want to balance loads to ensure that no processors are inactive while others do all the work. It is also important to balance other resources, such as memory. Synchronisation is essential to protect the integrity of the collector’s work lists and the application’s heap allocated structures. For example, allowing two threads to manipulate a mark stack pointer simultaneously risks losing entries. Furthermore, allowing two threads to copy an object simultaneously risks changing the topology of the heap. However, the finest grain balancing is likely to involve very high synchronisation costs.
The general solution is to assign to each collector thread a quantum of work that it can perform without further synchronisation with other threads. This begs the question of how the work can be divided between threads. The cheapest division, in the sense of the least synchronisation overhead, is to partition the work statically, at either build time, on program startup or before each collection cycle. In this case, the coordination between threads will be limited to consensus on termination. However, static partitioning may not lead to good load balancing. On the other hand, loads can be balanced by over-partitioning the work available and having threads compete to acquire tasks and having them return new tasks to a global pool. This offers the finest grain load balancing but at the cost of the most synchronisation. In between these two extremes, it is often possible to apply different load balancing strategies in different phases of the execution of a collection cycle. For example, information gathered by one phase (typically, the mark phase) can be used to estimate a fair division between threads of the work to done by subsequent phases. The Flood et al [2001] collector is a good example of this approach.
Tracing the heap involves consuming work (objects to mark or copy) and generating further work (their untraced children). Some structure, such as a stack or a queue, is needed to keep track of work to do. A single, shared structure would lead to high synchronisation costs so collection threads should be given their own private data structures. However, in order to balance load, some mechanism is required that can transfer work between threads. The first decision is what mechanism to use. We have discussed several in this chapter. Work stealing data structures can be used to allow work to be transferred safely from one thread’s to another. The idea is to make the common operation (pushing and popping entries while tracing) as cheap (that is, unsynchronised) as possible while still allowing infrequent operations (transferring work safely between threads). Endo et al [1997] give each thread its own stack and a stealable work queue, whereas Flood et al [2001] have each thread use just one double-ended queue both for tracing and stealing. Grey packets provide a global pool of buffers of work to do (hence their name) [Thomas et al, 1998; Ossia et al, 2002]. Here, each thread competes for a packet of work to do and returns new work to the pool in a fresh packet. Cheng and Blelloch [2001] resolve the problem of synchronising stack pushes and pops by splitting tracing into steps, which they call ‘rooms’. At its simplest, all threads are in the push room or all are in the pop room. In each case, every thread wants to move the stack pointer in the same direction so an atomic operation like FetchAndAdd can be used. Other authors eliminate the need for atomic operations by having tracing threads communicate through single-writer, single-reader channels [Wu and Li, 2007; Oancea et al, 2009].
The second decision is how much work to transfer and when to transfer it. Different researchers have proposed different solutions. The smallest unit of transfer is a single entry from the stack. However, if data structures are small, this may lead to a higher volume of traffic between threads. In the context of a parallel, concurrent and real-time collector, Siebert [2010] has a processor with no work steal all of another’s work list. This is only a sensible decision if it is unlikely that processors will run out of work to do at around the same time (in this case, because they are executing mutator code concurrently). A common solution is to transfer an intermediate amount of work between threads. Fixed size grey packets do this naturally; other choices include transferring half of a thread’s mark stack. If mark stacks are a fixed size, then some mechanism must be employed to handle overflow. Again, grey packets handle this naturally: when an output packet is filled, it is returned to the global pool and an empty one is acquired from the pool. Flood et al [2001] thread overflow sets through Java class objects, at the cost of a small, fixed space overhead per class. Large arrays are problematic for load balancing. One solution, commonly adopted in real-time systems, is to divide large, logically contiguous objects into linked data structures. Another is to record in the mark stack a sequence of sections of the array to scan for pointers to trace, rather than requiring all of the array to be scanned in a single step.
The techniques above are processor-centric: the algorithms concern the management of thread (processor) local work lists. The alternative is to use memory-centric strategies that take into account the location of objects. This may be increasingly important in the context of non-uniform memory architectures where access to a remote memory location is more expensive than access to a local one. Memory-centric approaches are common in parallel copying collectors, particularly where work lists are Cheney queues [Imai and Tick, 1993; Siegwart and Hirzel, 2006]. Here the issues are (i) the size of the blocks (the quanta of work), (ii) which block to process next and which to return to the global pool of work, and (iii) which thread ‘owns’ an object. There are two aspects to choosing sizes of blocks. First, any moving collector should be given its own, private region of the heap into which it can bump allocate. These chunks should probably be large in order to reduce contention on the chunk manager. However, large chunks do not offer an appropriate granularity for balancing the load of copying threads. Instead, chunks should be broken into smaller blocks which can act as the work quanta in a Cheney-style collector. Second, the choice of which object to process next affects the locality of both the collector and the mutator (as we saw in Section 4.2). In both cases, it seems preferable to select the next unscanned object in the block that is being used for allocation, returning intermediate, unscanned or incompletely scanned blocks to the global pool. Making this decision at the end of scanning a block may improve the collector’s locality; making this decision after scanning each object may improve the mutator’s locality as well because it causes the live object graph to be traversed in a more depth-first-like (hierarchical) order. Finally, the decision might be made on which processor is most likely to use an object next. Oancea et al [2009] uses the notion of a ‘dominant thread’ to guide the choice of which processor should copy an object (and hence the location to which it should be copied).
As well as synchronising operations on collector data structures, it may also be necessary to synchronise operations on individual objects. In principle, marking is an idempotent operation: it does not matter if an object is marked more than once. However, if a collector uses a vector of mark bits, it is essential that the marker sets these bits atomically. Since modern processors’ instruction sets do not provide the ability to set an individual bit in a word or byte, setting a mark may necessitate looping trying to set the value of the whole byte atomically. On the other hand, if the mark bit is held in the object’s header, or the mark vector is a vector of bytes (one per object), then no synchronisation is necessary since double writing the mark is safe.
A copying collector must not ‘mark’ (that is, copy) an object more than once, as this would change the topology of the graph, with possibly disastrous consequences for mutable objects. It is essential that copying an object and setting the forwarding address is seen by other collector threads to be a single, indivisible operation. The details come down to how the forwarding address is handled. A number of solutions have been adopted. A collector may attempt to write a ‘busy’ value into the forwarding address slot atomically, then copy the object and write the forwarding address with a simple store operation. If another thread sees a ‘busy’ value, it must spin until it sees the forwarding address. The synchronisation cost can be reduced by testing the forwarding address slot before attempting the atomic ‘busy’ write. Another tactic might be to copy the object if there is no forwarding address and then attempt to store the forwarding address atomically, retracting the copy if the store is unsuccessful. The effectiveness of such a tactic will depend on the frequency of collisions when installing forwarding addresses.
It is important that certain actions be made visible in the proper order to other processors on platforms with weakly consistent memory models. This requires the compiler to emit memory fences in the appropriate places. Atomic operations such as CompareAndSwap often act as fences but in many cases weaker instructions suffice. One factor in the choice of algorithm will be the complexity of deciding where to place fences, the number that need to be executed and the cost of doing so. It may well be worth trading simplicity of programming (and hence confidence that the code is correct) for some reduction in performance.
Sweeping and compaction phases essentially sweep linearly through the heap (in more than one pass in the case of compaction). Thus, these operations are well suited to parallelisation. The simplest load balancing strategy might be to divide the heap into as many partitions as there are processors. However, this can lead to uneven load balancing if the amount of work is uneven between partitions. To first approximation, the amount of work to be done is proportional to the number of objects in a partition. This information is available from the mark phase, and can be used to divide the heap into unequally sized (but object aligned) partitions, each of which contains roughly the same amount of work.
However, this strategy assumes that each partition can be processed independently of the others. This will not be true if processing one partition may destroy information on which another partition depends. For example, a sliding compaction collector cannot move objects in an arbitrary order to their destination as this would risk overwriting live but not yet moved data. In this case, it maybe necessary to process partitions in address order. Here, the solution is to over-partition the heap and have threads compete for the next partitions to use (one for the objects to be moved and one into which to move them).
Finally, termination of any collection phase must be determined correctly. The use of parallel threads clearly makes termination detection more complex. The problem is fundamentally that one thread may be attempting to detect whether the phase has terminated while another is generating more work. Unfortunately, flawed termination detection algorithms are quite easy to write! One (correct) solution to the problem is to nominate a single thread to detect termination and have threads indicate atomically whether they are busy or not; care is needed with the protocol for raising and lowering flags and processing work, and in placement of fences in the presence of relaxed memory orders. Systems with a global pool of work can offer simpler protocols that allow any number of threads to detect termination. For example, grey packet systems may allow the number of packets in the global pool to be counted: if they are all present (and empty), then the phase is complete.
1However, the first publication of this idea, other than through a patent application, was by Ossia et al [2002].
2This particularly clear notation is due to Siegwart and Hirzel [2006].
3The old generation is managed by concurrent mark-sweep with occasional stop-the-world compaction.
4Each thread in their generational collector holds two copy blocks, one for young and one for old objects; only one at a time can be aliased with the scan block.
5At 512 bytes, their blocks are also larger than those of Abuaiadh et al [2004].
6Amdahl’s law states that the speedup obtained from parallelising a program depends on the proportion of the program that can be parallelised. Thus, if s is the amount of time spent (by a serial processor) on serial parts of a program, and p is the amount of time spent (by a serial processor) on parts that can be done in parallel by n processors, then the speedup is 1/(s + p/n).