
7
Normalizing Data
Chapter 6, “Extracting Business Rules,” explained how you can make a database more flexible and robust by extracting certain business rules from the database's structure. By removing some of the more complex and changeable rules from the database's check constraints, you make it easier to change those rules later.
Another way to make a database more flexible and robust is to “normalize” it. Normalization makes the database more able to accommodate changes in the structure of the data. It also protects the database against certain kinds of errors.
This chapter explains what normalization is and tells how you can use it to improve your database design.
In this chapter, you will learn:
- What normalization is
- What problems different types or levels of normalization address
- How to normalize a database
- How to know what level of normalization is best for your database
After you normalize your relational model, you'll finally be ready to build the database.
WHAT IS NORMALIZATION?
Depending on how you design a relational database, it may be susceptible to all sorts of problems. For example:
- It may contain lots of duplicated data. This not only wastes space, but it also makes updating all of those duplicated values a time-consuming chore.
- It may incorrectly associate two unrelated pieces of data so you cannot delete one without deleting the other.
- It may require you to create a piece of data that shouldn't exist in order to represent another piece of data that should exist.
- It may limit the number of values that you can enter for what should be a multivalued piece of data.
In database terminology, these issues are called anomalies. (Anomaly is a euphemism for “problem.” I'm not sure why this needs a euphemism—I doubt the database's feelings would be hurt by the word “problem.”)
Normalization is a process of rearranging the database to put it into a standard (normal) form that prevents these kinds of anomalies.
There are seven different levels of normalization. Each level includes those before it. For example, a database is in Third Normal Form if it is in Second Normal Form plus it satisfies some extra properties. That means if a database is at one level of normalization, then by definition it gets the advantages of the “lower” levels.
The different levels of normalization in order from weakest to strongest are:
- First normal form (1NF)
- Second normal form (2NF)
- Third normal form (3NF)
- Boyce-Codd normal form (BCNF)
- Fourth normal form (4NF)
- Fifth normal form (5NF)
- Domain/key normal form (DKNF)
A database in DKNF has amazing powers of protection against anomalies, can leap tall buildings, and has all sorts of other super-database powers.
The following sections explain the properties that a database must satisfy to officially earn one of these coveted uber-database titles. They also explain the data anomalies that each level of normalization prevents.
FIRST NORMAL FORM (1NF)
First normal form (1NF) basically says that the data is in a relational database. It's sort of the price to play the game if you want be a relational database.
Most of the properties needed to be in 1NF are enforced automatically by any reasonable relational database engine. There are a couple of extra properties added on to make the database more useful, but mostly these rules are pretty basic. The official qualifications for 1NF are:
- Each column must have a unique name.
- The order of the rows and columns doesn't matter.
- Each column must have a single data type.
- No two rows can contain identical values.
- Each column must contain a single value.
- Columns cannot contain repeating groups.
The first two rules basically come for free when you use a relational database product such as Postgres, MySQL, or SQL Server. All these require that you give columns different names. They also don't really care about the order of rows and columns, although when you select data you will probably want to specify the order in which it is returned for consistency's sake. For example, you might want to sort a list of returned Student records by name.
Rule 3 means that two rows cannot store different types of data in the same column. For example, the Value field in a table cannot hold a string in one row, a date in another, and a currency value in a third. This is almost a freebie because database products won't let you say, “This field should hold numbers or dates.”
One way to run afoul of Rule 3 is to store values with different types converted into a common form. For example, you could store a date written as a string (such as “3/14/2027”) and a number written as a string (such as “17”) in a column designed to hold strings. Although this is an impressive display of your cleverness, it violates the spirit of the rule. It makes it much harder to perform queries using the field in any meaningful way. If you really need to store different kinds of data, split them apart into different columns that each holds a single kind of data. (In practice, many databases end up with just this sort of mishmash field. In particular, users often enter important data in comment or notes fields and a program must later search for values in those fields. Not the best practice but it does happen.)
Rule 4 makes sense because, if two rows did contain identical values, how would you tell them apart? The only reason you might be tempted to violate this rule is if you don't need to tell the rows apart. For example, suppose you fill out an order form for a pencil, some paper, and a tarantula. Oh, yeah, you also need another pencil so you add it at the end.
Now the form's list of items contains two identical rows listing a pencil. You don't care that the rows are identical because the pencils are identical. In fact, all you really know is that you want two pencils. That observation leads to the solution. Instead of using two identical rows, use one row with a new Quantity field and set Quantity to 2.
Note that Rule 4 is equivalent to saying that the table can have a primary key. Recall from Chapter 2, “Relational Overview,” that a primary key is a set of columns that you can use to uniquely identify rows. If no two rows can have exactly the same values, then you must be able to pick a set of columns to uniquely identify the rows, even if it includes every column.
In fact, let's make that a new rule:
- 4a. Every table has a primary key.
Rule 5 is the one you might be most tempted to violate. Sometimes, a data entity includes a concept that needs multiple values. The semantic object models described in Chapter 5, “Translating User Needs into Data Models,” even let you explicitly set an attribute's cardinality so that you can make one attribute that holds multiple values.
For example, suppose you are building a recipe table and you give it the fields Name, Ingredients, Instructions, and Notes (which contains things such as “Sherri loves this recipe” and “For extra flavor, increase ants to 3 tbsp”). This gives you enough information to print out a recipe, and you can easily follow it (assuming you have some talent for cooking and a garden full of ants).
However, the Ingredients, Instructions, and Notes fields contain multiple values. Two hints that this might be the case are the fact that the column names are plural and that the column values are probably broken up into subvalues by commas, periods, carriage returns, or some other delimiter.
Storing multiple values in a single field limits the usefulness of that field. For example, suppose you decide that you want to find all of your recipes that use ants as an ingredient. Because the Ingredients field contains a bunch of different values all glommed together, you cannot easily search for a particular ingredient. You might be able to search for the word “ants” within the string, but you're likely to get extraneous matches such as “currants.” You also won't be able to use indexes to make these searches in the middle of a string faster.
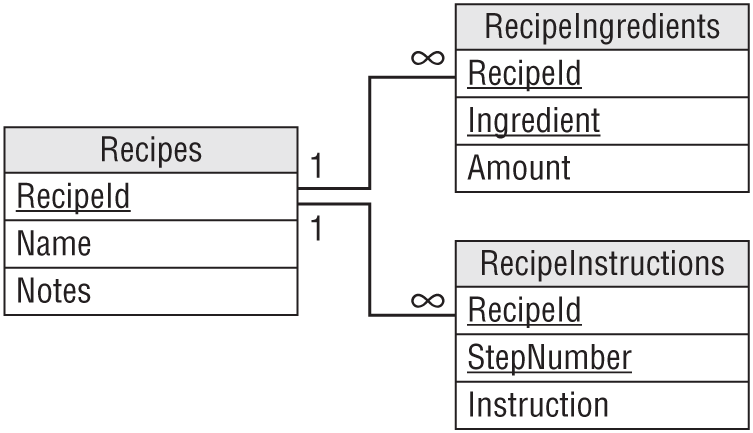
The solution is to break the multiple values apart, move them into a new table, and link those records back to this one with this record's primary key. For the recipe example, you would create a RecipeIngredients table with fields RecipeId, Ingredient, and Amount. Now, you can search for RecipeIngredients records where Ingredient is “ants.”
Similarly, you could make a RecipeInstructions table with fields RecipeId, StepNumber, and Instruction. The StepNumber field is necessary because you want to perform the steps in the correct order. (I've tried rearranging the steps and it just doesn't work! Baking bread before you mix the ingredients gives you a strange little brick-like puddle.) Now, you can search for Recipes records and matching RecipeInstructions records that contain the word “preheat” to see how hot the oven must be.
Note, you only need to separate a field's values if they are logically distinct for whatever purposes you will use them. For example, you might want to search for individual ingredients. It's a bit less clear that you'll need to search for particular instructions. It's even less sure that you'll want to search for specific values within a Notes field. Notes is more or less a free-format field, and it's not clear that any internal structure is useful there.
For an even more obvious example, consider an Authors table's Biography field. This field contains an author's brief biography. You could break it into sentences (or words, or even letters), but the individual sentences don't have any real context so there's little point. You will display the Biography as a whole anyway, which means there's not much benefit in chopping it up arbitrarily.
Rule 6 means you cannot have multiple columns that contain values that are not distinguishable. For example, suppose you decide that each Exterminators record should be able to hold the animals that an exterminator is qualified to remove (muskrat, ostrich, platypus, and so forth). (Don't worry, this is a humane pest control service, so the exterminators catch the critters and release them far away so they can bother someone else.)
You already know from Rule 5 that you can't just cram all of the animals into a single Critters field. Rule 6 says you also cannot create columns named Critter1, Critter2, and Critter3 to hold different animals. Instead, you need to split the values out into a new table and use the Exterminators table's primary key to link back to the main records.
Figure 7.1 shows a relational model for the recipe data. The ingredients and instructions have been moved into new tables but the Notes field remains as it was originally.
SECOND NORMAL FORM (2NF)
A table is in second normal form (2NF) if:
- It is in 1NF.
- All of the non-key fields depend on all of the key fields.
To see what this means, consider the alligator wrestling schedule shown in the following table. It lists the name, class (amateur or professional), and ranking for each wrestler, together with the time when this wrestler will perform. The Time/Wrestler combination forms the table's primary key.
| TIME | WRESTLER | CLASS | RANK |
|---|---|---|---|
| 1:30 | Annette Cart | Pro | 3 |
| 1:30 | Ben Jones | Pro | 2 |
| 2:00 | Sydney Dart | Amateur | 1 |
| 2:15 | Ben Jones | Pro | 2 |
| 2:30 | Annette Cart | Pro | 3 |
| 3:30 | Sydney Dart | Amateur | 1 |
| 3:30 | Mike Acosta | Amateur | 6 |
| 3:45 | Annette Cart | Pro | 3 |
Although this table is in 1NF (don't take my word for it—verify it yourself), it is trying to do too much work all by itself, and that leads to several problems.
First, this table is vulnerable to update anomalies. An update anomaly occurs when a change to a row leads to inconsistent data. In this case, update anomalies are caused by the fact that this table holds a lot of repeated data. For example, suppose Sydney Dart decides to turn pro, so you update the Class entry in the third row. Now that row is inconsistent with the Class entry in row 6 that still shows Sydney as an amateur. You'll need to update every row in the table that mentions Sydney to fix this problem.
Second, this table is susceptible to deletion anomalies. A deletion anomaly occurs when deleting a record can destroy information that you might need later. In this example, suppose you cancel the 3:30 match featuring Mike Acosta (because he strained a muscle while flexing in front of the mirror this morning). In that case, you lose the entire 7th record in the table, so you lose the fact that Mike is an amateur, that he's ranked 6th, and that he even exists. (Presumably, he disappears in a puff of smoke.)
Third, this table is subject to insertion anomalies. An insertion anomaly occurs when you cannot store certain kinds of information because it would violate the table's primary key constraints. Suppose you want to add a new wrestler, Nate Waffle, to the roster but you have not yet scheduled any matches for him. (Nate's actually the contest organizer's nephew so he doesn't really wrestle alligators; he just wants to be listed in the program to impress his friends.) To add Nate to this table, you would have to assign him a wrestling match, and Nate would probably have a heart attack. Similarly, you cannot create a new time for a match without assigning a wrestler to it.
Okay, I confess I pulled a fast one here. You could create a record for Nate that had Time set to null. That would be really bad form, however, because all of the fields that make up a primary key should have non-null values. Many databases require that all primary key fields not allow nulls. Because Time/Wrestler is the table's primary key, you cannot give Nate a record without assigning a Time and you're stuck.
The underlying problem is that some of the table's columns do not depend on all of the primary key fields. The Class and Rank fields depend on Wrestler but not on Time. Annette Cart is a professional whether she wrestles at 1:30, 2:30, or 3:45.
The solution is to pull the columns that do not depend on the entire primary key out of the table and put them in a new table. In this case, you could create a new Wrestlers table and move the Class and Rank fields into it. You would then add a WrestlerName field to link back to the original table.
Figure 7.4 shows a relational model for the new tables.
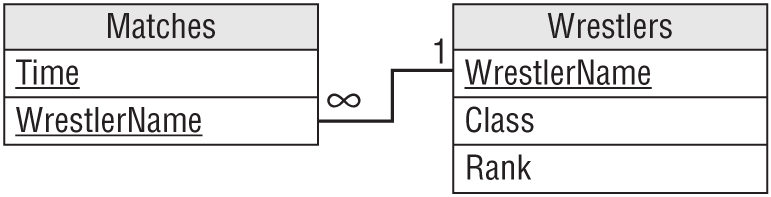
Figure 7.5 shows the new tables holding the original data. Here I've sorted the matches by wrestler name to make it easier to see the relationship between the two tables. (It's a mess if you sort the matches by time.)
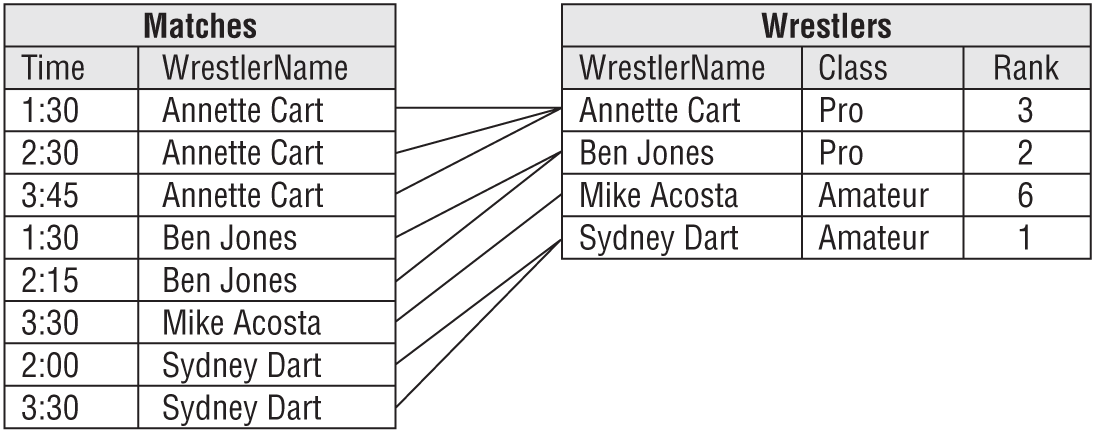
The new arrangement is immune to the three anomalies described earlier. To make Sydney Dart a professional, you only need to change her Wrestlers record. You can cancel the 3:30 match between Mike Acosta and Hungry Bob without losing Mike's information in the Wrestlers table. Finally, you can make a row for Nate in the Wrestlers table without making one in the Matches table.
You should also verify that all of the new tables satisfy the 2NF rule, “All of the non-key fields depend on all of the key fields.” The Matches table contains no fields that are not part of the primary key, so it satisfies this requirement trivially.
The primary key for the Wrestlers table is the WrestlerName field, and the Class and Rank fields depend directly on the value of WrestlerName. If you move to a different WrestlerName, you get different values for Class and Rank. Note that the second wrestler might have the same Class and Rank, but that would be mere coincidence. The new values belong to the new wrestler.
Intuitively, the original table had problems because it was trying to hold two kinds of information: information about matches and information about wrestlers. To fix the problem, we broke the table into two tables to hold those two kinds of information separately.
If you ensure that every table represents one single, unified concept such as wrestler or match, then the tables will be in 2NF. It's when a table tries to play multiple roles, such as storing wrestler and match information at the same time, that it is open to data anomalies.
THIRD NORMAL FORM (3NF)
A table is in third normal form (3NF) if:
- It is in 2NF.
- It contains no transitive dependencies.
A transitive dependency is when one non-key field's value depends on another non-key field's value. This probably sounds a bit confusing, but an example should help.
Suppose you and your friends decide to start a book club. To see what kinds of books people like, you put together the following table listing everyone's favorite books. It uses Person as the primary key. (Again, the Author field might violate 1NF if you consider it as containing multiple values: first and last name. For simplicity, and because you won't ever need to search for books by only first name or last name, we'll treat this as a single value.)
| PERSON | TITLE | AUTHOR | PAGES | YEAR |
|---|---|---|---|---|
| Amy | Support Your Local Wizard | Duane, Diane | 473 | 1990 |
| Becky | Three to Dorsai! | Dickson, Gordon | 532 | 1975 |
| Jon | Chronicles of the Black Company | Cook, Glen | 704 | 2007 |
| Ken | Three to Dorsai! | Dickson, Gordon | 532 | 1975 |
| Wendy | Support Your Local Wizard | Duane, Diane | 473 | 1990 |
You can easily show that this table is 1NF. It uses a single field as primary key, so every field in the table depends on the entire primary key, so it's also 2NF. (Each row represents that Person's favorite book, so every field must depend on that Person.)
However, this table contains a lot of duplication, so it is subject to modification anomalies. (At this point, you probably knew that!) If you discover that the Year for Support Your Local Wizard is wrong and fix it in row 1, it will conflict with the last row.
It's also subject to deletion anomalies (if Jon insults everyone and gets kicked out of the group so you remove the third row, you lose all of the information about Chronicles of the Black Company) and insertion anomalies (you cannot save Title, Author, Pages, and Year information about a book unless it's someone's favorite, and you cannot allow someone to join the group until they decide on a favorite).
The problem here is that some of the fields are related to others. In this example, Author, Pages, and Year are related to Title. If you know a book's Title, then you could look up its Author, Pages, and Year.
In this example, the primary key, Person, doesn't exactly drive the Author, Pages, and Year fields. Instead, it selects the Person's favorite Title and then Title determines the other values. This is a transitive dependency. Title depends on Person and the other fields depend on Title.
The main clue that there is a transitive dependency is that there are lots of duplicate values in the table.
You can fix this problem in a way similar to the way you put a table into 2NF: find the fields that are causing the problem and pull them into a separate table. Add an extra field to contain the original field on which those were dependent so that you can link back to the original table.
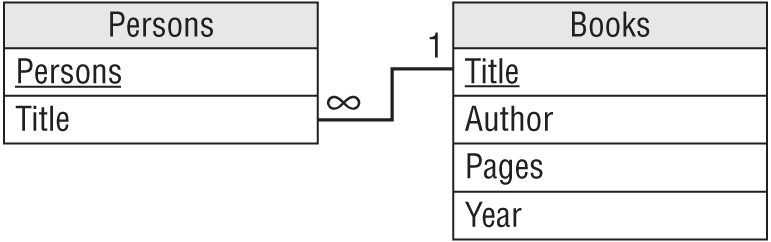
In this case, you could make a Books table to hold the Author, Pages, and Year fields. You would then add a Title field to link the new records back to the original table.
Figure 7.8 shows a relational model for the new design.
Figure 7.9 shows the new tables containing the original data.

STOPPING AT THIRD NORMAL FORM
Many database designers stop normalizing the database at 3NF because it provides the most bang for the buck. It's fairly easy to convert a database to 3NF and that level of normalization prevents the most common data anomalies. It stores separate data separately so that you can add and remove pieces of information without destroying unrelated data. It also removes redundant data so the database isn't full of a zillion copies of the same information that waste space and make updating values difficult.
However, the database may still be vulnerable to some less common anomalies that are prevented by the more complete normalizations described in the following sections. These greater levels of normalization are rather technical and confusing. They can also lead to unnecessarily complicated data models that are hard to implement, maintain, and use. In some cases, they can give worse performance than less completely normalized designs.
Although you might not always need to use these super-normalized databases, it's still good to understand them and the problems that they prevent. Then you can decide whether those problems are potentially big enough to justify including them in your design. (Besides, they make great ice breakers at parties. “Hey everyone! Let's see who can put the guest list in 4NF the fastest!”)
BOYCE-CODD NORMAL FORM (BCNF)
Even stating this one is kind of technical, so to understand it you need to know some terms.
Recall from Chapter 2, “Relational Overview,” that a superkey is a set of fields that contain unique values. You can use a superkey to uniquely identify the records in a table.
Also recall that a candidate key is a minimal superkey. In other words, if you remove any of the fields from the candidate key, then it won't be a superkey anymore.
Now for a new term. A determinant is a field that at least partly determines the value in another field. Note that the definition of 3NF worries about fields that are dependent on another field that is not part of the primary key. Now, we're talking about fields that might be dependent on fields that are part of the primary key (or any candidate key).
A table is in Boyce-Codd normal form (BCNF) if:
- It is in 3NF.
- Every determinant is a candidate key.
For example, suppose you are attending the Wizards, Knights, and Farriers Convention hosted by three nearby castles: Castle Blue, Castle Green, and Le Château du Chevalier Rouge. Each attendee must select a track: Wizard, Knight, or Farrier. Each castle hosts three seminars, one for each track.
During the conference, you might attend seminars at any of the three castles, but you can only attend the one for your track. That means if you pick a castle, I can deduce which session you will attend there.
Here's part of the attendee schedule. The letters in parentheses show the attendee and seminar tracks to make the table easier to read and they are not really part of this data.
| ATTENDEE | CASTLE | SEMINAR |
|---|---|---|
| Agress Profundus (w) | Green | Poisons for Fun and Profit (w) |
| Anabel (k) | Blue | Terrific Tilting (k) |
| Anabel (k) | Rouge | Clubs ‘N Things (k) |
| Frock Smith (f) | Blue | Dealing with Difficult Destriers (f) |
| Lady Mismyth (w) | Green | Poisons for Fun and Profit (w) |
| Sten Bors (f) | Blue | Dealing with Difficult Destriers (f) |
| The Mighty Brak (k) | Green | Siege Engine Maintenance (k) |
| The Mighty Brak (k) | Rouge | Clubs ‘N Things (k) |
This table is susceptible to update anomalies because it contains duplicated data. If you moved the Poisons for Fun and Profit seminar to Castle Blue in the first record, then it would contradict the Castle value in row 5.
It's also vulnerable to deletion anomalies because the relationship between Castle and Seminar is stored implicitly in this table. If you deleted the second record, then you would lose the fact that the Terrific Tilting seminar is taking place in Castle Blue.
Finally, this table suffers from insertion anomalies. For example, you cannot create a record for a new seminar without assigning an attendee to it.
In short, this table has a problem because it has multiple overlapping candidate keys.
This table has two candidate keys: Attendee/Castle and Attendee/Seminar. Either of those combinations will uniquely identify a record.
The remaining combination, Castle/Seminar, cannot identify the Attendee, so it's not a candidate key.
As you have probably noticed, the Castle and Seminar fields have a dependency: Seminar determines Castle (but not vice versa). In other words, Seminar is a determinant of Castle.
This table is not in BCNF because Seminar is a determinant but is not a candidate key.
You can put this table in BCNF by pulling out the dependent data and linking it to the determinant. In this case, that means moving the Castle data into a new table and linking it back to its determinant, Seminar.
Figure 7.12 shows the new design.

Figure 7.13 shows the new tables containing the original data.
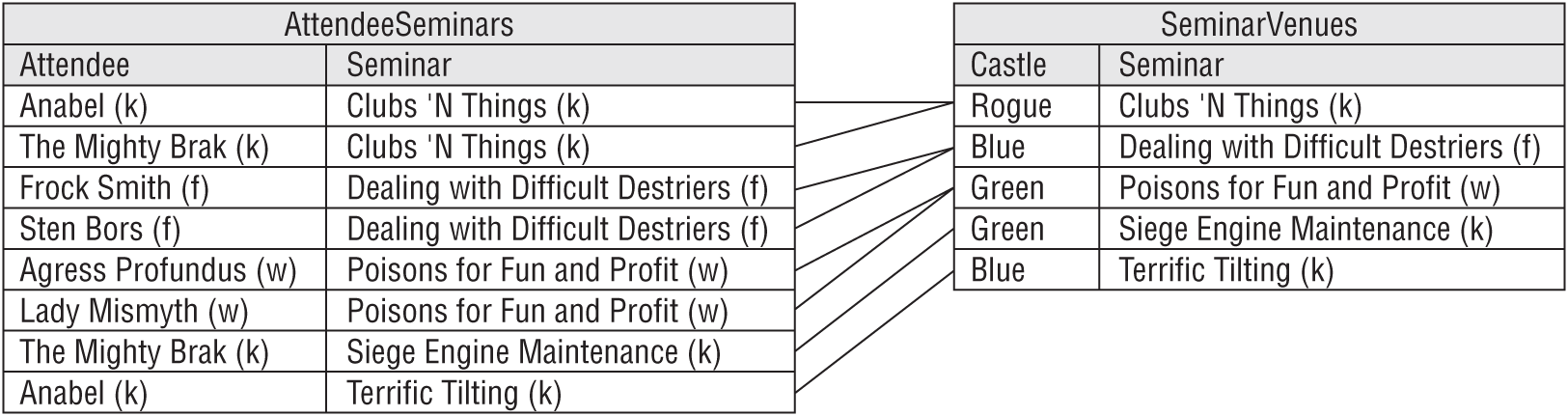
Now you can move the Poisons for Fun and Profit seminar to Castle Blue by changing a single record in the SeminarVenues table. You can delete Anabel's record for Terrific Tilting without losing the fact that Terrific Tilting takes place in Castle Blue because that information is in the SeminarVenues table. Finally, you can add a new record to the SeminarVenues table without assigning any attendees to it.
For another example, suppose you have an Employees table with columns EmployeeId, FirstName, LastName, SocialSecurityNumber, and Phone. Assume you don't need to worry about weird special cases such as roommates sharing a phone number or multiple employees with the same name.
This table has several determinants. For example, EmployeeId determines every other field's value. If you know an employee's ID, then all the other values are fixed. This doesn't violate BCNF because EmployeeId is also a candidate key.
Similarly, SocialSecurityNumber and Phone are each determinants of all of the other fields. Fortunately they, too, are candidate keys.
So far so good. Now for a stranger case. The combination FirstName/LastName is a determinant for all of the other fields. If you know an employee's first and last names, then the corresponding EmployeeId, SocialSecurityNumber, and Phone values are set. Fortunately, FirstName/LastName is also a candidate key, so even that doesn't break the table's BCNF-ness.
This table is in BCNF because every determinant is also a candidate key. Intuitively, the table is in BCNF because it represents a single entity: an employee.
The previous example was not in BCNF because it represented two concepts at the same time: attendees and the seminars they're attending, and the locations of the seminars. We solved that problem by splitting the table into two tables that each represented only one of those concepts.
Generally, if every table represents a single concept or entity, it will be in pretty good shape. It's when you ask a table to do too much that you run into problems.
FOURTH NORMAL FORM (4NF)
Suppose you run a home fixit service. Each employee has a set of skills, and each drives a particular truck that contains useful special equipment. They are all qualified to use any of the equipment. The following table shows a really bad attempt to store this information.
| EMPLOYEE | SKILLS | TOOLS |
|---|---|---|
| Gina Harris | Electric, Plumbing | Chop saw, Impact hammer |
| Pease Marks | Electric, Tile | Chain saw |
| Rick Shaw | Plumbing | Milling machine, Lathe |
You should instantly notice that this table isn't even in 1NF because the Skills and Tools columns contain multiple values.
The following table shows an improved version. Here each row holds only one skill and tool.
| EMPLOYEE | SKILL | TOOL |
|---|---|---|
| Gina Harris | Electric | Chop saw |
| Gina Harris | Electric | Impact hammer |
| Gina Harris | Plumbing | Chop saw |
| Gina Harris | Plumbing | Impact hammer |
| Pease Marks | Electric | Chain saw |
| Pease Marks | Tile | Chain saw |
| Rick Shaw | Plumbing | Milling machine |
| Rick Shaw | Plumbing | Lathe |
Unfortunately, to capture all of the data about each employee, this table must include a lot of duplication. To record the fact that Gina Harris has the electric and plumbing skills and that her truck contains a chop saw and an impact hammer, you need four rows showing the four possible combinations of values.
In general, if an employee has S skills and T tools, then the table would need S × T rows to hold all the combinations.
This leads to the usual assortment of problems. If you modify the first row's Skill to Tile, it contradicts the second row, causing a modification anomaly. If Gina loses her impact hammer, then you must delete two rows to prevent inconsistencies. If Gina takes classes in Painting, then you need to add two new rows to cover all of the new combinations. If she later decides to add a spray gun to her toolbox, then you need to add three more rows.
Something strange is definitely going on here. And yet this table is in BCNF!
You can easily verify that it's in 1NF.
Next, note that every field must be part of the table's primary key. If you omit one field from the key, then there might be two records with the same values for all of the remaining fields and that's not allowed if those fields form the primary key.
The table is in 2NF because all of the non-key fields (there are none) depend on all the key fields (all of them). It's in 3NF because there are no transitive dependencies (every field is in the primary key so no field is dependent on a non-key field). It's in BCNF because every determinant is a candidate key. (The only determinant is Employee/Skill/Tool, which is also the only candidate key.)
In this table, the problem arises because Employee implies Skill and Employee implies Tool but Skill and Tool are independent. This situation is called an unrelated multivalued dependency.
A table is in fourth normal form (4NF) if:
- It is in BCNF.
- It does not contain an unrelated multivalued dependency.
A particular Employee leads to multiple Skills and for any given Skill there can be many Employees, so there is a many-to-many relationship between Employee and Skill. Similarly, there is a many-to-many relationship between Employee and Tool. (Note, there is no relationship between Skill and Tool.)
Figure 7.15 shows an ER diagram for the entities involved: Employee, Skill, and Tool.
The solution to the problem is to find the field that drives the unrelated multivalued dependency. In this case, Employee is the central field. It's in the middle of the ER diagram shown in Figure 7.15, and it forms one part of each of the many-to-many relationships.

To fix the table, pull one of the other fields out into a new table. Add the central field (Employee) to link the new records back to the original ones.
Figure 7.16 shows the new model.

Figure 7.17 shows the original data in the new tables.
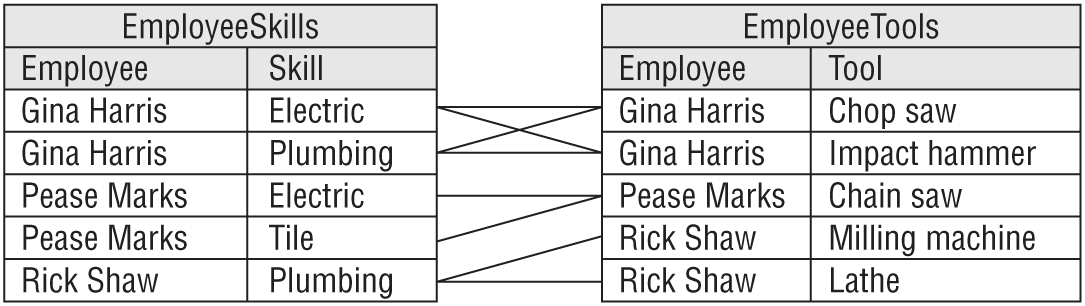
I want to mention two other ideas before leaving 4NF. First, you might not plan to normalize a database to this level and only worry about it when you run into problems. In this case, the problem is the multiplicative effect of multiple many-to-many relationships. The many combinations of Skill/Tool or Genre/Show fill the database with permutations of the same data, and that's your hint that there is a problem.
The second idea is that there may be a better way to solve this problem. If you have two many-to-many relationships, you can separate them by pulling one of them out into a new table. Often, it's better to pull them both out and make a central table to represent the common element in the relationships. For example, the solution to the Show-Artist-Genre example used Artist as a key to link the ArtistGenres and ArtistShows together.
That works, but what if you want to add more information about the artists such as their phone numbers, addresses, and online locations of their NFT marketplaces? Which table should hold that information? You could put it in either table, but then that table won't be in 2NF anymore. (Check for yourself and maybe review the alligator wrestling example.) It's the “one table trying to do too much” problem again.
A better solution would be to create a new Artists table to hold the new information and then link that table to both the ArtistGenres and ArtistShows tables. The moral of the story is, unless the concept in the middle of the multiple many-to-many relationships is a very simple linking concept with no other information, you should consider moving it into a new table.
FIFTH NORMAL FORM (5NF)
A table is in fifth normal form (5NF, also called project-join normal form) if:
- It is in 4NF.
- It contains no related multivalued dependencies.
For example, suppose you run an auto repair shop. The grease monkeys who work there may be certified to work on particular makes of vehicles (Honda, Toyota, DeLorean) and on particular types of engines (gas, diesel, hybrid, matter-antimatter).
If a grease monkey is certified for a particular make and for a particular engine, than that person must provide service for that make and engine (if that combination exists). For example, suppose Joe Quark is certified to repair Hondas and Diesel. Then he must be able to repair Diesel engines made by Honda.
Now, consider the following table showing which grease monkey can repair which combinations of make and engine.
| GREASEMONKEY | MAKE | ENGINE |
|---|---|---|
| Cindy Oyle | Honda | Gas |
| Cindy Oyle | DeLorean | Gas |
| Eric Wander | Honda | Gas |
| Eric Wander | Honda | Hybrid |
| Eric Wander | DeLorean | Gas |
| Joe Quark | Honda | Diesel |
| Joe Quark | Honda | Gas |
| Joe Quark | Honda | Hybrid |
| Joe Quark | Toyota | Diesel |
| Joe Quark | Toyota | Gas |
| Joe Quark | Toyota | Hybrid |
In this case, GreaseMonkey determines Make. For a given GreaseMonkey, there are certain Makes that this person can repair.
Similarly, GreaseMonkey determines Engine. For a given GreaseMonkey, there are certain Engines that this person can repair.
Up to this point, the table is very similar to the Employee/Skill/Tool table described in the previous section about 4NF. Here comes the difference.
In the Employee/Skill/Tool table, Skill and Tool were unrelated. In this new table, however, Make and Engine are related. For example, Eric Wander is certified in the Makes Honda and DeLorean. He is also certified in the Engines Gas and Hybrid. The rules state that he must repair Gas and Hybrid engines for Honda and DeLorean vehicles, if they provide those Engines. But DeLorean doesn't make a hybrid, so Eric doesn't need to service that combination.
There's the dependency between Make and Engine. While the GreaseMonkey determines the Make and Engine, Make also influences Engine.
So, how can you remove this dependency? Break the single table into three new tables that record the three different relationships: GreaseMonkey/Make, GreaseMonkey/Engine, and Make/Engine.
Figure 7.21 shows the new relational model.
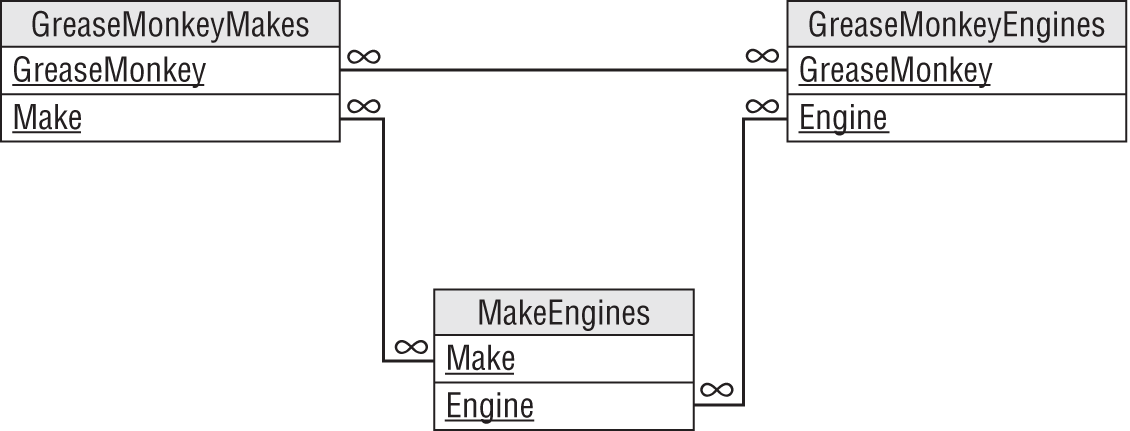
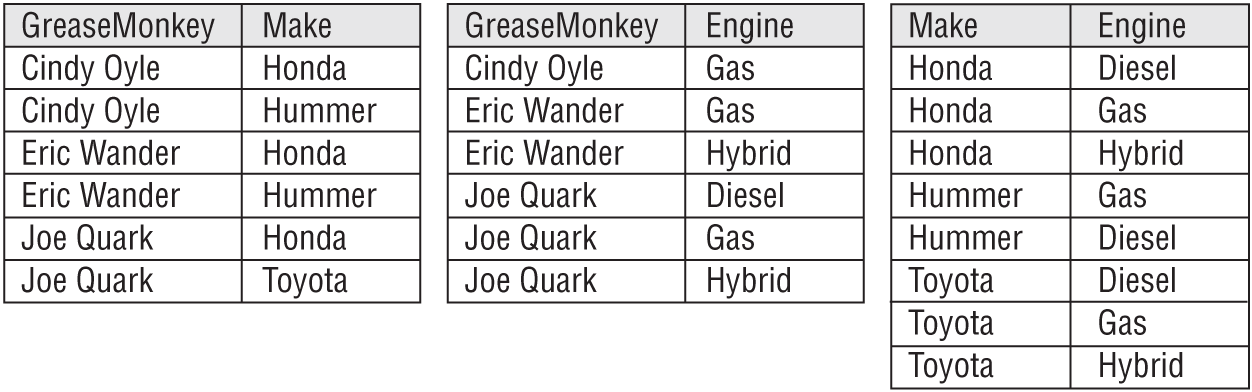
Figure 7.22 shows the new tables holding the original data. I haven't drawn lines connecting related records because it would make a big mess.
DOMAIN/KEY NORMAL FORM (DKNF)
A table is in domain/key normal form (DKNF) if:
- The table contains no constraints except domain constraints and key constraints.
In other words, a table is in DKNF if every constraint is a consequence of domain and key constraints.
Recall from Chapter 2, “Relational Overview,” that a field's domain consists of its allowed values. A domain constraint simply means that a field has a value that is in its domain. It's easy to check that a domain constraint is satisfied by simply examining all of the field's values.
A key constraint means the values in the fields that make up a key are unique.
So if a table is in DKNF, then to validate all constraints on the data it is sufficient to validate the domain constraints and key constraints.
For example, consider a typical Employees table with fields FirstName, LastName, Street, City, State, and Zip. There is a hidden constraint between Street/City/State and Zip because a particular Street/City/State defines a Zip value and a Zip value defines City/State. You could validate new addresses by using a web service or with a table-level check constraint that looked up Street/City/State/Zip to make sure it was a valid combination.
This table contains a constraint that is neither a domain constraint nor a key constraint, so it is not in DKNF.
You can make the table DKNF by simply removing the Zip field. Now instead of validating a new Street/City/State/Zip, you only store the Street/City/State and you look up the address's ZIP Code whenever you need it.
It can be proven (although not by me) that a database in DKNF is immune to all data anomalies. So, why would you bother with lesser forms of normalization? Mostly because it can be confusing and difficult to build a database in DKNF.
Lesser forms of normalization also usually give good enough results for most practical database applications, so there's no need for DKNF under most circumstances.
However, it's nice to know what DKNF means so that you won't feel left out at cocktail parties when everyone else is talking about it.
ESSENTIAL REDUNDANCY
One of the major data anomaly themes is redundancy. If a table contains a lot of redundant data, then it's probably vulnerable to data anomalies, particularly modification anomalies.
However, this is not true if the redundant data is within the keys. For example, look again at Figure 7.27. The StudentClasses table contains several repeated student names and class names. Similarly, the DepartmentClasses table contains repeated Department names. You might think that these create a modification anomaly hazard.
In fact, if you look at Figure 7.26, you'll see that all these fields are part of the tables' keys. Their repetition is necessary to represent the data that the tables hold. For example, the repeated Department values in the DepartmentClasses table are part of the data showing which departments hold which classes. Similarly, the repeated Student and Class data in the StudentClasses table is needed to represent the students' class assignments.
Although these repeated values are necessary, they do create a different potential problem. Suppose that you want to change the name of the class “Real Analysis II” to “Getting Real, the Sequel” because you think it will make more students sign up for it.
Unfortunately, you're not supposed to change the value of a primary key. If you could change the value, then you might need to update a large number of records and that could lead to problems like any other modification anomaly would.
The real problem here is that you decided that the class's name should be changed. Because you can't change key values, the solution is to use something else instead of the class's name for the key. Typically, a database will use an arbitrary ID number to represent the entity, and then move the real data (in this case the class's name) into another table. Because the ID is arbitrary, you should never need to change it.
Figure 7.28 shows one way to replace these fields used as keys with arbitrary IDs that you will never need to change.
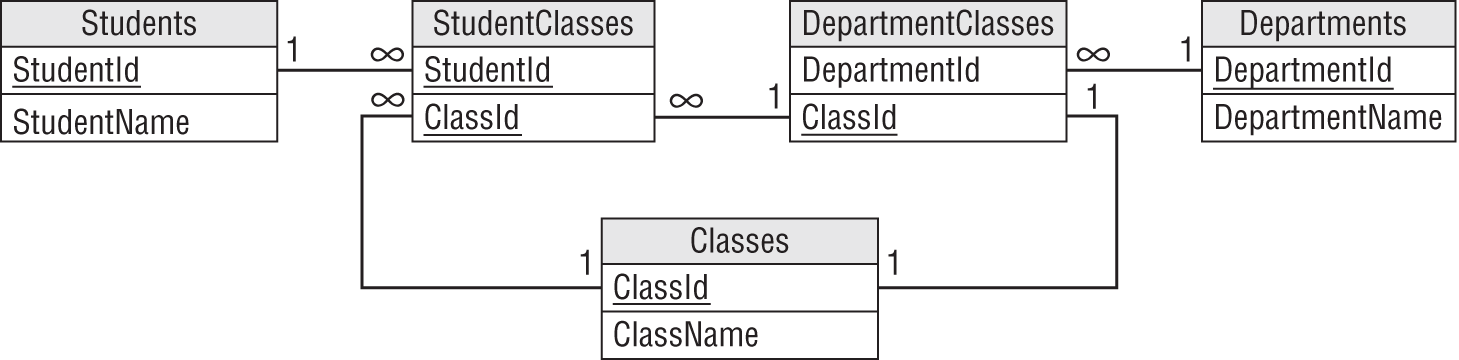
For bonus points, you can notice that you can combine the DepartmentClasses and Classes tables to give the simpler model shown in Figure 7.29. (The fact that they have a one-to-one relationship is a hint that you might be able to merge them.)

This is a reasonable model. Each table represents a single, well-defined entity: student, class, department, and the relationship between students and classes.
THE BEST LEVEL OF NORMALIZATION
Domain/key normal form makes a database provably immune to data anomalies, but it can be tricky to implement and it's not usually necessary. The higher levels of normalization may also require you to split tables into many pieces, making it harder and more time consuming to reassemble the pieces when you need them.
For example, the previous section explained that an Employees table containing Street, City, State, and Zip fields was not in DKNF because the Street/City/State combination duplicates some of the information in the Zip field. The solution was to remove the Zip field and to look up an employee's ZIP Code whenever it was needed. To see whether this change is reasonable, look at the costs and benefits.
The extra cost is that you must perform an extra lookup every time you need to display an employee's address with the ZIP Code. Nearly any time you display an employee's address you will need the ZIP Code, so you will probably perform this lookup a lot.
The benefit is that it makes the data less susceptible to data modification anomalies if you need to change a ZIP Code value. But how often do ZIP Codes change? On a national level, ZIP Codes change all the time, but unless you have millions of employees, your employees' ZIP Codes probably won't change all that frequently. This seems like a rare problem. It is probably better to use a table-level check constraint to validate the Street/City/State/Zip combination when the employee's data is created or modified and then leave well enough alone. On the rare occasion when a ZIP Code really does change, you can do the extra work to update all of the employees' ZIP Codes.
Often, 3NF reduces the chances of anomalies to a reasonable level without requiring confusing and complex modifications to the database's structure.
When you design your database, put it in 3NF. Then look for redundancy that could lead to anomalies. If the kinds of changes that would cause problems in your application seem like they may happen often, then you can think about using the more advanced normalizations. If those sorts of modifications seem rare, you may prefer to leave the database less normalized.
NOSQL NORMALIZATION
This chapter talks a lot about relational databases and how you normalize them, but what about NoSQL databases? (Here, I'm talking about nonrelational NoSQL databases, not relational pieces built into a “not only SQL” style database.) Should you normalize them too? Does that give you the same benefits as normalizing a relational database?
The short answer is, “No, NoSQL databases are not really normalized.” That's practically the definition of a nonrelational database. They don't use tables, so the same concepts don't apply.
This is both the benefit and the curse of NoSQL databases. The benefits include:
- Flexible data models—You can store just about any kind of data, structured or unstructured. A relational database can store only structured data.
- Changeable data models—You can easily change the data model over time. You might plan to store certain kinds of data, but if your needs change, then you can add new data to the database. This may make NoSQL databases particularly attractive if you don't know what data you'll eventually need.
- Scalable—Because the pieces of a relational database are tied together, it can be complicated to distribute data across many servers. If the pieces of data in a nonrelational database are not related, then they can be stored just about anywhere.
Disadvantages include:
- Poor standardization—Different kinds of nonrelational databases store data differently and have different query languages.
- Data anomalies—Relational databases provide a lot of tools to prevent anomalies such as foreign key constraints and the structure of the database itself. Those are missing in NoSQL databases, so just about any kind of data anomaly is possible. If you delete the last piece of data that refers to a particular customer, then you have no knowledge that the customer exists.
- Consistency—NoSQL databases often focus on performance and scalability, possibly at the expense of consistency. For example, the database won't stop you from adding two pieces of data that contradict each other the way a relational database can.
- Lack of atomicity—There's usually no way to commit or rollback a set of transactions as a group. Someone might fetch an inconsistent version of the data while you're in the middle of changing it. (NoSQL databases do support the idea of eventual consistency.)
You really can't normalize these databases, but this doesn't mean that you can't have rules if you want them.
For example, suppose you have a document-oriented database that stores customer data in a JavaScript Object Notation (JSON) format. JSON lets you define elements on the fly, so you can store just about anything in a JSON document. Need to add a Birthdate field? Just do it!
That doesn't mean you can't create a rule saying there can be only one Customer element for any given customer. You might have to do some extra work to enforce that rule because the document won't do it for you.
Similarly, you can use a graph database to define a network. If you like, you can make a rule that all nodes shall have between zero and four neighbors, but you'll have to enforce that rule yourself because the database won't do it for you.
SUMMARY
Normalization is the process of rearranging a database's table designs to prevent certain kinds of data anomalies. Different levels of normalization protect against different kinds of errors.
If every table represents a single, clearly defined entity, then you've already gone a long way toward making your database safe from data anomalies. You can use normalization to further safeguard the database.
In this chapter, you learned about:
- Different kinds of anomalies that can afflict a database
- Different levels of normalization and the anomalies that they prevent
- Methods for normalizing database tables
The next chapter discusses another way that you can reduce the chances of errors entering a database. It explains design techniques other than normalization that can make it safer for a software application to manipulate the database.
Before you move on to Chapter 8, however, use the following exercises to test your understanding of the material covered in this chapter. You can find the solutions to these exercises in Appendix A.