
CHAPTER 12
XML: THE BEST WAY IN AND OUT OF FLASH

In the last chapter, we looked at several different ways Flash can incorporate various types of external assets. For the most part, the classes talked about in the last chapter are all that the average Flash user will need to effectively incorporate external content within the multimedia or web development world. With this information you will have the ability to access an abundance of data ranging from simple text files to complex imagery and web applications.
In this chapter, we are going to look at XML (Extensible Markup Language), a specific way of formatting data to make it more meaningful when interacting with ActionScript. The importance of XML is universal. It is able to be read and written by most major programming languages of the modern era. Much like Flash, it has the ability to be conformed to meet the needs of the project in which it is being used. Because of this, we felt it necessary to devote an entire chapter to the introduction of XML and ActionScript. Further, like so many other topics covered in this book, an entire book about using XML with Flash could easily be written. As a matter of fact, several already have.
For these reasons XML is one of the best companion technologies for working with Flash. The relative ease in which XML can be created and the XML support offered in ActionScript 3.0 make XML the best way for sending data in and out of Flash.
What is XML?
Whenever we have a discussion with a person who is familiar with XML, but never had the opportunity to use it firsthand, there always seems to be a degree of mystique that surrounds that discussion. More often than not, XML is immediately thought of as this sophisticated programming language capable of performing all of these magic tricks for the benefit of a given application. In reality, it is not really a programming language at all.
The true magic of XML is in how eloquently simple it is by design. It is used to give meaning and structure to an otherwise meaningless series of computer characters. Other than that, it does not really do anything. It can perform no program execution of its own. It is simply a liaison, passing a structured series of information from one program to another. The assumption can then be made that, by design, XML was developed for the systematic transportation of information. In addition to being more efficient, the data will always be accessible because it will be formatted using XML. This is true regardless of the server-side technology or primary programming language.
Though you may not realize it, you're probably extremely familiar with several modern uses for XML-based technology. The most common form of XML in use today is the web service. Web services are a way for many third-party users to access a company's information without compromising security. About now you are probably looking for a real-world example. Well, most online applications have some level of XML interaction that allows outside developers access to their records. Some of the more common ones are as follows:
- Commerce: Many popular commercial sites, such as Amazon.com and eBay, offer the ability for developers to access their products and listings through a collection of web-based functions known as application programming interfaces (APIs). With this functionality developers have the ability to access many of the products, services, and listings that are offered by these companies. The data is exchanged using XML.
- Social networking: In a similar fashion, leading social networking companies such as Facebook and Meetup.com offer the ability to access and communicate with member and group information through a similar series of APIs. This information is also passed from place to place in the form of XML.
- News feeds: The news feed is an idea that is almost as old as the Internet itself. It is a native feature for most blogs and community web sites. The most popular brand of feed is RSS (Really Simple Syndication). However, because news feeds are almost a web site staple in this day and age, they come in many forms. Additionally, larger news firms such as CNN, MSNBC, and FOX Sports all transmit their news through some type of news feed, usually RSS. The data sent from news feeds are commonly formatted as XML.
While the most common use for XML is communication via web service, the purposes of XML far exceed data transmission. XML can be used to define other markup languages as well. It is the foundational standard for all modern markup languages. The following web programming languages are some of the more popular languages that find their roots in XML:
- ASP.NET: Microsoft's standard web language
- XHTML: A strict XML-conformant form of HTML
- MXML: A markup language developed for use with Adobe Flex
XML is used as a standard for desktop applications as well. For example, Microsoft completely rearchitected its markup model for Word 2007 to include the new XML-based file format DOCX.
ActionScript 3.0 and E4X
E4X simply stands for ECMAScript for XML. Huge help, we know. Ecma International (formerly the European Computer Manufacturers Association) is a private nonprofit association devoted to the standardization of communications and information as it relates to technology.
Recall that ActionScript is a derivative of ECMAScript and the ECMA-262 standard. Well, the more ActionScript matures, the more compliant it will become with ECMA standards. The primary benefit to standards conformance is to ensure that programming is strict, well-formed, and common among different programmers. E4X is then the current standard for working with XML data in ECMA-based languages like ActionScript. With the addition of E4X in ActionScript 3.0, we saw a significant movement toward greater code manageability and data access.
In previous versions of Flash, a developer would need to access information through all of an element's parents. For example, let's say we had information about various cities around the world organized in an XML structure.
To access this information in early versions of ActionScript, you would need to use something like this:
World.NorthAmerica.UnitedStates.Maryland.Baltimore.population.
Actually, it would look something more like this:
World.childNodes[1].childNodes[1].childNodes[1].childNodes[1]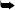
.attributes.population
You can see where this would become extremely inefficient.
Fortunately, ActionScript 3.0 and E4X do offer immediate help. To access the same information, as previously discussed, a developer can use a more condensed approached as shown here:
xml..Baltimore.@population
As you delve deeper into this chapter, you will get a better understanding of how Flash operates on XML. For now, it is sufficient to understand that Flash is now compliant with the standard method of operating on XML: E4X.
Let's get started examining the basics of the XML structure.
Learning to see XML
Much like any other type of computer language (markup or programming), when you first take a look at XML, it can be a bit overwhelming. Further, the more complicated the structure, the harder it becomes to discern data from syntax. Fortunately, there is no "doing" involved with XML as a language. Simply put, where ActionScript can perform computation and manipulation on various values, XML cannot. Therefore, there will be no added confusion associated with the learning of theory or interactive programming. Once a person learns a few very basic rules that govern the way XML is structured, developing and reading-in complex data structures becomes almost like riding a bike.
The most important thing that any new XML user needs to understand is that XML is self-descriptive. This simply means that the developer defines not only the data, but also the elements that contain the data. There are not an overwhelming number of reserved keywords or role-specific programming characters that need to be learned. With the exception of a few basic rules that we will discuss in this chapter, the entire document can be defined by the programmer. In essence, it then becomes a matter of not what is being organized but how.
As shown next, we have created an XML structure that organizes data relating to the members of a popular sports team into a structure that is more easily understood by both the human eye and a computer program. For sake of example, the structure defines a popular professional soccer team, the Red Devils. In the structure we are able to start defining information about the players on the team using the player tag. As you can see, this example actually defines three players. We then begin to have the ability to add further information about each player including name, pos, and number. This continual nesting of information is often referred to as the XML tree.
<red_devils>
<player>
<name>Van der Sar</name>
<pos>Keeper</pos>
<number>1</number>
</player>
<player>
<name>Giggs</name>
<pos>Midfielder</pos>
<number>11</number>
</player>
<player>
<name>Rooney</name>
<pos>Striker</pos>
<number>10</number>
</player>
</red_devils>
Figure 12-1 gives an excellent graphical model to further understand what the preceding data structure is representing.
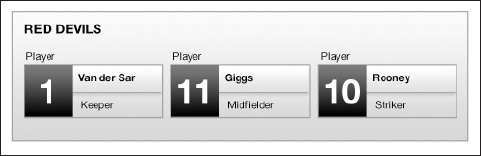
Figure 12-1. A graphical representaion of the defined XML structure
An XML tree must always contain a top-level node, or single element, which is commonly referred to as the root node. This element will contain everything else that exists in the XML data structure. In this example we used red_devils as the root node, which is also conveniently the name of the team. Because this is XML and self-descriptive, we could have just as easily used something like manchester, roster, or team as the root node. This becomes a powerful feature as the data and data structure are fully customizable.
Chapter 11 included a simple name-value pair data structure that sent data formatted as a query string to a remote PHP script. If you compare that example to the current one, you should see how much more powerful the XML approach becomes. Imagine trying to streamline this information in a name-value pair. Your variable-naming scheme would have to be pretty intricate. How would you define individual players? How would you associate attributes to those players? What about scalability? Right now, you are only working with three players. There are over 40 players on the Red Devils. Now imagine trying to pass information about the entire league. There are 20 teams registered this year. That's more than 800 players and a lot of statistics. Not to be obnoxious about the whole thing, but you can see where trying to organize this information into name-value pairs versus XML would become an absolute nightmare.
Conversely, using XML would be overkill in a situation as similar to that in the Chapter 11 form. XML is definitely better to use with complex data structures or data structures that have the potential for becoming complex.
Now, let's look a little more closely at how to create well-formed XML.
Using proper structure and syntax
To effectively work with XML, a developer only needs to become familiar with a few very basic syntactical rules to create a well-formed structure. Those rules pertain to the-following:
- Elements
- Entities and escapes
- Attributes
- Empty elements
- Efficiency
- Comments
Elements
The element is the most basic part of the XML structure. An element is defined by an opening and closing tag. A tag is any descriptive text that is contained within the less than (<) and greater than (>) characters. To help you better understand this concept, go ahead and open player_01.xml located in the Chapter 12 folder of the working files directory.
First thing you will want to do within the family.xml file is enter the following code, which will create an element. If you are familiar with working with HTML, you will no doubt feel right at home.
<family>
</family>
Notice that <family> is an opening tag that would also signify the start of the family element. The closing tag, </family>, is defined in the same manner and includes a forward slash (/) directly after the less than character (<). The entire element is then defined as everything located within these two tags, including the tags themselves.
Rules for working with elements
When working with XML elements, a few simple rules need to be adhered to. The ability to have self-descriptive items within a data structure is powerful indeed, but it is these rules that give the structure meaning.
- Closing tags: All XML elements must contain an opening and closing tag. Failure to properly tag your elements could result in a program error. The following is an example of an improperly tagged element. As you can see, there is an opening tag but no subsequent closing tag.
<name>Van der Sar - Tags must match: It is important, when establishing your elements, to make sure that the opening tag and the ending tag are exactly the same. Misspelling and case insensitivity will create program errors. The following opening and closing tags are not the same:
<name> Van der Sar </Name> - Proper nesting: One of the most important things associated with the XML structure is the structure itself. Improperly nested elements or broken structure will immediately create an error when the program tries to read in an XML document. The following example has the two closing tags out of order; this error completely undermines the XML structure.
<player><name>Van der Sar </player></name> - Proper naming: There are a few things to also understand when choosing names for your element tags:
- Element names may contain any alphanumeric character and most special characters with the exception of the reserved entities, which will be discussed shortly in the "Entities and escapes" section.
- Names cannot start with numbers or special characters.
- Names cannot begin with any derivative of the word "XML" (XML, xml, etc.).
- Names cannot contain spaces.
Filling out the XML tree
Now that you have become familiar with creating XML elements, take a few minutes and flesh out a structure within the family.xml file. For this example you will want to create several members of your "family," much like the members of the Red Devils soccer team introduced earlier in this chapter. In addition to the members of the family, create several more elements to use to add description to each member. In the following example, such elements include name for a name, hair for hair color, eyes for eye color, and rel for their relationship.
<family>
<member>
<name>Paul</name>
<hair>Brown</hair>
<eyes>Brown</eyes>
<rel>Me</rel>
</member>
<member>
<name>Erica</name>
<hair>Red</hair>
<eyes>Burnt Sienna</eyes>
<rel>Wife</rel>
</member>
<member>
<name>Kelli</name>
<hair>Brown</hair>
<eyes>Brown</eyes>
<rel>Sister</rel>
</member>
</family>
Entities and escapes
As mentioned earlier in this chapter, one of the greatest benefits to using XML is the lack of a complicated set of reserved keywords and characters. To create XML you simply need to know what data you want to organize and start organizing it. However, there are a few items that do have a specific meaning to the programs that digest the XML data. Take the following XML code, for example:
<math_problem> 3 + x < 10 </math_problem>
When a program begins to examine the structure of XML data, it knows that certain characters signify certain events. For instance, the less than (<) character lets the program know that a tag or closing tag is about to be defined. So, in the case of the aforementioned math problem element, the < character in the actual problem would make the parsing program think that a new tag was being defined. Because this is not actually a new tag and no other appropriate characters exist with it, the way that line is entered would create an error in the receiving program.
Fortunately, there is a simple workaround for this problem. To use a character that has been predetermined to perform a functional task in XML, you must employ the use of character entity references. The entity reference, also commonly referred to as an escape sequence, is a string of characters that is used in place of a specific character, or entity. There are only five reserved characters as defined by the XML specification, as shown in Table 12-1.
Table 12-1. The five primary reserved characters as dictated by the XMl specification
| Entity | Escape sequence | Usage |
| > | > | Greater than |
| < | < | Less than |
| & | & | Apostrophe |
| " | " | Quotation mark |
| ' | ' | Apostrophe; |
The syntax of an escape sequence is actually also fairly straightforward. to initiate an escape you must use an ampersand (&), followed by a character code, followed by a semicolon (;).so to solve the problem from the earlier code snippet, we implement a standard escape sequence, using the character code for the less than (<) sign as demonstrated here:
<math_problem> 3 + x < 10 </math_problem>
Attributes
Attributes give you the ability to add further information that is going to be associated with a specific element. An attribute is nothing more than a simple name-value pair that is added to the opening tag of any given element.
Attributes also allow you to package, or encapsulate, information within one element for the benefit of increased organization. As demonstrated in the following example, you can see how adding attributes to a simple element lets you effectively associate more information with that element. The following element defines a collection of information about an apple:
<apple>
<type>macintosh</type>
<color>red</color>
</apple>
By using attributes we have the ability to add more descriptive information about the given element.
<apple type="macintosh" color="red"></apple>
<apple type="macintosh" color="red"></apple>
Here's a note of caution about attributes. As a personal approach, we try to organize ourselves as efficiently as possible. When working with XML, we like to use attributes as much as we can. However, there are a couple things to think about before you become too attribute crazy.
Because attributes are nested within the opening tag of an element, they are limited in the amount of information they can represent. Like the name-value pair, an attribute can only contain one value. When using elements, however, you have the ability to have that element contain many values, including text nodes, other elements, and attributes. This also gives you the future flexibility to edit the structure if needed.
The best way to approach this, as a developer, is to determine what the program requires. Remember, this is XML, so you can shape it any way you want. Therefore, don't limit yourself to what may or may not be considered best practice in this situation. Try to take an objective look at the problem you are faced with and determine the best solution.
Empty elements
Another tool that can be used as a medium of efficiency is the empty element. As you can see in the preceding code, moving all descriptive information to attributes has a tendency to make the use of text nodes and subsequent closing tags unnecessary. If you know that your elements will not require a text node, you have the ability to define them as empty elements.
To create an empty element, you simply remove the closing tag and insert a slash (/) just before the greater than (>) character in the opening tag definition. The following will be recognized as a complete element by the parsing program:
<apple type="macintosh" color="red" />
Efficiency
For further insight into how XML can become a more efficient structure, let's revisit the players example from earlier in this chapter.
<red_devils>
<player>
<name>Van der Sar</name>
<pos>Keeper</pos>
<number>1</number>
</player>
<player>
<name>Giggs</name>
<pos>Midfielder</pos>
<number>11</number>
</player>
<player>
<name>Rooney</name>
<pos>Striker</pos>
<number>10</number>
</player>
</red_devils>
If you were to take the previously mentioned structure and streamline it using only attributes, you could end up with something similar to what you see next. Notice how much more compact and efficient this information becomes while maintaining all the same information.
<red_devils>
<player name="Van der Sar" pos="Keeper" number="1" />
<player name="Giggs" pos="Midfielder" number="11" />
<player name="Rooney" pos="Striker" number="10" />
</red_devils>
Commenting XML
In XML there are two primary methods of commenting text: standard XML-style commenting and using CDATA tags.Standard commenting is used in a manner similar to the way comments are employed in any other programming language. As shown next, a standard comment is exactly the type of comment found in HTML. Such comments are used to both describe areas of your coded document and serve as a vessel of communication between you and other developers.
Standard XML-style comment
The standard XML-style comment is initiated by the <!-- sequence of characters. It is then closed by the --> sequence of characters. Whatever text is typed between these two sets of characters will be ignored by the XML parser of the receiving program.
Here's an example:
<!-- This is a standard comment typically used for instruction. -->
CDATA comments
CDATA comments are actually very similar to block-level comments used in ActionScript. The biggest benefit to using CDATA comments is that they maintain format and allow you to pass whatever characters you want to the parsing program as exact. Therefore you could pass any set of characters, including reserved entities, to ActionScript, and the XML would maintain the integrity of those characters.
Here's an example:
<xmlData>
<a_cdata_comment>
<![CDATA[
function doSomethingCool(a:int, b:int)
{
var c:int;
c = a + b;
return c;
}
You may also type <b>any</b> manner
of text here & it will still work!
This includes reserved characters like >, <, and "".
]]>
</a_cdata_comment>
</xmlData>
Now that you are familiar with the structure of XML, you can try your hand at loading this data into Flash via ActionScript.
Loading an XML file with ActionScript
In this section you'll take a crack at loading XML into Flash using ActionScript. For this example, you are going to load in the XML data you created earlier in this chapter with the family_02.xml file.
Loading XML data into Flash involves all of the usual suspects that you would expect to find when loading any other type of external data. Let's take a quick look at the following code used in ch12_01.fla:
var req:URLRequest = new URLRequest("family.xml");
var xml:XML;
URLRequest and URLLoader objects
After reading Chapter 11, you should be pretty familiar with the URLRequest object and what it is used for. In this example, it retrieves the family.xml file you created earlier. The second line is new, however. You should recognize it as a variable declaration. And based on its name, you have probably also assumed that this variable will be used to store your incoming XML data. You will not be assigning value to the variable at this point because there is nothing to assign.
The next three lines should be pretty straightforward. The first line creates the loader object that will be used to load the previously created URLRequest. The second line will be used to assign the event listener to the URLLoader object and set the handler as the loadXML function. Finally, the load method is called and passed the value of the URLRequest as its parameter.
var xmlLoader:URLLoader = new URLLoader();
xmlLoader.addEventListener(Event.COMPLETE, loadXML);
xmlLoader.load(req);
Event handler
The final piece of the puzzle is the event handler. There isn't really much variation from this handler and the ones we discussed in Chapter 9. Here, we assign a value to the xml object. As discussed a moment ago, you needed to wait until data was available before you could assign it to a variable.
function loadXML (e:Event)
{
xml = new XML(e.target.data);
trace(xml);
}
The other question that may also arise is why the variable was not simply declared in the event handler. Well, aside from being a cleaner way of coding, the answer has everything to do with the scope of the variable. Had the variable been declared within the event handler, we would have no way to access it outside of the event handler without creating some other form of external reference. Ultimately, the information loaded in from an external source will need to be used by other parts of the program. By declaring the variable at the root level, we make the XML data accessible to the whole program.
Once the necessary code is in place, you can test your movie (Ctrl+Enter or Cmd+Enter). You then see your XML data traced out perfectly in the Output window, similarly to Figure 12-2.
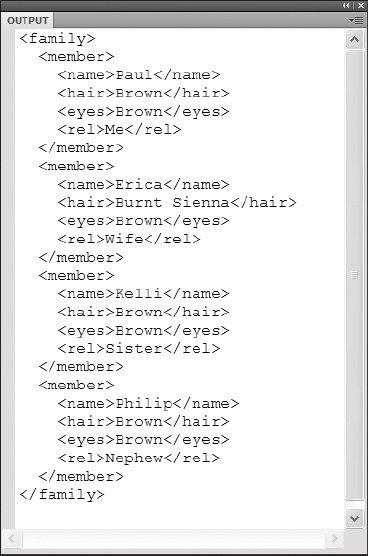
Figure 12-2. The Flash Output panel displaying XML data stored in the family.xml file
Once you have loaded an XML file into Flash, you will need to filter the information in the XML structure to use it in your application. In the next section we will discuss in detail the primary methods used to filter XML.
Reading the XML data
And now the real fun begins. So far we have looked at the creation structure for simple XML documents. We have also been able to access, load, and display an entire set of data stored within that XML document. At this time we will take a look at several methods for accessing that information for specific use in ActionScript.
XML and XMLList classes
For accessing the information stored in an XML tree, ActionScript offers two primary classes: the XML class and the XMLList class. For the most part, these two classes operate in a very similar fashion. Because of this, there is often some degree of confusion surrounding the best use of these classes.
The primary difference between the XML and XMLList class is that the XML class is used to work with a single, well-formed XML data structure, and the XMLList is capable of working with multiple XML objects including elements, text nodes, and attributes. Further, the XMLList offers increased functionality for handling lists of information. Ultimately, the XMLList class will aid you in the management of multiple sets of information like family members, players on a soccer team, or aggregated news feeds.
In the previous example you used the XML class to create an object and load in a data structure that was descriptive of members of your family. Because you created it from scratch, you know that the data was both thorough and well formed. As a result your information was loading into ActionScript with no problem.
However, if you were to remove the root element of the structure as shown next, you would no longer have a single well-formed XML structure. Instead, you would have a list of many XML objects.
<member>
<name>Paul</name>
<hair>Brown</hair>
<eyes>Brown</eyes>
<rel>Me</rel>
</member>
<member>
<name>Erica</name>
<hair>Red</hair>
<eyes>Burnt Sienna </eyes>
<rel>Wife</rel>
</member>
<member>
<name>Kelli</name>
<hair>Brown</hair>
<eyes>Brown</eyes>
<rel>Sister</rel>
</member>
<member>
<name>Philip</name>
<hair>Brown</hair>
<eyes>Brown</eyes>
<rel>Nephew</rel>
</member>
If you then tried to load this data, now referring to the file family_02.xml, using the standard XML object, you would be shown an error as demonstrated in Figure 12-3.
Figure 12-3. Output error generated by improper XML formatting
The error type Error #1088 is letting you know that the XML information that is being loaded into the XML object is not properly formatted. Recall that all well-formed XML must have a single root element or node that contains everything else in the structure. As a result of your data no longer having a root node, the family tag, ActionScript no longer accepts it as an XML object.
This minor setback is just what you need to get a glimpse at how the XMLList differs from the standard XML class. If you make a few minor edits to the code in ch12_01.fla (or jump right to ch12_02.fla) as shown next, you should now be able to load the XML data from family_02.xml with no adverse side effects. Because the XMLList is capable of handling multiple XML objects, it simply digests this information as a list of elements rather than one entire XML tree.
var req:URLRequest = new URLRequest("family_02.xml");
var xml:XMLList;
...
function loadXML (e:Event)
{
xml = new XMLList(e.target.data);
trace(xml);
}
Chances are, as a developer, you are not going to be dealing with malformed XML data coming from a remote source. In addition, as professionals, it is always a good idea to adhere to standards. Therefore, you will more than likely never have to use the XMLList object for loading XML information. The real purpose of the class is to allow you to work with different aspects of the information as a list. Therefore, though you may load the information from the family XML tree as an XML object, when you ultimately access that information it will be converted to an XMLList.
Accessing XML data
Thanks to the added benefit of E4X in ActionScript 3.0, accessing XML data has become significantly less difficult than in ActionScript 2.0. The primary reason is that you now have access to the various nodes (elements, attribute, and text) through the use of their names and the dot operator (.), as you would when accessing properties of ActionScript objects like Germ.height.
Accessing elements
Using the file ch12_03.fla, you will be loading and manipulating XML data from players_03.xml. Upon opening this file you should notice the standard loading sequence as used in several previous examples. The data found in the player_03.xml source is a slightly adjusted version of the earlier versions of the player XML files, as shown next. You will notice that this file contains data similar to preceding examples, the two differences being the mixed format offering both child elements and attributes and additional players for a more verbose data set.
<red_devils>
<player name="Van der Sar">
<pos>Keeper</pos>
<number>1</number>
</player>
<player name="Giggs">
<pos>Midfielder</pos>
<number>11</number>
</player>
<player name="Rooney">
<pos>Striker</pos>
<number>10</number>
</player>
<player name="Rinaldo">
<pos>Winger</pos>
<number>7</number>
</player>
<player name="Vidic">
<pos>Defender</pos>
<number>15</number>
</player>
</red_devils>
Now that you have had a quick look at the data you will be working with, you can begin to access that data directly. In the loadXML event handler in ch12_03.fla, enter the following line of code:
trace(xml.player);
In this trace statement, because you know that your XML data has been loaded into your xml object, you use that variable name to access the XML data. Because of the enhanced E4X capabilities, you can then access child nodes of the XML data's tree simply by using the node name as you would a property. Therefore, because you know that your data source contains a series of XML elements named player, you can access that information directly using xml.player. The trace statement would then send all information concerning the player nodes to the Output window as shown in Figure 12-4.
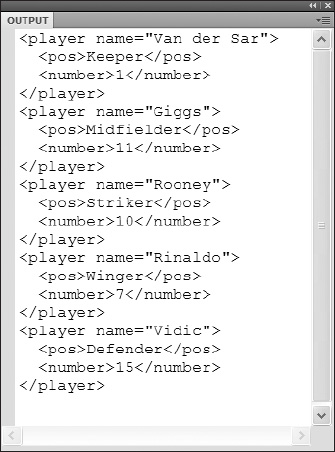
Figure 12-4. The output of a trace statement referencing xml.properties
Drilling down into the structure
In a similar fashion you also have the ability to drill down into the structure and access child nodes of child nodes (think grandchildren) by continually using the dot operator (.). If you change the trace statement in your current working file to the following, you will then have the ability to access information associated with the pos elements, or position, of each player.
trace(xml.player.pos);
You then get an output of all nodes that match the request for the pos name, as shown in Figure 12-5.
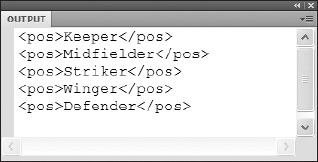
Figure 12-5. The output of the request for the xml.player.pos element name
Using the children() method
In the event that you are unable to access elements directly, you also have the ability to simply load all child elements of any particular node using the children() method. In this case let's assume that you know there are players or, more to the point, player elements within the XML data structure, but you are not sure what information, if any, is contained within those elements. You can then edit the trace statement, as shown next, to simply return all the child elements of any node that is named player.
trace(xml.player.children());
The resulting output would then contain a list of all child nodes and their values, as shown in Figure 12-6.
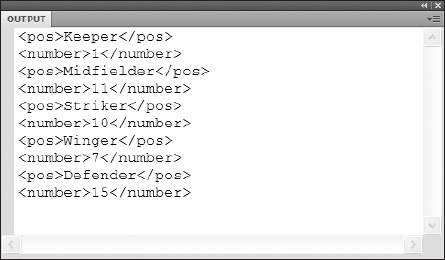
Figure 12-6. The trace output of values returned using the children() method
Retrieving text node values
When working with XML, the node name is important in order to access your information. However, because XML node names are typically repetitive, it is highly unlikely that you would ever want to use the node name as a valid piece of data. What is going to ultimately be important to the users of your application is the information stored in the text node element.
To access text node values in ActionScript, use the simple textx() method, shown next. If you once again edit the trace statement of your working file, you can very easily get access to a valid text value stored in any of the existing nodes.
trace(xml.player.pos.text());
The resulting trace statement output, shown in Figure 12-7, is at this point probably not a very effective piece of data, but it does demonstrate the ability to access textual data that has been stored within an XML element.

Figure 12-7. Text node values that have been captured using the text() method
Double dot notation
The double dot operator (..) gives developers the ability to bypass a long series of node names in the process of drilling into the XML structure. Earlier in this chapter we discussed the dot operator (.) as a means to access child nodes. This access was limited to parent-child relationships. With the double dot operator, you have the ability to jump to whichever node you wish to access. This is an incredibly valuable and effective tool for ActionScript programmers to now have the ability to use.
In the following example, the double dot is used to bypass the player node name.
trace(xml..pos.text());
Though this particular example is a relatively small leap, imagine if you need to access a more complex structure like the animal kingdom. To get to a dog, you would have to traverse a structure like Kingdom.Phylum.Classes.Orders.Families.Genera.Species. The double dot operator gives you the ability to bypass complex structures and go right to Kingdom..Species.
Accessing attribute values
As you may have guessed, because attributes have special placement within the XML structure, they do require a special method for reading their values. There are actually several ways to access XML attribute values. We'll discuss the following:
- Attribute identifier operator (@)
attribute()methodattributes()method
To access attributes directly by name, you may use the dot syntax that has been discussed so far in this chapter. However, you will be required to use the attribute identifier operator,@, as a prefix to the attribute name. In your current XML structure, all player elements have an attribute name that contains the last name of each player. If you then use the @ character followed by the attribute name name, you can directly access the value of that node just as you would any other node.
trace(xml.player.@name);
You then get an output of all attribute values as shown in Figure 12-8.
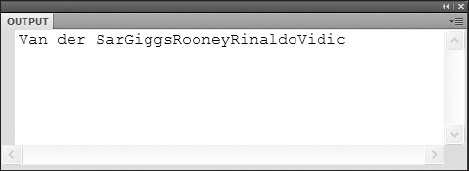
Figure 12-8. The output of the attribute values from the name attributes
The second method for accessing values is using the attribute() method. The attribute() method can be used in a similar fashion to the attribute identifier operator, where the targeting of a specific attribute name is taking place. As shown next, this method accepts one parameter: a string value representing the name of the attribute. When this file is tested, you will notice exactly the same output as was achieved in Figure 12-8.
trace(xml.player.attribute("name");
The final method for accessing attribute values works as the children() method did when retrieving the information about an element's children. This method is also used to search for attributes of an undetermined name or quantity. The attributes() method (note the s) is used exactly like the other two attribute routines. As shown next, this method accepts no parameter.
trace(xml.player.attributes());
Though the values returned in this example are exactly as shown in Figure 12-8, be advised that this example is only using one set of attributes. Unlike the previous two methods, which only returned attribute values associated with the attribute name, this method will return all attribute values associated with all child elements of the accessed XML element.
Bracket (array) notation
Having now thoroughly combed through the currently available XML data structure, it is about time we stop returning lists of data and started pinpointing individual values. To accomplish this ActionScript uses simple bracket notation ([0]). Bracket notation is used to access the values of a special type of data structure known as an array. Arrays are essentially variables that are used to store multiple values, or a list.
The following example demonstrates the building of an array (list):
var friends:Array = new Array("Tom","Dick","Harry");
trace(friends); //Tom,Dick,Harry
The values in this list can then be accessed individually through the use a set of brackets ([]) containing the index position of the value. If we wanted to trace Dick's name, we would use this notation as follows:
trace(players [1]); //Dick
We simply place the index value (position) of the item in our list inside brackets, directly after the name of the array. You're probably wondering why Dick's name was second in the list and accessed by a 1. Well, computers start counting with zeros. Therefore, the first index value of an array is always 0, so the first element in your list is going to be at the 0 position, not 1. So instead of thinking 1,2,3,4 . . ., start thinking 0,1,2,3 . . .
Virtually every example we have looked at over the last section has the ability to be augmented with array notation. When Flash parses XML data, the elements are stored as arrays (indexed lists), which allow us to use this same functionality.
Using the trace statements, you can see that the simple addition of bracket notation to each statement will allow you to no longer trace out entire lists associated with specific nodes but an individual value instead.
The first statement shown here will now only trace out the complete child for the first position of the list:
trace(xml.player[0]);
/*
<player name="Van der Sar">
<pos>Keeper</pos>
<number>1</number>
</player>
*/
You also have the ability to insert the array notation at several levels of the dot notation. The following example also targets the first player node, but it also uses the children() method to search for child elements. You can then use the array notation a second time to select only one specific child element and return the value. The following statement then traces 1, which is the value of the second child element of the first player:
trace(xml.player.children()[1]); // 1
Finally, array notation can be used with the other XML methods in an abundance of combinations to achieve the desired result. The following code sample demonstrates possible outcomes when working with array notation and the previous examples:
trace(xml..pos.text()[0]); //Keeper
trace(xml.player [2].@name); //Rooney
trace(xml.player.@name[2]); //Rooney
trace(xml.player.attribute("name")[4]); //Vidic
trace(xml.player.attributes()[4]); //Rinaldo
Filtering node values
One final aspect of accessing XML values that is definitely worth mentioning is the ability to filter various values using the filtering predicate operator (()). The filtering predicate operator allows values to be filtered based on a specific node or attribute value. By comparing the equality of a node and a value, we can pinpoint exact elements or groups of elements and various extra values.
The following uses the filtering predicate operator to determine which player elements have a pos value of Striker and returns the value of the number node:
trace(xml.player.(pos == "Striker").number); //10
In a similar fashion you can use this method to compare the values of attributes. The first example uses the filtering predicate in conjunction with an attribute identifier. This example returns the value of the name attribute that is associated with the player element whose pos value is equal to Striker. You are then given the output of Rooney.
trace(xml.player.(pos == "Striker").@name); //Rooney
In the second example you see that you can conveniently use the attribute identifier within the filtering predicate to achieve the almost reverse situation as the previous example. You are now looking for the pos value for the player element whose name attribute is equal to Rooney. The returned output is Striker.
trace(xml.player.(@name == "Rooney").pos); //Striker
Summary
The chapters in Part 3 have given you access to a tremendous amount of power with respect to ActionScript. As a Flash user, this is the material that is going to propel you into the realm of web application development. As a designer, you now possess the basic knowledge to begin communicating programmatically with web specialists authoring in an abundance of different programming languages.
In this chapter, we discussed the following important topics:
- Proper XML formatting and structure.
- The XML class, which is used for holding and manipulating an entire single XML object.
- The
XMLListobject, which is used to manipulate one or more elements or objects. You also have access to an additional level of functionality similar to theListclass.