
Within the .NET Framework base class library, the System.String type is the model citizen of how to create an immutable reference type that semantically acts like a value type.
Instances of String are immutable in the sense that once you create them, you cannot change them. Although it may seem inefficient at first, this approach actually does make code more efficient. If you call the ICloneable.Clone method on a string, you get an instance that points to the same string data as the source. In fact, ICloneable.Clone simply returns a reference to this. This is entirely safe because the String public interface offers no way to modify the actual String data. Sure, you can subvert the system by employing unsafe code trickery, but I trust you wouldn't want to do such a thing. In fact, if you require a string that is a deep copy of the original string, you may call the Copy method to do so.
Note
Those of you who are familiar with common design patterns and idioms may recognize this usage pattern as the handle/body or envelope/letter idiom. In C++, you typically implement this idiom when designing reference-based types that you can pass by value. Many C++ standard library implementations implement the standard string this way. However, in C#'s garbage-collected heap, you don't have to worry about maintaining reference counts on the underlying data.
In many environments, such as C++ and C, the string is not usually a built-in type at all, but rather a more primitive, raw construct, such as a pointer to the first character in an array of characters. Typically, string-manipulation routines are not part of the language but rather a part of a library used with the language. Although that is mostly true with C#, the lines are somewhat blurred by the .NET runtime. The designers of the CLI specification could have chosen to represent all strings as simple arrays of System.Char types, but they chose to annex System.String into the collection of built-in types instead. In fact, System.String is an oddball in the built-in type collection, because it is a reference type and most of the built-in types are value types. However, this difference is blurred by the fact that the String type behaves with value semantics.
You may already know that the System.String type represents a Unicode character string, and System.Char represents a 16-bit Unicode character. Of course, this makes portability and localization to other operating systems—especially systems with large character sets—easy. However, sometimes you might need to interface with external systems using encodings other than UTF-16 Unicode character strings. For times like these, you can employ the System.Text.Encoding class to convert to and from various encodings, including ASCII, UTF-7, UTF-8, and UTF-32. Incidentally, the Unicode format used internally by the runtime is UTF-16.[25]
When you use a string literal in your C# code, the compiler creates a System.String object for you that it then places into an internal table in the module called the intern pool. The idea is that each time you declare a new string literal within your code, the compiler first checks to see if you've declared the same string elsewhere, and if you have, then the code simply references the one already interned. Let's take a look at an example of a way to declare a string literal within C#:
using System;
public class EntryPoint
{
static void Main( string[] args ) {
string lit1 = "c:\windows\system32";
string lit2 = @"c:windowssystem32";
string lit3 = @"
Jack and Jill
Went up the hill...
";
Console.WriteLine( lit3 );
Console.WriteLine( "Object.RefEq(lit1, lit2): {0}",
Object.ReferenceEquals(lit1, lit2) );
if( args.Length > 0 ) {
Console.WriteLine( "Parameter given: {0}",
args[0] );
string strNew = String.Intern( args[0] );
Console.WriteLine( "Object.RefEq(lit1, strNew): {0}",
Object.ReferenceEquals(lit1, strNew) );
}
}
}First, notice the two declarations of the two literal strings lit1 and lit2. The declared type is string, which is the C# alias for System.String. The first instance is initialized via a regular string literal that can contain the familiar escaped sequences that are used in C and C++, such as and
. Therefore, you must escape the backslash itself as usual—hence, the double backslash in the path. You can find more information about the valid escape sequences in the MSDN documentation. However, C# offers a type of string literal declaration called verbatim strings, where anything within the string declaration is put in the string as is. Such declarations are preceded with the @ character as shown. Specifically, pay attention to the fact that the strange declaration for lit3 is perfectly valid. The newlines within the code are taken verbatim into the string, which is shown in the output of this program. Verbatim strings can be useful if you're creating strings for form submission and you need to be able to lay them out specifically within the code. The only escape sequence that is valid within verbatim strings is "", and you use it to insert a quote character into the verbatim string.
Clearly, lit1 and lit2 contain strings of the same value, even though you declare them using different forms. Based upon what I said in the previous section, you would expect the two instances to reference the same string object. In fact, they do, and that is shown in the output from the program, where I test them using Object.ReferenceEquals.
Finally, this example demonstrates the use of the String.Intern static method. Sometimes, you may find it necessary to determine if a string you're declaring at run time is already in the intern pool. If it is, it may be more efficient to reference that string rather than create a new instance. The code accepts a string on the command line and then creates a new instance from it using the String.Intern method. This method always returns a valid string reference, but it will either be a string instance referencing a string in the intern pool, or the reference passed in will be added to the intern pool and then simply returned. Given the string of "c:windowssystem32" on the command line, this code produces the following output:
Jack and Jill
Went up the hill... Object.RefEq(lit1, lit2): True Parameter given: c:windowssystem32
Object.RefEq(lit1, strNew): True
You often need to format the data that an application displays to users in a specific way. For example, you may need to display a floating-point value representing some tangible metric in exponential form or in fixed-point form. In fixed-point form, you may need to use a culture-specific character as the decimal mark. Traditionally, dealing with these sorts of issues has always been painful. C programmers have the printf family of functions for handling formatting of values, but it lacks any locale-specific capabilities. C++ took further steps forward and offered a more robust and extensible formatting mechanism in the form of standard I/O streams while also offering locales. The .NET standard library offers its own powerful mechanisms for handling these two notions in a flexible and extensible manner. However, before I can get into the topic of format specifiers themselves, let's cover some preliminary topics.
Note
It's important to address any cultural concerns your software may have early in the development cycle. Many developers tend to treat globalization as an afterthought. But if you notice, the .NET Framework designers put a lot of work into creating a rich library for handling globalization. The richness and breadth of the globalization API is an indicator of how difficult it can be. Address globalization concerns at the beginning of your product's development cycle, or you'll suffer from heartache later.
Every object derives a method from System.Object called ToString that you're probably familiar with already. It's extremely handy to get a string representation of your object for output, even if only for debugging purposes. For your custom classes, you'll see that the default implementation of ToString merely returns the type of the object itself. You need to implement your own override to do anything useful. As you'd expect, all of the built-in types do just that. Thus, if you call ToString on a System.Int32, you'll get a string representation of the value within. But what if you want the string representation in hexadecimal format? Object.ToString is of no help here, because there is no way to request the desired format. There must be another way to get a string representation of an object. In fact, there is a way, and it involves implementing the IFormattable interface, which looks like the following:
public interface IFormattable
{
string ToString( string format, IFormatProvider formatProvider )
}You'll notice that all built-in numeric types as well as date-time types implement this interface. Using this method, you can specify exactly how you want the value to be formatted by providing a format specifier string. Before I get into exactly what the format strings look like, let me explain a few more preliminary concepts, starting with the second parameter of the IFormattable.ToString method.
An object that implements the IFormatProvider interface is—surprise—a format provider. A format provider's common task within the .NET Framework is to provide culture-specific formatting information, such as what character to use for monetary amounts, for decimal separators, and so on. When you pass null for this parameter, the format provider that IFormattable.ToString uses is typically the CultureInfo instance returned by System.Globalization.CultureInfo.CurrentCulture. This instance of CultureInfo is the one that matches the culture that the current thread uses. However, you have the option of overriding it by passing a different CultureInfo instance, such as one obtained by creating a new instance of CultureInfo by passing into its constructor a string representing the desired locale formatted as described in the RFC 1766 standard such as en-US for English spoken in the United States. For more information on culture names, consult the MSDN documentation for the CultureInfo class. Finally, you can even provide a culture-neutral CultureInfo instance by passing the instance provided by CultureInfo.InvariantCulture.
Note
Instances of CultureInfo are used as a convenient grouping mechanism for all formatting information relevant to a specific culture. For example, one CultureInfo instance could represent the cultural-specific qualities of English spoken in the United States, while another could contain properties specific to English spoken in the United Kingdom. Each CultureInfo instance contains specific instances of DateTimeFormatInfo, NumberFormatInfo, TextInfo, and CompareInfo that are germane to the language and region represented.
Once the IFormattable.ToString implementation has a valid format provider—whether it was passed in or whether it is the one attached to the current thread—then it may query that format provider for a specific formatter by calling the IFormatProvider.GetFormat method. The formatters implemented by the .NET Framework are the NumberFormatInfo and DateTimeFormatInfo types. When you ask for one of these objects via IFormatProvider.GetFormat, you ask for it by type. This mechanism is extremely extensible, because you can provide your own formatter types, and other types that you create that know how to consume them can ask a custom format provider for instances of them.
Suppose you want to convert a floating-point value into a string. The execution flow of the IFormattable.ToString implementation on System.Double follows these general steps:
The implementation gets a reference to an
IFormatProvidertype, which is either the one passed in or the one attached to the current thread if the one passed in isnull.It asks the format provider for an instance of the type
NumberFormatInfovia a call toIFormatProvider.GetFormat. The format provider initializes theNumberFormatInfoinstance's properties based on the culture it represents.It uses the
NumberFormatInfoinstance to format the number appropriately while creating a string representation of this based upon the specification of the format string.
The globalization capabilities of the .NET Framework have always been strong. However, there was room for improvement, and much of that improvement came with the .NET 2.0 Framework. Specifically, with .NET 1.1, it was always a painful process to introduce cultural information into the system if the framework didn't know the culture and region information. The .NET 2.0 Framework introduced a new class named CultureAndRegionInfoBuilder in the System.Globalization namespace.
Using CultureAndRegionInfoBuilder, you have the capability to define and introduce an entirely new culture and its region information into the system and register them for global usage as well. Similarly, you can modify preexisting culture and region information on the system. And if that's not enough flexibility for you, you can even serialize the information into a Locale Data Markup Language (LDML) file, which is a standard-based XML format. Once you register your new culture and region with the system, you can then create instances of CultureInfo and RegionInfo using the string-based name that you registered with the system.
When naming your new cultures, you should adhere to the standard format for naming cultures. The format is generally [prefix-]language[-region][-suffix[...]], where the language identifier is the only required part and the other pieces are optional. The prefix can be either of the following:
Additionally, the prefix portion can be in uppercase or lowercase. The language part is the lowercase two-letter code from the ISO 639-1 standard, while the region is a two-letter uppercase code from the ISO 3166 standard. For example, Russian spoken in Russia is ru-RU. The suffix component is used to further subidentify the culture based on some other data. For example, Serbian spoken in Serbia could be either sr-SP-Cyrl or sr-SP-Latn—one for the Cyrillic alphabet and the other for the Latin alphabet. If you define a culture specific to your division within your company, you could create it using the name x-en-US-MyCompany-WidgetDivision.
To see how easy it is to use the CultureAndRegionInfoBuilder object, let's create a fictitious culture based upon a preexisting culture. In the United States, the dominant measurement system is English units. Let's suppose that the United States decided to switch to the metric system at some point, and you now need to modify the culture information on some machines to match. Let's see what that code would look like:
using System;
using System.Globalization;
public class EntryPoint
{
static void Main() {
CultureAndRegionInfoBuilder cib = null;
cib = new CultureAndRegionInfoBuilder(
"x-en-US-metric",
CultureAndRegionModifiers.None );
cib.LoadDataFromCultureInfo( new CultureInfo("en-US") );
cib.LoadDataFromRegionInfo( new RegionInfo("US") );
// Make the change.
cib.IsMetric = true;
// Create an LDML file.
cib.Save( "x-en-US-metric.ldml" );
// Register with the system.
cib.Register();
}
}Note
In order to compile the previous example, you'll need to reference the sysglobl.dll assembly specifically. If you build it using the command line, you can use the following:
csc /r:sysglobl.dll example.cs
You can see that the process is simple, because the CultureAndRegionInfoBuilder has a well-designed interface. For illustration purposes, I've sent the LDML to a file so you can see what it looks like, although it's too verbose to list in this text. One thing to consider is that you must have proper permissions in order to call the Register method. This typically requires that you be an administrator, although you could get around that by adjusting the accessibility of the %WINDIR%Globalization directory and the HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCustomLocale registry key. Once you register the culture with the system, you can reference it using the given name when specifying any culture information in the CLR. For example, to verify that the culture and information region is registered properly, you can build and execute the following code to test it:
using System;
using System.Globalization;
public class EntryPoint
{
static void Main() {
RegionInfo ri = new RegionInfo("x-en-US-metric");
Console.WriteLine( ri.IsMetric );
}
}You must consider what the format string looks like. The built-in numeric objects use the standard numeric format strings or the custom numeric format strings defined by the .NET Framework, which you can find in the MSDN documentation by searching for "standard numeric format strings." The standard format strings are typically of the form Axx, where A is the desired format requested and xx is an optional precision specifier. Examples of format specifiers for numbers are "C" for currency, "D" for decimal, "E" for scientific notation, "F" for fixed-point notation, and "X" for hexadecimal notation. Every type also supports "G" for general, which is the default format specifier and is also the format that you get when you call Object.ToString, where you cannot specify a format string. If these format strings don't suit your needs, you can even use one of the custom format strings that allow you to describe what you'd like in a more-or-less picture format.
The point of this whole mechanism is that each type interprets and defines the format string specifically in the context of its own needs. In other words, System.Double is free to treat the G format specifier differently than the System.Int32 type. Moreover, your own type—say, type Employee—is free to implement a format string in whatever way it likes. For example, a format string of "SSN" could create a string based on the Social Security number of the employee.
Note
Allowing your own types to handle a format string of "DBG" is of even more utility, thus creating a detailed string that represents the internal state to send to a debug output log.
Let's take a look at some example code that exercises these concepts:
using System;
using System.Globalization;
using System.Windows.Forms;
public class EntryPoint
{
static void Main() {
CultureInfo current = CultureInfo.CurrentCulture;CultureInfo germany = new CultureInfo( "de-DE" );
CultureInfo russian = new CultureInfo( "ru-RU" );
double money = 123.45;
string localMoney = money.ToString( "C", current );
MessageBox.Show( localMoney, "Local Money" );
localMoney = money.ToString( "C", germany );
MessageBox.Show( localMoney, "German Money" );
localMoney = money.ToString( "C", russian );
MessageBox.Show( localMoney, "Russian Money" );
}
}In this example, I display the strings using the MessageBox type defined in System.Windows.Forms, because the console isn't good at displaying Unicode characters. The format specifier that I've chosen is "C" to display the number in a currency format. For the first display, I use the CultureInfo instance attached to the current thread. For the following two, I've created a CultureInfo for both Germany and Russia. Note that in forming the string, the System.Double type has used the CurrencyDecimalSeparator, CurrencyDecimalDigits, and CurrencySymbol properties, among others, of the NumberFormatInfo instance returned from the CultureInfo.GetFormat method. Had I displayed a DateTime instance, then the DateTime implementation of IFormattable.ToString would have utilized an instance of DateTimeFormatInfo returned from CultureInfo.GetFormat in a similar way.
Throughout this book, you've seen me using Console.WriteLine extensively in the examples. One of the forms of WriteLine that is useful and identical to some overloads of String.Format allows you to build a composite string by replacing format tags within a string with a variable number of parameters passed in. In practice, String.Format is similar to the printf family of functions in C and C++. However, it's much more flexible and safer, because it's based upon the .NET Framework string-formatting capabilities covered previously. Let's look at a quick example of string format usage:
using System;
using System.Globalization;
using System.Windows.Forms;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 3 ) {
Console.WriteLine( "Please provide 3 parameters" );
return;
}
string composite =
String.Format( "{0} + {1} = {2}",
args[0],
args[1],
args[2] );Console.WriteLine( composite );
}
}You can see that a placeholder is contained within curly braces and that the number within them is the index within the remaining arguments that should be substituted there. The String.Format method, as well as the Console.WriteLine method, has an overload that accepts a variable number of arguments to use as the replacement values. In this example, the String.Format method's implementation replaces each placeholder using the general formatting of the type that you can get via a call to the parameterless version of ToString on that type. If the argument being placed in this spot supports IFormattable, the IFormattable.ToString method is called on that argument with a null format specifier, which usually is the same as if you had supplied the "G", or general, format specifier. Incidentally, within the source string, if you need to insert actual curly braces that will show in the output, you must double them by putting in either {{ or }}.
The exact format of the replacement item is {index[,alignment][:formatString]}, where the items within square brackets are optional. The index value is a zero-based value used to reference one of the trailing parameters provided to the method. The alignment represents how wide the entry should be within the composite string. For example, if you set it to eight characters in width and the string is narrower than that, then the extra space is padded with spaces. Lastly, the formatString portion of the replacement item allows you to denote precisely what formatting to use for the item. The format string is the same style of string that you would have used if you were to call IFormattable.ToString on the instance itself, which I covered in the previous section. Unfortunately, you can't specify a particular IFormatProvider instance for each one of the replacement strings. Recall that the IFormatter.ToString method accepts an IFormatProvider, however, when using String.Format and the placeholder string as previously shown, String.Format simply passes null for the IFormatProvider when it calls IFormatter.ToString resulting in it utilizing the default formatters associated with the culture of the thread. If you need to create a composite string from items using multiple format providers or cultures, you must resort to using IFormattable.ToString directly.
Let's take a look at another example using the venerable Complex type that I've used throughout this book. This time, let's implement IFormattable on it to make it a little more useful when generating a string version of the instance:
using System;
using System.Text;
using System.Globalization;
public struct Complex : IFormattable
{
public Complex( double real, double imaginary ) {
this.real = real;
this.imaginary = imaginary;
}
// IFormattable implementation
public string ToString( string format,
IFormatProvider formatProvider ) {
StringBuilder sb = new StringBuilder();if( format == "DBG" ) {
// Generate debugging output for this object.
sb.Append( this.GetType().ToString() + "
" );
sb.AppendFormat( " real: {0}
", real );
sb.AppendFormat( " imaginary: {0}
", imaginary );
} else {
sb.Append( "( " );
sb.Append( real.ToString(format, formatProvider) );
sb.Append( " : " );
sb.Append( imaginary.ToString(format, formatProvider) );
sb.Append( " )" );
}
return sb.ToString();
}
private double real;
private double imaginary;
}
public class EntryPoint
{
static void Main() {
CultureInfo local = CultureInfo.CurrentCulture;
CultureInfo germany = new CultureInfo( "de-DE" );
Complex cpx = new Complex( 12.3456, 1234.56 );
string strCpx = cpx.ToString( "F", local );
Console.WriteLine( strCpx );
strCpx = cpx.ToString( "F", germany );
Console.WriteLine( strCpx );
Console.WriteLine( "
Debugging output:
{0:DBG}",
cpx );
}
}The real meat of this example lies within the implementation of IFormattable.ToString. I've implemented a "DBG" format string for this type that will create a string that shows the internal state of the object and may be useful for debug purposes. I'm sure you can think of a little more information to display to a debugger output log that is specific to the instance, but you get the idea. If the format string is not equal to "DBG", then you simply defer to the IFormattable implementation of System.Double. Notice my use of StringBuilder, which I cover in the later section of this chapter called "StringBuilder," to create the string that I eventually return. Also, I chose to use the Console.WriteLine method and its format item syntax to send the debugging output to the console just to show a little variety in usage.
ICustomFormatter is an interface that allows you to replace or extend a built-in or already existing IFormattable interface for an object. Whenever you call String.Format or StringBuilder.AppendFormat to convert an object instance to a string, before the method calls through to the object's implementation of IFormattable.ToString, or Object.ToString if it does not implement IFormattable, it first checks to see if the passed-in IFormatProvider provides a custom formatter. If it does, it calls IFormatProvider.GetFormat while passing a type of ICustomFormatter. If the formatter returns an implementation of ICustomFormatter, then the method will use the custom formatter. Otherwise, it will use the object's implementation of IFormattable.ToString or the object's implementation of Object.ToString in cases where it doesn't implement IFormattable.
Consider the following example where I've reworked the previous Complex example, but I've externalized the debugging output capabilities outside of the Complex struct. I've bolded the code that has changed:
using System; using System.Text; using System.Globalization;public class ComplexDbgFormatter : ICustomFormatter, IFormatProvider{// IFormatProvider implementationpublic object GetFormat( Type formatType ) {if( formatType == typeof(ICustomFormatter) ) {return this;} else {return CultureInfo.CurrentCulture.GetFormat( formatType );}}// ICustomFormatter implementationpublic string Format( string format,object arg,IFormatProvider formatProvider ) {if( arg.GetType() == typeof(Complex) &&format == "DBG" ) {Complex cpx = (Complex) arg;// Generate debugging output for this object.StringBuilder sb = new StringBuilder();sb.Append( arg.GetType().ToString() + " " );sb.AppendFormat( " real: {0} ", cpx.Real );sb.AppendFormat( " imaginary: {0} ", cpx.Imaginary );return sb.ToString();} else {IFormattable formattable = arg as IFormattable;if( formattable != null ) {return formattable.ToString( format, formatProvider );} else {return arg.ToString();}}}}
public struct Complex : IFormattable
{
public Complex( double real, double imaginary ) {
this.real = real;
this.imaginary = imaginary;
}
public double Real {
get { return real; }
}
public double Imaginary {
get { return imaginary; }
}
// IFormattable implementation
public string ToString( string format,
IFormatProvider formatProvider ) {
StringBuilder sb = new StringBuilder();
sb.Append( "( " );
sb.Append( real.ToString(format, formatProvider) );
sb.Append( " : " );
sb.Append( imaginary.ToString(format, formatProvider) );
sb.Append( " )" );
return sb.ToString();
}
private double real;
private double imaginary;
}
public class EntryPoint
{
static void Main() {
CultureInfo local = CultureInfo.CurrentCulture;
CultureInfo germany = new CultureInfo( "de-DE" );
Complex cpx = new Complex( 12.3456, 1234.56 );
string strCpx = cpx.ToString( "F", local );
Console.WriteLine( strCpx );
strCpx = cpx.ToString( "F", germany );
Console.WriteLine( strCpx );
ComplexDbgFormatter dbgFormatter =
new ComplexDbgFormatter();
strCpx = String.Format( dbgFormatter,
"{0:DBG}",cpx );Console.WriteLine( " Debugging output: {0}",strCpx );} }
Of course, this example is a bit more complex (no pun intended). But if you were not the original author of the Complex type, then this may be your only way to provide custom formatting for that type. Using this technique, you can provide custom formatting to any of the other built-in types in the system.
When it comes to comparing strings, the .NET Framework provides quite a bit of flexibility. You can compare strings based on cultural information as well as without cultural consideration. You can also compare strings using case sensitivity or not, and the rules for how to do case-insensitive comparisons vary from culture to culture. There are several ways to compare strings offered within the Framework, some of which are exposed directly on the System.String type through the static String.Compare method. You can choose from a few overloads, and the most basic of them use the CultureInfo attached to the current thread to handle comparisons.
You often need to compare strings, and you don't need to worry about, or want to carry, the overhead of culture-specific comparisons. A perfect example is when you're comparing internal string data from, say, a configuration file, or when you're comparing file directories. In the .NET 1.1 days, the main tool of choice was to use the String.Compare method while passing the InvariantCulture property. This works fine in most cases, but it still applies culture information to the comparison even though the culture information it uses is neutral to all cultures, and that is usually an unnecessary overhead for such comparisons. The .NET 2.0 Framework introduced a new enumeration, StringComparison, that allows you to choose a true nonculture-based comparison. The StringComparison enumeration looks like the following:
public enum StringComparison
{
CurrentCulture,
CurrentCultureIgnoreCase,
InvariantCulture,
InvariantCultureIgnoreCase,
Ordinal,
OrdinalIgnoreCase
}The last two items in the enumeration are the items of interest. An ordinal-based comparison is the most basic string comparison; it simply compares the character values of the two strings based on the numeric value of each character compared (i.e., it actually compares the raw binary values of each character). Doing comparisons this way removes all cultural bias from the comparisons and increases the efficiency tremendously. On my computer, I ran some crude timing loops to compare the two techniques when comparing strings of equal length. The speed increase was almost nine times faster. Of course, had the strings been more complex with more than just lowercase Latin characters in them, the gain would have been even higher.
The .NET 2.0 Framework introduced a new class called StringComparer that implements the IComparer interface. Things such as sorted collections can use StringComparer to manage the sort. With regards to locale support, the System.StringComparer type follows the same idiom as the IFormattable interface. You can use the StringComparer.CurrentCulture property to get a StringComparer instance specific to the culture of the current thread. Additionally, you can get the StringComparer instance from StringComparer.CurrentCultureIgnoreCase to do case-insensitive comparison. Also, you can get culture-invariant instances using the InvariantCulture and InvariantCultureIgnoreCase properties. Lastly, you can use the Ordinal and OrdinalIgnoreCase properties to get instances that compare based on ordinal string comparison rules.
As you may expect, if the culture information attached to the current thread isn't what you need, you can create StringComparer instances based upon explicit locales simply by calling the StringComparer.Create method and passing the desired CultureInfo representing the locale you want as well as a flag denoting whether you want a case-sensitive or case-insensitive comparer.
When choosing between the various comparison techniques, take care to choose the appropriate choice for the job. The general rule of thumb is to use the culture-specific or culture-invariant comparisons for any user-facing data—that is, data that will be presented to end users in some form or fashion—and ordinal comparisons otherwise. However, it's rare that you'd ever use InvariantCulture compared strings to display to users. Use the ordinal comparisons when dealing with data that is completely internal. In fact, ordinal-based comparisons render InvariantCulture comparisons almost useless.
Note
Prior to version 2.0 of the .NET Framework, it was a general guideline that if you were comparing strings to make a security decision, you should use InvariantCulture rather than base the comparison on CultureInfo.CurrentCulture. In such comparisons, you want a tightly controlled environment that you know will be the same in the field as it is in your test environment. If you base the comparison on CurrentCulture, this is impossible to achieve, because end users can change the culture on the machine and introduce a probably untested code path into the security decision, since it's almost impossible to test under all culture permutations.
Naturally, in .NET 2.0 and onward, it is recommended that you base these security comparisons on ordinal comparisons rather than InvariantCulture for added efficiency and safety.
Within the confines of the .NET Framework, all strings are represented using Unicode UTF-16 character arrays. However, you often might need to interface with the outside world using some other form of encoding, such as UTF-8. Sometimes, even when interfacing with other entities that use 16-bit Unicode strings, those entities may use big-endian Unicode strings, whereas the typical Intel platform uses little-endian Unicode strings. The .NET Framework makes this conversion work easy with the System.Text.Encoding class.
In this section, I won't go into all of the details of System.Text.Encoding, but I highly suggest that you reference the documentation for this class in the MSDN for all of the finer details. Let's take a look at a cursory example of how to convert to and from various encodings using the Encoding objects served up by the System.Text.Encoding class:
using System;
using System.Text;
public class EntryPoint
{static void Main() {
string leUnicodeStr =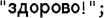 // "What's up!"
Encoding leUnicode = Encoding.Unicode;
Encoding beUnicode = Encoding.BigEndianUnicode;
Encoding utf8 = Encoding.UTF8;
byte[] leUnicodeBytes = leUnicode.GetBytes(leUnicodeStr);
byte[] beUnicodeBytes = Encoding.Convert( leUnicode,
beUnicode,
leUnicodeBytes);
byte[] utf8Bytes = Encoding.Convert( leUnicode,
utf8,
leUnicodeBytes );
Console.WriteLine( "Orig. String: {0}
", leUnicodeStr );
Console.WriteLine( "Little Endian Unicode Bytes:" );
StringBuilder sb = new StringBuilder();
foreach( byte b in leUnicodeBytes ) {
sb.Append( b ).Append(" : ");
}
Console.WriteLine( "{0}
", sb.ToString() );
Console.WriteLine( "Big Endian Unicode Bytes:" );
sb = new StringBuilder();
foreach( byte b in beUnicodeBytes ) {
sb.Append( b ).Append(" : ");
}
Console.WriteLine( "{0}
", sb.ToString() );
Console.WriteLine( "UTF Bytes: " );
sb = new StringBuilder();
foreach( byte b in utf8Bytes ) {
sb.Append( b ).Append(" : ");
}
Console.WriteLine( sb.ToString() );
}
}
// "What's up!"
Encoding leUnicode = Encoding.Unicode;
Encoding beUnicode = Encoding.BigEndianUnicode;
Encoding utf8 = Encoding.UTF8;
byte[] leUnicodeBytes = leUnicode.GetBytes(leUnicodeStr);
byte[] beUnicodeBytes = Encoding.Convert( leUnicode,
beUnicode,
leUnicodeBytes);
byte[] utf8Bytes = Encoding.Convert( leUnicode,
utf8,
leUnicodeBytes );
Console.WriteLine( "Orig. String: {0}
", leUnicodeStr );
Console.WriteLine( "Little Endian Unicode Bytes:" );
StringBuilder sb = new StringBuilder();
foreach( byte b in leUnicodeBytes ) {
sb.Append( b ).Append(" : ");
}
Console.WriteLine( "{0}
", sb.ToString() );
Console.WriteLine( "Big Endian Unicode Bytes:" );
sb = new StringBuilder();
foreach( byte b in beUnicodeBytes ) {
sb.Append( b ).Append(" : ");
}
Console.WriteLine( "{0}
", sb.ToString() );
Console.WriteLine( "UTF Bytes: " );
sb = new StringBuilder();
foreach( byte b in utf8Bytes ) {
sb.Append( b ).Append(" : ");
}
Console.WriteLine( sb.ToString() );
}
}The example first starts by creating a System.String with some Russian text in it. As mentioned, the string contains a Unicode string, but is it a big-endian or little-endian Unicode string? The answer depends on what platform you're running on. On an Intel system, it is normally little-endian. However, because you're not supposed to access the underlying byte representation of the string because it is encapsulated from you, it doesn't matter. In order to get the bytes of the string, you should use one of the Encoding objects that you can get from System.Text.Encoding. In my example, I get local references to the Encoding objects for handling little-endian Unicode, big-endian Unicode, and UTF-8. Once I have those, I can use them to convert the string into any byte representation that I want. As you can see, I get three representations of the same string and send the byte sequence values to standard output. In this example, because the text is based on the Cyrillic alphabet, the UTF-8 byte array is longer than the Unicode byte array. Had the original string been based on the Latin character set, the UTF-8 byte array would be shorter than the Unicode byte array usually by half. The point is, you should never make any assumption about the storage requirements for any of the encodings. If you need to know how much space is required to store the encoded string, call the Encoding.GetByteCount method to get that value.
Warning
Never make assumptions about the internal string representation format of the CLR. Nothing says that the internal representation cannot vary from one platform to the next. It would be unfortunate if your code made assumptions based upon an Intel platform and then failed to run on a Sun platform running the Mono CLR. Microsoft could even choose to run Windows on another platform one day, just as Apple has chosen to start using Intel processors. Also, just because Encoding.Unicode is not named Encoding.LittleEndianUnicode should not lead you to believe that the CLR forces all string data to be represented as little-endian internally. In fact, the CLI standard clearly states that for all data types greater than 1 byte in memory, the byte ordering of the data is dependent on the target platform.
Usually, you need to go the opposite way with the conversion and convert an array of bytes from the outside world into a string that the system can then manipulate easily. For example, the Bluetooth protocol stack uses big-endian Unicode strings to transfer string data. To convert the bytes into a System.String, use the GetString method on the encoder that you're using. You must also use the encoder that matches the source encoding of your data.
This brings up an important note to keep in mind. When passing string data to and from other systems in raw byte format, you must always know the encoding scheme used by the protocol you're using. Most importantly, you must always use that encoding's matching Encoding object to convert the byte array into a System.String, even if you know that the encoding in the protocol is the same as that used internally to System.String on the platform where you're building the application. Why? Suppose you're developing your application on an Intel platform and the protocol encoding is little-endian, which you know is the same as the platform encoding. So you take a shortcut and don't use the System.Text.Encoding.Unicode object to convert the bytes to the string. Later on, you decide to run the application on a platform that happens to use big-endian strings internally. You'll be in for a big surprise when the application starts to crumble because you falsely assumed what encoding System.String uses internally. Efficiency is not a problem if you always use the encoder, because on platforms where the internal encoding is the same as the external encoding, the conversion will essentially boil down to nothing.
In the previous example, you saw use of the StringBuilder class in order to send the array of bytes to the console. Let's now take a look at what the StringBuilder type is all about.
System.String objects are immutable; therefore, they create efficiency bottlenecks when you're trying to build strings on the fly. You can create composite strings using the + operator as follows:
string space = " "; string compound = "Vote" + space + "for" + space + "Pedro";
However, this method isn't efficient, because this code creates several strings to get the job done. Creating all those intermediate strings could increase memory pressure. Although this line of code is rather contrived, you can imagine that the efficiency of a complex system that does lots of string manipulation can quickly go downhill due to memory usage. Consider a case where you implement a custom base64 encoder that appends characters incrementally as it processes a binary file. The .NET library already offers this functionality in the System.Convert class, but let's ignore that for the sake of this example. If you repeatedly used the + operator in a loop to create a large base64 string, your performance would quickly degrade as the source data increased in size. For these situations, you can use the System.Text.StringBuilder class, which implements a mutable string specifically for building composite strings efficiently.
I won't go over each of the methods of StringBuilder in detail, because you can get all the details of each method within the MSDN documentation. However, I'll cover more of the salient points of note. StringBuilder internally maintains an array of characters that it manages dynamically. The workhorse methods of StringBuilder are Append, Insert, and AppendFormat. If you look up the methods in the MSDN, you'll see that they are richly overloaded in order to support appending and inserting string forms of the many common types. When you create a StringBuilder instance, you have various constructors to choose from. The default constructor creates a new StringBuilder instance with the system-defined default capacity. However, that capacity doesn't constrain the size of the string that it can create. Rather, it represents the amount of string data the StringBuilder can hold before it needs to grow the internal buffer and increase the capacity. If you know a ballpark figure of how big your string will likely end up being, you can give the StringBuilder that number in one of the constructor overloads, and it will initialize the buffer accordingly. This could help the StringBuilder instance from having to reallocate the buffer too often while you fill it.
You can also define the maximum-capacity property in the constructor overloads. By default, the maximum capacity is System.Int32.MaxValue, which is currently 2,147,483,647, but that exact value is subject to change as the system evolves. If you need to protect your StringBuilder buffer from growing over a certain size, you may provide an alternate maximum capacity in one of the constructor overloads. If an append or insert operation forces the need for the buffer to grow greater than the maximum capacity, an ArgumentOutOfRangeException is thrown.
For convenience, all of the methods that append and insert data into a StringBuilder instance return a reference to this. Thus, you can chain operations on a single string builder as shown:
using System;
using System.Text;
public class EntryPoint
{
static void Main() {
StringBuilder sb = new StringBuilder();
sb.Append("StringBuilder ").Append("is ")
.Append("very... ");
string built1 = sb.ToString();
sb.Append("cool");
string built2 = sb.ToString();
Console.WriteLine( built1 );
Console.WriteLine( built2 );
}
}In this example, you can see that I converted the StringBuilder instance sb into a new System.String instance named built1 by calling sb.ToString. For maximum efficiency, the StringBuilder simply hands off a reference to the underlying string so that a copy is not necessary. If you think about it, part of the utility of StringBuilder would be compromised if it didn't do it this way. After all, if you create a huge string—say, some megabytes in size, such as a base64-encoded large image—you don't want that data to be copied in order to create a string from it. However, once you call StringBuilder.ToString, you now have the string variable and the StringBuilder holding references to the same string. Because string is immutable, StringBuilder then switches to using a copy-on-write idiom with the underlying string. Therefore, at the place where I append to the StringBuilder after having assigned the built1 variable, the StringBuilder must make a new copy of the internal string. It's important for you to keep this behavior in mind if you're using StringBuilder to work with large string data.
The System.String type itself offers some rudimentary searching methods, such as IndexOf, IndexOfAny, LastIndexOf, LastIndexOfAny, and StartsWith. Using these methods, you can determine if a string contains certain substrings and where. However, these methods quickly become cumbersome and are a bit too primitive to do any complex searching of strings effectively. Thankfully, the .NET Framework library contains classes that implement regular expressions (regex). If you're not already familiar with regular expressions, I strongly suggest that you learn the regular-expression syntax and how to use it effectively. The regular-expression syntax is a language in and of itself. Excellent sources of information on the syntax include Mastering Regular Expressions, Third Edition, Jeffrey E. F. Friedl (Sebastopol, CA: O'Reilly Media, 2006) and the material under "Regular Expression Language Elements" within the MSDN documentation. The capabilities of the .NET regular-expression engine are on par with those of Perl 5 and Python. Full coverage of the capabilities of regular expressions with regard to their syntax is beyond the scope of this book. However, I'll describe the ways to use regular expressions that are specific to the .NET Framework.
There are really three main types of operations for which you employ regular expressions. The first is when searching a string just to verify that it contains a specific pattern, and if so, where. The search pattern can be extremely complex. The second is similar to the first, except, in the process, you save off parts of the searched expression. For example, if you search a string for a date in a specific format, you may choose to break the three parts of the date into individual variables. Finally, regular expressions are often used for search-and-replace operations. This type of operation builds upon the capabilities of the previous two. Let's take a look at how to achieve these three goals using the .NET Framework's implementation of regular expressions.
As with the System.String class itself, most of the objects created from the regular expression classes are immutable. The workhorse class at the bottom of it all is the Regex class, which lives in the System.Text.RegularExpressions namespace. One of the general patterns of usage is to create a Regex instance to represent your regular expression by passing it a string of the pattern to search for. You then apply it to a string to find out if any matches exist. The results of the search will include whether a match was found, and if so, where. You can also find out where all subsequent instances of the match occur within the searched string. Let's go ahead and look at an example of what a basic Regex search looks like and then dig into more useful ways to use Regex:
using System;
using System.Text.RegularExpressions;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );return;
}
// Create regex to search for IP address pattern.
string pattern = @"dd?d?.dd?d?.dd?d?.dd?d?";
Regex regex = new Regex( pattern );
Match match = regex.Match( args[0] );
while( match.Success ) {
Console.WriteLine( "IP Address found at {0} with " +
"value of {1}",
match.Index,
match.Value );
match = match.NextMatch();
}
}
}This example searches a string provided on the command line for an IP address. The search is crude, but I'll refine it a bit as I continue. Regular expressions can consist of literal characters to search for, as well as escaped characters that carry a special meaning. The familiar backslash is the method used to escape characters in a regular expression. In this example, d means a numeric digit. The ones that are suffixed with a ? mean that there can be one or zero occurrences of the previous character or escaped expression. Notice that the period is escaped, because the period by itself carries a special meaning: An unescaped period matches any character in that position of the match. Lastly, you'll see that it is much easier to use the verbatim string syntax when declaring regular expressions in order to avoid the gratuitous proliferation of backslashes. If you were to invoke the previous example passing the following quoted string on the command line
"This is an IP address:123.123.1.123"
the output would look like the following:
IP Address found at 22 with value of 123.123.1.123
The previous example creates a new Regex instance named regex and then, using the Match method, applies the pattern to the given string. The results of the match are stored in the match variable. That match variable represents the first match within the searched string. You can use the Match.Success property to determine if the regex found anything at all. Next, you see the code using the Index and Value properties to find out more about the match. Lastly, you can go to the next match in the searched string by calling the Match.NextMatch method, and you can iterate through this chain until you find no more matches in the searched string.
Alternatively, instead of calling Match.NextMatch in a loop, you can call the Regex.Matches method to retrieve a MatchCollection that gives you all of the matches at once rather than one at a time. Also, all of the examples using Regex in this chapter are calling instance methods on a Regex instance. Many of the methods on Regex, such as Match and Replace, also offer static versions where you don't have to create a Regex instance first and you can just pass the regular expression pattern in the method call.
From looking at the previous match, really all that is happening is that the pattern is looking for a series of four groups of digits separated by periods, where each group can be from one to three digits in length. The reason I say this is a crude search is that it will match an invalid IP address such as 999.888.777.666. A better search for the IP address would look like the following:
using System;
using System.Text.RegularExpressions;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );
return;
}
// Create regex to search for IP address pattern.
string pattern = @"([01]?dd?|2[0-4]d|25[0-5])." +
@"([01]?dd?|2[0-4]d|25[0-5])." +
@"([01]?dd?|2[0-4]d|25[0-5])." +
@"([01]?dd?|2[0-4]d|25[0-5])";
Regex regex = new Regex( pattern );
Match match = regex.Match( args[0] );
while( match.Success ) {
Console.WriteLine( "IP Address found at {0} with " +
"value of {1}",
match.Index,
match.Value );
match = match.NextMatch();
}
}
}Essentially, four groupings of the same search pattern [01]?dd?|2[0-4]d|25[0-5] are separated by periods, which of course, are escaped in the preceding regular expression. Each one of these subexpressions matches a number between 0 and 255.[26] This entire expression for searching for regular expressions is better, but still not perfect. However, you can see that it's getting closer, and with a little more fine-tuning, you can use it to validate the IP address given in a string. Thus, you can use regular expressions to effectively validate input from users to make sure that it matches a certain form. For example, you may have a web server that expects US telephone numbers to be entered in a pattern such as (xxx) xxx-xxxx. Regular expressions allow you to easily validate that the user has input the number correctly.
You may have noticed the addition of parentheses in the IP address search expression in the previous example. Parentheses are used to define groups that group subexpressions within regular expressions into discrete chunks. Groups can contain other groups as well. Therefore, the IP address regular-expression pattern in the previous example forms a group around each part of the IP address. In addition, you can access each individual group within the match. Consider the following modified version of the previous example:
using System;
using System.Text.RegularExpressions;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );
return;
}
// Create regex to search for IP address pattern.
string pattern = @"([01]?dd?|2[0-4]d|25[0-5])." +
@"([01]?dd?|2[0-4]d|25[0-5]) " +
@"([01]?dd?|2[0-4]d|25[0-5]) " +
@"([01]?dd?|2[0-4]d|25[0-5])";
Regex regex = new Regex( pattern );
Match match = regex.Match( args[0] );
while( match.Success ) {
Console.WriteLine( "IP Address found at {0} with " +
"value of {1}",
match.Index,
match.Value );
Console.WriteLine( "Groups are:" );
foreach( Group g in match.Groups ) {
Console.WriteLine( " {0} at {1}",
g.Value,
g.Index );
}
match = match.NextMatch();
}
}
}Within each match, I've added a loop that iterates through the individual groups within the match. As you'd expect, there will be at least four groups in the collection, one for each portion of the IP address. In fact, there is also a fifth item in the group—the entire match. So, one of the groups within the groups collection returned from Match.Groups will always contain the entire match itself. Given the following input to the previous example
"This is an IP address:123.123.1.123"
the result would look like the following:
IP Address found at 22 with value of 123.123.1.123
Groups are:
123.123.1.123 at 22
123 at 22
123 at 26
1 at 30123 at 32
Groups provide an excellent means of picking portions out of a given input string. For example, at the same time that you validate that a user has input a phone number of the required format, you could also capture the area code into a group for use later. Collecting substrings of a match into groups is handy. But what's even handier is being able to give those groups a name. Check out the following modified example:
using System;
using System.Text.RegularExpressions;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );
return;
}
// Create regex to search for IP address pattern.
string pattern = @"(?<part1>[01]?dd?|2[0-4]d|25[0-5])." +
@"(?<part2>[01]?dd?|2[0-4]d|25[0-5])." +
@"(?<part3>[01]?dd?|2[0-4]d|25[0-5])." +
@"(?<part4>[01]?dd?|2[0-4]d|25[0-5]) ";
Regex regex = new Regex( pattern );
Match match = regex.Match( args[0] );
while( match.Success ) {
Console.WriteLine( "IP Address found at {0} with " +
"value of {1}",
match.Index,
match.Value );
Console.WriteLine( "Groups are:" );
Console.WriteLine( " Part 1: {0}",
match.Groups["part1"] );
Console.WriteLine( " Part 2: {0}",
match.Groups["part2"] );Console.WriteLine( " Part 3: {0}",match.Groups["part3"] );Console.WriteLine( " Part 4: {0}",match.Groups["part4"] );match = match.NextMatch(); } } }
In this variation, I've captured each part into a group with a name, and when I send the result to the console, I access the group by name through an indexer on the GroupCollection returned by Match.Groups that accepts a string argument.
With the ability to name groups comes the ability to back-reference groups within searches. For example, if you're looking for an exact repeat of a previous match, you can reference a previous group in what's called a back-reference by including k<name>, where name is the name of the group to back-reference. For example, consider the following example that looks for IP addresses where all four parts are the same:
using System;
using System.Text.RegularExpressions;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );
return;
}
// Create regex to search for IP address pattern.
string pattern = @"(?<part1>[01]?dd?|2[0-4]d|25[0-5])." +
@"k<part1>." +
@"k<part1>." +
@"k<part1>";
Regex regex = new Regex( pattern );
Match match = regex.Match( args[0] );
while( match.Success ) {
Console.WriteLine( "IP Address found at {0} with " +
"value of {1}",
match.Index,
match.Value );
match = match.NextMatch();
}
}
}The following output shows the results of running this code on the string "My IP address is 123.123.123.123":
IP Address found at 17 with value of 123.123.123.123
If you've ever used Perl to do any text processing, you know that the regular-expression engine within it is indispensable. But one of the greatest powers within Perl is the regular-expression text-substitution capabilities. You can do the same thing using .NET regular expressions via the Regex.Replace method overloads. Suppose that you want to process a string looking for an IP address that a user input, and you want to display the string. However, for security reasons, you want to replace the IP address with xxx.xxx.xxx.xxx. You could achieve this goal, as in the following example:
using System;
using System.Text.RegularExpressions;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );
return;
}
// Create regex to search for IP address pattern.
string pattern = @"([01]?dd?|2[0-4]d|25[0-5])." +
@"([01]?dd?|2[0-4]d|25[0-5])." +
@"([01]?dd?|2[0-4]d|25[0-5])." +
@"([01]?dd?|2[0-4]d|25[0-5])";
Regex regex = new Regex( pattern );
Console.WriteLine( "Input given -> {0}",
regex.Replace(args[0],
"xxx.xxx.xxx.xxx") );
}
}Thus, given the following input
"This is an IP address:123.123.123.123"
the output would look like the following:
Input given -> This is an IP address:xxx.xxx.xxx.xxx
Of course, when you find a match within a string, you may want to replace it with something that depends on what the match is. The previous example simply replaces each match with a static string. In order to replace based on the match instance, you can create an instance of the MatchEvaluator delegate and pass it to the Regex.Replace method. Then, whenever it finds a match, it calls through to the MatchEvaluator delegate instance given while passing it the match. Thus, the delegate can create the replacement string based upon the actual match. The MatchEvaluator delegate has the following signature:
public delegate string MatchEvaluator( Match match );
Suppose you want to reverse the individual parts of an IP address. Then you could use a MatchEvaluator coupled with Regex.Replace to get the job done, as in the following example:
using System;using System.Text;using System.Text.RegularExpressions; public class EntryPoint { static void Main( string[] args ) { if( args.Length < 1 ) { Console.WriteLine( "You must provide a string." ); return; } // Create regex to search for IP address pattern.string pattern = @"(?<part1>[01]?dd?|2[0-4]d|25[0-5])." +@"(?<part2>[01]?dd?|2[0-4]d|25[0-5])." +@"(?<part3>[01]?dd?|2[0-4]d|25[0-5])." +@"(?<part4>[01]?dd?|2[0-4]d|25[0-5])";Regex regex = new Regex( pattern );MatchEvaluator eval = new MatchEvaluator(EntryPoint.IPReverse );Console.WriteLine( regex.Replace(args[0],eval) );}static string IPReverse( Match match ) {StringBuilder sb = new StringBuilder();sb.Append( match.Groups["part4"] + "." );sb.Append( match.Groups["part3"] + "." );sb.Append( match.Groups["part2"] + "." );sb.Append( match.Groups["part1"] );return sb.ToString();}}
Whenever a match is found, the delegate is called to determine what the replacement string should be. However, because all you're doing is changing the order, the job is not too complex for what are called regular-expression substitutions. If, in the example prior to this one, you had chosen to use the overload of Replace that doesn't use a MatchEvaluator delegate, you could have achieved the same result, because the regex lets you reference the group variables in the replacement string. To reference one of the named groups, you can use the syntax shown in the following example:
using System; using System.Text; using System.Text.RegularExpressions; public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );
return;
}
// Create regex to search for IP address pattern.
string pattern = @"(?<part1>[01]?dd?|2[0-4]d|25[0-5])." +
@"(?<part2>[01]?dd?|2[0-4]d|25[0-5])." +
@"(?<part3>[01]?dd?|2[0-4]d|25[0-5])." +
@"(?<part4>[01]?dd?|2[0-4]d|25[0-5])";
Regex regex = new Regex( pattern );
Match match = regex.Match( args[0] );
string replace = @"${part4}.${part3}.${part2}.${part1}" +
@" (the reverse of $&)";
Console.WriteLine( regex.Replace(args[0],
replace) );
}
}To include one of the named groups, simply use the ${name} syntax, where name is the name of the group. You can also see that I reference the full text of the match using $&. Other substitutions strings are available, such as $`, which substitutes the part of the input string prior to and up to the match, and $', which substitutes all text after the match. Others are documented in the MSDN documentation.
As you can imagine, you can craft complex string-replacement capabilities using the regular-expression implementation within .NET Framework just as you can using Perl.
One of the constructor overloads of a Regex allows you to pass various options of type RegexOptions during creation of a Regex instance. Likewise, the methods on Regex, such as Match and Replace, have a static overload allowing you to pass RegexOptions flags. I'll discuss some of the more commonly used options in this section, but for a description of all of the options and their behavior, consult the RegexOptions documentation within the MSDN.
By default, regular expressions are interpreted at run time. Complex regular expressions can chew up quite a bit of processor time while the regex engine is processing them. For times like these, consider using the Compiled option. This option causes the regular expression to be represented internally by IL code that is JIT-compiled. This increases the latency for the first use of the regular expression, but if it's used often, it will pay off in the end. Also, don't forget that JIT-compiled code increases the working set of the application.
Many times, you'll find it useful to do case-insensitive searches. You could accommodate that in the regular-expression pattern, but it makes your pattern much more difficult to read. It's much easier to pass the IgnoreCase flag when creating the Regex instance. When you use this flag, the Regex engine will also take into account any culture-specific, case-sensitivity issues by referencing the CultureInfo attached to the current thread. If you want to do case-insensitive searches in a culture-invariant way, combine the IgnoreCase flag with the CultureInvariant flag.
The IgnorePatternWhitespace flag is also useful for complex regular expressions. This flag tells the regex engine to ignore any white space within the match expression and to ignore any comments on lines following the # character. This provides a nifty way to comment regular expressions that are really complex. For example, check out the IP address search from the previous example rewritten using IgnorePatternWhitespace:
using System;
using System.Text.RegularExpressions;
public class EntryPoint
{
static void Main( string[] args ) {
if( args.Length < 1 ) {
Console.WriteLine( "You must provide a string." );
return;
}
// Create regex to search for IP address pattern.
string pattern = @"
# First part match
([01]?dd? # At least one digit,
# possibly prepended by 0 or 1
# and possibly followed by another digit
# OR
|2[0-4]d # Starts with a 2, after a number from 0-4
# and then any digit
# OR
|25[0-5]) # 25 followed by a number from 0-5
. # The whole group is followed by a period.
# REPEAT
([01]?dd?|2[0-4]d|25[0-5]).
# REPEAT
([01]?dd?|2[0-4]d|25[0-5]).
# REPEAT
([01]?dd?|2[0-4]d|25[0-5])
";
Regex regex = new Regex( pattern,
RegexOptions.IgnorePatternWhitespace );
Match match = regex.Match( args[0] );
while( match.Success ) {
Console.WriteLine( "IP Address found at {0} with " +
"value of {1}",
match.Index,
match.Value );
match = match.NextMatch();
}
}
}Notice how expressive you can be in the comments of your regular expression. Indeed, given how complex regular expressions can become, this is never a bad thing.
In this chapter, I've touched the tip of the iceberg on the string-handling capabilities of the .NET Framework and C#. Because the string type is such a widely used type, rather than merely include it in the base class library, the CLR designers chose to annex it into the set of built-in types. This is a good thing considering how common string usage is. Furthermore, the library provides a thorough implementation of cultural-specific patterns, via CultureInfo, that you typically need when creating global software that deals with strings heavily.
I showed how you can create your own cultures easily using the CultureAndRegionInfoBuilder class. Essentially, any software that interacts directly with the user and is meant to be used on a global basis needs to be prepared to service locale-specific needs. Finally, I gave a brief tour of the regular-expression capabilities of the .NET Framework, even though a full treatment of the regular-expression language is outside the scope of this book. I think you'll agree that the string and text-handling facilities built into the CLR, the .NET Framework, and the C# language are well-designed and easy to use.
In Chapter 9, I cover arrays and other, more versatile, collection types in the .NET Framework. Also, I spend a fair amount of time covering the new support for iterators in C#.
[25] For more information regarding the Unicode standard, visit www.unicode.org.
[26] Breaking down the specifics of how this regular expression works is beyond the scope of this book. I encourage you to reference one of the many fine resources in print or on the Internet detailing the grammar of regular expressions.