
Delegates provide a built-in, language-supported mechanism for defining and executing callbacks. Their flexibility allows you to define the exact signature of the callback, and that information becomes part of the delegate type. Anonymous functions are forms of delegates that allow you to shortcut some of the delegate syntax that, in many cases, is overkill and mundane[35]. Building on top of delegates is the support for events in C# and the .NET platform. Events provide a uniform pattern for hooking up callback implementations—and possibly multiple instances thereof—to the code that triggers the callback.
The CLR provides a runtime that explicitly supports a flexible callback mechanism. From the beginning of time, or at least from the beginning of Windows time, there has always been the need for a callback function that the system, or some other entity, calls at specific times to notify you of something interesting. After all, callbacks provide a convenient mechanism whereby users can extend functionality of a component. Even the most basic component of a Win32 GUI application—the window procedure—is a callback function that is registered with the system. The system calls the function any time it needs to notify you that a message for the window has arrived. This mechanism works just fine in a C-based programming environment.
Things became a little trickier with the widespread use of object-oriented languages such as C++. Developers immediately wanted the system to be able to call back into instance methods on objects rather than global functions or static methods. Many solutions to this problem exist. But no matter which solution you use, the bottom line is that somewhere, someone must store an instance pointer to the object and call the instance method through that instance pointer. Implementations typically consist of a thunk, which is nothing more than an adapter, such as an intermediate block of data or code that calls the instance method through the instance pointer[36]. This thunk is the actual function registered with the system. Many creative thunk solutions have been developed in C++ over the years. Your trusty author can recall many iterations of such designs with sentimental fondness.
Delegates are the preferred method of implementing callbacks in the CLR. I find it helpful to imagine a delegate as simply a glorified pointer to a function, and that function can be either a static method or an instance method. A delegate instance is exactly the same as a thunk, but at the same time it is a first-class citizen of the CLR. In fact, when you declare a delegate in your code, the C# compiler generates a class derived from MulticastDelegate, and the CLR implements all the interesting methods of the delegate dynamically at run time. That's why you won't see any IL code behind those delegate methods if you examine the compiled module with ILDASM.
The delegate contains a couple of useful fields. The first one holds a reference to an object, and the second holds a method pointer. When you invoke the delegate, the instance method is called on the contained object reference. However, if the object reference is null, the runtime understands that the method is a static method. One delegate type can handle callbacks to either an instance or a static method. Moreover, invoking a delegate syntactically is the same as calling a regular function. Therefore, delegates are perfect for implementing callbacks.
As you can see, delegates provide an excellent mechanism to decouple the method being called from the actual caller. In fact, the caller of the delegate has no idea (or necessity to know) whether it is calling an instance method or a static method, or on what exact instance it is calling. To the caller, it is calling arbitrary code. The caller can obtain the delegate instance through any appropriate means, and it can be decoupled completely from the entity it actually calls. Think for a moment about UI elements in a dialog, such as a Commit button, and how many external parties might be interested in knowing when that button is selected. If the class that represents the button must call directly to the interested parties, it needs to have intimate knowledge of the layout of those parties, or objects, and it must know which method to call on each one of them. Clearly, this requirement adds way too much coupling between the button class and the interested parties, and with coupling come complexity and code maintenance nightmares. Delegates come to the rescue and break this link. Now, interested parties only need to register a delegate with the button, and that delegate is preconfigured to call whatever method they want. This decoupling mechanism describes events as supported by the CLR. I have more to say about CLR events later in this chapter in the "Events" section. Let's go ahead and see how to create and use delegates in C#.
Delegate declarations look almost exactly like abstract method declarations, except they have one added keyword: the delegate keyword. The following is a valid delegate declaration:
public delegate double ProcessResults( double x, double y );
When the C# compiler encounters this line, it defines a type derived from MulticastDelegate, which also implements a method named Invoke that has exactly the same signature as the method described in the delegate declaration. For all practical purposes, that class looks like the following:
public class ProcessResults : System.MulticastDelegate
{
public double Invoke( double x, double y );
// Other stuff omitted for clarity
}Even though the compiler creates a type similar to that listed, the compiler also abstracts the use of delegates behind syntactical shortcuts. Typically, you use a syntax that looks similar to a function call to invoke the delegate rather than call Invoke directly, which I'll show shortly.
When you instantiate an instance of a delegate, you must wire it up to a method to call when it is invoked. The method that you wire it up to could be either a static or an instance method that has a signature compatible with that of the delegate. Thus, the parameter types and the return type must either match the delegate declaration or be implicitly convertible to the types in the delegate declaration.
Note
In .NET 1.x, the signature of the methods wired up to delegates had to match the delegate declaration exactly. In .NET 2.0, this requirement was relaxed to allow methods with compatible types in the declaration.
The following example shows the basic syntax of how to create a delegate:
using System;
public delegate double ProcessResults( double x,
double y );
public class Processor
{
public Processor( double factor ) {
this.factor = factor;
}
public double Compute( double x, double y ) {
double result = (x+y)*factor;
Console.WriteLine( "InstanceResults: {0}", result );
return result;
}
public static double StaticCompute( double x,
double y ) {
double result = (x+y)*0.5;
Console.WriteLine( "StaticResult: {0}", result );
return result;
}
private double factor;
}
public class EntryPoint
{
static void Main() {
Processor proc1 = new Processor( 0.75 );
Processor proc2 = new Processor( 0.83 );
ProcessResults delegate1 = new ProcessResults( proc1.Compute );
ProcessResults delegate2 = new ProcessResults( proc2.Compute );
ProcessResults delegate3 = Processor.StaticCompute;double combined = delegate1( 4, 5 ) +
delegate2( 6, 2 ) +
delegate3( 5, 2 );
Console.WriteLine( "Output: {0}", combined );
}
}In this example, I've created three delegates. Two of them point to instance methods, and one points to a static method. Notice that the first two delegates are created by creating instances of the ProcessResults type, which is the type created by the delegate declaration, and passing the target method in the constructor argument list. However, the delegate3 instance uses an abbreviated syntax where I simply assign the method to the delegate instance. Although it looks like Processor.StaticCompute is simply the name of the method, it's actually called a method group because the method could be overloaded and this name could refer to a group of methods. In this case, the method group Processor.StaticCompute has one method in it. And to make life easier, C# allows you to directly assign a delegate from a method group. When you create the delegate instances via new, you pass the method group in the constructor. Take note of the format of the method groups. In the first two cases, you pass an instance method on the proc1 and proc2 instances. However, in the third case, you pass a method group on the type rather than an instance. This is the way you create a delegate that points to a static method rather than an instance method. You could have just as well assigned an instance method group to delegate3 too. At the point where the delegates are called, the syntax is identical and independent of whether the delegate points to an instance method or a static method. Of course, this example is rather contrived, but it gives a clear indication of the basic usage of delegates within C#.
In all the cases in the previous code, a single action takes place when the delegate is called. It is possible to chain delegates together so that multiple actions take place and we will investigate this in the next section.
Delegate chaining allows you to create a linked list of delegates such that when the delegate at the head of the list is called, all the delegates in the chain are called. The System.Delegate class provides a few static methods to manage lists of delegates. To create delegate lists, you ultimately rely on the following methods declared inside of the System.Delegate type:
public class Delegate : ICloneable, ISerializable
{
public static Delegate Combine( Delegate[] );
public static Delegate Combine( Delegate first, Delegate second );
}Notice that the Combine methods take the delegates to combine and return another Delegate. The Delegate returned is a new instance of a MulticastDelegate, which derives from Delegate, because Delegate instances are immutable.
Notice that the first version of Combine listed previously takes an array of delegates to form the constituents of the new delegate list, and the second form takes just a pair of delegates. However, in both cases, any one of the Delegate instances could itself already be a delegate chain. So, you can see that some fairly complex nesting can take place here.
To remove delegates from a list, you ultimately rely upon the following two static methods on System.Delegate:
public class Delegate : IClonable, ISerializable
{
public static Delegate Remove( Delegate source, Delegate value );
public static Delegate RemoveAll( Delegate source, Delegate value );
}As with the Combine methods, the Remove and RemoveAll methods return a new Delegate instance created from the previous two. The Remove method removes the last occurrence of the invocation list represented by the parameter value from the source delegate list, whereas RemoveAll removes all occurrences of the invocation list represented by the parameter value from the source delegate list. Notice that I said that the value parameter can represent a delegate list rather than just a single delegate. Again, these methods have the capability to meet any complex delegate list management needs.
If the preceding methods seem cumbersome, C# overloads operators for combining and removing delegates from a chain. To combine two delegates or delegate lists, simply use the addition operator; and to remove a delegate or delegate list from a chain, use the subtraction operator. Let's look at a modified form of the code example in the last section to see how you can combine the delegates:
using System;
public delegate double ProcessResults( double x,
double y );
public class Processor
{
public Processor( double factor ) {
this.factor = factor;
}
public double Compute( double x, double y ) {
double result = (x+y)*factor;
Console.WriteLine( "InstanceResults: {0}", result );
return result;
}
public static double StaticCompute( double x,
double y ) {
double result = (x+y)*0.5;
Console.WriteLine( "StaticResult: {0}", result );
return result;
}
private double factor;
}
public class EntryPoint
{
static void Main() {
Processor proc1 = new Processor( 0.75 );
Processor proc2 = new Processor( 0.83 );
ProcessResults[] delegates = new ProcessResults[] {
proc1.Compute,
proc2.Compute,Processor.StaticCompute
};
// Chain the delegates now.
ProcessResults chained = delegates[0] +
delegates[1] +
delegates[2];
double combined = chained( 4, 5 );
Console.WriteLine( "Output: {0}", combined );
}
}Notice that instead of calling all the delegates, this example chains them together and then calls them by calling through the head of the chain. This example features some major differences from the previous example, which I have listed as follows:
The resultant
doublethat comes out of the chained invocation is the result of the last delegate called, which, in this case, is the delegate pointing to the static methodStaticCompute. The return values from the other delegates in the chain are simply lost.If any of the delegates throws an exception, processing of the delegate chain will terminate, and the CLR will begin to search for the next exception-handling frame on the stack.
Finally, be aware that if you declare delegates that take parameters by reference, each delegate that uses the reference parameter will see the changes made by the previous delegate in the chain. This could be a desired effect or it could be a surprise, depending on what your intentions are.
Sometimes you have to call a chain of delegates, but you need to harvest the return values from each invocation, or you might need to specify the ordering of the calls in the chain. For these times, the System.Delegate type, from which all delegates derive, offers the GetInvocationList method to acquire an array of delegates in which each element in the array corresponds to a delegate in the invocation list. Once you obtain this array, you can call the delegates in any order you please and you can process the return value from each delegate appropriately. You could also put an exception frame around each entry in the list so that an exception in one delegate invocation will not abort the remaining invocations. This modified version of the previous example shows how to call each delegate in the chain explicitly:
using System;
public delegate double ProcessResults( double x,
double y );
public class Processor
{
public Processor( double factor ) {
this.factor = factor;}
public double Compute( double x, double y ) {
double result = (x+y)*factor;
Console.WriteLine( "InstanceResults: {0}", result );
return result;
}
public static double StaticCompute( double x,
double y ) {
double result = (x+y)*0.5;
Console.WriteLine( "StaticResult: {0}", result );
return result;
}
private double factor;
}
public class EntryPoint
{
static void Main() {
Processor proc1 = new Processor( 0.75 );
Processor proc2 = new Processor( 0.83 );
ProcessResults[] delegates = new ProcessResults[] {
proc1.Compute,
proc2.Compute,
Processor.StaticCompute
};
ProcessResults chained = delegates[0] +
delegates[1] +
delegates[2];
Delegate[] chain = chained.GetInvocationList();
double accumulator = 0;
for( int i = 0; i < chain.Length; ++i ) {
ProcessResults current = (ProcessResults) chain[i];
accumulator += current( 4, 5 );
}
Console.WriteLine( "Output: {0}", accumulator );
}
}All the delegate examples so far show how to wire up a delegate to a static method on a specific type or to an instance method on a specific instance. This abstraction provides excellent decoupling, but the delegate doesn't really imitate or represent a pointer to a method per se because it is bound to a method on a specific instance. What if you want to have a delegate represent an instance method and then you want to invoke that same instance method, via the delegate, on a collection of instances?
For this task, you need to use an open instance delegate. When you call a method on an instance, there is a hidden parameter at the beginning of the parameter list known as this, which represents the current instance.[37] When you wire up a closed instance delegate to an instance method on an object instance, the delegate passes the object instance as the this reference when it calls the instance method. With open instance delegates, the delegate defers this action to whatever invokes the delegate. Thus, you can provide the object instance to call on at delegate invocation time.
Let's look at an example of what this would look like. Imagine a collection of Employee types, and the company has decided to give everyone a 10% raise at the end of the year. All the Employee objects are contained in a collection type, and now you need to iterate over each employee, applying the raise by calling the Employee.ApplyRaiseOf method:
using System;
using System.Reflection;
using System.Collections.Generic;
delegate void ApplyRaiseDelegate( Employee emp,
Decimal percent );
public class Employee
{
private Decimal salary;
public Employee( Decimal salary ) {
this.salary = salary;
}
public Decimal Salary {
get {
return salary;
}
}
public void ApplyRaiseOf( Decimal percent ) {
salary *= (1 + percent);
}
}
public class EntryPoint
{
static void Main() {
List<Employee> employees = new List<Employee>();
employees.Add( new Employee(40000) );
employees.Add( new Employee(65000) );
employees.Add( new Employee(95000) );
// Create open instance delegate.MethodInfo mi =typeof(Employee).GetMethod( "ApplyRaiseOf",BindingFlags.Public |BindingFlags.Instance );ApplyRaiseDelegate applyRaise = (ApplyRaiseDelegate )Delegate.CreateDelegate( typeof(ApplyRaiseDelegate),mi );// Apply raise. foreach( Employee e in employees ) { applyRaise( e, (Decimal) 0.10 ); // Send new salary to console. Console.WriteLine( e.Salary ); } } }
First, notice that the declaration of the delegate has an Employee type declared at the beginning of the parameter list. This is how you expose the hidden instance pointer so that you can bind it later. Had you used this delegate to represent a closed instance delegate, the Employee parameter would have been omitted. Unfortunately, the C# language doesn't have any special syntax for creating open instance delegates. Therefore, you must use one of the more generalized Delegate.CreateDelegate overloads to create the delegate instance as shown. Before you can do that, you must use reflection to obtain the MethodInfo instance representing the method to bind to.
The key point is that nowhere during the instantiation of the delegate do you provide a specific object instance. You won't provide that until the point of delegate invocation. The foreach loop shows how you invoke the delegate and provide the instance to call upon at the same time. Even though the ApplyRaiseOf method that the delegate is wired to takes only one parameter, the delegate invocation requires two parameters, so that you can provide the instance on which to make the call.
The previous example shows how to create and invoke an open instance delegate; however, the delegate could still be more general and more useful in a broad sense. In that example, you declared the delegate so that it knew it was going to be calling a method on a type of Employee. Thus, at invocation time, you could have placed the call only on an instance of Employee or a type derived from Employee. You can use a generic delegate to declare the delegate so that the type on which it is called is unspecified at declaration time.[38] Such a delegate is potentially much more useful. It allows you to state the following: "I want to represent a method that matches this signature supported by an as-of-yet unspecified type." Only at the point of instantiation of the delegate are you required to provide the concrete type that will be called. Examine the following modifications to the previous example:
delegate void ApplyRaiseDelegate<T>( T instance,Decimal percent );public class EntryPoint { static void Main() {
List<Employee> employees = new List<Employee>();
employees.Add( new Employee(40000) );
employees.Add( new Employee(65000) );
employees.Add( new Employee(95000) );
// Create open instance delegate
MethodInfo mi =
typeof(Employee).GetMethod( "ApplyRaiseOf",
BindingFlags.Public |
BindingFlags.Instance );
ApplyRaiseDelegate<Employee> applyRaise =
(ApplyRaiseDelegate<Employee> )
Delegate.CreateDelegate(
typeof(ApplyRaiseDelegate<Employee>),
mi );
// Apply raise.
foreach( Employee e in employees ) {
applyRaise( e, (Decimal) 0.10 );
// Send new salary to console.
Console.WriteLine( e.Salary );
}
}
}Now, the delegate is much more generic. You can imagine that this delegate could be useful in some circumstances. For example, consider an imaging program that supports applying filters to various objects on the canvas. Suppose that you need a delegate to represent a generic filter type that, when applied, is provided a percentage value to indicate how much of an effect it should have on the object. Using generic, open instance delegates, you could represent such a general notion.
In many cases, when you use delegates as a callback mechanism, you might just want to notify someone that some event happened, such as a button press in a UI. Suppose that you're designing a media player application. Somewhere in the UI is a Play button. In a well-designed system, the UI and the control logic are separated by a well-defined abstraction, commonly implemented using a form of the Bridge pattern. This abstraction facilitates slapping on an alternate UI later, or even better, because UI operations are normally platform-specific, it facilitates porting the application to another platform. For example, the Bridge pattern works well in situations in which you want to decouple your control logic from the UI.
Note
The purpose of the Bridge pattern, as defined in Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (Boston: Addison-Professional, 1995), is to decouple an abstraction from an implementation so that the two can vary independently.
By using the Bridge pattern, you can facilitate the scenario in which changes that occur in the core system don't force changes in the UI and, most importantly, in which changes in the UI don't force changes in the core system. One common way of implementing this pattern is by creating well-defined interfaces into the core system that the UI then uses to communicate with it, and vice versa. However, in these situations, defining interface types are cumbersome and less than ideal. Delegates, on the other hand, are an excellent mechanism to use in this scenario. With a delegate, you can begin to say things as abstract as, "When the user wants to play, I want you to call registered methods passing any information germane to the action." The beauty here is that the core system doesn't care how the user indicates to the UI that he wants the player to start playing media. It could be a button press, or there could be some sort of brain wave detection device that recognizes what the user is thinking. To the core system, it doesn't matter, and you can change and interchange both independently without breaking the other. Both sides adhere to the same agreed-upon contract, which in this case include a specifically formed delegate and a means to register that delegate with the event-generating entity.[39]
This pattern of usage, also known as publish/subscribe, is so common, even outside the realm of UI development, that the .NET runtime designers were so generous as to define a formalized built-in event mechanism. When you declare an event within a class, internally the compiler implements some hidden methods that allow you to register and unregister delegates, which are called when a specific event is raised. In essence, an event is a shortcut that saves you the time of having to write the register and unregister methods that manage a delegate chain yourself. Let's take a look at a simple event sample based on the previous discussion:
using System;
// Arguments passed from UI when play event occurs.
public class PlayEventArgs : EventArgs
{
public PlayEventArgs( string filename ) {
this.filename = filename;
}
private string filename;
public string Filename {
get { return filename; }
}
}
public class PlayerUI
{
// define event for play notifications.
public event EventHandler<PlayEventArgs> PlayEvent;
public void UserPressedPlay() {
OnPlay();
}
protected virtual void OnPlay() {
// fire the event.EventHandler<PlayEventArgs> localHandler
= PlayEvent;
if( localHandler != null ) {
localHandler( this,
new PlayEventArgs("somefile.wav") );
}
}
}
public class CorePlayer
{
public CorePlayer() {
ui = new PlayerUI();
// Register our event handler.
ui.PlayEvent += this.PlaySomething;
}
private void PlaySomething( object source,
PlayEventArgs args ) {
// Play the file.
}
private PlayerUI ui;
}
public class EntryPoint
{
static void Main() {
CorePlayer player = new CorePlayer();
}
}Even though the syntax of this simple event might look complicated, the overall idea is that you're creating a well-defined contract through which to notify interested parties that the user wants to play a file. That well-defined contract is encapsulated inside the PlayEventArgs class, which derives from System.EventArgs (as described in the following text).
Events put certain rules upon how you use delegates. The delegate must not return anything and it must accept two arguments as shown in the PlaySomething method in the previous example. The first argument is an object reference representing the party generating the event. The second argument must be a type derived from System.EventArgs. Your EventArgs derived class is where you define any event-specific arguments.
Note
In .NET 1.1, you had to explicitly define the delegate type behind the event. Starting in .NET 2.0, you can use the new generic EventHandler<T> delegate to shield you from this mundane chore.
Notice the way that the event is defined within the PlayerUI class using the event keyword. The event keyword is first followed by the defined event delegate, which is then followed by the name of the event—in this case, PlayEvent. Also notice that I declared the event member using the generic EventHandler<T> delegate.
When registering handlers using the += operator, as a shortcut you can provide only the name of the method to call, and the compiler will create the EventHandler<T> instance for you using the method group to delegate assignment rules I mentioned in a previous section. You could optionally follow the += operator with a new expression creating a new instance of EventHandler<T>, just as you could when creating delegate instances, but if the compiler provides the shortcut shown, why type more syntax that makes the code harder to read?
The PlayEvent identifier means two entirely different things, depending on what side of the decoupling fence you're on. From the perspective of the event generator—in this case, PlayerUI—the PlayEvent event is used just like a delegate. You can see this usage inside the OnPlay method. Typically, a method such as OnPlay is called in response to a UI button press. It notifies all the registered listeners by calling through the PlayEvent event (delegate).
Note
The popular idiom when raising events is to raise the event within a protected virtual method named On<event>, where <event> is replaced with the name of the event—in this case, OnPlay. This way, derived classes can easily modify the actions taken when the event needs to be raised. In C#, you must test the event for null before calling it; otherwise, the result could be a NullReferenceException. The OnPlay method makes a local copy of the event before testing it for null. This avoids the race condition where the event is set to null from another thread after the null check passes and before the event is raised.
From the event consumer side of the fence, the PlayEvent identifier is used completely differently, as you can see in the CorePlayer constructor.
That's the basic structure of events. As I alluded to earlier, .NET events are a shortcut to creating delegates and the contracts with which to register those delegates. As proof of this, you can examine the IL generated from compiling the previous example. Under the covers, the compiler has generated two methods, add_OnPlay and remove_OnPlay, which are called when you use the overloaded += and -= operators. These methods manage the addition and removal of delegates from the event delegate chain. In fact, the C# compiler doesn't allow you to call these methods explicitly, so you must use the operators. You might be wondering whether there is some way to control the body of those function members as you can with properties. The answer is yes, and the syntax is similar to that of properties. I modified the PlayerUI class to show the way to handle event add and remove operations explicitly:
public class PlayerUI
{
// define event for play notifications.
private EventHandler<PlayEventArgs> playEvent;
public event EventHandler<PlayEventArgs> PlayEvent {
add {
playEvent = (EventHandler<PlayEventArgs>)
Delegate.Combine( playEvent, value );
}
remove {
playEvent = (EventHandler<PlayEventArgs>)
Delegate.Remove( playEvent, value );
}}public void UserPressedPlay() { OnPlay(); } protected virtual void OnPlay() { // fire the event.EventHandler<PlayEventArgs> localHandler= playEvent;if( localHandler != null ) { localHandler( this, new PlayEventArgs("somefile.wav") ); } } }
Inside the add and remove sections of the event declaration, the delegate being added or removed is referenced through the value keyword, which is identical to the way property setters work. This example uses Delegate.Combine and Delegate.Remove to manage an internal delegate chain named playEvent. This example is a bit contrived because the default event mechanism does essentially the same thing, but I show it here for the sake of example.
Note
You would want to define custom event accessors explicitly if you needed to define some sort of custom event storage mechanism, or if you needed to perform any other sort of custom processing when events are registered or unregistered.
One final comment regarding design patterns is in order. As described, you can see that events are ideal for implementing a publish/subscribe design pattern, in which many listeners are registering for notification (publication) of an event. Similarly, you can use .NET events to implement a form of the Observer pattern, in which various entities register to receive notifications that some other entity has changed. These are merely two design patterns that events facilitate.
Many times, you might find yourself creating a delegate for a callback that does something very simple. Imagine that you're implementing a simple engine that processes an array of integers. Let's say that you design the system flexibly, so that when the processor works on the array of integers, it uses an algorithm that you supply at the point of invocation. This pattern of usage is called the Strategy pattern. In this pattern, you can choose to use a different computation strategy by providing a mechanism to specify the algorithm to use at run time. A delegate is the perfect tool for implementing such a system. Let's see what an example looks like:
using System; public delegate int ProcStrategy( int x );
public class Processor
{
private ProcStrategy strategy;
public ProcStrategy Strategy {
set {
strategy = value;
}
}
public int[] Process( int[] array ) {
int[] result = new int[ array.Length ];
for( int i = 0; i < array.Length; ++i ) {
result[i] = strategy( array[i] );
}
return result;
}
}
public class EntryPoint
{
private static int MultiplyBy2( int x ) {
return x*2;
}
private static int MultiplyBy4( int x ) {
return x*4;
}
private static void PrintArray( int[] array ) {
for( int i = 0; i < array.Length; ++i ) {
Console.Write( "{0}", array[i] );
if( i != array.Length-1 ) {
Console.Write( ", " );
}
}
Console.Write( "
" );
}
static void Main() {
// Create an array of integers.
int[] integers = new int[] {
1, 2, 3, 4
};
Processor proc = new Processor();
proc.Strategy = new ProcStrategy( EntryPoint.MultiplyBy2 );
PrintArray( proc.Process(integers) );
proc.Strategy = new ProcStrategy( EntryPoint.MultiplyBy4 );
PrintArray( proc.Process(integers) );
}
}Conceptually, the idea sounds really easy. However, in practice, you must do a few complicated things to make this work. First, you have to define a delegate type to represent the strategy method. In the previous example, that's the ProcStrategy delegate type. Then you have to write the various strategy methods. After that, the delegates are created and bound to those methods and registered with the processor. In essence, these actions feel disjointed in their flow. It would feel much more natural to be able to define the delegate method in a less verbose way. Many times, the infrastructure required with using delegates makes the code hard to follow because the pieces of the mechanism are sprinkled around various different places in the code.
Anonymous methods provide an easier and more compact way to define simple delegates such as these. In short, anonymous methods (introduced in C# 2.0) allow you to define the method body of the delegate at the point where you instantiate the delegate. Let's look at how you can modify the previous example to use anonymous methods. The following is the revised portion of the example:
public class EntryPoint
{
private static void PrintArray( int[] array ) {
for( int i = 0; i < array.Length; ++i ) {
Console.Write( "{0}", array[i] );
if( i != array.Length-1 ) {
Console.Write( ", " );
}
}
Console.Write( "
" );
}
static void Main() {
// Create an array of integers.
int[] integers = new int[] {
1, 2, 3, 4
};
Processor proc = new Processor();
proc.Strategy = delegate(int x) {
return x*2;
};
PrintArray( proc.Process(integers) );
proc.Strategy = delegate(int x) {
return x*4;
};
PrintArray( proc.Process(integers) );
proc.Strategy = delegate {
return 0;
};
PrintArray( proc.Process(integers) );
}
}Notice that the two methods, MultiplyBy2 and MultiplyBy4, are gone. Instead, a delegate is created using a special syntax for anonymous methods at the point where it is assigned to the Processor.Strategy property. You can see that the syntax is almost as if you took the delegate declaration and the method you wired the delegate to and then mashed them together into one. Basically, anywhere that you can pass a delegate instance as a parameter, you can pass an anonymous method instead.
When you pass an anonymous method in a parameter list that accepts a delegate, or when you assign a delegate type from an anonymous method, you must be concerned with anonymous method type conversion. Behind the scenes, your anonymous method is turned into a regular delegate that is treated just like any other delegate instance.
When you assign an anonymous method to a delegate instance storage location, a number of rules must apply.
First, the parameter types of the delegate must be compatible with those of the anonymous method. In the previous example's first two delegate usages, I showed you the long way to declare an anonymous method. Some of you might have noticed the different syntax in the third usage in the example. I left out the parameter list because the body of the method doesn't even use it. Yet, I was still able to set the
Strategyproperty based upon this anonymous method, so clearly some type conversion has occurred. Basically, if the anonymous method has no parameter list, it is convertible to a delegate type that has a parameter list, as long as the list doesn't include anyoutorrefparameters. If there areoutparameters, the anonymous method is forced to list them in its parameter list at the point of declaration.Second, if the anonymous method does list any parameters in its declaration, it must list the same count of parameters as the delegate type, and each one of those types must be the same types in the delegate declaration.
Finally, the return type returned from the anonymous method must be implicitly convertible to the declared return type of the delegate type it is being assigned to. Because the anonymous method declaration syntax doesn't explicitly state what the return type is, the compiler must examine each return statement within the anonymous method and make sure that it returns a type that matches the convertibility rules.
So far, anonymous methods have saved a small amount of typing and made the code more readable. But let's look at the scoping rules involved with anonymous methods. With C#, you already know that curly braces define units of nested scope. The braces delimiting anonymous methods are no different. Take a look at the following modifications to the previous example:
using System;
public delegate int ProcStrategy( int x );
public class Processor
{
private ProcStrategy strategy;
public ProcStrategy Strategy {
set { strategy = value; }
}
public int[] Process( int[] array ) {int[] result = new int[ array.Length ];
for( int i = 0; i < array.Length; ++i ) {
result[i] = strategy( array[i] );
}
return result;
}
}
public class Factor
{
public Factor( int fact ) {
this.fact = fact;
}
private int fact;
public ProcStrategy Multiplier {
get {
// This is an anonymous method.
return delegate(int x) {
return x*fact;
};
}
}
public ProcStrategy Adder {
get {
// This is an anonymous method.
return delegate(int x) {
return x+fact;
};
}
}
}
public class EntryPoint
{
private static void PrintArray( int[] array ) {
for( int i = 0; i < array.Length; ++i ) {
Console.Write( "{0}", array[i] );
if( i != array.Length-1 ) {
Console.Write( ", " );
}
}
Console.Write( "
" );
}
static void Main() {
// Create an array of integers.
int[] integers = new int[] {
1, 2, 3, 4
};Factor factor = new Factor( 2 );
Processor proc = new Processor();
proc.Strategy = factor.Multiplier;
PrintArray( proc.Process(integers) );
proc.Strategy = factor.Adder;
factor = null;
PrintArray( proc.Process(integers) );
}
}In particular, pay close attention to the Factor class in this example. I have made this example more flexible so that I can apply the factor differently, using either multiplication or addition. Notice that the anonymous methods in the Factor class are using a variable that is accessible within the scope they are defined in—namely, the fact instance field. You can do this because the regular scoping rules apply even to the block of the anonymous method. There's something tricky going on here, though. See where I set the factor instance variable in Main to null? Notice that I did it before the delegate obtained from the Factor.Adder property is invoked. That's fine because the Adder property returns a delegate instance, even though I decided to declare the delegate as an anonymous method rather than the original way. But what about that Factor.fact instance field? If I set the factor variable to null in Main, the GC can collect the factor object even before the delegate, which uses the field, is done with it, right? Could this actually be a volatile race condition if the GC collects the Factor.fact instance before the delegate is finished with it? The answer is no because the delegate has captured the variable.
Within anonymous method declarations, any variables defined outside the scope of the anonymous method but accessible to the anonymous method's scope, including the this reference, are considered outer variables. And whenever an anonymous method body references one of these variables, it is said that the anonymous method has "captured" the variable. In this case, this has been captured. Thus, the Factor.fact field in the previous example will continue to live as it is still referenced in active delegates.
The ability of anonymous method bodies to access variables within their containing definition scope is enormously useful. In computer science circles, this is commonly referred to as a closure. Imagine how much more difficult it would have been to achieve the same mechanism as in the example if you'd used regular delegates. You would have to create a mechanism, external to the delegate, to maintain the instance that you want the delegate to use. One solution when using standard delegates is to introduce another level of indirection in the form of a class, as is so often done when solving problems like these. However, I'm sure you'll agree that anonymous methods can save a fair amount of work, not to mention that they can make your code significantly briefer and more readable.
When a variable is captured by an instance of an anonymous method, you have to be careful of the implications that can have. Keep in mind that a captured variable's representation lives on the heap somewhere, and the variable in a delegate instance is merely a reference to that data. Therefore, it's entirely possible that two delegate instances created from an anonymous method can hold references to the same variable. Let me show an example of what I'm talking about:
using System;
public delegate void PrintAndIncrement();
public class EntryPoint
{
public static PrintAndIncrement[] CreateDelegates() {PrintAndIncrement[] delegates = new PrintAndIncrement[3];
int someVariable = 0;
int anotherVariable = 1;
for( int i = 0; i < 3; ++i ) {
delegates[i] = delegate {
Console.WriteLine( someVariable++ );
};
}
return delegates;
}
static void Main() {
PrintAndIncrement[] delegates = CreateDelegates();
for( int i = 0; i < 3; ++i ) {
delegates[i]();
}
}
}The anonymous method inside the CreateDelegates method captures someVariable, which is a local variable in the CreateDelegates method scope. However, because three instances of the anonymous method are put into the array, three anonymous method instances have now captured the same instance of the same variable. Therefore, when the previous code is run, the result looks like this:
0
1
2
As each delegate is called, it prints and increments the same variable. Now, consider what effect a small change in the CreateDelegates method can have. If you move the someVariable declaration into the loop that creates the delegate array, a fresh instance of the local variable is instantiated every time you go through the loop, thus mimicking the semantics of when variables are allocated on the stack. Notice the following change to the CreateDelegates method:
public static PrintAndIncrement[] CreateDelegates() {
PrintAndIncrement[] delegates = new PrintAndIncrement[3];
for( int i = 0; i < 3; ++i ) {
int someVariable = 0;
delegates[i] = delegate {
Console.WriteLine( someVariable++ );
};
}
return delegates;
}This time, the output is as follows:
0
0
0
This is why you need to be careful when you use variable capture in anonymous delegates. In the first case, the three delegates all captured the same variable. In the second case, they all captured separate instances of the variable because each iteration of the for loop creates a new (separate) instance of someVariable. Although you should keep this powerful feature handy in your bag of tricks, you must know what you're doing so you don't end up shooting yourself in the foot.
Savvy readers might be wondering how the code can possibly work without blowing up because the captured variables in this example are value types that live on the stack by default. Remember that value types are created on the stack unless they happen to be declared as a field in a reference type that is created on the heap, which includes the case when they are boxed. However, someVariable is a local variable, so under normal circumstances, it is created on the stack. But these are not normal circumstances. Clearly, it's not possible for an instance of an anonymous method to capture a local variable on the stack and expect it to be there later when it needs to reference it. It must live on the heap. Local value type variables that are captured must have different lifetime rules than such variables that are not captured. Therefore, the compiler does quite a bit of magic under the covers when it encounters local value type captured variables.
Note
Although the previous discussion uses a captured value type as an example, the compiler employs the same capture mechanism for reference type variables as well.
When the compiler encounters a captured value type variable, it silently creates a class behind the scenes. Where the code initializes the local variable, the compiler generates IL code that creates an instance of this transparent class and initializes the field, which represents someVariable in this case. You can verify this with the first example if you open the compiled code in ILDASM or Reflector. I included the dummy variable anotherVariable so you could see the difference in how the IL treats them. Because anotherVariable is not captured, it is created on the stack, as you'd expect. The following code contains a portion of the IL for the CreateDelegates call after compiling the example with debugging symbols turned on:
// Code size 85 (0x55)
.maxstack 5
.locals init ([0] class PrintAndIncrement[] delegates,
[1] int32 anotherVariable,
[2] int32 i,
[3] class PrintAndIncrement '<>9__CachedAnonymousMethodDelegate1',
[4] class EntryPoint/'<>c__DisplayClass2' '<>8__locals3',
[5] class PrintAndIncrement[] CS$1$0000,
[6] bool CS$4$0001)
IL_0000: ldnullIL_0001: stloc.3IL_0002: newobj instance void EntryPoint/'<>c__DisplayClass2'::.ctor()IL_0007: stloc.s '<>8__locals3' IL_0009: nop IL_000a: ldc.i4.3 IL_000b: newarr PrintAndIncrement IL_0010: stloc.0 IL_0011: ldloc.s '<>8__locals3' IL_0013: ldc.i4.0IL_0014: stfld int32 EntryPoint/'<>c__DisplayClass2'::someVariableIL_0019: ldc.i4.1 IL_001a: stloc.1 IL_001b: ldloc.1 IL_001c: call void [mscorlib]System.Console::WriteLine(int32)
Note the two variables' usages. In line IL_0002, a new instance of the hidden class is created. In this case, the compiler named the class <>c__DisplayClass2. That class contains a public instance field named someVariable, which is assigned in IL_0014. The compiler has transparently inserted the proverbial extra level of indirection in the form of a class to solve this sticky wicket of local value types captured by anonymous methods. Also, note that anotherVariable is treated just like a normal stack-based variable, as can be shown by the fact that it is declared in the local variables portion of the method.
Anonymous methods, coupled with variable capture, can provide a convenient means of implementing parameter binding on delegates. Parameter binding is a technique in which you want to call a delegate, typically with more than one parameter, so that one or more parameters are fixed while the others can vary per delegate invocation. For example, if you have a delegate that takes two parameters, and you want to convert it into a delegate that takes one parameter where the other parameter is fixed, you could use parameter binding to accomplish this feat. This technique is sometimes called currying[40]. Those of you C++ programmers who are familiar with the STL or the Boost Library might be familiar with parameter binders. Here's an example:
using System;
public delegate int Operation( int x, int y );
public class Bind2nd
{
public delegate int BoundDelegate( int x );
public Bind2nd( Operation del, int arg2 ) {
this.del = del;
this.arg2 = arg2;}
public BoundDelegate Binder {
get {
return delegate( int arg1 ) {
return del( arg1, arg2 );
};
}
}
private Operation del;
private int arg2;
}
public class EntryPoint
{
static int Add( int x, int y ) {
return x + y;
}
static void Main() {
Bind2nd binder = new Bind2nd(
new Operation(EntryPoint.Add),
4 );
Console.WriteLine( binder.Binder(2) );
}
}In this example, the delegate of type Operation with two parameters, which calls back into the static EntryPoint.Add method, is converted into a delegate that takes only one parameter. The second parameter is fixed using the Bind2nd class. Basically, the instance field Bind2nd.arg2 is set to the value that you want the second parameter fixed to. Then the Bind2nd.Binder property returns a new delegate in the form of an anonymous method instance, which captures the instance field and applies it along with the first parameter that is applied at the point of invocation.
Readers familiar with the C++ STL are probably exclaiming that this example would be infinitely more useful if Bind2nd was generic so it could support a generic two-parameter delegate, much as the binder in STL does. This would be nice indeed, but some language barriers make it a bit tricky. Let's start with an attempt to make the delegate type generic in the Bind2nd class. You could try the following:
// WILL NOT COMPILE !!!
public class Bind2nd< DelegateType >
{
public delegate int BoundDelegate( int x );
public Bind2nd( DelegateType del, int arg2 ) {
this.del = del;
this.arg2 = arg2;
}
public BoundDelegate Binder {
get {
return delegate( int arg1 ) {return this.del( arg1, arg2 ); // OUCH!
};
}
}
private DelegateType del;
private int arg2;
}This is a noble attempt, but unfortunately it fails miserably because the compiler gets confused inside the anonymous method body and complains that an instance field is being used like a method. The exact error looks like the following:
error CS1955: Non-invocable member 'Bind2nd<DelegateType>.del' cannot be used like a method.
The compiler is correct. What it is saying you cannot do is exactly what you want to do, even though the compiler cannot make heads or tails of it. What's a programmer to do?
Another attempt involves generic constraints. Using constraints, you can say that even if the type is generic, it must derive from a certain base class or implement a specific interface. Fair enough! Let's just help the compiler out and tell it that DelegateType will derive from System.Delegate, as follows:
// STILL WILL NOT COMPILE !!!
public class Bind2nd< DelegateType >
where DelegateType : Delegate
{
public delegate int BoundDelegate( int x );
public Bind2nd( DelegateType del, int arg2 ) {
this.del = del;
this.arg2 = arg2;
}
public BoundDelegate Binder {
get {
return delegate( int arg1 ) {
return this.del( arg1, arg2 ); // OUCH!
};
}
}
private DelegateType del;
private int arg2;
}Alas, you're stuck again! This time, the compiler says that a constraint of type Delegate is not allowed as shown in the following error:
error CS0702: Constraint cannot be special class 'System.Delegate'
It turns out that the solution lies with using generic delegates to get the job done. The following is a solution to the problem:
using System;
public class Bind2nd<Arg1Type, Arg2Type, ReturnType>
{
public Bind2nd( Func<Arg1Type, Arg2Type, ReturnType> del,
Arg2Type arg2 ) {
this.del = del;
this.arg2 = arg2;
}
public Func<Arg1Type, ReturnType> Binder {
get {
return delegate( Arg1Type arg1 ) {
return del( arg1, arg2 );
};
}
}
private Func<Arg1Type, Arg2Type, ReturnType> del;
private Arg2Type arg2;
}
public class EntryPoint
{
static int Add( int x, int y ) {
return x + y;
}
static void Main() {
Bind2nd<int,int,int> binder = new Bind2nd<int,int,int>(
EntryPoint.Add,
4 );
Console.WriteLine( binder.Binder(2) );
}
}First, in order for the anonymous method to be able to use the del field as a method, the compiler must know that it is a delegate. Also, it cannot simply be of type System.Delegate. In order to call through to a delegate using the method call syntax, it must be a concrete delegate type. To make things simple, I used the Func<> generic delegate type to avoid having to declare my own generic delegates. We now have a working generic binder.
The Bind2nd type in the previous example provides an excellent segue into generics, disussed in Chapter 11.
Delegates offer up a handy mechanism to implement the Strategy pattern. In a nutshell, the Strategy pattern allows you to swap computational algorithms dynamically, based on the runtime situation. For example, consider the common case of sorting a group of items. Let's suppose that you want the sort to occur as quickly as possible. Because of system circumstances, however, more temporary memory is required in order to achieve this speed. This works great for collections of reasonably manageable size, but if the collection grows to be huge, it's possible that the amount of memory needed to perform the quick sort could exceed the system resource capacity. For those cases, you can provide a sort algorithm that is much slower but taxes the system resources far less. The Strategy pattern allows you to swap out these algorithms at run time depending on the conditions. This example, although a tad contrived, illustrates the purpose of the Strategy pattern perfectly.
Typically, you implement the Strategy pattern using interfaces. You declare an interface that all implementations of the strategy implement. Then, the consumer of the algorithm doesn't have to care which concrete implementation of the strategy it is using. Figure 10-1 features a diagram that describes this typical usage.
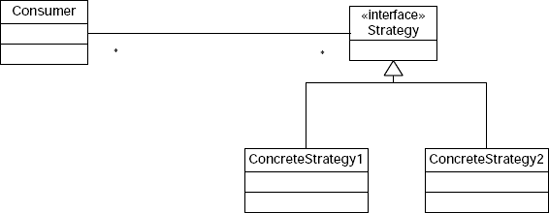
Delegates offer a more lightweight alternative to using interfaces to implement a simple strategy. Interfaces are merely a mechanism to implement a programming contract. Instead, imagine that your delegate declaration is used to implement the contract, and any method that matches the delegate signature is a potential concrete strategy. Now, instead of the consumer holding on to a reference to the abstract strategy interface, it simply retains a delegate instance. The following example illustrates this scenario:
using System;
using System.Collections;
public delegate Array SortStrategy( ICollection theCollection );
public class Consumer
{
public Consumer( SortStrategy defaultStrategy ) {
this.strategy = defaultStrategy;}
private SortStrategy strategy;
public SortStrategy Strategy {
get { return strategy; }
set { strategy = value; }
}
public void DoSomeWork() {
// Employ the strategy.
Array sorted = strategy( myCollection );
// Do something with the results.
}
private ArrayList myCollection;
}
public class SortAlgorithms
{
static Array SortFast( ICollection theCollection ) {
// Do the fast sort.
}
static Array SortSlow( ICollection theCollection ) {
// Do the slow sort.
}
}When the Consumer object is instantiated, it is passed a sort strategy, which is nothing more than a method that implements the SortStrategy delegate signature. Depending on the run time conditions, the appropriate delegate is provided to the Consumer instance, and the Consumer.DoSomeWork method automatically calls into the desired strategy. Using the SortStrategy property, one could even change which strategy is used at run time. You could argue that implementing a strategy pattern this way is even more flexible than using interfaces because delegates can bind to both static methods and instance methods. Therefore, you could create a concrete implementation of the strategy that also contains some state data that is needed for the operation, as long as the delegate points to an instance method on a class that contains that state data. Similarly, the delegate could be an anonymous method returned by a property of that class.
Delegates offer a first-class, system-defined, and system-implemented mechanism for uniformly representing callbacks. In this chapter, you saw various ways to declare and create delegates of different types, including single delegates; chained delegates; open instance delegates; and anonymous methods, which are delegates. Additionally, I showed how to use delegates as the building blocks of events. You can use delegates to implement a wide variety of design patterns because delegates are a great means for defining a programming contract. And at the heart of just about all design patterns is a well-defined contract.
The next chapter covers the details of generics, which is arguably one of the most powerful features of the CLR and the C# language for creating type safe code.
[35] Even better than anonymous functions are lambda expressions, which deserve an entire chapter and are covered in Chapter 15.
[36] You can find out more about various styles of thunks at the following link: http://www.wikipedia.org/wiki/Thunk.
[38] I cover generics in Chapter 11.
[40] I talk more about currying in Chapter 15 when I cover lambda expressions, which are a more syntactically expressive way of achieving the same goals as anonymous methods.