
When working with large-scale applications that serve millions of requests a day (or more), even a well-written data-intensive application can begin to show cracks. These issues may appear in the form of slow responses, timeouts, or a complete loss of service until the incoming traffic is reduced. Besides disk I/O, one of the most costly tasks in your performance budget is the communication to and from your database. Although today's relational database management systems (RDBMSs) are excellent at storing execution plans and retrieving data quickly, sometimes the sheer volume of requests and minor delays in handling them are overwhelming to one component or another along the processing pipeline. The obvious solution is to cache frequently used or infrequently changing data to avoid the trip to the database. It's not a silver bullet, however. For applications that are deployed on multiple servers (for example, in a load-balanced environment), the in-session cache quickly becomes insufficient for reasons we will look at shortly. In this chapter, we'll discuss the solution to that problem: the distributed cache. We'll cover what it is, what it is not, and best practices for using it. We'll also create a tree structure for our CMS and explore how a distributed cache is an ideal location for storing such objects; we'll also learn why configuring Memcached properly is critical for effective cache usage.
The easiest way to define a distributed cache is by comparison to the typical in-session cache. Let's assume we have a hypothetical application on a single-server environment; our lone machine hosts the application and probably the database as well. In this situation, it's perfectly acceptable (and absolutely faster) to use the in-session cache provided by .NET. Assuming good data layer design, your cache hit ratio should quickly get very high, and the database traffic will reduce accordingly.
Tip
Cache hit ratio refers to the percentage of requests to the cache that result in successful returns of data. For any specific data point, you need to first check the cache for the presence of a specific key-value pair. If this value exists, you can retrieve it and move on; otherwise, you have to make a request for that data point from your data source (RDBMS, XML feed, flat file, and so on) and then insert the value into the cache for retrieval next time. Obviously, you want the cache hit ratio to be as high as possible; spending processing time on excessive cache misses is worse than having no cache at all sometimes.
The limitations of this design become apparent only when moving to more complex application hosting architectures. Consider an environment where your application is hosted on five web servers that are positioned behind a load balancer. The load balancer handles incoming HTTP requests and directs traffic to servers that are capable of handling additional traffic, spreading the workload across each of the five machines (ergo, "load balancing").
The .NET cache that you're familiar with is tied to the particular instance of the application instance on a specific box; what that means is if your user hits box A and stores the value for the key "foo" in the cache, their next request may result in them communicating with box B. The .NET cache is not distributed, so box B has no knowledge of the key-value pair "foo" that exists on box A. The consequence of this is that the ratio of cache hits to misses is painfully low, particularly as the number of servers increases. You may be able to get away with this in an environment with few boxes and light traffic, but when things ramp up, it's going to represent a potentially serious bottleneck.
Enter Memcached to save the day. Memcached is a free, open source, distributed cache application that was written by Danga Interactive, the company behind the massively popular LiveJournal. Let's consider the nature of LiveJournal for a moment. If you're not familiar with this site, it is sufficient to say that LiveJournal is a very popular blogging web site where users can also befriend one another and establish communities. With an entity like an online blog, it quickly becomes apparent that a lot of the data is infrequently changing; blog posts tend to be static entities (this is not a hard and fast rule, but a typical generalization of behavior). It doesn't make a lot of sense to constantly request infrequently changing data from the database when a cache is typically much faster at handling precanned individual data points.
Memcached was developed to allow LiveJournal to distribute its cache across any number of servers and alleviate these costly database trips. Since then, it has become wildly popular, having been adopted by Facebook, Twitter, Digg, and YouTube, just to name a few. Part of the strength of Memcached is that many experienced developers and engineers in a variety of companies have contributed to the code, adding features and increasing stability and performance. The net effect is that we have at our disposal a battle-worn piece of software that has been proven time and time again in real-world, production environments at the enterprise level...plus, it's totally free.
Tip
How important is Memcached (and the broader category of distributed caches) to the scalability potential of high-volume web presences? When Facebook introduced the option to create a specific friendly URL for individual profile pages, 200,000 people used this feature in the first 3 minutes. Each username has to be checked for availability, so Facebook created a specific Memcached tier with 1TB of memory allocated to handle this. Within the hour, 1 million people had used the service, which functioned solely because of the quick nature of the Memcached tier and not having to make costly database trips. You can read more about this at Facebook's engineering blog at http://www.facebook.com/note.php?note_id=39391378919.
Memcached can be hosted on either Windows or Unix environments. Once an instance of Memcached is running, it listens on a particular port (11211 by default) for requests and has a limited API for CRUD (create, read, update, and delete) operations, plus some diagnostic commands. You typically do not speak to Memcached directly; more commonly, you will use a client to do so. Clients offer a variety of benefits, including handling data compression/decompression and the low-level TCP/IP or UDP communication requirements so you aren't forced to implement them yourself (although you're certainly free to do so). Furthermore, Memcached is supposed to be fault-tolerant; if you have 10 servers handling Memcached requests, you should be able to remove any of them from the pool at any time without issue. Client libraries help to manage the server pool and identify healthy, responsive boxes.
A variety of Memcached clients are available that support a large number of languages and platforms. For the purposes of this chapter, we will use the .NET Memcached client library available from http://sourceforge.net/projects/memcacheddotnet/. This project contains DLLs that you can import into your .NET applications that will connect to a Memcached server.
When you download and extract this project, you will find a variety of source control folders present. The libraries themselves are present in the memcacheddotnet runkclientlibsrc folder. You'll want to open the .NET 2.0 version of the solution and build it; this will create the actual DLLs for use in your application as shown in Figure 6-1. The clientliblib folder and subfolders contain additional libraries such as log4net that are dependencies of the client library.
Now that you have the client libraries available to speak to a Memcached server, we need to actually set up an instance of a Win32 port. A free port of Memcached is available at http://jehiah.cz/projects/memcached-win32/. Feel free to download and explore the source code if you like; for the purposes of this chapter, we need to concern ourselves only with the binaries.
Once you've acquired the Win32 version of the Memcached server, open a new command prompt window and make your way to the directory where you've placed it. Type memcached -vv, and press Enter. This will spin up a new Memcached instance in verbose mode (omitting the -vv parameter will start the instance with no output sent to the console window). You can also start Memcached as a Windows service, but we're not going to cover that at this point; for now, we want to have access to the play-by-play actions that occur, and we won't have that if we spin up a Windows service.
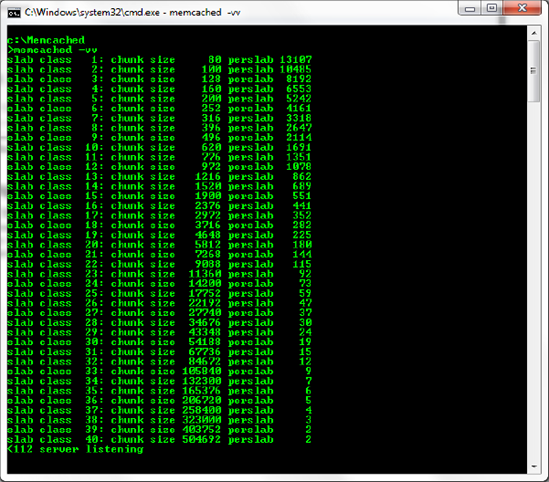
When Memcached starts, you'll see the default slab allocations including the accepted maximum object size (in bytes) for the slab and a total of how many objects of that maximum size will fit. A slab is an abstraction of memory that accommodates objects within a certain size range. The nice thing here is that you don't have to do any particular coding to align objects with slabs; Memcached will handle that for you automatically. Figure 6-2 displays the default slab allocations. We will discuss configuration considerations regarding slab sizes later in this chapter.
Note
Memcached, in its initial form, relied on the glibc malloc call. This resulted in address space fragmentation and various performance problems after any individual instance had been active for several days straight. Eventually, the Memcached instance would simply crash. The newer versions of Memcached use a custom slab allocation system where items are automatically placed into particular buckets based on their size; for example, by default there are only 2 spaces for large items in the 500,000+ slab, but more than 13,000 spaces in the size 80 slab. The reason? It's more likely that you will store many small items as opposed to many large items. You can (and likely will) resize and redefine these slab classes when you spin up an instance. For now, the defaults work fine, although by the end of the chapter we will have identified conditions in which the defaults are unsuitable, as well as how to change them.
The last line Memcached displays via the console output at startup is usually something like <112 server listening. At this point, the server is capable of accepting incoming requests. We don't have to use handwritten code to do so; we can use Telnet to communicate with the instance if desired. Open a new command window and type telnet localhost 11211. The Memcached instance will report that a new client has made a connection to the server, as demonstrated in Figure 6-3.
Figure 6-3. Connecting via Telnet on the default port, 11211. The Memcached instance displays a new connection.
Working with Memcached via a direct connection such as Telnet requires a fairly in-depth knowledge of the Memcached protocol, in no small part because the messages returned when you get the syntax wrong can be less than helpful in sorting out the problem. With that said, being able to connect via Telnet can be very useful in diagnosing application issues, examining the health of the cache, and so on, once you've got it running in a production environment. At the time of this writing, the current protocol lives at http://github.com/memcached/memcached/blob/master/doc/protocol.txt; it's definitely worth bookmarking and having readily accessible at all times.
Note
Before we get into the code, let me take a moment to mention this critical point: caching is hard. It's simple enough to dump objects into the cache and retrieve them, but knowing what to cache and when to cache it (and maybe more importantly when to expire it) is the key to an effective caching layer. It seems easiest to simply cache everything and cache it often, but your application's requirements may not be in line with this approach. Also, caching can occasionally hide bugs (of many types) if applied too early in the development process; this is part of why we are discussing it later in the game.
One of the strengths of the .NET 4 Framework is the ability to swap providers for your cache (including the OutputCache). As such, if we want to engineer flexibility in our caching options, we should opt to hide the specific implementation details away in our libraries and work through abstractions and wrappers. The next few examples will use the client libraries we built directly to see how they work; then we'll wrap them in other code to hide what's actually being done.
Create a new console application called MemcachedTest. Add a reference to the MemcachedClient library, and then add the code in Listing 6-1 to the Program.cs file.
Example 6-1. Using the Win32 Memcached Client to Store and Retrieve Three Objects
using System;
using System.Text;
using Memcached.ClientLibrary;
namespace MemcachedTest
{
class Program
{
static void Main(string[] args)
{
MemcachedClient cache = new MemcachedClient();
string[] serverPool = { "127.0.0.1:11211" };
SockIOPool pool = SockIOPool.GetInstance();
pool.SetServers(serverPool);
pool.Initialize();
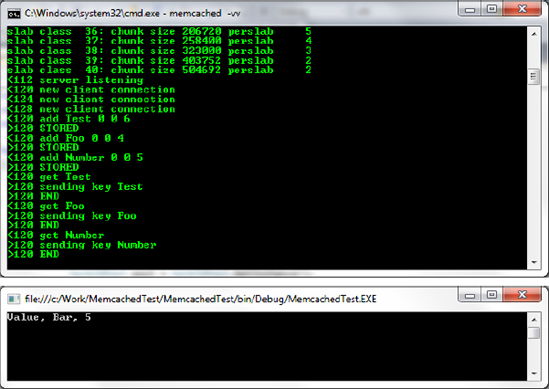
cache.Add("Test", "Value");
cache.Add("Foo", "Bar");
cache.Add("Number", 5);
Console.WriteLine("{0}, {1}, {2}", cache.Get("Foo"), cache.Get("Test"), cache.Get("Number")
);
Console.ReadLine();
}
}
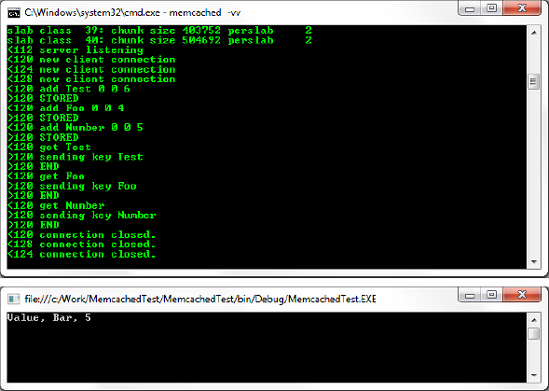
}The code is actually pretty straightforward; first, we configure a pool of servers as an array and add our particular instance to it by calling SetServers(). Next, we add objects to the cache in the traditional key-value pair format with the Add() method. Finally, we retrieve items with the Get() method and output the values to the console window, as shown in Figure 6-4.
Warning
When storing and retrieving objects via the Memcached client, you are dealing with the .NET type object. As such, it is up to you to enforce good coding practices; if you store a string object in the cache and try to retrieve it into an integer variable, you will not receive an error within the IDE or when compiling. The exception will be thrown at runtime when the value is read from the Memcached instance. In a moment, we'll create a generic class that will help clarify the intention of code that handles object transmission.
Now that we know we have connectivity to our instance, we can extract the code for communicating with Memcached out and hide it in a separate library. Create a new class library called MemcachedLib, add a reference to the client library, and add a file called Client.cs to the project (you can also delete the default class file while you're at it). We'll also create a private MemcachedClient to hold the client library instance and check for its existence when we initialize our code (see Listing 6-2).
Example 6-2. A Static Class to Hold Connections to a Memcached Instance
using System;
using System.Collections.Generic;
using System.Text;
using Memcached.ClientLibrary;
namespace MemcachedLib
{
public static class Client
{
private static string[] _serverPool = { "127.0.0.1:11211" };
private static MemcachedClient _memcached;
private static SockIOPool _pool;
public static MemcachedClient InitClient()
{
if (_memcached == null) _memcached = new MemcachedClient();
if (_pool == null)
{
_pool = SockIOPool.GetInstance();
_pool.SetServers(_serverPool);
_pool.Initialize();
}
return _memcached;
}
}
}Earlier we briefly mentioned that the items stored in and retrieved from the cache are of type object and therefore subject to both (un)boxing and type conversion errors. We can address some of these concerns by creating a class that accepts generic types. Add a new class file to the library called CacheItem.cs. This class will serve as the basic entity that handles cache operations (see Listing 6-3).
Example 6-3. A Generic Class to Facilitate Strongly Typed Object Transmission to a Memcached Instance
using System;
using System.Collections.Generic;
using System.Text;
namespace MemcachedLib
{
public class CacheItem<T>
{
public string Key { get; set; }public T Value { get; set; }
public void Save()
{
Memcached.ClientLibrary.MemcachedClient m = Client.InitClient();
m.Add(Key, Value);
}
public T Get()
{
Memcached.ClientLibrary.MemcachedClient m = Client.InitClient();
this.Value = (T)m.Get(Key);
return this.Value;
}
}
}The CacheItem objects are responsible for self-storage and retrieval; in this case, it's a matter of personal preference for me. You could simply opt for the class to have a string Key property and a Value property of generic type T and leave it at that, making another class responsible for storage and retrieval. As we'll see in the next example, making the object responsible for these tasks lends itself to a very natural syntax.
Note
At this point, we are still tied to the specific implementation of the Memcached client library based on the code in the Save() and Get() methods. We will extract that functionality at a later point to fully decouple the CacheItem class from the Memcached client.
Let's return to the console application again and modify it to use this new generic class. Add a reference to the MemcachedLib project, and make the bold modifications to the Program.cs file (see Listing 6-4). Figure 6-5 displays the output.
Example 6-4. Using the New Generic Class to Communicate with the Memcached Instance
using System;using System.Text;using MemcachedLib;using System.Diagnostics;namespace MemcachedTest { class Program { static void Main(string[] args) {AddTest();GetTest();Console.ReadLine();
}
private static void AddTest()
{
CacheItem<string> test =
new CacheItem<string> { Key = "Test", Value = "Value" };
test.Save();
CacheItem<string> foo = new CacheItem<string> { Key = "Foo", Value = "Bar" };
foo.Save();
CacheItem<int> number = new CacheItem<int> { Key = "Number", Value = 5 };
number.Save();
}
private static void GetTest()
{
CacheItem<string> test = new CacheItem<string> { Key = "Test" };
CacheItem<string> foo = new CacheItem<string> { Key = "Foo" };
CacheItem<int> number = new CacheItem<int> { Key = "Number" };
Console.WriteLine("{0}, {1}, {2}", test.Get(), foo.Get(), number.Get());
}
}
}
You may have noticed that we added a reference to System.Diagnostics to the Program.cs file but haven't used anything in that namespace yet. We're going to modify the Program class to iterate over our cache operations 1,000 times and test how long it takes to complete the operations. We want to identify any potential performance bottlenecks as well as determine how efficiently the .NET Framework is managing the memory related to our objects (see Listing 6-5).
Example 6-5. Running the Initial Methods 1,000 Times with a Stopwatch Attached to Determine Approximate Execution Time
namespace MemcachedTest
{
class Program
{
static void Main(string[] args)
{
for (int i = 0; i < 1000; i++)
{
Stopwatch sw = new Stopwatch();
sw.Start();
AddTest();
Console.WriteLine("Operation took {0}ms.", sw.ElapsedMilliseconds);
sw.Stop();
sw.Reset();
sw.Start();
GetTest();
Console.WriteLine("Operation took {0}ms.", sw.ElapsedMilliseconds);
sw.Stop();
sw.Reset();
}
Console.ReadLine();
}
}
}Figure 6-6 demonstrates the sort of result we want to see. Even after 1,000 iterations, the operations are still taking betwen 3 and 5 milliseconds to complete. The memory usage of the application was also consistent across the runs, taking up a rough maximum of 25KB to 26KB throughout, as shown in Figure 6-7.

The final primary operation is deletion, which is extremely straightforward. The Delete() method, added to the CacheItem class, will handle removing objects from the cache (see Listing 6-6).
Example 6-6. A Generic Class to Facilitate Strongly Typed Object Transmission to a Memcached Instance
using System;
using System.Collections.Generic;
using System.Text;
namespace MemcachedLib
{
public class CacheItem<T>
{
public string Key { get; set; }
public T Value { get; set; }
public void Save()
{
Memcached.ClientLibrary.MemcachedClient m = Client.InitClient();
m.Add(Key, Value);
}
public T Get()
{
Memcached.ClientLibrary.MemcachedClient m = Client.InitClient();
this.Value = (T)m.Get(Key);
return this.Value;
}
public void Delete()
{
Memcached.ClientLibrary.MemcachedClient m = Client.InitClient();
m.Delete(this.Key);
}
}
}So far the objects we've stored have been simple .NET types such as int and string. Although the Memcached client library is capable of handling most of the plumbing and infrastructure for us, there are still some considerations we need to factor in with regard to class design. To demonstrate this, create a new class file called CustomObject.cs in the MemcachedTest project. This class will hold a theoretical business entity that exposes CustomerID, CustomerName, and Salary properties (see Listing 6-7).
Example 6-7. A Simple Custom Object Representing a Business Tier Entity
using System;
namespace MemcachedTest
{
public class CustomObject
{
public int CustomerID { get; set; }
public string CustomerName { get; set; }
public decimal Salary { get; set; }
}
}Now we can modify the Program.cs file to store and retrieve objects of this CustomObject type to Memcached (see Listing 6-8).
Example 6-8. Modifying the Main Program to Store a CustomObject in the Cache
namespace MemcachedTest
{
class Program
{
static void Main(string[] args)
{
AddTest();
GetTest();
Console.ReadLine();
}
private static void AddTest()
{
CacheItem<CustomObject> customObj =
new CacheItem<CustomObject> {
Key = "Customer",
Value = new CustomObject {
CustomerID = 1, CustomerName = "John Smith", Salary = 100000
}
};
customObj.Save();
}
private static void GetTest()
{
CacheItem<CustomObject> customObj =
new CacheItem<CustomObject> { Key = "Customer" };
customObj.Get();
}
}
}Running this code will trigger an exception as shown here. What's the problem with this code?
Type 'MemcachedTest.CustomObject' in Assembly 'MemcachedTest, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null' is not marked as serializable.
The issue is that the CustomObject class has not been marked with the Serializable attribute; alternatively, you could implement ISerializable if desired and handle serialization manually. The built-in binary serialization in .NET is sufficient for resolving this problem, as demonstrated in Listing 6-9; Figure 6-8 shows the output.

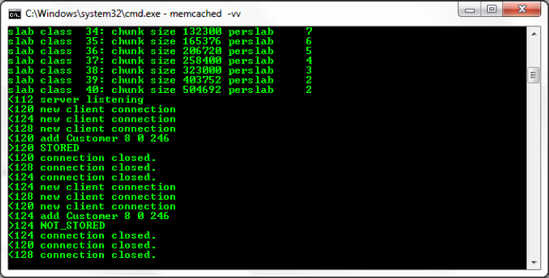
Earlier I mentioned that knowledge of the Memcached protocol is useful in designing an effective cache layer. In this case, although our code is functional, we've introduced a potentially subtle bug that wouldn't be totally obvious without viewing the verbose output of the Memcached instance.
Our CacheItem class uses the Add() method of the MemcachedClient library, which appears to work properly. The issue is exposed only when we run the Add() method on the same object repeatedly before the object has expired; see Figure 6-9 to see the problem in action. Note that the output displays "NOT STORED," indicating no change has been made to the cache.
The MemcachedClient library defines a method called Set() that will automatically override the value of an item regardless of whether it has expired; Add() is a conditional method that modifies the contents of the cache only if the object in question either does not exist or has reached its expiration point. Note that this behavior is not dictated by the library itself but by the Memcached protocol; SET overwrites automatically while ADD is conditional.
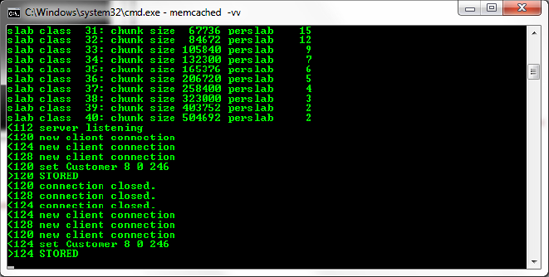
We can resolve this issue in a variety of ways including method overloads or alternative methods (creating separate Add() and Set() methods in the CacheItem class). Since we're using .NET 4, we can take advantage of a new feature: optional parameters. This type of parameter allows us to specify some value (if desired) or operate on a default value if none is provided, as shown in Listing 6-10. This is a very convenient way to add conditional logic without excessive repetition (affectionately known as "don't repeat yourself"). The code from Listing 6-10 gives results as shown in Figure 6-10.
Example 6-10. Optional Parameters Provide a Cleaner Approach Than Overloads in This Case
public class CacheItem<T>
{
public string Key { get; set; }
public T Value { get; set; }
public void Save(bool overwrite = false)
{
Memcached.ClientLibrary.MemcachedClient m = Client.InitClient();
if (overwrite)
{
m.Set(Key, Value);
}
else
{
m.Add(Key, Value);
}
}
public T Get()
{
Memcached.ClientLibrary.MemcachedClient m = Client.InitClient();
this.Value = (T)m.Get(Key);
return this.Value;
}
}
Although in an ideal world nothing would ever break, sometimes things do go off the rails, and being able to identify the cause (or at least narrow it down) is valuable when the clock is ticking. The Memcached protocol defines a method (conveniently called STATS) for retrieving statistics about the state of the instance; this feature is exposed in the MemcachedClient library via the Stats() method.
We will make this modification to the Client class in the MemcachedLib project (Listing 6-11). The results are shown in Figure 6-11.
Example 6-11. Retrieving Statistics from Registered Cache Instances
using System;
using System.Collections;
using System.Collections.Generic;
using System.Text;
using Memcached.ClientLibrary;
namespace MemcachedLib
{
public static class Client
{
private static string[] _serverPool = { "127.0.0.1:11211" };
private static MemcachedClient _memcached;
private static SockIOPool _pool;
public static MemcachedClient InitClient(){
if (_memcached == null) _memcached = new MemcachedClient();
if (_pool == null)
{
_pool = SockIOPool.GetInstance();
_pool.SetServers(_serverPool);
_pool.Initialize();
}
return _memcached;
}
public static string Stats()
{
InitClient();
StringBuilder results = new StringBuilder();
Hashtable table = _memcached.Stats();
foreach (DictionaryEntry serverInstance in table)
{
Hashtable properties = (Hashtable)serverInstance.Value;
foreach (DictionaryEntry property in properties)
{
results.Append(
String.Format("{0,-25} : {1}
", property.Key, property.Value)
);
}
}
return results.ToString();
}
}
}Tip
String.Format() allows you to specify a variety of formatting options, such as the one used in Listing 6-10 to pad space between the first and second properties being appended to the results variable. It is similar in function to the object.ToString() overloads (such as the ability to specify currency output) but with a richer set of capabilities. An in-depth discussion of the String.Format() method is available in the MSDN library at http://msdn.microsoft.com/en-us/library/b1csw23d%28VS.100%29.aspx.
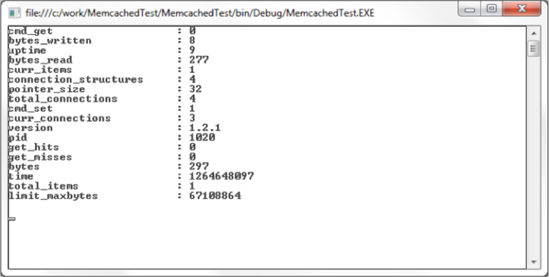
The most critical statistics provided in this output are get_hits and get_misses. These two values make up the cache hit ratio, which is a critical diagnostic metric in determining the health of the cache. Ideally the misses will be very low, although in production it will likely never be zero. The reason for this is that the typical pattern of cache item storage is first checking for the presence of an item in the cache. If it exists, return it; otherwise, take the necessary steps to generate the data and then store it in the cache. If you're in a situation where the get_misses field is high (or worse, higher than the get_hits value), then it's time to step back and examine the business logic that relates to the items in the cache because there is likely a serious flaw.
Tip
The Win32 version of Memcached is unfortunately not in lockstep with the Unix-based Memcached releases. The newer versions on the Unix side include richer statistics, including a property called evictions that will allow you to see the relative churn of the cache. Items are evicted by Memcached when slab space is low, so knowing how frequently this is happening can be a key step in slab optimization. In production environments, my personal experience (and what I hear from others) is that the Win32 port is fine for development and testing, but one or more dedicated Unix boxes hosting the most up-to-date version of Memcached are the norm.
In Chapter 2 we established data structures and code for handling individual pieces of content such that a user arriving at a page would have a combination of buckets and embeddable controls delivered to them to form a complete page. What we failed to address at the time was the creation of a tree structure suitable for describing the hierarchy of a CMS site in a navigable fashion. Now that we have a robust caching infrastructure, the creation of a tree structure will fill this gap as well as demonstrate some Memcached considerations that have been hinted at but not yet enumerated.
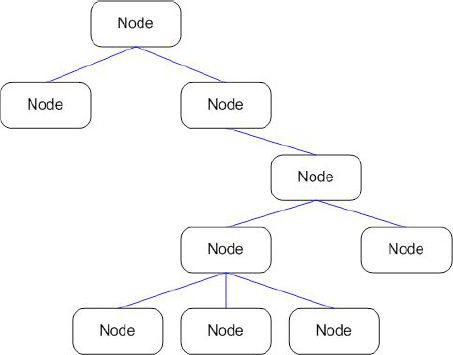
In the context of the CMS, the tree can be visualized as an unbalanced collection of nodes, which are object representations of the pages in the site. Each node can have zero to n child nodes, and each child node can have zero to n child nodes of its own, and so on. Nodes at the same level are referred to as siblings. The CMS tree is considered unbalanced because there is no requirement that a node have a specific number of children or siblings; there are other types of tree structures (such as binary trees) that impose such restrictions but are unsuited to the nature of a web site hierarchy.
Figure 6-12 demonstrates a representation of a typical unbalanced tree.
It seems an obvious first step to begin the construction of this tree by creating the Node object and populating it with relevant fields.
The code in Listing 6-12 demonstrates the implementation of the Node object in the CMS. There are some basic properties such as the ID of the content and the author, some search engine optimization features such as keywords and a description (covered more in-depth in Chapter 9), and some tree-specific settings such as a List of Node objects and a Guid indicating the immediate parent Node. It's not necessary to have a parent as the first Node in the tree, called the root, which by definition will not have a parent.
Example 6-12. Defining a Structure for a Node, Which Represents a CMS Page
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Business.SiteTree
{
[Serializable]
public class Node
{
// Basic settings (ID, who wrote it, etc.)
public Guid ContentID { get; set; }
public string Title { get; set; }
public string Author { get; set; }
public string FriendlyUrl { get; set; }
// SEO-specific settings
public string Keywords { get; set; }
public string Description { get; set; }
public bool Visible { get; set; }
public bool FollowLinks { get; set; }
// Tree-specific settings
public List<Node> Pages { get; set; }
public Guid? ParentID { get; set; }
public Node()
{
Pages = new List<Node>();
}
}
}Given that a Node object has a list of child Nodes, it seems that we have a sufficient structure and a Tree object is superfluous. The CMS (as implemented in a real-world production environment) had an additional stipulated requirement: although each site should have a home page that contains the majority of subpages, it's occasionally necessary to have one-off pages (called single pages) that don't live within the normal tree structure. These pages are typically promotional events or short-lived content that don't need to fall within the categories defined in the normal hierarchy.
Since we must have the capacity to have pages outside the normal hierarchy, we'll need to create a Tree object that can hold our Nodes in a flexible way. Listing 6-13 demonstrates the basic Tree object. Note that the Tree contains a List<Nodes> object. With this present, we can insert any number of Nodes at the top-level, and each one can have zero to n children. This meets the business requirements of the system while offering us an object that can wrap Nodes and provide useful functionality without cluttering the Node objects themselves.
Example 6-13. Defining the Structure for a Tree
using System;
using System.Collections.Generic;
using System.Linq;
using System.IO;
using System.Runtime.Serialization;
using System.Runtime.Serialization.Formatters.Binary;
using System.Text;
namespace Business.SiteTree
{
[Serializable]
public class Tree
{
#region Public Methods
public List<Node> Pages { get; set; }
/// <summary>
/// Initializes the list of page nodes
/// </summary>
public Tree()
{
Pages = new List<Node>();
}
#endregion
}
}Note
The Tree class has also been marked with the Serializable attribute to facilitate storage in Memcached.
Now that the Tree supports a list of Node objects, we need a way to find a specific Node at some unknown level within the Tree. As has been the case throughout the system, we'll begin with the intended usage and work backward so that our API is clean and usable. Listing 6-14 demonstrates a simple way to retrieve a specific Node from the Tree.
Example 6-14. Finding a Node Within the Tree
// Create an instance of a tree; assume for now that it has been filled with Nodes Tree site = new Tree(); // Create a GUID that represents content
Guid contentID = new Guid("9aafa5d0-c20f-41de-9c04-b8284c8cc4cb");
// Get a complete Node object using only the GUID
Node page = site.FindPage(contentID);Ideally, all we will need to know about a page is the GUID that uniquely identifies it in the CMS. Based on that information, we shouldn't need to concern ourselves with how to search through the tree or how many levels deep we need to go to find the Node in question. This API means we can fire and forget and let the Tree back end figure out the logistics for us.
Listing 6-15 shows an implementation that permits this type of functionality. Note that we have split the methods into two regions: Public Methods and Private Methods. The public-facing methods should be as simple as possible, calling one or more private methods to accomplish the required functionality.
Note
The total implementation for the Tree class is moderately long at approximately 270 lines of code, including the XML comments for each method. As such, we'll walk through only the most relevant methods in this chapter; for topics such as reordering Nodes or arbitrary relocation, the downloadable code for this book will serve as demonstration.
Example 6-15. Implementation for Finding a Node Within the Tree
namespace Business.SiteTree
{
[Serializable]
public class Tree
{
#region Public Methods
public List<Node> Pages { get; set; }
/// <summary>
/// Initializes the list of page nodes
/// </summary>
public Tree()
{
Pages = new List<Node>();
}
/// <summary>
/// Finds a page node for a given content ID
/// </summary>
/// <param name="contentID">the unique identifier for the content</param>
/// <returns>The page node for the content ID provided</returns>
public Node FindPage(Guid contentID)
{
Node page = new Node();
Search(this.Pages, contentID, ref page);return page;}#endregion#region Private Methods/// <summary>/// Recursively searches the tree structure for a page node/// </summary>/// <param name="tree">The list of page nodes</param>/// <param name="contentID">The page node content ID to search for</param>/// <param name="page">/// A reference to a page node that is filled by the method/// </param>private void Search(List<Node> tree, Guid contentID, ref Node page){foreach (var p in tree){if (p.ContentID == contentID){page = p;}else{Search(p.Pages, contentID, ref page);}}}} }
The Search() method operates in a recursive fashion; if a specific Node is not properly matched at the current level, the method will be called again, and the current Node's children will be provided as the first parameter. This permits a top-down search of the structure until (and if) a match is found.
Now that the Tree provides a way to find Nodes located at any depth, we need a way to insert them. If a Node has a parent, we'll need to use the FindPages() method to first locate the parent, and then we'll insert the Node as one of its children. If no parent is supplied, we can assume that the Node lives as a top-level single page.
Listing 6-16 demonstrates our intended manner of Node insertion, assuming that there is a Node already defined called ParentNode. Leaving the second parameter as null indicates a top-level page.
Listing 6-17 contains the implementation for inserting a Node based on whether a parent is provided. If a parent ID is provided, the FindPage() method is used to retrieve that Node from the Tree, and then the Node to be inserted is added as one of its children.
Example 6-17. Inserting a Node into the Tree namespace Business.SiteTree
{
[Serializable]
public class Tree
{
#region Public Methods
/// <summary>
/// Inserts a page node below a particular parent
/// </summary>
/// <param name="page">The page node to insert</param>
/// <param name="parentID">
/// The nullable parent ID; pages without a parent ID are top-level pages
/// </param>
public void InsertPage(Node page, Guid? parentID)
{
if (parentID.HasValue)
{
Node parent = FindPage(parentID.Value);
page.ParentID = parentID.Value;
parent.Pages.Add(page);
}
else
{
this.Pages.Add(page);
}
}
#endregion
}
}Serializing an object in binary form is extremely easy in the .NET Framework, taking only a few lines to implement. The code in Listing 6-18 is all that is necessary to handle this functionality.
Example 6-18. Inserting a Node into the Tree
namespace Business.SiteTree
{
[Serializable]
public class Tree{
#region Public Methods
/// <summary>
/// Serializes a tree using binary serialization
/// </summary>
/// <returns>A MemoryStream containing the serialized information</returns>
public MemoryStream SerializeTree()
{
MemoryStream ms = new MemoryStream();
IFormatter formatter = new BinaryFormatter();
formatter.Serialize(ms, this);
return ms;
}
/// <summary>
/// Deserializes a binary serialized tree
/// </summary>
/// <param name="serializedNode">The MemoryStream object containing the tree</param>
/// <returns>A deserialized Tree object</returns>
public Tree DeserializeTree(MemoryStream serializedTree)
{
IFormatter formatter = new BinaryFormatter();
serializedTree.Seek(0, SeekOrigin.Begin);
return (Tree)formatter.Deserialize(serializedTree);
}
#endregion
}
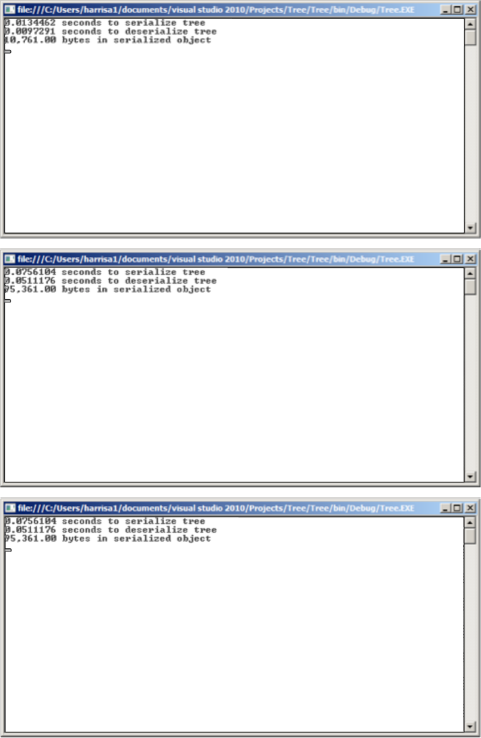
}The tree is very responsive even as the number of objects grows considerably. Figure 6-13 shows the output of three different tests; in the first, a Tree object was created, and 200 Nodes were inserted at random depths. The second test used 2000 Nodes, and the third used 20,000. Even at a size of 20,000 Nodes, the Tree could be serialized in approximately .80 seconds.
At this point, we have developed a Memcached wrapper that facilitates the quick storage and retrieval of items from the cache, and we've also developed a custom tree structure that supports binary serialization.
Earlier in the chapter, we examined the Memcached concept of slabs as a form of custom memory allocation. Objects being inserted into the cache (or updated within it) are automatically placed in the slab container best suited to the size of the object in question; if a slab can't contain an object because of a lack of available space, then an existing object will be evicted. Under heavy load, this creates a potential performance bottleneck as potentially large objects will constantly be entering and leaving the cache.
Refer to Figure 6-2, which describes each of the slabs as configured automatically by Memcached. Figure 6-14 shows the size of a serialized Tree that contains 2,000 Nodes. Based on the slab allocations and their chunk sizes as shown in Figure 6-2, we won't be able to fit many Tree objects of this size in the cache before we begin to run out of space and evict items.
In the case of Figure 6-14, the object is 95,361 bytes. Memcached will then look at the slabs to find the most appropriate size; according to Figure 6-2, that would be slab 33 as the chunk size is 105,840 bytes. A chunk can be thought of as a container for an object; our 95k object fits in a chunk suited for objects between 84,673 bytes and 105,840 bytes. Slab 33 can currently hold 9 of these chunks. Once 9 chunks have been filled, objects will begin to expire from the cache.

This is the reason we created the Tree object at this point in the book. It is a real -world object with a demonstrable size consideration that highlights the need for Memcached configuration to avoid what can quickly become a very serious performance bottleneck. Memcached supports a variety of configuration options that can aid in performance tuning, although some understanding of the Memcached slab allocation structure is necessary. For example, the slab size is dictated by a multiplier against the base size; the default of 1.25 produces the slab sizes shown in Figure 6-2. Figure 6-15 shows what happens if we set the -f parameter (which stands for "factor") to 6.0 instead of the default 1.25.
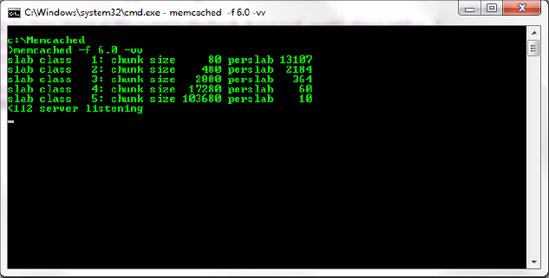
With the default Memcached configuration, we could hold 9 objects in the appropriate slab; by reconfiguring to a different growth factor, we have 60 available chunks (an increase of approximately 6.7 times) in the appropriate slab and should experience less cache churn as a result.
This is just an example of how to adjust Memcached for the type of object being stored; the growth factor in your slabs will be dictated by the size of the Tree objects you're storing, as well as the size of any other objects you plan to store. For instance, if you don't plan to host more than one site within a CMS instance, you can probably get away with the default slab configuration. If you plan to host 20 or 30 sites, you will likely need to segment slabs accordingly.
Memcached excels with small objects but can quite capably handle larger ones like our Tree. Understanding how the cache allocates space and determines where objects live is critical to identifying performance issues and (where possible) eliminating them before they cause you a headache.
Tip
I can't emphasize enough the importance of planning for caching early and implementing it late, coupled with careful evaluation of metrics gathered on objects that are destined for life in the cache. Identify the performance bottlenecks, and resolve what can be resolved in code or configuration; then look to caching to aid where appropriate. A distributed cache is of no use to you as a developer when it is constantly expiring items because they don't meet default size conventions, and a performance problem hidden by the cache remains a problem to be addressed (sooner or later).
In this chapter, we learned about Memcached and the problems that it solves when scaling outward in a high-traffic environment. We installed the Win32 version of the Memcached server and built custom libraries to wrap communications with it. Finally, we created a serializable tree structure for the CMS and used it to demonstrate why configuration of the internal Memcached slab allocation can be critical to the success of the distributed cache performance. Moving along, we'll look at how to implement a custom scripting solution into the CMS using IronPython, and we'll explore both the language and the benefits it offers to us as developers.