
C H A P T E R 2
How Web Sites Work
Why is it that the simplest of questions have hideously complicated answers? On the surface, the Web is quite simple—at least in how it is actually used. Under the covers, though, the systems that work together to make the World Wide Web possible are complex and they interact in various interesting (and often frustrating) ways. We’re not kidding when we say that it took about six drafts of this chapter before we had something we were reasonably confident addressed this question sufficiently!
In most cases, we can get away with saying that the Web is simply a collection of documents that link to each other. If pressed further, we might mention web servers, dynamic and static content, HTML and JSON, and other things; this level tends to satisfy most people. For you, dear reader, we need to dig deeper. You need to understand where these beasts came from and what makes them work. Only then can you really get an instinctive feel for web performance.
We can hear the stifled groans already, but yes, we are going to talk about how the Web works and why. Yes, you’ve probably heard it all before or accidentally read about it during a Wikipedia marathon. For those of you hoping we have some insider information about the birth of the Web, we’re afraid we’re going to disappoint you. We promise, however, that it is important to revisit this stuff, and we’ll tell you why.
The Guide to Assembly Language Programming in Linux (by Sivarama P. Dandamudi; Springer, 2005) is a very good book. Although it teaches assembly, you won’t see any mention of assembly until you’re nearly a third of the way through. The first thing it teaches you is the concept of Boolean logic, and from there, how you can implement the most simple logic gates (such as AND, OR, and NOT) using transistors. It takes around 5 nanoseconds for a transistor to “react” to a change in input. That sounds fast, but when you have millions of them working together, all of a sudden you can see a performance hit. You learn how memory is constructed from 1 bit to a multi-gigabyte array and how the processor addresses it. Why is any of that important? It’s important because when you start looking at writing in assembly you know precisely what each command you execute involves, how long it will take, and why. It means you can pick the best commands for a given situation, and you can optimize your code to leverage your chosen architecture. You wouldn’t have been able to do any of this if you hadn’t first learned about logic gates.
In this chapter, we hope to take a leaf from that book and take you back to the beginning. We3 won’t spend too much time in the past, certainly not a third of a book, but we will look at how we got to where we are today. We will look at what the Web was created to solve and some of the challenges we’ve seen since. We will then look at the network protocols that support the Web and some of the hot spots for performance issues.
Let the Games Commence!
When you view a web page, a surprising number of things need to happen before you get to see the page in all its glory. The good news is that from a user’s point of view all they have to do is type in the proper address—and thanks to Google even that isn’t really important any more. However, you shouldn’t confuse simple with simplistic. The web as you see it today is made possible because of myriad systems that all work nicely together in order to create the appearance of a single system. If any one of these systems were to fail, it would significantly impact your ability to browse the web—and in many cases would stop it all together.
Coming from a Non-IT Background
Many people have come to building and managing web sites from backgrounds other than the traditional IT route. In fact, some of the best web designers we know have very little in the way of computer science knowledge; it’s really their creative side that has made them successful at what they do. The technicalities of making a web site work and the infrastructure to run them is often just a cost of doing business; it’s a necessary evil and not something they have a particular interest in. Unfortunately, these folks may be unaware of certain technical issues that they really should address, such as SQL injection attacks and cross-site scripting. (Of course, not everyone falls into this category; many people who develop web sites not only have a grasp of the underlying technology but actively develop and enhance it to the point where they are redefining some of the basic concepts of the Web itself.)
Before I can talk about how to make web sites fast, I need to talk about what makes web sites slow. Some of this information may be obvious but a lot of it is hidden in plain sight; it isn’t until you actually think about it that you start to realize the significance of some of things that you take for granted.
Kicking Off the Process
Loading a web page starts on the user’s computer with their browser. She enters the address for your web site and hit the Enter button. Already there are several pieces at work here. First, the browser has an impact on the way the web site is loaded, including the order files are requested, the way the page is rendered, and much more. The browser is also impacted by the operating system and the computer that it’s running on. Older operating systems may not take full advantage of available system memory (such as any 32-bit version of Linux or Windows) or be able to efficiently use the multi-core CPUs that have been become standard in recent years. Operating systems are, of course, limited to the resources made available by the computer they’re running on. Even today’s low-cost computer would seem simply incredible to any computer scientist 10 years ago; today, though, it may already seem sluggish and far from high performance. Moreover, computers have moved far beyond the tower sitting under your desk. Every day more and more people browse the web from their phones and tablet devices. These devices have very different performance profiles than desktop computers and usually support a smaller range of features (though not always).
This is just the first stage of browsing the web and already I’ve identified several significant issues that affect how to deliver high-performing web sites. Clearly it’s not simply a case of bigger and faster servers; it doesn’t matter how fast your servers are if the browser blows up when it tries to access your page.
Finding the Site with DNS
So the user has pressed the Enter button and is eagerly awaiting your web page. First, her computer needs to look up the IP address of your web site. Computers can’t use the URL directly; it must be converted to the numerical address that is used on the network itself. All computers attached to the Internet have been configured with at least one (and usually two) DNS servers. This is normally part of the automatic configuration done when the computer requests an IP address either from your router or your ISP. So, before the browser can even think of connecting to your site, it needs to wait for the OS to contact the ISP’s DNS server to ask for the right address. Because there are so many computers on the Internet, no one computer can know all the answers. In other words, unless your web site is the next Facebook or Google, it’s pretty unlikely that the user’s ISP will have any idea what the address should be. So another request is made to another DNS server, which is also unlikely to know the answer. However, it can point to a server that might know. So yet another request goes out to the latest DNS server, which may or may not know the answer and may instead refer to another server. This goes on until it finally reaches a server that does know the answer. The answer is then passed back to the user’s computer and at last she can start the process of connecting to the site.
If this process sounds tedious, it’s because it is. However, it’s also far better than the original solution, which involved copying a massive text file around. Thanks to caching and the small amount of resources DNS requires, a look-up from a human point of view is actually pretty swift and almost instantaneous. However, if your domain is sitting on an old yellowing PC in the corner of the office and serves results via an extremely busy ADSL line, it might actually take a second or two for that server to be able to respond to a user’s request. Even if the web site is on a super-fast server with the world’s faster Internet connection, if it takes two seconds to find that server, then your web site will always appear slow.
DNS is often overlooked and it shouldn’t be. Not only is it critical to the speed of your web site, it also offers some easy ways of doing load balancing and ramping up the perceived speed of your site. That said, if you’re hosting your domain with a half-decent provider, you are unlikely to have any trouble with this aspect.
Connecting to the Server (Finally!)
Now that the user finally has the address, she can start connecting to the remote site. To make a very long story slightly shorter, the web runs over TCP, a protocol that guarantees all data is delivered and (just as importantly) arrives in the order in which it was sent. As developers, we can take this ability for granted. One of the key design goals of TCP is that the developer doesn’t need to worry about how TCP performs its magic. However, this magic has its trade-offs. In order to provide these guarantees, it has to do a lot of work under the covers. TCP’s companion protocol UDP is far lighter than TCP but it makes none of the guarantees that TCP provides. UDP packets can (and do) get lost in transit, and they can (and do) arrive in any order. Of course, you can write your software with this in mind to give UDP similar properties to TCP, but unless you have a very specific reason for this, you’ll probably find you’ve just recreated TCP.
What can you do about this overhead? Well, you can’t replace TCP even if you wanted to. Every web browser and server uses TCP, so if you want to be able to talk to the rest of the world, you need to comply with the same standards as everyone else. However, being aware of how TCP works and the process involved in providing these useful guarantees will allow you to make the most of the resources and thus limit the overhead to just the bare essentials.
On the Server Itself
Okay, now we’re at the connection to your site and it’s only taken six sections to get that far! You send the request for the page and now you pass over control to the web server. At this stage, pretty much anything can happen. Is the page requested a static page being loaded from the disk? Is it a page that’s created on-demand in real time? If it’s a dynamic page, does it require access to a database? Does it need to make requests of its own to other web sites? Is any of the data cached?
Web servers are not born equal. For example, the Apache web server out of the box on most Linux distributions isn’t particular efficient in either CPU or memory usage. However, it does tend to just work and it offers plenty of support and documentation. If you want a small server that’s designed for serving static files at high speed and eats very little resources, you might want to look at nginx. (This isn’t to say that one is better than the other, simply that their target audiences are different.)
![]() Note At this point, some people will be shouting out that Apache can be slimmed down and can compete with nginx. While it is true that you can tweak Apache and remove as many of its modules as you want, why would you bother when there are servers available that were designed for your particular use case? Actually, there are some good reasons, such as only having to learn how one web server works and how to configure it. That said, ask yourself whether stripping down Apache is really any easier to maintain or support than simply installing a server that is already optimized to do what you want out of the box. Like many things in IT, it comes down to personal preference. As long as you have good reasons for your choice, you can use whichever sever you feel is the best fit for your needs.
Note At this point, some people will be shouting out that Apache can be slimmed down and can compete with nginx. While it is true that you can tweak Apache and remove as many of its modules as you want, why would you bother when there are servers available that were designed for your particular use case? Actually, there are some good reasons, such as only having to learn how one web server works and how to configure it. That said, ask yourself whether stripping down Apache is really any easier to maintain or support than simply installing a server that is already optimized to do what you want out of the box. Like many things in IT, it comes down to personal preference. As long as you have good reasons for your choice, you can use whichever sever you feel is the best fit for your needs.
Next up is the programming language used to develop the site. Different languages and frameworks have difference performance characteristics, but this is really too specialized for a general book on performance; you can find a great deal of information about the various platforms and languages online. Not all of the performance tuning will necessarily work for you; use your discretion and test the solutions to see which help you the most.
Talking to the Database
Once you get past the language, you’re now looking at the database. Most dynamic sites have a database of some sort that they use for storing either content or information that the user wants to query, such as statistics or scientific results. Even the simplest of web sites may use a database for storing information on site hits or for providing a member’s area. Again, each database has its own pros and cons—as well as a long list of supporters and (more often than not) detractors. If you exclude web sites that need to contact other web sites to generate a page, databases are by far the slowest parts of any web application, even if they are in real terms extremely fast. Caching greatly helps here and is something you will look into in the next chapter.
Quick Look at Caching
Depending on the site itself, there might be some sort of caching involved. Few developers, in our experience, really get their hands dirty with caching; most tend to use whatever the languages or frameworks provide by default. This can range from excellent to non-existent. Usually the server or application looks in the cache before doing expensive calls to the database or content generation, so usually it greatly improves performance rather than impacts it negatively. Again, you’ll get hands-on with this in Chapter 3.
If the web site has to make use of other external web resources, you can almost replicate this whole “load a web page” process again for that stage. This is more common than you might think, as many web sites act as middlemen or brokers for other services. For example, resellers often have access to a back-end system via a web API such as SOAP or REST. When a user wants to sign up for, say, ADSL, she puts in her details into a form on the web site and presses the Enter button. The web site collects this data and then sends a request to the actual supplier to run the check for them. SOAP and REST use HTTP, so it’s very similar to a standard browser request. If the back end itself needs to contact other services (again, not too unusual; a reseller might contact a broker who contacts the actual supplier) then the chain can get even longer.
If your web site contacts back-end services like this, you need to factor their response times into your system design and see if there is any way you can minimize the impact to the end user. For example, you could show a “Please wait” page so at least the user knows something is still happening in the background.
Back to the Client
All being well, the server now (finally) sends the page back to the user. This is where the browser has to render the page so that the user actually gets to see something. We won’t talk much about the browser seeing as we already bored you with that earlier; suffice it to say that if your page contains twenty images and some external JavaScript and CSS, the browser will need to repeat this loading process for each of these resources. In a worst case scenario, on a very busy page this could mean hundreds of requests to the server. In other words, the process you have just followed is just for one file; it has to be repeated for as many files as the page requires, which could be substantial.
And so ends this quick look at loading a web page. I’ve deliberately glossed over things such as server hardware and available bandwidth as we’ll talk about these issues in more depth later in this chapter. However, you should now have a greater understanding of the intricacies involved in loading even the simplest of web pages and the myriad factors that can slow down your site. Throughout the book, I will look at many of these and demonstrate how you can either mitigate them entirely or at least manage them as much as possible.
The rest of this chapter takes a more in-depth look at some of the highlights from the previous section. Again, the plan is to give you a general idea as to what’s going on in the background so that as you progress through the coming chapters you will have an understanding of how the solutions they provide fit into the grand scheme of things and thus how you can best use them to your advantage.
Taking a Closer Look
After that whirlwind tour you’re either regretting picking up this book or you’re starting to see that making web sites go faster is not quite as simple as it might appear. It’s true that you can get very big gains from even simple optimization, but now you know where these optimizations take effect and why you get the benefits that you do.
To round out the chapter, we’re going to look at some of those key areas again, only this time we’re going to dip into more of the technical aspects. For example, we’ll look at the composition of a web page, the format it’s stored in, and how this affects the performance of your web site. As before, this is not intended to be a comprehensive guide to each and every topic. Entire books can (and have) been written on these individual subjects alone. Instead, think of the rest of this chapter as some of the choicer bits. You will no doubt come up with a lot of questions, many of which will be answered in the rest of this book. For those questions that we haven’t anticipated, we encourage you to use your favorite search engine to unearth the answer. If you have a question, you’re probably not the first; it’s often amazing (and humbling) to find entire discussions from years past where your exact question was answered and debated.
The following sections are broken down into various key areas. We start off by looking at the network layer, which includes examining how TCP and DNS work as well as examining the differences between speed, bandwidth, and latency. I then look at the component parts of a web page, specifically HTML and its related text format, and discuss the pros and cons as well as how to get an easy boost using compression. I also look at the concept of hyperlinks and what this means for performance. Next, I take a quick look at how web content is generated and the differences between static and dynamic content. I also briefly look at how this has developed over the years from a performance perspective and how this effects how you should serve the content. I also very lightly touch on the browser itself, and finally, on why databases are the weakest link in terms of performance and why even very simple caching can make incredible differences to performance.
The Network
The two key network-related things as far as web performance is concerned are TCP and DNS. DNS provides the means to find the server you want to talk to and TCP provides the mechanism for moving the data to your browser. I will also take a very quick look at the differences between speed, bandwidth, and latency—and why they aren’t the same thing.
TCP
Here’s the deal: if you promise not to fall asleep while we very briefly talk about TCP and how it works at a basic operational level, we will promise not to include yet another pretty picture of the OSI network stack or to bore you to death with tedious RTT (round-trip time) calculations. Deal?
TCP is one of the two key protocols used on the Internet today, with the other being UDP. These two protocols are used for very different purposes and have very different characteristics when they’re used. The interesting thing, though, is that really there’s only one major distinction between the two and all of the differences extend from it. Basically, TCP is reliable and UDP is not.
For that to make much sense, I need to take a step back and look at the Internet Protocol (IP) itself. It’s no accident that you usually see TCP/IP written together (although historically it’s actually because IP evolved from an unrelated TCP). Previously, it was something of a challenge to make different networks talk to each other. Either there were different network technologies at a hardware level (Ethernet, Token Ring, serial links, and so forth) or they had their own weird and wonderful protocols that wouldn’t talk to anything else (NetBEUI and IPX/SPX, for example). The other problem was that networks were fairly static and didn’t handle failure very well. If a key distribution point failed, it could cause the whole network to fail. This is far from ideal at the best of times but something you really don’t want in your critical infrastructure, such as emergency services or nuclear command and control systems.
IP solved this problem by creating a protocol that didn’t require static networks. By putting the address information into each packet and moving responsibility for delivery to the network itself, IP was able to “just work.” For example, when you send a packet, it goes to your default gateway. If that is your modem or router at home, it likely knows of just one gateway, the one at your ISP. Your router then passes the packet to the ISP’s router. Your ISP knows many more routes but they are usually generic; by this we mean the router might not know the exact location of the destination computer, but it does know which router it knows about is closest to the destination (and thus hopefully also the fastest). The router then forwards the packet on to that router, which repeats the process until the packet finally reaches its destination. This process is done for every packet you send and receive.
Because handling packets like this can be done in a stateless way (the routers don’t need to know anything about the packet other than the details provided in the header), they don’t need to remember packets they’ve seen before or keep any complex statistics. Each packet is treated individually and so this system can scale nicely. This is a concept you will see many times in this book.
This system has another benefit. The list of available routers (usually referred to as a list of routes) is dynamic. Each router maintains its own list but only knows about a couple of routes (though some core routers may know many more than this). If a router stops responding, routers will stop sending packets to it and will pick the best alternative route from their list. In fact, it’s quite possible that for a given connection that sends ten packets, each one could have been sent via a completely different route.
There is a problem with this system. The simplicity that makes it fast, efficient, and reliable in the sense that a single router failure won’t disable the whole network doesn’t offer any delivery guarantees. That is, as each router just forwards on a packet-by-packet basis and each packet can take a different route, there is no way to know if any went missing en route. We can’t add state to the network itself or we would lose the massive scalability that we’ve gained—and we’d be back where we started.
This is the problem that TCP solves. It uses IP to deliver and route packets but it guarantees delivery and the order of packets. From a developer’s point of view, once a TCP connection is established, what you send down one end is guaranteed to arrive at the other. To do this, TCP uses the concept of sequence numbers based on the amount of data sent. This information is ignored by the routers and only used by the computers at either end of the connection. So we can keep state but we only need to do it at the two end points, not all of the routers in between. By using the sequence numbers, it’s possible to determine if any data has gone missing as well as the correct order the packets should be delivered in. Remember, IP packets can take any route so it is quite possible and actually common for packets to arrive out of order. Of course, for this to work, the two computers need to do a bit of negotiation so that they start off on the same page. This is done at the beginning of the connection and is called the handshake.
A TCP handshake consists of three stages. They can be summarized (see the note for a more technical version) by the following:
Client: I want to open a connection.
Server: No problem. Do you still want to chat?
Client: Yup! Let’s go!
This needs to be done for each connection that is opened. When you download graphics from a web site, ultimately you use TCP to do the downloading. In earlier versions of HTTP, each request and response required a new connection; if you had to download 30 images, you needed 30 connections and hence 30 handshakes. Not surprisingly, if your connection speed is already less than awesome, the last thing you want is an additional 30 “empty” round trips to the server.
![]() Note Okay, the TCP handshake is a bit more formal than that but really it is as simple as it looks (see Figure 2-1)! If you look in a textbook you will find the handshake defined as SYN (for synchronize), SYN-ACK (the server wants to synchronize and is also acknowledging your SYN with an ACK), and ACK (the client acknowledges the server’s request). If you think it looks almost like you’re negotiating two connections at the same time, you’re spot on. Sockets are negotiated in both directions and this allows you to send and receive data at the same time. Cunning, eh?
Note Okay, the TCP handshake is a bit more formal than that but really it is as simple as it looks (see Figure 2-1)! If you look in a textbook you will find the handshake defined as SYN (for synchronize), SYN-ACK (the server wants to synchronize and is also acknowledging your SYN with an ACK), and ACK (the client acknowledges the server’s request). If you think it looks almost like you’re negotiating two connections at the same time, you’re spot on. Sockets are negotiated in both directions and this allows you to send and receive data at the same time. Cunning, eh?
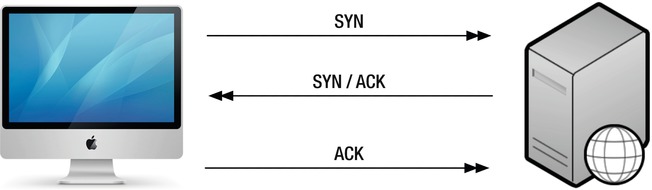
Figure 2-1. TCP Handshake
As promised, this part didn’t contain any discussion of the OSI layers and no RTT calculations. However, there are some important points that we’re hoping you will take away from this (very) brief tour of TCP. Every time you create a new TCP connection, you need to go through a handshake. There is simply no way around this; the only way to avoid a new handshake is to avoid opening a new connection. The second point is that packets can take any route to get from point A to point B. The idea is that the closest or faster router is chosen, but that isn’t guaranteed. It’s possible for packets to get stuck in a congested network just as cars get stuck on the motorway. This gives us the second golden rule: to avoid getting stuck in traffic, make sure that points A and B are as close together as possible.
DNS
Okay, now you know how data gets from the server to the client and vice versa but one thing I didn’t touch on is that IP has no concept of names. It only understands numbers. An IP address is usually represented as a “dotted quad” number and looks like this: 192.168.1.1. In fact, it’s just a 32-bit number that has been made a bit easier to read. While it’s nicer to look at, it’s still a nightmare to remember. Humans are inherently bad at remembering numbers. There is a reason we have phonebooks and why people write their PIN numbers on the back of their debit cards. Let’s be honest; if we can’t reliably remember a four-digit PIN number, what are the chances we’re going to remember the computer address for every web site we want to visit? And even if we could, what if the site has several computers or the address changes?
I go in to the history of DNS and how we ended up with the current system (and most importantly how you can exploit it to make your sites go faster) in the DNS chapter. For now, all you need to know is that you can change nice human readable names such as www.example.com into the address format that the computer needs.
The reason we’re mentioning DNS in this chapter is because although DNS is very efficient for what it does, looking up a name is not free. DNS looks like a big tree with each branch being the next level down. The top of the tree is the dot domain. The next level contains domains like .com, .org, and .hk. Under .com is example.com, and under example.com is www.example.com. Assuming no one has looked up this name for a while, you must walk the whole tree. It works a bit like sending out a messenger. You go to the top of the tree and ask about www.example.com. The top server doesn’t know the answer to your request but it can tell you who you need to ask for questions related to .com. So you go to that server and repeat your request. You get a similar response this time as well: it won’t know the answer to your question but it can point you to the server who knows about example.com. And so on and so forth until we get to the server that actually can answer our request.
This is admittedly a worst-case scenario. Most DNS servers cache requests and each computer keeps its own local copy. In reality, your own computer can often answer the question and your ISP’s server (your first port of call usually) handles requests from every customer, so they are likely to have the results for the most common sites already to hand. Sites like www.google.com and www.facebook.com are almost guaranteed to be permanently cached.
I won’t look at the cool things you can do with DNS in this chapter but the key take-away point for this section is that although looking up names is not exactly slow, you take a slight performance hit each time you do it. In other words, the less names you use, the better; then, in a worst case scenario where all the names have to be looked up, there are fewer requests that need to be sent.
Speed, Bandwidth, and Latency
Speed, bandwidth, and latency are the source of much confusion and pain for a lot of people. Everyone intuitively understands speed but the other two have definitions that, while quite simple, do sound very alike. Bandwidth is the amount of data a given connection can transfer in a particular amount of time. This is generally measured in bits per second. Latency is the time it takes for a given request to receive a response. This has a more precise definition but practically everyone measures it with the ping command. This command measures the time it takes for a small packet to reach a given server and for that server’s response to reach the client.
The confusion stems from the idea that the more bandwidth you have, the faster your Internet connection is. That’s not technically true. The more bandwidth you have, the more data you can receive at a given time. So, yes, it takes less time for the data to arrive—but the time taken to actually send each bit of data might actually be slower than a connection that has less bandwidth.
Confused? ISPs have spent the past 15 years telling everyone how if you upgrade to their latest and greatest connection you will get everything so much faster, so you’d be forgiven for thinking that we’re talking rubbish. After all, downloading the same file takes 30 seconds on one connection and 60 seconds on the other. Quite clearly one downloads the file quicker than the other, so how can the slow one actually be faster?
Here’s an example that actually makes sense. Imagine two cities that are 100 miles apart. Connecting them is a single road with one lane heading from City A to City B. (For some reason, people who go to City B never want to go back to City A.) Let’s say that you drive your car from City A to City B at a fixed speed of 50mph (ignoring the fiddly bits of acceleration and laws of thermodynamics so it can cruise perfectly at 50mph from start to finish.) How long does it take your car to get from A to B? Well, if the distance is 100 mph and your car moves at 50 mph, it’s going to take you two hours. Okay, that wasn’t exactly taxing but what if there are 10 cars that need to get from A to B? Let’s say for safety reasons, that there must be a 30 minute gap between each car. This is now getting a bit more complex. Have a look at Table 2-1.

This is getting more interesting. The trip time for each remained the same at 2 hours, but it actually took 6.5 hours for all of the cars to arrive. Now imagine you are a holding an important meeting and you need all 10 people to turn up before you can begin. Your first person turns up at 2:00 p.m. but the last guy doesn’t turn up until 6:30 p.m., five and a half hours later. Not ideal.
Now let’s look at a slightly different scenario. Let’s say that the road contains two lanes. The same rules apply as before: one car can leave every 30 minutes and it travels at a perfect 50mph. Table 2-2 shows the same scenario on the new dual carriageway.
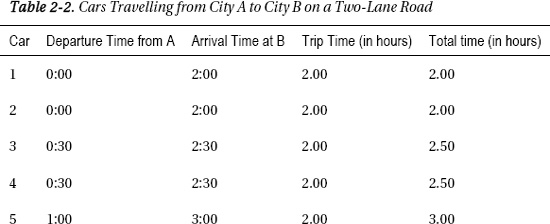

Adding an extra lane has cut 2.5 hours off the total waiting time. The meeting can begin at 4:00 instead of 6:30, which is definitely an improvement. But is the road any faster than it was in the previous example? The answer is no. In both cases the cars travelled at the same speed. The latency was the same; it was the bandwidth that changed.
Let’s take this example even further by considering 10 lanes of traffic. In this case, all of the cars will arrive after exactly two hours. That’s not surprising but what happens if you increase the road to 20 lanes of traffic? You got it; it will still take exactly two hours. There are only ten cars and even if you could split them in half, you wouldn’t get any benefit because the bandwidth was already sufficient; the problem is now latency.
Let’s go back to networks and data transfer. The IP protocol uses small packets to send data. For most network tests, a packet size of 500 bytes is used as it’s close to the average sizes of packets on the Internet. Note that average sizes aren’t as meaningful as you might think because different protocols use different sizes. If you think this is cheating, now would be a good time to read the sidebar “Networking and the Facts of Life.”
NETWORKING AND THE FACTS OF LIFE
With this simplified model in hand, you can begin to see the difference between bandwidth and latency. If you need to send an image that is 100KB in size, you need 200 packets (100KB = 100,000 bytes). In two scenarios (one where you receive 10 packets at a time and one where you receive 100 packets), the one that can receive 100 packets will download the image in less time than the other connection. If each packet takes 1 second to get from the server to the client, the total waiting time is 20 seconds for the first connection and only 2 seconds for the second connection. The transit time for the packets is the same (1 second) in both cases, but the extra bandwidth in the second scenario means that more data could be transferred at a given time.
Generally speaking, the faster connection technologies do also boast lower latencies but that is not always the case. For example, some satellite-based Internet connections use the satellite for downloading but a modem for uploading (it’s expensive to have a satellite base station in your backyard). Even though the satellite can send data to you much faster than the modem, there is much higher latency because the data needs to be beamed to the satellite and then beamed back to your receiver. This process takes time. Once the transfer has started, it will download quickly. For those sorts of connections, you have very high latency (1,500ms compared to 300ms on dial-up, for example) but much higher bandwidth. This makes the connection fine for downloading large files, but you certainly wouldn’t be able to play games like Quake or Counter Strike on it; it would just be too slow. You would be seeing events two seconds after they happened, which means you won’t survive very long!
So what’s the take-away from this section? Latency and bandwidth are related but they’re not the same thing. When optimizing your web site and your content, you need to keep this in mind so that you can play to the latency and bandwidth available to you.
Network Summary
Hopefully that quick tour wasn’t enough to put you off. You should now have a pretty good idea how these technologies play a part in the speed of your web site. You learned the basics of TCP/IP—how it gets data from A to B and the overhead involved in accepting guaranteed delivery. You learned how the names of web sites are turned into the network addresses that TCP/IP uses to establish the connection and how that can play a part in web site performance. Finally, you learned the differences between latency and bandwidth, and why bandwidth and speed are not the same thing.
HTML and the Web
This section will be familiar territory for most of you, so we’re not going to spend much time on it. Much of this content might seem obvious, but these concepts underpin the majority of what you will read in this book so it bears going over again. If you have a complete grasp of HTML, feel free to skim this section, but do keep an eye out for the subheadings and see if anything catches your eye.
HTML
How many of you have really sat down and thought about what HTML actually is? How many of you simply use HTML (or perhaps even a WYSIWYG designer) as a means to create a pretty web site and leave it at that?
If you fall into the latter category, that’s not surprising; HTML was originally designed to be unobtrusive. It was designed to be a very simple way for academics (not programmers) to create documents that were easy to read, compatible on all systems that had the right viewer, and easy to link to other documents.
Today HTML5 has many more tags and a ton of extra functionality. It’s certainly more complex than what Tim Berners Lee originally came up with in the CERN lab a couple of decades ago.
They say that the more things change, the more they stay the same. A basic web page written in the originally HTML standard will still render quite happily (if more blandly) on a modern browser. So what else do HTML and HTML5 have in common? They are both text, and they both work by linking to other documents.
Why is Text-Based Important?
Being text-based makes things simple on many levels. For a start, humans can easily read and modify text files in any text editor. No special software is required. Yes, character sets such as Chinese, Russian, and Hebrew are more complicated, but they are still easier for humans to work with than raw binary data. The problem is that text is not the most efficient way to store data; in many cases, a binary representation would be far more compact.
For example, if you are using the ASCII character set (the de facto simple text standard) and you have a line consisting of ten zeros (0000000000), you need 1 byte per zero, so 10 bytes. There are numerous ways to rewrite this to save space. For instance, a simple system such as the character, number of times it appears, and a dot would give you “09.”. You can write 9 because you know the character must appear at least once. You’ve now only used three bytes in this example—less than a third of the original system. A more advanced compression system could potentially save even more, especially over bigger documents.
As usual, it’s a tradeoff. You get ease of use, creation, and storage—and a format that requires more space. If you look at an HTML or XML file where a lot of the space is taken up with tags and other overhead, you find that the content-to-overhead ratio is quite low. On the other hand, you can work with your document on any machine without special software. Also, generally speaking, text files make beautiful candidates for compression, which can often reduce their size by 90% or more.
The thing is, you don’t want to store the files compressed. True, you can compress them easily but then you have to decompress them before you can work with them. Also, hard disk space is cheap and text files are very small files. The reason you care about how much space the file takes up is not because it’s expensive to store; it’s because you want to send the page to the browser as quickly as possible—and the smaller the file, the faster it will get there.
To deal with this and make the solution as transparent as possible, all of the major browsers and web servers offer automatic compression. All you have to do is turn it on in the web server and you’re good to go. This is actually one of the few performance tweaks you can make that doesn’t really have any tradeoff, apart from a little processing power to actually do the compression itself.
So you can have your cake and eat it. You get easy-to-use files and you can send them over the wire in a compressed form. True, you might save an extra few bytes if you did something funky with the text but the benefits would be low and the pain you would cause yourself would likely be high. There are other ways to get even better performance.
Why is Linking Important?
Web sites are made up of documents that link to other documents. Even a simple web site consisting of three pages can actually be pretty complex when you think about it (see Figure 2-2). If you look at the source code for a page on Facebook, you can see that there are links to other pages but also links to resources needed for the current page. For example, all modern web sites require JavaScript libraries and CSS files. Web sites also require images for the layout and background—and the images used in the document itself. Many sites now embed video and music, too.
Think about this for a moment. If you need all these things in order to render the page properly, you can’t really show the completed page until all these files have arrived. Often they’re not being downloaded from the same site. There are ways around this. For example, when you add an image tag, if you specify the size of the image, the browser can render the page around it because it knows how much space it has to leave. If you don’t set that information, the browser can’t possibly know how big the image will be until after it has downloaded the image itself. That can take time, and meanwhile the page isn’t being rendered properly. In short, your page depends on many other resources, and your page will either not look right or not work properly until all those resources have arrived at their destination.
There are many ways to deal with this issue. In fact, a large part of this book is dedicated to showing you how to work around this problem. We’ll show you how to get the content to the user as quickly as possible while providing as much help to the browser so that it can do the right thing. So even if you’re waiting for a large image to download, the rest of your page will be readable and look nice.
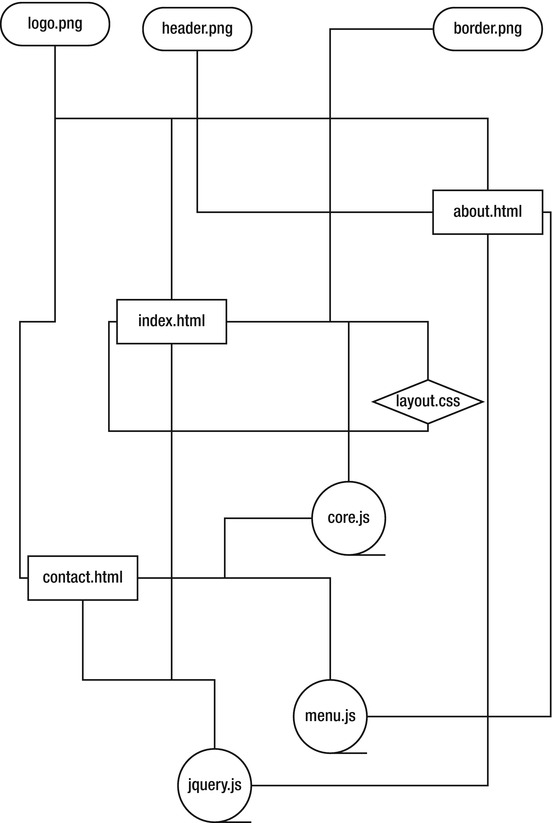
Figure 2-2. A simple web site that doesn’t look so simple
HTML Summary
HTML is the language for building web sites; as such, it’s the key tool in every web developer’s toolbox. However, with modern tools, an in-depth understanding of HTML is not required to make nice web sites, so it’s easy to overlook the potential issues you might be creating. Sure, a single page doesn’t take long to download, but what happens when a hundred people download it? What happens if they don’t have ADSL and are downloading over a modem or connecting to your site from another country? Often this side of performance tuning is not considered. Worry not; you’ll be looking at these issues and others later in this book.
The Browser
The number of possible browsers, versions, and plug-ins are quite staggering and none of them, as best we can tell, seem to work exactly how they’re supposed to. The developer’s nightmare used to be limited to trying to make a web site look the same in each browser; these days, that’s only one of many problems developers have to face. Trying to ensure that the JavaScript essential to the site’s operation works for everyone and that the style sheets apply in the same way (and look decent on mobile devices) are some new issues. Many excellent libraries have been developed to try to resolve these problems but there’s always something new to throw a spanner in the works.
Sadly, you can’t force a user to use a particular browser on their machine. You also can’t tell in advance which browser a user is going to use. The “best” browser seems to alternate on a monthly basis, so it’s not even easy to optimize for the most popular browser. Even though you can’t control it, the choice of browser certainly plays a part in how fast your site loads and thus the end user experience.
As an example, using a popular JavaScript charting package, a graph with a reasonably large number of points (around 80,000 or so) took 12 seconds to render on Internet Explorer 8 (and a warning about slow scripts) but only 4 seconds to render on Chrome. We’re not trying to start a fight over which browser is better, nor are we claiming that our experiment was in any way scientific or conclusive. What we can say is that people who viewed our chart with Internet Explorer complained that the graph crashed their browser or they hit refresh about 20 times before they gave up.
It’s not just JavaScript performance that can cause pain, either. Chrome supports WebSockets out of the box and we had no trouble hooking up a nice application to take advantage of it. Unfortunately, the best practice method for using WebSockets on Chrome doesn’t seem to work on any other browser, at least not without changing the source. Again, there are libraries (in this case, socket.io) that provide a nice, consistent interface across browsers, but this adds other issues, such as dealing with its dependencies. If you want to use the latest and greatest technologies, you need to make sure they work in all of the browsers you plan to support and that the performance characteristics are similar.
So what can you do about this situation? Apart from being aware of it, there isn’t a lot you can do. You need to take each browser’s personality into account when you develop your site so that you can provide a consistent service across all of the browsers. Sometimes this means you don’t implement certain features. Maybe you limit the special effects you use in a particular browser or use a different charting engine. Maybe you load the data in a different way on the slower browsers so that the user is at least aware that the site hasn’t crashed. While you can’t control the situation, you can at least attempt to manage it and lower the impact for your users. It’s unlikely that you’ll get it right each time, and it’s unlikely that nothing will ever slip through the cracks. However, if you’re aware of the potential for these issues to spring up and bite you, you’re already a step ahead of the game.
Web Content
There are really two types of content on the web today. Content is either static or dynamic. In many cases, the distinction has become somewhat blurred as static resources end up being used in a dynamic way. Generally, if you send a resource as-is, such as a file on a disk, the content is static. If you take a resource and alter it or combine it with another resource in some way, the resource becomes dynamic. In short, if you do anything that alters the content before you send it out, the content is dynamic.
One thing to watch out for with Web 2.0 is that rather than generating all the content on the server and then delivering it to the client all at once (the web browser used to be a glorified viewing application), the content can be delivered and updated throughout the time the user has the page open. AJAX, for example, allows a web browser to poll the server for new data. Newer technologies such as WebSockets allow a browser to maintain an open connection that the server can use to send data on demand. The data, and the type of data, generally remain the same even though it is delivered using a different mechanism. Sometimes it’s hard to say whether the data being delivered is static or dynamic.
Static Content
Static content is the most basic form of content. It is stored data that is used as-is over and over again. A good example is a company logo .jpg or your site’s CSS file. These files sit on the disk until they are requested by a browser. The web server opens the file, sends the content to the browser, closes the file, and that’s it. Because these files don’t need any special handling, you can make some assumptions that will help you improve performance. For example, you can place them on a server that’s optimized for sending out small static files. You can use a content delivery network to put these files closer to the users. With services such as Amazon’s Cloud Front and Rack Space’s Cloud Files, placing these files in various locations around the world for optimum delivery is both painless and effective.
Remember that you can only get away with this because the content doesn’t change and because you don’t need to do any special handling or checking. Restricting these files to certain users is more difficult to scale because wherever the file is, the request would need to be checked by your application before it could be released. The take-away: you can get some awesome speed boosts with static files, but they limit your flexibility.
Dynamic Content
All web applications make use of dynamic content. Any web page that responds to search requests or clicking buttons is generated dynamically. That is, a page has to be created in order to respond to request. Some requests are generic and can be cached (more on this later) but if you are showing content based on which users are logged in or you want to display real time statistics, it becomes much harder to cache this content as it is either time sensitive or specific to each individual.
There are techniques for accelerating dynamic content and they all have slightly different approaches. For example, Ruby on Rails offers a simple form of caching: after it creates a dynamic page, it writes the contents out to disk, making it basically just a normal static file. The web server is configured to try to read from disk before it asks Rails to generate the page. This makes for a very simple caching system but one that is very effective. The downside with this technique (and one that is common whenever caching is used) is that the content displayed to the end users may not be the most current. I look at this tradeoff in more detail in Chapter 3 and I touch on it again at the end of this chapter.
Creating Dynamic Content
As you’ve seen, web pages are simply text documents that are sent over the network. Whether or not that content comes from an actual file or the server generated it specifically for you is irrelevant as far as the browser is concerned. After all, it only cares about the HTML content, not how it was generated.
Originally, the Web was just static pages, making it effectively read-only. There were no forms, drop-down menus, or submit buttons. You could read content and jump to other documents or locations within documents, but that was pretty much it. The biggest benefit was that you could do this on any machine with a browser; apart from the browser, you didn’t need to install any special software. This was a big improvement over proprietary formats, and as it was simple to use, people were able to mark up their own content with little effort.
It wasn’t long before people started making little programs that could respond with web content. This meant you could view it in a browser but you still couldn’t interact with it as such. It was also difficult to program and maintain and a lot of boiler-plating was needed in every application. It was, quite frankly, a bit messy.
The CGI (Computer Gateway Interface) was developed to make everyone’s life easier by defining a standard that web servers could use to call programs that would generate dynamic content. This provided a standard way for a script (often written in Perl at the time) to receive variables from the web server about the request and to set variables and provide content for the response. Combined with HTML FORM elements, this provided a very easy way to communicate and generate HTML in real time.
It did have problems. Each CGI request would start a new copy of the program to deal with the user’s request. So if 20 people looked at your home page, you’d have to start 20 Perl scripts, including a full interpreter for each one. It was a performance nightmare; even a powerful server couldn’t scale very well under CGI. There were two main solutions to this.
- FastCGI implemented the same CGI standard, but rather than executing the script every time a request came in, the FastCGI process would start the script but would leave it open after the request. In this way, it was possible for a FastCGI instance to be re-used for multiple requests and thus save the overhead from starting each request from scratch. FastCGI was fairly successful and most web servers (such as Lighttpd and Apache) still offer it as a mechanism for generating dynamic content.
- The other approach was to embed the interpreter into the web server itself. Rather than open a new process each time a request arrived, the web server would pass the request to the interpreter that it already had in memory. Thus communication between the interpreter and web server was very fast because they were effectively the same process; they didn’t need to use any special protocol to communicate. It also meant that the web server could make other optimizations simply because it now had full control over the environment and the way the script was executed.
This was the state of affairs for quite some time; the modular approach was seemingly more popular than FastCGI, which tended to be fiddly to set up and manage. With the modular approach, you simply started your web server and you were done; it’s hard to get any easier than that. Interestingly, with the advent of some of the newer web frameworks, we appear to almost take a step backwards.
Ruby on Rails was originally single-threaded; it could only handle one request at any time. The first request needed to finish before the second was processed. On a small and simple site, this might not even be noticeable but if you wanted to scale out to thousands of users, well, even 10 users would probably feel the pain.
The solution was to do something similar to the FCGI approach where a standard web server would sit in front and receive all of the requests from the users and then forward those requests to numerous Rails instances running in the background. For example, you might have two servers each running 10 Rails instances (complete copies of your web site). Then you have your web server sit in front and spread the requests over these 10 instances. This added overhead in the form of network bandwidth and a bit of processing but it provided one huge advantage: you could add as many back-end servers as you needed to meet the load. You weren’t restricted to a single machine. The emphasis on being able to scale out rather than scale up is a recurring theme in modern software design and is the de facto standard these days for almost all new systems.
Web Content Summary
Content can be either dynamic or static. You’ve seen that, for performance reasons, it’s often desirable to make dynamic content static (as in the Rails caching system). In a similar vein to the discussions about the user’s browser, you’re usually limited by what you can make static and what must be dynamic content. It’s not always obvious, though, and an appreciation of the basic differences can help you decide the best course of action when planning what to do with your own web resources.
You learned how content is generated and the evolution of that process; you also learned how the Web started off as a simple way for reading documents and gradually evolved into the powerful system that we use today.
Databases: The Weakest Link
Databases are where most web applications spend the majority of their time; in fact, times in excess of 70% are not uncommon in many applications. It’s not that the database itself is inherently slow; actually, it’s often extremely fast. However, when compared to how fast the server can execute the software itself, the database just can’t match it. In many cases, the database has to hunt around on disk for the data—and accessing disk is enough to kill the performance of any application.
I look at databases in greater detail in a later chapter but for now the take-away is that generally speaking, database access is bad and should be avoided whenever possible. This is easier said than done, especially if it’s the contents of the database that you want to display to the end user. You can get around this by using caching but that, too, is a tradeoff.
One way to avoid hitting the database is to keep data somewhere else—somewhere very fast and easy to access. There are numerous solutions for this, and MemcacheD is one of the most popular solutions. In effect, when you generate your database content, you stick it in MemcacheD for later use. When you receive a request, you first look in the cache to see if you already have what the user wants. If you do, you simply send that content back and you’re done; no calls to the database needed. If not, you make the database calls as normal, but before you send the results to the user, you place it in the cache.
It sounds a bit painful but it’s actually really straightforward to implement—just a few lines of code for simple situations. So what’s the downside? After all, surely this massive performance boost isn’t free. Reading data back from memory rather than querying the database can make a web site much faster and scale from hundreds of users to many thousands. So what’s the catch?
The problem is that the data is not necessarily fresh. This may or may not be a problem. If your main database is only updated every five minutes, querying the database in the meantime will always return the same results. In this case, caching is a no brainer because you have nothing to lose. You can even generate the page in a separate script and just update the cache when it’s done; this way no one ever sees a slow page.
However, if you want to restrict data or generate different data for different people, you have to do more work to make caching beneficial and support your needs. If it’s imperative that users always get the latest data (which updates constantly), you simply can’t cache it—but maybe you can cache the data around it. Or if two user requests come within a certain period of time, the same data could be sent to both. There isn’t a one-size-fits-all solution, but there’s usually something you can do.
Summary
This chapter covered a lot of diverse ground in a relatively small amount of space. You looked at the processes involved in viewing a web page and saw how many individual and unrelated systems need to work in perfect harmony for the World Wide Web to work. As each of these areas has their own performance issues, each area needs to be considered when developing a performance strategy.
You then learned some of the more interesting issues that affect web performance, with a focus on the network, the browser, HTML, how the content is generated, and how you can get the most bang for your buck when it comes to using databases.
The overall focus of this chapter has been to highlight the diverse nature of the ecosystem that powers the Web and how a simple one-size-fits-all performance solution either won’t work or won’t offer optimal results. Although we didn’t mention types of Internet connections, server hardware, infrastructure, and other potentially obvious items, this doesn’t mean that they aren’t important; I just wanted to focus your thoughts on some of the unsung heroes of the performance world.
In the next chapter, you will take closer look at caching. Even the simplest of changes can make a huge difference to the performance of a web site. Caching is generally easy to set up, easy to use, and offers big gains in terms of performance. It’s a great place to start tuning your web site for ultimate performance!