
![]()
XML and JSon Processing
XML (eXtensible Markup Language) has been used in the Java EE platform since the beginning of deployment descriptors and metadata information. We deal with XML in persistence.xml, beans.xml or ejb-jar.xml files. That’s often how Java developers first entered the rich world of XML. But we quickly discovered that there was more to XML than just deploying a web application or an EJB.
XML is an industry standard defined by the World Wide Web Consortium (W3C). Although it is not tied to any programming language or software vendor, it has solved the problem of data independence and interoperability. Because XML is extensible, platform-independent, and supports internationalization, it became the preferred language to interchange data among software components, systems, and enterprises (e.g., by leveraging SOAP Web Services that will be described in Chapter 14).
On the other hand, JSON (JavaScript Object Notation) originated with JavaScript for representing simple data structures in a less verbose manner than XML. To be precise, the JSON format is often used for serializing and transmitting structured data over a network connection. It rapidly became so popular that today recent web browsers have native JSON encoding/decoding support. But, in addition to its relationship with browsers and JavaScript, JSON works nicely as a data interchange format (e.g., extensively used in RESTful Web Services; described in Chapter 15).
In this chapter, I will describe both XML and JSON formats focusing on the document structure and the APIs to manipulate these structures. The XML world is richer, so you will notice that several specifications help you in parsing, validating or binding XML to Java objects. It is so ingrained in our ecosystem that most of these XML specifications belong to Java SE. JSON is a relative newcomer in the Java platform and therefore has less standard support in Java SE/EE.
Understanding XML
The eXtensible Markup Language (XML), derived from the Standard Generalized Markup Language (SGML), was originally envisioned as a language for defining new document formats for the World Wide Web. XML can actually be considered to be a meta-language as it is used to construct other languages. Today it provides the basis for a wide variety of industry specific languages such as Mathematical Markup Language (MathML), Voice Markup Language (VXML), or OpenOffice and LibreOffice (OpenDocument).
XML is used to create human-readable structured data and self-describing documents that conform to a set of rules. XML parsers can then validate the structure of any XML document, given the rules of its language. XML documents are text-based structures described using markup tags (words surrounded by '<' and '>').
XML Document
Listing 12-1 shows an XML document representing a customer’s purchase order for the CD-BookStore application (see Chapter 1). Note that this document is easily readable as well as being structured and therefore can be understood by an external system. In this case it describes information about the purchase order, the customer who made the order, the items bought by the customer as well as the credit card information used to pay the order.
Listing 12-1. An XML Document Representing a Purchase Order
<?xml version="1.0" encoding="UTF-8" ?>
<order id="1234" date="05/06/2013">
<customer first_name="James" last_name="Rorrison">
<email>[email protected]</email>
<phoneNumber>+44 1234 1234</phoneNumber>
</customer>
<content>
<order_line item="H2G2" quantity="1">
<unit_price>23.5</unit_price>
</order_line>
<order_line item="Harry Potter" quantity="2">
<unit_price>34.99</unit_price>
</order_line>
</content>
<credit_card number="1357" expiry_date="10/13" control_number="234" type="Visa"/>
</order>
The document begins with an optional XML declaration (specifying which version of XML and character encoding is being used by the document) and then is composed of both markups and content. Markups, also referred to as tags, describe the structure of the document, allowing you to easily send and receive data, or transform data from one format to another.
As you can see in Table 12-1, the XML terminology is quite simple. Despite this simplicity and readability, XML can be used to describe any kind of document, data structure, or deployment descriptor when it comes to Java EE.
Table 12-1. XML Terminology
| Terminology | Definition |
|---|---|
| Unicode character | An XML document is a string of characters represented by almost every legal Unicode character |
| Markup and content | The Unicode characters are divided into markup and content. Markups begin with the character < and end with a > (<email>) and what is not markup is considered to be content (such as [email protected]) |
| Tag | Tags come in three flavors of markups: start-tags (<email>), end-tags (</email>) and empty-element tags (<email/>) |
| Element | An element begins with a start-tag and ends with a matching end-tag (or consists only of an empty-element tag). It can also include other elements, which are called child elements. An example of an element is <email> [email protected] </email> |
| Attribute | An attribute consists of a name/value pair that exists within a start-tag or empty-element tag. In the following example item is the attribute of the order_line tag: <order_line item="H2G2"> |
| XML Declaration | XML documents may begin by declaring some information about themselves, as in the following example: <?xml version="1.0" encoding="UTF-8" ?> |
Validating with XML Schema
The XML terminology is so broad that it allows you to write anything you want with XML and declare your own language. In fact, you can write so many things that your XML structure can become meaningless if you don’t define a grammar. This grammar can be set using an XML Schema Definition (XSD). By having a grammar attached to your XML document, you can have any validating XML parser enforce the rules of a particular XML dialect. This removes a tremendous burden from your application’s code as the parser will automatically validate your XML document.
![]() Note The first and earliest language definition mechanism is the document type definition (DTD). Still being used in several legacy frameworks, the DTD mechanism has been replaced by XSD due to DTD's numerous limitations. One basic and major limitation is that a DTD is not itself a valid XML document. Therefore, it cannot be handled by XML parsing tools, just like XML itself. More problematic, DTDs are quite limited in their ability to constrain the structure and content of XML documents.
Note The first and earliest language definition mechanism is the document type definition (DTD). Still being used in several legacy frameworks, the DTD mechanism has been replaced by XSD due to DTD's numerous limitations. One basic and major limitation is that a DTD is not itself a valid XML document. Therefore, it cannot be handled by XML parsing tools, just like XML itself. More problematic, DTDs are quite limited in their ability to constrain the structure and content of XML documents.
An XML Schema Definition (XSD) is an XML-based grammar declaration used to describe the structure and content of an XML document. For instance, the schema in Listing 12-2 can be used to specify the XML document described in Listing 12-1, giving it an extra meaning: “This is not just a text file, it’s a structured document representing an order with items and customer details.” During document interchange, the XSD describes the contract between the producer and consumer because it describes what constitutes a valid XML message between the two parties.
Listing 12-2. XSD Describing the Purchase Order XML Document
<?xml version="1.0" encoding="UTF-8" ?>
<xs: schema version="1.0" xmlns: xs =" http://www.w3.org/2001/XMLSchema ">
<xs:element name="order" type="order"/>
<xs:complexType name="creditCard">
<xs:sequence/>
<xs:attribute name="number" type="xs:string"/>
<xs:attribute name="expiry_date" type="xs:string"/>
<xs:attribute name="control_number" type="xs:int"/>
<xs:attribute name="type" type="xs:string"/>
</xs:complexType>
<xs:complexType name="customer">
<xs:sequence>
<xs:element name="email" type="xs:string" minOccurs="0"/>
<xs:element name="phoneNumber" type="xs:string" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="first_name" type="xs:string"/>
<xs:attribute name="last_name" type="xs:string"/>
</xs:complexType>
<xs: complexType name="order">
<xs:sequence>
<xs:element name="customer" type=" customer " minOccurs="0"/>
<xs:element name="content" minOccurs="0">
<xs:complexType>
<xs:sequence>
<xs:element name="order_line" type="orderLine" minOccurs ="0" →
maxOccurs ="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="credit_card" type="creditCard" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="id" type=" xs:long "/>
<xs:attribute name="date" type="xs:dateTime"/>
</xs:complexType>
<xs:complexType name="orderLine">
<xs:sequence>
<xs:element name="unit_price" type="xs:double" minOccurs="0"/>
</xs:sequence>
<xs: attribute name="item" type="xs:string"/>
<xs: attribute name="quantity" type="xs:int"/>
</xs:complexType>
</xs:schema>
As you can see in Listing 12-2, the XSD allows a very precise definition of both simple (<xs:attribute name="expiry_date" type="xs:string"/>) and complex data types (<xs:complexType name="creditCard">), and even allows types to inherit properties from other types. The purchase order schema consists of a variety of subelements, most notably elements, complex types, and attributes that determine the appearance of the content. Thanks to XSD, elements and attributes become strongly typed and have datatype information associated with them. Such strongly typed XML can now be mapped to objects using technologies such as JAXB, which you’ll see later in this chapter.
Table 12-2 only lists a subset of the XSD elements and attributes. XSD is a much richer language, but it’s not the goal of this book to be an exhaustive XSD resource. If you want to know more about XSD, its structure, and its datatypes, you should check the related W3C website.
Table 12-2. XSD Elements and Attributes
| Element | Description |
|---|---|
| schema | Is the root element of every XML Schema. It may contain some attributes such as the schema version |
| xmlns | Each element in the schema has a default prefix xs: (or sometimes xsd: although any prefix can be used) which is associated with the XML Schema namespace (xmlsn) through the declaration, xmlns:xsd=" http://www.w3.org/2001/XMLSchema " |
| element | Elements are declared using the element element. For example, order is defined as an element and appears as <order id="1234" date="11/08/2013" total_amount="93.48"> in the XML document |
| type | An element can be of a simple type such as string, decimal, long, double and so on (type="xs:long") or a complex type (type="customer") |
| minOccurs, maxOccurs | Define the minimum and maximum occurrence of a type. This value may be a positive integer or the term unbounded to indicate there is no maximum number of occurrences |
| complexType | It describes a complex type with elements, sub-elements, and attributes. A complexType element can contain another complexType. For example, the complex type order contains a complexType |
| sequence | An element may include other elements, which are called child elements. The sequence element specifies that the child elements must appear in a sequence. Each child element can occur from 0 to any number of times |
| attribute | A complex type may have one or more attributes that are defined by attribute elements. The orderLine type has two attributes; item and quantity |
| choice | Used to indicate only one set of elements can be present in the containing element |
| complexContent | A complex type can extend or restrict another complex type using complexContent element |
| extension | The extension element extends an existing simpleType or complexType element |
Once you have an XML document and its associated XML Schema Definition you can use a parser to do the validation for you. Parsers come in two major flavors: DOM and SAX.
Parsing with SAX and DOM
Before a document can be used, it must be parsed and validated by an XML parser. The parser, a.k.a. processor, analyzes the markup and makes the data contained in the XML available to the application that needs to use it. Most XML parsers can be used in two distinct modes. One mode is the Document Object Model (DOM) that reads in an entire XML data source and constructs a treelike representation of it in memory. The other mode is an event-based model called the Simple API for XML (SAX) that reads in the XML data source and makes callbacks to the application whenever it encounters a distinct section (the end of an element).
The Document Object Model (DOM) API is generally an easy API to use. It provides a familiar tree structure of objects enabling the application to rearrange nodes, add or delete contents as needed.
DOM is generally easy to implement, but constructing the DOM requires reading the entire XML structure and holding the object tree in memory. Therefore, it is better to use DOM with small XML data structures in situations in which speed is not of paramount importance to the application and random access to the entire content of the document is essential. There are also other technologies such as JDOM and DOM4J that provide a simple object-oriented XML-programming API for applications with less complexity.
The streaming model in parsers is used for local processing of resources where random access to the other parts of the data in the resource is not required. The Simple API for XML (SAX) is based on a push parsing streaming model in which data is pushed to the client reader application.
SAX is an event-driven, serial-access mechanism that does element-by-element processing. Using a SAX parser, a SAX event is fired whenever the end of an XML element has been encountered. The event includes the name of the element that has just ended. The SAX handler is a state machine that can only operate on the portion of the XML document that has already been parsed.
SAX is the fastest parsing method for XML, and it is appropriate for handling large documents that could not be read into memory all at once. It tends to be preferred for server-side, high-performance applications and data filters that do not require an in-memory representation of the data. Though, it places greater demands on the software developer’s skills.
Querying with XPath
XPath is a query language designed to query XML structures that is used by a variety of other XML standards, including XSLT, XPointer, and XQuery. It defines the syntax for creating expressions, which are evaluated against an XML document.
XPath expressions can represent a node, a boolean, a number, or a string. The most common type of XPath expression is a location path, which represents a node. For example, the XPath expression / is an expression that represents all nodes in the XML document from the root. Below is an XPath expression representing all the unit_price nodes whose value is greater than 20 (see the purchase order XML in Listing 12-1):
//content/order_line[unit_price>=20]/unit_price
Also, XPath has a set of built-in functions that enable you to develop very complex expressions. The following expression returns the children text node of unit_price elements:
//content/order_line[unit_price>=20]/unit_price/text()
XQuery is another query language that is designed to query collections of XML data using XPath expressions. XQuery is syntactically similar to SQL, with a set of keywords including FOR, LET, WHERE, ORDER BY or RETURN. The following is a simple XQuery expression that is using the doc() function (that reads the order.xml document) to return all order_line children nodes which have a quantity greater than 1 and unit_price less than 50;
for $orderLine in doc("order.xml")//content/order_line[@quantity>1]
where $orderLine/unit_price < 50
return $orderLine/unit_price/text()
There are more complex queries you can do with XQuery like joining XML documents, making complex conditions or ordering the result on an element.
In some cases, extracting information from an XML document using an API may be too cumbersome mostly because the criteria for finding the data are complex and a bunch of code is needed to iterate through the nodes. XML query languages such as XPath 1.0 and XQuery provide rich mechanisms for extracting information from XML documents.
A key advantage of XML over other data formats is the ability to transform an XML document from one vocabulary to another, in a generic manner. For example you can render an XML document into a print-friendly format or into a web page. The technology that enables this translation is the eXtensible Stylesheet Language Transformations (XSLT).
Simply stated, XSLT provides a framework for transforming the structure of an XML document by combining it with an XSL stylesheet to produce an output document. All you have to do is to create an XSL stylesheet that contains a set of transformation instructions for transforming a source tree into a result tree. Then an XSLT processor will transform the source document by associating patterns within the source XML tree with XSL stylesheet templates that are to be applied to them.
A pattern is an XPath expression that is matched against elements in the source tree. On a successful match, a template is instantiated to create part of the result tree. In constructing the result tree, elements from the source can be filtered and reordered, and arbitrary structure can be added.
The XSLT stylesheet in Listing 12-3 converts the order.xml document shown in Listing 12-1 into an XHTML Web page showing a table of sold items whose price is greater than 30.
Listing 12-3. XSLT Stylesheet for Purchase Order XML Document
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0" xmlns:xsl=" http://www.w3.org/1999/XSL/Transform ">
<xsl:template match="/">
<html>
<body>
<h2>Sold Items</h2>
<table border="1">
<tr>
<th>Title</th>
<th>Quantity</th>
<th>Unit Price</th>
</tr>
<xsl:for-each select=" order/content/order_line ">
<tr>
<td>
<xsl:value-of select="@item"/>
</td>
<td>
<xsl:value-of select="@quantity"/>
</td>
<xsl:choose>
<xsl:when test=" unit_price > 30 ">
<td bgcolor="#FF0000">
<xsl:value-of select="unit_price"/>
</td>
</xsl:when>
<xsl:otherwise>
<td>
<xsl:value-of select="unit_price"/>
</td>
</xsl:otherwise>
</xsl:choose>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
The generic XSLT APIs in the javax.xml.transform package are used for compiling stylesheet instructions, and performing a transformation from XML source to a XML result. XSLT can also be used with the SAX APIs to convert data to XML.
XML specification became a W3C (World Wide Web Consortium) recommendation in 1998, after which, several XML specifications like XSLT, XPath, XML Schema, and XQuery were introduced and became standard in W3C. Java platform-independent code and XML platform-independent data were two complementary points that led to standardization and simplification of various Java APIs for XML. This has made developing XML-aware applications in Java much simpler.
A Brief History of XML Specifications
The W3C is a consortium that is known for developing and maintaining web technologies like HTML, XHTML, RDF, or CSS. But, W3C is also the central organ for XML and all the related XML technologies like XML Schema, XSLT, XPATH, and DOM.
Development of XML (Extensible Markup Language) started in 1996 by the XML Working Group of the W3C and led to a W3C recommendation in February 1998. However, the technology was not entirely new. It was based on SGML (Standard Generalized Markup Language), which had been developed in the early 1980s and became an ISO standard in 1986.
XSD (XML Schema) offers the facilities to describe the structure of XML documents in an .xsd file. This structure constrains the contents of XML documents and therefore, can be used to validate XML documents. XSD is one of several XML schema languages and it was the first separate schema language for XML, published as a W3C recommendation in 2001.
XSLT (EXtensible Stylesheet) is one of the first XML specifications, influenced by functional languages and by text-based pattern matching languages, to transform XML documents. Its most direct predecessor is DSSSL (Document Style Semantics and Specification Language), which did for SGML what XSLT does for XML. XSLT 1.0 became part of W3C in 1999 and the project led to the creation of XPath. Xalan, Saxon, and AltovaXML are some of several XSLT processors available for XML transformation.
XPath 1.0 is a query language for addressing nodes in an XML document. It was introduced and accepted as a W3C Recommendation in 1999. It was originally motivated by a desire to provide a common syntax between XPointer and XSLT. It can be directly used inside Java or it can be embedded in languages such as XSLT, XQuery or XML Schema.
The mission of the XML Query project is to provide flexible query facilities to extract data from documents. The development of XQuery 1.0 by the XML Query Working Group was closely coordinated with the development of XSLT 2.0 by the XSL Working Group; the two groups shared responsibility for XPath 2.0, which is a subset of XQuery 1.0. XQuery 1.0 became a W3C Recommendation on January 23, 2007.
The Document Object Model (DOM) is a tree-based interface for representing and interacting with contents, structures and styles in HTML, XHTML, and XML documents. At the beginning, DOM was an effort to develop a standard for scripting languages used in browsers. The current release of the DOM specification, DOM Level 3, supports XPath as well as an interface for serializing documents into XML.
The Simple API for XML (SAX ) is the first widely adopted API for XML in Java. It is a streaming, event-based interface to parse XML data. SAX was originally implemented in Java, but is now supported by nearly all major programming languages.
From the start, the development of XML specifications has been intertwined with a focus to improve the usability of XML.
Table 12-3 contains some of the specifications for XML technologies.
Table 12-3. W3C XML Specifications
| Specification | Version | URL |
|---|---|---|
| Extensible Markup Language (XML) | 1.1 | http://www.w3.org/TR/xml11/ |
| XML Schema | 1.0 | http://www.w3.org/TR/xmlschema-1 |
| EXtensible Stylesheet (XSLT) | 1.0 | http://www.w3.org/TR/xslt |
| XML Path (XPath) | 1.0 | http://www.w3.org/TR/xpath |
| Document Object Model (DOM) | level 3 | http://www.w3.org/TR/DOM-Level-3-Core/ |
| Simple API for XML (SAX) | 2.0.2 | http://sax.sourceforge.net/ |
The XML ecosystem was created by the W3C. But because it works hand in hand with Java, there are several XML-related specifications that were created within the JCP. Examples include from processing XML to binding documents into Java objects.
JAXP (Java Architecture for XML Processing) is a low-level specification (JSR 206) that gives you the possibility to process XML in a very flexible manner; allowing you to use SAX, DOM, or XSLT. It is the API used under the hood for JAXB or StAX.
The JAXB (Java Architecture for XML Binding) specification provides a set of APIs and annotations for representing XML documents as Java artifacts, allowing developers to work with Java objects representing XML documents. JAXB (JSR 222) facilitates unmarshalling XML documents into objects and marshalling objects back into XML documents. Even if JAXB can be used for any XML purpose, it is tightly integrated with JAX-WS (see Chapter 14).
StAX (Streaming API for XML) version 1.0 (JSR 173) is an API to read and write XML documents. Its main focus is to gather the benefits of tree-based APIs (DOM parsers) and event-based APIs (SAX parsers). DOM parsers allow random, unlimited access to the document, while SAX parsers provide a smaller memory footprint and have reduced processor requirements.
Table 12-4 lists all the Java specifications related to XML.
Table 12-4. XML-related Specifications

Reference Implementations
The primary goal of a Reference Implementation (RI) is to support the development of the specification and to validate it. StAX RI is the reference implementation for the JSR-173 specification which is based on a standard pull parser streaming model. StAX has been included in JDK since version 1.6 and can be downloaded separately for JDK 1.4 and 1.5. The RI for the JAXP specification is also integrated into Java SE as well as Metro, which is the reference implementation for JAXB. Metro is a production-quality implementation of JAXB that is used directly in a number of Oracle products.
Java Architecture for XML Processing
Java Architecture for XML Processing (JAXP) is an API that provides a common, implementation-independent interface for creating and using the SAX, DOM, and XSLT APIs in Java.
Prior to JAXP, there were different incompatible versions of XML parsers and transformers from different vendors. JAXP has provided an abstraction layer on top of these vendor-specific XML API implementations to parse and transform XML resources.
Note that JAXP doesn’t use a different mechanism to parse and transform XML documents. Instead, applications can use it to access the underlying XML APIs indirectly in a common manner. Applications can then replace a vendor’s implementation with another.
Using JAXP, you can parse XML documents with SAX or DOM as the underlying strategy, or transform them to a new format using XSLT. The JAXP API architecture is depicted in Figure 12-1.
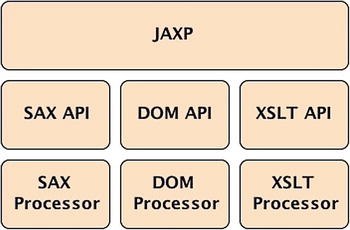
Figure 12-1. JAXP Architecture
JAXP consists of four packages summarized in Table 12-5. In these packages you’ll find interfaces and classes to parse and transform XML data in a generic way.
Table 12-5. The JAXP Packages
| Package | Description |
|---|---|
| javax.xml.parsers | A common interface to DOM and SAX parsers |
| org.w3c.dom | The generic DOM API for Java |
| org.xml.sax | Defines the interfaces used for the SAX parser |
| javax.xml.transform | The XSLT APIs to transform XML into other forms |
As JAXP is flexible, you can configure it to use any processing implementation you need. But you can always use the defaults as the JAXP reference implementation uses Xerces as the default XML parser and Xalan as the default XSLT processor to transform XML documents.
Imagine a scenario in which there are more than one JAXP-compliant implementations in your classpath. In this case, you have to tell JAXP which API to use. Depending if your application either runs in a standalone client mode or an application server mode, you can provide your application with an XML parser or transformer through a property file. For example, putting a jaxp.properties file (a standard file following the java.util.Properties format) in lib subdirectory of the JRE directory causes the JAXP implementation to use the specified factories. The following is the content of a jaxp.properties file that defines which DOM builder, SAX parser, and XSLT transformer is to be used:
javax.xml.parsers. DocumentBuilderFactory =org.apache.xerces.jaxp.DocumentBuilderFactoryImpl
javax.xml.parsers. SAXParserFactory =org.apache.xerces.jaxp.SAXParserFactoryImpl
javax.xml.transform. TransformerFactory =org.apache.xalan.processor.TransformerFactoryImpl
The other way is to configure Java system properties before running the application. For example, the following system property informs the JVM to use Xerces as XML parser:
-Djavax.xml.parsers. DocumentBuilderFactory =org.apache.xerces.jaxp.DocumentBuilderFactoryImpl
The main system properties that can be modified to introduce new parsers or transformers are listed in Table 12-6.
Table 12-6. System Properties for XML Parser/Transformer Configuration
| System Property | Description |
|---|---|
| javax.xml.parsers.DocumentBuilderFactory | Sets the DOM builder |
| javax.xml.parsers.SAXParserFactory | Configures the SAX parser |
| javax.xml.transform.TransformerFactory | Determines which XSLT implementation to use |
SAX is known for its low memory requirements and fast processing functionality. SAX is an event-driven, serial access mechanism to parse XML documents. You have to provide the parser with callback methods that are invoked by the parser as it reads the XML document. For example, the SAX parser calls a method in your application each time an element is reached and calls a different method when a text node is encountered.
The way in which you process the current element in an XML document without maintaining any state from previously parsed elements is called state-independent processing. This is the most suited model for processing XML resources with SAX parsers. The other model is state-dependent parsing, which is handled with pull parsers like StAX parsers.
Listing 12-4 shows a class that parses the order.xml document using the SAX event-model. The SaxParsing class extends DefaultHandler which is required for different parsing needs and implements four different handlers (ContentHandler, ErrorHandler, DTDHandler, and EntityResolver). The SAXParserFactory configures and creates a SAX parser instance. As mentioned earlier, it is possible to manually configure the system property javax.xml.parsers.SAXParserFactory to use a third-party SAX parser. The SAXParser wraps a SAXReader object which can be referenced by getXMLReader(). Therefore, when the SAX parser’s parse() method is invoked, the reader invokes one of several handler methods implemented by the application (e.g. the startElement method).
Listing 12-4. SAX Parser Parsing the Purchase Order Document
public class SaxParsing extends DefaultHandler {
private List<OrderLine> orderLines = new ArrayList<>();
private OrderLine orderLine;
private Boolean dealingWithUnitPrice = false;
private StringBuffer unitPriceBuffer;
public List<OrderLine> parseOrderLines() {
try {
File xmlDocument = Paths.get("src/main/resources/ order.xml ").toFile();
// SAX Factory
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
// Parsing the document
saxParser. parse (xmlDocument, this);
} catch (SAXException | IOException | ParserConfigurationException e) {
e.printStackTrace();
}
return orderLines;
}
@Override
public void startElement (String namespaceURI, String localName, String qualifiedName, →
Attributes attrs) throws SAXException {
switch (qualifiedName) {
// Getting the order_line node
case "order_line":
orderLine = new OrderLine();
for (int i = 0; i < attrs.getLength(); i++) {
switch (attrs.getLocalName(i)) {
case "item":
orderLine.setItem(attrs.getValue(i));
break;
case "quantity":
orderLine.setQuantity(Integer.valueOf(attrs.getValue(i)));
break;
}
}
break;
case "unit_price":
dealingWithUnitPrice = true;
unitPriceBuffer = new StringBuffer();
break;
}
}
@Override
public void characters (char[] ch, int start, int length) throws SAXException {
if (dealingWithUnitPrice)
unitPriceBuffer.append(ch, start, length);
}
@Override
public void endElement (String namespaceURI, String localName, String qualifiedName) →
throws SAXException {
switch (qualifiedName) {
case "order_line":
orderLines.add(orderLine);
break;
case "unit_price":
orderLine.setUnitPrice(Double.valueOf(unitPriceBuffer.toString()));
dealingWithUnitPrice = false;
break;
}
}
}
The ContentHandler interface handles the basic document-related events like the start and end of elements with startDocument, endDocument, startElement, and endElement methods. These methods are called when the starting or ending of XML document or tags occur. In Listing 12-4 the startElement method checks that the element is either order_line or unit_price to either create an OrderLine object or get the unit price value. The ContentHandler interface also defines the method characters(), which is invoked when the parser encounters a chunk of characters in an XML element (in Listing 12-4 the characters() method buffers the unit price of each item).
To ensure error handling while parsing an XML document, an ErrorHandler can be registered to the SAXReader. The ErrorHandler interface methods (warning, error, and fatalError) are invoked in response to various types of parsing errors.
The DTDHandler interface defines methods to handle DTD-related events. The parser uses the DTDHandler to report notation and unparsed entity declarations to the application. This is useful when processing a DTD to recognize and act on declarations for an unparsed entity.
JAXP provides interfaces to parse and modify the XML data using DOM APIs. The entry point is the javax.xml.parsers.DocumentBuilderFactory class. It is used to produce a DocumentBuilder instance as shown in Listing 12-5. Using one of the parse methods in DocumentBuilder, you can create a tree structure of the XML data in an org.w3c.dom.Document instance. This tree contains tree nodes (such as elements and text nodes), which are implementations of the org.w3c.dom.Node interface. Alternatively, to create an empty Document object, you can use the newDocument() method on the DocumentBuilder instance.
Listing 12-5. DOM Parser Parsing the Purchase Order Document
public class DomParsing {
public List<OrderLine> parseOrderLines() {
List<OrderLine> orderLines = new ArrayList<>();
try {
File xmlDocument = Paths.get("src/main/resources/order.xml").toFile();
// DOM Factory
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// Parsing the document
DocumentBuilder documentBuilder = factory.newDocumentBuilder();
Document document = documentBuilder. parse (xmlDocument);
// Getting the order_line node
NodeList orderLinesNode = document.getElementsByTagName(" order_line ");
for (int i = 0; i < orderLinesNode.getLength(); i++) {
Element orderLineNode = (Element) orderLinesNode.item(i);
OrderLine orderLine = new OrderLine();
orderLine.setItem(orderLineNode.getAttribute(" item "));
orderLine.setQuantity(Integer.valueOf(orderLineNode.getAttribute(" quantity ")));
Node unitPriceNode = orderLineNode.getChildNodes().item(1);
orderLine.setUnitPrice(Double.valueOf(unitPriceNode.getFirstChild().getNodeValue()));
orderLines.add(orderLine);
}
} catch (SAXException | IOException | ParserConfigurationException e) {
e.printStackTrace();
}
return orderLines;
}
}
Listing 12-5 parses the order.xml document, which results in a tree representation in memory. Thanks to the numerous Document methods, you can then get the list of order_line nodes or the quantity attribute (e.g., getAttribute("quantity")) to create an OrderLine object.
As previously mentioned, it is possible to override the platform's default DOM parser by setting the system property javax.xml.parsers.DocumentBuilderFactory for a different DOM API to be used.
JAXP is also used to transform XML documents using the XSLT API. XSLT interacts with XML resources to transform an XML source to an XML result using a transformation stylesheet (see Listing 12-3).
Listing 12-6 takes the order.xml document (Listing 12-1) and transforms it into an HTML page using the XSLT defined in Listing 12-3. The code first uses the newInstance() method of the javax.xml.transform.TransformerFactory class, to instantiate a transformer factory. Then, it calls the newTransformer() method to create a new XSLT Transformer. Then it transforms the order.xml document to a stream resulting in an HTML page.
Listing 12-6. Transforming an XML Document with XSLT
public class XsltTransforming {
public String transformOrder() {
StringWriter writer = new StringWriter();
try {
File xmlDocument = Paths.get("src/main/resources/ order.xml ").toFile();
File stylesheet = Paths.get("src/main/resources/ order.xsl ").toFile();
TransformerFactory factory = →
TransformerFactory.newInstance("net.sf.saxon.TransformerFactoryImpl", null);
// Transforming the document
Transformer transformer = factory.newTransformer(new StreamSource( stylesheet ));
transformer.transform(new StreamSource( xmlDocument ), new StreamResult( writer ));
} catch (TransformerException e) {
e.printStackTrace();
}
return writer .toString();
}
}
Java Architecture for XML Binding
Java offers various ways to manipulate XML, from common APIs that are bundled in the JDK such as javax.xml.stream.XmlStreamWriter and java.beans.XMLEncoder to more complex and low-level models such as SAX, DOM, or JAXP.
The Java Architecture for XML Binding (JAXB) specification (JSR 222) provides a higher level of abstraction than SAX or DOM and is based on annotations. JAXB defines a standard to bind Java representations to XML and vice versa. This allows developers to work with Java objects that represent XML documents.
Listing 12-7 shows a simple CreditCard class annotated with the JAXB annotation @javax.xml.bind.annotation.XmlRootElement. JAXB will then bind the CreditCard object back and forth from XML to Java.
Listing 12-7. A CreditCard Class with a JAXB Annotation
@XmlRootElement
public class CreditCard {
private String number ;
private String expiryDate ;
private Integer controlNumber ;
private String type ;
// Constructors, getters, setters
}
Except for the @XmlRootElement annotation, Listing 12-7 shows the code of a simple Java class. With this annotation and a marshalling mechanism, JAXB is able to create an XML representation of a CreditCard instance that could look like the XML document shown in Listing 12-8.
Listing 12-8. An XML Document Representing Credit Card Data
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<creditCard>
< controlNumber >566</controlNumber>
< expiryDate >10/14</expiryDate>
< number >12345678</number>
< type >Visa</type>
</creditCard>
Marshalling is the action of transforming an object into XML (see Figure 12-2). The inverse is also possible with JAXB. Unmarshalling would take the XML document in Listing 12-8 as an input and instantiate a CreditCard object with the values defined in the document.
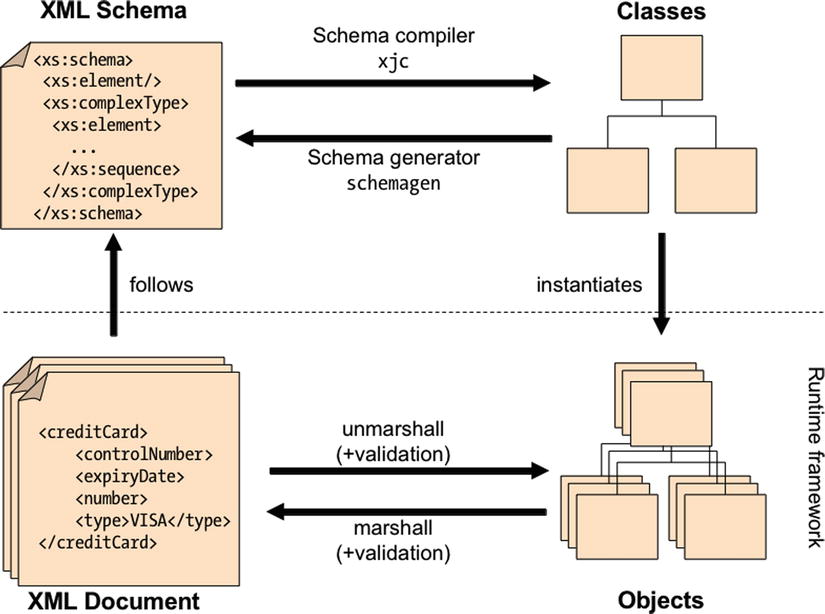
Figure 12-2. JAXB architecture
JAXB manages XML documents and XML Schema Definitions (XSD) in a transparent, object-oriented way that hides the complexity of the XSD language. JAXB can automatically generate the schema that would validate the credit card XML structure to ensure that it would have the correct structure and data types (thanks to the schemagen utility in the JDK). Listing 12-9 shows the XML Schema Definition (XSD) of the CreditCard class.
Listing 12-9. XML Schema Validating the Previous XML Document
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<xs:schema version="1.0" xmlns: xs =" http://www.w3.org/2001/XMLSchema ">
<xs:element name="creditCard" type="creditCard"/>
<xs: complexType name=" creditCard ">
<xs:sequence>
<xs: element name=" controlNumber " type="xs:int" minOccurs="0"/>
<xs:element name=" expiryDate " type="xs:string" minOccurs="0"/>
<xs:element name="number" type="xs:string" minOccurs="0"/>
<xs:element name="type" type="xs:string" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
The schema in Listing 12-9 is made of simple elements (controlNumber, expiryDate, etc.) and a complex type (creditCard). Notice that all of the tags use the xs prefix (xs:element, xs:string, etc.). This prefix is called a namespace and is defined in the xmlns (XML namespace) header tag of the document:
<xs:schema version="1.0" xmlns: xs =" http://www.w3.org/2001/XMLSchema ">
Namespaces create unique prefixes for elements in separate documents or applications that are used together. They are used primarily to avoid conflict problems that may be caused if the same element name appears in several documents (for example, the <element> tag could appear in several documents and have different meanings).
JAXB provides a lightweight, two-way mapping between Java objects and XML structures. It enables the conversion of Java objects to XML data without the need to create complex code that is hard to maintain and debug. For example, JAXB allows you to easily transfer the state of an object to XML data and serialize it to network stream for example. On the other hand, JAXB enables you to work with XML documents as if they are Java objects without the need to explicitly perform SAX or DOM parsing in your application code.
Binding
The JAXB API, defined in the javax.xml.bind package, provides a set of interfaces and classes to produce XML documents and to generate Java classes. In other words, it binds the two models. The JAXB runtime framework implements the marshall and unmarshall operations. Table 12-7 contains the main JAXB packages for marshalling and unmarshalling operations.
Table 12-7. The JAXB Packages
| Package | Description |
|---|---|
| javax.xml.bind | A runtime binding framework including marshalling, unmarshalling, and validation capabilities |
| javax.xml.bind.annotation | Annotations for customizing the mapping between the Java program and XML data |
| javax.xml.bind.annotation.adapters | Adapter classes to be used with JAXB |
| javax.xml.bind.attachment | Enables marshalling to optimize storage of binary data and unmarshalling a root document containing binary data formats |
| javax.xml.bind.helpers | Contains partial default implementations for some of the javax.xml.bind interfaces |
| javax.xml.bind.util | Provides useful utility classes |
As shown in Figure 12-2, marshalling is the process of converting instances of JAXB-annotated classes to XML representations. Likewise, unmarshalling is the process of converting an XML representation to a tree of objects. During the process of marshalling/unmarshalling, JAXB can also validate the XML against an XSD (Listing 12-9). JAXB can also work at the class level and is able to automatically generate a schema from a set of classes and vice versa.
The center of the JAXB API is the javax.xml.bind.JAXBContext class. This abstract class manages the binding between XML documents and Java objects as it provides:
- An Unmarshaller class that transforms an XML document into an object graph and optionally validates the XML
- A Marshaller class that takes an object graph and transforms it into an XML document
For example, to transform our CreditCard object into an XML document (see Listing 12-10), the Marshaller.marshal() method must be used. This method takes an object as a parameter and marshalls it into several supports (StringWriter to have a string representation of the XML document or FileOutputStream to store it in a file).
Listing 12-10. A Main Class Marshalling a CreditCard Object
public class Main {
public static void main(String[] args) throws JAXBException {
CreditCard creditCard = new CreditCard("1234", "12/09", 6398, "Visa");
StringWriter writer = new StringWriter();
JAXBContext context = JAXBContext.newInstance(CreditCard.class);
Marshaller m = context.createMarshaller();
m.marshal(creditCard, writer);
System.out.println(writer.toString());
}
}
The code in Listing 12-10 creates an instance of JAXBContext by using the static method newInstance(), to which it passes the root class that needs to be marshalled (CreditCard.class). From the created Marshaller object, it then calls the marshal() method that generates the XML representation (shown previously in Listing 12-8) of the credit card object into a StringWriter and displays it. The same approach could be used to unmarshall an XML document into objects using the Unmarshaller.unmarshal() method.
Metro the JAXB reference implementation, has other tools, specifically the schema compiler (xjc) and the schema generator (schemaGen). While marshalling/unmarshalling deals with objects and XML documents, the schema compiler and the schema generator deal with classes and XML Schemas. These tools can be used in the command line (they are bundled with Java SE 7) or as Maven goals.
Annotations
JAXB is similar to JPA in many ways. However, instead of mapping objects to a database, JAXB does the mapping to an XML document. Also, like JPA, JAXB defines a set of annotations (in the javax.xml.bind.annotation package) to customize this mapping, and relies on configuration by exception to minimize the work of the developer. If persistent objects have to be annotated with @Entity, the correspondent in JAXB is @XmlRootElement (see Listing 12-11).
Listing 12-11. A Customized CreditCard Class
@XmlRootElement
@XmlAccessorType(XmlAccessType.FIELD)
public class CreditCard {
@XmlAttribute(required = true)
private String number;
@XmlElement(name = "expiry-date", defaultValue = "01/10")
private String expiryDate;
private String type;
@XmlElement(name = "control-number")
private Integer controlNumber;
// Constructors, getters, setters
}
In Listing 12-11 the @XmlRootElement annotation notifies JAXB that the CreditCard class is the root element of the XML document. If this annotation is missing, JAXB will throw an exception when trying to marshall it. This class is then mapped to the schema shown in Listing 12-12 using all the JAXB default mapping rules (each attribute is mapped to an element and has the same name).
Listing 12-12. The Credit Card Schema with Attributes and Default Values
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<xs:schema version="1.0" xmlns:xs=" http://www.w3.org/2001/XMLSchema ">
<xs:element name="creditCard" type="creditCard"/>
<xs:complexType name="creditCard">
<xs:sequence>
<xs:element name=" expiry-date " type="xs:string" default="01/10" minOccurs="0"/>
<xs:element name="type" type="xs:string" minOccurs="0"/>
<xs:element name=" control-number " type="xs:int" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="number" type="xs:string" use="required"/>
</xs:complexType>
</xs:schema>
With a Marshaller object, you can easily get an XML representation of a CreditCard object (shown earlier in Listing 12-10). The root element <creditCard> represents the CreditCard object, and it includes the value of each attribute.
JAXB provides a way to customize and control this XML structure. An XML document is made of elements (<element>value</element>) and attributes (<element attribute="value"/>). JAXB uses two annotations to differentiate them: @XmlAttribute and @XmlElement. Each annotation has a set of parameters that allows you to rename an attribute, allow null values or not, give default values, and so forth. The class properties are mapped to XML elements by default if they are not annotated with @XmlAttribute annotation.
Listing 12-11 uses these annotations to turn the credit card number into an attribute (instead of an element) and to rename the expiry date and control number. This class will get mapped to a different schema in which the credit card number is represented as a required <xs:attribute>, and the expiry date is renamed and has a default value set to 01/10, as shown in Listing 12-12.
The XML representation of the CreditCard will also change as you can see Listing 12-13 (compared with the one in Listing 12-8).
Listing 12-13. An XML Document Representing a Customized CreditCard Object
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<creditCard number ="1234">
< expiry-date >12/09</expiry-date>
<type>Visa</type>
< control-number >6398</control-number>
</creditCard>
Table 12-8 lists the main JAXB annotations. Some can annotate attributes (or getters), others classes, and some can be used on an entire package (such as @XmlSchema).
Table 12-8. JAXB Annotations
| Annotation | Description |
|---|---|
| @XmlAccessorType | Controls whether attributes or getters should be mapped (FIELD, NONE, PROPERTY, PUBLIC_MEMBER) |
| @XmlAttribute | Maps an attribute or a getter to an XML attribute of simple type (String, Boolean, Integer, and so on) |
| @XmlElement | Maps a nonstatic and nontransient attribute or getter to an XML element |
| @XmlElements | Acts as a container for multiple @XmlElement annotations |
| @XmlEnum | Maps an enum to an XML representation |
| @XmlEnumValue | Identifies an enumerated constant |
| @XmlID | Identifies the key field of an XML element (of type String), which can be used when referring back to an element using the @XmlIDREF annotation (XML Schema ID and IDREF concepts) |
| @XmlIDREF | Maps a property to an XML IDREF in the schema |
| @XmlList | Maps a property to a list |
| @XmlMimeType | Identifies a textual representation of the MIME type for a property |
| @XmlNs | Identifies an XML namespace |
| @XmlRootElement | Represents an annotation required by any class that is to be bound as the root XML element |
| @XmlSchema | Maps a package name to an XML namespace |
| @XmlTransient | Informs JAXB not to bind an attribute (analogous to the Java transient keyword or @Transient annotation in JPA) |
| @XmlType | Annotates a class as being a complex type in XML Schema |
| @XmlValue | Allows the mapping of a class to a simple schema content or type |
When using these annotations, you can map objects to a specific XML Schema. And sometimes you need this flexibility with legacy web services, as you will see in the coming chapters. Referring to JPA, when you need to map entities to a legacy database, there is a set of annotations that allows the customization of every part of the mapping (columns, table, foreign keys, etc.). With web services, it’s similar: web services are described in a WSDL file written in XML. If it’s a legacy web service, its WSDL cannot change. Instead, a mechanism to map it to objects must be used, which is why JAXB is used with web services.
![]() Note In this section, I’ve mentioned JPA several times because both JPA and JAXB technologies heavily rely on annotations and are used to map objects to a different media (database or XML). In terms of architecture, entities should only be used to map data to a database, and JAXB classes to map data to XML. But sometimes you may want the same object to have a database representation as well as an XML one. As you’ll see in Chapter 14, it is possible to annotate the same class with @Entity and @XmlRootElement.
Note In this section, I’ve mentioned JPA several times because both JPA and JAXB technologies heavily rely on annotations and are used to map objects to a different media (database or XML). In terms of architecture, entities should only be used to map data to a database, and JAXB classes to map data to XML. But sometimes you may want the same object to have a database representation as well as an XML one. As you’ll see in Chapter 14, it is possible to annotate the same class with @Entity and @XmlRootElement.
Understanding JSON
JavaScript Object Notation (JSON) is a lightweight data-interchange format that is less verbose and more readable than XML. It is often used for serializing and transmitting structured data over a network connection between a server and web application.
As an alternative to XML, JSON is directly consumable by JavaScript code in web pages. This is the major reason for using JSON over other representations. Listing 12-14 is the JSON representation of the purchase order XML document show in Listing 12-1.
Listing 12-14. The JSON Representation of Purchase Order
{
" order ": {
"id": "1234",
"date": "05/06/2013",
" customer ": {
"first_name": "James",
"last_name": "Rorrison",
"email": " [email protected] ",
"phoneNumber": "+44 1234 1234"
},
"content": {
" order_line ": [
{
"item": "H2G2",
"quantity": "1",
"unit_price": "23.5"
},
{
"item": "Harry Potter",
"quantity": "2",
"unit_price": "34.99"
}
]
},
" credit_card ": {
"number": "1357",
"expiry_date": "10/13",
"control_number": "234",
"type": "Visa"
}
}
}
JSON objects can be serialized in JSON, which will end up in a less complex structure than XML. By enclosing the variable’s value in curly braces, it indicates that the value is an object. Inside the object, we can declare any number of properties using a "name":"value" pair, separated by commas. To access the information stored in JSON, we can simply refer to the object and name of the property.
JSON is a text-based language-independent format that uses a set of conventions to represent simple data structures. Many languages have implemented APIs to parse JSON documents. Data structures in JSON are human-readable and are much like data structures in Java. JSON can represent four primitive types (number, string, booleans, and null) and two structured types (objects and arrays). Table 12-9 lists the JSON conventions to represent data.
Table 12-9. JSON Terminology
| Terminology | Definition |
|---|---|
| Number | Number in JSON is much like number in Java except that the octal and hexadecimal formats are not used |
| String | A string is a sequence of zero or more Unicode characters, wrapped in double quotes, using backslash escapes |
| Value | A value in JSON can be in one of these formats; a string in double quotes, a number, true, false, null, an object, or an array |
| Array | An array is an ordered set of values. Brackets ([,]) mark the beginning and end of an array. Values in an array are separated by commas (,) and can be of object type |
| Object | JSON and Java have the same definition for objects. In JSON, an object is an unordered set of name/value pairs. Braces ({,}) mark the beginning and the end of an object. The name/value pairs in JSON are separated by comma (,) and represent attributes for a POJO in Java |
Colon (:) is used as the name-separator and comma as the value-separator in JSON. Valid JSON data is a serialized object or array of data structures that can be nested. For example, a JSON object can contain a JSON array. In Listing 12-14, content is an object that contains an array of order_line.
JSON is derived from the object literals of JavaScript. JSON was submitted as RFC 4627 in the Internet Engineering Task Force (IETF) in 2006. The IETF is an open international community of network designers, researchers, operators, and vendors concerned with the evolution of the Internet architecture.
The official Internet media type for JSON is application/json (see Chapter 15 with RESTful Web services) and the JSON filename extension is .json. Though JSON is not currently submitted as a W3C recommendation, there are many W3C specifications and APIs that are based directly or indirectly on JSON or that use JSON such as JSON-LD, JSONPath, JSONT, and JSONiq. Also, a large variety of programming languages have implemented APIs to parse and generate data in JSON format.
Java has several implementations to process, transform, serialize/deserialize, or generate JSON data such as Json-lib, fastjson, Flexjson, Jettison, Jackson, and so on (check http://json.org , which lists several Java APIs for JSON); each could be useful for different scenarios.
To provide a standard Java API for processing JSON, the JSR 353 (Java API for JSON Processing) was submitted to the JCP in 2011 and was released with Java EE 7.
JSON-P
Java API for JSON Processing (JSR 353) known as JSON-P, is a specification that allows JSON processing in Java. The processing includes mechanisms to parse, generate, transform, and query JSON data. JSON-P provides a standard to build a Java object in JSON using an API similar to DOM for XML. At the same time, it provides a mechanism to produce and consume JSON by streaming in a manner similar to StAX for XML.
Although it is not a strict requirement in the original JSR, some JSON-P implementations may also provide binding of JSON data to Java objects and vice versa (but this will be specified in a future JSR, which could be called JSON-B, ‘B’ for Binding). Table 12-10 lists the important JSON-P packages.
Table 12-10. The JSON-P Packages
| Package | Description |
|---|---|
| javax.json | Provides an API to describe JSON data structure (e.g. JsonArray class for JSON array and JsonObject class for JSON object), provides the entry point to parse, build, read, and write JSON objects and arrays by streaming |
| javax.json.spi | Service Provider Interface (SPI) to plug JsonParser and JsonGenerator implementations |
| javax.json.stream | Provides a streaming API to parse and generate JSON |
Reference Implementation
There are several JSON processors implemented in Java, but the open source reference implementation for JSON-P (JSR 353) is JSON RI.
JSON Processing
JSON-P provides two different programming models to process JSON documents: the Object Model API, and the Streaming API. Similar to the DOM API for XML, the Object Model API provides classes to model JSON objects and arrays in a treelike structure that represent JSON data in memory. As with the DOM API, the Object Model API provides flexible navigation and queries to the whole content of the tree.
The streaming API is a low-level API designed to process large amounts of JSON data efficiently. The Streaming API is much like the StAX API for XML. It provides a way to stream JSON without maintaining the whole document in memory. The streaming API provides an event-based parser based on a pull parsing streaming model, enabling the user to process or discard the parser event, and ask for the next event (pull the event). JSON Generator also helps you to generate and write JSON in by streaming.
The JSR 353 has a main javax.json.Json API, which is a class for creating JSON processing objects. This central API has methods to create a JsonParser, JsonGenerator, JsonWriter, JsonReader, JsonArrayBuilder and JsonObjectBuilder.
The object and array structures in JSON are represented by the javax.json.JsonObject and javax.json.JsonArray classes. The API lets you navigate and query the tree structure of data.
JsonObject provides a Map view to access the unordered collection of zero or more name/value pairs. Similarly, JsonArray provides a List view to access the ordered sequence of zero or more values. The API uses the builder patterns to create the tree representation of JsonObject and JsonArray through the javax.json.JsonObjectBuilder and javax.json.JsonArrayBuilder interfaces.
Listing 12-15 shows how to build the purchase order in JSON described in Listing 12-14. As you can see, the Json class is used to create JsonObjectBuilder and JsonArrayBuilder objects that will end up building a JsonObject (using the final build() method). JsonObject provides a map view to the JSON object name/value mappings.
Listing 12-15. The OrderJsonBuilder Class Building a Purchase Order in JSON
public class OrderJsonBuilder {
public JsonObject buildPurchaseOrder() {
return Json.createObjectBuilder ().add("order", Json. createObjectBuilder ()
.add("id", "1234")
.add("date", "05/06/2013")
.add("customer", Json. createObjectBuilder ()
.add("first_name", "James")
.add("last_name", "Rorrison")
.add("email", " [email protected] ")
.add("phoneNumber", "+44 1234 1234"))
.add("content", Json. createObjectBuilder ()
.add("order_line", Json. createArrayBuilder ()
.add(Json. createObjectBuilder ()
.add("item", "H2G2")
.add("quantity", "1")
.add("unit_price", "23.5"))
.add(Json. createObjectBuilder ()
.add("item", "Harry Potter")
.add("quantity", "2")
.add("unit_price", "34.99"))))
.add("credit_card", Json. createObjectBuilder ()
.add("number", "1357")
.add("expiry_date", "10/13")
.add("control_number", "234")
.add("type", "Visa"))). build ();
}
}
The JsonObject can also be created from an input source (such as InputStream or Reader) using the interface javax.json.JsonReader. The following example shows how to read and create the JsonObject using the interface JsonReader. A JsonReader is created from an order.json file (Listing 12-14). Then, to access the order object, the getJsonObject() method is called and returns a JsonObject. If no object is found, null is returned:
JsonReader reader = Json.createReader(new FileReader("order.json"));
JsonObject jsonObject = reader.readObject();
jsonObject = jsonObject.getJsonObject("order");
JsonReader also provides the general read() method to read any javax.json.JsonStructure subtype (JsonObject and JsonArray). Using the JsonStructure.getValueType() method returns the ValueType (ARRAY, OBJECT, STRING, NUMBER, TRUE, FALSE, NULL) and then you can read the value. The toString() method on JsonStructure returns the JSON representation of the object model.
Similarly, JsonObject and JsonArray can be written to an output source (such as OutputStream or Writer) using the class javax.json.JsonWriter. The builder method Json.createWriter()can create a JsonWriter for different outputs.
The Streaming API (package javax.json.stream) facilitates parsing JSON via streaming with forward and read-only access. It provides the javax.json.stream.JsonParser interface to parse a JSON document. The entry point is the javax.json.Json factory class, which provides a createParser() method that returns a javax.json.stream.JsonParser from a specified input source (such as a Reader or an InputStream). As an example, a JSON parser for parsing an empty JSON object could be created as follows:
StringReader reader = new StringReader("{}");
JsonParser parser = Json.createParser(reader);
You can configure the parser by passing a Map property to the createParserFactory() method. This factory creates a JsonParser specifically configured to parse your JSON data:
StringReader reader = new StringReader("{}");
JsonParserFactory factory = Json.createParserFactory(properties) ;
JsonParser parser = factory.createParser (reader);
The JsonParser is based on a pull parsing streaming model. Meaning that the parser generates events when a JSON name/value is reached or the beginning/end of an object/array is read. Table 12-11 lists all of the events triggered by the parser.
Table 12-11. JSon Parsing Events
| Package | Description |
|---|---|
| START_OBJECT | Event for start of a JSON object (fired when { is reached) |
| END_OBJECT | Event for end of an object (fired when } is reached) |
| START_ARRAY | Event for start of a JSON array (fired when [ is reached) |
| END_ARRAY | Event for end of an array (fired when ] is reached) |
| KEY_NAME | Event for a name in name(key)/value pair of a JSON object |
| VALUE_STRING | Event for a string value |
| VALUE_NUMBER | Event for a number value |
| VALUE_TRUE | Event for a true value |
| VALUE_FALSE | Event for a false value |
| VALUE_NULL | Event for a null value |
The class in Listing 12-16 parses the JSON in Listing 12-14 (saved in an order.json file) to extract the customer’s e-mail. The parser moves forward until it encounters an email property name. The next() method causes the parser to advance to the next parsing state. It returns the next javax.json.stream.JsonParser.Event enum (Table 12-11) of for the next parsing state. When the parser reaches the email property value, it returns it.
Listing 12-16. The OrderJsonParser Class Parsing the JSON Representation of the Purchase Order
public class OrderJsonParser {
public String parsePurchaseOrderAndReturnEmail() throws FileNotFoundException {
String email = null;
JsonParser parser = Json.createParser (new FileReader("src/main/resources/ order.json "));
while ( parser.hasNext() ) {
JsonParser.Event event = parser.next();
while (parser.hasNext() && !( event.equals (JsonParser.Event. KEY_NAME ) && →
parser.getString().matches(" email "))) {
event = parser. next ();
}
if ( event.equals (JsonParser.Event. KEY_NAME ) && parser.getString().matches(" email ")) {
parser.next();
email = parser. getString ();
}
}
return email;
}
}
By using the Event.equals() method, you can determine the type of the event and process the JSON based on the event. While the JsonParser streams the JSON, you can use the getString() method to get a String representation for each name (key) and value depending on the state of the parser. The name is returned if the event is KEY_NAME, the String value is returned when the event is VALUE_STRING, and the number value when the event is VALUE_NUMBER. In addition to getString(), which returns a String value, you can use other methods such as getIntValue(), getLongValue(), and getBigDecimalValue(), depending on the type.
If an incorrect data format is encountered while parsing, the parser will throw runtime exceptions such as javax.json.stream.JsonParsingException and java.lang.IllegalStateException, depending on the source of the problem.
Generating JSON
The JSON builder APIs allow you to build a JSON tree structure in memory. The JsonParser parses a JSON object via streaming, whereas the javax.json.stream.JsonGenerator allows the writing of JSON to a stream by writing one event at a time.
The class in Listing 12-17 uses the createGenerator() method from the main javax.json.Json factory to get a JsonGenerator and generates the JSON document defined in Listing 12-14. The generator writes name/value pairs in JSON objects and JSON arrays.
Listing 12-17. Generating a Purchase Order Object In JSON
public class OrderJsonGenerator {
public StringWriter generatePurchaseOrder() throws IOException {
StringWriter writer = new StringWriter();
JsonGenerator generator = Json.createGenerator (writer);
generator. writeStartObject ()
.write("id", "1234")
.write("date", "05/06/2013")
. writeStartObject ("customer")
.write("first_name", "James")
.write("last_name", "Rorrison")
.write("email", " [email protected] ")
.write("phoneNumber", "+44 1234 1234")
. writeEnd ()
. writeStartArray ("content")
. writeStartObject ()
.write("item", "H2G2")
.write("unit_price", "23.5")
.write("quantity", "1")
.writeEnd()
.writeStartObject()
.write("item", "Harry Potter")
.write("unit_price", "34.99")
.write("quantity", "2")
.writeEnd()
. writeEnd ()
.writeStartObject("credit_card")
.write("number", "123412341234")
.write("expiry_date", "10/13")
.write("control_number", "234")
.write("type", "Visa")
.writeEnd()
.writeEnd()
. close ();
return writer;
}
}
Familiarity with object and array contexts is needed when generating JSON. JSON name/value pairs can be written to an object, whereas JSON values can be written to an array. While the writeStartObject() method writes a JSON start object character ({), the writeStartArray() method is used to write a JSON start array character ([). Each opened context must be terminated using the writeEnd() method. After writing the end of the current context, the parent context becomes the new current context.
The writeStartObject() method is used to start a new child object context and the writeStartArray() method starts a new child array context. Both methods can be used only in an array context or when a context is not yet started and both can only be called when no context is started. A context is started when one of these methods are used.
The JsonGenerator class provides other methods, such as write(), to write a JSON name/value pair in the current object context or to write a value in current array context.
Although the flush() method can be used to write any buffered output to the underlying stream, the close() method closes the generator and frees any associated resources.
Putting It All Together
By putting the concepts of this chapter all together, let’s write a CreditCard POJO and use JAXB and JSON-P to get an XML and JSON representation of the credit card. To test both formats we will write unit tests. The CreditCardXMLTest class marshalls and unmarshalls the CreditCard to check that the XML representation is correct. The CreditCardJSonTest class checks that the generated JSON is also well formatted.
Writing the CreditCard Class
The CreditCard class in Listing 12-18 is annotated with the JAXB @XmlRootElement annotation to be marshalled into XML. The other JAXB annotation @XmlAccessorType, with parameter XmlAccessType.FIELD, tells JAXB to bind the attributes rather than the getters.
Listing 12-18. The CreditCard Class with a JAXB Annotation
@XmlRootElement
@XmlAccessorType(XmlAccessType.FIELD)
public class CreditCard {
@XmlAttribute
private String number;
@XmlElement(name = "expiry_date")
private String expiryDate;
@XmlElement(name = "control_number")
private Integer controlNumber;
private String type;
// Constructors, getters, setters
}
The CreditCard object has some basic fields such as the credit card number, the expiry date (formatted as MM/YY), a credit card type (Visa, Master Card, American Express, etc.), and a control number. Some of these attributes are annotated with @XmlAttribute to be mapped to an XML attribute. The @XmlElement is used to override the XML element name.
Writing the CreditCardXMLTest Unit Test
The CreditCardXMLTest class shown in Listing 12-19 marshalls and unmarshalls a CreditCard object back and forth from XML to Java using the JAXB marshalling mechanism. The shouldMarshallACreditCard method creates an instance of the CreditCard class and checks it has the correct XML representation. The method shouldUnmarshallACreditCard does the opposite as it unmarshalls the XML document into a CreditCard instance and checks that the object is correctly set.
Listing 12-19. The CreditCardXMLTest Unit Test Marshalls and Unmarshalls XML
public class CreditCardXMLTest {
public static final String creditCardXML =
"<?xml version="1.0" encoding="UTF-8" standalone="yes"?> " +
"<creditCard number="12345678"> " +
" <expiry_date>10/14</expiry_date> " +
" <control_number>566</control_number> " +
" <type>Visa</type> " +
"</creditCard>";
@Test
public void shouldMarshallACreditCard () throws JAXBException {
CreditCard creditCard = new CreditCard("12345678", "10/14", 566, "Visa");
StringWriter writer = new StringWriter();
JAXBContext context = JAXBContext.newInstance(CreditCard.class);
Marshaller m = context.createMarshaller();
m.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE);
m. marshal (creditCard, writer);
System.out.println(writer);
assertEquals( creditCardXML , writer.toString().trim());
}
@Test
public void shouldUnmarshallACreditCard () throws JAXBException {
StringReader reader = new StringReader( creditCardXML );
JAXBContext context = JAXBContext.newInstance(CreditCard.class);
Unmarshaller u = context.createUnmarshaller();
CreditCard creditCard = (CreditCard) u. unmarshal (reader);
assertEquals("12345678", creditCard.getNumber());
assertEquals("10/14", creditCard.getExpiryDate());
assertEquals((Object) 566, creditCard.getControlNumber());
assertEquals("Visa", creditCard.getType());
}
}
Writing the CreditCardJSonTest Unit Test
The CreditCardJSonTest class shown in Listing 12-20 uses the JsonGenerator API to write a JSON object representation of a CreditCard. It then checks that the JSonObject has a valid syntax by comparing it to the creditCardJSon constant.
Listing 12-20. The CreditCardJSonTest Unit Test Generates JSon
public class CreditCardJSonTest {
public static final String creditCardJSon =
"{"creditCard":" +
"{"number":"12345678"," +
""expiryDate":"10/14"," +
""controlNumber":566," +
""type":"Visa"}" +
"}";
@Test
public void shouldGenerateACreditCard(){
CreditCard creditCard = new CreditCard("12345678", "10/14", 566, "Visa");
StringWriter writer = new StringWriter();
JsonGenerator generator = Json.createGenerator(writer);
generator.writeStartObject()
.writeStartObject("creditCard")
.write("number", creditCard.getNumber())
.write("expiryDate", creditCard.getExpiryDate())
.write("controlNumber", creditCard.getControlNumber())
.write("type", creditCard.getType())
.writeEnd()
.writeEnd()
.close();
assertEquals( creditCardJSon , writer.toString().trim());
}
}
Summary
XML is more than just a text format for describing documents. It is a mechanism for describing platform-independent complex structured data. Java provides a set of powerful, lightweight APIs to parse, validate, and generate XML data. Different parsing models such as DOM, SAX, and StAX are supported in Java. Although you can use low-level Java APIs to work with XML based on DOM or SAX models, the JAXP API provides the wrapper classes to parse your XML resources based on the DOM or SAX model and transfers the XML document using XSLT and XPath.
Java Architecture for XML Binding (JAXB) defines a standard to bind Java representations to XML and vice versa. It provides a high level of abstraction, as it is based on annotations. Even if JAXB can be used in any kind of Java application, it fits well in the web service space because any information exchanged is written in XML, as you will see in Chapter 14.
JSON is a lightweight data-interchange format. It is an alternative to XML, and its suggested use is for simpler data structures. JSON-P facilitates parsing and generating data in JSON format via streaming. Even if the JAXB equivalent in JSON doesn’t exist yet, specifications such as JAX-RS use JSON-P to return JSON objects from RESTful web services (see Chapter 15).