
![]()
Before speaking about ASP.NET Web API itself, we need to provide some fundamentals to get a better understanding of why ASP.NET Web API works as it does. The very basic goal of ASP.NET Web API was to make HTTP a first-class citizen in .NET and provide a foundation for RESTful applications based on the .NET Framework. So in order to understand the Web API framework better, we will explain the fundamentals of HTTP, REST and hypermedia, starting with HTTP basics.
HTTP Basics
As just mentioned, ASP.NET Web API primarily is about handling the HTTP protocol in an efficient and fluent manner using .NET, so we need a good understanding of HTTP.
Consider a scenario now happening billions of times a day. A user types www.google.com into a web browser, and within a few milliseconds she gets the Google search start page rendered in her browser. This is a simple request and response technique which is displayed simplified in Figure 3-1.

Figure 3-1. Simplified request response model between browser and server
As you can imagine, this doesn’t happen without some technical stuff under the hood, and that’s where HTTP enters the room.
HTTP is the abbreviation for “hypertext transfer protocol,” which handles the communication (through the requests and responses) between the user’s web browser and web servers (in this case Google’s). To speak in a more generalized manner, the web browser is an HTTP client and the web server is just an HTTP server.
As HTTP is a communication protocol, it has a set of standardized elements, both of which the server and the client need to be able to deal with. We’ll explain each of them in the following sections in detail.
Basically, all pages in web sites in the World Wide Web (WWW) are regarded as resources, and that’s exactly what they’re called in HTTP language. But resources in HTTP are not just files in the form of HTML web pages. In general, a resource is any piece of information that can be unambiguously identified by a Uniform Resource Identifier (URI), such as http://microsoft.com/windows. (In nontechnical contexts and on the World Wide Web, the term URL—uniform resource locator—is also used.)
A URI consists of a URI scheme name such as “http” or “ftp” followed by a colon character and then by a scheme-specific part. The scheme-specific part’s syntax and semantics are defined in scheme specifications, where they share a general syntax that reserves certain characters for special purposes. The general syntax is as follows, according to RFC 3986:
<scheme name> : <hierarchical part> [ ? <query> ] [ # <fragment> ]
The HTTP protocol uses the generic syntax, as the following URI shows:
http://www.apress.com/web-development/web-api?dir=asc&order=name
In that sample URI, the scheme name is “http”; it is followed by the hierarchical part, “www.apress.com/web-development/web-api”, which is also referred to as path. The hierarchical part usually starts with “//”, as shown in the sample URI. It also contains an optional query, which is “dir=asc&order=name” here.
An example of a URI containing the optional fragment part would be the following:
http://localhost/wiki/rest#hypermedia
In this example, “hypermedia” is the fragment part.
In order to provide consistency, the syntax of the URI also enforces restrictions on the scheme-specific part.
To handle actions on URIs (i.e., our resources), HTTP uses so-called HTTP request methods—also referred as to “verbs.” There are a few of them, and we’ll take a look at the most important ones now.
- GET
- POST
- PUT
- DELETE
One of the HTTP request methods frequently used in web browsers is GET. GET is always used when requesting a URL like microsoft.com.
With that in mind, Figure 3-2 takes a more technical look at the previous request/response model.
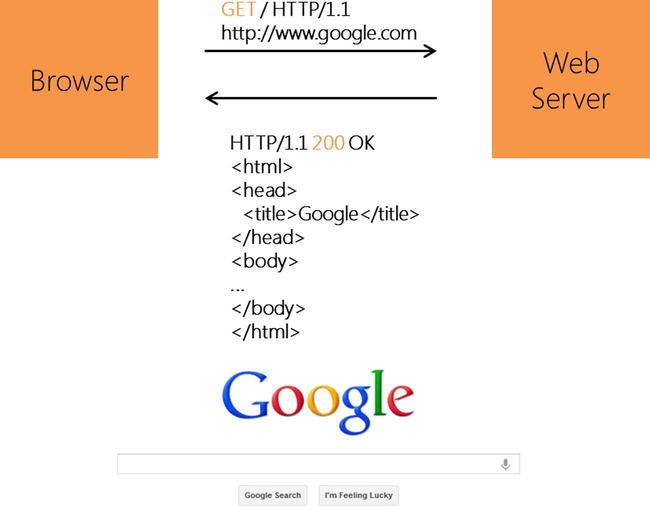
Figure 3-2. A request/response model between browser and server using the HTTP protocol
You can see now what’s happening at the level of HTTP: the client sends a request to the server, with the first line of the request looking like this:
GET / HTTP/1.1 http://www.google.com
Just as it sounds, GET is telling the server that we want to get a resource from it. Which resource is told here by the slash, “/”, following GET, which in this case is the resource at the root of the server. This often (not to say always) is mapped to a default document such as “index.htm” or “default.htm” in the case of Microsoft Internet Information Services (IIS). If you want to receive another resource, you need to specify the resource’s identifier after the slash, for example, “/search”.
Another important verb is POST, which allows you to send data to the server. If you have a web development background, you may have seen POST when submitting HTML forms to the server, as shown in Listing 3-1.
Listing 3-1. An HTML 5 Form That Is Sent Using the POST Method
<form action="http://www.example.org/feedback" method="post">
<input name="firstname" type="text" />
<input name="lastname" type="text" />
<input name="email" type="email" />
<textarea name="feedback" />
<button type="submit">Send Feedback</button>
</form>
Very similar to POST is PUT, but PUT is used for updating a resource. As surprising as it may seem, the HTTP specification was written with that in mind; also, you won’t be able to invoke it from within your browser.
Once this is understood, it seems quite logical that HTTP also provides a DELETE method.
To get a deeper understanding of which method should be used and when to use it, let’s inspect the HTTP methods under the aspects of safety and idempotency.
Some methods (e.g., GET and OPTIONS) are defined as safe. That means they should not have side effects. Exceptions to that are effects such as logging, caching, and incrementing an access counter. Issuing arbitrary GET requests should therefore be considered safe if they’re not changing the application’s state.
In contrast, methods such as POST, PUT, and DELETE are used for actions that do create side effects on the server; also included are subsequent external effects, such as a sent e-mail.
When it comes to implementation, you should be aware that although GET requests are called safe, their handling by the server is not technically limited in any way. As a consequence, you can write code that can very well lead to side effects on the server. In a RESTful application, you should absolutely avoid that, because it can cause problems for web caching, search engines and other automated agents, all of which rely on the safety of GET.
The methods PUT and DELETE are defined as idempotent. That means that multiple identical requests should have the same effect as a single request. As HTTP is a stateless protocol, the methods being prescribed as safe (namely, GET, HEAD, OPTIONS and TRACE) should also be idempotent.
![]() Note Idempotence refers to the state of the system after the request has completed. That means that the action the server takes (e.g., deleting a customer) or the response code it returns may differ for subsequent requests, but the system state will be the same every time.
Note Idempotence refers to the state of the system after the request has completed. That means that the action the server takes (e.g., deleting a customer) or the response code it returns may differ for subsequent requests, but the system state will be the same every time.
In contrast, the POST method is not necessarily idempotent. Thus, sending the same POST request multiple times may further affect state or cause further side effects (such as sending e-mails). There may be some cases where this is wanted. But there may also be cases where it happens by accident, such as when the user, having failed to receive adequate feedback that the first request was successful, sends another request. Also, most web browsers warn users in cases where reloading a page may reissue a POST request; generally the web application is responsible for handling when a POST request should only be submitted once.
As with safety, whether a method is idempotent is not enforced by the protocol or handling on the server. For example, it is easily possible to write a web application in which a database insert or other non-idempotent action is invoked by a GET or some other HTTP method. If you ignore this, your requests may have undesirable consequences. Remember that clients assume the correct behavior when repeating a request.
HTTP Status Codes
HTTP Status codes are another important part of the HTTP protocol. Look again at Figure 3-2; you will see that the server returns not only an HTML page but also this:
HTTP/1.1 200 OK
200 is a status code; it means “everything is OK”—that is, the server found the requested resource and has been able to send it to the client.
This status code is always returned when you browse the Web and everything works fine; you won’t see the status code itself, however.
A status code you might have already seen in your browser is the 404 status code; it means that the requested resource identified by the URI you sent to the server could not be found.
There are other status codes, including 303, which stands for “see other”—that is, the resource of the initial request can be found under a different URI and should be retrieved using the GET method on that URI.
If you have tried to access a web server that has been under heavy load, you might have also seen a 503 status code—for “Service Unavailable”—in your browser. That message means that the server is overloaded or under maintenance.
If you compare the preceding status codes, you will notice that not only do they have different values as a whole but they also start with different digits. That is so because they are divided into five classes.
- 1xx—Informational—indicates a provisional response, which consists only of the status line and optional headers. The status code line is terminated by an empty line. This class of status code does not require any headers.
- 2xx—Successful—indicates that the client’s request was successfully received, understood, and accepted.
- 3xx—Redirection—indicates that the client needs to take further action in order to complete the request. The action required may be carried out by the client without user interaction when the second request method is GET or HEAD. In addition, a client should detect infinite redirection loops.
- 4xx—Client Error—should be used if the client seems to have done something wrong. For all requests other than HEAD, the server should include a response body explaining the error, whether the error is temporary or permanent, and whether the response body should be shown to the user. The 4xx status can be applied to any request method.
- 5xx—Server Error—indicates cases where the server is aware that it is responsible for an error or is not able to perform the request For all requests other than HEAD, the server should include a response body explaining the error, whether the error is temporary or permanent, and whether the response body should be shown to the user. The 5xx status can be applied to any request method.
The HTTP protocol defines many more status codes besides, but we’ll stick with these.
HTTP in Action
To see how URIs, resources, verbs, and status codes play together within requests and responses, let’s take a closer look at the Apress web site.
Figure 3-3 shows how the site looks in the browser of your choice.

Figure 3-3. The Apress web site inside the browser
As there’s nothing uncommon to see (besides great books), let’s dig a little bit deeper using Fiddler, which was introduced in the “Know Your Tools” section in Chapter 1.
First, let’s issue a new request inside the Composer tab to the URI http://apress.com, as shown in Figure 3-4.
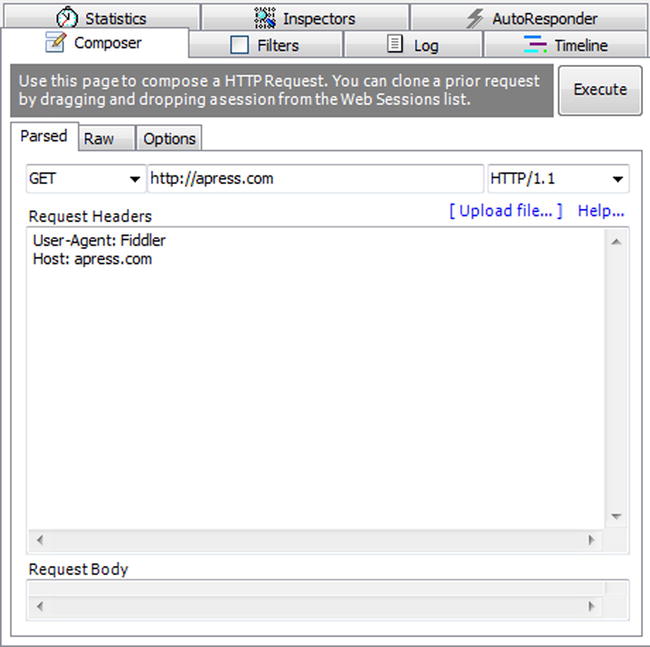
Figure 3-4. Issuing a new request to apress.com using Fiddler
Now let’s take a look at the left section of Fiddler, as shown in Figure 3-5, where the list of issued requests contains two new entries.

Figure 3-5. The left section of the Fiddler request to apress.com
You might wonder why there are two requests. That’s because we issued http://apress.com , which sent a 302 status code response to the client. The 302 status code tells the client that the requested resource is temporarily available under another URI. If you select the 302 response from the left list, you can inspect it in the lower right window by clicking the Raw tab, as shown in Figure 3-6.
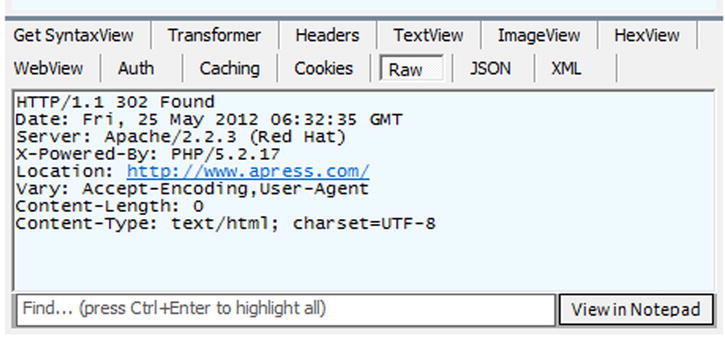
Figure 3-6. A 302 response in Fiddler
Please take note of the line containing
Location: http://www.apress.com/
That information tells the client where to find the temporary new location of the requested resource specified by http://apress.com/. The new location is http://www.apress.com/; that’s where the second request is issued automatically by the browser itself.
Notice the response for that request inside the WebView tab of Fiddler, as shown in Figure 3-7; it looks totally different from the browser view of Figure 3-3.
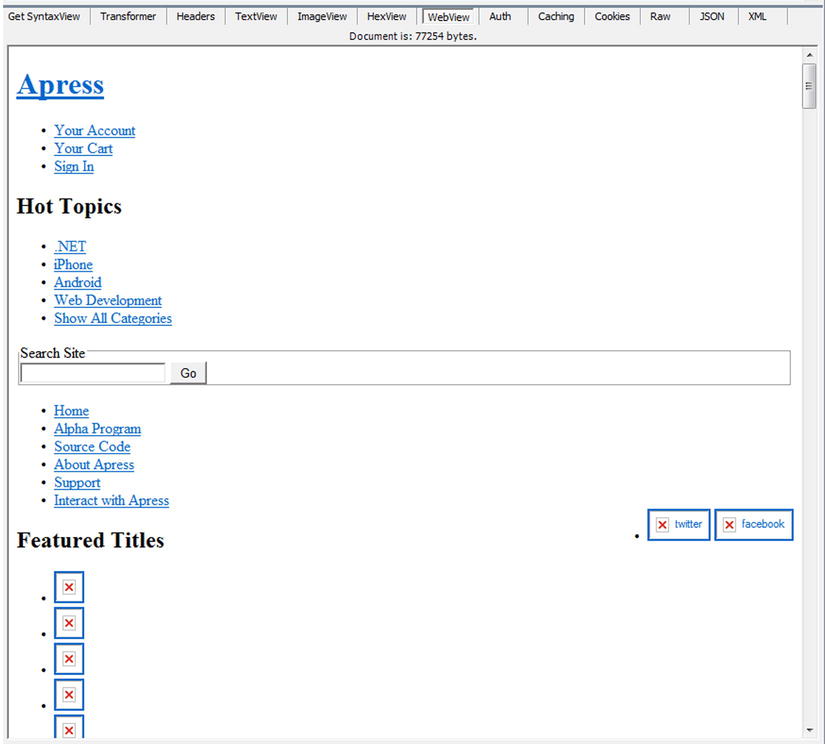
Figure 3-7. Apress web site in Fiddler WebView
The reason for that is that the returned HTML code does not contain any style sheets, scripts, or pictures.
The style sheets in particular are referenced by <link /> HTML tags, which tell the browser (more generally, the client) to follow them, fetch their resources (i.e., the style sheet), and use them to render the HTML representation of the web page according to the format definitions inside the style sheet. We’ll take a closer look at the <link /> tags later in this chapter.
In Figure 3-6 we saw the following line:
Location: http://www.apress.com/
Around that line are Content-Type, Content-Length, and a few others. Each of them is a so-called HTTP Header Field. These fields exist in both requests and responses. Most of them differ for requests and responses, but some, such as content-type, exist on both sides of the HTTP protocol.
HTTP Header Fields define parameters for the HTTP operation; we’ll be using some of them throughout the book.
One of the most important HTTP Header Fields is the aforementioned content-type header, which tells the other side (request or response) which type the transmitted content is. In the case of web pages, the content-type is text/html, and the complete header definition looks like this:
content-type: text/html
The phrase “text/html” is an identifier for a file format on the Internet and is called an Internet media type.
Internet Media Types
Internet media types were originally called MIME types (Multipurpose Internet Mail Extensions), but their use has expanded from e-mails sent using the SMTP protocol to HTTP and other Internet protocols.
As was seen in the text/html media type definition, it consists of (at least) two parts, where the first is a type and the second is a subtype. Either can be followed by one or more parameters.
We’ll get deeper insight into Internet media types (or just content-types, as they are also referred to) in “Shifting to a RESTful Architecture” and sections that follow it in this chapter.
If you need more detailed information about the HTTP protocol and its elements, read RFC 2616, the specification of the HTTP protocol; it can be found at https://www.ietf.org/rfc/rfc2616.txt.
Now that you have a very basic understanding of the HTTP protocol and its most important concepts—resources, URIs, HTTP methods, status codes, headers and media types—let’s head over to Service Oriented Architectures to see how they have been created within the last decade.
In this section, we will first consider Service Oriented Architectures (SOA) using a SOAP example, as this has become a familiar solution nowadays. With that context in mind, we will look at REST, which is an architectural style for distributed applications introduced first by Roy T. Fielding in his doctoral dissertation in the year 2000. Throughout the section, we’ll see how we can improve SOA by moving toward a RESTful architecture.
Service Oriented Architectures and HTTP
If you’ve heard about Service Oriented Architectures, you might also have heard about or even used SOAP in a distributed application—as in the .NET ecosystem, represented by ASMX web services, or Windows Communication Foundation (WCF).
The original meaning of SOAP was “Simple Object Access Protocol”; it was a specification for exchanging structured data (i.e., XML) using web services built on top of the HTTP protocol.
As it relies on HTTP, it also follows the request/response model, where both request and response are represented by XML documents, called messages.
A typical SOAP request message representing a request to a customer service that returns a customer named Microsoft might look like Listing 3-2.
Listing 3-2. A Typical SOAP Request Message
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.example.org/customer">
<m:GetCustomer>
<m:CustomerName>Microsoft</m:CustomerName>
</m:GetCustomer>
</soap:Body>
</soap:Envelope>
The message consists of some header information and a so-called envelope, which contains the message body.
The method of the addressed customer service that should be invoked is the GetCustomer method, and the required parameter is CustomerName, where the value is Microsoft.
In SOAP the message above (to get a customer resource) is POSTed to the server via HTTP protocol, because according to the HTTP specification, the method to send (new) content from the client to the server is POST, as you can see in Listing 3-3.
Listing 3-3. HTTP POST Request in SOAP
POST /customerservice HTTP/1.1
Host: www.example.org
Content-Type: application/soap+xml; charset=utf-8
Content-Length: 332
After some operations involving the database, the service might return the customer wrapped in a response message such as the one shown in Listing 3-4.
Listing 3-4. SOAP Response Message
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.example.org/customer">
<m:GetCustomerResponse>
<m:CustomerId>123</m:CustomerId >
<m:CustomerName>Microsoft</m:CustomerName>
</m:GetCustomerResponse>
</soap:Body>
</soap:Envelope>
As everything went fine during request and response, the response header will look like Listing 3-5.
Listing 3-5. Response Headers of a SOAP Response
HTTP/1.1 200 OK
Content-Type: application/soap+xml
charset=utf-8
Content-Length: 390
Now let’s try that again, but this time let’s imagine that we mistyped the customer name and our new request is the one from Listing 3-6.
Listing 3-6. SOAP Request with Mistyped Customer Name
POST /customerservice HTTP/1.1
Host: www.example.org
Content-Type: application/soap+xml; charset=utf-8
Content-Length: 332
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.example.org/customer">
<m:GetCustomer>
<m:CustomerName>Microsft</m:CustomerName>
</m:GetCustomer>
</soap:Body>
</soap:Envelope>
The response generated by the server might easily be the one in Listing 3-7.
Listing 3-7. SOAP Response to Request with Mistyped Customer Name
HTTP/1.1 200 OK
Content-Type: application/soap+xml
charset=utf-8
Content-Length: 390
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.example.org/customer">
<soap:Fault>
<faultcode>soap:Server</faultcode>
<faultstring>Customer could not be found.</faultstring>
<detail />
</soap:Fault></soap:Body>
</soap:Envelope>
As you can see, the server tells you that it couldn’t find a customer with the name Microsft—well, you are to blame!
That’s how we’ve handled SOA many times for many years. More or less we have been happy with it—but does that mean it’s been the best way? We’ll try to answer that question within the next section.
Shifting to a RESTful Architecture
Now let’s inspect the two requests and responses again; this time let’s focus on the HTTP headers, status codes, and methods being used.
First things first, we POST the requests to get data from the server. Again, we send data to get data.
At the very beginning of this chapter, we mentioned two things that contrast with that behavior:
- HTTP uses URIs to unambiguously identify resources.
- HTTP uses GET to retrieve representations of resources from the server.
With that in mind, wouldn’t it be more natural to get (or at least try to get) the customer named Microsoft that way?
GET /customer/Microsoft HTTP/1.1 http://www.example.org
That request lets us get exactly the same result as the first SOAP request got, but with three improvements:
- The URI identifying the resource for the customer named Microsoft is unique now.
- GET is the semantically right method to request the customer data.
- We don’t need to send a request body that consumes bandwidth unnecessarily and is potentially slower.
![]() Note ASP.NET Web API makes it quite easy for you to embrace REST and create a RESTful application, but it doesn’t force you to do so.
Note ASP.NET Web API makes it quite easy for you to embrace REST and create a RESTful application, but it doesn’t force you to do so.
After tweaking the client side, let’s head over to the server. When comparing both responses shown before, there’s one commonality—the responses start with the following line:
HTTP/1.1 200 OK
Well, what’s wrong with that? In the SOAP world, that’s totally fine, as both responses are able to ship their response message: the XML containing the SOAP envelope containing a representation of the requested customer.
Really? Remember that the second response contained an error code and no customer. So not everything has been OK, as the status code 200 indicates; instead, the customer requested has not been found.
What would be a better and a more obvious solution? Earlier in this chapter we learned that there are far more status codes than the 200 OK. To be honest, we have already seen the solution to our problem above: it’s status code 404 Not Found, which should be thrown when the server has not found anything matching the requested parameter in the URI.
So if we return
HTTP/1.1 404 NOT FOUND
we’re telling the client exactly the same thing we did with our full-blown XML response message before.
The shift from SOAP to a more HTTP-oriented approach did work well for GET and thus for getting data from the server. But will it also work if we want to create data on the server?
Of course, it does; that’s how our request and response look, as shown in Listings 3-8 and 3-9.
Listing 3-8. Request for Creating a New Customer Using HTTP
POST /customers/ HTTP/1.1
Content-Type: application/vnd.247app.customer+xml
Accept: application/vnd.247app.customer+xml
<customer xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.example.org">
<name>Apress</name>
<address>233 Spring Street</address>
<city>New York</city>
</customer>
Listing 3-9. Response After Creating a Customer Using HTTP
HTTP/1.1 201 CREATED
Location: http://www.example.org/customer/42
<customer xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.example.org">
<id>42</id>
<name>Apress</name>
<address>233 Spring Street</address>
<city>New York</city>
<link rel="self" href="http://www.expample.org/customer/42" />
<link rel="previous" href="http://www.example.org/customer/41" />
</customer>
Now let’s inspect the request first. Since we’re aiming to create a new customer, the request is a POST operation. The POST is addressed to the /customers URI. That’s because we’re adding another customer to an already existing list of customers.
By specifying the content-type header with its value application/vnd.247app.customer+xml, we tell the server that we’re sending the customer data for our application to it. The format application/vnd.247app.customer+xml is not a definition made or registered by an official organization like IANA; it’s a definition we made to describe the format of our request or response content being sent around. What application/vnd says is that the Internet media type defined by it is vendor specific (i.e., us); 247app is the name of our application, and customer+xml indicates that it represents a customer resource based on the XML format.
If you prefer the JSON (JavaScript Object Notation) format to XML, your media type definition would look like this: application/vnd.247app.customer+json. That’s the only thing you’d have to modify to tell the server or client which format you want to get or send your customer representation. You don’t have to attach /xml or /json to your URI—it’s tied into HTTP from the very beginning.
![]() Note Don’t worry if you don’t know exactly what JSON is. It’ll be explained in Chapter 12.
Note Don’t worry if you don’t know exactly what JSON is. It’ll be explained in Chapter 12.
So if you’d like to provide a PNG image of your customers logo, you could still use the URI http://www.example.org/customer/{id}/; by specifying the content-type application/png or, being even more specific, application/vnd.247app.customerlogo+png, you tell the server that it should stream a PNG image.
Now let’s get back to the request we’re sending our server using POST. There’s a second HTTP header, Accept, and its value is application/vnd.247app.customer+xml. By providing the Accept header, we tell the server which media type we’re expecting to get within the response for our current request. That’s what we’re inspecting next.
The head line of the response is
HTTP/1.1 201 CREATED
which introduces another HTTP status code to us. Instead of just telling us that our request has been processed and everything is OK (200), that response is more specific; it says that the customer has been CREATED (201) based on the input POSTed to the server.
The next response header is one we saw earlier in this chapter.
Location: http://www.expample.org/customer/42
It tells the client where to find the newly created customer so that the client can store that information for later use.
Listing 3-10 shows the response body, consisting of the requested application/vnd.247app.customer+xml media type.
Listing 3-10. Response body for application/vnd.247app.customer+xml media type
<customer xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.example.org">
<id>42</id>
<name>Apress</name>
<address>233 Spring Street</address>
<city>New York</city>
<link rel="self" href="http://www.expample.org/customer/42" type="
application/vnd.247app.customer+xml" />
<link rel="previous" href="http://www.example.org/customer/41" type="
application/vnd.247app.customer+xml"/>
</customer>
But what happened to our customer? He got assigned an ID on the server side, and there are two <link /> tags inside, as the application now uses hypermedia as the Engine of Application State (HATEOAS). A client can follow the links to navigate through an application by entering a single fixed URI. This contrasts with the strongly coupled interface that SOAP has. The contrasts grow greater as the links above are generated dynamically at runtime, whereas the strongly coupled interface of SOAP is a contract being defined at the development time of the server and client.
Further operations are discovered by the media types and their provided links.
The application-specific Internet media types using links are called hypermedia. This concept allows server and client to evolve independently without each breaking functionality on the other’s side.
Now that we’ve moved very far from the SOAP messages at the beginning of this section, let’s sum up the changes with some theory behind REST and hypermedia.
REST in Theory
The architectural style which uses HTTP as an application protocol and hypermedia, as shown in the last section, is called REST (representational state transfer). The term was introduced by Roy T. Fielding in his doctoral dissertation in the year 2000.
REST is constraint driven, whereas other approaches are requirements driven. That means that REST is aware of the eight fallacies of distributed computing; the constraints of REST exist to protect an application from the effects of those fallacies.
The eight fallacies of distributed computing are
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn’t change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
By ignoring them you may add harmful effects to your application.
REST defines six constraints a RESTful architecture needs to apply to deal with the eight fallacies of distributed computing. Table 3-1 shows the six constraints and the benefits a RESTful application gains from them.
Table 3-1. The Six REST Constraints and Their Benefits
| Constraint | Benefits |
|---|---|
| Client/server | Evolvability, portability of clients, scalability |
| Stateless | Reliability, visibility, scalability |
| Cacheable | Performance, efficiency, scalability |
| Layered system | Manageability, scalability |
| Code on demand (optional) | Managing complexity, extensibility |
| Uniform interface | Evolvability, visibility |
Now let’s see how these six constraints achieve the benefits.
Client/Server
The client/server constraint improves separation of concerns by separating servers from clients. That means, the client doesn’t have to deal with data storage, and so the client is allowed to evolve independent of the server. Moreover it allows the client’s software to be ported to other platforms or programming languages. On the other hand, servers don’t need to care about user interfaces to let them evolve independently. Due to the lack of complicated UI code (besides other client-side aspects), the server-side code is more simple and scalable.
Stateless
The stateless constraint ensures that no client context is stored on the server. This constraint requires every request from any client to contain all the information necessary to process the request. All session states need to be stored on the client. The constraint embraces reliability, visibility, and scalability.
Cacheable
As is known from web browsers, clients can cache responses they receive from the servers. To prevent clients from reusing stale or inappropriate data in response to further requests, servers, implicitly or explicitly, must declare responses cacheable or not. When done right, caching may completely (certainly at least partially) make a lot of client/server interaction obsolete, with improved performance and scalability of the application being the result.
Adding intermediary servers, load balancers, or shared caches to the system improves overall scalability. Security might be improved by enforcing security policies. That way clients won’t be able to determine whether they are communicating with the end server.
Code on Demand (Optional)
The server is able to send executable code to the client to modify or add functionality on the client side. The coding, introduced with Java applets in mind, is now mainly achieved by using client-side JavaScripts.
Uniform Interface
The uniform interface was partially dealt with in the “Shifting to a RESTful Architecture” section in this chapter. In theory it consists of four concepts:
- identification of resources
- manipulation of resources through these representations
- self-descriptive messages
- Hypermedia as the engine of application state
Identification of resources means that the resources of your application can be identified by URIs. The resources are separated from their representations, which are sent to the client. This means that the servers sends, for example, an XML or JSON fragment that represents a resource, such as a customer, with its properties.
Manipulation of resources through these representations means that if a client holds a representation of a customer including, for example, the metadata and has the appropriate permission, it is able to modify or delete the resource for that representation on the server.
Self-descriptive messages means that each message includes enough information to describe how to process the message. For example, the Internet media type tells the client or server how to parse the message. Another example is the indication of cacheability in server-side response (as also shown in the Cacheable constraint).
Hypermedia as the engine of application state (HATEOAS) means that after hitting a fixed entry point URI, the client navigates through the application by dynamically generated hypermedia (hypertext with hyperlinks), which the client receives within the representations of the resources from the server.
Richardson Maturity Model
As was seen in the “Shifting to a RESTful Architecture” section, we continuously improved the application from a classical service-oriented architecture using SOAP (also referred to as “plain old XML,” or POX) toward a RESTful one.
The path from POX to the use of hypermedia inside the application has been described in a three-step model by Leonard Richardson, the Richardson Maturity Model, shown in Figure 3-8.

Figure 3-8. The Richardson Maturity Model
The Richardson Maturity Model describes the levels leading to a RESTful architecture, beginning at level 0, which is XML over HTTP (SOAP). Using the example from the preceding sections, it’s at level 0 because it was the base camp from which we started; it messed up HTTP methods and status codes and made no use of any improvement shown later. Each of the other three levels accounts for a step in the Richardson Maturity Model.
- Level 1 embraces the use of Resources, by introducing unambiguous URIs for “customer” and “customers”.
- Level 2 makes proper use of HTTP methods and status codes, both on the client and server.
- By adding hypermedia (links and custom Internet media types) to the application, the peak of REST at level 3 is finally reached.
There are a few more aspects to be seen to when planning or implementing a RESTful architecture. Some of them we’ll discover during the implementation of our sample application, as well as the implementations of ASP.NET Web API extensions in the upcoming chapters.
As has already been said, ASP.NET Web API allows you to easily embrace REST and hypermedia, but it doesn’t force you to. So if a piece of code shown in this book helps you to move toward a RESTful architecture in your application, it is marked appropriately.
Now you might ask, why should I care about REST at all?
If you’re developing a distributed application that deals with a huge number of platforms and programming languages, you should regard REST as a valid option. It is even more of a good choice if you want to support different client deployment cycles and if you’re planning to host your application in the cloud. If your application needs to deal with eventual available connectivity (think of all those mobile devices which have already entered or will someday enter the market), a RESTful implementation will lend you a hand in dealing with those issues.
Consider a RESTful application to have a network-based API instead of a library-based API.
Summary
ASP.NET Web API, in our opinion, is a great piece of software. It allows easy creation of HTTP-based applications. In this chapter we laid out the foundation for a proper understanding of what HTTP is and how to use it in an evolvable, scalable, and well-performing application.
As ASP.NET Web API was developed with those concepts as a major goal, it should be quite easy now to understand the hows and whys of ASP.NET Web API in the coming chapters.