
![]()
Semijoins and antijoins are two closely related join methods (options of join methods, actually) that the Oracle optimizer can choose to apply when retrieving information. The SQL language is designed to specify the set of data the user wishes to retrieve, but to leave the decisions regarding how to navigate to the data up to the database itself. Therefore, there is no SQL syntax to invoke a particular join method specifically. Of course, Oracle does provide the ability to give the optimizer directives via hints. In this chapter, I explain these two join optimization options, the SQL syntax that can provoke them, requirements for and restrictions on their use, and, last, some guidance on when and how they should be used.
It is important to be aware that Oracle is constantly improving the optimizer code and that not all details of its behavior are documented. All examples in this chapter were created on an Oracle 12c database (12.1.0.1). My version of 12c currently has 3332 parameters, many of which affect the way the optimizer behaves. When appropriate, I mention parameter settings that have a direct bearing on the topics at hand. However, you should verify the behavior on your own system.
Semijoins
A semijoin is a join between two sets of data (tables) in which rows from the first set are returned based on the presence or absence of at least one matching row in the other set. I revisit the “absence” of a matching row later—this is a special case of the semijoin called an antijoin. If you think back to your days in grade school math, you should be able to visualize this operation with a typical set theory picture such as the one shown in Figure 11-1.
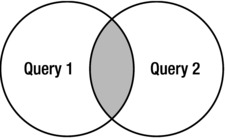
Figure 11-1. Ilustration of a semijoin
Figure 11-1 provides a basic idea of what a semijoin is but it’s not detailed enough to describe the nuances. Diagrams of this sort are called Venn diagrams; this particular Venn diagram is used often to illustrate an inner join, which is essentially an intersection. Unfortunately, there is not a convenient way to describe a semijoin completely with a Venn diagram. The main difference between a normal inner join and a semijoin is that, with a semijoin, each record in the first set (Query 1 in Figure 11-1) is returned only once, regardless of how many matches there are in the second set (Query 2 in Figure 11-1). This definition implies that the actual processing of the query can be optimized by stopping Query 2 as soon as the first match is found. And at its heart, this is what a semijoin is—the optimization that allows processing to stop before the Query 2 part is complete. This join technique is a choice that’s available to Oracle’s cost-based optimizer when the query contains a subquery inside an IN or EXISTS clause (or inside the rarely used =ANY clause, which is synonymous with IN). The syntax should look pretty familiar. Listings 11-1 and 11-2 show examples of the two most common forms of semijoin queries using IN and EXISTS.
Listing 11-1. Semijoin IN example
SQL>
SQL> select /* using in */ department_name
2 from hr.departments dept
3 where department_id IN (select department_id from hr.employees emp);
DEPARTMENT_NAME
------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
Listing 11-2. Semijoin EXISTS example
SQL> select /* using exists */ department_name
2 from hr.departments dept
3 where EXISTS (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
These two queries are functionally equivalent. That is to say, they always return the same set of data, given the same inputs. There are several other forms that are closely related. Listings 11-3 through 11-6 show several examples of closely related alternatives.
Listing 11-3. Alternatives to EXISTS and IN: Inner Join
SQL> select /* inner join */ department_name
2 from hr.departments dept, hr.employees emp
3 where dept.department_id = emp.department_id;
DEPARTMENT_NAME
------------------------------
Administration
Marketing
Marketing
Purchasing
Purchasing
Shipping
IT
IT
Public Relations
Sales
Sales
. . .
Executive
Finance
Finance
Accounting
106 rows selected.
Obviously the inner join is not functionally equivalent to the semijoin because of the number of rows returned. Note that there are many repeating values. Let’s try using DISTINCT to eliminate the duplicates. Look at Listing 11-4.
Listing 11-4. Alternatives to EXISTS and IN: Inner Join with DISTINCT
SQL> select /* inner join with distinct */ distinct department_name
2 from hr.departments dept, hr.employees emp
3 where dept.department_id = emp.department_id;
DEPARTMENT_NAME
------------------------------
Administration
Accounting
Purchasing
Human Resources
IT
Public Relations
Executive
Shipping
Sales
Finance
Marketing
11 rows selected.
The inner join with DISTINCT looks pretty good. In this case, it actually returns the same exact set of records. As previously mentioned, the INTERSECT set operation is very close to a semijoin, so let’s try that next in Listing 11-5.
Listing 11-5. Alternatives to EXISTS and IN: Ugly INTERSECT
SQL> select /* ugly intersect */ department_name
2 from hr.departments dept,
3 (select department_id from hr.departments
4 intersect
5 select department_id from hr.employees) b
6 where b.department_id = dept.department_id;
DEPARTMENT_NAME
------------------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
The INTERSECT also looks pretty good, but the syntax is convoluted. Last, let’s try the somewhat obscure =ANY keyword with a subquery in Listing 11-6.
Listing 11-6. Alternatives to EXISTS and IN: =ANY Subquery
SQL> select /* ANY subquery */ department_name
2 from hr.departments dept
3 where department_id = ANY (select department_id from hr.employees emp);
DEPARTMENT_NAME
------------------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
There isn’t much to say about the =ANY version because it is merely an alternate way of writing IN. So, to recap, the query in Listing 11-3 (inner join) doesn’t look promising because it obviously doesn’t return the same set of data. And because it returns a row for each match, the total number of records returned is 106 instead of 11. Let’s skip over the second one using the DISTINCT operator for a moment. Note that the query in Listing 11-5 (an ugly INTERSECT), although it returns the correct set of records, doesn’t look promising either because it uses convoluted syntax, even for the simple case I’m illustrating. Of course, the query in Listing 11-6 (using the =ANY syntax) is exactly the same as the IN version because IN and =ANY are the same thing.
The query in Listing 11-4 (inner join with DISTINCT) looks promising, but is it functionally equivalent to the queries in Listings 11-1 and 11-2? The short answer is no; it’s not. In many situations the inner join with the DISTINCT query returns the same data as a semijoin (using IN or EXISTS), as it does in this case. But, this is because of a convenient fluke of the data model, and it does not make the query in Listing 11-3 equivalent to the semijoin queries in Listing 11-1 and 11-2. Consider the example in Listing 11-7, which shows a case when the two forms return different results.
Listing 11-7. Semijoin and DISTINCT Are Not the Same
SQL> select /* SEMI using IN */ department_id
2 from hr.employees
3 where department_id in (select department_id from hr.departments);
DEPARTMENT_ID
-------------
10
20
20
30
30
30
30
30
30
40
50
50
50
. . .
80
110
110
106 rows selected.
SQL>
SQL> select /* inner join with distinct */ distinct emp.department_id
2 from hr.departments dept, hr.employees emp
3 where dept.department_id = emp.department_id;
DEPARTMENT_ID
-------------
10
20
30
40
50
60
70
80
90
100
110
11 rows selected.
So it’s clear from this example that the two constructs are not equivalent. The IN/EXISTS form takes each record in the first set and, if there is at least one match in the second set, returns the record. It does not apply a DISTINCT operator at the end of the processing (in other words, it doesn’t sort and throw away duplicates). Therefore, it is possible to get repeating values, assuming that there are duplicates in the records returned by Query 1. The DISTINCT form, on the other hand, retrieves all the rows, sorts them, and then throws away any duplicate values. As you can see from the example, these are clearly not the same. And as you might expect from the description, the DISTINCT version can end up doing significantly more work because it has no chance to bail out of the subquery early. I talk more about this shortly.
There is another common mistake that is made with the EXISTS syntax that should probably be mentioned. If you use EXISTS, you need to make sure you include a subquery that is correlated to the outer query. If the subquery does not reference the outer query, it’s meaningless. Listing 11-8 shows an example from a web page that is currently number one on Google for the search term “Oracle EXISTS.”
Listing 11-8. Common Mistake with EXISTS: Noncorrelated Subquery
select
book_key
from
book
where
exists (select book_key from sales) ;
Because the subquery in this example is not related to the outer query, the end result is to return every record in the book table (as long as there is at least one record in the sales table). This is probably not what the author of this statement intended. Listing 11-9 shows a few examples demonstrating the difference between using correlated and noncorrelated subqueries—the first two showing EXISTS with a proper correlated subquery, and the last two showing EXISTS with noncorrelated subqueries.
Listing 11-9. Common Mistake with EXISTS: Correlated vs. Noncorrelated Subquery
SQL> select /* correlated */ department_id
2 from hr.departments dept
3 where exists (select department_id from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_ID
-------------
10
20
30
40
50
60
70
80
90
100
110
11 rows selected.
SQL>
SQL> select /* not correlated */ department_id
2 from hr.departments dept
3 where exists (select department_id from hr.employees emp);
DEPARTMENT_ID
-------------
10
20
30
40
50
60
70
80
90
100
110
120
130
140
150
160
170
180
190
200
210
220
230
240
250
260
270
27 rows selected.
SQL>
SQL> select /* not correlated no nulls */ department_id
2 from hr.departments dept
3 where exists (select department_id from hr.employees emp
4 where department_id is not null);
DEPARTMENT_ID
-------------
10
20
30
40
50
60
70
80
90
100
110
120
130
140
150
160
170
180
190
200
210
220
230
240
250
260
270
27 rows selected.
SQL>
SQL> select /* non-correlated totally unrelated */ department_id
2 from hr.departments dept
3 where exists (select null from dual);
DEPARTMENT_ID
-------------
10
20
30
40
50
60
70
80
90
100
110
120
130
140
150
160
170
180
190
200
210
220
230
240
250
260
270
27 rows selected.
SQL>
SQL> select /* non-correlated empty subquery */ department_id
2 from hr.departments dept
3 where exists (select 'anything' from dual where 1=2);
no rows selected
So the correlated queries get the records we expect (in other words, only the ones that have a match in the second query). Obviously, the noncorrelated subqueries do not work as expected. They return every record from the first table, which is actually what you’ve asked for if you write a query that way. In fact, as you can see in the next-to-last example (with the noncorrelated query against the dual table), no matter what you select in the subquery, all the records from the first table are returned. The last example shows what happens when no records are returned from the subquery. In this case, no records are returned at all. So, without a correlated subquery, you either get all the records in the outer query or none of the records in the outer query, without regard to what the inner query is actually doing.
Semijoin Plans
I mentioned in the introduction that semijoins are not really a join method on their own, but rather are an option of other join methods. The three most common join methods in Oracle are nested loops, hash joins, and merge joins. Each of these methods can have the semi option applied to it. Remember, also, that it is an optimization that allows processing to stop when the first match is found in the subquery. Let’s use a little pseudocode to exemplify the process more fully. The outer query is Q1 and the inner (subquery) is Q2. What you see in Listing 11-10 is the basic processing of a nested loop semijoin.
Listing 11-10. Pseudocode for Nested Loop Semijoin
open Q1
while Q1 still has records
fetch record from Q1
result = false
open Q2
while Q2 still has records
fetch record from Q2
if (Q1.record matches Q2.record) then= semijoin optimization
result = true
exit loop
end if
end loop
close Q2
if (result = true) return Q1 record
end loop
close Q1
The optimization provided by the semi option is the IF statement that lets the code exit the inner loop as soon as it finds a match. Obviously, with large datasets, this technique can result in significant time savings compared with a normal nested loops join that must loop through every record returned by the inner query for every row in the outer query. At this point, you may be thinking that this technique could save a lot of time with a nested loops join vs. the other two, and you’d be right because the other two have to get all the records from the inner query before they start checking for matches. So the nested loops joins in general have the most to gain from this technique. Keep in mind that the optimizer still picks which join method to use based on its costing algorithms, which include the various semi options.
Now let’s rerun the queries from Listings 11-1 and 11-2 and look at the plans the optimizer generates (shown in Listing 11-11). Note that some of the plan output has been removed for brevity.
Listing 11-11. Semijoin Execution Plans
SQL> -- semi_ex1.sql
SQL>
SQL> select /* in */ department_name
2 from hr.departments dept
3 where department_id in (select department_id from hr.employees emp);
DEPARTMENT_NAME
------------------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 954076352
------------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN SEMI | | 11 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 |
| 3 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 4 | SORT UNIQUE | | 107 |
| 5 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("DEPARTMENT_ID"="DEPARTMENT_ID")
filter("DEPARTMENT_ID"="DEPARTMENT_ID")
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
5 consistent gets
0 physical reads
0 redo size
758 bytes sent via SQL*Net to client
544 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
11 rows processed
SQL>
SQL> select /* exists */ department_name
2 from hr.departments dept
3 where exists (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
Elapsed: 00:00:00.05
Execution Plan
----------------------------------------------------------
Plan hash value: 954076352
------------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN SEMI | | 11 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 |
| 3 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 4 | SORT UNIQUE | | 107 |
| 5 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
filter("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
5 consistent gets
0 physical reads
0 redo size
758 bytes sent via SQL*Net to client
544 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
11 rows processed
The autotrace statistics are included so that you can see that these statements are indeed processed the same way. The plans are identical and the statistics are identical. I make this point to dispel the long-held belief that queries written with EXIST behave very differently than queries written with IN. This was an issue in the past (version 8i), but it has not been an issue for many years. The truth is that the optimizer can and does transform queries in both forms to the same statement.
Note that there is a way to get a better idea of the decision-making process the optimizer goes through when parsing a statement. You can have the optimizer log its actions in a trace file by issuing the following command:
alter session set events '10053 trace name context forever, level 1';
Setting this event causes a trace file to be created in the USER_DUMP_DEST directory when a hard parse is performed. I call it Wolfganging, because Wolfgang Breitling was the first guy really to analyze the content of these 10053 trace files and publish his findings. For further information, please refer to Wolfgang’s paper called “A Look Under the Hood of CBO.” (http://www.centrexcc.com/A%20Look%20under%20the%20Hood%20of%20CBO%20-%20the%2010053%20Event.pdf) At any rate, a close look at 10053 trace data for each statement confirms that both statements are transformed into the same statement before the optimizer determines a plan. Listing 11-12 and 11-13 show excerpts of 10053 trace files generated for both the IN and the EXISTS versions.
Listing 11-12. Excerpts from 10053 traces for the IN version
****************
QUERY BLOCK TEXT
****************
select /* using in */ department_name
from hr.departments dept
where department_id IN (select department_id from hr.employees emp)
*****************************
Cost-Based Subquery Unnesting
*****************************
SU: Unnesting query blocks in query block SEL$1 (#1) that are valid to unnest.
Subquery removal for query block SEL$2 (#2)
RSW: Not valid for subquery removal SEL$2 (#2)
Subquery unchanged.
Subquery Unnesting on query block SEL$1 (#1)SU: Performing unnesting that does not require costing.
SU: Considering subquery unnest on query block SEL$1 (#1).
SU: Checking validity of unnesting subquery SEL$2 (#2)
SU: Passed validity checks.
SU: Transforming ANY subquery to a join.
Final query after transformations:******* UNPARSED QUERY IS *******
SELECT "DEPT"."DEPARTMENT_NAME" "DEPARTMENT_NAME" FROM "HR"."EMPLOYEES" "EMP","HR"."DEPARTMENTS" "DEPT" WHERE "DEPT"."DEPARTMENT_ID"="EMP"."DEPARTMENT_ID"
Listing 11-13. Excerpts from 10053 traces for the EXISTS version
****************
QUERY BLOCK TEXT
****************
select /* using exists */ department_name
from hr.departments dept
where EXISTS (select null from hr.employees emp
where emp.department_id = dept.department_id)
*****************************
Cost-Based Subquery Unnesting
*****************************
SU: Unnesting query blocks in query block SEL$1 (#1) that are valid to unnest.
Subquery Unnesting on query block SEL$1 (#1)SU: Performing unnesting that does not require costing.
SU: Considering subquery unnest on query block SEL$1 (#1).
SU: Checking validity of unnesting subquery SEL$2 (#2)
SU: Passed validity checks.
SU: Transforming EXISTS subquery to a join.
Final query after transformations:******* UNPARSED QUERY IS *******
SELECT "DEPT"."DEPARTMENT_NAME" "DEPARTMENT_NAME" FROM "HR"."EMPLOYEES"
"EMP","HR"."DEPARTMENTS" "DEPT" WHERE "EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID"
As you can see in the trace file excerpts, subquery unnesting has occurred on both queries and they have both been transformed into the same statement (in other words, the Final Query after Transformations section is exactly the same for both versions). Oracle Database releases from 10gR2 onward behave the same way, by the way.
Controlling Semijoin Plans
Now let’s look at some of the methods to control the execution plan, should the optimizer need a little help. There are two mechanisms at your disposal. One mechanism is a set of hints that you can apply to individual queries. The other is an instance-level parameter that affects all queries.
Controlling Semijoin Plans Using Hints
There are several hints that may be applied to encourage or discourage semijoins. As of 11gR2, the following hints are available:
- SEMIJOIN: Perform a semijoin (the optimizer gets to pick which kind).
- NO_SEMIJOIN: Obviously, don’t perform a semijoin.
- NL_SJ: Perform a nested loops semijoin (deprecated as of 10g).
- HASH_SJ: Perform a hash semijoin (deprecated as of 10g).
- MERGE_SJ: Perform a merge semijoin (deprecated as of 10g).
The more specific hints (NL_SJ, HASH_SJ, MERGE_SJ) have been deprecated since 10g. Although they continue to work as in the past, even with 12c, be aware that the documentation says they may be going away at some point. All the semijoin-related hints need to be specified in the subquery, as opposed to in the outer query. Listing 11-14 shows an example using the NO_SEMIJOIN hint.
Listing 11-14. EXISTS with NO_SEMIJOIN Hint
SQL> set autotrace trace
SQL> -- semi_ex5a.sql - no_semijoin hint
SQL>
SQL> select /* exists no_semijoin */ department_name
2 from hr.departments dept
3 where exists (select /*+ no_semijoin */ null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Human Resources
Executive
Marketing
Shipping
Accounting
Administration
Purchasing
Public Relations
Sales
Finance
IT
11 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3628941896
--------------------------------------------------------------------
| Id | Operation | Name | Rows |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | VIEW | VM_NWVW_2 | 106 |
| 2 | HASH UNIQUE | | 106 |
| 3 | NESTED LOOPS | | |
| 4 | NESTED LOOPS | | 106 |
| 5 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
| 6 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 |
| 7 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 |
--------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
111 consistent gets
0 physical reads
0 redo size
758 bytes sent via SQL*Net to client
544 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
11 rows processed
In this example, I turned off the optimizer’s ability to use semijoins via the NO_SEMIJOIN hint. As expected, the query no longer does a semijoin, but instead joins the two row sources and removes duplicates as indicated by the HASH UNIQUE operation. This is actually different behavior than exhibited in Oracle 11g, in which a FILTER operation was used to combine the two row sources. Listing 11-15 shows the Oracle 11g plan output for the same statement.
Listing 11-15. EXISTS with NO_SEMIJOIN Hint (Oracle 11g)
Execution Plan
----------------------------------------------------------
Plan hash value: 440241596
----------------------------------------------------------------------------
| Id|Operation |Name |Rows|Bytes|Cost (%CPU)|Time |
----------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 1| 16| 17 (0)|00:00:01|
|* 1| FILTER | | | | | |
| 2| TABLE ACCESS FULL| DEPARTMENTS | 27| 432| 3 (0)|00:00:01|
|* 3| INDEX RANGE SCAN | EMP_DEPARTMENT_IX| 2| 6| 1 (0)|00:00:01|
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( EXISTS (SELECT 0 FROM "HR"."EMPLOYEES" "EMP" WHERE
"EMP"."DEPARTMENT_ID"=:B1))
3 - access("EMP"."DEPARTMENT_ID"=:B1)
Note that the Predicate Information section of 11g explain plan output shows the FILTER operation is used to enforce the EXISTS clause. As is often the case, a new version of Oracle changes the plan choices the optimizer makes, so never assume you know what the choice is. Always verify!
Controlling Semijoin Plans at the Instance Level
There is also a hidden parameter that exerts control over the optimizer’s semijoin choices; _always_semi_join was a normal parameter originally, but was changed to a hidden parameter in 9i. Listing 11-16 shows a list of the valid values for the parameter.
Listing 11-16. Valid Values for _always_semi_join
SYS@LAB112> select NAME_KSPVLD_VALUES name, VALUE_KSPVLD_VALUES value
2 from X$KSPVLD_VALUES
3 where NAME_KSPVLD_VALUES like nvl('&name',NAME_KSPVLD_VALUES);
Enter value for name: _always_semi_join
NAME VALUE
-------------------- -------------
_always_semi_join HASH
_always_semi_join MERGE
_always_semi_join NESTED_LOOPS
_always_semi_join CUBE
_always_semi_join CHOOSE
_always_semi_join OFF
The parameter has a somewhat misleading name because it does not force semijoins at all. The default value is CHOOSE, which allows the optimizer to evaluate all the semi-join methods and to choose the one it thinks is the most efficient. Setting the parameter to HASH, MERGE, or NESTED_LOOPS appears to reduce the optimizer’s choices to the specified join method. Setting the parameter to OFF disables semijoins. The parameter can be set at the session level. Listing 11-17 contains an example showing how the parameter can be used to change the optimizer’s choice from a MERGE semi to a NESTED_LOOPS semi.
Listing 11-17. Using _always_semi_join to Change Plan to NESTED_LOOPS Semijoin
SQL> @semi_ex1a
SQL> -- semi_ex1a.sql
SQL>
SQL> select /* using in */ department_name
2 from hr.departments dept
3 where department_id IN (select department_id from hr.employees emp);
DEPARTMENT_NAME
------------------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 954076352
------------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN SEMI | | 11 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 |
| 3 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 4 | SORT UNIQUE | | 107 |
| 5 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("DEPARTMENT_ID"="DEPARTMENT_ID")
filter("DEPARTMENT_ID"="DEPARTMENT_ID")
SQL> alter session set "_always_semi_join"=NESTED_LOOPS;
Session altered.
SQL> @semi_ex1a
SQL> -- semi_ex1a.sql
SQL>
SQL> select /* using in */ department_name
2 from hr.departments dept
3 where department_id IN (select department_id from hr.employees emp);
DEPARTMENT_NAME
------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1089943216
------------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | NESTED LOOPS | | |
| 2 | NESTED LOOPS | | 11 |
| 3 | SORT UNIQUE | | 107 |
| 4 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
| 5 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 |
| 6 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("DEPARTMENT_ID"="DEPARTMENT_ID")
Semijoin Restrictions
There is only one major documented restriction controlling when the optimizer can use a semijoin (in 11gR2). The optimizer does not choose a semijoin for any subqueries inside an OR branch. In previous versions of Oracle, the inclusion of the DISTINCT keyword would also disable semijoins, but that restriction no longer exists. Listing 11-18 contains an example showing a semijoin being disabled inside an OR branch.
Listing 11-18. Semijoins disabled inside an OR branch in 11gR2
SQL> select /* exists with or */ department_name
2 from hr.departments dept
3 where 1=2 or exists (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1089943216
------------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11 |
| 1 | NESTED LOOPS | | |
| 2 | NESTED LOOPS | | 11 |
| 3 | SORT UNIQUE | | 107 |
| 4 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
|* 5 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 |
| 6 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
In 12c, however, this restriction seems to have been lifted, as demonstrated in Listing 11-19. As you can see, a semijoin plan is chosen.
Listing 11-19. Semijoin Restriction Lifted in 12c
SQL> select /* exists with or */ department_name
2 from hr.departments dept
3 where 1=2 or exists (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Administration
Marketing
Purchasing
Human Resources
Shipping
IT
Public Relations
Sales
Executive
Finance
Accounting
11 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 954076352
------------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN SEMI | | 11 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 |
| 3 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 4 | SORT UNIQUE | | 107 |
| 5 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
filter("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
Semijoin Requirements
Semijoins are an optimization that can improve performance of some queries dramatically. They are not used that often, however. Here, briefly, are the requirements for Oracle’s cost-based optimizer to decide to use a semijoin:
- The statement must use either the keyword IN ( = ANY) or the keyword EXISTS.
- The statement must have a subquery in the IN or EXISTS clause.
- If the statement uses the EXISTS syntax, it must use a correlated subquery (to get the expected results).
- The IN or EXISTS clause may not be contained inside an OR branch.
Many systems have queries with massive numbers of literals (thousands sometimes) inside IN clauses. These are often generated statements that get populated by doing a query to find the list in the first place. These statements can occasionally benefit from being rewritten to let the optimizer take advantage of a semijoin—that is, taking the query that populated the literals in the IN clause and combining it with the original, instead of running them as two separate queries.
One of the reasons that developers avoid this approach is fear of the unknown. The IN and EXISTS syntax was at one time processed very differently, leading to situations in which performance could vary considerably depending on the method chosen. The good news is that the optimizer is smart enough now to transform either form into a semijoin, or not, depending on the optimizer costing algorithms. The question of whether to implement a correlated subquery with EXISTS or the more simple IN construct is now pretty much a moot point from a performance standpoint. And with that being the case, there seems to be little reason to use the more complicated EXISTS format. No piece of software is perfect, though; occasionally, the optimizer makes incorrect choices. Fortunately, when the optimizer does make a mistake, there are tools available to “encourage” it to do the right thing.
Antijoins
Antijoins are basically the same as semijoins in that they are an optimization option that can be applied to nested loop, hash, and merge joins. However, they are the opposite of semijoins in terms of the data they return. Those mathematician types familiar with relational algebra would say that antijoins can be defined as the complement of semijoins.
Figure 11-2 shows a Venn diagram that is often used to illustrate a MINUS operation (all the records from table A, MINUS the records from table B). The diagram in Figure 11-2 is a reasonable representation of an antijoin as well. The Oracle Database SQL Language Reference, 11g Release 2,() describes the antijoin this way: “An antijoin returns rows from the left side of the predicate for which there are no corresponding rows on the right side of the predicate. It returns rows that fail to match (NOT IN) the subquery on the right side” (http://docs.oracle.com/cd/E11882_01/server.112/e41084/queries006.htm#sthref2260).
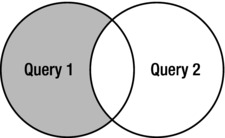
Figure 11-2. Illustration of an antijoin
The Oracle manual also provides this example of an antijoin (http://docs.oracle.com/cd/E11882_01/server.112/e41084/statements_10002.htm#i2182875):
SELECT * FROM employees
WHERE department_id NOT IN
(SELECT department_id FROM departments
WHERE location_id = 1700)
ORDER BY last_name;
As with semijoins, there is no specific SQL syntax that invokes an anti-join. Antijoins are one of several choices that the optimizer may use when the SQL statement contains the keywords NOT IN or NOT EXISTS. By the way, NOT IN is much, much more common than NOT EXISTS, probably because it is easier to understand.
So let’s take a look at our standard queries, now altered to anti form (in other words, using NOT IN and NOT EXISTS instead of IN and EXISTS) in Listing 11-20.
Listing 11-20. Standard NOT IN and NOT EXISTS Examples
SQL> -- anti_ex1.sql
SQL>
SQL> select /* NOT IN */ department_name
2 from hr.departments dept
3 where department_id NOT IN
4 (select department_id from hr.employees emp);
no rows selected
SQL>
SQL> select /* NOT EXISTS */ department_name
2 from hr.departments dept
3 where NOT EXISTS (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
Clearly NOT IN and NOT EXISTS do not return the same data in this example, and are therefore not functionally equivalent. The reason for this behavior has to do with how the queries deal with null values being returned by the subquery. If a null value is returned to a NOT IN operator, then no records are returned by the overall query, which seems counterintuitive. But, if you think about it for a minute, it should make a little more sense. In the first place, the NOT IN operator is just another way of saying !=ANY. So you can think of it as a loop comparing values. If it finds a match, the record is discarded. If it doesn’t, the record gets returned to the user. But what if it doesn’t know whether the records match? Remember that a null is not equal to anything, not even another null. In this case, Oracle has chosen to return a value of FALSE, even though the theoretical answer is unknown. C. J. Date 1 would probably argue that this is a shortcoming of Oracle’s implementation of relational theory, because it should provide for all three potential answers. At any rate, this is the way it works in Oracle.
Assuming that your requirements are to return records even in the case of nulls being returned by the subquery, you have the following options:
- Apply an NVL function to the column or columns returned by the subquery.
- Add an IS NOT NULL predicate to the subquery.
- Implement a NOT NULL constraint or constraints
- Don’t use NOT IN; use the NOT EXISTS form, which doesn’t care about nulls.
In many cases a NOT NULL constraint is the best option, but there are situations when there are valid arguments against them. Listing 11-21 shows two examples of dealing with the null issue.
Listing 11-21. Avoiding Nulls with NOT IN
SQL> select /* IN with NVL */ department_name
2 from hr.departments dept
3 where department_id NOT IN
4 (select nvl(department_id,-10) from hr.employees emp);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL>
SQL> select /* IN with NOT NULL */ department_name
2 from hr.departments dept
3 where department_id NOT IN (select department_id
4 from hr.employees emp where department_id is not null);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
As you can see, although an unconstrained NOT IN statement is not the same as a NOT EXISTS, applying an NVL function or adding an IS NOT NULL clause to the subquery predicate solves the issue.
Although NOT IN and NOT EXISTS are the most commonly chosen syntax options for producing an antijoin, there are at least two other options that can return the same data. The MINUS operator can obviously be used for this purpose. A clever trick with an outer join can also be used. Listing 11-22 shows examples of both techniques.
Listing 11-22. Alternative Syntax to NOT IN and NOT EXISTS
SQL> select /* MINUS */ department_name
2 from hr.departments
3 where department_id in
4 (select department_id from hr.departments
5 minus
6 select department_id from hr.employees);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL> select /* LEFT OUTER */ department_name
2 from hr.departments dept left outer join
3 hr.employees emp on dept.department_id = emp.department_id
4 where emp.department_id is null;
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL> select /* LEFT OUTER OLD (+) */ department_name
2 from hr.departments dept, hr.employees emp
3 where dept.department_id = emp.department_id(+)
4 and emp.department_id is null;
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
So the MINUS is slightly convoluted but it returns the right data and is functionally equivalent to the NOT EXISTS form and the null constrained NOT IN form. The LEFT OUTER statement probably needs a little discussion. It makes use of the fact that an outer join creates a dummy record on the right side for each record on the left that doesn’t have an actual match. Because all the columns in the dummy record are null, we can get the records without matches by adding the EMP.DEPARTMENT_ID IS NULL clause to the outer join. This statement is also functionally equivalent to the NOT EXISTS statement and the null constrained NOT IN form. There is a myth that this form performs better than NOT EXISTS, and maybe this was true at some point, but it is not the case now. Therefore, there appears to be little reason to use it because it is considerably less clear in its intent.
Antijoin Plans
As with semijoins, antijoins are an optimization option that may be applied to nested loop joins, hash joins, or merge joins. Also remember that it is an optimization that allows processing to stop when the first match is found in the subquery. Listing 11-23 shows the pseudocode that should help to describe the process more fully. Note that the outer query is Q1 and the inner (subquery) is Q2.
Listing 11-23. Pseudocode for Nested Loop Antijoin
open Q1
while Q1 still has records
fetch record from Q1
result = true
open Q2
while Q2 still has records
fetch record from Q2
if (Q1.record matches Q2.record) then
result = false
exit loop
end if
end loop
close Q2
if (result = true) return Q1 record
end loop
close Q1
This example is basically a nested loop antijoin. The optimization provided by the anti option is the IF statement that lets the code bail out of the inner loop as soon as it finds a match. Obviously, with large datasets, this technique can result in significant time savings compared with a normal nested loops join that must loop through every record returned by the inner query.
Now let’s rerun our first two antijoin examples (the standard NOT IN and NOT EXISTS queries) in Listing 11-24 and look at the plans the optimizer generates.
Listing 11-24. Antijoin Execution Plans
SQL> select /* NOT IN */ department_name
2 from hr.departments dept
3 where department_id NOT IN (select department_id from hr.employees emp);
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 4208823763
---------------------------------------------------------------------
| Id | Operation | Name | Rows |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN ANTI NA | | 17 |
| 2 | SORT JOIN | | 27 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| DEPARTMENTS | 27 |
| 4 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 5 | SORT UNIQUE | | 107 |
| 6 | TABLE ACCESS FULL | EMPLOYEES | 107 |
---------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("DEPARTMENT_ID"="DEPARTMENT_ID")
filter("DEPARTMENT_ID"="DEPARTMENT_ID")
SQL>
SQL> select /* NOT EXISTS */ department_name
2 from hr.departments dept
3 where NOT EXISTS (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1314441467
------------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN ANTI | | 17 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 27 |
| 3 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 4 | SORT UNIQUE | | 107 |
| 5 | INDEX FULL SCAN | EMP_DEPARTMENT_IX | 107 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
filter("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
Notice that the NOT EXISTS statement generated a MERGE JOIN ANTI plan whereas the NOT IN statement generated a MERGE JOIN ANTI NA plan. The MERGE JOIN ANTI is the standard antijoin that has been available since version 7 or thereabouts. The ANTI NA that was applied to the MERGE JOIN, however, is a new optimization that was introduced in 11g. (NA stands for null aware.) This new optimization allows the optimizer to deal with NOT IN queries when the optimizer doesn’t know if nulls can be returned by the subquery. Prior to 11g, antijoins could not be performed on NOT IN queries unless the optimizer was sure the nulls would not be returned. Note that this optimization technique has nothing at all to do with the “unintuitive” behavior of NOT IN clauses with respect to nulls that was mentioned previously. The query still returns no records if a null is returned by the subquery, but it does it a lot faster with the ANTI NA option. Listing 11-25 provides another example that shows how the various ways of handling nulls in the subquery affect the optimizer’s choices. (Note that the fsp.sql script shows some execution statistics from v$sql along with the operation and options from v$sql_plan if a semi- or antijoin is used.)
Listing 11-25. Antijoin Execution Plans
SQL > set echo on
SQL > @flush_pool
SQL > alter system flush shared_pool;
System altered.
SQL > @anti_ex2
SQL > set echo on
SQL > -- anti_ex2.sql
SQL >
SQL > select /* IN */ department_name
2 from hr.departments dept
3 where department_id not in
4 (select department_id from hr.employees emp);
no rows selected
SQL >
SQL > select /* IN with NVL */ department_name
2 from hr.departments dept
3 where department_id not in
4 (select nvl(department_id,-10) from hr.employees emp);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL >
SQL > select /* IN with NOT NULL */ department_name
2 from hr.departments dept
3 where department_id not in (select department_id
4 from hr.employees emp where department_id is not null);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL>
SQL > select /* EXISTS */ department_name
2 from hr.departments dept
3 where not exists (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL >
SQL > set echo off
SQL > set echo on
SQL > @fsp
SQL > select distinct s.sql_id,
2 -- s.child_number,
3 s.plan_hash_value plan_hash,
4 sql_text,
5 -- decode(options,'SEMI',operation||' '||options,null) join
6 case when options like '%SEMI%' or options like '%ANTI%' then
7 operation||' '||options end join
8 from v$sql s, v$sql_plan p
9 where s.sql_id = p.sql_id
10 and s.child_number = p.child_number
11 and upper(sql_text) like upper(nvl('&sql_text','%department%'))
12 and sql_text not like '%from v$sql where sql_text like nvl(%'
13 and s.sql_id like nvl('&sql_id',s.sql_id)
14 order by 1, 2, 3
15 /
Enter value for sql_text:
Enter value for sql_id:
SQL_ID PLAN_HASH SQL_TEXT JOIN
------------- ---------- --------------------------------------------- ------------------
0pcrmdk1tw0tf 4201340344 select /* IN */ department_name from MERGE JOIN ANTI NA
hr.departments dept where department_id not
in (select department_id from hr.employees emp)
56d82nhza8ftu 3082375452 select /* IN with NOT NULL */ department_name MERGE JOIN ANTI
from hr.departments dept where department_id
not in (select department_id from hr.employees
emp where department_id is not null)
5c77dgzy60ubx 3082375452 select /* EXISTS */ department_name from MERGE JOIN ANTI
hr.departments dept where not exists
(select null from hr.employees emp where
emp.department_id = dept.department_id)
a71yzhpc0n2uj 3822487693 select /* IN with NVL */ department_name from MERGE JOIN ANTI
hr.departments dept where department_id
not in (select nvl(department_id,-10) from
hr.employees emp)
As you can see, the EXISTS, NOT IN with NOT NULL, and NOT IN with NVL all use the normal antijoin, whereas the NOT IN that ignores the handling of nulls must use the new null-aware antijoin (ANTI NA). Now let’s rerun our examples of LEFT OUTER and MINUS and see what plans they come up with. Listing 11-26 shows the results of the optimizer for several alternative syntax variations.
Listing 11-26. Alternate Antijoin Syntax Execution Plans
SQL> set echo on
SQL> @flush_pool
SQL> alter system flush shared_pool;
System altered.
SQL > @anti_ex3
SQL > set echo on
SQL > -- anti_ex3.sql
SQL >
SQL > select /* NOT EXISTS */ department_name
2 from hr.departments dept
3 where not exists (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL >
SQL > select /* NOT IN NOT NULL */ department_name
2 from hr.departments dept
3 where department_id not in (select department_id
4 from hr.employees emp where department_id is not null);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL >
SQL > select /* LEFT OUTER */ department_name
2 from hr.departments dept left outer join
3 hr.employees emp on dept.department_id = emp.department_id
4 where emp.department_id is null;
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL >
SQL > select /* LEFT OUTER OLD (+) */ department_name
2 from hr.departments dept, hr.employees emp
3 where dept.department_id = emp.department_id(+)
4 and emp.department_id is null;
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL >
SQL > select /* MINUS */ department_name
2 from hr.departments
3 where department_id in
4 (select department_id from hr.departments
5 minus
6 select department_id from hr.employees);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL >
SQL > set echo off
SQL > @fsp
Enter value for sql_text:
Enter value for sql_id:
SQL_ID PLAN_HASH SQL_TEXT JOIN
------------- ---------- -------------------------------------------------- ---------------
6tt0zwazv6my9 3082375452 select /* NOT EXISTS */ department_name MERGE JOIN ANTI
from hr.departments dept where not exists
(select null from hr.employees emp where
emp.department_id = dept.department_id)
as34zpj5n5dfd 3082375452 select /* LEFT OUTER */ department_name MERGE JOIN ANTI
from hr.departments dept left outer join
hr.employees emp on dept.department_id =
emp.department_id where emp.department_id is null
czsqu5txh5tyn 3082375452 select /* NOT IN NOT NULL */ department_name MERGE JOIN ANTI
from hr.departments dept where department_id
not in (select department_id from hr.employees
emp where department_id is not null)
dcx0kqhwbuv6r 3082375452 select /* LEFT OUTER OLD (+) */ department_name MERGE JOIN ANTI
from hr.departments dept, hr.employees emp where
dept.department_id = emp.department_id(+) and
emp.department_id is null
gvdsm57xf24jv 2972564128 select /* MINUS */ department_name from
hr.departments where department_id in
(select department_id from hr.departments
minus select department_id from hr.employees)
Although all these statements return the same data, the MINUS does not use the antijoin optimization. If you look closely, you can see that all the other statements have the same plan hash value—meaning, they have exactly the same plan.
Controlling Antijoin Plans
Not surprisingly, the mechanisms for controlling antijoin plans are similar to those available for controlling semijoins. As before, you have both hints and parameters to work with.
Controlling Antijoin Plans Using Hints
There are several hints:
- ANTIJOIN: Perform an antijoin (the optimizer gets to pick which kind).
- USE_ANTI: Perform an antijoin (this is an older version of the ANTIJOIN hint).
- NL_AJ: Perform a nested loops antijoin (deprecated as of 10g).
- HASH_AJ: Perform a hash antijoin (deprecated as of 10g).
- MERGE_AJ: Perform a merge antijoin (deprecated as of 10g).
As with the hints controlling semijoins, several of the antijoin hints (NL_AJ, HASH_AJ, MERGE_AJ) have been documented as being deprecated. Nevertheless, they continue to work in 12c. However, it should be noted that these specific hints do not work in situations when the optimizer must use the new null-aware version of antijoin (more on that in a moment). All the antijoin hints should be specified in the subquery, as opposed to in the outer query. Also note that there is not a NO_ANTIJOIN hint, which is a bit unusual. Listing 11-27 shows an example of using the NL_AJ hint.
Listing 11-27. Controlling Antijoin Execution Plans with Hints
SQL> set autotrace traceonly exp
SQL> @anti_ex4
SQL> -- anti_ex4.sql
SQL>
SQL> select /* IN */ department_name
2 from hr.departments dept
3 where department_id not in (select /*+ nl_aj */ department_id
4 from hr.employees emp);
Execution Plan
----------------------------------------------------------
Plan hash value: 4208823763
---------------------------------------------------------------------
| Id | Operation | Name | Rows |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN ANTI NA | | 17 |
| 2 | SORT JOIN | | 27 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| DEPARTMENTS | 27 |
| 4 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 5 | SORT UNIQUE | | 107 |
| 6 | TABLE ACCESS FULL | EMPLOYEES | 107 |
---------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("DEPARTMENT_ID"="DEPARTMENT_ID")
filter("DEPARTMENT_ID"="DEPARTMENT_ID")
SQL>
SQL> select /* EXISTS */ department_name
2 from hr.departments dept
3 where not exists (select /*+ nl_aj */ null from hr.employees emp
4 where emp.department_id = dept.department_id);
Execution Plan
----------------------------------------------------------
Plan hash value: 3082375452
--------------------------------------------------------
| Id | Operation | Name | Rows |
--------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | NESTED LOOPS ANTI | | 17 |
| 2 | TABLE ACCESS FULL| DEPARTMENTS | 27 |
| 3 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 41 |
--------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID")
Controlling Antijoin Plans at the Instance Level
There are also a number of parameters (all hidden) that affect the optimizer’s behavior with respect to antijoins:
- _always_anti_join
- _gs_anti_semi_join_allowed
- _optimizer_null_aware_antijoin
- _optimizer_outer_to_anti_enabled
The main parameter to be concerned about is _always_anti_join, which is equivalent to _always_semi_join in its behavior (it has the same valid values, and the options do the same things). Note that it’s been documented as being obsolete for some time. Nevertheless, as with _always_semi_join, it still appears to work in 12c. Listing 11-28 shows an example of using a hint and turning off antijoins altogether with the _optimizer_null_aware_antijoin parameter.
Listing 11-28. Controlling Antijoin Execution Plans with Parameters
SQL> -- anti_ex5.sql
SQL>
SQL> select /* EXISTS */ department_name
2 from hr.departments dept
3 where not exists (select null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
Treasury
Corporate Tax
Control And Credit
Shareholder Services
Benefits
Manufacturing
Construction
Contracting
Operations
IT Support
NOC
IT Helpdesk
Government Sales
Retail Sales
Recruiting
Payroll
16 rows selected.
SQL>
SQL> select /* EXISTS with hint */ department_name
2 from hr.departments dept
3 where not exists (select /*+ hash_aj */ null from hr.employees emp
4 where emp.department_id = dept.department_id);
DEPARTMENT_NAME
------------------------------
NOC
Manufacturing
Government Sales
IT Support
Benefits
Shareholder Services
Retail Sales
Control And Credit
Recruiting
Operations
Treasury
Payroll
Corporate Tax
Construction
Contracting
IT Helpdesk
16 rows selected.
SQL>
SQL> select /* IN */ department_name
2 from hr.departments dept
3 where department_id not in
4 (select department_id from hr.employees emp);
no rows selected
SQL>
SQL> alter session set "_optimizer_null_aware_antijoin"=false;
Session altered.
SQL>
SQL> select /* IN with AAJ=OFF*/ department_name
2 from hr.departments dept
3 where department_id not in
4 (select department_id from hr.employees emp);
no rows selected
SQL>
SQL> alter session set "_optimizer_null_aware_antijoin"=true;
Session altered.
SQL>
SQL> set echo off
SQL> @fsp
Enter value for sql_text:
Enter value for sql_id:
SQL_ID PLAN_HASH SQL_TEXT JOIN
------------- ---------- ------------------------------------------------- --------------------
0kvb76bzacc7b 3587451639 select /* EXISTS with hint */ department_name HASH JOIN ANTI
from hr.departments dept where not exists
(select /*+ hash_aj */ null from hr.employees
emp where emp.department_id = dept.department_id)
0pcrmdk1tw0tf 4201340344 select /* IN */ department_name from MERGE JOIN ANTI NA
hr.departments dept where department_id not in
(select department_id from hr.employees emp)
5c77dgzy60ubx 3082375452 select /* EXISTS */ department_name from NESTED LOOPS ANTI
hr.departments dept where not exists
(select null from hr.employees emp where
emp.department_id = dept.department_id)
67u11c3rv1aag 3416340233 select /* IN with AAJ=OFF*/ department_name from
hr.departments dept where department_id not in
(select department_id from hr.employees emp)
Antijoin Restrictions
As with semijoins, antijoin transformations cannot be performed if the subquery is on an OR branch of a WHERE clause. I trust you will take my word for this one, because the behavior has already been demonstrated with semijoins in the previous sections.
As of 12c, there are no major restrictions on the use of antijoins. The major restriction in 10g was that any subquery that could return a null was not a candidate for antijoin optimization. The new ANTI NA (and ANTI SNA) provide the optimizer with the capability to apply the antijoin optimization even in those cases when a null may be returned by a subquery. Note that this does not change the somewhat confusing behavior causing no records to be returned from a subquery contained in a NOT IN clause if a null value is returned by the subquery.
Because 10g is still in wide use, a brief discussion of the restriction that has been removed in 11g and above by the null-aware antijoin is warranted. When a NOT IN clause is specified in 10g, the optimizer checks to see if the column or columns being returned are guaranteed not to contain nulls. This is done by checking for NOT NULL constraints, IS NOT NULL predicates, or a function that translates null into a value (typically NVL). If all three of these checks fail, the 10g optimizer does not choose an antijoin. Furthermore, it transforms the statement by applying an internal function (LNNVL) that has the possible side effect of disabling potential index access paths. Listing 11-29 shows an example from a 10.2.0.4 database.
Listing 11-29. 10g NOT NULL Antijoin Behavior
> !sql
sqlplus "/ as sysdba"
SQL*Plus: Release 10.2.0.4.0 - Production on Tue Jun 29 14:50:25 2010
Copyright (c) 1982, 2007, Oracle. All Rights Reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> @anti_ex6
SQL> -- anti_ex6.sql
SQL>
SQL> set autotrace trace exp
SQL>
SQL> select /* NOT IN */ department_name
2 from hr.departments dept
3 where department_id not in (select department_id from hr.employees emp);
Execution Plan
----------------------------------------------------------
Plan hash value: 3416340233
--------------------------------------------------------------------
|Id|Operation |Name |Rows|Bytes|Cost (%CPU)|Time |
--------------------------------------------------------------------
| 0|SELECT STATEMENT | | 26| 416| 29 (0)|00:00:01|
|*1| FILTER | | | | | |
| 2| TABLE ACCESS FULL|DEPARTMENTS| 27| 432| 2 (0)|00:00:01|
|*3| TABLE ACCESS FULL|EMPLOYEES | 2| 6| 2 (0)|00:00:01|
--------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( NOT EXISTS (SELECT /*+ */ 0 FROM "HR"."EMPLOYEES" "EMP"
WHERE LNNVL("DEPARTMENT_ID"<>:B1)))
3 - filter(LNNVL("DEPARTMENT_ID"<>:B1))
SQL> select /* NOT NULL */ department_name
2 from hr.departments dept
3 where department_id not in (select department_id
4 from hr.employees emp where department_id is not null);
Execution Plan
----------------------------------------------------------
Plan hash value: 3082375452
---------------------------------------------------------------------------
|Id|Operation |Name |Rows|Bytes|Cost (%CPU)|Time |
---------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 323| 2 (0)|00:00:01 |
| 1| NESTED LOOPS ANTI | | 17| 323| 2 (0)|00:00:01 |
| 2| TABLE ACCESS FULL|DEPARTMENTS | 27| 432| 2 (0)|00:00:01 |
|*3| INDEX RANGE SCAN |EMP_DEPARTMENT_IX| 41| 123| 0 (0)|00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DEPARTMENT_ID"="DEPARTMENT_ID")
filter("DEPARTMENT_ID" IS NOT NULL)
SQL>
SQL> select /* NVL */ department_name
2 from hr.departments dept
3 where department_id not in (select nvl(department_id,'-10')
4 from hr.employees emp);
Execution Plan
----------------------------------------------------------
Plan hash value: 2918349777
--------------------------------------------------------------------
|Id|Operation |Name |Rows|Bytes|Cost (%CPU)|Time |
--------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 323| 5 (20)|00:00:01|
|*1| HASH JOIN ANTI | | 17| 323| 5 (20)|00:00:01|
| 2| TABLE ACCESS FULL|DEPARTMENTS| 27| 432| 2 (0)|00:00:01|
| 3| TABLE ACCESS FULL|EMPLOYEES | 107| 321| 2 (0)|00:00:01|
--------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("DEPARTMENT_ID"=NVL("DEPARTMENT_ID",(-10))
The first statement in this example is the same old NOT IN query that we’ve run several times already in 12c. Note that in 10g, instead of doing an ANTI NA, it doesn’t apply the anti optimization at all. This is because of the restriction guaranteeing that nulls are not returned from the subquery in 10g. The second statement (NOT NULL) applies the NOT NULL predicate to the WHERE clause in the subquery, which enables the optimizer to pick a standard antijoin. The third statement uses the NVL function to ensure that no nulls are returned by the subquery. Notice that it also is able to apply the antijoin. Last, notice the Predicate Information section below the plan for the first statement (NOT IN). Note that the optimizer has transformed the statement by adding the LNNVL function, which can have the unpleasant side effect of disabling index access paths. The other plans do not have this transformation applied. Listing 11-30 shows the same NOT IN statement run in 12c.
Listing 11-30. 12c NOT NULL Antijoin Behavior
SQL> -- anti_ex6.sql
SQL>
SQL> set autotrace trace exp
SQL>
SQL> select /* NOT IN */ department_name
2 from hr.departments dept
3 where department_id not in (select department_id from hr.employees emp);
Execution Plan
----------------------------------------------------------
Plan hash value: 4208823763
---------------------------------------------------------------------
| Id | Operation | Name | Rows |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | MERGE JOIN ANTI NA | | 17 |
| 2 | SORT JOIN | | 27 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| DEPARTMENTS | 27 |
| 4 | INDEX FULL SCAN | DEPT_ID_PK | 27 |
| 5 | SORT UNIQUE | | 107 |
| 6 | TABLE ACCESS FULL | EMPLOYEES | 107 |
---------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("DEPARTMENT_ID"="DEPARTMENT_ID")
filter("DEPARTMENT_ID"="DEPARTMENT_ID")
Notice that in 12c the optimizer generates the new null-aware ANTI join (ANTI NA). Also note that the internally applied LNNVL function that is used in 10g is no longer necessary.
Requirements is such a strong word. Oracle’s optimizer is a very complex piece of software. Producing an exhaustive list of every possible way to get a specified result is a difficult task at best. With respect to antijoins, Oracle has recently implemented some clever ways of making use of this join option that you would not normally expect. So please take these “requirements” as a list of the most probable ways to cause Oracle to produce an anti-join, as opposed to an exhaustive list:
- The statement should use either the NOT IN (!= ALL) or NOT EXISTS phrases.
- The statement should have a subquery in the NOT IN or NOT EXISTS clause.
- The NOT IN or NOT EXISTS clause should not be contained inside an OR branch.
- Subqueries in NOT EXISTS clauses should be correlated to the outer query.
![]() Note 10g requires NOT IN subqueries to be coded to not return nulls (11g and higher doesn’t).
Note 10g requires NOT IN subqueries to be coded to not return nulls (11g and higher doesn’t).
Antijoins are a powerful optimization option that can be applied by the optimizer. They can provide impressive performance improvements, particularly when large data volumes are involved. Although the NOT IN syntax is more intuitive, it also has some counterintuitive behavior when it comes to dealing with nulls. The NOT EXISTS syntax is better suited to handling subqueries that may return nulls, but is, in general, a little harder to read and—probably for that reason—is not used as often. The outer join trick is even less intuitive than the NOT EXISTS syntax and, in general, provides no advantage over it. The MINUS operator does not appear to offer any advantages over the other forms and does not currently use the antijoin optimization. It is apparent that Oracle’s intent is to allow the optimizer to use the antijoin option whenever possible because of the dramatic performance enhancement potential that it provides.
Summary
Antijoins and sSemijoins are options that the optimizer can apply to many of the common join methods. The basic idea of these optimization options is to cut short the processing of the normal hash, merge, or nested loop joins. In some cases, antijoins and semijoins can provide dramatic performance improvements. There are multiple ways to construct SQL statements that result in the optimizer using these options. The most common are the IN and EXISTS keywords. When these optimizations were first released, the processing of the statements varied significantly, depending on whether you used IN or EXISTS. Over the years, the optimizer has been enhanced to allow many statement transformations; the result is that, in 11g and higher, there is little difference between using one form or the other. In many cases, the statements get transformed into the same form anyway. In this chapter you’ve seen how this optimization technique works, when it can be used, and how to verify whether it is being used. You’ve also seen some mechanisms for controlling the optimizer’s use of this feature.
1 C.J. Date is most well known for his work, while working for IBM in the late 1960's, with Ted Codd on the development of the relational model for database management.