
![]()
Big Data Storage Patterns
There are various storage infrastructure options available in the market, and big data appliances have added a new dimension to infrastructure options. Enterprises can leverage their existing infrastructure and storage licenses in addition to these new solutions for big data. In this chapter, we will cover the various storage mechanisms available, as well as patterns that amalgamate existing application storage frameworks with new big data implementations.
Understanding Big Data Storage
Since data is now more than just plain text, it can exist in various persistence-storage mechanisms, with Hadoop distributed file system (HDFS) being one of them. The way data is ingested or the sources from which data is ingested affects the way data is stored. On the other hand, how the data is pushed further into the downstream systems or accessed by the data access layer decides how the data is to be stored.
The need to store huge volumes of data has forced databases to follow new rules of data relationships and integrity that are different from those of relational database management systems (RDBMS).
RDBMS follow the ACID rules of atomicity, consistency, isolation and durability. These rules make the database reliable to any user of the database. However, searching huge volumes of big data and retrieving data from them would take large amounts of time if all the ACID rules were enforced.
A typical scenario is when we search for a certain topic using Google. The search returns innumerable pages of data; however, only one page is visible or basically available (BA). The rest of the data is in a soft state (S) and is still being assembled by Google, though the user is not aware of it. By the time the user looks at the data on the first page, the rest of the data becomes eventually consistent (E). This phenomenon—basically available soft state and eventually consistent—is the rule followed by the big data databases, which are generally NoSQL databases following BASE properties.
Database theory suggests that any distributed NoSQL big database can satisfy only two properties predominantly and will have to relax standards on the third. The three properties are consistency, availability, and partition tolerance (CAP). This is the CAP theorem.
The aforementioned paradigms of ACID, BASE, and CAP give rise to new big data storage patterns (Figure 4-1) like the following:
- Façade pattern: HDFS serves as the intermittent façade for the traditional DW systems.
- Lean pattern: HBase is indexed using only one column-family and only one column and unique row-key.
- NoSQL pattern: Traditional RDBMS systems are replaced by NoSQL alternatives to facilitate faster access and querying of big data.
- Polyglot pattern: Multiple types of storage mechanisms—like RDBMS, file storage, CMS, OODBMS, NoSQL and HDFS—co-exist in an enterprise to solve the big data problem.
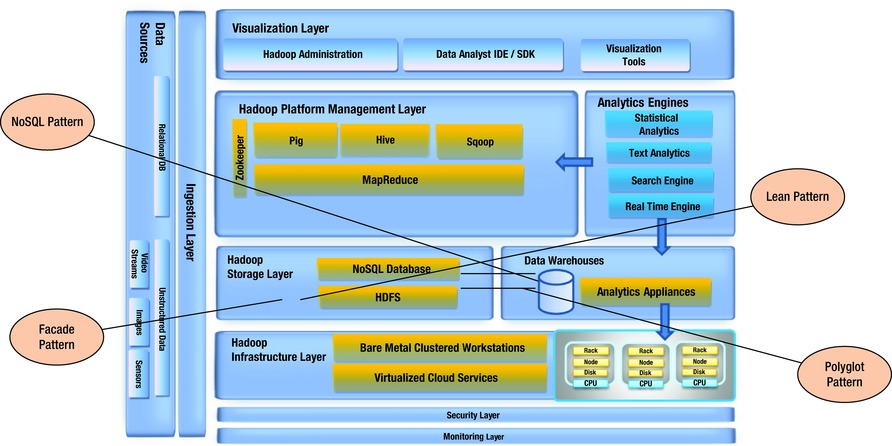
Figure 4-1. Big data storage patterns
Façade Pattern
Solution
Hadoop is not necessarily a replacement for a data warehouse (DW). It can also act as façade for a DW (Figure 4-2 and Figure 4-3). Data from different sources can be aggregated into an HDFS before being transformed and loaded to the traditional DW and business intelligence (BI) tools.
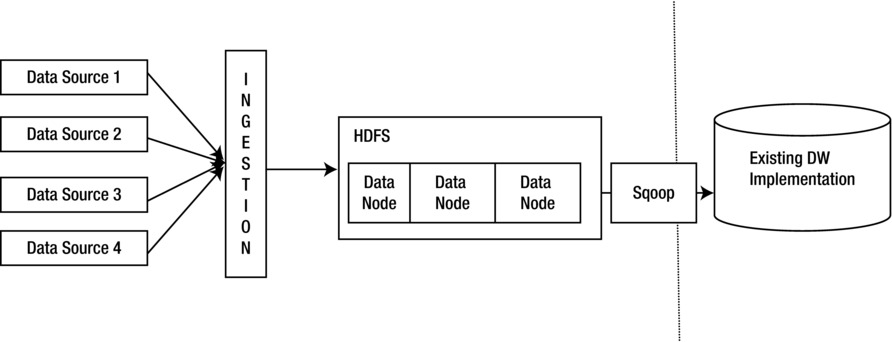
Figure 4-2. The Hadoop Façade pattern
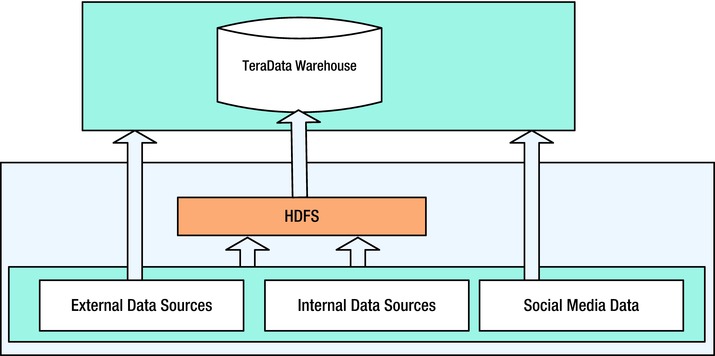
Figure 4-3. Hadoop as a façade for TeraData
This helps in retaining the investment in the existing DW framework, as well as the data usage in the downstream systems. This also helps re-use the existng infrastructure and add an abstraction of the DW. Hence, if new data sources are added to the ingestion system, it is still abstracted from the DW framework. This pattern solves the variety challenge among the three Vs (velocity, variety, and volume) of big data as shown in the example in Figures 4-3 to 4-6.
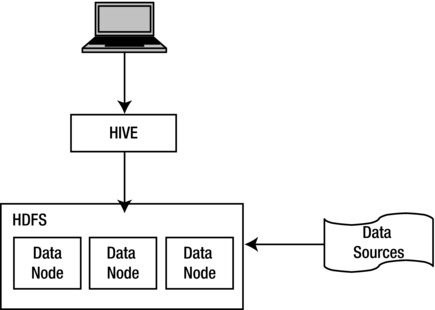
Figure 4-4. Typical big data storage and access
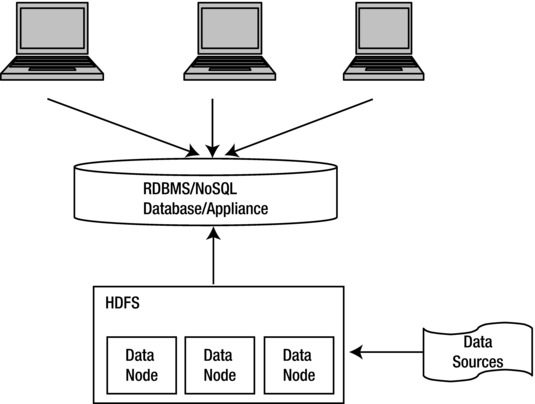
Figure 4-5. Abstraction of RDBMS above HDFS
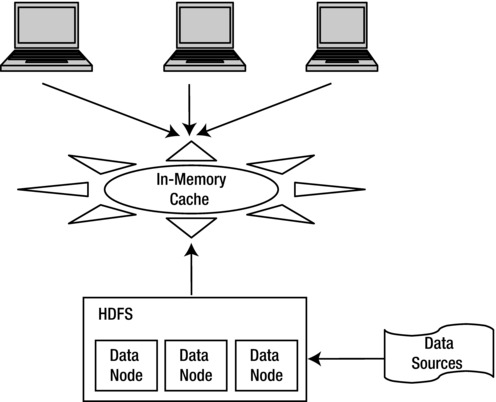
Figure 4-6. Abstraction of in-memory cache above HDFS
Data can be stored as “structured” data after being ingested into HDFS in the form of storage in an RDBMS (Figure 4-5) or in the form of applicances like IBM Netezza/EMC Greenplum, NoSQL Databases like Cassandra/HO Vertica/Oracle Exadata, or simply in an in-memory cache (Figure 4-6).
This ensures that only necessary data resides in the “structured” storage, thereby reducing the data size as well as latency (while accessing the data).
The types of big data appliances claiming to offer high performance and low latency have mushroomed in the market. We need to be aware how they really affect the existing infrastructure and the benefits that these appliances bring to the table.
Problem
What are the benefits of using an integrated big data appliance?
Solution
HP Vertica, IBM Netezza, Oracle Exadata, and EMC Greenplum are packaged, commercial off-the-shelf COTS appliances available in the market. The advantage of such appliances is that they bring together the infrastructure, the Hadoop firmware, and management tools (for managing the Hadoop nodes). These appliances also ensure that instead of aligning with multiple vendors for software, storage and tools, only a tie-up with a single vendor is needed. This reduces considerable legwork for the client, ensuring the client deals with a single vendor for all issues.
HP Vertica (Figure 4-7) is an example of an all-in-one appliance.
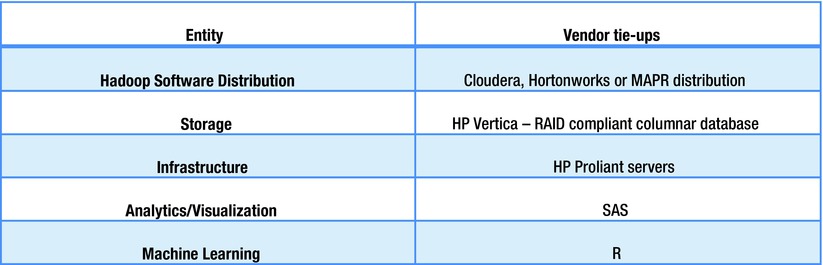
Figure 4-7. Vendors with multiple tie-ups
As you can see from the preceding example, the HP big data implementation brings with it back-to-back collaboration with other vendors. Other examples are shown in Figure 4-8.

Figure 4-8. List of big data vendors with multiple tie-ups
For one financial firm, a shift from a relational database to an appliance saw a 270 times faster query run. So the difference can be quite substantial.
The points to consider before implementing an appliance are these:
- Vendor lock-in
- Time to bring appliance implementation into production (porting data from legacy applications to appliance)
- Skills and expertise availability
- License cost
- Annual maintenance cost
- Total cost of ownership (TCO)
- Return on investment (ROI)
- Business case or the need for performance improvements over the existing Hadoop implementation
- Security (encryption and authentication)
- Integration with existing tools and hardware
SAN, NAS, and SSD are some well-known storage formats. Big data has been tested on SAN disks, but there is not much performance data available regarding SSD.
Solution
RAID configuration is not necessary if the default storage is HDFS, because it already has a replication mechanism. Some appliances, including some of those discussed earlier, abstract the data that needs to be analyzed into a “structured” format that might have to be RAID-configured.
Problem
Is there a time-to-live for data to reside in HDFS?
Solution
Yes, as in any storage solution, data needs to be persisted only as long as the business demands it. Beyond this period, the data can be archived to products like EMC Isilon (http://www.emc.com/archiving/archive-big-data.htm ). A data purge also has to be business driven.
Data Partitioning/Indexing and the Lean Pattern
Problem
HDFS is a distributed file system and inherently splits a file into chunks and replicates them. Does it still need further partitioning and indexing?
Solution
As a best practice, data partitioning is recommended for HDFS-based NoSQL databases. Because HDFS is a folder structure, data can be distributed/partitioned in multiple folders that are created on the basis of time-stamp, geography, or any other parameters that drive the business. This ensures that data access is capable of very high performance.
Solution
Data indexing as known in the RDBMS world is not applicable to HDFS but is applicable to NoSQL databases, like HBase, that are HDFS aware and compliant.
HBase works on the concept of column-family apart from columns, which can be leveraged to aggregate similar data together (Figures 4-9 and 4-10).

Figure 4-9. HBase implementation with only one column-family and multiple columns

Figure 4-10. HBase implementation with multiple column-families and multiple columns
As you can see in the preceding illustrations, there are three ways a dataset can be uniquely identified. A unique combination of column-family name and a column can be used to uniquely identify a dataset. This can be achieved by having a combination of one-column or multiple-column families. A third way is to create a unique row-key, while having only a one column-family and one column. This implementation is called a Lean pattern implementation (Figure 4-11). The row-key name should end with a suffix of a time-stamp.

Figure 4-11. Lean pattern—HBase implementation with only one column-family and only one column and unique row-key
This not only helps create a unique row-key but also helps in filtering or sorting data because the suffix is numeric in the form of a time-stamp.
Since maintenance can be difficult if the Lean pattern is implemented, it should be chosen over the other two only if the right skills and expertise exist in the big data team.
Problem
Are there other publicly available big data storage mechanisms?
Solution
Amazon Web Services (AWS) has its own storage mechanism in the form of S3. Data can be stored in S3 in the form of buckets. Whether all the data resides in a single bucket or in multiple buckets, again, should be driven by business needs and/or the skills available in the organization.
Other vendors, like IBM (GPFS) and EMC (Figure 4-12), have also been marketing their own file systems, but not many industry credentials are present to make them serious contenders to HDFS.

Figure 4-12. HDFS alternatives
MapR claims to have a file system two times faster than HDFS. (See http://www.slideshare.net/mcsrivas/design-scale-and-performance-of-maprs-distribution-for-hadoop .) However, clients would be reluctant to have a vendor lock-in at the file level. Migrating from a MapR Hadoop distribution to a Cloudera or a Hortonworks distribution will surely result in different performance statistics.
Problem
What role do NoSQL databases play in the Hadoop implementation?
Solution
NoSQL databases can store data on local NFS disks as well as HDFS. NoSQL databases are HDFS-aware; hence, data can be distributed across Hadoop data nodes and, at the same time, data can be easily accessed because it is stored in a nonrelational, columnar fashion. As we have discussed there are four types of NoSQL databases. Figure 4-13 lists their major big data use cases. Vendor implementations of NoSQL subsequently became open source implementations as seen in Figure 4-14.
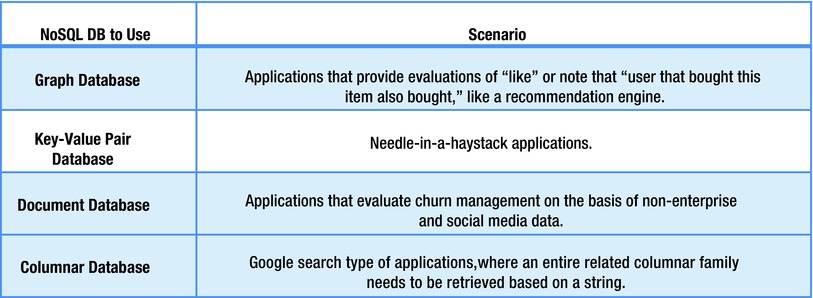
Figure 4-13. NoSQL use cases

Figure 4-14. NoSQL vendors
- “N+1 Selects” problem for a large dataset
- Writing a huge amount of data
- Semi structured data
You should investigate NoSQL technologies to determine which offerings best fit your needs.
As mentioned, NoSQL databases allow faster searching on huge unstructured data.
Key-value pair databases store data as simple key-value pairs. The keys are unique and do not have any foreign keys or constraints. They are suitable for parallel lookups because the data sources have no relationships among each other. As you can imagine, such a structure is good for high read access. Due to a lack of referential integrity, the data integrity has to be managed by the front-end applications.
Column-oriented databases have a huge number of columns for each tuple. Each column also has a column key. Related columns have a column-family qualifier so that they can be retrieved together during a search. Because each column also has a column key, these databases are suitable for fast writes.
Document databases store text, media, and JSON or XML data. The value in a row is a blob of the aforementioned data and can be retrieved using a key. If you want to search through multiple documents for a specific string, a document database should be used.
Graph databases store data entities and connections between them as nodes and edges. They are similar to a network database and can be used to calculate shortest paths, social network analysis, and other parameters.
Figure 4-15 depicts a NoSQL application pattern, where HBASE (which is a columnar data store) is used to store log-file data and then accessed by the front-end application to search for patterns or specific occurrences of certain strings.
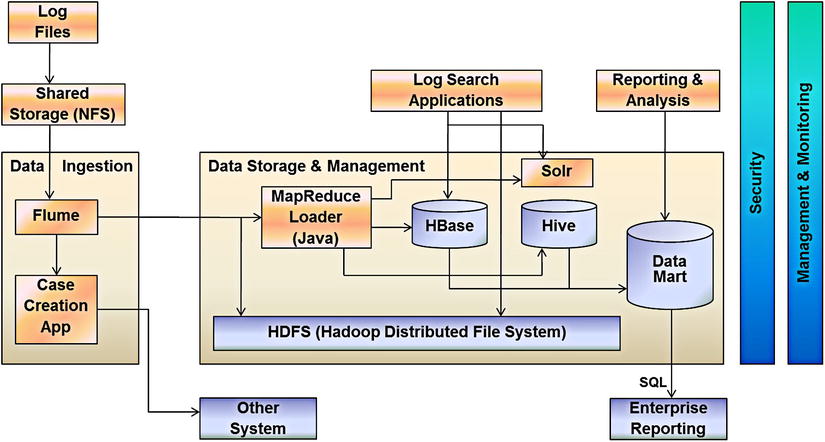
Figure 4-15. NoSQL pattern—HBase
Problem
Can multiple storage mechanisms like RDBMS, Hadoop, and big data appliances co-exist in a solution—a scenario known as “Polyglot Persistence”?
Solution
Certainly. Because the type of data to be stored by an application has changed from being text to other unstructured formats, data can be persisted in multiple sources, like RDBMS, Content Management Systems (CMS), and Hadoop. As seen in Figure 4-16, for a single application and for various use cases, the storage mechanism changes from traditional RDBMS to a key-value store to a NoSQL database to a CMS system. This contrasts with the traditional view of storing all application data in one single storage mechanism.
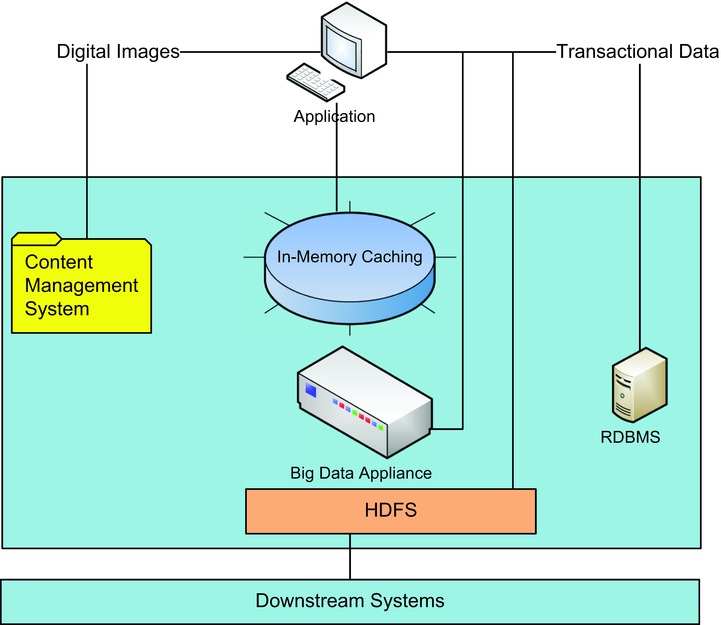
Figure 4-16. Polyglot pattern
Big Data Storage Infrastructure
Solution
As per the IDC (http://www.idc.com/getdoc.jsp?containerId=IDC_P25990 ), the following are the major vendors:
- Storage vendors (incumbents): Dell, EMC, HP, IBM, NetApp, and Oracle
- Storage vendors (upcoming): Amplidata, Cleversafe, Compuverde, Coraid, DDN, Nexsan, Nimble, Nimbus, and Violin Memory
Because Hadoop is about distributed storage and analysis, infrastructure vendors play a major role. Vendors like Oracle, EMC and IBM have started packaging infrstructure apart from their big data appliance as part of their Hadoop solutions. The only advantage of such solutions is that the client has to be concerned about only a single vendor. But, again, there is a concern of a being locked to a single vendor and that migrating or decoupling individual entities of a Hadoop ecosystem might become too costly for the client. Due diligence and a total cost of ownership (TCO) assessment needs to be thoroughly done before opting for such a packaged solution.
Typical Data-Node Configuration
Multiple vendors have varying configurations for a data node.
Problem
What is a typical data-node configuration?
Solution
Per information from Intel (www.intel.com/bigdata ), Figure 4-17 shows the configuration of the data node.

Figure 4-17. Intel—Data-node configuration
Figure 4-18 shows the same information for the IBM Big Data Networked Storage Solution for Hadoop (http://www.redbooks.ibm.com/redpapers/pdfs/redp5010.pdf ).
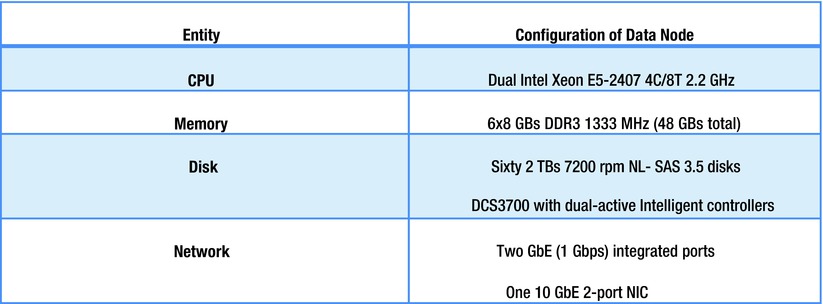
Figure 4-18. IBM—Data-node configuration
Summary
Since multi-structured formats are here to stay, various mechanisms of storage have evolved and are changing the way data storage architecture is designed. As visualization tools take the center stage in the big data world, they will drive how data has to be stored or restructured and necessitate that data be stored in newer formats. But the basic premise of infrastructure capacity planning will still prevail—the only difference being horizontal scaling taking precedence over vertical scaling. Subsequent chapters on data access and data visualization will provide more insight into how the data needs to be stored.