
![]()
Big Data NFRs
Non-Functional requirements (NFRs) like security, performance, scalability, and others are of prime concern in big data architectures. Apart from traditional data security and privacy concerns, virtualized environments add the challenges of a hybrid environment. Big data also introduces challenges of NoSQL databases, new distributed file systems, evolving ingestion mechanisms, and minimal authorization security provided by the Hadoop-like platforms. Let’s look at the different scenarios where NFRs can be fine-tuned by extending the patterns discussed in earlier chapters as well as new patterns.
Problem
What are the common “ilities” that we should be cognizant of while architecting big data systems?
Solution
Due to the distributed ecosystem, there are multiple “ilities” that a big data architect should consider while designing a system:
- Reliability: Reliability is the ability of the system to be predictable and give the desired results on time and every time. It is related to the integrity of the system to give consistent results to every user of the system.
- Scalability: The ability of the system to increase processing power within the same machine instance (vertical scaling) or to add more machine instances in parallel (horizontal scaling) is called scalability.
- Operability: Once in production, how amenable the system is for monitoring every aspect that could affect the smooth operations determines its operability.
- Maintainability: A system is highly maintainable if defects, change requests, and extended features can be quickly incorporated into the running system without affecting existing functionality.
- Availability: Metrics like 99.999 and 24*7 are used to define the availability of the system for the users so that there is no downtime or very little downtime.
- Security:Distributed nodes, shared data, access ownership, internode communication, and client communication are all prime candidates for security vulnerabilities that can be exploited in a big data system.
A big data architect has to provide support for all the aforementioned “ilities” and trade-off some of them against each other based on the application priorities.
Traditional RDBMS systems have evolved over the years to incorporate extensive security controls like secure user and configuration management, distributed authentication and access controls, data classification, data encryption, distributed logging, audit reports, and others.
On the other hand, big data and Hadoop-based systems are still undergoing modifications to remove security vulnerabilities and risks. As during its inception, the primary job of Hadoop was to manage large amounts data; confidentiality and authentication were ignored.. Because security was not thought about in the beginning as part of the Hadoop stack, additional security products now are being offered by big data vendors. Because of these security concerns, in 2009 Kerberos was proposed as the authentication mechanism for Hadoop.
Cloudera Sentry, DataStax Enterprise, DataGuise for Hadoop, provide secure versions of Hadoop distributions. Apache Accumulo is another project that allows for additional security when using Hadoop.
The latest Hadoop versions have the following support for security features:
- Authentication for HTTP web clients
- Authentication with Kerberos RPC (SASL/GSSAPI) on RPC connections
- Access control lists for HDFS file permissions
- Delegation tokens for subsequent authentication checks after the initial authentication on Kerberos
- Job tokens for task authorization
- Network encryption
You have seen how to use ingestion patterns, data access patterns, and storage patterns to solve commonly encountered use-cases in big data architectures. In this chapter, you will see how some of these patterns can be further optimized to provide better capabilities with regard to performance, scalability, latency, security, and other factors.
Problem
How do I increase the rate of ingestion into disparate destination systems inside the enterprise?
Solution
The data ingested from outside the enterprise can be stored in many destinations, like data warehouses, RDBS systems, NoSQL databases, content management systems,and file systems. However, the speed of the incoming data passing through a single funnel or router could cause congestion and data regret. The data integrity also gets compromised due to leakage of data, which is very common in huge volumes of data. This data also hogs network bandwidth that can impede all other business-as-usual (BAU) transactions in the enterprise.
To overcome these challenges, an organization can adopt the Parallel Exhaust pattern (Figure 9-1). Each destination system has a separate router to start ingesting data into the multiple data stores. Each router, instead of publishing data to all sources, has a one-to-one communication with the destinations, unlike the “multi-destination” ingestion pattern seen in an earlier chapter. The routers can be scaled horizontally by adding more virtual instances in a cloud environment, depending on the volume of data and number of destinations.
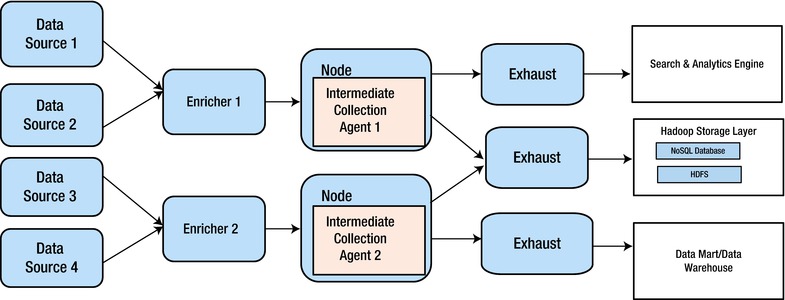
Figure 9-1. Parallel Exhaust pattern
Variety Abstraction Pattern
Solution
One size does not fit all. With unstructured and structured data, for a business case, storage mechanisms can be a combination of storage mechanisms, like an RDBMS, a NoSQL database, and other forms of storage. For example, a web site can have transactional data in an RDBMS, session data stored in a key-value NoSQL database, relationships between users or products stored in a graph database, and so forth. Thus, the landscape database in an enterprise is moving toward a heterogeneous combination of different types of databases for different purposes.
Problem
With polyglot persistence (multiple data storage systems) becoming the norm in an enterprise, how do we make sure that we do not become tightly coupled to a specific big data framework or platform? Also, if we have to change from one product to another, how do we make sure that there is maximum interoperability?
Solution
With multiple analytics platforms storing disparate data, we need to build an abstraction of application program interfaces (APIs) so that data can be interchangeably transferred across different storage systems.
This helps in retaining legacy DW frameworks. This pattern (Figure 9-2) helps simplify the variety problem of big data. Data can be stored in, imported to, or exported to HDFS, in the form of storage in an RDBMS or in the form of appliances like IBM Netezza/EMC Greenplum, NoSQL databases like Cassandra/HO Vertica/Oracle Exadata, or simply in an in-memory cache.
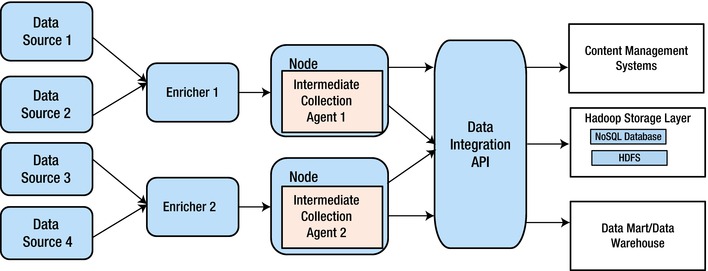
Figure 9-2. Variety Abstraction pattern
Real-Time Streaming Using the Appliance Pattern
Hadoop and MapReduce were created with off-line batch jobs in mind. But with the demand for real-time or near-real-time reports, abstraction of the data in a layer above the Hadoop layer that is also highly responsive requires a real-time streaming capability, which is being addressed by some big data appliances.
The other use-cases that require real-time monitoring of data are smartgrids, real-time monitoring of application and network logs, and the real-time monitoring of climatic changes in a war or natural-calamity zone.
Problem
I want a single-vendor strategy to implement my big data strategy. Which pattern do I go for?
Solution
The virtualization of data from HDFS to NoSQL databases is implemented very widely and, at times, is integrated with a big data appliance to accelerate data access or transfer to other systems. Also, for real-time streaming analysis of big data, appliances are a must (Figure 9-3).
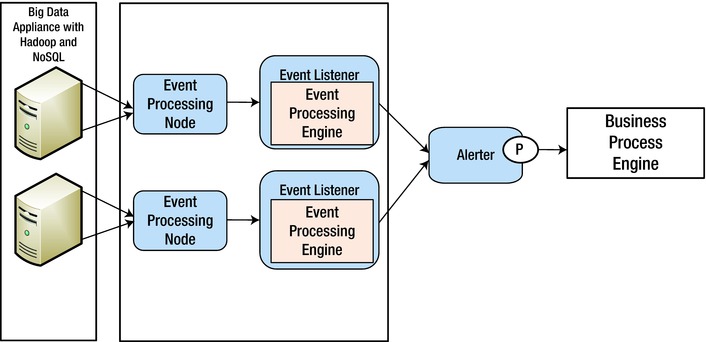
Figure 9-3. Real-time streaming using an Appliance pattern
EMC Greenplum, IBM PureData (Big Insights + Netezza), HP Vertica, and Oracle Exadata are some of the appliances that bring significant performance benefits. Though the data is stored in HDFS, some of these appliances abstract data in NoSQL databases. Some vendors have their own implementation of a file system (GreenPlum’s OneFS) to improve data access.
Real-time big data analytics products like SAP HANA come integrated with appliances that are fine-tuned for maximum performance.
Distributed Search Optimization Access Pattern
Problem
How can I search rapidly across the different nodes in a Hadoop stack?
Solution
With the data being distributed and a mix of structured as well as unstructured, searching for patterns and insights is very time consuming. To expedite these searches, string search engines like Solr are preferred because they can do quick scans in data sources like log files, social blog streams, and so forth.
However, these search engines also need a “near shore” cache of indexes and metadata to locate the required strings rapidly. Figure 9-4 shows the pattern.
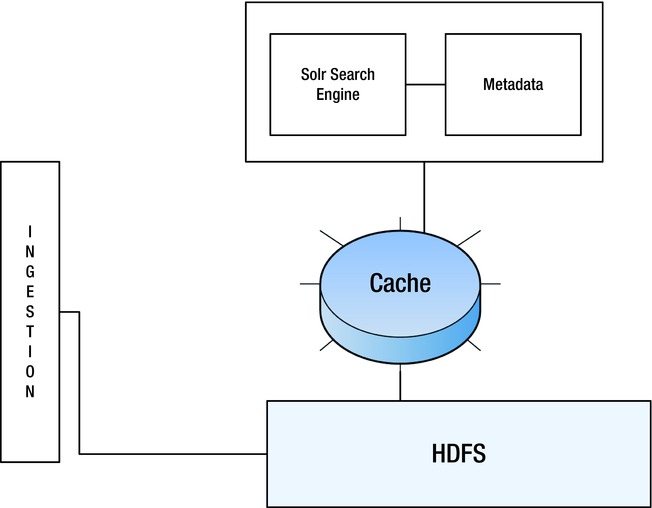
Figure 9-4. Distributed search optimization Access pattern
Problem
If there are multiple data storages—that is, “polyglot persistence”—in the enterprise, how do I select a specific storage type?
Solution
For a storage landscape with different storage types, data analysts need the flexibility to manipulate, filter, select, and co-relate different data formats. Different data adapters should also be available at the click of a button through a common catalog of services. The Service Locator pattern, where data-storage access is available in a SaaS model, resolves this problem. However, this pattern, which simplifies interoperability and scalability concerns for the user, is possible only if the underlying platform is API enabled and abstracts all the technical complexities from the service consumer (Figure 9-5).
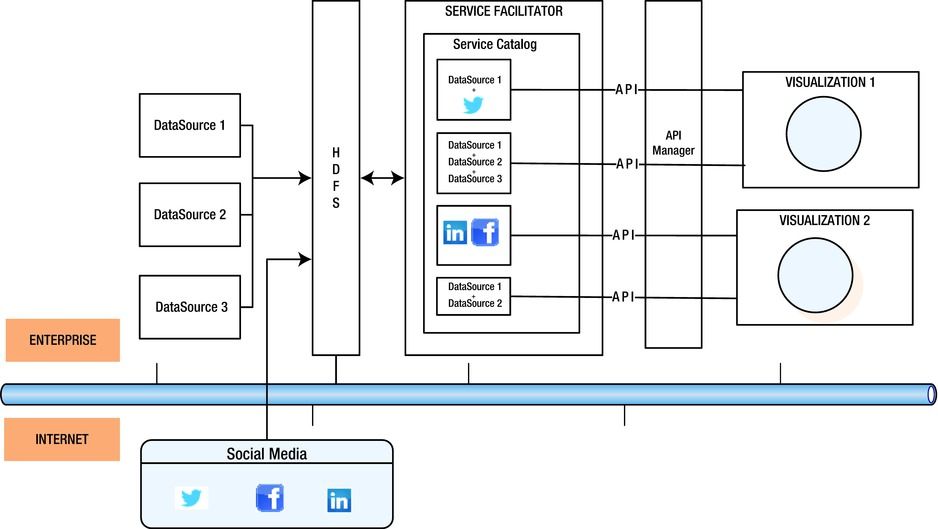
Figure 9-5. Anything as an API pattern
Security Challenges
Problem
What are the key security challenges in big data clusters?
Solution
Here are the key security challenges you’ll face with big data clusters:
- The distributed nature of the data and the autonomy that each node needs to have to process, manage, and compute data creates a multi-armed Hydra that is difficult to secure against unauthorized or unauthenticated access.
- Since the big data cluster is a redundant architecture, with data split and replicated across multiple servers, after a period of time managing the multiple copies of data becomes a very complex governance problem.
- Since each node is independent and a peer to others, the access ownership is mostly at schema level. Also, since NoSQL databases do not have referential integrity and validations at the database level, the user applications have to build the validations in the UI or business layer.
- Due to the use of multiple nodes, there are frequent handoffs between nodes. These handoff points become prime candidates for man-in-the-middle attacks because most communication between nodes is via RPC.
- Since all nodes are peers, it is difficult to define a “gateway” where a DMZ or firewall can be set up.
- Node coordinating and access control are managed by frameworks like Zookeeper or YARN, whose main concern is to detect failure of nodes and switch to live nodes. They are not designed with enterprise security in mind.
Operability
Solution
Following are the most important operational challenges for big data administrators:
- Big data administrators need the right tools to manage the mammoth clusters.
- Replication should be authorized properly using Kerberos; otherwise, any rogue client can create their own copy of the data on any of the nodes.
- Data has to be encrypted, but at the same time, it should not lead to a lag in decryption, as a very small lag can multiply exponentially across multiple nodes.
- Since the big data environment is essentially a megacluster that could be spread across multiple physical locations, it needs multiple administrators with different access rights and a clear separation of responsibilities.
- Since it is possible for different nodes to have different releases of OS, VM, and so forth, a governance tool is needed that manages these configurations and patches.
- We know Kerberos is used to authenticate Hadoop users. However, if a Kerberos ticket is stolen by a man-in-the-middle attack, a client can be duplicated and a rogue clone can be added to the cluster.
- Distributed logging is a must to track the train errors across the cluster landscape. Open source tools like scribe and logstash provide good log management in big data environments.
- As more and more big data services become API driven, strong API management tools are required that can keep track of REST-based APIs and provide life-cycle management for these APIs.
Big Data System Security Audit
Problem
As a big data compliance and security auditor, what are the basic questions that I should ask the concerned stakeholders of the company?
Solution
The following set of questions is a good starting point to begin a big data related audit:
- What are the various technology frameworks being used in the big data ecosystem for computation, data access, pattern recognition, task, and job management and monitoring?
- Who are the primary user-groups running big data queries? What functions are they trying to perform using these queries?
- Are these big data queries made by authorized users in real time or in batch mode using map reduce jobs?
- Are there any new applications built specifically to leverage the big data functions? Have those applications been audited?
- What is the amount of replication of data across nodes, and is there a complete dependency chart that is updated in real time for all these nodes?
- What tools and processes are being used for statistical analysis, text search, data serialization, process coordination, and workflow and job orchestration?
- What is the process for replication and recovery across node clusters?
- What are the different distributed file systems in the big data environment? Are they all storing structured data or unstructured?
- What are the backup, archiving, and recovery processes for all the above applications and storage systems?
- Are there any caching systems both persistent and in-memory? What is the level of confidentiality of the data stored in the caches? Are they purged regularly, and is there protection from other unauthorized access during run-time?
- Are there any performance criteria established as baselines, and what is the process to detect noncompliance and solve noncompliance issues? Typical reasons for noncompliance could be large input records, resource contention (CPU, network, and storage), race conditions between competing jobs, and so forth.
- How are different versions of Hadoop, OS, VMs, and so forth tracked and managed?
Problem
If I want to harden my big data architecture, are there any open source, common off the shelf (COTS) products I can buy?
Solution
Cloudera’s Sentry is an open source, enterprise-grade, big data security and access-control software that provides authorization for data in Apache Hadoop. It can integrate with Apache Hive.
Problem
Is there a big data API management tool I can use with minimum loss in performance?
Solution
Intel Expressway API Manager (Intel EAM) is a security-gateway enforcement point for all REST Hadoop APIs. Using this manager, all Hadoop API callers access data and services through this gateway.
It supports the authentication of REST calls, manages message-level security and tokenization, and protects against denial of service. There are other products also in the market that can do this.
Problem
I want to maintain the confidentiality of my data and only expose data relevant to a user’s access levels. What should I use?
Solution
InfoSphere Optim data masking (InfoSphere Optim DM) is a product that ensures data privacy, enables compliance, and helps manage risk. Flexible masking services allow you to create customized masking routines for specific data types or leverage out-of-the-box support.
InfoSphere Optim data masking on demand is one of the many masking services available for Hadoop-based systems. You can decide when and where to mask based on your application needs.
Problem
For efficient operability, I need good monitoring tools for big data systems. Are there any COTS products I can buy?
Solution
Products like Infosphere Guardium monitor and audit high-performance, big data analytics systems. InfoSphere Guardium provides built-in audit reporting to help you demonstrate compliance to auditors quickly.
IBM Tivoli Key Lifecycle Manager (TKLM) is another product that enhances data security and compliance management with a simple and robust solution for key storage, key serving, and key lifecycle management for IBM self-encrypting storage devices and non-IBM devices. TKLM offers an additional layer of data protection by providing encryption lifecycle key management for self-encrypting storage devices above and beyond the Guardium and Optim security capabilities.
Problem
What are the future plans of the Hadoop movement to enhance data protection of the Hadoop ecosystem?
Solution
Project Rhino is an open source Hadoop project that’s trying to address security and compliance challenges.
Project Rhino is targeted to achieve the following objectives:
Problem
What are some of the well-known, global-regulatory compliance rules that big data environments spread over different geographies and over public and private clouds have to comply with?
Solution
Table 9-1 shows some of the significant compliance rules that affect big data environments, showing what the constraint is along with the jurisdiction.
Table 9-1. Big Data Compliance Issues
Compliance Rule |
Data Constraints |
Geography |
|---|---|---|
EU Model Clauses for data transfers outside the EU |
Allows clients with EU data to lawfully use U.S. data centers. |
This is a basic requirement for any client with consumer or employee data of EU origin. |
A HIPAA “Business Associate Agreement” |
Allows clients with HIPAA-regulated data to lawfully use the data center. |
U.S. insurers, healthcare providers, and employee health benefit plans (often relevant for HR work) |
Model Gramm-Leach-Bliley insurance regulations |
Enables U.S. insurers and other financial institutions1 to use the data center to host consumer data. |
U.S. insurers and other financial institutions, relative to consumer data.2 |
Massachusetts Data Security Regulations |
Allows personal data from Massachusetts to be hosted by the data center consistent with MA requirements, which are currently the strictest state-level standards in the U.S. |
Companies with personal data of Massachusetts origin. |
The UK Data Protection Act |
Allows data from UK to be hosted by the data center consistent with local UK requirements. |
Companies with personal data of UK origin. |
Spanish Royal Decree on information security |
Allows data from Spain to be hosted by the data center consistent with local Spanish requirements. |
Companies with personal data of Spanish origin. |
Canadian federal PIPEDA and provincial PIPA acts. |
Allows clients with personal data of Canadian origin to use the data center. |
Companies with personal data of Canadian origin. |
Canadian provincial statutes focused on health data |
Allows for data center hosting of health-related data from relevant Canadian provinces. |
Entities with health-related data of Canadian origin. |
Summary
Big data architectures have to consider many non-functional requirements at each layer of the ecosystem. There are a host of tools to support administrators, developers, and designers in meeting these service level agreements (SLAs). Various design patterns can be used to improve the “ilities” without affecting the functionality of the use-case. The horizontal cross-cutting concerns can be addressed by the appropriate mix of design patterns, tools, and processes.