
![]()
Network Roadmap Evolution
Owing to this struggle for life, any variation, however slight and from whatever cause proceeding, if it be in any degree profitable to an individual of any species, in its infinitely complex relations to other organic beings and to external nature, will tend to the preservation of that individual, and will generally be inherited by its offspring . . . I have called this principle, by which each slight variation, if useful, is preserved, by the term of Natural Selection, in order to mark its relation to man’s power of selection.
The Origin of Species —Charles Darwin
After a diligent inquiry, I can discern four principal causes of the ruin of Rome, which continued to operate in a period of more than a thousand years. I. The injuries of time and nature. II. The hostile attacks of the Barbarians and Christians. III. The use and abuse of the materials. And, IV. The domestic quarrels of the Romans.
The History of the Decline and Fall of the Roman Empire —Edward Gibbon
According to Darwin’s Origin of Species, it is not the most intellectual of the species that survives; it is not the strongest that survives; but the species that survives is the one that is able best to adapt and adjust to the changing environment in which it finds itself.
'Lessons from Europe for American Business‘ —Leon C. Megginson
Most living things, evolution experts point out, survive and flourish due to two critical factors. First, the organism is so exceptionally designed for its environment that it continues to flourish in spite of many changes that push other organisms out of business; sharks and crocodiles fall under this category. Second, the organism is capable of changes in its genetic code to select traits and maximize abilities that give it an advantage for surviving in the environment. Such organisms that show adaptability continue to evolve and flourish. It is only natural to extend this phenomenon to organizations in comparing their origins, evolution, and continual growth in a stretch of organic thinking. Continuing on the same vein, while we could expect networks, superior by design, to survive forever, it is only logical to plan the way for which networks could evolve.
This chapter examines in detail some of the ways in which network evolution can be planned. Network resilience is one such tool that could help us understand the aspects of the network that need to be planned for toward evolution. It could also help us to deal with further changes in the industry, which could include both sudden unplanned changes and those that could be anticipated based on industry trends. As discussed in Chapter 4, careful planning and alignment of future goals and services would help businesses and organizations to evolve in the best manner possible.
Later in this chapter, we’ll also look at organizational factors that could keep the network viable and operational. This would include having response teams in place for any contingency in the network, making detailed and careful service and business continuity plans and executing them, and the ability to infuse radical thinking into the organization to help embrace changing scenarios and anticipate evolutionary requirements. We also discuss ways to measure the mutability and agility of the roadmaps to help planners find better tools to understand and track roadmap evolution.
The primary goal of this chapter is to help you get a grasp on the aspects of network roadmap evolution that matter and introduce tools that could be used to assess and analyze these. This will be useful in putting in place a process for network roadmap evolution, which we will discuss in detail in the next chapter.
Planned Evolution
This section will discuss techniques of testing the resilience of the network and what the results of the testing can tell us about the network. This would expose the gaps in the roadmap and help you take steps to evolve the roadmap to address those gaps in a planned manner. Also we will explain how reactive evolution can result from sudden changes and how changes can be anticipated.
Network Resilience
What is meant by resilience? What does it take for an entity to be resilient?
re·sil·ience
The ability to recover quickly from illness, change, or misfortune; buoyancy.
The American Heritage Dictionary of the English Language, Fourth Edition
Resilience is denoted by the ability to be able to recover quickly from events or external forces that may cause disruption. A similar description is very much applicable to network resilience. Just as different things are innately perceived to have varying abilities of resilience, experts have found that networks too need to be designed and built to be resilient. In an age where all networks are interconnected and most systems run out of the network, the system is as strong as its weakest link, which in this case could be any part of the network that is prone to attacks or disruptions, both natural and manmade. Failures and faults that could cripple the network or add to downtime are most certainly going to cause huge losses to different entities in following ways:
- Loss of revenue to the business due to failures in network and penalty clauses about availability
- Loss of trust in the quality of the network’s ability to survive failures and thwart future attacks
- Disruption of operations and services to operators running businesses out of the network
- Disruptions to customers and end users who may be running real-time and life critical operations from services provided by the network
With the increasing number of services and applications being hosted on the Cloud, disruptions to a network could imply denial of all those vital services and applications.
J.P.G. Sterbenz et al. define resilience for networks as follows:
[We define] resilience as the ability of the network to provide and maintain an acceptable level of service in the face of various faults and challenges to normal operation.
Resilience and Survivability in Communication Networks: Strategies, Principles, and Survey of Disciplines —J.P.G. Sterbenz et al. (2010)
Although resilience is defined based on a network’s ability to provide and maintain an acceptable level of service, survivability of the network is also an equally important aspect and is defined as follows by P. Cholda et al.:
[Network survivability is the] Quantified ability of a system, subsystem, equipment, process, or procedure to continue to function during and after a natural or man-made disturbance.
A Survey of Resilience Differentiation Frameworks in Communication Networks —P. Cholda et al.
So what are the disciplines on which network resilience can be analyzed? The fundamental concept that governs the ideas within the resilience domain are driven by the fault ![]() error
error ![]() failure chain, as shown in Figure 5-1.
failure chain, as shown in Figure 5-1.
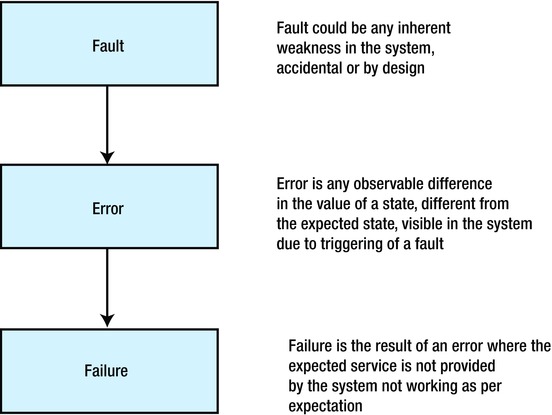
Figure 5-1. The fault ![]() error
error ![]() failure link
failure link
The rate at which dormant faults are exploited to become errors and observable errors become failures in the system can be limited by defenses built into the network. Also, by systematically improving the complete communication channel, the ability of the network to provide end-to-end connectivity to users is improved. This is disruption tolerance, also defined in following way:
Disruption tolerance is the ability of a system to tolerate disruptions in connectivity among its components, consisting of the environmental challenges: weak and episodic channel connectivity, mobility, unpredictably-long delay, as well as tolerance of energy (or power) challenges.
Resilience and Survivability in Communication Networks: Strategies, Principles, and Survey of Disciplines —J.P.G. Sterbenz et al. (2010)
Disciplines of Network Resilience
So how do we make the network more resilient? J.P.G. Sterbenz et al. classify the disciplines related to resilience under the following categories of challenge tolerance and trustworthiness:
- Challenge tolerance. As can be inferred, this relates to how the network continues to provide services on the face of challenges based on its design and engineering strengths. This could be broken down further into the following categories:
- Fault tolerance: Relating to the ability of the network to be able to handle and contain fault situations from escalating to system-level issues, leading to service disruptions. Relying primarily on redundancy techniques, fault tolerance can be seen as a way of handling noncorrelated fault events of limited scope.
- Survivability: A discipline that extends fault tolerance to more complicated scenarios where correlated fault events are being witnessed in the network. These could be malicious intentional coordinated efforts to bring the network down or an unintentional chain of events caused by large-scale disasters, both natural and manmade. Measures to define survivability have been suggested based on the factors drawn from Towards a Rigorous Definition of Information System Survivability by John C. Knight, Elisabeth A. Strunk, and Kevin J. Sullivan as a sextuple specification based on:
- Set of acceptable service states
- Set of service value factors
- Reachable environmental states that the system is subject to, which normally represent the challenges for the system
- Ordered relative service values as experienced by the user
- Set of valid transitions that the system may make between all acceptable forms of service
- Service probabilities that define the chances that each service state satisfies the criteria of dependability
- Disruption tolerance: This could primarily arise from environmental challenges that are intrinsic to communication networks. There could be a wide variety of disruptions affecting components of the network, as in:
- Problems with channel connectivity
- Issues related to mobility
- Latency figures that cannot be predicted
- Rapidly changing environment factors
- Aspects of energy management in the end-user devices, which could mean issues with low energy levels
- Traffic tolerance: Primarily relates to dynamically injected traffic load into the system:
- This could be a related to unexpected but valid events like a surge of people arriving at some location due to some valid reason (arrival of a celebrity, attending a ball game, etc.)
- It could also be a result of attacks initiated by people or systems with malicious intent, like a distributed denial of service (DDoS) attack.
- Trustworthiness. Contributes a counter set of disciplines related to aspects of the network that can be measured when it is subjected to challenges. Properties related to trustworthiness give a measure of the resilience indicator of the network, including:
- Dependability: A discipline that tries to quantify the extent to which a network can be relied upon to provide a service. This includes the factors of availability and reliability, which can be defined based on the following failure and repair-related measures:
- Mean time to failure (MTTF) is the expected value of the failure density function or a measure of how soon the next failure could occur.
- Mean time to repair (MTTR) is the expected value of the repair density function or a measure of how soon the system recovers from the failure.
- Mean time between failures (MTBF) is the sum of MTTR and MTTF, as in the time from failure to repair to the occurrence of the next failure.
- Availability: Defined as the probability that a service provided by the system or network will be operational and hence can be represented as a ratio of MTTF over MTBF.
- Reliability: This is more related to continuity of service, whereas availability is more about a network being available to initiate a service. Reliability is defined as the probability of a system continuing to be in service over a defined time period.
- Maintainability: The ability of the system to undergo repairs and changes to continue to remain functional.
- Safety: The reliability of the system being dependable during times of crippling failures.
- Integrity: This is factored into dependability in terms of the system being able to maintain its state of operations and being consistent with respect to it services.
- Security: This is characterized by the ability of a network or system to maintain and implement authorization and authentication policies consistently. Security is the backbone of network correctness and operation in the sense that failures in security can drastically impact other factors due to wrong access being granted to agent provocateurs and saboteurs. Factors influencing security include:
- Authentication under security pertains to ensuring that any user of the system is indeed the same user as being claimed.
- Authorization pertains to making sure the users are only able to perform or access services from the network they are authorized to do so.
- Auditability pertains to ensuring that all access to the system, including success and failure, valid and invalid, authorized and unauthorized, are audited in a consistent manner and available for future review.
- Performability: Covers aspects of the system governing the specifications of services to be offered by the system, including the QoS aspects. Performability directly affects overall effectiveness of the network and would mostly be covered by key performance indicators, as described in Chapter 1.
- Dependability: A discipline that tries to quantify the extent to which a network can be relied upon to provide a service. This includes the factors of availability and reliability, which can be defined based on the following failure and repair-related measures:
In addition to these factors, the complexity of the system under analysis, in terms of the large number of interconnected systems, plays a significant role too. In a system where many subcomponents interact in diverse ways, it may be found that undefined behaviors are also being manifest in the system with interactions not in accordance to any specification. Such complexity could inherently increase vulnerabilities in the system.
Frameworks and Strategies for Resilience in Networks
This section explains the different strategies for network resilience that have been used. We then assess the importance of some recent strategies in terms of applicability to the latest LTE networks.
The Advanced Networked Systems Architecture (ANSA) project addressed aspects related to dependability in large-scale system design. Their strategy consists of eight stages: fault confinement, fault detection, fault diagnosis, reconfiguration, recovery, restart, repair, and reintegration. Performability is considered in terms of availability of acceptable levels of service.
The Alliance for Telecommunications Industry Solutions (ATIS) has developed a multilayer framework for network survivability, including four layers:
- Physical layer. Relating to the infrastructure available at the physical layer, including provision for geographic redundancy
- System layer. With representation of nodes and links between the nodes, including the ability to do switching of links based on survivability requirements
- Logical layer. With provisions for support of required capacity for the network on top of the physical layer
- Service layer. With resources required for voice and data services and having the intelligence to do dynamic routing and an ability to reconfigure to support survivability
The Computer Emergency Response Team at the Carnegie Mellon University proposes a four-step strategy, including
- Resistance. Covering topics of traditional security and offering resistance to threats
- Recognition. With tools to analyze real-time attacks and manage threat responses
- Recovery. Including usage of redundancy concepts and planning of contingency responses
- Adaptation and evolution. To manage current and future threats for the network
The Survivable Mobile Wireless Networking project introduced the following techniques for managing survivability, with a key focus on mobile wireless networks (Survivable Mobile Wireless Networks: Issues, Challenges, and Research Directions, by James P.G. Sterbenz and Rajesh Krishnan):
- Proposed use of adaptive and agile networking concepts where the link layers are aware of the environmental conditions and adapt to adjust operational parameters to enhance survivability, for example, selection of alternate frequencies based on feedback from channels.
- Support for routing techniques that uses geographic knowledge to enhance survival operations, such as use of alternate routing nodes when information about geographic redundancy is available.
- Adaptive networking could also include selective use of MAC (Medium Access Control) and network layer parameters to help adapt to varying communication layer requirements. For example, at some instant, ensuring correctness of delivery at lower performability regions may be the requirement, while in some other conditions maximizing throughput with low RTT could be the goal.
- Usage of satellite communication to enhance and provide connectivity in scenarios to exploit specific requirements is also part of the proposal. This includes using satellites to connect network segments that have become isolated and also exploiting specific availability and dependability windows provided by the satellite communication to be able to perform multicast operations to a large set of listener nodes for reasons of security and communication.
The ResiliNets initiative argues for a strategy based on the following axioms:
- Faults are inevitable
- Understanding normal operations is necessary
- Expectations and preparation for adverse events and conditions is necessary
- Response to adverse events and conditions is necessary
The resilience strategy of ResiliNets includes dual components: Defend, Detect, Remediate, Recover (D2R2 component), and Diagnose and Refine (DR component).The D2R2 loop, also called the inner loop, operates in real time on a proactive basis, creating defenses, applying a constant proactive monitoring of threats, remediating to actively work against an actual threat, and finally recovering to improve the weakness that actually allowed the threat to materialize.
The outer loop, also called the DR loop, works on a more long-term basis in analyzing the nature of a threat and making a diagnosis about the fundamental issues that allowed the threat to exist in the first place. The Refine action allows for a long-term remedy to improve the design, which could help eliminate the current threat and improve the ability to avoid future threats of the same category.
The Resilience Control Loop, developed by J.P.G. Sterbenz et al. (Network resilience: A Systematic Approach, IEEE communications, July 2011), builds on top of the D2R2 + DR strategy to take a system-level look at the topic of resilience strategy. It starts by defining the resilience targets and goals that are to be met. These could very well be represented system-level KPIs and other targets. Defensive measures, such as provisioning for redundancy at different layers, are prescribed, along with services that are implemented in manners in which they protect their availability. A challenge analysis component performs the role of detecting the challenges that are being subjected on the system that impair its successful working and ability to meet its services. A resilience estimator works on the information provided about the findings of the challenge analysis and makes an assessment on the impact to the resilience targets, if resilience targets are indeed not being met. Based on inputs supplied by the estimator, a resilience manager makes active management decisions to control the resilience mechanisms (including those offered by the protocols and services in the network) that are available to the system to ensure that the provided service is not impaired. It also provides further feedback to the challenge analysis on the remedy to the challenge, which is incorporated into future evolution strategies.
Reactive Evolution to Sudden Changes
A key aspect of network resilience is one of the axioms expressed by the ResiliNets framework: the ability to address the requirements placed on the network satisfactorily under all conditions initiated by establishing an understanding of the expectations of acceptable levels of service from the network. This should be followed by a thorough study of past challenges faced by the network in providing resilience. The outputs of such a study will illustrate the challenges and their impacts on resilience, including actions taken at those times and their impact on recovering the resilience characteristics of the network.
The following quote further explains the axioms mentioned previously:
We define an adverse event or ongoing condition as challenging (Section 3) the normal operation of the network.
We can further classify adverse events and conditions by severity as mild, moderate, or severe, and categorise them into two types:
(1) Anticipated adverse events and conditions are ones that we can predict based either on past events (such as natural disasters), and attacks (e.g. viruses, worms, DDoS) or that a reasoned threat analysis would predict might occur.
(2) Unanticipated adverse events and conditions are those that we cannot predict with any specificity, but for which we can still be prepared in a general sense. For example, there will be new classes of attacks for which we should be prepared.
Resilience and Survivability in Communication Networks: Strategies, Principles, and Survey of Disciplines —J.P.G. Sterbenz et al. (2010)
To clarify further, this section will explain how to formulate a cogent set of steps to address those challenges that can be anticipated, their effect on the network resilience as studied and understood, and design measures that can be put in place to evolve the aspects of the network that are under stress to maintain the expected level of service.
A Generic Template
We suggest a sequence of steps to manage reactive evolution of a network. You can start by tabulating the expected levels of service, including critical attributes that could categorize the service. The KPIs of the network need to be listed, along with the service expectation to complete the understanding of requirements of network resilience. You can also mark critical KPIs among those that would necessarily need to be addressed.
Next the challenges that can be imposed on the network should be tabulated, including detailed explanations about the impact on the network, by positing impacts on the KPI and the variations that could be expected. The intent of such tabulation is to gain a critical understanding of the challenge to the network and to understand the detailed impacts on the characteristics of the network as denoted by the KPIs. It is also recommended to include past challenges that have been recorded during the operations of the network under question and how the critical KPIs were impacted during these.
The next step would be to link the critically impacted KPIs and make an assessment of the parts of the system that are unable to maintain the requisite functionality and thus impair the KPI as a service of the network. The critical components of the system should then be analyzed to understand how these can be reactively managed to address the challenge posed and to ensure that the key services offered by the network still manage to satisfy QoS criteria set on the operations.
To complete the process, the reactive changes that are necessary are then encoded as a set of steps to be triggered manually or are recommended to be built into a set of automated processes in the network that could reactively address the challenge by managing and evolving the necessary parts of the network to satisfy the operational criteria. SON concepts (as discussed in Chapter 2) include measures that address such automatic evolution decisions.
A Specific Example
One of the events that tends to affect functioning of networks is the problem of “flash crowds.” Wikipedia (http://en.wikipedia.org/wiki/Flash_mob) defines “flash mob,” which is the equivalent of a flash crowd, in the physical world as follows:
A flash mob (or flashmob) is a group of people who assemble suddenly in a public place, perform an unusual and seemingly pointless act for a brief time, and then quickly disperse, often for the purposes of entertainment, satire, and artistic expression. Flash mobs are organized via telecommunications, social media, or viral emails.
In a networked world, a similar phenomenon can occur that may be related to the flash mob scenario: communication networks are overloaded due to many people physically arriving at a location as part of an unplanned event (from service provider perspective) or it may be related to conditions occurring online in other parts of interconnected networks that may be sending more traffic in a burst to the network under scrutiny, more commonly called a Slashdot effect, which Wikipedia defined as (http://en.wikipedia.org/wiki/Slashdot_effect):
The Slashdot effect, also known as slashdotting, occurs when a popular website links to a smaller site, causing a massive increase in traffic. This overloads the smaller site, causing it to slow down or even temporarily become unavailable . . . the name is somewhat dated as flash crowds from Slashdot were reported to be diminishing as of 2005 due to competition from similar sites. . . . Typically, less robust sites are unable to cope with the huge increase in traffic and become unavailable—common causes are lack of sufficient data bandwidth, servers that fail to cope with the high number of requests, and traffic quotas. A flash crowd is a more generic term without using any specific name that describes a network phenomenon where a network or host suddenly receives a lot of traffic. This is sometimes due to the appearance of a web site on a blog or news column.
The first response in such a scenario would be to determine the impacts on the network’s KPI due to such a flash crowd event, which could possibly include the following for an LTE network:
- Availability impact. New subscribers may not be able to latch on to the network in the area covered by cells subject to the flash crowd.
- Dependability impact. Existing subscribers may face diminished or unreliable service in terms of download or other operations on ongoing requests.
- Performability impact. Existing subscribers may face a huge drop in performance in terms of ensured speeds in the network during the event.
Some of the conditions for handling of such situations in a related domain of video service is covered by Wenan Zhou et al. Remedial actions to this in our scenario could involve the following:
- Detection that a flash crowd event has occurred in real time
- Distribution of incoming requests to other parts of the network (neighboring cells) or to interrelated systems like 2G or 3G as a fixed rule until the flash event has passed
- Reducing QoS in a planned manner across all ongoing services in the network region under the impact
- Continually measuring system performance and taking additional measures like engaging alternate service providers to share some requests based on existing sharing arrangements kept in place for such exigencies
Selection of suitable steps to be taken would depend on and be determined by the resilience management function discussed earlier, which would control the actions and help the system handle the challenge.
Anticipation of Changes in Industry
This section provides a walkthrough of what could be a dream scenario for a company with a very successful product in the industry.
You have a great product running successfully in the industry. Customers throng to your product and services in huge hoards. Cash registers are ringing metaphorically all the time and the company’s future seems to be limitless, filled to the horizon with nary a sunset that can be envisioned and everyone in the company is living happily ever after.
If this sounds too good to be true, it may well be. Numerous companies with the sun-never-sets attitude have had their visions broken and brought rapidly down to the reality of declining profits or even bankruptcy by changes happening in the industry. The focus of our efforts here is on those situations where the changes happening in the industry have caught the company or product napping.
We focus here on an example of one such drastic change as was seen in recent history within the communications industry.
The Decline of BlackBerry
![]() Note The information in this section relates to recent events in the decline in BlackBerry’s position in the U.S. smartphone market and reasons that could be attributed for the same. It is not indicative of a position on BlackBerry’s future as a company or of performance of BlackBerry in other markets.
Note The information in this section relates to recent events in the decline in BlackBerry’s position in the U.S. smartphone market and reasons that could be attributed for the same. It is not indicative of a position on BlackBerry’s future as a company or of performance of BlackBerry in other markets.
In September 2013, the company BlackBerry made announcements to the following effects when declaring its Preliminary Second Quarter Fiscal 2014 Results (http://www.marketwired.com/press-release/blackberry-announces-preliminary-second-quarter-fiscal-2014-results-provides-business-nasdaq-bbry-1833209.htm):
- Expecting a GAAP net operating loss of approximately $950 million to $995 million
- Resulting from the increasingly competitive business environment impacting BlackBerry smartphone volumes, and a pretax restructuring charge of $72 million
- Announcing restructuring plans including:
- Reduction of approximately 4,500 employees
- Targeted reduction of operating expenditures by approximately 50% by end of Q1 Fiscal 2015
- Further roadmap updates included the following:
- To refocus on enterprise and prosumer market
- Offering end-to-end solutions, including hardware, software, and services
- Reduce smartphone portfolio from six devices to four
- With two phones targeting high-end prosumer and two entry-level devices
- Further forward-looking statements include:
- Increasing penetration in BlackBerry Enterprise Service 10 (BES 10) with nearly 31% increase in servers installation from July 2013
- Board continues to look at strategic alternative (Note: more on this later in this section)
Although BlackBerry may still be able to make a turnaround and reinvent itself, the decline in the company’s performance is very evident. Also, some additional information on where BlackBerry was a few years earlier (year 2011) may yield further pointers as to the direction the company’s results have been leading it (http://business.time.com/2013/09/20/blackberry-to-layoff-4500-amid-massive-losses/):
- BlackBerry was employing 17,000 people around 2011
- It was the proud owner of a 14% share in the U.S. smartphone market in 2011
Compare that to the following figures:
- BlackBerry had less than a 3% share of the smartphones in U.S. market in 2013
- Its total employee strength in March 2013 was 12,700, which would undergo a reduction by nearly 35%, as mentioned above
As a result of the strategic alternatives assessment mentioned in their 2014 results, BlackBerry announced a LoI (Letter of Intent) with a consortium led by Fairfax to sell and transfer ownership (http://press.blackberry.com/financial/2013/blackberry-enters-into-letter-of-intent-with-consortium-led-by-f.html).
It is obvious to ask the question, Where did BlackBerry seemingly go wrong? It was very much a company in good health and named by Fortune magazine in 2009 to be the fastest growing company in the world, attested to by earnings growing by an astounding 84% per year (http://business.time.com/2013/09/24/the-fatal-mistake-that-doomed-blackberry/). Exploring its situation would seem to indicate some chief reasons for its demise. BlackBerry had ridden the wave, making phones that were tuned to serve business users with its own very unique features of push e-mail, which allowed users to receive their company e-mails automatically. Also, the usage of a qwerty keyboard enabled fully functional and easier typing. What BlackBerry did not do well was anticipate the changes that were occurring in the market. Consumers (i.e., end users) were becoming the new drivers for smartphone sales. Applications were driving mobile content, and usage and lack of applications meant lack of usability and a disadvantage in comparison to other smartphones. Mobile phones were becoming full-fledged entertainment stations, with larger screens, touchscreen displays, and additional processing and performance requirements.
Apple and Google were driving the innovations through iPhone and Android mobiles and leaving the competition behind, but they were also helped by other trends. The proprietary security feature offered by BlackBerry became its Achilles’ heel for regulators who wanted to monitor communication. Faster network speeds offered by 3G and 4G networks made a big pipeline available for end users to access from their phones. Push messaging was no longer a differentiator, as the new smartphones were offering the same by default.
BlackBerry has seemingly now taken steps to adapt its roadmap and is seeking to reinvent itself in the new order of things. It is ironic though that changes that need to be made in anticipation of industry trends (trend of touchscreen-based smartphones) are often delayed by such companies until the time when they see declining results. As we will explain in the next section, failure to anticipate and adapt to the marketplace changes are primary reasons why businesses start to decline. Learning this may not be so easy though, as even cultural aspects of the organization need to be evolved to get into an adaptive mindset.
Future Goals and Services from a Business or Organization Perspective
What would be the best way to accomplish planned evolution for a company? If you discount innovative streaks that could help create industry-defining, path-breaking innovations, the most common tool available to an organization would prove to be goals and services that an organization wants to provide and target. This would help the organization in the following ways:
- Establish a process by which all key stakeholders can be involved to get a shared vision of the organization’s future
- Enable envisioning such a future to be implemented using specific goals and services
- Incorporate inputs related to the latest trends as seen in the industry or domain
- Make meaningful actions to be taken to be able to change as needed
Much of this has been discussed in Chapter 4. Here we will discuss the aspect of requirements from a organizational perspective in more detail, and in the process, we will define the roadmap evolution that will be discussed in Chapter 6. Yet, for an organization to be able to implement the evolution process, there needs to be much thought given to certain organizational factors, including:
- What the maturity level of the organization is
- How contingency plans are put in place
- How the company plans to manage its service and business continuity requirements
- How open the organization is to new thoughts and nurturing an ability or culture to think openly about adapting to and embracing change
The next section will discuss these areas in more depth.
Organizational Factors
So hopefully you now understand the process of planned evolution, including the models used to assess the resilience of the network, the frameworks available for evaluation, and how organizations can plan to put these processes in action to provide reactive evolution to sudden changes. You also should now know how important it is for organizations to learn to anticipate changes that come in the industry so new directions and goals can be set to help guide the organization to evolve in a planned manner and to provide a future that still holds relevance to the network, the product, and the company as a whole, which could help sustain success and ensure profitability and increase the chances for continued growth.
As discussed previously, much of planned evolution starts with defining the acceptable levels of service and putting in place a planned process for handling challenging situations where the level of service can be disrupted. The response team plays an integral part in this process.
Response Team in Place
One of the critical aspects of deployment of any network or service involves the ability to visualize how the product will work after deployment. This will involve understanding the process by which customers will deploy the product, including any qualification cycles and what is expected from the organization during these times. What levels of service are expected and provided will also depend on the type of contract executed between the entities and the service-level agreements (SLA) that are put in place.
Let’s look at it from the other side. If you are an operator, what should you be looking at before deploying a network? What are the critical questions you need to ask of an organization to make sure all the pieces are in place to help make a successful rollout of the product? You could start with the following:
- What are the capabilities of operations and monitoring that are provided by the network?
- What levels of service are ensured by the network?
- Are there dedicated network monitoring centers available?
- Are there ways to do live monitoring of the performance of the networks?
- Is there a process in place to ensure that a solution is found as quickly as possible without violating any SLAs agreed upon?
- What processes are in place to ensure that issues do not occur again?
- Is there a process in place to proactively discuss the health of the network and steps that can be taken to ensure continued acceptable performance in the face of changing requirements?
![]() Note Aspects of network operations in regard to product features are discussed in Chapter 4.
Note Aspects of network operations in regard to product features are discussed in Chapter 4.
Assuming the product features are taken care of in terms of setting up appropriate operations and management capabilities, let’s look at the aspects of a response team that will help the organization responsible for network operations run a successful deployment in line with customer expectations. In organizations where a network service team exists, they have the following responsibilities:
- Interacting with the network design team, or the team that would have engineered the network (in accordance with principles laid out in Chapter 1), to ensure they understand the network
- Setting up and run the network monitoring centers on a service basis
- Performing first-level analysis on any outage reported by the customer on the network
- Analyzing and assessing the root cause and taking the necessary actions to ensure services offered by the network are not diminished
- Escalating to a customer support team for issues they are not able to handle by raising an incidence report and collecting enough information and adding their own analysis to the customer incidence ticket
There should be a customer support team of experts who are the first response team to manage issues reported by customer. Their responsibilities would include:
- Being trained experts in the product and the domain
- Understanding first-level issues and what is going wrong at the customer set up
- Collecting enough information about the issue and being able to ask further questions to understand what is happening with the network
- Solving the issue for the customer or propose a workaround within approved SLA
- Escalating the incident to product engineering to be able to get a solution if they are unable to find one
There should be a critical response team to handle scenarios in which certain unplanned events may have occurred that have put performance of the network under critically unacceptable levels. These situations include, but are not restricted to:
- A natural disaster or a manmade event (war scenarios) that may have materialized to severely impact operability of the network
- Attacks on security of the network that may have created critical vulnerabilities to compromise security of the network
Such situations require deployment of a critical response team, which would be tuned to handle the situation in the following ways:
- Be authorized to take actions to help deescalate the situation
- Have enough preapprovals to help procure necessary resources and support
- Travel to the customer’s location if needed to resolve the issues on an urgent basis
- Find ways to give critical responses in very short time spans
- Help reduce the criticality of the situation to an extent that normal operations, even at an impaired level, can be resumed so the case can be handed over to the regular support team
Although having response teams in place for different levels of support to the customer is a good practice, it must be made clear to personnel in such teams how these teams are supposed to interact with one another and define the SLAs governing those interactions. This would help ensure that the teams know the roles they play and are focused on providing the best possible responses to the customer and help the network achieve is best performance. Having a document detailing the process of such engagement with the customer and within the teams is a good step toward achieving such goals.
Business Continuity Planning
Previously in this chapter, we discussed the concepts of network resilience, how it is defined, measured, about the disciplines contributing to it, and the processes and strategies for managing it. As an extension of that discussion, business continuity can be defined as the ability of the business to be resilient during challenges (including natural calamities and other manmade disasters) and to continue to operate and execute normal business functions. With that introduction, let’s get some definitions out of the way.
Business Continuity (BC) is defined as the capability of the organization to continue delivery of products or services at acceptable predefined levels following a disruptive incident.
ISO 22300:2012(en) Societal security—Terminology
Business Continuity Management (BCM) is defined as holistic management process that identifies potential threats to an organization and the impacts to business operations those threats, if realized, might cause, and which provides a framework for building organizational resilience with the capability of an effective response that safeguards the interests of its key stakeholders, reputation, brand and value-creating activities.
ISO 22301:2012(en) Societal security—Business continuity management systems—Requirements [5]
The Business Continuity Institute defines a BCM lifecycle as one that improves the overall resilience of the organization using the following good practices:
- A culture of embedding business continuity should be at the core of the practice
- A cycle of analysis, design, and implementation should form a continuous loop around business continuity
- An outer cycle of policy and program management should be used to control and determine the overall BCM lifecycle
The British Standards Institution defines its business continuity management code of practice (BS 25999-1:2006) to cover the following aspects of business continuity:
- Scope
- Policy
- Identifying critical business functions
- Developing and managing a business specific continuity plan
- Monitoring and maintaining performance
- Embedding a culture of business continuity awareness in your organization.
A business continuity management system (BCMS), a system for managing business continuity, would thus ensure that business continuity is defined and managed effectively in accordance with the context and needs of the organization. Let’s investigate the requirements for implementing such a system.
Requirements for Business Continuity Management System
The ISO 22301 standards define the BCMS framework in conjunction with the well-known quality control loop of the PDCA cycle (also known as Deming cycle), which comprises the following four phases applied continuously:
- Plan. Where one establishes the objectives and processes necessary for achieving the goals, and hence formulates a plan.
- Do. Where the steps in accordance to the plan are executed.
- Check. Where the results are actually checked and measured to help understand the deviations against specified results. This phase was also later changed to Study to help understand that the phase is not just about measuring, but more about understanding the results.
- Act: Where corrective actions are taken to help act on the significant differences between expected and actual results. This should encompass an understanding of the root causes for the deviations so the corrective actions are both remedial and preventive in nature.
The guidelines necessary to determine the framework for requirements for a BCMS are:
- Understanding the organization’s needs and the necessity for establishing business continuity management policy and objectives
- Implementing and operating controls and measures for managing an organization’s overall capability to manage disruptive incidents
- Monitoring and reviewing the performance and effectiveness of the BCMS
- Continual improvement based on objective measurement
Having introduced components of the BCMS, let’s look at the actual requirements of the BCMS as defined by the ISO standard (http://pecb.org/iso22301/iso22301_whitepaper.pdf). The context of the organization should include:
- A thorough understanding of the products, services, partners, channels, and relationships to understand the impact of an event that could challenge business continuity.
- The corporate policy of the organization determines the values chosen by the organization to help drive its goals and objectives.
- The business continuity policy (BCP) determines the necessary requirements for business continuity that are acceptable to the organization.
- A strategic alignment between the corporate policy and the BCP is vital for the success of the BCMS.
- A risk assessment gives information about the risk appetite of the organization, as to what levels of risk it is comfortable with.
- Identify the relevant stakeholders and their needs and expectations from the BCMS to complete the understanding of the context.
- Impacts or constraints imposed by any regulatory bodies for operation.
Leadership is entrusted with the ownership for the success of the BCMS and also the role of sponsor for the BCMS to convey the necessary importance of the BCMS to the teams. Hence, leadership will need to ensure:
- Necessary resources are available for the BCMS.
- The importance of BCMS is understood by the teams.
- Continual support is provided to help implement, execute, monitor, and improve the BCMS.
- The right people are assigned clearly communicated roles and responsibilities for the BCMS.
Planning is the most critical part of the BCMS, and it should ensure the following:
- The plan is clear and takes into account maps to the acceptable levels of service expected from the network and product.
- The plan should provide for measurability of the functioning of the BCMS.
- The plan should ensure that there are opportunities provided to review and update it as needed.
Support includes the necessary parts needed to complete the planning in terms of:
- Synchronizing the plan with all relevant stakeholders, internal and external
- Documenting the plan correctly and making proper communication regarding the plan at correct points of time
- Provision and enablement of required resources to implement the plan
Operation is the phase when the plan is put into action after considering the following inputs:
- Business impact analysis when critical processes and services and their interdependencies are identified to support appropriate levels of service.
- Risk assessment of the various events and their impacts on business should be assessed and the risks ranked to ensure systematic processing of risks. Only those risks with enough disruptive potential as determined by the policy should be handled as part of the plan.
- The actual strategy that will be used to handle business continuity challenges should be established.
- Procedures that need to be followed as part of implementation of the BCMS should be documented, including exact conditions of the disruptive event being handled, the communication protocol that should be followed to indicate the plan is being executed, the roles and responsibilities of different people involved, and awareness of factors that could impact the effectiveness of actions.
- Exercising and testing the procedures to confirm that the procedures work as expected. It also helps if the organization can assess that BCMS work in alignment with other goals of the organization.
Performance evaluation should include:
- Permanent systems to monitor performance of the BCMS
- Formal audits conducted on a regular basis to monitor and assess the performance and collect inputs for improvement
Improvement to the BCMS should include continuous processes that are set in place to keep checking the performance of BCMS against requirements. There should be a means to control and improve the procedures and guidelines to ensure performance is maintained or improved on an ongoing basis.
All of these requirements should be implemented as part of BCMS to have a system that will enable, monitor, track, and maintain business continuity at all times, especially in times of strife and disaster. Let’s look at some more specific inputs related to service continuity planning, which in many ways is a subset of BCP.
Service Continuity Planning
Service continuity planning is widely seen as a subset of business continuity planning. There is a reason for this. Most organizations look at service continuity as denoting IT service continuity. This is both a necessary and important view as IT services provide the backbone for operations of most businesses around the world. BCP cannot exist without IT service continuity planning in place. The European Network and Information Security Agency has the following to say on the topic:
IT service continuity addresses the IT aspect of business continuity. In today’s economy, business processes increasingly rely on information and communication technology (ICT) and electronic data (e-data). ICT systems and e-data are, therefore, crucial components of the processes and their safe and timely restoration is of paramount importance. If such systems are disrupted, an organization’s operations can grind to a halt. If the interruption is serious enough, and no risk management planning has occurred, a firm may even go out of business
.
So how do we go about preparing for service continuity planning? What are the steps involved in this? Will the framework for BCP also work here? These are some of the questions that need answering. In most cases, we could very well apply the principles used for developing BCP and BCMS to requirements for IT services as well.
We should start by defining the key stakeholders involved in the IT service continuity planning. Although this would definitely include key people from the IT team, it would also include key stakeholders from other business units who are dependent on the IT services for their valuable input toward defining the critical IT services that need to be assessed for continuity purposes.
This should be followed by an enumeration of key IT services and the importance placed by business on continued functioning of these services during critical periods. Comprehensive risk assessment about threats to these services should be completed and the risks and the strategies to mitigate these should be documented. Contingency plans in case of failure of mitigation should also be assessed, and alternate strategies should be put in place to handle them. One such valuable contingency planning involves setting up multiple redundant sites to take over IT and business service processing in the event of a primary site going out of service.
Provisioning of Alternate Facilities
In the event that an organization’s main facility or IT assets, networks, and applications are lost, an alternate and redundant facility should be made available to help continue provisioning of services and processing of information. The Office of Critical Infrastructure Protection and Emergency Preparedness of the Government of Canada refers to the following types of alternate facilities that can be provisioned:
- Cold site: This form of facility is the least costly method of maintaining an alternate site. The reference to coldness is in a way related to the time taken to get the site up and running from its cold or inert state. Cold sites take a maximum time to become fully operational. In terms of IT infrastructure, the site could take time to build up services to the level that the functioning site was providing before it can handle the services by itself.
- Warm site: A warm site could be partially equipped with required service and facilities so that it can take over the responsibilities of an active site in a short span of time, which may be a matter of a few hours. Warm sites are more costly to maintain compared to cold sites.
- Hot site: A hot site is the most resilient way of maintaining an alternate site. A hot site is normally completely in synch with the primary site and can take over responsibilities very much in real time. A hot site is very costly to maintain as services and infrastructure need to be brought up and maintained to be a complete and online backup for the primary site.
The site that is selected as the primary alternate should be decided based on the criticality of the services and the cost of not providing service. This could help in assessing the tradeoff between the costs incurred by a lack of continuity vs. the cost of setting up an appropriate alternate site.
Cultural Encouragement to Embrace Futuristic and Even Fantastic Scenarios
You can lead a horse to water, but you can’t make it drink
English proverb
The processes described in this chapter are aimed primarily at helping an organization improve its ability to handle challenging situations. Processes are a way to achieve a shared goal: a common language to help different people understand the issues involved in a joint venture and a common path to achieve collective results. But processes alone do not guarantee anything. Processes are only as effective as the efforts of the people who are applying them. A change in processes needs to be preceded by a change in thinking in the people involved in the organization to understand the context of the change and to appreciate the reasons for implementing the change. In the event that new processes are implemented without the mindset being changed, it may pretty well end up like the proverbial horse that is brought to the water. It may snort, it may nibble, and it may stomp nervously around, but it most definitely would not drink the water unless it has a mind to do so.
The Jisc infoNet infokit on Change Management (http://www.jiscinfonet.ac.uk/infokits/change-management/) notes the following aspects are involved in any change: “Change usually involves three aspects: people, processes, and culture.”
It is not enough to get only the processes right. To properly manage the change, it is as important to understand the people involved and the culture prevalent among them. Every change that is brought about inherently faces resistance toward adoption of the change. Once this resistance is overcome, it becomes easier to make the transition and implement the change. Also, in some cases, it could make it easier to understand which aspects of the culture itself need to be changed for the betterment of the organization. The onus for cultivating the necessary culture needed to inspire and evolve an organization is largely place on leadership of the organization.
Coming back to the topic of resilience and continuity of services, it should be apparent that people and personnel involved should be encouraged to cultivate an attitude for thinking about possibilities. These possibilities could be about both good and bad events that could happen and have an impact on the business and the organization. Better anticipation in problem-oriented thinking could lead to better preparedness for such situations in that all aspects of planning—impact analysis, preparation of mitigation plans, and putting such plans into action—can help the evolution of the roadmap to embrace the change.
Roadmap Mutability
mu-ta-ble
Capable of change or of being changed in form, quality, or nature
Merriam-Webster’s Dictionary
Mutability, in the context of roadmaps, is important in that it provides a way to assess whether the roadmaps are capable of changing over time. It also provides a way to check the effectiveness of the processes set in place for evolution of roadmaps under various conditions.
Having introduced a reasonably acceptable definition for roadmap mutability, we propose the following as one of the ways to measure this. It is important to understand that while the concept of defining and measuring mutability of roadmaps seems important enough to us, we were unable to find specific references to this in our searches in standard publications.
How can a change be defined as completed? One way is to define conditions of acceptance to confirm that the change is definitely in place in an entity where it is being changed. It follows that implementation of the change should be verifiable by inspection of the entity and also by observations associated with the behavior of the entity in cases where the change impacts some visible behavior of that change.
If we were to define the conditions for successful change to a roadmap, they could include:
- All aspects of the roadmap are updated
- Viable plans for implementation of updated roadmap are available
- All stakeholders involved in roadmap communication have been updated about the changes
- All documentation related to the change is completed and available
- The resources necessary for achieving the changed roadmap are in place or arranged
Based on such an acceptance of a change to a roadmap, mutability could be defined as a function of the number of valid changes initiated vs. the number of changes accepted successfully by the roadmap. A lower factor of accepted changes could imply that the organization still has a ways to go to achieve better roadmap mutability in order to evolve the network and the product at a rate at which meaningful evolution could be possible.
Roadmap Agility
a·gil·i·ty
n.
The state or quality of being agile; nimbleness.
The American Heritage Dictionary of the English Language, Fourth Edition
Although the concept of mutability focuses more on the ability to change, agility is concerned more with the rate at which such a change is possible. An entity that is receptive to change, yet not agile enough, may struggle to survive through conditions that demand better agility.
In the context of roadmaps, we could define agility as a measure of the rate at which changes are accepted and implemented as part of the roadmap. We define this measure to start at the arrival of a valid request for a change in roadmap and measure the time taken for the change to be reviewed, evaluated, and incorporated as part of the roadmap.
At periods that are deemed to be critical to the network or product, it may be a valid expectation for an organization to be able to respond very quickly to change requests. Agility at such times may be the x-factor that helps a good product that is slow to respond to changes become something close to a market leader. Such agility needs a culture of understanding between the stakeholders of the product: a shared vision and singleness of purpose to make changes happen in the product and overcome their personal differences to achieve a greater goal—that of product betterment.
Summary
This chapter began by looking at planned evolution to the networks roadmap. We defined the concept of network resilience and looked at different models this. We also walked through a strategy of reactive evolution for sudden changes, illustrated with a specific example for using a suggested template. We then suggested ways in which industry changes could be anticipated. We also looked at ways in which future goals for business and services could be used as a tool to help manage evolution of the roadmap.
We then went through organizational factors that could help in roadmap evolution—that of designing and having a response team in place, on planning business continuity and service continuity aspects, and the importance of developing a culture to embracing change in the organization.
We also briefly discussed proposed measures of roadmap mutability and roadmap agility to help assess and evaluate aspects of roadmap management for the organization, which could help answer questions about the flexibility of the roadmap and the speed with which the organization evolves.
This chapter emphasized that managing evolving LTE networks is also about paying attention to aspects of network resilience, business and service continuity planning, and being responsive to changes as needed in the industry.