
Chapter 8. Odds and Ends
Pointers are vital to almost all aspects of C. Many of these areas are fairly well defined, such as arrays and functions. This chapter examines several topics that do not neatly fit into the previous chapters. Coverage of these topics will round out your knowledge of how pointers work.
In this chapter, we will examine several topics related to pointers:
Casting pointers
Accessing hardware devices
Aliasing and strict aliasing
Use of the
restrictkeywordThreads
Object-oriented techniques
With regards to threads, there are two areas of interest. The first deals with the basic problem of sharing data between threads using pointers. The second discusses how pointers are used to support callbacks. An operation may invoke a function to perform a task. When the actual function called changes, this is referred to as a callback function. For example, the sort function used in Chapter 5 is an example of a callback function. A callback is also used to communicate between threads.
We will cover two approaches for providing object-oriented type support within C. The first is the use of an opaque pointer. This technique hides a data structure’s implementation details from users. The second technique will demonstrate how to effect polymorphic type behavior in C.
Casting Pointers
Casting is a basic operator that can be quite useful when used with pointers. Casting pointers are useful for a number of reasons, including:
Accessing a special purpose address
Assigning an address to represent a port
Determining a machine’s endianness
We will also address a topic closely related to casting in the sectionUsing a Union to Represent a Value in Multiple Ways.
Note
The endianness of a machine generally refers to the order of bytes within a data type. Two common types of endian include little endian and big endian. Little endian means the low-order bytes are stored in the lowest address, while big endian means the high-order bytes are stored at the lowest address.
We can cast an integer to a pointer to an integer as shown below:
intnum=8;int*pi=(int*)num;
However, this is normally a poor practice as it allows access to an arbitrary address, potentially a location the program is not permitted to access. This is illustrated in Figure 8-1, where address 8 is not in the application’s address space. If the pointer is dereferenced, it will normally result in the application’s termination.
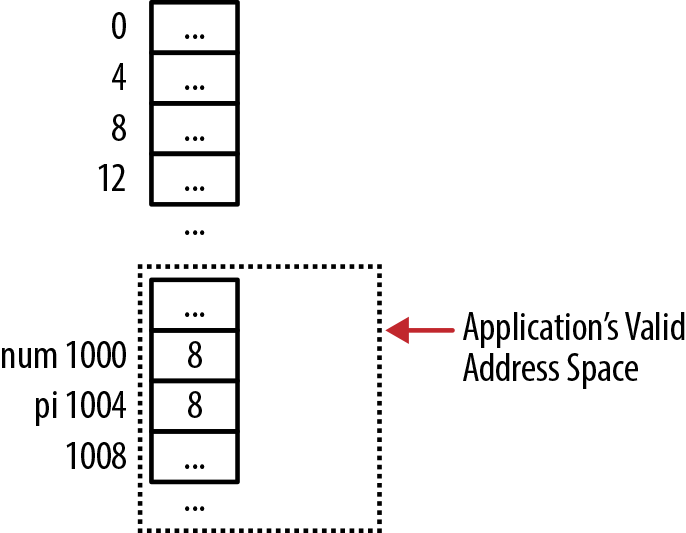
For some situations, such as when we need to address memory location zero, we may need to cast a pointer to an integer and then cast it back to a pointer. This is more common on older systems where a pointer’s size is the same size as an integer. However, this does not always work. The approach is illustrated below, where the output is implementation-dependent:
pi=#printf("Before: %p",pi);inttmp=(int)pi;pi=(int*)tmp;printf("After: %p",pi);
Casting a pointer to an integer and then back to a pointer has never been considered good practice. If this needs to be done, consider using a union, as discussed in the sectionUsing a Union to Represent a Value in Multiple Ways.
Remember that casting to and from an integer is different from casting to and from void, as illustrated in Pointer to void.
Note
The term handle is sometimes confused with a pointer. A handle is a reference to a system resource. Access to the resource is provided through the handle. However, the handle generally does not provide direct access to the resource. In contrast, a pointer contains the resource’s address.
Accessing a Special Purpose Address
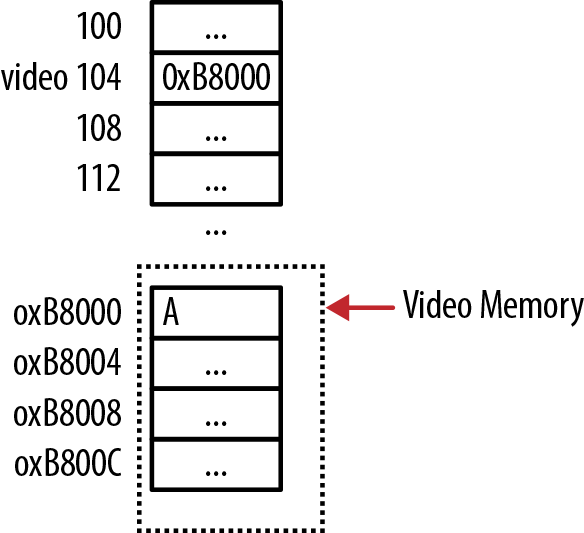
The need to access a special purpose address often occurs on embedded systems where there is minimal operating system mediation. For example, in some low-level OS kernels the address of video RAM for a PC is 0xB8000. This address holds the character to be displayed in the first row and first column when in text mode. We can assign this address to a pointer and then assign a character to the location, as illustrated below. The memory layout is shown in Figure 8-2:
#defineVIDEO_BASE0xB8000int*video=(int*)VIDEO_BASE;*video='A';
If appropriate, the address can also be read. This is not typically done for video memory.
When you need to address memory at location zero, sometimes the
compiler will treat it as a NULL
pointer value. Access to location zero is often needed in low-level
kernel programs. Here are a few techniques to address this
situation:
Set the pointer to zero (this does not always work)
Assign a zero to an integer and then cast the integer to the pointer
Use a union as discussed in the section Using a Union to Represent a Value in Multiple Ways
An example of using the memset
function follows. Here, the memory referenced by ptr is set to all zeros:
memset((void*)&ptr,0,sizeof(ptr));
On systems where addressing memory location zero is needed, the vendor will frequently have a workaround.
Accessing a Port
A port is both a hardware and a software concept. Servers use software ports to indicate they should receive certain messages sent to the machine. A hardware port is typically a physical input/output system component connected to an external device. By either reading or writing to a hardware port, information and commands can be processed by the program.
Typically, software that accesses a port is part of the OS. The following illustrates the use of pointers to access a port:
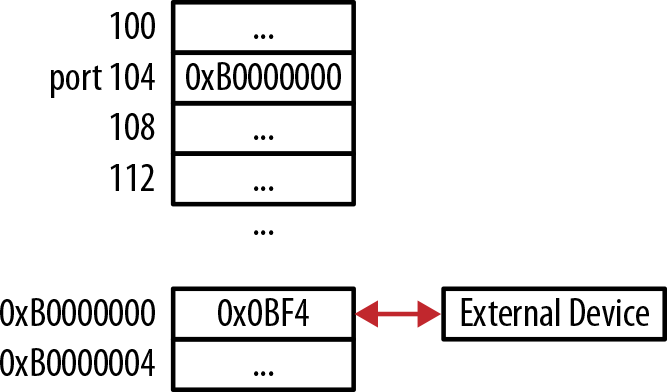
#definePORT0xB0000000unsignedintvolatile*constport=(unsignedint*)PORT;
The machine uses the hexadecimal value address to designate a
port. The data is treated as an unsigned integer. The volatile keyword
qualifier indicates that the variable can be changed outside of the
program. For example, an external device may write data to a port. This
write operation is performed independent of the computer’s processor.
Compilers will sometimes temporarily use a cache, or register, to hold
the value in a memory location for optimization purposes. If the
external write modifies the memory location, then this change will not
be reflected in the cached or register value.
Using the volatile keyword will prevent the runtime system from using a register to temporarily store the port value. Each port access requires the system to read or write to the port instead of reading a possibly stale value stored in a register. We don’t want to declare all variables as volatile, as this will prevent the compiler from performing certain types of optimizations.
The application can then read or write to the port by dereferencing the port pointer as follows. The layout of memory is shown in Figure 8-3, where the External Device can read/write to the memory at 0xB0000000:
*port=0x0BF4;// write to the portvalue=*port;// read from the port
Accessing Memory using DMA
Direct Memory Access (DMA) is a low-level operation that assists in transferring data between main memory and some device. It is not part of the ANSI C specification but operating systems typically provide support for this operation. DMA operations are normally conducted in parallel with the CPU. This frees up the CPU for other processing and can result in better performance.
The programmer will invoke a DMA function and then wait for the operation’s completion. Often, a callback function is provided by the programmer. When the operation completes, the callback function is invoked by the operating system. The callback function is specified using a function pointer and is discussed further in the section Using Function Pointers to Support Callbacks.
Determining the Endianness of a Machine
The cast operator can also be used to determine the endianness of architecture. Endian refers to the order of bytes in a unit of memory. The endianness is usually referred to as either little endian or big endian. For example, for a four-byte representation of an integer using little endian ordering, the integer’s least significant byte is stored in the lowest address of the four bytes.
In the following example, we cast an integer’s address as a
pointer to a char. The individual
bytes are then displayed:
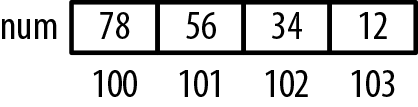
intnum=0x12345678;char*pc=(char*)#for(inti=0;i<4;i++){printf("%p: %02x",pc,(unsignedchar)*pc++);}
The output of this code snippet as executed on an Intel PC reflects a little-endian architecture, as shown below. Figure 8-4 illustrates how these values are allocated in memory:
100: 78 101: 56 102: 34 103: 12
Aliasing, Strict Aliasing, and the restrict Keyword
One pointer is said to alias another pointer if they both reference the same memory location. This is not uncommon, and it can present a number of problems. In the following code sequence, two pointers are declared and are both assigned the same address:
intnum=5;int*p1=#int*p2=#
When the compiler generates code for pointers, it has to assume that aliasing may occur unless told otherwise. The use of aliasing imposes restrictions on compiler-generated code. If two pointers reference the same location, either can potentially modify that location. When the compiler generates code to read or write to that location, it is not always able to optimize the code by storing the value in a register. It is forced to perform machine-level load and store operations with each reference. The repeated load/store sequence can be inefficient. In some situations, the compiler must also be concerned about the order in which the operations are performed.
Strict aliasing is another form of aliasing. Strict aliasing does not allow a pointer of one data type to alias a pointer of a different data type. In the following code sequence, a pointer to an integer aliases a pointer to a float. This violates the strict aliasing rule. The sequence determines whether the number is negative. Instead of comparing its argument to zero to see whether it is positive, this approach will execute faster:
floatnumber=3.25f;unsignedint*ptrValue=(unsignedint*)&number;unsignedintresult=(*ptrValue&0x80000000)==0;
Note
Strict aliasing does not apply to pointers differing only by sign or qualifier. The following are all valid strict aliases:
intnum;constint*ptr1=#int*ptr2=#intvolatileptr3=#
However, there are situations where the ability to use multiple representations of the same data can be useful. To avoid aliasing problems, several techniques are available:
Use a union
Disable strict aliasing
Use a pointer to
char
A union of two data types can get around the strict aliasing problem. This is discussed in the section Using a Union to Represent a Value in Multiple Ways. If your compiler has an option to disable strict aliasing, it can be turned off. The GCC compiler has the following compiler options:
-fno-strict-aliasingto turn it off-fstrict-aliasingto turn it on-Wstrict-aliasingto warn of strict aliasing-related problems
Code requiring strict aliasing to be turned off probably reflects poor memory access practices. When possible, take time to resolve these issues instead of turning off strict aliasing.
Note
Compilers do not always do a good job at reporting alias-related warnings. They can sometimes miss aliases and may sometimes report alias problems where they don’t exist. It is ultimately up to the programmer to identify alias conditions.
A pointer to char is always
assumed to potentially alias any object. Thus, it can be used safely in
most situations. However, casting a pointer to one data type to a pointer
to char and then casting the pointer to
char to a second pointer data type will
result in undefined behavior and should be avoided.
Using a Union to Represent a Value in Multiple Ways
C is a typed language. When a variable is declared, a type is assigned to it. Multiple variables can exist with different types. At times, it may be desirable to convert one type to another type. This is normally achieved with casting but can also be performed using a union. The term type punning describes the technique used to subvert the type system.
When the conversion involves pointers, serious problems can result. To illustrate this technique, we will use three different functions. These will determine whether a floating point number is positive.
The first function shown below uses a union of a float and an unsigned integer. The function first assigns the floating point value to the union and then extracts the integer to perform the test:
typedefunion_conversion{floatfNum;unsignedintuiNum;}Conversion;intisPositive1(floatnumber){Conversionconversion={.fNum=number};return(conversion.uiNum&0x80000000)==0;}
This will work correctly and does not involve aliasing because no pointers are involved. The next version uses a union that contains pointers to the two data types. The floating point number’s address is assigned to the first pointer. The integer’s pointer is then dereferenced to perform the test. This violates the strict aliasing rule:
typedefunion_conversion2{float*fNum;unsignedint*uiNum;}Conversion2;intisPositive2(floatnumber){Conversion2conversion;conversion.fNum=&number;return(*conversion.uiNum&0x80000000)==0;}
The following function does not use a union and violates the
strict aliasing rule since the ptrValue pointer shares the same address as
number:
intisPositive3(floatnumber){unsignedint*ptrValue=(unsignedint*)&number;return(*ptrValue&0x80000000)==0;}
The approach used by these functions assumes:
The IEEE-754 floating point standard is used to represent a floating point number
The floating number is laid out in a particular manner
Integer and floating point pointers are aligned correctly
However, these assumptions are not always valid. While approaches such as this can optimize operations, they are not always portable. When portability is important, performing a floating point comparison is a better approach.
Strict Aliasing
A compiler does not enforce strict aliasing. It will only generate warnings. The compiler assumes that two or more pointers of different types will never reference the same object. This includes pointers to structures with different names but that are otherwise identical. With strict aliasing, the compiler is able to perform certain optimizations. If the assumption is incorrect, then unexpected results may occur.
Even if two structures have the same field but different names,
two pointers to these structures should never reference the same object.
In the following example, it is assumed the person and employee pointers will never reference the
same object:
typedefstruct_person{char*firstName;char*lastName;unsignedintage;}Person;typedefstruct_employee{char*firstName;char*lastName;unsignedintage;}Employee;Person*person;Employee*employee;
However, the pointers can reference the same object if the structure definitions differ only by their name, as illustrated below:
typedefstruct_person{char*firstName;char*lastName;unsignedintage;}Person;typedefPersonEmployee;Person*person;Employee*employee;
Using the restrict Keyword
C compilers assume pointers are aliased by default. Using
the restrict keyword when declaring a
pointer tells the compiler that the pointer is not aliased. This allows
the compiler to generate more efficient code. Frequently, this is
achieved by caching the pointer. Bear in mind that this is only a
recommendation. The compiler may decide not to optimize the code. If
aliases are used, then the code’s execution will result in undefined
behavior. The compiler will not provide any warning when the assumption
is violated.
Note
New code development should use the restrict keyword with most pointer
declarations. This will enable better code optimization. Modifying
existing code may not be worth the effort.
The following function illustrates the definition and use of the
restrict keyword. The function adds
two vectors together and stores the result in the first vector:
voidadd(intsize,double*restrictarr1,constdouble*restrictarr2){for(inti=0;i<size;i++){arr1[i]+=arr2[i];}}
The restrict keyword is used
with both array parameters, but they should not both reference the same
block of memory. The following shows the correct usage of the
function:
doublevector1[]={1.1,2.2,3.3,4.4};doublevector2[]={1.1,2.2,3.3,4.4};add(4,vector1,vector2);
In the following sequence, the function is called improperly with the same vector being passed as both parameters. The first statement uses an alias while the second statement uses the same vector twice:
doublevector1[]={1.1,2.2,3.3,4.4};double*vector3=vector1;add(4,vector1,vector3);add(4,vector1,vector1);
Though it may sometimes work correctly, the results of the function invocation may not be reliable.
Several standard C functions use the restrict keyword, including:
void *memcpy(void * restrict s1, const void * restrict s2, size_t n);char *strcpy(char * restrict s1, const char * restrict s2);char *strncpy(char * restrict s1, const char * restrict s2, size_t n);int printf(const char * restrict format, ... );i
nt sprintf(char * restrict s, const char * restrict format, ... );i
nt snprintf(char * restrict s, size_t n, const char * restrict format, ... );int scanf(const char * restrict format, ...);
The restrict keyword has two
implications:
Threads and Pointers
When threads share data, numerous problems can occur. One common problem is the corruption of data. One thread may write to an object but the thread may be suspended momentarily, leaving that object in an inconsistent state. Subsequently, a second thread may read that object before the first thread is able to resume. The second thread is now using an invalid or corrupted object.
Since pointers are a common way of referencing data in another thread, we will examine various issues that can adversely affect a multithreaded application. As we will see in this section’s examples, mutexes are frequently used to protect data.
The C11 standard implements threading, but it is not widely supported at this time. There are numerous libraries that support threads in C. We will use Portable Operating System Interface (POSIX) threads since they are readily available. Regardless of the library used, the techniques presented here should be applicable.
We will use pointers to support a multithreaded application and callbacks. Threads are an involved topic. We assume you are familiar with basic thread concepts and terms, and therefore, we will not go into detail about how the POSIX thread functions work. The reader is referred to O’Reilly’s PThreads Programming for a more detailed discussion of this topic.
Sharing Pointers Between Threads
When two or more threads share data, the data can become corrupted. To illustrate this problem, we will implement a multi-threaded function that computes the dot product of two vectors. The multiple threads will simultaneously access two vectors and a sum field. When the threads complete, the sum field will hold the dot product value.
The dot product of two vectors is computed by summing the product
of the corresponding elements of each vector. We will use two data
structures in support of the operation. The first one, VectorInfo, contains information about the two
vectors being manipulated. It has pointers to the two vectors, the
sum field to hold the dot product,
and a length field to specify the
vector segment’s size used by the dot product function. The length field represents that portion of the
vector that a thread will process, not the entire length of a
vector:
typedefstruct{double*vectorA;double*vectorB;doublesum;intlength;}VectorInfo;
The second data structure, Product, contains a pointer to a VectorInfo instance and the beginning index
the dot Product vector will use. We
will create a new instance of this structure for each thread with a
different beginning index:
typedefstruct{VectorInfo*info;intbeginningIndex;}Product;
While each thread will be acting on both vectors at the same time,
they will be accessing different parts of the vector, so there is no
conflict there. Each thread will compute a sum for its section of the
vectors. However, this sum will need to be added to the sum field of the VectorInfo structure. Since multiple threads
may be accessing the sum field at the
same time, it is necessary to protect this data using a
mutex as declared below. A mutex allows only one
thread to access a protected variable at a time. The following declares
a mutex to protect the sum variable.
It is declared at a global level to allow multiple threads to access
it:
pthread_mutex_tmutexSum;
The dotProduct function is
shown below. When a thread is created, this function will be called.
Since we are using POSIX, it is necessary to declare this function as
returning void and being passed a pointer to void. This pointer passes
information to the function. We will pass an instance of the Product structure.
Within the function, variables are declared to hold the beginning
and ending indexes. The for loop performs the actual multiplication and
keeps a cumulative total in the total
variable. The last part of the function locks the mutex, adds total to sum, and then unlocks the mutex. While the
mutext is locked, no other threads can access the sum variable:
voiddotProduct(void*prod){Product*product=(Product*)prod;VectorInfo*vectorInfo=Product->info;intbeginningIndex=Product->beginningIndex;intendingIndex=beginningIndex+vectorInfo->length;doubletotal=0;for(inti=beginningIndex;i<endingIndex;i++){total+=(vectorInfo->vectorA[i]*vectorInfo->vectorB[i]);}pthread_mutex_lock(&mutexSum);vectorInfo->sum+=total;pthread_mutex_unlock(&mutexSum);pthread_exit((void*)0);}
The code to create the threads is shown below. Two simple vectors
are declared along with an instance of VectorInfo. Each vector holds 16 elements. The
length field is set to 4:
#define NUM_THREADS 4voidthreadExample(){VectorInfovectorInfo;doublevectorA[]={1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0};doublevectorB[]={1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0};doublesum;vectorInfo.vectorA=vectorA;vectorInfo.vectorB=vectorB;vectorInfo.length=4;
A four-element array of threads is created next, along with code to initialize the mutex and an attribute field for the thread:
pthread_tthreads[NUM_THREADS];void*status;pthread_attr_tattr;pthread_mutex_init(&mutexSum,NULL);pthread_attr_init(&attr);pthread_attr_setdetachstate(&attr,PTHREAD_CREATE_JOINABLE);intreturnValue;intthreadNumber;
With each for loop iteration, a new instance of the Product structure is created. It is assigned
the address of vectorInfo and a
unique index based on threadNumber.
The threads are then created:
for(threadNumber=0;threadNumber<NUM_THREADS;threadNumber++){Product*product=(Product*)malloc(sizeof(Product));product->beginningIndex=threadNumber*4;product->info=&vectorInfo;returnValue=pthread_create(&threads[threadNumber],&attr,dotProduct,(void*)(void*)(product));if(returnValue){printf("ERROR; Unable to create thread: %d",returnValue);exit(-1);}}
After the for loop, the thread attribute and
mutex variables are destroyed. The for loop ensures
the program will wait until all four threads have completed. The dot
product is then displayed. For the above vectors, the product is
1496:
pthread_attr_destroy(&attr);for(inti=0;i<NUM_THREADS;i++){pthread_join(threads[i],&status);}pthread_mutex_destroy(&mutexSum);printf("Dot Product sum: %lf",vectorInfo.sum);pthread_exit(NULL);}
Using Function Pointers to Support Callbacks
We previously used a callback function in the sort function developed in Chapter 5. Since the sort example does not use multiple threads, some programmers do not call this a callback function. A more widely accepted definition of a callback is when an event in one thread results in the invocation, or callback, of a function in another thread. One thread is passed a function pointer to a callback function. An event in the function can trigger a call to the callback function. This approach is useful in GUI applications to handle user thread events.
We will illustrate this approach using a function to compute the
factorial of a number. The function will callback a second function when
the factorial has been computed. Information regarding the factorial is
encapsulated in a FactorialData structure and is passed
between the functions. This structure and the factorial function are
shown below. The data consists of the factorial number, the results, and
a function pointer for the callback. The factorial function uses this data to compute
the factorial, store the answer in the result field, call the callback function, and
then terminate the thread:
typedefstruct_factorialData{intnumber;intresult;void(*callBack)(struct_factorialData*);}FactorialData;voidfactorial(void*args){FactorialData*factorialData=(FactorialData*)args;void(*callBack)(FactorialData*);// Function prototypeintnumber=factorialData->number;callBack=factorialData->callBack;intnum=1;for(inti=1;i<=number;i++){num*=i;}factorialData->result=num;callBack(factorialData);pthread_exit(NULL);}
The thread is created in a startThread function as shown below. The
thread executes the factorial
function and passes it factorial data:
voidstartThread(FactorialData*data){pthread_tthread_id;intthread=pthread_create(&thread_id,NULL,factorial,(void*)data);}
The callback function simply displays the factorial results:
voidcallBackFunction(FactorialData*factorialData){printf("Factorial is %d",factorialData->result);}
The factorial data is initialized and the startThread function is called as shown below.
The Sleep function provides time for
all of the threads to terminate properly:
FactorialData*data=(FactorialData*)malloc(sizeof(FactorialData));if(!data){printf("Failed to allocate memory");return;}data->number=5;data->callBack=callBackFunction;startThread(data);Sleep(2000);
When this is executed, the output will be as follows:
Factorial is 120
Instead of sleeping, the program can perform other tasks. The program does not have to wait for the thread to complete.
Object-Oriented Techniques
C is not known for its support of object-oriented programming. However, you can use C to encapsulate data using an opaque pointer and to support a certain level of polymorphic behavior. By hiding a data structure’s implementation and its supporting functions, the user does not need to know how the structure is implemented. Hiding this information will reduce what the user needs to know and thus reduce the application’s complexity level. In addition, the user will not be tempted to take advantage of the structure’s internal details, potentially causing later problems if the data structure’s implementation changes.
Polymorphic behavior helps make an application more maintainable. A polymorphic function behavior depends on the object it is executing against. This means we can add functionality to an application more easily.
Creating and Using an Opaque Pointer
An opaque pointer can be used to effect data encapsulation in C. One approach declares a structure without any implementation details in a header file. Functions are then defined to work with a specific implementation of the data structure in an implementation file. A user of the data structure will see the declaration and the functions’ prototypes. However, the implementation is hidden (in the .c/.obj file).
Only the information needed to use the data structure is made visible to the user. If too much internal information is made available, the user may incorporate this information and become dependent on it. Should the internal structure change, then it may break the user’s code.
We will develop a linked list to demonstrate an opaque pointer. The user will use one function to obtain a pointer to a linked list. This pointer can then be used to add and remove information from the linked list. The details of the linked list’s internal structure and its supporting function are not available to the user. The only aspects of this structure are provided through a header file, as shown below:
//link.htypedefvoid*Data;typedefstruct_linkedListLinkedList;LinkedList*getLinkedListInstance();voidremoveLinkedListInstance(LinkedList*list);voidaddNode(LinkedList*,Data);DataremoveNode(LinkedList*);
Data is declared as a pointer to void. This allows the
implementation to handle any type of data. The type definition for
LinkedList identifies a structure
called _linkedList. The definition of
this structure is hidden from the user in its implementation
file.
Four methods are provided to permit the use of the linked list.
The user will begin by obtaining a LinkedList’s instance using the getLinkedListInstance function. Once the
linked list is no longer needed, the removeLinkedListInstance function should be
called. Passing linked list pointers allows the functions to work with
one or more linked lists.
To add data to the linked list, the addNode function is used. It is passed the
linked list to use and a pointer to the data to add to the linked list.
The removeNode method returns the
data found at the head of the linked list.
The linked list’s implementation is found in a separate file
called link.c. The first part of
the implementation, as shown below, declares variables to hold the
user’s data and to connect to the next node in the linked list. This is
followed by the _linkedList
structure’s definition. In this simple linked list, only a head pointer
is used:
// link.c#include <stdlib.h>#include "link.h"typedefstruct_node{Data*data;struct_node*next;}Node;struct_linkedList{Node*head;};
The second part of the implementation file contains implementations of the linked list’s four supporting functions. The first function returns an instance of the linked list:
LinkedList*getLinkedListInstance(){LinkedList*list=(LinkedList*)malloc(sizeof(LinkedList));list->head=NULL;returnlist;}
The removeLinkedListInstance
function’s implementation follows. It will free each node in the linked
list, if any, and then free the list itself. This implementation can
result in a memory leak if the data referenced by the node contains
pointers. One solution is to pass a function to deallocate the members
of the data:
voidremoveLinkedListInstance(LinkedList*list){Node*tmp=list->head;while(tmp!=NULL){free(tmp->data);// Potential memory leak!Node*current=tmp;tmp=tmp->next;free(current);}free(list);}
The addNode function adds the
data passed as the second parameter to the linked list specified by the
first parameter. Memory is allocated for the node, and the user’s data
is associated with the node. In this implementation, the linked list’s
nodes are always added to its head:
voidaddNode(LinkedList*list,Datadata){Node*node=(Node*)malloc(sizeof(Node));node->data=data;if(list->head==NULL){list->head=node;node->next=NULL;}else{node->next=list->head;list->head=node;}}
The removeNode function returns
the data associated with the first node in the linked list. The head
pointer is adjusted to point to the next node in the linked list. The
data is returned and the old head node is freed, releasing it back to
the heap.
Note
This approach eliminates the need for the user to remember to free nodes of the linked list, thus avoiding a memory leak. This is a significant advantage of hiding implementation details:
DataremoveNode(LinkedList*list){if(list->head==NULL){returnNULL;}else{Node*tmp=list->head;Data*data;list->head=list->head->next;data=tmp->data;free(tmp);returndata;}}
To demonstrate the use of this data structure, we will reuse the
Person structure and its functions
developed in Introduction. The following
sequence will add two people to a linked list and then remove them.
First, the getLinkedListInstance
function is invoked to obtain a
linked list. Next, instances of Person are created using the initializePerson function
and then added to the linked list using the addNode function. The displayPerson function displays the persons
returned by the removeNode functions.
The linked list is then freed:
#include "link.h";...LinkedList*list=getLinkedListInstance();Person*person=(Person*)malloc(sizeof(Person));initializePerson(person,"Peter","Underwood","Manager",36);addNode(list,person);person=(Person*)malloc(sizeof(Person));initializePerson(person,"Sue","Stevenson","Developer",28);addNode(list,person);person=removeNode(list);displayPerson(*person);person=removeNode(list);displayPerson(*person);removeLinkedListInstance(list);
There are a couple of interesting aspects of this approach. We had
to create an instance of the _linkedList structure in the list.c file. It needs to be created there
because the sizeof operator cannot be
used without a complete structure declaration. For example, if we had
tried to allocate memory for this structure in the main function, as
follows, we would get a syntax error:
LinkedList*list=(LinkedList*)malloc(sizeof(LinkedList));
The syntax error generated will be similar to the following:
error: invalid application of ‘sizeof’ to incomplete type ‘LinkedList’
The type is incomplete because the compiler has no insight into
the actual definition as found in the list.c file. All it sees is the _linkedList structure’s type definition. It
does not see the structure’s implementation details.
The user’s inability to see and potentially use the linked list’s internal structure is restricted. Any changes to the structure are hidden from the user.
Only the signatures of the four supporting functions are visible to the user. Otherwise, the user is unable to use knowledge of their implementation or to modify them. The linked list structure and its supporting functions are encapsulated, reducing the burden on the user.
Polymorphism in C
Polymorphism in an object-oriented language such as C++ is based on
inheritance between a base and a derived class. Since C does not support
inheritance we need to simulate inheritance between structures. We will
define and use two structures to illustrate polymorphic behavior. A
Shape structure will represent a base
“class” and a Rectangle structure will be derived from
the base Shape.
The structure’s variable allocation order has a large impact on how this technique works. When an instance of a derived class/structure is created, the base class/structure’s variables are allocated first, followed by the derived class/structure’s variables. As we will see, we also need to account for the functions we plan to override.
Note
Understanding how memory is allocated for objects instantiated from a class is key to understanding how inheritance and polymorphism work in an object-oriented language. The same is true when we use this technique in C.
Let’s start with the Shape
structure’s definition as shown below. First, we allocate a structure to
hold the function pointers for the structure. Next, integers are
declared for an x and a y position:
typedefstruct_shape{vFunctionsfunctions;// Base variablesintx;inty;}Shape;
The vFunction structure and its
supporting declarations are defined below. When a function is executed
against a class/structure, its behavior will depend on what it is
executing against. For example, when a display function is executed
against a Shape, then a Shape should be displayed. When it is executed
against a Rectangle, then a Rectangle should be displayed. In an
object-oriented programming language this is typically achieved using a
Virtual Table or VTable. The vFunction structure is intended to serve in
this capacity:
typedefvoid(*fptrSet)(void*,int);typedefint(*fptrGet)(void*);typedefvoid(*fptrDisplay)();typedefstruct_functions{// FunctionsfptrSetsetX;fptrGetgetX;fptrSetsetY;fptrGetgetY;fptrDisplaydisplay;}vFunctions;
This structure consists of a series of function pointers. The
fptrSet and fptrGet function pointers define the typical
getter and setter functions for integer type data. In this case, they
are used for getting and setting the x and y
values for a Shape or Rectangle. The fptrDisplay function pointer defines a
function that is passed void and
returns void. We will use the display
function to illustrate polymorphic behavior.
The Shape structure has four
functions designed to work with it, as shown below. Their
implementations are straightforward. To keep this example simple, in the
display function, we simply print out
the string “Shape.” We pass the Shape
instance to these functions as the first argument. This allows these
functions to work with more than one instance of a Shape:
voidshapeDisplay(Shape*shape){printf("Shape");}voidshapeSetX(Shape*shape,intx){shape->x=x;}voidshapeSetY(Shape*shape,inty){shape->y=y;}intshapeGetX(Shape*shape){returnshape->x;}intshapeGetY(Shape*shape){returnshape->y;}
To assist in the creation of a Shape instance, we have provided a getShapeInstance function. It allocates memory
for the object and the object’s functions are assigned:
Shape*getShapeInstance(){Shape*shape=(Shape*)malloc(sizeof(Shape));shape->functions.display=shapeDisplay;shape->functions.setX=shapeSetX;shape->functions.getX=shapeGetX;shape->functions.setY=shapeSetY;shape->functions.getY=shapeGetY;shape->x=100;shape->y=100;returnshape;}
The following sequence demonstrates these functions:
Shape*sptr=getShapeInstance();sptr->functions.setX(sptr,35);sptr->functions.display();printf("%d",sptr->functions.getX(sptr));
The output of this sequence is:
Shape 35
This may seem to be a lot of effort just to work with a Shape structure. We can see the real power of
this approach once we create a structure derived from Shape: Rectangle. This structure is shown
below:
typedefstruct_rectangle{Shapebase;intwidth;intheight;}Rectangle;
The memory allocated for the Rectangle structure’s first field is the same
as the memory allocated for a Shape
structure. This is illustrated in Figure 8-5. In addition, we
have added two new fields, width and
height, to represent a rectangle’s
characteristics.
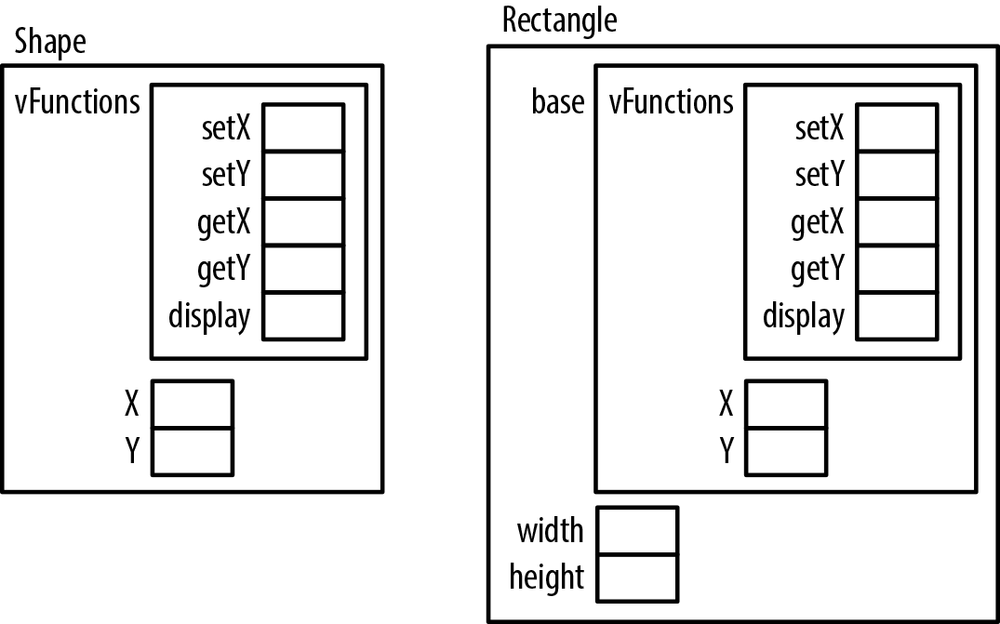
Rectangle, like Shape, needs some functions associated with
it. These are declared below. They are similar to those associated with
the Shape structure, except that they
use the Rectangle’s base
field:
voidrectangleSetX(Rectangle*rectangle,intx){rectangle->base.x=x;}voidrectangleSetY(Rectangle*rectangle,inty){rectangle->base.y;}intrectangleGetX(Rectangle*rectangle){returnrectangle->base.x;}intrectangleGetY(Rectangle*rectangle){returnrectangle->base.y;}voidrectangleDisplay(){printf("Rectangle");}
The getRectangleInstance
function returns an instance of a Rectangle structure as follows:
Rectangle*getRectangleInstance(){Rectangle*rectangle=(Rectangle*)malloc(sizeof(Rectangle));rectangle->base.functions.display=rectangleDisplay;rectangle->base.functions.setX=rectangleSetX;rectangle->base.functions.getX=rectangleGetX;rectangle->base.functions.setY=rectangleSetY;rectangle->base.functions.getY=rectangleGetY;rectangle->base.x=200;rectangle->base.y=200;rectangle->height=300;rectangle->width=500;returnrectangle;}
The following illustrates the use of this structure:
Rectangle*rptr=getRectangleInstance();rptr->base.functions.setX(rptr,35);rptr->base.functions.display();printf("%d",rptr->base.functions.getX(rptr));
The output of this sequence is:
Rectangle 35
Now let’s create an array of Shape pointers and initialize them as follows.
When we assign a Rectangle to
shapes[1], we do not have to cast it
as a (Shape*). However, we will get a
warning if we don’t:
Shape*shapes[3];shapes[0]=getShapeInstance();shapes[0]->functions.setX(shapes[0],35);shapes[1]=getRectangleInstance();shapes[1]->functions.setX(shapes[1],45);shapes[2]=getShapeInstance();shapes[2]->functions.setX(shapes[2],55);for(inti=0;i<3;i++){shapes[i]->functions.display();printf("%d",shapes[i]->functions.getX(shapes[i]));}
When this sequence is executed, we get the following output:
Shape 35 Rectangle 45 Shape 55
While we created an array of Shape pointers, we created a Rectangle and assigned it to the array’s
second element. When we displayed the element in the for loop, it used
the Rectangle’s function behavior and
not the Shape’s. This is an example
of polymorphic behavior. The display
function depends on the structure it is executing against.
Since we are accessing it as a Shape, we should not try to access its width
or height using shapes[i] since the
element may or may not reference a Rectangle. If we did, then we could be
accessing memory in other shapes that do not represent width or height
information, yielding unpredictable results.
We can now add a second structure derived from Shape, such as a Circle, and then add it to the array without
extensive modification of the code. We also need to create functions for
the structure.
If we added another function to the base structure Shape, such as getArea, we could implement a unique getArea function for each class. Within a
loop, we could easily add up the sum of all of the Shape and Shape-derived structures without having to
first determine what type of Shape we
are working with. If the Shape’s
implementation of getArea is
sufficient, then we do not need to add one for the other structures.This
makes it easy to maintain and expand an application.
Summary
In this chapter, we have explored several aspects of pointers. We started with a discussion of casting pointers. Examples illustrated how to use pointers to access memory and hardware ports. We also saw how pointers are used to determine the endianness of a machine.
Aliasing and the restrict keyword
were introduced. Aliasing occurs when two pointers reference the same
object. Compilers will assume that pointers may be aliased. However, this
can result in inefficient code generation. The restrict keyword allows the compiler to perform
better optimization.
We saw how pointers can be used with threads and learned about the need to protect data shared through pointers. In addition, we examined techniques to effect callbacks between threads using function pointers.
In the last section, we examined opaque pointers and polymorphic behavior. Opaque pointers enable C to hide data from a user. Polymorphism can be incorporated into a program to make it more maintainable.