
![]()
Data Storage, Logging, and Recovery
This chapter discusses how In-Memory OLTP stores the data from durable memory-optimized tables on disk. It illustrates the concept of checkpoint file pairs used by SQL Server to persist the data, provides an overview of checkpoint process in In-Memory OLTP, and discusses recovery of memory-optimized data. Finally, this chapter demonstrates how In-Memory OLTP logs the data in a transaction log and why In-Memory OLTP logging is more efficient compared to on-disk tables.
Data Storage
The data from durable memory-optimized tables is stored separately from on-disk tables. SQL Server uses a streaming mechanism to store it, which is based on FILESTREAM technology. In-Memory OLTP and FILESTREAM, however, store data separately from each other and you should have two separate filegroups: one for In-Memory OLTP and another for FILESTREAM data when the database uses both technologies.
There is a conceptual difference between how on-disk and memory-optimized data are stored. On-disk tables store the single, most recent version of the row. Multiple updates of the row change the same row object multiple times. Deletion of the row removes it from the database. Finally, it is always possible to locate a data row in a data file when needed.
In-Memory OLTP uses a completely different approach and persists multiple versions of the row on disk. Multiple updates of the data row generate multiple row objects, each of which has a different lifetime. SQL Server appends them to binary files stored in the In-Memory OLTP filegroup, which are called checkpoint file pairs (CFP).
It is impossible to predict where a data row is stored in checkpoint file pairs. Nor are there use cases for such an operation. The only purposes these files serve is to provide data durability and improve the performance of loading data into memory on database startup.
As you can guess by the name, each checkpoint file pair consists of two files: a data file and a delta file. Each CFP covers operations for a range of Global Transaction Timestamp values, logging operations on the rows that have BeginTs in this range. Every time you insert a row, it is saved into a data file. Every time you delete a row, the information about the deleted row is saved into a delta file. An update generates two operations, INSERT and DELETE, and it saves this information to both files. Figure 8-1 provides a high-level overview of the structure of checkpoint file pairs.

Figure 8-1. Data in checkpoint files
Figure 8-2 shows an example of a database with six check point file pairs in the different states. The vertical rectangles with a solid fill represent data files. The rectangles with a dotted fill represent delta files. This is just an illustration. In reality, every database will have at least eight checkpoint file pairs in the various states, which we will cover in detail shortly.

Figure 8-2. A database with multiple checkpoint file pairs
Internally, SQL Server stores checkpoint file pair metadata in an 8,192 slot array. Even though, in theory, it allows you to store up to 8,192 * 128MB = 1TB of data, Microsoft does not recommend nor support configurations with more than 256GB of data stored in durable memory-optimized tables. There is no restriction on the amount of data stored in non-durable memory-optimized tables.
Using a separate delta file to log deletions allows SQL Server to avoid modifications in data files and random I/O in cases when rows are deleted. Both data and delta files are append-only. Moreover, when files are closed (again, more on this shortly), they become read-only.
Checkpoint File Pairs States
Each checkpoint file pair can be in one of several states during its lifetime, as illustrated in Figure 8-3.
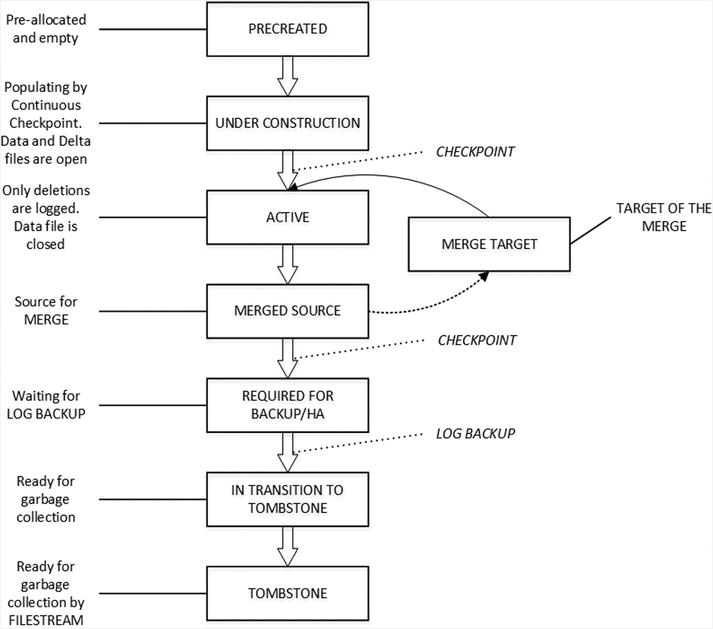
Figure 8-3. Checkpoint file pair states
Let’s look at all of these states in more detail.
PRECREATED CFP State
When you create the first memory-optimized table in the database, SQL Server generates the set of checkpoint file pairs. Those files are empty and they are created to minimize wait time when new files are needed.
The total number of new files is based on the storage and hardware configuration. SQL Server creates a separate checkpoint file pair per scheduler (logical CPU) with a minimum of eight CFPs. The initial size of the files is based on the amount of server memory, as shown in Table 8-1.
Table 8-1. Initial Size of Checkpoint Files
Server Memory | Data File Size | Delta File Size |
|---|---|---|
Less than 16GB | 16MB | 1MB |
16GB or more | 128MB | 8MB |
UNDER CONSTRUCTION CFP State and CHECKPOINT Process
As you already know, SQL Server uses the transaction log to persist information about data modifications in the database. Transaction log records can be used to reconstruct any data changes in the event of an unexpected shutdown or crash; however, that process can be very time-consuming if a large number of log records need to be replayed.
SQL Server uses checkpoints to mitigate that problem. Even though on-disk and In-Memory OLTP checkpoint processes are independent from each other, they do the same thing: persist the data changes on disk, reducing database recovery time. The last checkpoint identifies up to which point the data changes have been persisted and from which log records need to be replayed.
With on-disk tables, the frequency of checkpoint operations depends on the server-level recovery interval and database-level TARGET_RECOVERY_TIME settings. While such an approach helps SQL Server to improve write performance by batching multiple random I/O writes together, it leads to spikes in I/O activity at the time when checkpoint occurs.
In contrast, In-Memory OLTP implements continuous checkpoints. It continuously scans the transaction log, streaming and appending the changes to checkpoint file pairs in the UNDER CONSTRUCTION state. The new versions of the rows are appended to the data files and deletions are appended to delta files. The continuous checkpoint also appends information about deletions to CFPs in the ACTIVE state, which we will discuss shortly.
As mentioned, the rows in checkpoint file pairs are never updated. Instead, the new row version is appended to the data file and the old version is marked as deleted in the delta files. This leads to sequential streaming I/O, which is significantly faster compared to random I/O even in the case of SSD drives.
ACTIVE CFP State
The continuous checkpoint process continuously persists the data from memory-optimized tables on disk. However, there is still a checkpoint event, which performs several actions.
- It scans the remaining (unscanned) portion of the transaction log and hardens all remaining log records to checkpoint file pairs. You can consider it as the continuous checkpoint catching up and processing the remaining part of the log up to the checkpoint event.
- It transitions all UNDER CONSTRACTION CFPs to the ACTIVE state.
- It creates a checkpoint inventory, which contains the information about all files from the previous checkpoint along with any files added by the current checkpoint. The checkpoint inventory and the Global Transaction Timestamp are hardened in the transaction log and available to SQL Server during the recovery process. The combination of ACTIVE CFPs and the tail of the log allow SQL Server to recover the data from memory-optimized tables if needed.
The checkpoint event changes the state of all UNDER CONSTRUCTION checkpoint file pairs to ACTIVE. SQL Server does not stream new data into ACTIVE CFPs so data files become read-only; however, it still uses the delta files storing the information about the DELETE and UPDATE operations that occurred against the versions of the rows from the corresponding data files.
In the case of memory-optimized tables, a checkpoint is invoked either manually with the CHECKPOINT command, or automatically when the transaction log has grown more than 512MB since the last checkpoint. It is worth mentioning that SQL Server does not differentiate log activity between on-disk and memory-optimized tables when using this 512MB threshold. It is entirely possible that a checkpoint is triggered even when there were no transactions against memory-optimized tables.
Typically, the combined size of the ACTIVE checkpoint file pairs on disk is about twice the size of the durable memory-optimized tables in memory. However, in some cases, SQL Server may require more space to store memory-optimized data.
MERGE TARGET and MERGED SOURCE CFP States and Merge Process
Overtime, as data modifications progress, the percent of deleted rows in the ACTIVE checkpoint file pairs increases. This condition adds unnecessary storage overhead and slows down the data loading process during recovery. SQL Server addresses this situation with a process called merge.
A background task called the Merge Policy Evaluator periodically analyzes if adjacent ACTIVE CFPs can be merged together in a way that active, non-deleted rows from the merged data files would fit into the new 16MB or 128MB data file. When it happens, SQL Server creates the new CFP in a MERGE TARGET state and populates it with the data from the multiple ACTIVE CFPs, filtering out deleted rows.
Even though the Merge Policy Evaluator can identify multiple possible merges, every CFP can participate only in one of them. Table 8-2 shows several examples of the possible merges.
Table 8-2. Merge Examples
Adjacent Source Files (% Full) | Merge Results |
|---|---|
CFP0(40%), CFP1(45%), CFP2(60%) | CFP0 + CFP1 (85%) |
CFP0(10%), CFP1(15%), CFP2(70%), CFP3(10%) | CFP0 + CFP1 + CFP2 (95%) |
CFP0(55%), CFP1(50%) | No Merge is done |
In most cases, you can rely on the automatic merge process. However, you can trigger a manual merge using the sys.sp_xtp_merge_checkpoint_files stored procedure. You will see such an example in Appendix C.
Once the merge process is complete, the next checkpoint event transitions the MERGE TARGET CFP to ACTIVE and former ACTIVE CFPs to MERGED SOURCE states.
REQUIRED FOR BACKUP/HA, IN TRANSITION TO TOMBSTONE, and TOMBSTONE CFP States
After the next checkpoint event occurs, the MERGED SOURCE CFPs are no longer needed for database recovery. Former MERGE TARGET and now ACTIVE CFPs can be used for this purpose. However, those CFPs are still needed if you want to restore the database from a backup, so they are switched to the REQUIRED FOR BACKUP/HA state.
The checkpoint file pairs stay in that state until the log truncation point passed their LSNs. In FULL recovery model that means that a log backup has been taken, log records were sent to secondary nodes, and other processes that read transaction log have not fallen behind. Obviously, in a SIMPLE recovery model, log backup is not required and the log truncation point is controlled by checkpoints.
Once it happens, CFPs are transitioned to the IN TRANSITION TO TOMBSTONE state, where they become eligible for garbage collection. Another In-Memory OLTP background thread switches them to the TOMBSTONE state, which they stay in until they are deallocated by the FILESTREAM garbage collector thread.
![]() Note In reality, it is possible that multiple log backups are required for the CFP to switch to the IN TRANSITION TO TOMBSTONE state.
Note In reality, it is possible that multiple log backups are required for the CFP to switch to the IN TRANSITION TO TOMBSTONE state.
As with the merge process, in most cases you can rely on automatic garbage collection in both In-Memory OLTP and FILESTREAM; however, you can force garbage collection using the sys.sp_xtp_checkpoint_force_garbage_collection and sys.sp_filestream_force_garbage_collection stored procedures. You can see these procedures in action in Appendix C.
![]() Note You can analyze the state of a checkpoint file pair using the sys.dm_db_xtp_checkpoint_files DMV. Appendix C talks about this view in greater depth and shows how CFP states change through their lifetime.
Note You can analyze the state of a checkpoint file pair using the sys.dm_db_xtp_checkpoint_files DMV. Appendix C talks about this view in greater depth and shows how CFP states change through their lifetime.
Transaction Logging
As mentioned in the previous chapter, transaction logging in In-Memory OLTP is more efficient compared to Storage Engine. Both engines share the same transaction log and perform write-ahead logging (WAL); however, the log records format and algorithms are very different.
With on-disk tables, SQL Server generates transaction log records on a per-index basis. For example, when you insert a single row into a table with clustered and nonclustered indexes, it will log insert operations in every individual index separately. Moreover, it will log internal operations, such as extent and page allocations, page splits, and a few others.
All log records are saved in a transaction log and hardened on disk pretty much synchronously at the time when they were created. Even though every database has a cache called Log Buffer to batch log writes, that cache is very small, about 60KB. Moreover, some operations, such as COMMIT and CHECKPOINT, flush that cache whether it is full or not.
Finally, SQL Server has to include before-update (UNDO) and after-update (REDO) versions of the row to the log records. Checkpoint process is asynchronous and it does not check the state of transaction that modified the page. It is entirely possible for the checkpoint to save the dirty data pages from uncommitted transactions and the UNDO part of the log records are required to roll back the changes.
Transaction logging in In-Memory OLTP addresses these inefficiencies. The first major difference is that In-Memory OLTP generates and saves log records at the time of the transaction COMMIT rather than during each data row modification. Therefore, rolled-back transactions do not generate any log activity.
The format of a log record is also different. Log records do not include any UNDO information. Dirty data from uncommitted transactions will never materialize on disk and, therefore, In-Memory OLTP log data does not need to support the UNDO stage of crash recovery nor log uncommitted changes.
In-Memory OLTP generates log records based on the transactions write set. All data modifications are combined together in one or very few log records based on the write set and inserted rows’ size.
Let’s examine this behavior and run the code shown in Listing 8-1. It starts a transaction and inserts 500 rows into a memory-optimized table. Then it examines the content of the transaction log using the undocumented sys.fn_dblog system function.
Figure 8-4 illustrates the content of the transaction log. You can see the single transaction record for the In-Memory OLTP transaction.

Figure 8-4. Transaction log content after the In-Memory OLTP transaction
Let’s repeat this test with an on-disk table of a similar structure. Listing 8-2 shows the code that creates a table and populates it with data.
As you can see in Figure 8-5, the same transaction generated more than 1,000 log records.

Figure 8-5. Transaction log content after on-disk table modification
You can use another undocumented function, sys.fn_dblog_xtp, to examine the logical content of an In-Memory OLTP log record. Listing 8-3 shows the code that utilizes this function and Figure 8-6 shows the output of that code. You should use the LSN of the LSN_HK log record from the Listing 8-2 output as the parameter of the function.
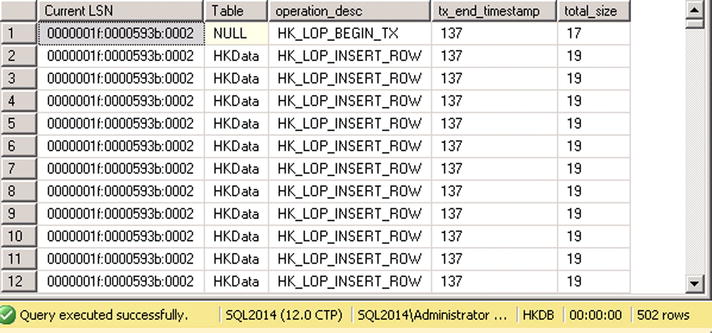
Figure 8-6. In-Memory OLTP transaction log record details
Finally, it is worth stating again that any data modification on non-durable tables (DURABILITY=SCHEMA_ONLY) is not logged in the transaction log nor is its data persisted on disk.
Recovery
During the recovery stage, SQL Server locates the most recent checkpoint inventory and passes it to the In-Memory OLTP Engine, which starts recovering memory-optimized data in parallel with on-disk tables. The In-Memory OLTP Engine obtains the list of all ACTIVE checkpoint file pairs and starts loading data from them. It loads only the non-deleted versions of rows using delta files as the filter. It checks that a row from a data file is not deleted and is not referenced in the delta files. Based on the results of this check, a row is either loaded to memory or discarded.
The process of loading data is highly scalable. SQL Server creates one thread per logical CPU, and each thread processes an individual checkpoint file pair. In a large number of cases, the performance of the I/O subsystem becomes the limiting factor in data-loading performance.
As the opposite of on-disk tables, indexes on memory-optimized tables are not persisted. As you remember, indexes in In-Memory OLTP are just the memory pointers, and the memory addresses of the rows change after they are reloaded into the memory. Therefore, indexes must be recreated during the recovery stage.
Figure 8-7 illustrates the data-loading process.

Figure 8-7. Loading data to memory
After the data from CFPs has been loaded, SQL Server completes the recovery by applying the changes from the tail of the transaction log, bringing the database back to the state as of the time of crash or shut down. As you already know, In-Memory OLTP does not log uncommitted changes and, therefore, no UNDO stage is required during the recovery.
Summary
The data from durable memory-optimized tables is placed into a separate file group utilizing FILESTREAM technology under the hood. The data is stored in the set of checkpoint file pairs. Each pair consists of two files, data and delta. Data files store the row version data. Delta files store the information about deleted rows.
The data in checkpoint file pairs is never updated. A DELETE operation generates the new entry in delta files. An UPDATE operation stores the new version of the row in the data file, marking the old version as deleted in the delta file. SQL Server utilizes the sequential streaming API to write data to those files without any random I/O involved.
Every checkpoint file pair covers a particular interval of Global Transaction Timestamps and goes through a set of predefines states. SQL Server stores the new row data in CFPs in the UNDER CONSTRUCTION state. These CFPs are converted to the ACTIVE state at a checkpoint event. Data files of ACTIVE CFPs are closed and they do not accept the new row versions; however, they still log the information about deletions in the delta files.
SQL Server merges the data from the ACTIVE checkpoint file pairs, filtering out deleted rows. After the merge is completed and the source CFPs are backed up, SQL Server marks them for garbage collection and deallocates them.
ACTIVE checkpoint file pairs are used during database recovery along with the tail of the log. The In-Memory OLTP recovery process is highly scalable and very fast. Indexes on memory-optimized tables are not persisted on disk and recreated when data is loaded into the memory.
Transaction logging in In-Memory OLTP is more efficient compared to on-disk tables. Transactions are logged at time of COMMIT based on the transaction write set. Log records are compact and contain information about multiple row-related operations.