
Monoliths and decoupled architectures
REST architectures
The GraphQL query language
In this chapter, we review traditional web applications, the classic MVC pattern based on views, models, and controllers.
We begin to outline use cases, benefits, and drawbacks of decoupled architectures. We explore the foundations of REST, look at how it compares to GraphQL, and learn that REST APIs are not only RESTful after all.
Monoliths and MVC
For at least two decades, traditional websites and applications all shared a common design based on the Model-View-Controller pattern, abbreviated MVC.
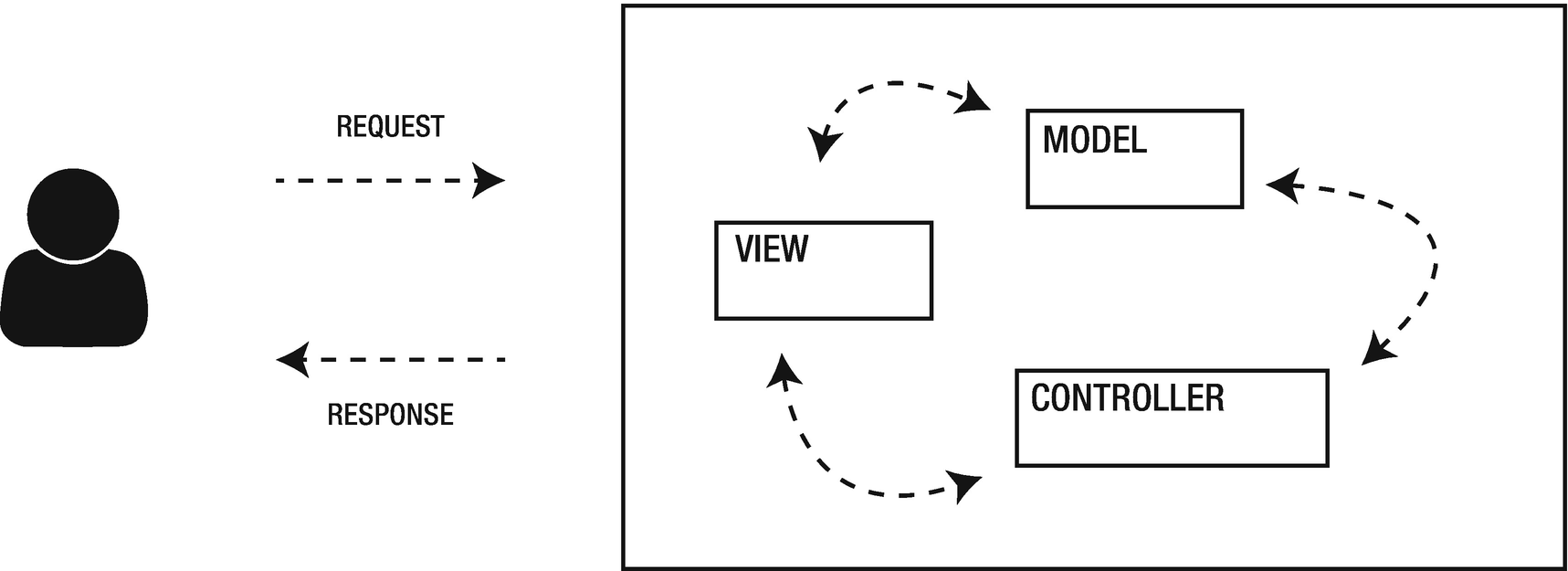
An MVC application responds to the user with a view, generated by a controller. The model layer supplies the data from the database
MVC has variations, like the Model-View-Template pattern employed by Django. In Django’s MVT, the data comes still from the database, but the view acts like a controller: it gets data from the database through the ORM and injects the result in a template, which is returned to the user. MVC and its variations are well and alive: all the most popular web frameworks like .NET core, Rails, Laravel, and Django itself employ this pattern with success. However, in recent times we are seeing the spread of decoupled applications based on a service-oriented architecture.
In this design, a RESTful or a GraphQL API exposes data for one or more JavaScript frontends, for a mobile application, or for another machine. Service-oriented and decoupled architectures are a broader category that encompasses the galaxy of microservices systems. Throughout the book, we refer to decoupled architectures in the context of web applications, mainly as systems with a REST API, or GraphQL on the backend, and a separated JavaScript/HTML frontend. Before focusing on REST APIs, let’s first unpack what’s behind a decoupled architecture.
What Makes a Decoupled Architecture?
A decoupled architecture is a system that abides to one of the most important rules in software engineering: separation of concerns.

A decoupled application with a REST API as a data source for a JavaScript/HTML frontend
As you will see later in the book, this separation between client and server, views and controllers, is not always strict, and depending on the decoupling style, the distinction becomes blurry. For example, we can have the REST API and the frontend living in two completely different environments (separate domains or different origins). In this case, the division is crystal clear. In some situations, when a full JavaScript frontend would not make sense, Django can still expose a REST or GraphQL API, with JavaScript embedded in a Django template talking to the endpoints.
To muddle things further, frameworks like Angular adopt the Model-View-Controller pattern even for structuring frontend code. In a single-page application, we can find the same MVC design, which replicates the backend structure. You can already guess that one of the disadvantages of a purely decoupled architecture is, to some extent, code duplication. Having defined what is a decoupled architecture, let’s now talk about its use cases.
Why and When to Decouple?
This isn’t a book about the JavaScript gold rush. In fact, you should weigh your options long before thinking about a full rewrite of your beloved Django monolith.
Machine-to-machine communication
Interactive dashboards with heavy JS-driven interactions
Static site generation
Mobile applications
With Django, you can build all sorts of things involving machine-to-machine communication. Think of an industrial application to collect data from sensors that can be later aggregated in all sorts of data reporting. Such dashboards can have a lot of JS-driven interactions. Another interesting application for decoupled architectures are content repositories . Monoliths like Django, CMS like Drupal, or blogging platforms like WordPress are good companions for static site generators. We explore this topic in detail later.
Constrained teams
Websites with little or no JS-driven interactions
Constrained devices
Content-heavy websites with search engine optimization in mind
As you will see in Chapter 7, frameworks like Next.js can help with search engine optimization for single-page apps by producing static HTML. Other examples of frameworks employing this technique are Gatsby and Prerenderer.
It’s easy to get overwhelmed by modern frontend development, especially if the team is small. One of the most serious hindrances when designing or building a decoupled architecture from scratch is the sheer amount of complexity lurking behind the surface of JavaScript tooling. In the next sections, we focus on REST and GraphQL, the two pillars of a decoupled architecture.
Hypermedia All the Things
The foundation for almost any decoupled frontend architecture is the REST architectural style .
HTTP Methods with the Corresponding Effect on a Given Resource Present on the Backend
Method | Effect | Idempotent |
|---|---|---|
POST | Create resource | No |
GET | Retrieve resource(s) | Yes |
PUT | Update resource | Yes |
DELETE | Delete resource | Yes |
PATCH | Partial update resource | No |
To refer to this set of HTTP methods we also use the term CRUD, which stands for Create, Read, Update, and Delete. As you can see from the table, some HTTP verbs are idempotent, meaning that the result of the operation is always stable. A GET request for example always returns the same data, no matter how many times we issue the command after the first request.
When creating a new resource with POST instead, we can send a request body alongside the request. Depending on the operation type, the API can respond with an HTTP status code, and with the newly created object. Common examples of HTTP response code are 200 OK and 201 Created, 202 Accepted. When things don’t go well, the API might respond with an error code. Common examples of HTTP error codes are 500 Internal Server Error, 403 Forbidden, and 401 Unauthorized.
Hypermedia as the engine: When requesting a resource, the response from the APIs must also include hyperlinks to related entities or to other actions.
Client-server separation: The consumer (JavaScript, a machine, or a generic client) and the Web API must be two separate entities.
Stateless: The communication between client and server should not use any data stored on the server.
Cacheable: The API should leverage HTTP caching as much as possible.
Uniform interface: The communication between client and server should use a representation of the resources involved, and a standard language for the communication.
It’s worth taking a quick detour to dive deeper into each of these rules.
Hypermedia as the Engine
In the original dissertation, this constraint is buried under the Uniform Interface section, but it’s crucial for understanding the real nature of REST APIs.
A JSON Response with Hyperlinked Relationships
A JSON Response with Pagination Links
Another interesting feature of the Django REST framework is the browsable API, a web interface for interacting with the REST API. All these features make Django REST framework Hypermedia APIs ready, which is the correct definition for these systems.
Client-Server Separation
The second constraint, client-server separation, is easily achievable.
A REST API can expose endpoints to which consumers can connect to retrieve, update, or delete data. In our case, consumers will be JavaScript frontends.
Stateless
A compliant REST API should be stateless.
Stateless means that during the communication between client and server, the request should not use any context data stored on the server. This doesn’t mean that we can’t interact with the resources exposed by the REST APIs. The constraint applies to session data, like session cookies or other means of identification stored on the server. This strict prescription urged engineers to find new solutions for API authentication. JSON Web Token, referred to as JWT later in the book, is a product of such research, which is not necessarily more secure than other methods, as you will see later.
Cacheable
A compliant REST API should take advantage of HTTP caching as much as possible.
An HTTP Response with Cache Headers
Another method for enabling HTTP caching involves the Last-Modified header. If the server sets this header, the client can in turn use If-Modified-Since or If-Unmodified-Since to check the resource’s freshness.
200 OK
301 Moved Permanently
404 Not Found
206 Partial Content
Moreover, responses with the Authorization header set aren’t cached by default, unless the Cache-Control header includes the public directive. Also, as you will see later, GraphQL operates mainly with POST requests, which aren’t cached by default.
Uniform Interface
Uniform interface is one of the most important rules of REST.
One of its tenets, representations, prescribes that the communication between client and server, for example to create a new resource on the backend, should carry the representation of the resource itself. What this means is that if I want to create a new resource on the backend, and I issue a POST request, I should provide a payload with the resource.
A POST Request
Here we use JSON as the media type, and a representation of the resource as the request body. Uniform interface refers also to the HTTP verbs used to drive the communication from the client to the server. When we talk to a REST API, we mainly use five methods: GET, POST, PUT, DELETE, and PATCH. These methods are also the uniform interface, that is, the common language we use for client-server communication. After reviewing REST principles, let’s now turn our attention to its alleged contender, GraphQL.
An Introduction to GraphQL
GraphQL appeared in 2015, proposed by Facebook, and marketed as a replacement for REST.
A JSON Response from a REST API
A GraphQL Query
A JSON Response from the Previous Query
A GraphQL Query over a POST Request
A GraphQL Mutation
A GraphQL Subscription
A Simple GraphQL Schema
Graphene, with its code-first approach to building GraphQL services
Ariadne, a schema-first GraphQL library
Strawberry, built on top of data classes, code-first, and with type hints
All these libraries have integrations with Django. The difference between a code-first approach and a schema-first approach to GraphQL is that the former promotes Python syntax as a first-class citizen for writing the schema. The latter instead uses a multi-line Python string to represent it. In Chapters 10 and 11, we work extensively with GraphQL in Django with Ariadne and Strawberry.
Summary
Monoliths are systems acting as a whole unit to serve HTML and data to the users
REST APIs are in reality Hypermedia APIs because they use HTTP as the communication medium, and hyperlinks for providing paths to related resources
JavaScript-first and single-page apps are not the perfect solution to every use case
GraphQL is a strong contender for REST
In the next chapter, we dive deep into the JavaScript ecosystem to see how it fits within Django.