In the past chapters, we have formed a foundation for machine learning approaches. These “traditional” machine learning methods have been used in academic research and industry applications for decades. However, the subject of focus in the new innovations in the past few years has been neural networks – the capability, the performance, and the versatility of various deep neural network architectures.
This and the next few chapters primarily focus on neural networks as well as deep neural network architectures, mainly the convolutional neural networks and the recurrent neural networks that are directly applicable in many situations. In this chapter, we will discuss how neural networks work, how are they applicable in so many different types of solutions, and how PyTorch can be used.
There are several software libraries and toolkits that have become popular in the past few years. Python has become the most popular choice for most of the projects that involve machine learning – and for deep learning, PyTorch is one of the competing tools whose popularity has been increasing in the recent past. We will limit ourselves to this library – though the API and the way of using the library might be different compared to the other tools, the ideas are still directly relevant and applicable.
In this chapter, we will begin with basics of perceptrons, which are the basic building block of neural networks. This will also involve basic mathematical operations that are required in constructing neural networks. We will then have a crisp introduction of PyTorch and look at the basic features. We will learn to do basic computations using PyTorch. Throughout this chapter and the next, you will be introduced to features of PyTorch based on their relevance.
Neural networks are interconnected nodes of computations that are at the heart of deep learning algorithms. The most basic element of neural networks is called a perceptron, which performs very basic vector arithmetic operations. Perceptrons can be combined together to depend on each other’s results for further computation and thus be arranged in layers of computing units. Such networks are called neural networks.
We will discuss more details about neural networks, starting with the basic unit, the perceptron, in the further sections.
Though the simplicity of design is the main source of power and popularity of neural networks, these computations can often grow too big and complex to program and manipulate using basic programming tools, which led to the rise of frameworks for neural network programming.
PyTorch is one of the most popular tools often applauded for being simple and more Pythonic – thus leading to easy learning and improved developer productivity. PyTorch is also at par, and, in some cases, faster than other popular deep learning libraries. The benefits are summarized by a highly cited AI scientist in his tweet1 (Figure 12-1).
Figure 12-1
Andrej Karpathy’s tweet about PyTorch. Andrej is presently leading AI and autopilot vision at Tesla
Installing PyTorch
One of the most preferred ways to install PyTorch is to use Anaconda distribution’s package manager tool – conda. If you do not have Anaconda installed, you may download the suitable package for your system at the Anaconda website.2Anaconda is a popular Python distribution that gives powerful environment management and package management capabilities. Once you have installed Anaconda, you can use this command:
This will instruct conda to install PyTorch and the required libraries, including cudatoolkit, which provides an environment for creating high-performance gpu-based programming.
Alternatively, you can install using Python’s package manager, pip.
pip3 install torch torchvision torchaudio
To explore more alternative ways to install, you can refer to the Getting Started3 page of PyTorch, which gives you more options to configure your installation depending on your system and requirements.
After installation, you can perform a simple test to verify that your PyTorch installation works as expected. Open Jupyter Notebook or Python Shell to import torch and verify the PyTorch version.
import torch
torch.__version__
Out: '1.9.1'
PyTorch Basics
In PyTorch, tensor is a term that refers to any generic multidimensional array. In practice, tensor establishes a multilinear relationship between the sets of algebraic objects related to a vector space. In PyTorch, tensor is the primary data structure that encodes the inputs, outputs, as well as the model parameters.
Creating a Tensor
Tensors are similar to Ndarrays in NumPy. You can create a tensor from a Python’s list or multidimensional lists of lists. You can also create a tensor from an existing NumPy array.
mylist = [1,2,3,4]
mytensor = torch.tensor(mylist)
mytensor
Out: tensor([1, 2, 3, 4])
As you might expect, you can also create a tensor from a NumPy array.
import numpy as np
myarr = np.array([[1,2],[3,4]])
mytensor_2 = torch.from_numpy(myarr)
mytensor_2
Out: tensor([[1, 2],
[3, 4]], dtype=torch.int32)
When you create a tensor from a NumPy array, it is not copied to a new memory location – but both the array and tensor share the same memory location. If you make any change in the tensor, it will be reflected in the original array from which it was created.
mytensor_2[1,1]=5
myarr
Out: tensor([[1, 2],
[3, 5]], dtype=torch.int32)
Inversely, you can also use mytensor_2.numpy() to return a NumPy array object that shares the same data. Just like NumPy Ndarrays, PyTorch tensors are also homogeneous; that is, all the elements in the tensor have same data type. There are other tensor creation methods similar to NumPy’s array creation methods. This is an example of creating a simple tensor.
torch.zeros((2,3))
Out: tensor([[0., 0., 0.],
[0., 0., 0.]])
This will create a tensor of shape 3x3 with all values as zeros. A similar function in NumPy is np.zeros(3,3). It returns an array of shape 3x3. Though the representation is similar, tensors are the primary unit of data representation in PyTorch. You can use a similar functions to create arrays of ones, or random values of user-defined size.
torch.ones((2,3))
Out: tensor([[1., 1., 1.],
[1., 1., 1.]])
torch.rand((2,3))
Out: tensor([[0.0279, 0.5261, 0.9984],
[0.7442, 0.3559, 0.3686]])
PyTorch also includes a method to create or initialize a tensor with properties (like shape) of another tensor.
torch.ones_like(mytensor_2)
Out: tensor([[1, 1],
[1, 1]], dtype=torch.int32)
Tensor Operations
PyTorch tensors support several operations in a similar manner as NumPy’s arrays – though the capabilities are more. Arithmetic operations with scalers are broadcasted, that is, applied to all the elements of the tensor. Matrix operations between tensors of compatible shapes are applied in a similar fashion.
myarr = np.array([[1.0,2.0],[3.0,4.0]])
tensor1 = torch.from_numpy(myarr)
tensor1+1
Out: tensor([[2., 3.],
[4., 5.]], dtype=torch.float64)
tensor1/ tensor1
Out: tensor([[1., 1.],
[1., 1.]], dtype=torch.float64)
tensor1.sin()
Out: tensor([[ 0.8415, 0.9093],
[ 0.1411, -0.7568]], dtype=torch.float64)
tensor1.cos()
Out: tensor([[ 0.5403, -0.4161],
[-0.9900, -0.6536]], dtype=torch.float64)
tensor1.sqrt()
Out: tensor([[1.0000, 1.4142],
[1.7321, 2.0000]], dtype=torch.float64)
The functions for describing the data can also be used in a similar manner:
print ("The 90-quantile is present at {}".format(tensor1.quantile(0.5)))
These operations give the following output:
Statistical Quantities:
Mean: 2.5,
Median: 2.0,
Minimum: 1.0,
Maximum: 4.0
The 90-quantile is present at 2.5
Similar to NumPy, PyTorch also provides operations like cat, hstack, vstack, etc., to join the tensors. Here are the examples:
tensor2 = torch.tensor([[5,6],[7,8]])
torch.cat([tensor1, tensor2], 0)
This method would concatenate the two tensors. The direction (or axis) of concatenation is provided as the second argument. 0 signifies that the tensors will be joined vertically, and 1 would signify that they will be joined horizontally.
tensor([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.]], dtype=torch.float64)
Other similar functions are hstack and vstack, which can also be used to join two or more tensors horizontally or vertically.
torch.hstack((tensor1,tensor2))
Out: tensor([[1., 2., 5., 6.],
[3., 4., 7., 8.]], dtype=torch.float64)
torch.vstack((tensor1,tensor2))
Out: tensor([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.]], dtype=torch.float64)
There’s a reshape function that changes the shape of the tensor. To convert the tensor into a single row with an arbitrary number of columns, we can use shape as (1,-1):
We will continue discussing more operations based on their use in the future sections and chapters.
Perceptron
Perceptron, shown in Figure 12-2, is the simplest form of neural network. It takes one or more quantities often describing features of a data item as input, performs a simple computation on it, and produces a single output. The simplest form of perceptron is a single-layer perceptron – it is easy to understand, quick to run, and simple to implement, though it can classify only linearly separable data.
Figure 12-2
A simple perceptron structure with constituent computations
As illustrated in Figure 12-2, perceptron applies a simple computation to predict the class label based on the input vector x, with features being represented as [x1, x2, x3 … xn], and a weight vector, with features being represented as [w1, w2, w3, … w]. We usually add an additional bias term that doesn’t affect the output based on the input as w0. To ease the computation, we add an input feature as x0, with its value being set as 1. Thus, the two vectors, x and w, lead to the final output based on a simple step function:
Here, x is the input vector with n+1 dimensions, w is the weight vector, and the objective of the learning process is to learn the best possible weights so that the error computed by comparing the results with the training labels is minimized.
To train the perceptron, we first initialize the weights with random values. We use the training dataset to find the predicted output based on the formula shown previously. Because the algorithm has not learned the right set of weights yet, the results may be far than we expected – thus leading to an error. To reduce the noise in next iterations, we apply the following update to the weights based on the current outputs:
Here, we have also added a step parameter, α, which controls how severely are the weights impacted. We iteratively repeat this process till a predetermined number of times (or till convergence) and hope to reach a good enough weight vector by the end, which may lead to a low error. To predict the output, we simply plug in the features x to the same computation.
The computation function we saw in the previous section is called a stepper function. In many cases, you might rather see sigmoid function, that is:
Let’s see how to program these first using basic Python and NumPy, and later we will use PyTorch to do the same.
Perceptron in Python
We will first create a simple separable dataset using Scikit-learn’s dataset module. You can use any other dataset that we have used before.
from sklearn import datasets
import matplotlib.pyplot as plt
X, y = datasets.make_blobs(n_samples=100,n_features=2, centers=2, random_state=42, shuffle=1)
These lines will create 100 rows of data with two features, which is divided into two major blobs. Let’s visualize it before building the perceptron.
fig = plt.figure(figsize=(10,8))
plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], 'b+')
plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], 'ro')
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
The data points are clearly visible as shown in Figure 12-3, and we deliberately chose this kind of randomly generated dataset to keep the classification boundary simple.
Figure 12-3
Simple dataset generated using make_blobs
We have X and y. Let’s create fit() and predict() methods from scratch. You know that weights are updated based on the predicted value of each data point at the current step. In the formula , we already know x and y; α is a hyperparameter that you can configure to set the steps, and w is the set of weights that we will learn in this process.
Because our dataset contains two features, we need three (2 + 1 for the bias term) weights in the weight vector. Let’s implement the predict function first.
def predict(X, weight):
return np.where(np.dot(X, weight) > 0.0, 1, 0)
This implements the formula for by first computing the product between the input data and weight and then applies the case to compare if the resulting product is larger than 0. This function can act as the prediction function as well as help us find the right value to update the weights.
Remember there are three weights, though the dataset still has two columns. We will add a column to compensate for the bias, thus leading to a shape of 100x3. We will initialize the weights to random values.
X = np.concatenate( (np.ones((X.shape[0],1)), X), axis=1)
weight = np.random.random(X.shape[1])
After initialization, we will run an iterative process till a predetermined number of iterations (or epochs) and, within each iteration, process each point and update the weights. The fit() method should now look like the following:
def fit(X, y, niter=100, alpha=0.1):
X = np.concatenate( (np.ones((X.shape[0],1)), X), axis=1)
weight = np.random.random(X.shape[1])
for i in range(niter):
err = 0
for xi, target in zip(X, y):
weight += alpha * (target - predict(xi, weight)) * xi
return weight
We have not structured the code as a class which might store the weights internally – but have to return it, which can be supplied to the predict method. To learn the weights, we can now call
W is a weight vector with three values representing the bias and corresponding coefficient for each feature. We can use the predict() method to predict the output. Let’s pick some random elements from X to compare how our perceptron labels them:
Now let’s call the predict method and compare the results with the actual values.
print (predict(X_test, w))
print (y[random_elements])
Out:
[0 0 1 0 0]
[0 0 1 0 0]
The results look good because the dataset is too simple – however, remember that a simple perceptron doesn’t perform well in cases where decision boundaries are not so clear. We will discuss how to combine such simple computation units to create a more complex neural network in the next chapters.
Artificial Neural Networks
A simple perceptron learns how important each feature of the dataset is through a single threshold logic unit, when it attempts to combine the weighted sum of features and pass it to a function. We used a simple step function that was implemented by if-else conditions in Python, or np.where function while using NumPy. We may use a sigmoid function or other alternate functions to manipulate how and when a feature set produces the output – or activates the neuron. We can combine multiple activations like these and connect them in the form of a fully connected layer.
Such networks surpass the simplicity of using a simple perceptron and allow you to create multiple fully connected layers, thus leading to creation of hidden layers, thus creating a multilayer perceptron as shown in Figure 12-4. The output may become input to the next layer, which is further manipulated by a new set of weights at the next layer.
Figure 12-4
A simple multilayer perceptron with one output unit
Computation units can be arranged in a different fashion to create more diverse deep neural networks. The convolutional neural networks (CNNs) use a special kind of layers that apply a filter to an input image by sliding the filter to produce an activation map. CNNs are a highly preferable choice in many computer vision (CV) or natural language processing (NLP) applications. We will discuss more about them in depth in Chapter 14.
Another popular neural network architecture is called recurrent neural network (RNN), which has an internal state whose value is maintained based on input data in order to produce an output using a combination of the state and an input sample. This might also update the internal state and affect the future outputs. This thus helps interpret the sequential information in the data, which is highly helpful in NLP applications. We will study about this in Chapter 15.
Summary
In this chapter, we have discussed the basics of neural networks and have started to explore PyTorch to define tensors and create simple neural units that can learn to classify data. The next chapter discusses the algorithms that are used to learn network weights in neural networks, thus leading to feedforward and backward propagation.



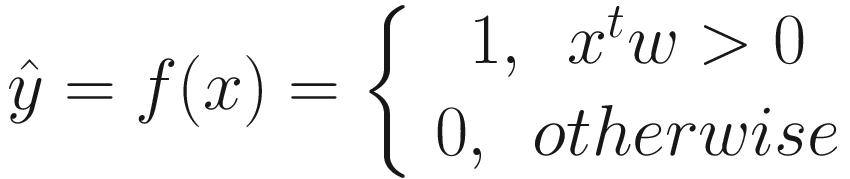
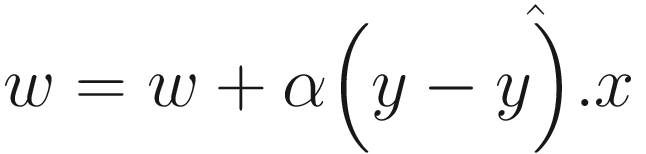
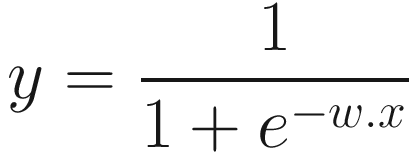

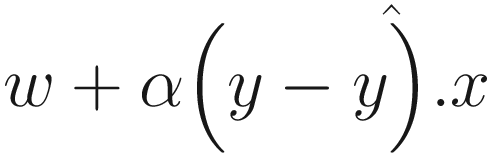 , we already know x and y; α is a hyperparameter that you can configure to set the steps, and w is the set of weights that we will learn in this process.
, we already know x and y; α is a hyperparameter that you can configure to set the steps, and w is the set of weights that we will learn in this process.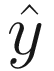 by first computing the product between the input data and weight and then applies the case to compare if the resulting product is larger than 0. This function can act as the prediction function as well as help us find the right value to update the weights.
by first computing the product between the input data and weight and then applies the case to compare if the resulting product is larger than 0. This function can act as the prediction function as well as help us find the right value to update the weights.