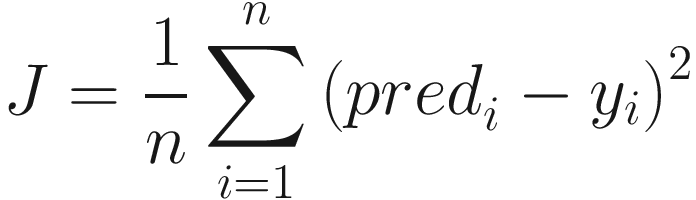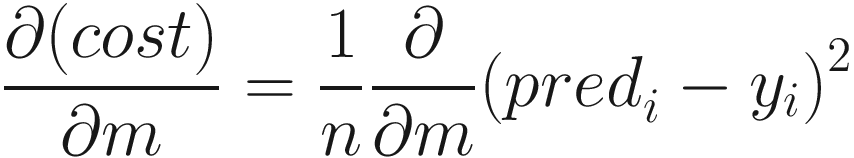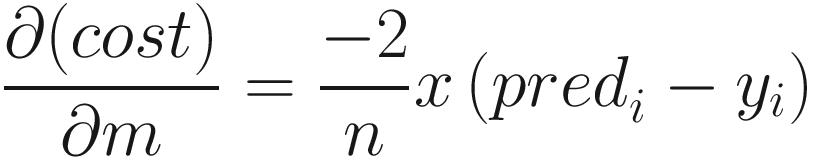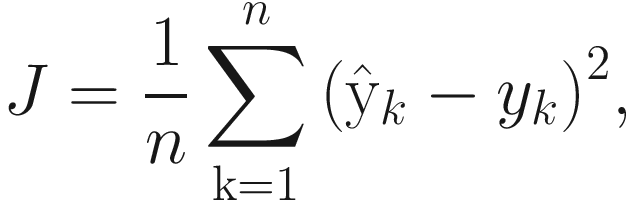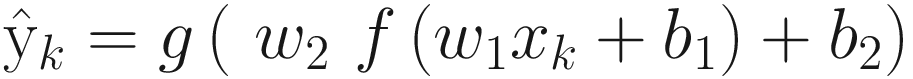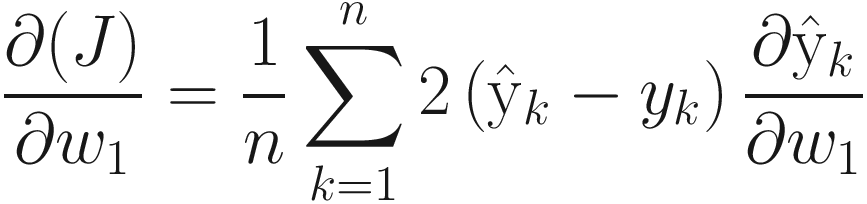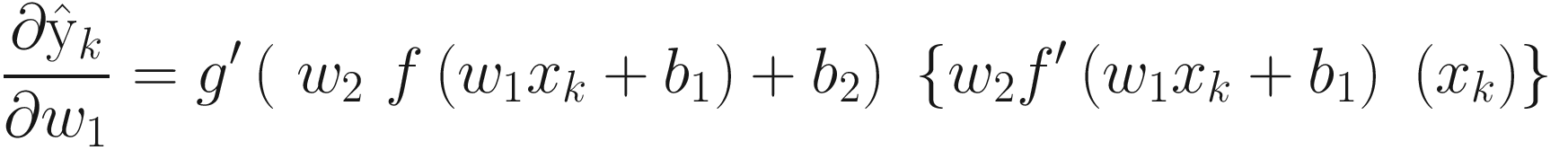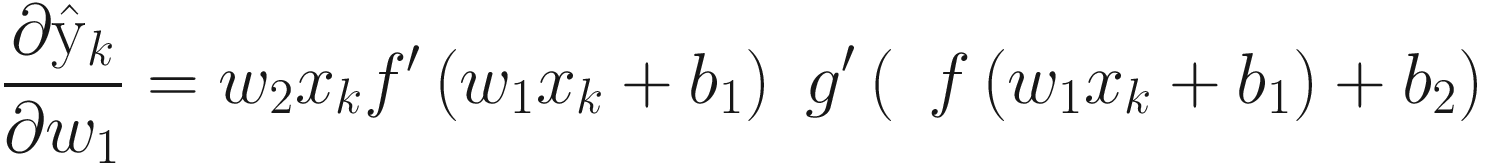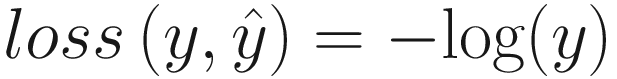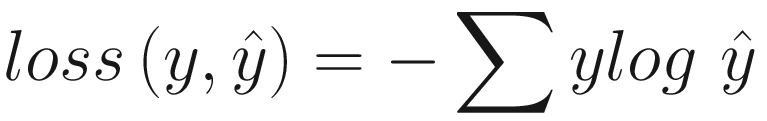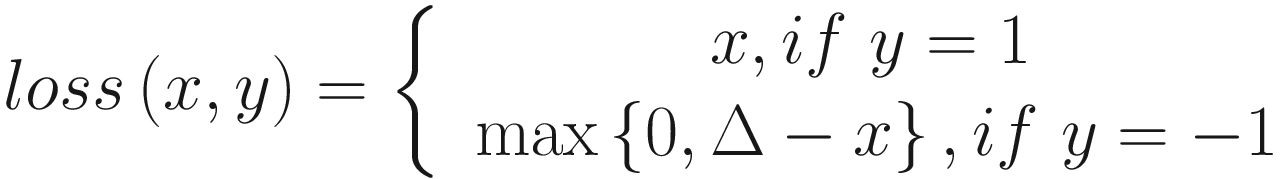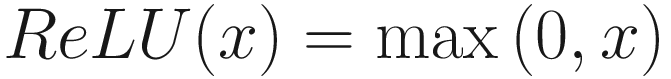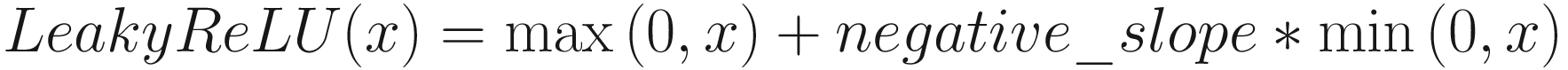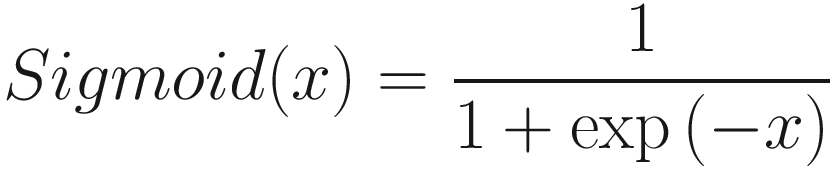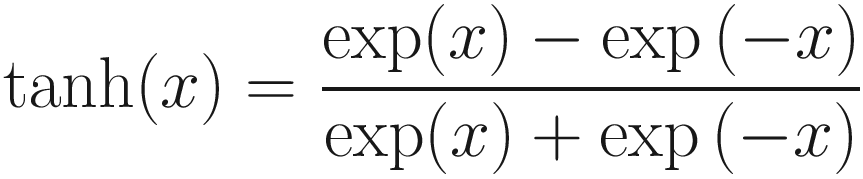Artificial neural networks (ANN)s are collections of interconnected computation units modelled based on the neurons in the brain so that the program thus created is capable of learning patterns in structured, textual, speech, or visual data. The basic computational unit in an artificial neural network is thought to be similar to (or rather, inspired from) a neural cell that accepts input signals from multiple sources, operates on them, and activates based on the given condition, which passes the signal to other neurons connected to it. Figure 13-1 shows the symbolic link between the biological neuron and the artificial neuron.
Figure 13-1
Comparison of a biological neuron with an artificial neuron
Just like neurons come together to form parts of the brain that are together responsible for recognizing some patterns or perform an action, artificial neural networks consist of a large number of such units. As we saw in the previous chapter, the neurons or computational units combine signals from multiple sources, apply an activation function, and pass the processed signal to other neurons connected to it. In a practical application, there can be a dozen to millions of neurons present that can be trained to operate and activate based on the input and expected output values in training data.
In this chapter, we will study neural networks in which layers of computational units are tied to each other till an output layer, in which the input signals are operated in each layer and fed forward, while the training process compares the output and traces back the changes required to develop a better neural network.
The concepts covered in this chapter form the basis of more advanced architectures of deep neural networks. We will discuss the process of training neural networks through a process called backpropagation, which is based on gradient descent. We will use PyTorch to create neural networks for regression and classification problems.
Feedforward Neural Network
Feedforward neural network is a simple form of artificial neural network in which the computation units pass the values gradually toward the output, combining them in a highly efficient manner to lead to improved results. The computation units in a feedforward neural network propagate the information in the forward direction (there are no cycles or backward links), through the hidden nodes and then to the output nodes. A simple example of a feedforward neural network is shown in Figure 13-2.
Figure 13-2
A simple feedforward neural network
Training Neural Networks
Backpropagation is the process for training neural networks. Backpropagation is based loosely on techniques that are being used since the 1960s, though this was thoroughly defined in 1986 by Rumelhart, Hinton, and Williams, which was followed by Yann LeCun’s work in 1987. During this time period, there were several promising works on neural networks, which form the basis of the field of deep learning today, though they couldn’t catch much attention in the general public due to limited computational infrastructure of that time. Later, around the 2010s, the cost of computer processors and graphics processors (GPUs) declined sharply, thus giving rise to the refinement of decade-old models and the creation of novel neural network architectures, leading to their use in speech recognition, computer vision, and natural language processing.
Gradient Descent
Training of neural networks requires a process called gradient descent, an iterative algorithm that is used to find the minimum (or maximum) value of a loss or a cost function. Imagine a regression problem (similar to what we saw in Chapter 7) in which a continuous output variable is determined based on a continuous input variable. In most practical cases, the predicted output, shown as a line in Figure 13-3, will not be exactly the same as the actual (expected) output. This difference is called errors, or residuals, and the learning algorithm aims to minimize the total residuals or some other aggregation of residuals.
Figure 13-3
Errors in a regression model
The learning process tends to learn the parameters of equation of a line in the form of y = w0 + w1x1 + w2x2 + ⋯. To simplify our example, we will stick to only one variable, thus leading to y = w0 + w1x1. One of the approaches used to solve such problems is gradient descent. In this example, we define an optimization function, here, a cost function, which shows how far the model’s results are with respect to the actual values in the training data. In linear regression, we can use mean squared error, which is the average of squares of differences in the values predicted by the model and the actual values.
The idea behind gradient descent is that the well-trained model should be the one in which the cost function is minimized. Each possible set of slopes (w0, w1,…) will produce a different model. Figure 13-4 shows the change in cost with respect to a slope, say, w1.
Figure 13-4
Gradient descent algorithm aims to find the parameters that minimize the cost
Our aim is to find a slope that produces the minimum cost. You can see the corresponding point at the lowest point of curve in the figure. Gradient descent algorithm begins with a randomly initialized value, and based on the slope of the cost at the point given by the partial derivative with respect to the slope, the algorithm changes:
which resolves to
This denotes the update in the value of m that should ideally lead toward a model with low cost. This process is the basis of backprop algorithm, and through the right choice of the loss function, we can train neural networks for much more complex problems.
If we translate this idea to neural network terminology, gradient descent provides us a way to update the weights of a one-layer neural network like the one we saw in the previous chapter.
Backpropagation
In a multilayer network, this method can be directly applied at the final layer where we can find the difference in the actual (or target) and the predicted value; however, this can’t be applied in the hidden layers because we don’t have any target values to compare. To continue updating the weights on all the individual cells of the neural network, we calculate the error in the final layer and propagate that error back from the last layer to the first layer. This process is called backpropagation.
Let’s consider a simplified neural network with one hidden layer as shown in Figure 13-5. We have only three nodes; the first one represents the input, the second is a hidden layer that performs computation on the input based on weight w1 and bias b1, and the third is an output layer, which also performs computation on the output from the hidden layer based on weight w1 and bias b1.
Figure 13-5
Simplified neural network with one hidden layer
Here, the first node accepts the input and forwards it to the second node, the hidden layer. Hidden layer applies the weight w1 to the input and adds bias b1, thus producing w1xk+b1, which is then applied with the activation function f. Thus, the output of hidden layer is f(w1xk+b1).
The output of hidden layer is being forwarded as the input of the third unit. This will be multiplied by w2 and added to bias b2. Thus, the input of the third unit is w2f(w1xk+b1) + b2.
When the activation function g is applied to it, it produces the output g(w2f(w1xk+b1) + b2), which is the predicted output, also denoted in Figure 13-5 as ŷk.
This process of forward propagation happens in each iteration during the training phase. Once we know the predicted value for all the items in the training dataset, we can find the loss or the cost function. For this explanation, let’s continue the same loss function we defined in the previous section.
(where)
We know that we can compute the derivative of loss function with respect to w1 to update w1 in order to reduce the overall loss in the next iteration.
This leads to another quantity that is resolved using chain rule as follows:
Or
We can find partial derivative with respect to w2 as
Thus, in more complex networks, we can continue computing partial derivatives in the backward direction. We will notice that there are several quantities that we have computed previously, for example, f(w1xk + b1) in the preceding example. You can see that in each iteration, the intermediate values and the output values are computed during a forward pass, followed by the process of updating weights using gradient descent starting from the output layer, moving backward till all the weights are updated. This is called backpropagation.
Loss Functions
In the previous explanation, we used a loss function called mean squared error (MSE). Due to its nature, this kind of loss function is suitable for regression problems where the output is a continuous variable. There are several other common loss functions that you can use depending on the problem in hand.
Mean Squared Error (MSE)
This averages the sum of squares of the error between actual value and predicted value. This penalizes the model for large errors and ignores small errors. This is also called L2 loss. For two values, y and ŷ, usually expected output and predicted output, the error component for each training sample is given by
Mean Absolute Error
Instead of considering the squares, we can simply look at the absolute sum of squares and take a mean across the dataset. This is also called L1 loss, and it is robust to outliers.
Negative Log Likelihood Loss
In simple classification problems, negative log likelihood loss is an efficient option that encourages the models in which the prediction is made correctly with high probabilities and penalizes it when it predicts the correct class with smaller probabilities.
Cross Entropy Loss
This is a suitable function to use in classification problems. It penalizes the model for producing wrong output with high probability. It is one of the mostly used loss functions when training a classification problem with C classes.
Hinge Loss
In problems where we want to learn nonlinear embeddings, hinge loss measures the loss given an input tensor x and a label tensor y (containing 1 or -1). This is usually used for measuring whether two inputs are similar or dissimilar.
For more loss functions that are defined in PyTorch, you can look at the official documentation.1
ANN for Regression
Let’s use PyTorch to create a simple neural network for a regression problem. Let’s begin with creating a simple dataset with one independent variable (X) and a dependent variable (y), where there might be a linear-like relationship between X and y. We will create tensors of shape [20,1], thus representing 20 inputs and 20 output values. The output plot is shown in Figure 13-6.
from matplotlib import pyplot
import torch
import torch.nn as nn
x = torch.randn(20,1)
y = x + torch.randn(20,1)/2
pyplot.scatter(x,y)
pyplot.show()
Figure 13-6
Randomly generated samples for regression
The data is ready. This model is a simple sequential model, which will have an input layer, followed by an activation function, and another output layer.
model = nn.Sequential(
nn.Linear(1,1),
nn.ReLU(),
nn.Linear(1,1)
)
Activation function is the function f that is applied to the weighted inputs f(wixi). ReLU, or Rectified Linear Unit, is a simple function that produces an output of 0 for any negative inputs and produces the unchanged input value for positive inputs. We will discuss about ReLU and other activation functions in the next section.
Because we have only one input variable, we expect to learn two weights, w1 and b. Due to ease of implementation, we refer to b as w0. For the input linear layer and the output linear layer, there will be two sets of weights each, thus a total of four weights initialized randomly, that we need to learn during training. Let’s see the model parameters to understand the quantities that will be learned.
list(model.parameters())
Out: [Parameter containing:
tensor([[-0.7681]], requires_grad=True),
Parameter containing:
tensor([0.2275], requires_grad=True),
Parameter containing:
tensor([[0.1391]], requires_grad=True),
Parameter containing:
tensor([-0.1167], requires_grad=True)]
We can now begin the process to learn the weights that minimizes the loss function using the method defined as the optimizer. However, remember that PyTorch requires the data to be in the form of a tensor. Let’s quickly (1) scale the data in the 0–1 range and (2) convert to tensor.
x = (x-x.min())/(x.max()-x.min())
y = (y-y.min())/(y.max()-y.min())
We now need to initialize mean squared error (MSE) loss function and an optimizer, which will use stochastic gradient descent for updating the weights.
While initializing the optimizer, we have defined a learning rate of 0.05. This affects how quickly (or slowly) the weights are updated.
The learning process requires multiple iterations in three steps:
1.
Forward propagation: Using the current set of weights, compute the output.
2.
Computation of losses: Compare outputs with the actual values.
3.
Backpropagation: Use the losses for updating weights.
Here, we use a for loop to iterate over 50 epochs. In this process, we will also keep track of losses so that we can later visualize how errors change over epochs.
loss_history = []
for epoch in range(50):
pred = model(x)
loss = lossfunction(pred, y)
loss_history.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
After 50 iterations, we expect the losses to be low enough to produce a decent result. Let’s visualize how the losses changed by plotting a chart of loss_history. We must remember that the loss object produced by lossfunction() will also contain data as a tensor, and we need to detach it so that Matplotlib can process it.
import matplotlib.pyplot as plt
plt.plot([x.detach() for x in loss_history], 'o-', markerfacecolor='w', linewidth=1)
plt.plot()
Figure 13-7
Loss reduces as the model is trained for more epochs and converges after a point
It is evident from Figure 13-7 that the losses decrease rapidly till the tenth epoch, after which the errors were so low that the gradient reduced, and the further changes were slower – till somewhere around the 30th epoch, after which the loss stayed the same and the change in weights was minimal.
Figure 13-8
Actual values and output predicted by a simple neural network
Let’s look at the results produced by the system. The result thus produced is shown in Figure 13-8.
This overly simple one-layer neural network might not always give best results for problems in which you can use fairly straightforward statistical solutions. It is possible that despite the graph showing evident reduction in losses, the final regression line might not be as closely fitting as you might expect. You can define the model and train it multiple times to see the difference due to random initialization.
With this model, you are now ready to work with more complex neural network architectures. We will first build a multilayer neural network with different activation function and use it to classify Iris flowers using the same dataset we have used so far.
Activation Functions
Each computation unit in a neural network accepts the input, multiplies weights, adds the bias, and applies an activation function to it before forwarding it to the next layer. This becomes input for the computation units in the next layer. In this example, we used Rectified Linear Unit (ReLU), which returns x, for an input x if x>0; otherwise, it returns 0. Thus, if a unit’s weighted computation yields a negative value, ReLU will make it as 0, which will be the input to the next layer. If the input is zero or negative, the derivative of activation function is 0, otherwise, 1.
There are many activation functions that have been defined. Here are some of the activation functions that you might often see being used.
ReLU Activation Function
Rectified Linear Unit is a simple and efficient function that enables the input as it is, if it is positive and doesn’t activate for the negative input; thus, it rectifies the incoming signal. It is computationally fast, nonlinear, and differentiable. It is defined as
However, because in case of negative inputs the neuron doesn’t affect the output at all, its contribution to the output becomes zero and thus doesn’t learn during backpropagation. This is solved by a variation of ReLU called Leaky ReLU.
Figure 13-9 shows the graph of ReLU and Leaky ReLU.
Figure 13-9
ReLU and Leaky ReLU activation function
Leaky ReLU produces a relatively small output for negative signals, which can be configured by changing the negative_slope.
Sigmoid Activation Function
Sigmoid function produces an output between 0 and 1, with output values close to 0 for a negative input and close to 1 for a positive input. The output is 0.5 for input of 0. You can see the graph for sigmoid activation function in Figure 13-10. This function is highly suitable for classification problems, and if used in the output layer, the output value that is between 0 and 1 can be interpreted as a probability.
Figure 13-10
Sigmoid and tanh activation function
However, sigmoid is computationally more expensive. If the input values are too high or too small, it can cause the neural network to stop learning. This problem is called vanishing gradient problem.
Tanh Activation Function
Tanh function is similar to sigmoid function but produces an output between -1 and 1, with output values close to -1 for a negative input and close to 1 for a positive input. The function crosses the origin at (0,0). The graph for tanh function is shown in Figure 13-10. You can see that though the two functions look similar, tanh function is significantly different.
Despite the similar shape, the gradients of tanh function are much stronger than sigmoid function. It is also used for layers which we wish to pass the negative inputs as negative outputs.
If a very negative input is provided to sigmoid function, the output value will be close to zero, and thus, the weights will be updated very slowly during backpropagation. Tanh thus improves the performance of the network in such situations.
Multilayer ANN
We can make the network slightly larger by (1) adding more computation units in the layers and (2) adding more layers. We can modify our network by editing how we specified the layers in the previous example.
model = nn.Sequential(
nn.Linear(1,8),
nn.ReLU(),
nn.Linear(8,4),
nn.Sigmoid(),
nn.Linear(4,1),
)
Here, we have defined an input layer that takes one input and forwards it to the layer with eight units. This is followed by ReLU activation function before moving to a layer with eight units, which then forwards to another layer with four units. This is followed by sigmoid activation, which forwards to the output layer with one unit.
We can modify the output layer to contain more than one unit if required. Let’s work on a multiclass classification problem we’ve seen before. Iris dataset contains elements from three species of Iris flowers. We can create three units in the output layer that will supposedly indicate the probability of an Iris sample falling in one of the three categories.
Let’s import the Iris dataset the way we’ve been doing before.
x = df.drop(labels='class', axis=1).astype(np.float32).values
y = df['class'].astype(np.float32).values
Because we’re going to use PyTorch, let’s import the required libraries.
import torch, torch.nn as nn
We now need to convert x and y to tensors. This can be done using torch.tensor(). Note that we’ll also convert the tensors to required data types so that we don’t have data format–related issues in the later stages.
data = torch.tensor( x ).float()
labels = torch.tensor( y ).long()
print (data.size())
print (labels.size())
Out: torch.Size([150, 4])
torch.Size([150])
We’ll now define a simple neural network that accepts four inputs, 16 units in the hidden layer, and three units in the output. All the activations will be ReLU. A schematic diagram for this network is shown in Figure 13-11.
Now we can initiate the training loop. In this example, we will train for 1000 iterations, or 1000 epochs. Just like the previous example, we’ll keep a track of the losses to visualize the learning process. We’ll also compute accuracy by comparing the predictions of the model with the values in the original dataset and keep a record of these for visualizations.
After 1000 iterations, we assume the loss to have sufficiently reduced and accuracies to be consistent. Let’s plot the two:
import matplotlib.pyplot as plt
fig,ax = plt.subplots(1,2,figsize=(13,4))
ax[0].plot(losses)
ax[0].set_ylabel('Loss')
ax[0].set_xlabel('epoch')
ax[0].set_title('Losses')
ax[1].plot(accuracy)
ax[1].set_ylabel('accuracy')
ax[1].set_xlabel('epoch')
ax[1].set_title('Accuracy')
plt.show()
Figure 13-12 shows the gradual decline of losses that almost didn’t vary enough beyond the 800th epoch. The accuracy chart shows a steep increase of accuracy in the initial epochs, which also reached a sufficiently high rate.
Figure 13-12
Graphs showing reduction in losses and growth of accuracy over the epochs
To monitor the accuracy, let’s find the predictions again for the final model and compare with the original values:
However, rather than ending this experiment here, it will be an interesting idea to understand what kind of decision boundaries are created in such a network. This might reveal more insight about how ANNs create boundaries.
We will create a new program for this so that the model is created based on two dimensions of the data (instead of four). Here’s the complete code:
At this point, the model has been trained, and we can continue preparing a two-dimensional space for plotting a contour plot that will show the decision boundaries based on how the model labels each point.
Thus, we’ll get a clear plot of how each point in the two-dimensional feature space will be classified as shown in Figure 13-3. On top of that, we have overlaid the original training points.
Figure 13-13
Decision boundaries created by the neural network for classifying Iris data
Based on the structure of your network and the activation functions, the boundaries might be much more different. However, one interesting pattern here is that the decision boundaries may not be straight – and with more complex data, they might be even more complex.
Now that you understand how neural networks can be built, let’s pick another classification problem and work with it.
NN Class in PyTorch
In the previous examples, we have always defined the structure of neural network using nn.Sequential(), which allows us to define how layers and activations are connected to each other. Another way of defining a network is a neural network class that inherits nn.Module and defines the layers that will be used and implements a method to define how forward propagation occurs. This is specifically useful when you want to model a complex model instead of a simple sequence of existing modules.
Let’s prepare data for classification using sklearn’s make_classification() method to create two distinct clusters.
We’ll now define a simple neural network with an input layer that accepts two inputs: a hidden layer with eight nodes and an output layer with one node denoting the class (0 or 1).
import torch, torch.nn as nn, torch.nn.functional as F
import numpy as np
class MyNetwork(nn.Module):
def __init__(self):
super().__init__()
self.input = nn.Linear(2,8)
self.hidden = nn.Linear(8,8)
self.output = nn.Linear(8,1)
def forward(self,x):
x = self.input(x)
x = F.relu( x )
x = self.hidden(x)
x = F.relu(x)
x = self.output(x)
x = torch.sigmoid(x)
return x
In this class, we need to explicitly indicate the sequence of layers and activation functions along with additional operations as we will see in the next section. This class can be instantiated, and model can be trained over multiple epochs in the same way as we did in the previous examples. We add few lines to print a graph to show the change in losses as shown in Figure 13-14.
Creating such classes helps us define a more sophisticated network block that may be composed of multiple smaller blocks, though in simpler networks, sequential is a good option.
Overfitting and Dropouts
Just like we saw in previous chapters, overfitting is a common problem in machine learning tasks where a model might learn too much from the training dataset and might not generalize well. This is true in neural networks as well, and due to flexible nature, neural networks are susceptible to overfitting.
There are, in general, two solutions to overfitting. One is to use a sufficiently large number of training data examples. The second method requires modifying how complex a network is in terms of network structures and network parameters. You may reduce some layers in the model or reduce the number of computation nodes in each layer.
Another popular method used in neural networks is called dropouts. You can define dropout at a certain layer so that the model will randomly deliberately ignore some of the nodes during training, thus causing those nodes to drop out – and thus, not able to learn “too much” from the training data samples.
Because dropout means less computation, the training process becomes faster, though you might require more training epochs to ensure that the losses are low enough. This method of using dropouts has proven to be effective in reducing overfitting to complex image classification and natural language processing problems.
In PyTorch, dropout can be defined with a probability of dropout, thus
dropout = nn.Dropout(p=prob)
In the NN class, we can add the dropout layers in the forward propagation definition with a predefined dropout rate of 20%. See the changes in the following code:
class MyNetwork(nn.Module):
def __init__(self):
super().__init__()
self.input = nn.Linear(2,8)
self.hidden = nn.Linear(8,8)
self.output = nn.Linear(8,1)
def forward(self,x):
x = self.input(x)
x = F.relu( x )
x = F.dropout(x,p=0.2)
x = self.hidden(x)
x = F.relu(x)
x = F.dropout(x,p=0.2)
x = self.output(x)
x = torch.sigmoid(x)
return x
If you keep a track of losses, they might look like Figure 13-15. Though the losses don’t reduce smoothly, we eventually find that the loss reduces as we train the network for more and more epochs, and it is possible that the network will be trained with sufficiently usable loss after a certain number of epochs.
Figure 13-15
Change in loss function
Classifying Handwritten Digits
Now that we can create a basic neural network, let’s use a more realistic dataset and tackle an image classification problem. For this task, we will use a dataset popularized by Yann LeCun, which contains 70,000 examples of handwritten digits, called MNIST (Modified National Institute of Standards and Technology) database. This dataset has been widely used for image processing and classification. A few digits are shown in Figure 13-16.
Figure 13-16
Digits from the MNIST digits dataset
Let’s import the required libraries. For this program, we also need to import torchvision, which is a part of PyTorch and provides various datasets, models, and image transformations.
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
Before we download the dataset programmatically, we can define a list of transforms that must be applied to help us process the dataset. We will need to convert the images to tensor format. We can use torchvision.datasets() to download the dataset.
The files will be exported to “/train/MNIST/raw” and “/test/MNIST/raw” folders. The next two lines initialize a DataLoader item for both training data and test data. DataLoader doesn’t directly provide the data but can be controlled by a user-defined iterable. Before we define a neural network, let’s look at a data item. The following lines would generate a batch of training data of 64 elements.
Each digit is present in a 28x28 pixel box. Each pixel, in this grayscale dataset, contains a value from 0 to 255 indicating the color (in terms of darkness). Thus, each image is defined by 784 values. Now we can proceed to defining the network. We know that the input layer contains 784 units and the output layer contains 10 units, each representing a number. We will add two more input layers with 64 units each. For this example, we will keep activations as ReLU, and because we have a multiclass classification problem, loss layer will be cross-entropy. Figure 13-17 summarizes the neural network we will be creating in this example.
Figure 13-17
Neural network for classifying handwritten digits. The input will always be of length 784, and the output will have a length of 10, each representing a digit
In the training phase, we will limit the number of epochs to ten, as the dataset is much larger than the examples we’ve covered so far. However, this should be good enough to bring the losses sufficiently low to make the model able to predict well for most of the examples. Within each epoch, train_loader would iterate over batches of 64 entries.
losses = []
for epoch in range(10):
running_loss = 0
for images, labels in train_loader:
images = images.view(images.shape[0], -1)
optimizer.zero_grad()
output = model(images)
loss = lossfn(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print("Epoch {} - Training loss: {}".format(epoch, running_loss/len(train_loader)))
losses.append(running_loss/len(train_loader))
This should show gradual reduction of losses over each epoch.
Epoch 0 - Training loss: 1.7003767946635737
Epoch 1 - Training loss: 0.5622020193190971
Epoch 2 - Training loss: 0.4039541946005211
Epoch 3 - Training loss: 0.35494661225534196
Epoch 4 - Training loss: 0.32477016467402486
Epoch 5 - Training loss: 0.302617403871215
Epoch 6 - Training loss: 0.2849765776086654
Epoch 7 - Training loss: 0.2697247594261347
Epoch 8 - Training loss: 0.25579357369622185
Epoch 9 - Training loss: 0.24312975907773732
The graph in Figure 13-18 shows how losses reduce over time.
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
Figure 13-18
Change in loss over a few epochs
Let’s now test how the model predicts for an item from the test dataset:
Figure 13-19 shows the first digit from the test dataset. The sample we had clearly shows that this is the number eight (8).
Please note that some samples in MNIST datasets might not be so clear. As you might expect, the dataset contains some examples that might be confusing to even human readers, for example, a six (6) that looks more like a zero (0) or a seven (7) that looks more like a one (1). Some simple neural networks trained for a small number of epochs might not be very accurate.
Figure 13-19
A single digit from MNIST dataset
We will first compress the image to 1x784 cell format and find the values at the output layer. The highest value would correspond to the predicted value. We’ll also convert the values of output cells to the probabilities, of which, the best can be chosen as the output.
Here, all the ten output units represent a probability. You can explore probabilities object to see the probability of alternate outputs – we can see that this eight (8) also has a very minor chance of being a 6 or a 2.
Summary
In this chapter, we learned how neural network units work and how they can be combined to create more capable neural networks that can solve complex problems. We created simple and complex neural networks for regression and classification problems. In the next chapter, we’ll proceed to a special kind of neural network architecture especially suitable for images and other two- or three-dimensional data.