
Single Responsibility Principle (SRP)
Open/Closed Principle (OCP)
Liskov Substitution Principle (LSP)
Interface Segregation Principle (ISP)
Dependency Inversion Principle (DIP)
Robert C. Martin and Micah Martin also discussed these principles in their book Agile Principles, Patterns, and Practices in C# (Prentice Hall). Taking the first letter of each principle, Michael Feathers introduced the SOLID acronym so we can remember these names easily.
The SOLID principles are not rules. They are not laws. They are not perfect truths. They are statements on the order of “An apple a day keeps the doctor away.” This is a good principle, it is good advice, but it’s not a pure truth, nor is it a rule.
—Robert C. Martin
In this chapter, we’ll explore these principles in detail. One way to understand a principle is to recognize its need in the first place. So, in each case, I start with a program that does not follow any specific design guidelines but compiles and runs successfully. Then in the “Analysis” section, we’ll discuss the possible drawbacks and try to find a better solution using these principles. These case studies will help you think better and make high-quality applications.
Single Responsibility Principle
A class acts like a container that can hold many things such as data, properties, or methods. If you put too much data, properties, or methods together that are not related to each other, you end up with a bulky class that can create problems in the future. Let us consider an example. Suppose you create a class with multiple methods that do different things. In such a case, even if you make a small change in one method, you need to retest the whole class again to ensure the workflow is correct. This is because changes in one method can impact the other methods in the class. This is the reason that the single responsibility principle opposes the idea of putting multiple responsibilities in a class. It says that a class should have only one reason to change.
To describe the principle, I used the concept of a class. Robert C. Martin described this principle in terms of modules. The term module can be confusing for you if you purely think in terms of C#. For example, the Microsoft documentation (see https://docs.microsoft.com/en-us/dotnet/api/system.reflection.module?view=net-6.0) says the following: “A module is a portable executable file, such as type .dll or application .exe, consisting of one or more classes and interfaces. There may be multiple namespaces contained in a single module, and a namespace may span multiple modules.” This documentation also says that a .NET Framework module is not the same as a module in Visual Basic, which is used by programmers to organize functions and subroutines in an application. Similarly, any Python programmer knows that a module can contain many things. To organize his code, a Python programmer can place variables, functions, and classes in a module. The programmer creates a separate file with a .py extension for this purpose. Later the programmer can import the whole module or a particular function from the module in the current file.
To make things easy, I’ll use classes to describe this principle and subsequent principles in this chapter.
So, before you make a class, identify the responsibility or the purpose of the class. If multiple members help you to achieve one single purpose, you can place all the members inside the class.
When you follow the SRP, your code is smaller, cleaner, and less fragile. Now the question is, how do you follow this principle? A simple answer is that you can divide a big problem into smaller chunks based on different responsibilities and put each of these small parts into separate classes. The next question is, what do we mean by responsibility? In simple words, responsibility is a reason for a change.
Let us consider some examples. For an Employee class, suppose you see methods such as SaveEmpDetails(Employee e), DisplaySalary(Employee e), etc. Probably, you can guess that SaveEmpDetails will save the details of an employee to a database. So, a database administrator should be responsible for ensuring everything is maintained properly. You can also guess that DisplaySalary will probably show the salary details of an employee. Now the question is, who maintains them? Probably the account head of the company will be responsible for ensuring that it shows the correct data. So, you can see that different people are “responsible” for changes.
In the upcoming discussion, you’ll see a class that contains three different methods that are not closely related to each other. We’ll analyze the impact, and in the end, I’ll segregate the code based on different responsibilities and put them into different classes. Let’s start.
Initial Program
The DisplayEmployeeDetail() method shows the employee’s name and his working experience in years.
The CheckSeniority() method can evaluate whether an employee is a senior person. To make things simple, I assume that if the employee has 5+ years of experience, they are a senior employee; otherwise, they are a junior employee.
The GenerateEmployeeId() method generates an employee ID using string concatenation. The logic is simple: I concatenate the first letter of the first name with a random number to form an employee ID. In the client code, I’ll create two Employee instances and use these methods to display the relevant details.
Demonstration 1
Output
Analysis
The top management can set different criteria to decide on a seniority level.
The human resource department can use a new algorithm to generate the employee ID.
In each case, you need to modify the Employee class and so forth. You understand that it is better to follow the SRP and separate the activities.
Better Program
In the following demonstration, I introduce two more classes. The SeniorityChecker class now contains the CheckSeniority() method, and the EmployeeIdGenerator class contains the GenerateEmployeeId() method to generate the employee ID. As a result, in the future, if you need to change the program logic to determine the seniority level or use a new algorithm to generate an employee ID, you can make the changes in the respective classes. Other classes are untouched. So, you do not need to retest those classes. Now you have followed the SRP.
In addition, apart from following the SRP, this time I improved the code readability too. Notice that in demonstration 1, I called all the required methods inside the client code. But for better readability and to avoid clumsiness, this time I introduce three static methods: PrintEmployeeDetail(...), PrintEmployeeId(...), and PrintSeniorityLevel(...). I have defined them inside a helper class, called Helper. These methods call the DisplayEmployeeDetail() method from Employee, the GenerateEmployeeId() method from EmployeeIdGenerator, and the CheckSeniority() method from SeniorityChecker, respectively. I repeat that these three methods are not necessary, but they make the client code simple and easily understandable.
Demonstration 2
Output
Note that the SRP does not say that a class should have at most one method. Here the emphasis is on the single responsibility. There may be closely related methods that can help you to implement a responsibility. For example, if you have different methods to display the first name, the last name, and a full name, you can put these methods in the same class. These methods are closely related, and it makes sense to place all these display methods inside the same class.
In addition, you should not conclude that you need to separate responsibilities in every application that you make. You must analyze the change’s nature. This is because too many classes can make your application complex, which is difficult to maintain. But if you know this principle and think carefully before you implement a design, you are likely to avoid similar mistakes that I discussed earlier.
Open/Closed Principle
The Open-Closed Principle(OCP) was coined in 1988 by Bertrand Meyer. It says: A software artifact should be open for extension but closed for modification.
Any modular decomposition technique must satisfy the OCP: modules should be both open and closed.
- The contradiction between the two terms is apparent because they have different goals:
A module is said to be open if it is still available for extension. For example, it should be possible to expand its set of operations or add fields to its data structures.
A module is said to be closed if it is available for use by other modules. This assumes that the module has been given a well-defined, stable description (its interface in the sense of information hiding). At the implementation level, closure for a module also implies that you may compile it, perhaps store it in a library, and make it available for others (its clients) to use.
The need for modules to be closed and the need for them to remain open arise for different reasons.
He explains that openness is useful for software developers because they can’t foresee all the elements that a module may need in the future. But the “closed” modules will satisfy the need of the project managers because they want to complete the project instead of waiting for each other to complete their parts.
The previous points are self-explanatory. You understand that the idea behind this design philosophy is that in a stable and working application, once you create a class and other parts of your application start using it, any further change in the class can cause the working application to break. If you require new features (or, functionalities), instead of changing the existing class, you can extend the class to adopt those new requirements. What is the benefit? Since you do not change the old code, your existing functionalities continue to work without any problem, and you can avoid testing them again. Instead, you need to test the “extended” part (or, functionalities) only.
A class is closed, since it may be compiled, stored in a library, baselined, and used by client classes. But it is also open, since any new class may use it as a parent, adding new features and redeclaring inherited features; in this process there is no need to change the original or to disturb its clients. This property is fundamental in applying inheritance to the construction of reusable, extendible software.
But inheritance promotes tight coupling. In programming, we like to remove these tight couplings. Robert C. Martin improved the definition and made it polymorphic OCP. His proposal uses abstract base classes with protocols instead of a superclass to allow different implementations. These protocols are closed for modification, and they provide another level of abstraction that enables loose coupling. In this chapter, we’ll follow Robert C. Martin’s idea that promotes polymorphic OCP.
In the final chapter of this book, I describe some common terms including cohesion and coupling. If required, you can take a quick look at them.
Initial Program
Author’s Note: In my book Java Design Patterns (3rd Edition), I showed individual subjects such as computer science, physics, history, and English under different streams. You can understand that computer science and physics belong to the Science stream and the other two belong to the Arts stream. For simplicity, I have ignored this activity in this chapter. Here, I mention the streams directly and refer to them as departments.
Suppose you start with two instance methods in this example. The DisplayResult() displays the result with all the necessary details of a student, and the EvaluateDistinction() method evaluates whether a student is eligible for a distinction certificate. I assume that if a student from the science department scores above 80 in this examination, they get the certificate with distinction. But the criterion for a student from the arts department is slightly relaxed. Here the student gets the distinction if their score is above 70.
First, you’ll violate the SRP when you place both the DisplayResult() and the EvaluateDistinction() methods inside the same class.
In the future, the examining authority can change the distinction criteria. In this case, you need to change the EvaluateDistinction() method. Does this solve the problem? In the current situation, the answer is yes. But a college authority can change the distinction criteria again. How many times will you modify the EvaluateDistinction() method?
Remember that each time you modify the method, you need to write/modify the existing test cases too.
You can see that every time the distinction criteria changes, you need to modify the EvaluateDistinction() method in the Student class. So, this class does not follow the SRP, and it is also not closed for modification.
In the following program, Student and DistinctionDecider are two different classes.
The DistinctionDecider class contains the EvaluateDistinction() method in this example.
You understand that to show the details of a student, you can override the ToString() method, instead of using a separate method, DisplayResult(). So, inside the Student class, you see the ToString() method now.
There is a Helper class with a method called MakeStudentList(). Inside the client code, you’ll see the following line:
The MakeStudentList() method creates a list of students. It helps me to avoid repetitive code for each student. You use this list to print the student’s details one by one. You also use the same list to invoke EvaluateDistinction() to identify the students who have received the distinction.
Demonstration 3
Here is the complete demonstration.
You’ll see me using raw-string literals in this program. It is a C# 11 preview feature. I have used this new feature in many programs in this book so that you can be familiar with it. I like it because it is easier to read and it more closely resembles the output text.
Output
Analysis
The college authority can introduce a new stream such as commerce and set a new distinction criterion for this stream.
You need to make some obvious changes again. For example, you need to modify the EvaluateDistinction() method and add another if statement to consider commerce students. Now the question is, is it OK to modify the EvaluateDistinction() method in this manner? Remember that each time you modify the method, you need to test the entire code workflow again.
You understand the problem now. In demonstration 3, every time the distinction criteria changes, you need to modify the EvaluateDistinction() method in the DistinctionDecider class. So, this class is not closed for modification.
Better Program
To tackle this problem, you can write a better program. The following program shows such an example. I write this program following the OCP principle that suggests we write code segments (such as classes or methods) that are open for extension but closed for modification.
The OCP can be achieved in different ways, but abstraction is the heart of this principle. If you can design your application following the OCP, your application is flexible and extensible. It is not always easy to fully implement this principle, but partial OCP compliance too can generate greater benefit to you. Also notice that I started demonstration 3 following the SRP. If you do not follow the OCP, you may end up with a class that performs multiple tasks, which means the SRP is broken too.
The previous code segment clearly shows the distinction criteria in different streams. So, I remove the department field from the Student class now.
In addition to these changes, this time, I enroll science students and arts students separately. This is why the Helper class contains two methods, MakeScienceStudentList() and MakeArtsStudentList(), respectively. The remaining code is easy, and you should not have any trouble understanding the following demonstration now.
Demonstration 4
Output
Analysis
The Student class and IDistinctionDecider both are unchanged for any future changes in the distinction criteria. They are closed for modification.
Notice that every participant follows the SRP.
If you consider students from a different stream such as commerce, you can add a new derived class, say CommerceDistinctionDecider, that can implement the IDistinctionDecider interface and set new distinction criteria for commerce students.
Using this approach, you avoid an if-else chain (shown in demonstration 3). This chain could grow if you consider new streams such as commerce. In cases like this, avoiding a big if-else chain is considered a better practice. This is because by avoiding the if-else chains, you lower the cyclomatic complexity of a program and produce better code. (Cyclomatic complexity is a software metric to indicate the complexity of a program. It indicates the number of paths through a particular piece of code. So, in simple terms, by lowering the cyclomatic complexity, you make your code easily readable and testable.)
I’ll finish this section with Robert C. Martin’s suggestion. In his book Clean Architecture, he gave us a simple formula: if you want component A to protect from component B, component B should depend on component A. Now the question is, why do we give component A such importance? It is because we may want to put the most important rules in it.
It is time to study the next principle.
Liskov Substitution Principle
This principle originated from the work of Barbara Liskov in 1988. The LSP says that you should be able to substitute a parent (or base) type with a subtype. This means that in a program segment, you can use a derived class instead of its base class without altering the correctness of the program.
Can you recall how you use inheritance? There is a base class, and you create one (or more) derived classes from it. Then you can add new methods to the derived classes. As long as you directly use the derived class method with a derived class object, everything is fine. A problem may occur, though, if you try to get the polymorphic behavior without following the LSP. How? You’ll see a detailed discussion with examples in this chapter.
This method works fine until the point you pass a B instance to it. But what happens if you pass a D instance instead of a B instance? Ideally, the program should not fail. This is because you use the concept of polymorphism and you say that D is basically a B type since class D inherits from class B. A common example is when we say a soccer player is also a player, where we consider the Player class is a parent type/supertype of Soccer Player.
Now see what the LSP suggests to us. It says that SomeMethod should not misbehave/fail if you pass a D instance instead of a B instance to it. But it may happen if you do not write your code following the LSP. The concept will be clearer to you when you go through the upcoming example.
Polymorphic code shows your expertise, but remember that it’s the developer’s responsibility to implement polymorphic behavior properly and avoid unwanted outcomes.
Initial Program
Let me show you an example that I see every month: I use an online payment portal to pay my electricity bill. Since I am a registered user, when I raise a payment request in this portal, it shows my previous payment(s) too. Let us consider a simplified example based on this real-life scenario.
Inside the client code, you create two users and show their current payment requests along with previous payments. Everything is OK so far.
Demonstration 5
Output

The program encounters the NotImplementedException
In every iteration, you have called the method LoadPreviousPaymentInfo() on the respective IPayment object, and the exception is raised for the GuestUser instance. The previous working solution does not work now because the GuestUser violates the LSP. What is the solution? Go to the next section.
Better Program
The first obvious solution that may come into your mind is to employ an if-else chain to verify whether the IPayment instance is a GuestUser or a RegisteredUser. It is a bad solution because if you have another special type of user, you again verify it inside the if-else chain. Most importantly, you violate the OCP each time you modify the existing class using this if-else chain. So, let us search for a better solution.
Demonstration 6
Output
Analysis
What are the key changes? Notice that in demonstration 5, ShowPreviousPayments() and ProcessNewPayments() both processed IPayment instances. Now ShowPreviousPayments() processes IPreviousPayment instances, and ProcessNewPayments() processes INewPayment instances. This new structure solves the problem that we faced in demonstration 5.
Interface Segregation Principle
You often see a fat interface that contains many methods. A class that implements the interface may not need all these methods. Now the question is, why does the interface contain all these methods? One possible answer is to support some of the implementing classes of this interface. But this should not be the case, and this is the area that the ISP focuses on. It suggests not polluting an interface with these unnecessary methods only to support one (or some) of the implementing classes of this interface. The idea is that a client should not depend on a method that it does not use. Once you understand this principle, you’ll identify that I have already used ISP when I showed you a better design following the LSP. For now, let us consider an example with a full focus on the ISP.
A client means any class that uses another class (or interface).
The word Interface of the interface segregation principle is not limited to a C# interface. It applies to any base class interface, such as an abstract class or a simple base class.
Many examples across different programming languages explain the violation of the ISP with an emphasis on throwing an exception such as NotImplementedException() in C# or UnsupportedOperationException() in Java. In demonstration 7, I also demonstrated to you such an example. It helps me to show you the disadvantages of an approach that does not follow the ISP (and the LSP).
ISP suggests your class should not depend on interface methods that it does not use. This statement will make more sense to you when you go through the following example.
Initial Program
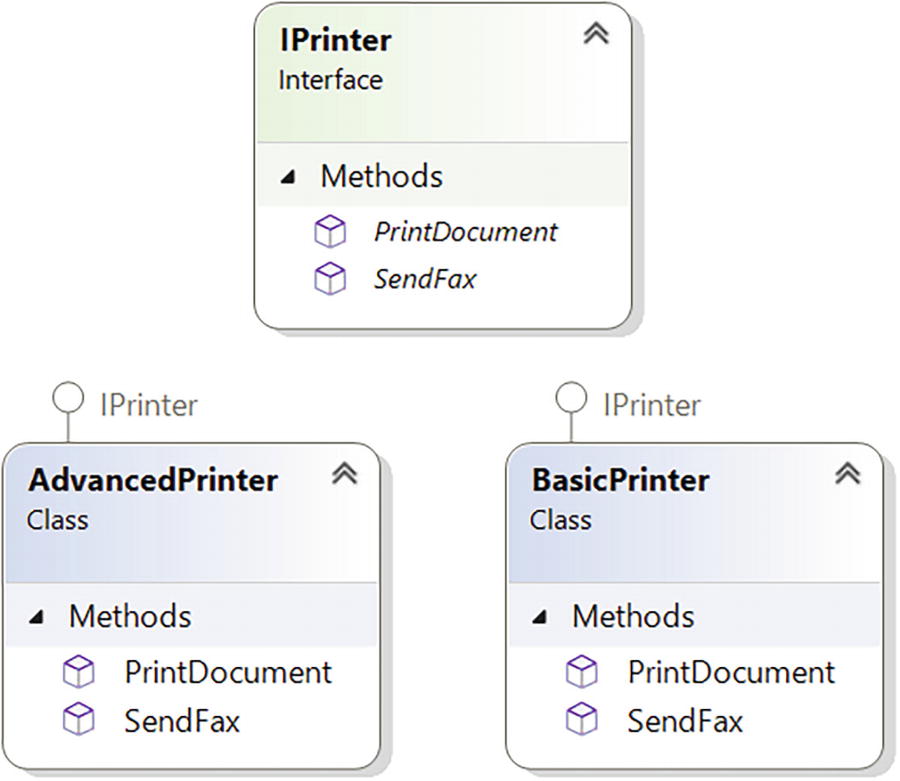
The Printer class hierarchy
Though everything is OK so far, with this kind of design, you may face trouble in the future. To illustrate this, let me show you a complete program and analyze it further. Do not worry! You’ll see a better program shortly.
Demonstration 7
Output
Analysis
This program suffers from various issues. First and most important, a change to the SendFax() method in the AdvancedPrinter can force the interface Printer to change, which in turn forces the BasicPrinter code to recompile. This situation is always unwanted.
Now you ask me, why does a user invite the problem in the first place? Or, why does a user need to change a base class (or, an interface)? To answer this, assume that you want to show which type of fax you are using in a later development phase. We know that there are different variations of fax methods, such as LanFax, InternetFax (or, EFax), and AnalogFax. So, earlier, the SendFax() method did not use any parameter, but now it needs to accept a parameter to show the type of fax it uses.
To use this inheritance chain, let us assume you update the original SendFax() in AdvancedPrinter. So, you modify the SendFax() method to SendFax (IFax faxType) in the AdvancedPrinter class, which demands you to change the interface IPrinter. When you do this, you need to update BasicPrinter class too to accommodate this change. In short, in this program, if you change the SendFax() method signature in AdvancedPrinter, you need to adjust the change in IPrinter, which causes BasicPrinter to change and recompile. Now you see the problem!
It is not the end! Assume that to support another printer that can print, fax, and photocopy, you add a photocopying method in the IPrinter interface. Now both the existing clients, BasicPrinter and AdvancedPrinter, need to accommodate the change. This is why when you see a fat interface, you should ask yourself the following question: are all these methods required for the clients? If not, split the interface into smaller interfaces to ensure no client needs to implement unnecessary methods.
In both these cases, you will see runtime exceptions.
Better Program
The class that wants print functionality implements the IPrinter interface, and the class that wants fax functionality implements the IFaxDevice interface.
If a class wants both these functionalities, it implements both these interfaces.
You should not assume that ISP says an interface should have only one method. In my example, there are two methods in the IPrinter interface, and the BasicPrinter class needs only one of them. That is the reason you see the segregated interfaces with a single method only.
Demonstration 8
Output
Analysis
The foremost point is that before C# 8, interfaces couldn’t have default methods. All those methods were abstract by default.
Second, if you use a default method inside the interface or an abstract class, the method is available for use in the derived classes. This kind of practice can violate the OCP and the LSP, which in turn causes hard maintenance and reusability issues. For example, if you provide a default fax method in an interface (or an abstract class), the BasicPrinter must override it by saying something similar to the following:
You can still argue, what happens if I use an empty method, instead of throwing the exception? Yes, the code will work, but for me, providing an empty method for a feature that is not supported at all is not a good solution in a case like this. From my point of view, it is misleading because the client sees no change in output when invoking a valid method.
An alternative technique to implement the ISP is to use the delegation technique. The discussion of this is beyond the scope of this book. But you can remember the following point: delegations increase the runtime (it can be small, but it is nonzero for sure) of an application that can affect the performance of the application. Also, in a particular design, a delegated call can create some additional objects too. The unnecessary creation of objects can cause trouble for you because they occupy some memory blocks. So, if you make an application that needs to run using a very small memory (such as a real-time embedded system), you should be careful enough before you create an extra object.
Dependency Inversion Principle
A high-level concrete class should not depend on a low-level concrete class. Instead, both should depend on abstractions.
Abstractions should not depend upon details. Instead, the details should depend upon abstractions.
We’ll examine both these points.
The reason for the first point is simple. If the low-level class changes, the high-level class may need to adjust the change; otherwise, the application breaks. What does this mean? It says that you should avoid creating a concrete low-level class inside a high-level class. Instead, you should use abstract classes or interfaces. As a result, you remove the tight coupling between the classes.
The second point is also easy to understand when you analyze the case study that I discussed for the ISP. You saw that if an interface needs to change to support one of its clients, other clients can be impacted due to the change. No client likes to see such an application.
So, in your application, if your high-level modules are independent of low-level modules, you can reuse them easily. This idea also helps you design nice frameworks.
In his book Agile Principles, Patterns and Practices in C#, Robert C. Martin explains that a traditional software development model (such as structured analysis and design) tended to create software where high-level modules depend on low-level modules. But in OOP, a well-designed program opposes the idea. It inverts the dependency structure that often results from a traditional procedural method. This is the reason he used the word inversion in this principle.
Initial Program
Assume that you have a two-layer application. In this application, a user can save an employee ID in a database. Throughout this book, I use console applications. So, to make things simple, I’ll again use a console application instead of a Windows Forms application.
Here you see two classes, UserInterface and OracleDatabase. As per their names, the UserInterface represents a user interface (such as a form where a user can type an employee ID and click the Save button to save the id in a database). Similarly, the OracleDatabase is used to mimic an Oracle database. Again, for simplicity, there is no actual database in this application, and there is no code to validate an employee ID. Here our focus is on the DIP only, so those discussions are not important.

A high-level class, UserInterface, depends on a low-level class, OracleDatabase
This style of coding is common. But there are some problems. We’ll discuss them in the “Analysis” section before I show you a better approach. For now, go through the following program.
Demonstration 9
Output
Analysis
The top-level class (UserInterface) has too much dependency on the bottom-level class (OracleDatabase). These two classes are tightly coupled. So, in the future, if the OracleDatabase class changes, you may need to adjust the changes in the UserInterface. For example, when you change the signature of the SaveEmpIdInDatabase method, you need to adjust the changes in the UserInterface class.
The low-level class should be available before you write the top-level class. So, you are forced to complete the low-level class before you write or test the high-level class.
What will you do when you need to support a different database? For example, you may switch from the Oracle database to a MySQL database; or, you may need to support both.
Better Program
In the upcoming program, you’ll see the following code segments:
From these two code segments, you can see that the high-level class UserInterface and the low-level class OracleDatabase both depend on the abstraction IDatabase. This structure fulfills the criteria for the DIP and makes the program efficient.
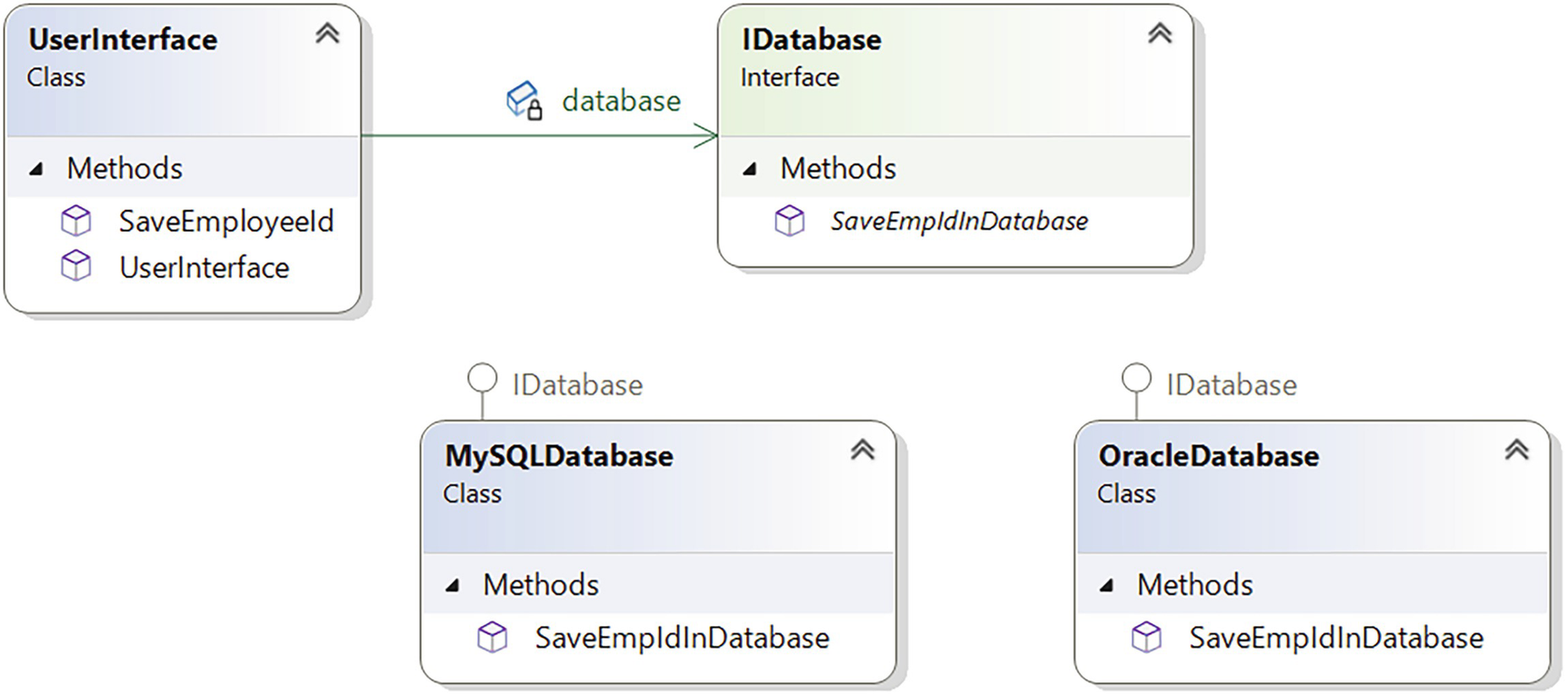
The high-level class UserInterface depends on the abstraction IDatabase
The second part of the DIP suggests making the IDatabase interface consider the needs of the UserInterface class. This interface does not depend on a low-level class such as OracleDatabase or MySQLDatabase. This is important because if an interface needs to change to support one of its clients, other clients can be impacted due to the change. You saw this when we analyzed the design problems of demonstration 7.
Demonstration 10
Output
Analysis
You can see that this program resolves all the potential issues of the previous program that I showed you in demonstration 9.
High-level modules simply should not depend on low-level modules in any way.
So, when you have a base class and a derived class, your base class should not know about any of its derived classes. But there are a few exceptions to this suggestion. For example, consider the case when your base class needs to restrict the count of the derived class instances at a certain point.
You can follow the same technique for similar examples that are used in this book.
Summary
The SOLID principles are the fundamental guidelines in object-oriented design. They are high-level concepts that help you make better software. These are neither rules nor laws, but they help you think of possible scenarios/outcomes in advance. In this chapter, I showed you applications that follow (and do not follow) these principles and discussed the pros and cons.
The SRP says that a class should have only one reason to change. Using the SRP, you can write cleaner and less fragile code. You identify the responsibilities and make classes based on each responsibility. What is a responsibility? It is a reason for a change. But you should not assume that a class should have a single method only. If multiple methods help you to achieve a single responsibility, your class can contain all these methods. You are OK to bend this rule based on the nature of possible changes. The reason for this is that if you have too many classes in an application, it is difficult to maintain. But the idea is that when you know this principle and think carefully before you implement a design, you can avoid some typical mistakes that I discussed earlier.
Robert C. Martin mentioned the OCP as the most important object-oriented design principle. The OCP suggests that software entities (a class, module, method, etc.) should be open for extension but closed for modification. The idea is if you do not touch a running code, you do not break it. For new features, you add new codes but do not disturb the existing code. This helps you to save time to retest the entire workflow again. Instead, you focus on the newly added code and test that part. This principle is often hard to achieve, but partial OCP compliance too can provide a bigger benefit to you in the long term. In many cases, when you violate OCP, you break the SRP too.
The idea of the LSP is that you should be able to substitute a parent (or base) type with a subtype. It is your responsibility to write true polymorphic code using the LSP. Using this principle, you can avoid the long tail of if-else chains and make your code OCP compliant too.
The idea behind ISP is that a client should not depend on a method that it does not use. This is why you may need to split a fat interface into multiple interfaces to make a better solution. I have shown you a simple technique to implement the idea. When you do not modify an existing interface (or an abstract class or a simple base class), you follow OCP too. In fact, an ISP compliance application can help you make OCP and LSP compliance applications. You can make an ISP compliance application using the delegation technique, which I did not discuss in this book. But the important point is that when you use the delegation, you increase the runtime (you may say it is negligible, but it is nonzero for sure), which can affect a time-sensitive application. Using delegation, you may create a new object when a client uses the application. It may cause memory issues in certain scenarios.
The DIP suggests two important points for us. First, a high-level concrete class should not depend on a low-level concrete class. Instead, both should depend on abstractions. Second, the abstractions should not depend upon details. Instead, the details should depend upon abstractions. When you consider the first part of the suggestion, your application is efficient and flexible; you can consider new concrete implementations in your application. When you analyze the second part of this principle, you understand that you should not change an existing base class or interface to support one of its clients. This can cause another client to break, and you violate OCP in such a case. I analyzed the importance of both these points.