
Chapter 11. Practical Applications and Use Cases
Over the course of the preceding pages, we have described the foundational components of a privacy-protective information management architecture. Just like a set of building blocks, these capabilities can be combined in a wide variety of ways to create the final product. In some cases, you will find that you end up using more of one kind of block than another, and in others you might not use one particular block at all. In still other cases, you might need to design and build a bespoke privacy-enhancing technology as yet undreamt of and tailored to some set of unique circumstances. There are no absolute “right” answers when it comes to privacy: the ultimate design of your product will depend on the specific desires of you and your customers.
It may be helpful to see how our various building blocks interact. The following examples are not based on any particular real-world models, and the solutions we suggest are by no means the only possible privacy-protective configuration for the systems in these contexts. Indeed, you might be able to come up with far better configurations than we have. The intent is not to provide a guide to building these types of systems, but rather to demonstrate how some of the capabilities that have been described in the preceding chapters can fit together.
Basic Framework
Now that you’re equipped with the ideas and techniques from the preceding chapters, let’s return to the questions that were set out in “Before You Get Started”. Although this framework is by no means the only approach to thinking through privacy issues with a technology, it’s one way to organize your approach to identifying and addressing privacy questions. As a refresher:
-
Does this technology interact with personally identified or identifiable information?
-
What is the technology supposed to do with the data?
-
What could the technology do with the data?
-
What are the potential privacy concerns?
-
How can you configure your privacy building blocks to address those issues?
This guide will help you when you start to design your product, and you should repeat the process any time you add a new data set or create new functionality.
Use Case #1: Social Media Analysis
Social media platforms offer a trove of information about individuals, and much of that information is freely available to anyone with access to the Internet. Everyone from marketers to academic institutions to law enforcement and intelligence agencies wants to figure out how to derive valuable insight from those platforms. Can this be done in a way that preserves individual privacy? In this use case, we consider a hypothetical social media analysis product.
- The technology
-
You have designed a technology that analyzes social media information. Your product scrapes publicly available social media data, stores that data, and allows users to analyze this data in a variety of ways.1
- Does this technology interact with personally identified or identifiable information?
-
Yes. Social media information can contain personally identifiable information, including names, addresses, and telephone numbers. In addition, social media information might be highly identifiable. Geolocation information, statements regarding attendance at certain events, statements describing unique features of home, family, or social life, and other information might allow others to identify the individual even when they are not directly identified by PII.
Social media information can also contain a substantial amount of other sensitive information about individuals, including religious affiliation, political opinion, health information, and sexual orientation. This information can be explicit (e.g., a statement that “I am a Catholic”) or it can be inferred from other information in the data (e.g., weekly Sunday geolocation check-ins at a Catholic church).
- What is the technology supposed to do with the data?
-
Let’s assume that your social media analysis technology is designed to scrape data from social media based on product mentions to allow corporate users to gain a better understanding of those users and their influence (possibly in order to engage with those users on some level to help promote the product). For example, the technology might search through social media platforms for all mentions of Brand X soda products and collect those mentions (in status updates, user profiles, etc.) as well as other public information about those users (demographic information, social network, etc.). The Brand X manufacturer can then analyze that data in order to understand the appeal of their product, gauge the effect of their advertising strategies, and evaluate the utility of social media as an advertising vehicle.2
- What could the technology do with the data?
-
The technology will be working with significant amounts of unstructured data in the form of status updates, free-form profiles, and other such information, depending on the nature of the platform. Consequently, the technology will very likely collect more information than just that relevant to soda consumption. For example, references to Brand X might be included with a laundry list of other “Favorite Things” in a user profile. Alternatively, Brand X might be referenced in a context irrelevant to soda preference (e.g., “We were drinking Brand X that night when…”). Included in this over-collection of data could be sensitive information that most social media users would not expect (or condone) a private company with which the user has no pre-existing relationship to hold.
For social media platforms that do not require users to identify themselves but instead allow them to use pseudonymous handles, it may nonetheless be possible to identify individuals based on the aggregation of data points within the profile and posts on the platform (or even by comparing information on the platform with identified activities on other platforms or even outside the digital world). In addition, sophisticated data analytics could potentially expose other, nonobvious information about social media users based on the data collected, such as sexual orientation and religion (based on social network connections)3 or even health conditions such as pregnancy.4 These types of discoveries could strike many of the people located by such an analysis as disconcerting.
Also note the possibility of unsanctioned use of the data by analysts and other individuals with access to your technology. Any of the above analysis could be directed against individuals with a connection to the analyst and used to steal an identity or track the person with the intent to harass or cause physical harm.
- What are the potential privacy concerns?
-
Each function or potential function above can raise privacy concerns, including the following:
-
Identify when a product is mentioned on a social media platform: Although social media users should be aware that information not protected by privacy controls is public, they may nonetheless not intend for extensive personal information about them to be collected and maintained by third parties.
-
Identify the “influencers”—those whose comments reach the widest audience of social media consumers: Even when social media users call attention to themselves by explicitly tagging a consumer product manufacturer or distributor, the collection of information regarding their social networks involves the collection of information on individuals who have no wish for the entity to collect and maintain information about them. They may even be completely unaware that someone in their social network mentioned the consumer product and therefore may have exposed them to such collection and analysis.
-
Identify anonymous users based on particular data in the collected information: Users who wished to remain anonymous may find those preferences thwarted by data analytics those users do not even know exist. Identification of those users could have severe consequences for those individuals, especially if they rely on their anonymity for some purpose, such as avoiding political persecution.
-
Derive nonobvious information about social media users: Users of social media who do not protect their activity through privacy controls presumably make a conscious choice to share this information with some audience. Derivation of nonobvious information may thwart user intent by revealing information about them that they have not knowingly shared (and may not ever have intended to make public).
-
Tracking and analysis of individuals for unsanctioned purposes (harassment, stalking, etc.): This one should be self-explanatory. Any unwanted attention experienced by an individual infringes on their right to privacy.
-
- How can you configure your building blocks to address those issues?
-
Each privacy concern requires separate consideration:
-
Personal data collected without users’ consent: Obtaining individual consent for the use of the data would be advisable—and indeed is a core tenet of the FIPPs. Conditional access controls could be configured to only provide analysts access to the data if there is a record of consent in the system (or, if there is an indication of consent in the data itself, such as the tagging of Brand X in the social media activity).5
-
Collecting additional, nonuser personal information: Adoption of granular, cell-level security controls would allow data stewards to remove identifying information from the social media data while still reaping analytic benefits from the data collected. Granular data management could also allow for the removal of any information from the data not directly relevant to the analysts’ interests.
-
Piercing anonymity: The identification of deidentified data generally requires analysis to be run against additional data sets to those containing the anonymous data. Put another way, in order to determine identity, you must compare your data to a data set with some identifying information. Functional access controls could be used to limit (or prevent altogether) the export of data in an electronic form that can then be processed against an identified data set.
-
Derivation of unintentionally disclosed information: Such derivations can be produced in a variety of ways depending on the data in question, so there may be a variety of potential solutions. In general, the best strategy is to prevent the aggregation of the data necessary to arrive at these conclusions. Table-level access controls or federated system architecture can be used to keep potentially revelatory data sets apart. Temporal access controls might also limit the number of available data points available to drive accurate mosaic analysis.
-
Misuse of data: Audit logs should be configured to provide enough information to ensure accountability for anyone attempting to use the system to intentionally violate an individuals’ privacy.
-
Use Case #2: Secure Messaging
Communications that are secure from eavesdropping, copying by a provider, or legal intercept (a fancy term for government wiretapping) have value to certain consumers. In this use case, we consider a hypothetical secure messaging application.
- The technology
-
You’re building a secure messaging service that allows users to exchange messages (not unlike email—but without all the legacy compatibility requirements). Users will interact with the messaging service either through a smartphone app or by using a traditional web application to securely exchange messages in a manner that is resistant to any sort of eavesdropping by virtue of sophisticated cryptography as it travels through the service.
- Does this technology interact with personally identified or identifiable information?
-
Yes, absolutely. The service directly interacts with personal identifiable addresses that correspond to each user as well as the message traffic itself. In addition, the service will necessarily have access to the metadata (things like their IP address, pattern of recipients, time and frequency of messaging), which contain information about how those messages arrive to and are delivered through the messaging services infrastructure.
- What is the technology supposed to do with data?
-
Usually, a system with privacy controls aims to strategically equip its users with limited access to data about other people. The privacy adversary is the users of the system. But in this case, that model is flipped, with the system itself being considered the adversary. First, your product must ensure that the contents of the messages are protected from the service itself, not to mention any entity that could compromise the service through technical (hacking) or legal (warrant, subpoena, or seizure by a government entity) means. Second, the service must minimize the privacy risk incurred by the metadata to the greatest extent possible while still operating the service. Here, risk can be mitigated by a careful collection and minimization strategy. Metadata necessary to operate the service will be collected and held as briefly as possible.
- What could the technology do with the data?
-
If the security aspects of this system fail and data could actually be accessed by unauthorized parties, then it could become a durable archive of all the message traffic in the system as well as the metadata about when and where the messages originated from—essentially, exactly the same as the traditional email services that users explicitly sought to avoid. By looking at the contents of the message traffic, it could be used to deliver targeted ads. It could also enable re-identification of the individuals using the system, even when they have provided no personal identifiers in the creation of their accounts. Re-identification and location tracking can also occur through metadata, without access to message content. Even if users sign up to the service using pseudonyms, metadata can all be used to re-identify them in the dataset when correlated with other datasets where they are already identified. Finally, in a breach of the system, the sensitive information in the message content could be publicly released or privately stolen for nefarious purposes.
- What are the potential privacy concerns?
-
Various privacy concerns are connected to different parts of the system, and should be mitigated separately. These concerns include:
-
Loss of confidentially of the message contents: This risk applies to any user of the system once someone else (ranging from the service operator, to a law enforcement official, to a cyber attacker), gains access to the contents of a message via the services’ infrastructure.
-
Re-identification using message contents: Aside from leaking the potentially sensitive information in the messages themselves, the message contents could be used in re-identification. Combining specific details revealed in messages with other sources could identify the entities involved in any given message exchange.
-
Re-identification using metadata: A combination of timestamps and IP address information can be used to uniquely identify individuals sending messages by cross-referencing or inference using other data sets like ISP logs or social network analysis.6
-
- How can you configure your building blocks to address those issues?
-
Let’s look at how the privacy risks outlined can be addressed through architectural decisions:
-
Loss of confidentially of the message contents and re-identification using message contents: To ensure that contents of the messages will not be compromised, we can apply encryption to the message traffic. Keeping the messages safe from the service means never allowing an unencrypted message to cross the service infrastructure.
Using public-key cryptography, each instance of the client software will generate its own public and private key pair, and store the private key while publishing the public key via the secure messaging-service infrastructure or some other key distribution service (see Figure 11-1). Key exchange poses a significant problem, especially given the threat of government coercion to surrender keys.7 Handling private keys is a delicate business. Today, some smartphones have specialized hardware for securely storing private keys that can simplify this task for native applications. In web browsers, there is no safe way to do secure cryptography in Javascript,8 but there are browser plugins that can safely store secret keys and securely run cryptographic functions.
The benefit of using public and private keys is that the client code can fully encrypt the messages before giving them to service infrastructure. Each sent message will consist of the intact list of recipients and the encrypted message. By ensuring the message contents remain confidential, the first two privacy risks are mitigated.
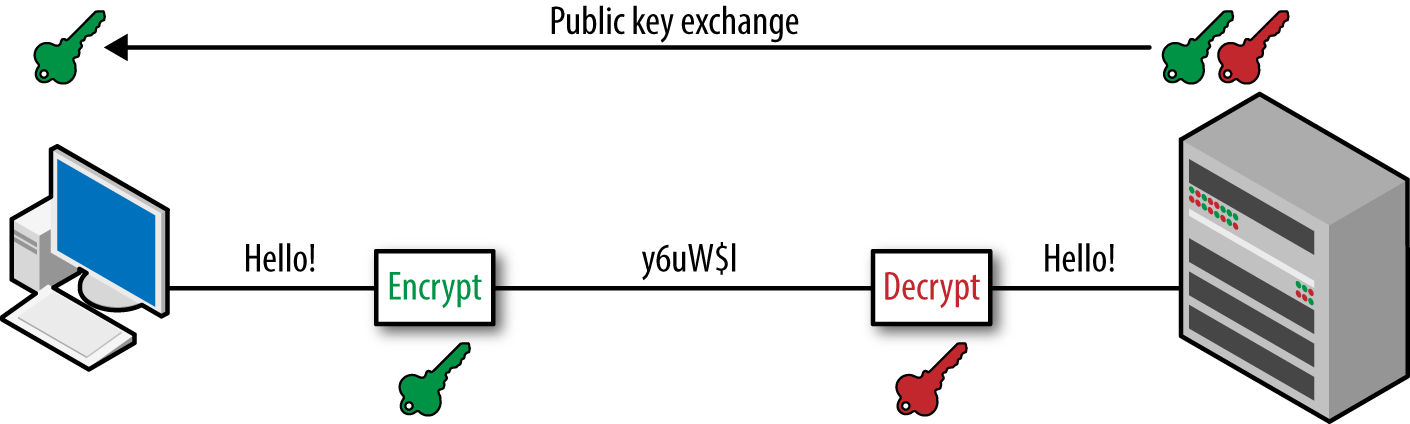
Figure 11-1. Public-key cryptography provides a common method for ensuring that message exchange occurs in a way such that an intercepted message cannot be read and that only the intended application services can make sense of the message content.
-
Re-identification using IP addresses: This risk is harder to mitigate fully using technical means. All network traffic comes with an IP address associated with it. One of the simplest ways to re-identify someone is to link their IP address to their identity using the logs of the ISP or wireless carrier that is routing the address. The logs can be used to map the lease of the IP address to a specific customer. While it requires data not held by the service infrastructure, that information is not out of reach of a government.
To mitigate this risk, start by implementing a minimization or retention policy that limits the amount of time that IP address data is held. Such a policy could reasonably range from keeping a few days of logs (for troubleshooting and performance analytics purposes) to more stringent minimization that calls for IP addresses never to be recorded (other than transiently in the operation of the infrastructure). The amount of time an IP address is held is somewhat immaterial as long as it’s reasonably short. However, this only limits privacy when studying the past. The service infrastructure can still be compelled to do logging of IP address data.
The only way to fully offset the privacy risk that an IP address represents is to never know the real IP address in the first place. The service could be designed to use a third-party VPN or proxy service, such that the service infrastructure never sees the true IP address of the clients. (Of course, your customers could choose to use such a service as well.) This will make it much more difficult to connect the use of the service to an identity-linked IP address. That said, while it may take more hops to trace IP back to its source, it’s not impossible.
An example of a way to significantly defray the risks of re-identification via IP address is to run the secure messaging service on the Tor network. Tor supports the hidden service protocol, which offers substantial anonymity in IP communications between the clients and service.9
-
Re-identification using message metadata: If a few nodes in a network of communications are compromised, it’s possible to start identifying other nodes in the network by building inferences bases on the pattern, timing, and frequency of communications between various nodes in the network. In order to remove this particular risk, you can relax the notion of durable identifiers (even pseudonymous or randomized IDs) for each user in your network and instead use a technique called mailbox chaining to make it impossible to tie one act of communication to another.
Mailbox chaining requires that existing users are able to allocate new addresses using new credentials in an automatic fashion. As each message is composed, the client allocates a new mailbox. This new mailbox address is put into the encrypted message as the next-reply address—should the recipient wish to respond, the response is sent to this address. Since the link between the initial address and the next-reply address is established inside the encrypted message, the link can be considered secret. If each reply also comes from a new address, no two acts of communication can be easily linked via identifiers. The upshot here is that instead of a graph of communications that can be analyzed, the whole system just looks like messages exchanged between single-use addresses.
-
Use Case #3: Automated License Plate Readers (ALPR)
Law enforcement agencies are increasingly using automated recognition of license plates to assist in emergency and investigative workflows. The ability to capture license plate “reads” and associate them with the geo-temporal information of the time of the reading can help determine whether vehicles may have been involved in suspected criminal activity. The growing ubiquity of these mass surveillance tools has generated much concern in certain quarters. In this use case, we explore the hypothetical implementation of such a technology.
- The technology
-
You’re a technology administrator for your local police department and have received a federal grant to purchase automated license plate reader (ALPR) devices to deploy either on your department’s vehicles or at fixed public locations throughout your municipality. You are also responsible for establishing a framework for utilizing the license plate reads captured by these devices. You’re aware of the concerns raised by civil liberties advocacy groups, as well as questions raised by members of your own community in city council discussions. You’ve been directed to develop a plan to implement these capabilities in a way that is responsive to privacy concerns, but that also provides your law enforcement officers and analysts with the tools to fulfill their legitimate responsibility to public safety.
- Does this technology interact with personally identified or identifiable information?
-
On the surface, ALPR data might appear to be a form of anonymized, nonidentifying information. The data captured by license plate readers is limited to images of license plates that are digitally processed to extract license plate alphanumeric characters, augmented with the capture event metadata (including geo-location, timestamps, and the type of device used for collection) and indexed for ease of recall. Though the license plate number itself is not directly personally identifying, the ability to somewhat readily link that plate with its owner (through vehicle registry or other data sources) may be construed in some jurisdictions as creating effectively personally identifying information.10 Moreover, the images captured by these devices may, however rarely, inadvertently capture unequivocally identifying information, such as faces of drivers.
- What is the technology supposed to do with data?
-
ALPR systems can assist law enforcement agencies by allowing them to identify and locate vehicles of interest during authorized investigative activity. Here, the primary privacy “adversary” is typically the ALPR user. A secondary “adversary” could be a potential unauthorized intruder who manages to gain access to the system. Providing safeguards to minimize over-collection, unwarranted use, repurposing, and unnecessary retention and dissemination of data, as well as critical security measures can protect privacy interests.
- What could the technology do with the data?
-
In an unregulated environment, community members and privacy advocates may worry that the system could be used to support a ubiquitous surveillance regime for tracking the movements of innocent community members and suspected criminals alike. Concerns around law enforcement officers tracking protesters attending constitutionally protected political events or ex-spouses being tracked by the scorned have already generated media attention.11 Detractors may assert that expansive collection of ALPR data undermines reasonable expectations of privacy in public spaces (i.e., on public roads) and that unfettered usage and indefinite retention offends proportionality principles. Furthermore, lack of understanding and accountability measures in place to oversee use of ALPR systems will likely only exacerbate these concerns and further undermine public trust in law enforcement agencies.
- What are the potential privacy concerns?
-
The privacy concerns and community interests mentioned above should be treated discretely to begin to work toward appropriate mitigation strategies in designing such a system. Those concerns are:
-
Overly-broad collection of ALPR data: ALPR units are unsophisticated in the sense that they operate by performing blanket image collection and processing based strictly on where they are located. They do not discriminate with regard to vehicle types and, unless they are turned on and off according to some prescribed collection regime, make no distinction between collecting plate reads for vehicles that may be the subject of suspicious activity or criminal investigation and reads for vehicles that have no suspect involvements. Proponents of ALPR systems argue that since these devices operate in public spaces, they are doing nothing more than taking photographs and processing images in the public sphere. Opponents argue that the volume and efficiency with which these devices operate makes them transcend manual image collection. Additionally, the ability to piece together a mosaic of such images across potentially expansive regions (limited only by the number and placement of these devices) creates novel concerns about reasonable expectations of privacy in the public domain.
-
Misidentification of license plates: ALPR reader units rely on optical character recognition (OCR) to translate images of license plates into text that can then be indexed and searched. While OCR technology may have advanced to the point of providing a reasonably high rate of translation fidelity, errors still occur in cases of unfamiliar or out-of-state plates, inclement weather conditions, obfuscation of characters, and other situations. Such erroneous reads can cause vehicles (and their drivers) that have no connection to a law enforcement investigation to be inadvertently implicated in criminal activity.12
-
Re-identification of ALPR data: Though ALPR data and license plates may not be directly personally identifying, the format and structure of the data may be such that linking the ALPR data through other information and analysis systems could make personal identification little more than a trivial step beyond the initial data collection event.
-
Abuse of ALPR data for unauthorized and illegal applications: Advocacy groups may concede to the value of using ALPR reads in the investigation of vehicles that are suspected of involvement in active criminal cases. However, they might worry that departments will allow scope creep to present new uses of the data that have not been formerly authorized. The data could also be misused by bad actors within departments for tracking vehicles with no legitimate justification for inquiry (e.g., the jealous officer tracking the ex-spouse).
-
Indefinite retention of ALPR data exacerbating other privacy concerns over time: The compounding storage of historical ALPR data may raise concerns that data collected without any initial suspicion of criminal involvement is applied many months later to investigations or character assessments that could not have been warranted at the time of initial collection. The ability to potentially construct patterns of life of community members may also raise fears of a repressive surveillance state that may have a chilling effect on constitutionally protected activities, such as free assembly.
-
- How can you configure your building blocks to address those issues?
-
Let’s explore these risks individually and evaluate design considerations that might be applied to help address each concern:
-
Overly-broad collection of ALPR data: The collection concern is difficult to fully resolve. While protocols might be placed to prohibit the placement of ALPR cameras on private properties or near sensitive institutions and locations, data is still likely to be collected that implicates an overwhelming majority of vehicles that may never have any connection to a legitimate law enforcement investigation. If, at a policy level, administrators are willing to accept that extraneous ALPR reads are going to be unavoidably captured, the most important privacy mitigations will need to be addressed by analysis and retention practices.
-
Misidentification of license plates: ALPR misidentification instances can be reduced or avoided altogether rather easily. Officers who need ALPR information must compare the alphanumeric readout to the image from which the license-plate characters were derived and ensure a proper match. Simple system design choices, such as creating dynamic icons that incorporate the ALPR image for each record and display them prominently alongside the OCR-derived license plate text, can ensure the visual inspection process does not needlessly impede investigative workflows.
-
Re-identification of ALPR data: The ability to readily associate other identifying vehicle records (e.g., vehicle registry information) with ALPR data may motivate additional authorizations at the point of drawing in re-identifying data. The ALPR analysis capability may therefore be configured in such a way that allows analysts or users to search for raw license plate numbers, but in order to further associate numbers of interest with identifying records, analysts may need to document or certify some motivating level of suspicion, a case number, or other formalized authorization.
-
Abuse of ALPR data for unauthorized and illegal applications: Controlling for unauthorized and illegal applications of ALPR data is an exemplary reason for using purpose- and/or scope-driven revelation practices. By codifying specific purposes for use of ALPR data, queries against the system can be configured such that users must submit an authorized search purpose. The purpose entered may then be used to further limit the set of results according to geo-spatial or temporal constraints associated with each permitted purpose.
While purpose-driven data revelation may be required to run a search query, it doesn’t explicitly prevent a nefarious user from falsely entering a search purpose in order to return desired results that may not be authorized for the investigation at hand. However, there’s a good chance the affirmative purpose entry requirement will prompt the user to think twice about deception. Moreover, entering a false search purpose should be logged by the system’s audit trails to ensure that subsequent administrative or supervisory inquiries have a reliable record to draw upon when holding the user accountable for malfeasance.
In environments where a history of ALPR records abuse warrants heightened and proactive scrutiny of user searches, the system can be configured to require per-query supervisor review and authorization process prior to returning the requested results. By introducing a layer of manual review that is bound to generate analysis latency, the system introduces a tradeoff between workflow efficiency and active oversight. This tradeoff may not be tolerable for agencies where timely results are mission critical. But it may provide a tolerable compromise for agencies that may otherwise be stripped of ALPR data access without a more aggressive review regime.
-
Indefinite retention of ALPR data exacerbating other privacy concerns over time: In order to decide whether ALPR data should be retained and for how long, you should first examine the justifications for using that data. If, for example, your ALPR data collection is warranted strictly for running the license plate numbers against a known set of vehicles associated with previously identified crimes, you only need to keep the data for the time that it takes to complete those “hotlist” checks. Afterward, nonmatching ALPR reads can be purged.
On the other hand, if your department insists on the value of retaining historical ALPR data in order to inform potential future investigations, you may want to conduct an empirical analysis of investigations involving ALPR data to set sensible polices for retaining the data. If such an analysis reveals, for example, a sharp drop in the utility of ALPR data that is 18 months old or more, this can serve as a strong, data-driven justification to establish 18 months as the limit in an overarching retention policy. After 18 months, you then may choose to adopt an appropriate deletion method from among the options outlined in Chapter 10 and as required by policy and other practical considerations.
-
Conclusion
These examples should provide you with a rough idea for how to think about privacy in the context of designing and building a product. They aren’t perfect; the various mitigations proposed in each use case do not necessarily completely address the potential privacy concerns we have described. In some cases, they must be supported by other, nontechnical actions in order to be effective. In other cases, there may not be any combination of technical and policy mitigations that resolve the privacy concerns to total satisfaction. In yet other cases, there may be some completely new and better technical or policy approach that the world (or at least this book) has yet to address. How you decide to proceed with your own product will very much depend on the wider context in which you are developing it—your business objectives, your profit margins, and the numerous other nonprivacy factors you have to weigh as you create your product.
1 Be aware that a website’s Terms of Service may restrict the scraping of this type of data without permission from the website owners, and violation of those Terms of Service may expose you and/or your customers to criminal and civil liability. Be sure to read the Terms of Service and obtain consent where required. This is one of those situations where you absolutely should check with a lawyer before investing too much time and money in your product.
2 Not all social media scraping tools have to be used for corporate benefit. Another use could be for public health insights, such as conducting social media monitoring, along with computational linguistics and machine learning, to identify early warning signs of a possible epidemic by tracking references to particular diseases or symptoms, and reasoning where the people who mentioned them are located. Such insight could be extremely useful to society at large but still unnerving to individuals.
3 Carter Jernigan and Behram F.T. Mistree, “Gaydar: Facebook Friendships Expose Sexual Orientation”. First Monday, October 5, 2009.
4 Duhigg, Charles. “How Companies Learn Your Secrets”. The New York Times. February 18, 2012.
5 Social media platforms would argue that they obtain valid consent for broad data usage from users who consent to their Terms of Service when signing up for the platform. There is an ongoing debate as to whether such consent should be considered sufficient—a debate we will refrain from entering into here. The alternative—obtaining valid, informed consent from individuals at scale—would be a significant and costly logistical challenge. But as with all such technical challenges, perhaps it only awaits the right innovator to devise a solution.
6 We are referring specifically to the academic discipline of social network analysis (SNA), which studies communications graphs to glean inferences about identity, community structure, and status. A different method of re-identification using the metadata mentioned here is traffic analysis of log data and correlating timing of events, which need not look at a social graph.
7 For one novel approach to the difficult problem of key exchange, see the documentation of the CONIKS service.
8 See “Javascript Cryptography Considered Harmful” for a full breakdown of why Javascript cryptography is not currently an option.
9 The developers of Tor (formerly TOR, the since-deprecated acronym for The Onion Router) acknowledge that, despite Tor’s great strengths, there are still re-identification risks in certain specific circumstances, such as end-to-end traffic correlation if an ISP has records of the exact times users were online, or coarse-grained activity matching to correlate time periods of Tor use with time periods of activity occurrence that match multiple times. Nevertheless, Tor is often a good choice for protecting a user’s location and defending against IP address metadata analysis.
10 Ease of linking ALPR reads to vehicle registry information should not be universally assumed. Some jurisdictions place particularly firm restrictions on law enforcement agencies’ abilities to access DMV records such as vehicle registries outside of specific procedural contexts that exclude many ALPR use cases. On the other hand, many law enforcement agencies do have access to DMV registries, and barring these kinds of jurisdictional restrictions, they can connect DMV records to ALPR reads without too much effort—and certainly far more easily than the general public.
11 Crump, Catherine. “Police Documents on License Plate Scanners Reveal Mass Tracking”. American Civil Liberties Union. July 17, 2013.
12 See Green v. California for an example of a law enforcement vehicular stop in which the misidentification of a single character in a license plate led to the plaintiff’s vehicle being falsely identified and the plaintiff held at gunpoint.