
Chapter 13. State Machines
We have mentioned workflows several times in the preceding chapters. A workflow can be simply defined as a sequence of operations or steps that make up a work process. Many tasks that we perform as cloud or systems administrators can be broken down into simple workflow steps:
-
Do something.
-
Do something.
-
Do something.
CloudForms Automate allows us to add intelligence to our workflow steps by defining steps as states. Each state is capable of performing pre and postprocessing around the main task, and can handle and potentially recover from errors that occur while performing the task (see Table 13-1). Individual states can enter a retry loop, with the maximum number of retries and overall timeout for the state being definable.
| Step | On entry | Task | On exit | On error |
|---|---|---|---|---|
1 |
Preprocess before doing something. |
Do something. |
Postprocess after doing something. |
Handle any errors while doing something. |
2 |
Preprocess before doing something. |
Do something. |
Postprocess after doing something. |
Handle any errors while doing something. |
3 |
Preprocess before doing something. |
Do something. |
Postprocess after doing something. |
Handle any errors while doing something. |
When we assemble several of these intelligent states together, it becomes an Automate state machine. The logic flow through an Automate state machine is shown in Figure 13-1.

Figure 13-1. Simple Automate state machine workflow
Building a State Machine
We build an Automate state machine in much the same way that we define any other class schema. One of the types of schema field is a state, and if we construct a class schema definition comprising a sequence of states, this then becomes a state machine.
Tip
A state machine schema should comprise only assertions, attributes, or states. We should not have any schema lines that have a Type field of Relationship in a state machine.
State Machine Schema Field Columns
If we look at all of the attributes that we can add for a schema field, in addition to the familar Name, Description, and Value headings, we see a number of column headings that we haven’t used so far (see Figure 13-2).

Figure 13-2. Schema field column headings
The schema columns for a state machine are the same as in any other class schema, but we use more of them.
Value (instance)/Default Value (schema)
As in any other class schema, this value is a relationship to an instance to be run to perform the main processing of the state. Surprising as it may seem, we don’t necessarily need to specify a value here for a state machine (see On Entry, next), although it is good practice to do so.
On Entry
We can optionally define an On Entry method to be run before the “main” method (the Value entry) is run. We can use this to set up or test for preconditions to the state; for example, if the “main” method adds a tag to an object, the On Entry method might check that the category and tag exist.
The method name can be specified as a relative path to the local class (i.e., just the method name), or in namespace/class/method syntax.
Note that some older state machines, such as /Infrastructure/VM/Provisoning/StateMachines/ProvisionRequestApproval/, use an On Entry method instead of a Value relationship to perform the main work of the state. This usage is deprecated, and we should always use a Value relationship in our state machines.
State Machine Example
We can look at the out-of-the-box /Infrastructure/VM/Provisoning/StateMachines/ProvisionRequestApproval/Default state machine instance as an example and see that it defines four attributes and has just two states: ValidateRequest and ApproveRequest (see Figure 13-3).
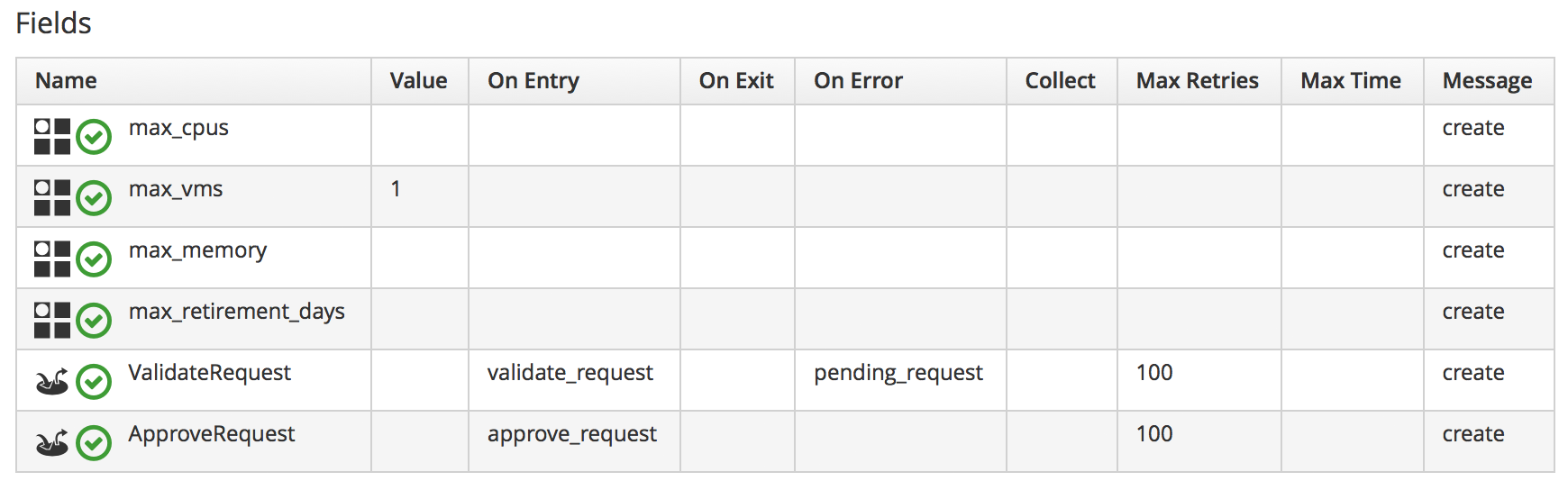
Figure 13-3. The /ProvisionRequestApproval/Default state machine
Neither state has a Value relationship, but each runs a locally defined class method to perform the main processing of the state.
The ValidateRequest state runs the validate_request On Entry method and pending_request as the On Error method.
The ApproveRequest state runs the approve_request On Entry method.
State Variables
There are several state variables that can be read or set by state methods to control the processing of the state machine.
Setting State Result
We can run a method within the context of a state machine to return a completion status to the Automation Engine, which then decides which next action to perform (such as whether to advance to the next state).
We do this by setting one of three values in the ae_result hash key:
# Signal an error$evm.root['ae_result']='error'$evm.root['ae_reason']="Failed to do something"# Signal that the step should be retried after a time interval$evm.root['ae_result']='retry'$evm.root['ae_retry_interval']='1.minute'# Signal that the step completed successfully$evm.root['ae_result']='ok'
State Machine Enhancements in CloudForms 4.0
Several useful additions to state machine functionality were added in CloudForms 4.0.
Jumping to a Specific State
Any of our state machine methods can set $evm.root['ae_next_state'] = <state_name> to allow the state machine to advance several steps.
Note that setting ae_next_state allows us only to go forward in a state machine. If we want to go back to a previous state, we can restart the state machine but set ae_next_state to the name of the state at which we want to restart. When issuing a restart, if we do not specify ae_next_state, the state machine will restart at the first state:
# Currently in state4$evm.root['ae_result']='restart'$evm.root['ae_next_state']='state2'
Nested State Machines
As has been mentioned, the Value field of a state machine should be a relationship to an instance. Prior to CloudForms 4.0 this could not be another state machine, but with 4.0 this requirement has been lifted, so now we can call an entire state machine from a step in a parent state machine (see Figure 13-4).

Figure 13-4. Nested state machines
Saving Variables Between State Retries
When a step is retried in a state machine, the Automation Engine reinstantiates the entire state machine, starting from the state issuing the retry.
Note
This is why state machines should not contain lines that have a Type field of Relationship. A state is a special kind of relationship that can be skipped during retries. If we had a Relationship line anywhere in our state machine, then it would be rerun every time a later state issued a $evm.root['ae_result'] = 'retry'.
This reinstantiation makes life difficult if we want to store and retrieve variables between steps in a state machine (something we frequently want to do). Fortunately, there are three $evm methods that we can use to test for the presence of, save, and read variables between reinstantiations of our state machine:
$evm.set_state_var(:server_name,"myserver")if$evm.state_var_exist?(:server_name)server_name=$evm.get_state_var(:server_name)end
We can save most types of variables, but because of the dRuby mechanics behind the scenes, we can’t save hashes that have default initializers—for example:
my_hash=Hash.new{|h,k|h[k]={}}
Here the |h, k| h[k] = {} is the initializer function.
Summary
State machines are incredibly useful, and we often use them to create our own intelligent, reusable workflows. They allow us to focus on the logic of our state methods, while the Automation Engine handles the complexity of the on-entry and on-exit condition handling and the state retry logic.
When deciding whether to implement a workflow as a state machine, consider the following:
-
Could I skip any of my workflow steps by intelligently preprocessing?
-
Would my code be cleaner if I could assume that preconditions had been set up or tested before entry?
-
Might any of my workflow steps result in an error that could possibly be handled and recovered from?
-
Do any of my workflow steps require me to retry an operation in a wait loop?
-
Do I need to put a timeout on my workflow completing?
If the answer to any of these questions is yes, then a state machine is a good candidate for implementation.