


Maintaining Strong Ordering Guarantees
While it often isn’t the case for analytics use cases, most business systems need strong ordering guarantees. Say a customer makes several updates to their customer information. The order in which these updates are processed is going to matter, or else the latest change might be overwritten with one of the older, out-of-date values.
There are a couple of things that need to be considered to ensure strong ordering guarantees. The first is that messages that require relative ordering need to be sent to the same partition. (Kafka provides ordering guarantees only within a partition.) This is managed for you: you supply the same key for all messages that require a relative order. So a stream of customer information updates would use the CustomerId as their partitioning key. All messages for the same customer would then be routed to the same partition, and hence be strongly ordered (see Figure 4-3).
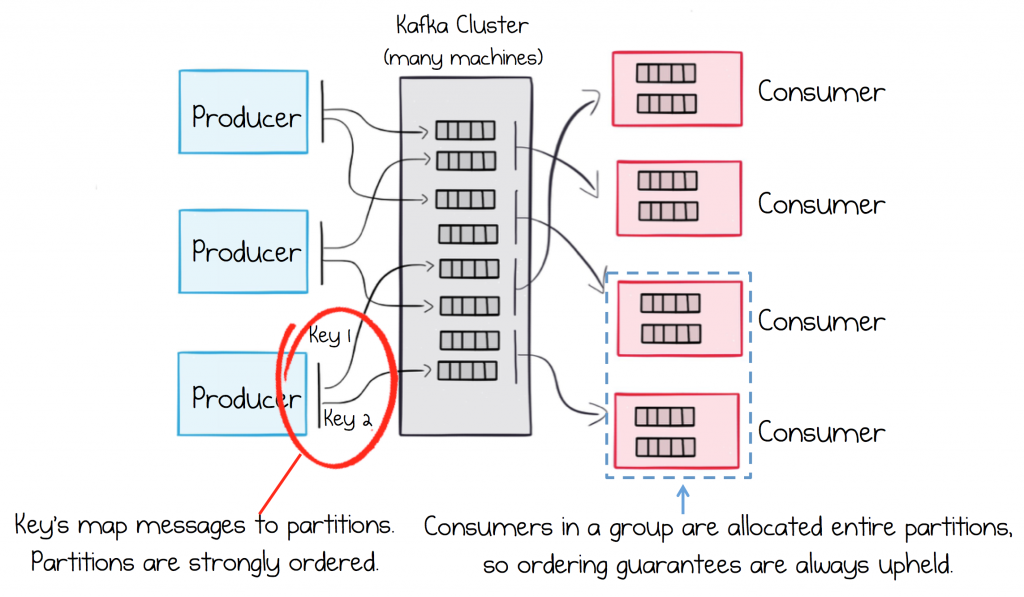
Figure 4-3. Ordering in Kafka is specified by producers using an ordering key
Sometimes key-based ordering isn’t enough, and global ordering is required. This often comes up when you’re migrating from legacy messaging systems where global ordering was an assumption of the original system’s design. To maintain global ordering, use a single partition topic. Throughput will be limited to that of a single machine, but this is typically sufficient for use cases of this type.
The second thing to be aware of is retries. In almost all cases we want to enable retries in the producer so that if there is some network glitch, long-running garbage collection, failure, or the like, any messages that aren’t successfully sent to the cluster will be retried. The subtlety is that messages are sent in batches, so we should be careful to send these batches one at a time, per destination machine, so there is no potential for a reordering of events when failures occur and batches are retried. This is simply something we configure.

