
Chapter 8. Sharing Data and Services Across an Organization
When we build software, our main focus is, quite rightly, aimed at solving some real-world problem. It might be a new web page, a report of sales features, an analytics program searching for fraudulent behavior, or an almost infinite set of options that provide clear and physical benefits to our users. These are all very tangible goals—goals that serve our business today.
But when we build software we also consider the future—not by staring into a crystal ball in some vain attempt to predict what our company will need next year, but rather by facing up to the fact that whatever does happen, our software will need to change. We do this without really thinking about it. We carefully modularize our code so it is comprehensible and reusable. We write tests, run continuous integration, and maybe even do continuous deployment. These things take effort, yet they bear little resemblance to anything a user might ask for directly. We do these things because they make our code last, and that doesn’t mean sitting on some filesystem the far side of git push. It means providing for a codebase that is changed, evolved, refactored, and repurposed. Aging in software isn’t a function of time; it is a function of how we choose to change it.
But when we design systems, we are less likely to think about how they will age. We are far more likely to ask questions like: Will the system scale as our user base increases? Will response times be fast enough to keep users happy? Will it promote reuse? In fact, you might even wonder what a system designed to last a long time looks like.
If we look to history to answer this question, it would point us to mainframe applications for payroll, big-name client programs like Excel or Safari, or even operating systems like Windows or Linux. But these are all complex, individual programs that have been hugely valuable to society. They have also all been difficult to evolve, particularly with regard to organizing a large engineering effort around a single codebase. So if it’s hard to build large but individual software programs, how do we build the software that runs a company? This is the question we address in this particular section: how do we design systems that age well at company scales and keep our businesses nimble?
As it happens, many companies sensibly start their lives with a single system, which becomes monolithic as it slowly turns into the proverbial big ball of mud. The most common response to this today is to break the monolith into a range of different applications and services. In Chapter 1 we talked about companies like Amazon, LinkedIn, and Netflix, which take a service-based approach to this. This is no panacea; in fact, many implementations of the microservices pattern suffer from the misconceived notion that modularizing software over the network will somehow improve its sustainability. This of course isn’t what microservices are really about. But regardless of your interpretation, breaking a monolith, alone, will do little to improve sustainability. There is a very good reason for this too. When we design systems at company scales, those systems become far more about people than they are about software.
As a company grows it forms into teams, and those teams have different responsibilities and need to be able to make progress without extensive interaction with one another. The larger the company, the more of this autonomy they need. This is the basis of management theories like Slack.1
In stark contrast to this, total independence won’t work either. Different teams or departments need some level of interaction, or at least a shared sense of purpose. In fact, dividing sociological groups is a tactic deployed in both politics and war as a mechanism for reducing the capabilities of an opponent. The point here is that a balance must be struck, organizationally, in terms of the way people, responsibility, and communication structures are arranged in a company, and this applies as acutely to software as it does to people, because beyond the confines of a single application, people factors invariably dominate.
Some companies tackle this at an organizational level using approaches like the Inverse Conway Maneuver, which applies the idea that, if the shape of software and the shape of organizations are intrinsically linked (as Conway argued), then it’s often easier to change the organization and let the software follow suit than it is to do the reverse. But regardless of the approach taken, when we design software systems where components are operated and evolved independently, the problem we face has three distinct parts—organization, software, and data—which are all intrinsically linked. To complicate matters further, what really differentiates the good systems from the bad is their ability to manage these three factors as they evolve, independently, over time.
While this may seem a little abstract, you have no doubt felt the interplay between these forces before. Say you’re working on a project, but to finish it you need three other teams to complete work on their side first—you know intuitively that it’s going to take longer to build, schedule, and release. If someone from another team asks if their application can pull some data out of your database, you know that’s probably going to lead to pain in the long run, as you’re left wondering if your latest release will break the dependency they have on you. Finally, while it might seem trivial to call a couple of REST services to populate your user interface, you know that an outage on their side is going to mean you get called at 3 a.m., and the more complex the dependencies get, the harder it’s going to be to figure out why the system doesn’t work. These are all examples of problems we face when an organization, its software, and its data evolve slowly.
The Microservices pattern is unusually opinionated in this regard. It comes down hard on independence in organization, software, and data. Microservices are run by different teams, have different deployment cycles, don’t share code, and don’t share databases.2 The problem is that replacing this with a web of RPC/REST calls isn’t generally a preferable solution. This leads to an important tension: we want to promote reuse to develop software quickly, but at the same time the more dependencies we have, the harder it is to change.
Note
Reuse can be a bad thing. Reuse lets us develop software quickly and succinctly, but the more we reuse a component, the more dependencies that component has, and the harder it is to change.
To better understand this tension, we need to question some core principles of software design—principles that work wonderfully when we’re building a single application, but fare less well when we build software that spans many teams.
Encapsulation Isn’t Always Your Friend
As software engineers we’re taught to encapsulate. If you’re building a library for other people to use, you’ll carefully pick a contract that suits the functionality you want to expose. If you’re building a service-based system, you might be inclined to follow a similar process. This works well if we can cleanly separate responsibilities between the different services. A single sign-on (SSO) service, for example, has a well-defined role, which is cleanly separated from the roles other services play (Figure 8-1). This clean separation means that, even in the face of rapid requirement churn, it’s unlikely the SSO service will need to change. It exists in a tightly bounded context.
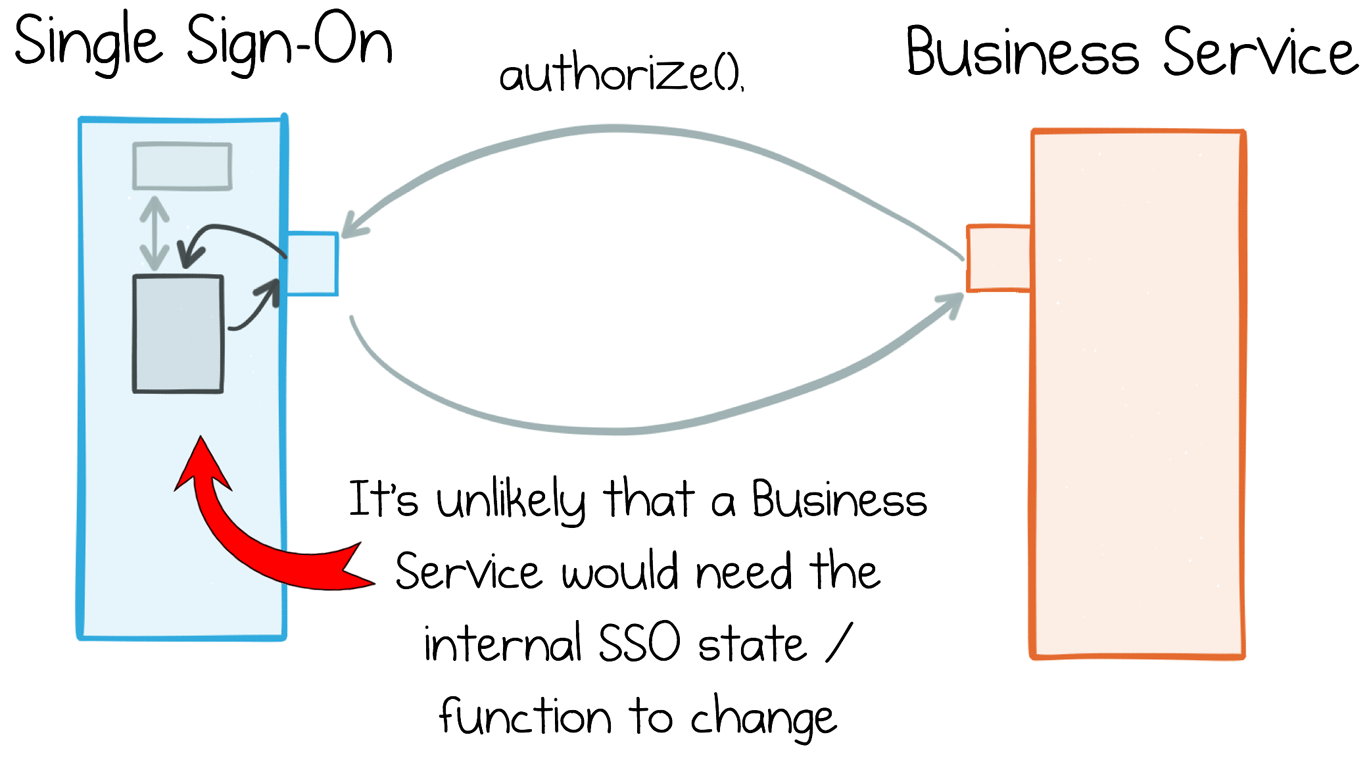
Figure 8-1. An SSO service provides a good example of encapsulation and reuse
The problem is that, in the real world, business services can’t typically retain the same clean separation of concerns, meaning new requirements will inevitably crosscut service boundaries and several services will need to change at once. This can be measured.3 So if one team needs to implement a feature, and that requires another team to make a code change, we end up having to make changes to both services at around the same time. In a monolithic system this is pretty straightforward—you make the change and then do a release—but it’s considerably more painful where independent services must synchronize. The coordination between teams and release cycles erodes agility.
This problem isn’t actually restricted to services. Shared libraries suffer from the same problem. If you work in retail, it might seem sensible to create a library that models how customers, orders, payments, and the like all relate to one another. You could include common logic for standard operations like returns and refunds. Lots of people did this in the early days of object orientation, but it turned out to be quite painful because suddenly the most sensitive part of your system was coupled to many different programs, making it really fiddly to change and release. This is why microservices typically don’t share a single domain model. But some library reuse is of course OK. Take a logging library, for example—much like the earlier SSO example, you’re unlikely to have a business requirement that needs the logging library to change.
But in reality, of course, library reuse comes with a get-out clause: the code can be implemented anywhere. Say you did use the aforementioned shared retail domain model. If it becomes too painful to use, you could always just write the code yourself! (Whether that is actually a good idea is a different discussion.) But when we consider different applications or services that share data with one another, there is no such solution: if you don’t have the data, there is literally nothing you can do.
This leads to two fundamental differences between services and shared libraries:
-
A service is run and operated by someone else.
-
A service typically has data of its own, whereas a library (or database) requires you to input any data it needs.
Data sits at the very heart of this problem: most business services inevitably rely heavily on one another’s data. If you’re an online retailer, the stream of orders, the product catalog, or the customer information will find its way into the requirements of many of your services. Each of these services needs broad access to these datasets to do its work, and there is no temporary workaround for not having the data you need. So you need access to shared datasets, but you also want to stay loosely coupled. This turns out to be a pretty hard bargain to strike.
The Data Dichotomy
Encapsulation encourages us to hide data, but data systems have little to do with encapsulation. In fact, quite the opposite: databases do everything they can to expose the data they hold (Figure 8-2). They come with wonderfully powerful, declarative interfaces that can contort the data they hold into pretty much any shape you might desire. That’s exactly what a data scientist needs for an exploratory investigation, but it’s not so great for managing the spiral of interservice dependencies in a burgeoning service estate.

Figure 8-2. Services encapsulate the data they hold to reduce coupling and aid reuse; databases amplify the data they hold to provide greater utility to their user
So we find ourselves faced with a conundrum, a dichotomy: databases are about exposing data and making it useful. Services are about hiding it so they can stay decoupled. These two forces are fundamental. They underlie much of what we do, subtly jostling for supremacy in the systems we build.
What Happens to Systems as They Evolve?
As systems evolve and grow we see the effects of this data dichotomy play out in a couple of different ways.
The God Service Problem
As data services grow they inevitably expose an increasing set of functions, to the point where they start to look like some form of kooky, homegrown database (Figure 8-3).

Figure 8-3. Service interfaces inevitably grow over time
Now creating something that looks like a kooky, shared database can lead to a set of issues of its own. The more functionality, data, and users data services have, the more tightly coupled they become and the harder (and more expensive) they are to operate and evolve.
The REST-to-ETL Problem
A second, often more common, issue when you’re faced with a data service is that it actually becomes preferable to suck the data out so it can be held and manipulated locally (Figure 8-4). There are lots of reasons for this to happen in practice, but some of the main ones are:
-
The data needs to be combined with some other dataset.
-
The data needs to be closer, either due to geography or to be used offline (e.g., on a mobile).
-
The data service displays operational issues, which cause outages downstream.
-
The data service doesn’t provide the functionality the client needs and/or can’t change quick enough.
But to extract data from some service, then keep that data up to date, you need some kind of polling mechanism. While this is not altogether terrible, it isn’t ideal either.

Figure 8-4. Data is moved from service to service en masse
What’s more, as this happens again and again in larger architectures, with data being extracted and moved from service to service, little errors or idiosyncrasies often creep in. Over time these typically worsen and the data quality of the whole ecosystem starts to suffer. The more mutable copies, the more data will diverge over time.
Making matters worse, divergent datasets are very hard to fix in retrospect. (Techniques like master data management are in many ways a Band-aid over this.) In fact, some of the most intractable technology problems that businesses encounter arise from divergent datasets proliferating from application to application. This issue is discussed in more detail in Chapter 10.
So a cyclical pattern of behavior emerges between (a) the drive to centralize datasets to keep them accurate and (b) the temptation (or need) to extract datasets and go it alone—an endless cycle of data inadequacy (Figure 8-5).

Figure 8-5. The cycle of data inadequacy
Make Data on the Outside a First-Class Citizen
To address these various issues, we need to think about shared data in a slightly different way. We need to consider it a first-class citizen of the architectures we build. Pat Helland makes this distinction in his paper “Data on the Inside and Data on the Outside.”
One of the key insights he makes is that the data services share needs to be treated differently from the data they hold internally. Data on the outside is hard to change, because many programs depend upon it. But, for this very reason, data on the outside is the most important data of all.
A second important insight is that service teams need to adopt an openly outward-facing role: one designed to serve, and be an integral part of, the wider ecosystem. This is very different from the way traditional applications are built: written to operate in isolation, with methods for exposing their data bolted on later as an afterthought.
With these points in mind it becomes clear that data on the outside—the data services share—needs to be carefully curated and nurtured, but to keep our freedom to iterate we need to turn it into data on the inside so that we can make it our own.
The problem is that none of the approaches available today—service interfaces, messaging, or a shared database—provide a good solution for dealing with this transition (Figure 8-6), for the following reasons:
-
Service interfaces form tight point-to-point couplings, make it hard to share data at any level of scale, and leave the unanswered question: how do you join the many islands of state back together?
-
Shared databases concentrate use cases into a single place, and this stifles progress.
-
Messaging moves data from a tightly coupled place (the originating service) to a loosely coupled place (the service that is using the data). This means datasets can be brought together, enriched, and manipulated as required. Moving data locally typically improves performance, as well as decoupling sender and receiver. Unfortunately, messaging systems provide no historical reference, which means it’s harder to bootstrap new applications, and this can lead to data quality issues over time (discussed in “The Data Divergence Problem” in Chapter 10).

Figure 8-6. Tradeoff between service interfaces, messaging, and a shared database
A better solution is to use a replayable log like Kafka. This works like a kind of event store: part messaging system, part database.
Note
Messaging turns highly coupled, shared datasets (data on the outside) into data a service can own and control (data on the inside). Replayable logs go a step further by adding a central reference.
Don’t Be Afraid to Evolve
When you start a new project, form a new department, or launch a new company, you don’t need to get everything right from the start. Most projects evolve. They start life as monoliths, and later they add distributed components, evolve into microservices, and add event streaming. The important point is when the approach becomes constraining, you change it. But experienced architects know where the tipping point for this lies. Leave it too late, and change can become too costly to schedule. This is closely linked with the concept of fitness functions in evolutionary architectures.4
Summary
Patterns like microservices are opinionated when it comes to services being independent: services are run by different teams, have different deployment cycles, don’t share code, and don’t share databases. The problem is that replacing this with a web of RPC calls fails to address the question: how do services get access to these islands of data for anything beyond trivial lookups?
The data dichotomy highlights this question, underlining the tension between the need for services to stay decoupled and their need to control, enrich, and combine data in their own time.
This leads to three core conclusions: (1) as architectures grow and systems become more data-centric, moving datasets from service to service becomes an inevitable part of how systems evolve; (2) data on the outside—the data services share—becomes an important entity in its own right; (3) sharing a database is not a sensible solution to data on the outside, but sharing a replayable log better balances these concerns, as it can hold datasets long-term, and it facilitates event-driven programming, reacting to the now.
This approach can keep data across many services in sync, through a loosely coupled interface, giving them the freedom to slice, dice, enrich, and evolve data locally.
1 Tom DeMarco, Slack: Getting Past Burnout, Busywork, and the Myth of Total Efficiency (New York: Broadway Books, 2001).
2 Sam Newman, Building Microservices (Sebastopol, CA: O’Reilly, 2014).
3 See https://www.infoq.com/news/2017/04/tornhill-prioritise-tech-debt and http://bit.ly/2pKa2rR.
4 Neil Ford, Rebecca Parsons, and Pat Kua, Building Evolutionary Architectures (Sebastopol, CA: O’Reilly, 2017).