
Chapter 12. Transactions, but Not as We Know Them
Kafka ships with built-in transactions, in much the same way that most relational databases do. The implementation is quite different, as we will see, but the goal is similar: to ensure that our programs create predictable and repeatable results, even when things fail.
Transactions do three important things in a services context:
-
They remove duplicates, which cause many streaming operations to get incorrect results (even something as simple as a count).
-
They allow groups of messages to be sent, atomically, to different topics—for example, Order Confirmed and Decrease Stock Level, which would leave the system in an inconsistent state if only one of the two succeeded.
-
Because Kafka Streams uses state stores, and state stores are backed by a Kafka topic, when we save data to the state store, then send a message to another service, we can wrap the whole thing in a transaction. This property turns out to be particularly useful.
In this chapter we delve into transactions, looking at the problems they solve, how we should make use of them, and how they actually work under the covers.
The Duplicates Problem
Any service-based architecture is itself a distributed system, a field renowned for being difficult, particularly when things go wrong. Thought experiments like the Two Generals’ Problem and proofs like FLP highlight these inherent difficulties. But in practice the problem seems less complex. If you make a call to a service and it’s not running for whatever reason, you retry, and eventually the call will complete.
One issue with this is that retries can result in duplicate processing, and this can cause very real problems. Taking a payment twice from someone’s account will lead to an incorrect balance (Figure 12-1). Adding duplicate tweets to a user’s feed will lead to a poor user experience. The list goes on.

Figure 12-1. The UI makes a call to the payment service, which calls an external payment provider; the payment service fails before returning to the UI; as the UI did not get a response, it eventually times out and retries the call; the user’s account could be debited twice
In reality we handle these duplicate issues automatically in the majority of systems we build, as many systems simply push data to a database, which will automatically deduplicate based on the primary key. Such processes are naturally idempotent. So if a customer updates their address and we are saving that data in a database, we don’t care if we create duplicates, as the worst-case scenario is that the database table that holds customer addresses gets updated twice, which is no big deal. This applies to the payment example also, so long as each one has a unique ID. As long as deduplication happens at the end of each use case, then, it doesn’t matter how many duplicate calls are made in between. This is an old idea, dating back to the early days of TCP (Transmission Control Protocol). It’s called the end-to-end principle.
The rub is this—for this natural deduplication to work, every network call needs to:
-
Have an appropriate key that defines its identity.
-
Be deduplicated in a database that holds an extensive history of these keys. Or, duplicates have to be constantly considered in the business logic we write, which increases the cognitive overhead of this task.
Event-driven systems attempt to move away from this database-centric style of processing, instead executing business logic, communicating the results of that processing, and moving on.
The result of this is that most event-driven systems end up deduplicating on every message received, before it is processed, and every message sent out has a carefully chosen ID so it can be deduplicated downstream. This is at best a bit of a hassle. At worst it’s a breeding ground for errors.
But if you think about it, this is no more an application layer concern than ordering of messages, arranging redelivery, or any of the other benefits that come with TCP. We choose TCP over UDP (User Datagram Protocol) because we want to program at a higher level of abstraction, where delivery, ordering, and so on are handled for us. So we’re left wondering why these issues of duplication have leaked up into the application layer. Isn’t this something our infrastructure should solve for us?
Transactions in Kafka allow the creation of long chains of services, where the processing of each step in the chain is wrapped in exactly-once guarantees. This reduces duplicates, which means services are easier to program and, as we’ll see later in this chapter, transactions let us tie streams and state together when we implement storage either through Kafka Streams state stores or using the Event Sourcing design pattern. All this happens automatically if you are using the Kafka Streams API.
The bad news is that this isn’t some magic fairy dust that sprinkles exactly-onceness over your entire system. Your system will involve many different parts, some based on Kafka, some based on other technologies, the latter of which won’t be covered by the guarantee.
But it does sprinkle exactly-onceness over the Kafka bits, the interactions between your services (Figure 12-2). This frees services from the need to deduplicate data coming in and pick appropriate keys for data going out. So we can happily chain services together, inside an event-driven workflow, without these additional concerns. This turns out to be quite empowering.

Figure 12-2. Kafka’s transactions provide guarantees for communication performed through Kafka, but not beyond it
Using the Transactions API to Remove Duplicates
As a simple example, imagine we have an account validation service. It takes deposits in, validates them, and then sends a new message back to Kafka marking the deposit as validated.
Kafka records the progress that each consumer makes by storing an offset in a special topic, called consumer_offsets. So to validate each deposit exactly once, we need to perform the final two actions—(a) send the “Deposit Validated” message back to Kafka, and (b) commit the appropriate offset to the consumer_offsets topic—as a single atomic unit (Figure 12-3). The code for this would look something like the following:
//Read and validate deposits validatedDeposits = validate(consumer.poll(0)) //Send validated deposits & commit offsets atomically producer.beginTransaction() producer.send(validatedDeposits) producer.sendOffsetsToTransaction(offsets(consumer)) producer.endTransaction()

Figure 12-3. A single message operation is in fact two operations: a send and an acknowledge, which must be performed atomically to avoid duplication
If you are using the Kafka Streams API, no extra code is required. You simply enable the feature.
Exactly Once Is Both Idempotence and Atomic Commit
As Kafka is a broker, there are actually two opportunities for duplication. Sending a message to Kafka might fail before an acknowledgment is sent back to the client, with a subsequent retry potentially resulting in a duplicate message. On the other side, the process reading from Kafka might fail before offsets are committed, meaning that the same message might be read a second time when the process restarts (Figure 12-4).

Figure 12-4. Message brokers provide two opportunities for failure—one when sending to the broker, and one when reading from it
So idempotence is required in the broker to ensure duplicates cannot be created in the log. Idempotence, in this context, is just deduplication. Each producer is given an identifier, and each message is given a sequence number. The combination of the two uniquely defines each batch of messages sent. The broker uses this unique sequence number to work out if a message is already in the log and discards it if it is. This is a significantly more efficient approach than storing every key you’ve ever seen in a database.
On the read side, we might simply deduplicate (e.g., in a database). But Kafka’s transactions actually provide a broader guarantee, more akin to transactions in a database, tying all messages sent together in a single atomic commit. So idempotence is built into the broker, and then an atomic commit is layered on top.
How Kafka’s Transactions Work Under the Covers
Looking at the code example in the previous section, you might notice that Kafka’s transactions implementation looks a lot like transactions in a database. You start a transaction, write messages to Kafka, then commit or abort. But the whole model is actually pretty different, because of course it’s designed for streaming.
One key difference is the use of marker messages that make their way through the various streams. Marker messages are an idea first introduced by Chandy and Lamport almost 30 years ago in a method called the Snapshot Marker Model. Kafka’s transactions are an adaptation of this idea, albeit with a subtly different goal.
While this approach to transactional messaging is complex to implement, conceptually it’s quite easy to understand (Figure 12-5). Take our previous example, where two messages were written to two different topics atomically. One message goes to the Deposits topic, the other to the committed_offsets topic.
Begin markers are sent down both.1 We then send our messages. Finally, when we’re done, we flush each topic with a Commit (or Abort) marker, which concludes the transaction.
Now the aim of a transaction is to ensure only “committed” data is seen by downstream programs. To make this work, when a consumer sees a Begin marker it starts buffering internally. Messages are held up until the Commit marker arrives. Then, and only then, are the messages presented to the consuming program. This buffering ensures that consumers only ever read committed data.

Figure 12-5. Conceptual model of transactions in Kafka
To ensure each transaction is atomic, sending the Commit markers involves the use of a transaction coordinator. There will be many of these spread throughout the cluster, so there is no single point of failure, but each transaction uses just one.
The transaction coordinator is the ultimate arbiter that marks a transaction committed atomically, and maintains a transaction log to back this up (this step implements two-phase commit).
For those that worry about performance, there is of course an overhead that comes with this feature, and if you were required to commit after every message, the performance degradation would be noticeable. But in practice there is no need for that, as the overhead is dispersed among whole batches of messages, allowing us to balance transactional overhead with worst-case latency. For example, batches that commit every 100 ms, with a 1 KB message size, have a 3% overhead when compared to in-order, at-least-once delivery. You can test this out yourself with the performance test scripts that ship with Kafka.
In reality, there are many subtle details to this implementation, particularly around recovering from failure, fencing zombie processes, and correctly allocating IDs, but what we have covered here is enough to provide a high-level understanding of how this feature works. For a comprehensive explanation of how transactions work, see the post “Transactions in Apache Kafka” by Apurva Mehta and Jason Gustafson.
Store State and Send Events Atomically
As we saw in Chapter 7, Kafka can be used to store data in the log, with the most common means being a state store (a disk-resident hash table, held inside the API, and backed by a Kafka topic) in Kafka Streams. As a state store gets its durability from a Kafka topic, we can use transactions to tie writes to the state store and writes to other output topics together. This turns out to be an extremely powerful pattern because it mimics the tying of messaging and databases together atomically, something that traditionally required painfully slow protocols like XA.
Note
The database used by Kafka Streams is a state store. Because state stores are backed by Kafka topics, transactions let us tie messages we send and state we save in state stores together, atomically.
Imagine we extend the previous example so our validation service keeps track of the balance as money is deposited. So if the balance is currently $50, and we deposit $5 more, then the balance should go to $55. We record that $5 was deposited, but we also store this current balance, $55, by writing it to a state store (or directly to a compacted topic). See Figure 12-6.
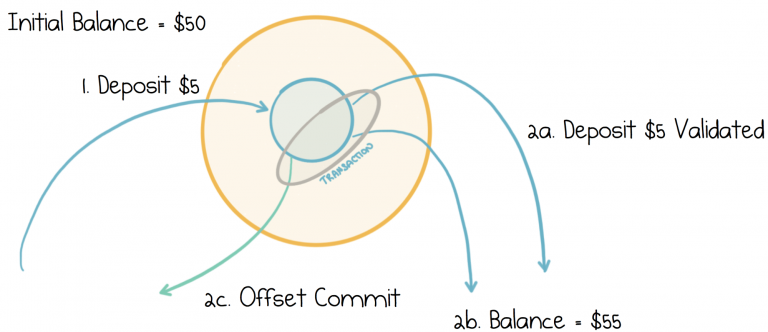
Figure 12-6. Three messages are sent atomically: a deposit, a balance update, and the acknowledgment
If transactions are enabled in Kafka Streams, all these operations will be wrapped in a transaction automatically, ensuring the balance will always be atomically in sync with deposits. You can achieve the same process with the product and consumer by wrapping the calls manually in your code, and the current account balance can be reread on startup.
What’s powerful about this example is that it blends concepts of both messaging and state management. We listen to events, act, and create new events, but we also manage state, the current balance, in Kafka—all wrapped in the same transaction.
Do We Need Transactions? Can We Do All This with Idempotence?
People have been building both event- and request-driven systems for decades, simply by making their processes idempotent with identifiers and databases. But implementing idempotence comes with some challenges. While defining the ID of an order is relatively obvious, not all streams of events have such a clear concept of identity. If we had a stream of events representing the average account balance per region per hour, we could come up with a suitable key, but you can imagine it would be a lot more brittle and error-prone.
Also, transactions encapsulate the concept of deduplication entirely inside your service. You don’t muddy the waters seen by other services downstream with any duplicates you might create. This makes the contract of each service clean and encapsulated. Idempotence, on the other hand, relies on every service that sits downstream correctly implementing deduplication, which clearly makes their contract more complex and error-prone.
What Can’t Transactions Do?
There are a few limitations or potential misunderstandings of transactions that are worth noting. First, they work only in situations where both the input and the output go through Kafka. If you are calling an external service (e.g., via HTTP), updating a database, writing to stdout, or anything other than writing to and from the Kafka broker, transactional guarantees won’t apply and calls can be duplicated. So, much like using a transactional database, transactions work only when you are using Kafka.
Also akin to accessing a database, transactions commit when messages are sent, so once they are committed there is no way to roll them back, even if a subsequent transaction downstream fails. So if the UI sends a transactional message to the orders service and the orders service fails while sending messages of its own, any messages the orders service sent would be rolled back, but there is no way to roll back the transaction in the UI. If you need multiservice transactions, consider implementing sagas.
Transactions commit atomically in the broker (just like a transaction would commit in a database), but there are no guarantees regarding when an arbitrary consumer will read those messages. This may seem obvious, but it is sometimes a point of confusion. Say we send a message to the Orders topic and a message to the Payments topic, inside a transaction there is no way to know when a consumer will read one or the other, or that they might read them together. But again note that this is identical to the contract offered by a transactional database.
Finally, in the examples here we use the producer and consumer APIs to demonstrate how transactions work. But the Kafka’s Streams API actually requires no extra coding whatsoever. All you do is set a configuration and exactly-once processing is enabled automatically.
But while there is full support for individual producers and consumers, transactions are not currently supported for consumer groups (although this will change). If you have this requirement, use the Kafka Streams API, where consumer groups are supported in full.
Making Use of Transactions in Your Services
In Chapter 5 we described a design pattern known as Event Collaboration. In this pattern messages move from service to service, creating a workflow. It’s initiated with an Order Requested event and it ends with Order Complete. In between, several different services get involved, moving the workflow forward.
Transactions are important in complex workflows like this because the end-to-end principle is hard to apply. Without them, deduplication would need to happen in every service. Moreover, building a reliable streaming application without transactions turns out to be pretty tough. There are a couple of reasons for this: (a) Streams applications make use of many intermediary topics, and deduplicating them after each step is a burden (and would be near impossible in KSQL), (b) the DSL provides a range of one-to-many operations (e.g., flatMap()), which are hard to manage idempotently without the transactions API. Kafka’s transactions feature resolves these issues, along with atomically tying stream processing with the storing of intermediary state in state stores.
Summary
Transactions affect the way we build services in a number of specific ways:
-
They take idempotence right off the table for services interconnected with Kafka. So when we build services that follow the pattern “read, process, (save), send,” we don’t need to worry about deduplicating inputs or constructing keys for outputs.
-
We no longer need to worry about ensuring there are appropriate unique keys on the messages we send. This typically applies less to topics containing business events, which often have good keys already. But it’s useful when we’re managing derivative/intermediary data—for example, when we’re remapping events, creating aggregate events, or using the Streams API.
-
Where Kafka is used for persistence, we can wrap both messages we send to other services and state we need internally in a single transaction that will commit or fail. This makes it easier to build simple stateful apps and services.
So, to put it simply, when you are building event-based systems, Kafka’s transactions free you from the worries of failure and retries in a distributed world—worries that really should be a concern of the infrastructure, not of your code. This raises the level of abstraction, making it easier to get accurate, repeatable results from large estates of fine-grained services.
Having said all that, we should also be careful. Transactions remove just one of the issues that come with distributed systems, but there are many more. Coarse-grained services still have their place. But in a world where we want to be fast and nimble, streaming platforms raise the bar, allowing us to build finer-grained services that behave as predictably in complex chains as they would standing alone.
1 In practice a clever optimization is used to move buffering from the consumer to the broker, reducing memory pressure. Begin markers are also optimized out.