
Chapter 6. Write
In this chapter we shall explore methods for building generative models on text data. There are several key differences between text and image data that mean that many of the methods that work well for image data are not so readily applicable to text data. In particular:
-
Text data is composed of discrete chunks (either characters or words), whereas pixels in an image are points in a continuous color spectrum. We can easily make a green pixel more blue, but it is not obvious how we should go about making the word cat more like the word dog, for example. This means we can easily apply backpropagation to image data, as we can calculate the gradient of our loss function with respect to individual pixels to establish the direction in which pixel colors should be changed to minimize the loss. With discrete text data, we can’t apply backpropagation in the usual manner, so we need to find a way around this problem.
-
Text data has a time dimension but no spatial dimension, whereas image data has two spatial dimensions but no time dimension. The order of words is highly important in text data and words wouldn’t make sense in reverse, whereas images can usually be flipped without affecting the content. Furthermore, there are often long-term sequential dependencies between words that need to be captured by the model: for example, the answer to a question or carrying forward the context of a pronoun. With image data, all pixels can be processed simultaneously.
-
Text data is highly sensitive to small changes in the individual units (words or characters). Image data is generally less sensitive to changes in individual pixel units—a picture of a house would still be recognizable as a house even if some pixels were altered. However, with text data, changing even a few words can drastically alter the meaning of the passage, or make it nonsensical. This makes it very difficult to train a model to generate coherent text, as every word is vital to the overall meaning of the passage.
-
Text data has a rules-based grammatical structure, whereas image data doesn’t follow set rules about how the pixel values should be assigned. For example, it wouldn’t make grammatical sense in any content to write “The cat sat on the having.” There are also semantic rules that are extremely difficult to model; it wouldn’t make sense to say “I am in the beach,” even though grammatically, there is nothing wrong with this statement.
Good progress has been made in text modeling, but solutions to the above problems are still ongoing areas of research. We’ll start by looking at one of the most utilized and established models for generating sequential data such as text, the recurrent neural network (RNN), and in particular, the long short-term memory (LSTM) layer. In this chapter we will also explore some new techniques that have led to promising results in the field of question-answer pair generation.
First, a trip to the local prison, where the inmates have formed a literary society…
The Literary Society for Troublesome Miscreants
Edward Sopp hated his job as a prison warden. He spent his days watching over the prisoners and had no time to follow his true passion of writing short stories. He was running low on inspiration and needed to find a way to generate new content.
One day, he came up with a brilliant idea that would allow him to produce new works of fiction in his style, while also keeping the inmates occupied—he would get the inmates to collectively write the stories for him! He branded the new society the LSTM (Literary Society for Troublesome Miscreants).
The prison is particularly strange because it only consists of one large cell, containing 256 prisoners. Each prisoner has an opinion on how Edward’s current story should continue. Every day, Edward posts the latest word from his novel into the cell, and it is the job of the inmates to individually update their opinions on the current state of the story, based on the new word and the opinions of the inmates from the previous day.
Each prisoner uses a specific thought process to update their own opinion, which involves balancing information from the new incoming word and other prisoners’ opinions with their own prior beliefs. First, they decide how much of yesterday’s opinion they wish to forget, using the information from the new word and the opinions of other prisoners in the cell. They also use this information to form new thoughts and decide how much of this they want to mix into the old beliefs that they have chosen to carry forward from the previous day. This then forms the prisoner’s new opinion for the day.
However, the prisoners are secretive and don’t always tell their fellow inmates everything that they believe. They also use the latest chosen word and the opinions of the other inmates to decide how much of their opinion they wish to disclose.
When Edward wants the cell to generate the next word in the sequence, the prisoners tell their disclosable opinions to the somewhat dense guard at the door, who combines this information to ultimately decide on the next word to be appended to the end of the novel. This new word is then fed back into the cell as usual, and the process continues until the full story is completed.
To train the inmates and the guard, Edward feeds short sequences of words that he has written previously into the cell and monitors if the inmates’ chosen next word is correct. He updates them on their accuracy, and gradually they begin to learn how to write stories in his own unique style.
After many iterations of this process, Edward finds that the system has become quite accomplished at generating realistic-looking text. While it is somewhat lacking in semantic structure, it certainly displays similar characteristics to his previous stories.
Satisfied with the results, he publishes a collection of the generated tales in his new book, entitled E. Sopp’s Fables.
Long Short-Term Memory Networks
The story of Mr. Sopp and his crowdsourced fables is an analogy for one of the most utilized and successful deep learning techniques for sequential data such as text: the long short-term memory (LSTM) network.
An LSTM network is a particular type of recurrent neural network (RNN). RNNs contain a recurrent layer (or cell) that is able to handle sequential data by making its own output at a particular timestep form part of the input to the next timestep, so that information from the past can affect the prediction at the current timestep. We say LSTM network to mean a neural network with an LSTM recurrent layer.
When RNNs were first introduced, recurrent layers were very simple and consisted solely of a tanh operator that ensured that the information passed between timesteps was scaled between –1 and 1. However, this was shown to suffer from the vanishing gradient problem and didn’t scale well to long sequences of data.
LSTM cells were first introduced in 1997 in a paper by Sepp Hochreiter and Jürgen Schmidhuber.1 In the paper, the authors describe how LSTMs do not suffer from the same vanishing gradient problem experienced by vanilla RNNs and can be trained on sequences that are hundreds of timesteps long. Since then, the LSTM architecture has been adapted and improved, and variations such as gated recurrent units (GRUs) are now widely utilized and available as layers in Keras.
Let’s begin by taking a look at how to build a very simple LSTM network in Keras that can generate text in the style of Aesop’s Fables.
Your First LSTM Network
As usual, you first need to get set up with the data.
You can download a collection of Aesop’s Fables from Project Gutenberg. This is a collection of free ebooks that can be downloaded as plain text files. This is a great resource for sourcing data that can be used to train text-based deep learning models.
To download the data, from inside the book repository run the following command:
bash ./scripts/download_gutenburg_data.sh 11339 aesop
Let’s now take a look at the steps we need to take in order to get the data in the right shape to train an LSTM network. The code is contained in the 06_01_lstm_text_train.ipynb notebook in the book repository.
Tokenization
The first step is to clean up and tokenize the text. Tokenization is the process of splitting the text up into individual units, such as words or characters.
How you tokenize your text will depend on what you are trying to achieve with your text generation model. There are pros and cons to using both word and character tokens, and your choice will affect how you need to clean the text prior to modeling and the output from your model.
If you use word tokens:
-
All text can be converted to lowercase, to ensure capitalized words at the start of sentences are tokenized the same way as the same words appearing in the middle of a sentence. In some cases, however, this may not be desirable; for example, some proper nouns, such as names or places, may benefit from remaining capitalized so that they are tokenized independently.
-
The text vocabulary (the set of distinct words in the training set) may be very large, with some words appearing very sparsely or perhaps only once. It may be wise to replace sparse words with a token for unknown word, rather than including them as separate tokens, to reduce the number of weights the neural network needs to learn.
-
Words can be stemmed, meaning that they are reduced to their simplest form, so that different tenses of a verb remained tokenized together. For example, browse, browsing, browses, and browsed would all be stemmed to brows.
-
You will need to either tokenize the punctuation, or remove it altogether.
-
Using word tokenization means that the model will never be able to predict words outside of the training vocabulary.
-
The model may generate sequences of characters that form new words outside of the training vocabulary—this may be desirable in some contexts, but not in others.
-
Capital letters can either be converted to their lowercase counterparts, or remain as separate tokens.
-
The vocabulary is usually much smaller when using character tokenization. This is beneficial for model training speed as there are fewer weights to learn in the final output layer.
For this example, we’ll use lowercase word tokenization, without word stemming. We’ll also tokenize punctuation marks, as we would like the model to predict when it should end sentences or open/close speech marks, for example. Finally, we’ll replace the multiple newlines between stories with a block of new story characters, ||||||||||||||||||||. This way, when we generate text using the model, we can seed the model with this block of characters, so that the model knows to start a new story from scratch.
The code in Example 6-1 cleans and tokenizes the text.
Example 6-1. Tokenization
importrefromkeras.preprocessing.textimportTokenizerfilename="./data/aesop/data.txt"withopen(filename,encoding='utf-8-sig')asf:text=f.read()seq_length=20start_story='| '*seq_length# CLEANUPtext=text.lower()text=start_story+texttext=text.replace('',start_story)text=text.replace('',' ')text=re.sub(' +','. ',text).strip()text=text.replace('..','.')text=re.sub('([!"#$%&()*+,-./:;<=>?@[]^_`{|}~])',r' 1 ',text)text=re.sub('s{2,}',' ',text)# TOKENIZATIONtokenizer=Tokenizer(char_level=False,filters='')tokenizer.fit_on_texts([text])total_words=len(tokenizer.word_index)+1token_list=tokenizer.texts_to_sequences([text])[0]
An extract of the raw text after cleanup is shown in Figure 6-1.

Figure 6-1. The text after cleanup
In Figure 6-2, we can see the dictionary of tokens mapped to their respective indices and also a snippet of tokenized text, with the corresponding words shown in green.

Figure 6-2. The mapping dictionary between words and indices (left) and the text after tokenization (right)
Building the Dataset
Our LSTM network will be trained to predict the next word in a sequence, given a sequence of words preceding this point. For example, we could feed the model the tokens for the greedy cat and the and would expect the model to output a suitable next word (e.g., dog, rather than in).
The sequence length that we use to train the model is a parameter of the training process. In this example we choose to use a sequence length of 20, so we split the text into 20-word chunks. A total of 50,416 such sequences can be constructed, so our training dataset X is an array of shape [50416, 20].
The response variable for each sequence is the subsequent word, one-hot encoded into a vector of length 4,169 (the number of distinct words in the vocabulary). Therefore, our response y is a binary array of shape [50416, 4169].
The dataset generation step can be achieved with the code in Example 6-2.
Example 6-2. Generating the dataset
importnumpyasnpfromkeras.utilsimportnp_utilsdefgenerate_sequences(token_list,step):X=[]y=[]foriinrange(0,len(token_list)-seq_length,step):X.append(token_list[i:i+seq_length])y.append(token_list[i+seq_length])y=np_utils.to_categorical(y,num_classes=total_words)num_seq=len(X)('Number of sequences:',num_seq,"")returnX,y,num_seqstep=1seq_length=20X,y,num_seq=generate_sequences(token_list,step)X=np.array(X)y=np.array(y)
The LSTM Architecture
The architecture of the overall model is shown in Figure 6-3. The input to the model is a sequence of integer tokens and the output is the probability of each word in the vocabulary appearing next in the sequence. To understand how this works in detail, we need to introduce two new layer types, Embedding and LSTM.

Figure 6-3. LSTM model architecture
The Embedding Layer
An embedding layer is essentially a lookup table that converts each token into a vector of length embedding_size (Figure 6-4). The number of weights learned by this layer is therefore equal to the size of the vocabulary, multiplied by embedding_size.

Figure 6-4. An embedding layer is a lookup table for each integer token
The Input layer passes a tensor of integer sequences of shape [batch_size, seq_length] to the Embedding layer, which outputs a tensor of shape [batch_size, seq_length, embedding_size]. This is then passed on to the LSTM layer (Figure 6-5).

Figure 6-5. A single sequence as it flows through an embedding layer
We embed each integer token into a continuous vector because it enables the model to learn a representation for each word that is able to be updated through backpropagation. We could also just one-hot encode each input token, but using an embedding layer is preferred because it makes the embedding itself trainable, thus giving the model more flexibility in deciding how to embed each token to improve model performance.
The LSTM Layer
To understand the LSTM layer, we must first look at how a general recurrent layer works.
A recurrent layer has the special property of being able to process sequential input data [x1,…,xn]. It consists of a cell that updates its hidden state, ht, as each element of the sequence xt is passed through it, one timestep at a time. The hidden state is a vector with length equal to the number of units in the cell—it can be thought of as the cell’s current understanding of the sequence. At timestep t, the cell uses the previous value of the hidden state ht–1 together with the data from the current timestep xt to produce an updated hidden state vector ht. This recurrent process continues until the end of the sequence. Once the sequence is finished, the layer outputs the final hidden state of the cell, hn, which is then passed on to the next layer of the network. This process is shown in Figure 6-6.

Figure 6-6. A simple diagram of a recurrent layer
To explain this in more detail, let’s unroll the process so that we can see exactly how a single sequence is fed through the layer (Figure 6-7).

Figure 6-7. How a single sequence flows through a recurrent layer
Here, we represent the recurrent process by drawing a copy of the cell at each timestep and show how the hidden state is constantly being updated as it flows through the cells. We can clearly see how the previous hidden state is blended with the current sequential data point (i.e., the current embedded word vector) to produce the next hidden state. The output from the layer is the final hidden state of the cell, after each word in the input sequence has been processed. It’s important to remember that all of the cells in this diagram share the same weights (as they are really the same cell). There is no difference between this diagram and Figure 6-6; it’s just a different way of drawing the mechanics of a recurrent layer.
Note
The fact that the output from the cell is called a hidden state is an unfortunate naming convention—it’s not really hidden, and you shouldn’t think of it as such. Indeed, the last hidden state is the overall output from the layer, and we will be making use of the fact that we can access the hidden state at each individual timestep later in this chapter.
The LSTM Cell
Now that we have seen how a generic recurrent layer works, let’s take a look inside an individual LSTM cell.
The job of the LSTM cell is to output a new hidden state, ht, given its previous hidden state, ht–1, and the current word embedding, xt. To recap, the length of ht is equal to the number of units in the LSTM. This is a parameter that is set when you define the layer and has nothing to do with the length of the sequence. Make sure you do not confuse the term cell with unit. There is one cell in an LSTM layer that is defined by the number of units it contains, in the same way that the prisoner cell from our earlier story contained many prisoners. We often draw a recurrent layer as a chain of cells unrolled, as it helps to visualize how the hidden state is updated at each timestep.
An LSTM cell maintains a cell state, Ct, which can be thought of as the cell’s internal beliefs about the current status of the sequence. This is distinct from the hidden state, ht, which is ultimately output by the cell after the final timestep. The cell state is the same length as the hidden state (the number of units in the cell).
Let’s look more closely at a single cell and how the hidden state is updated (Figure 6-8).

Figure 6-8. An LSTM cell
The hidden state is updated in six steps:
-
The hidden state of the previous timestep, ht–1, and the current word embedding, xt, are concatenated and passed through the forget gate. This gate is simply a dense layer with weights matrix Wf, bias bf, and a sigmoid activation function. The resulting vector, ft, has a length equal to the number of units in the cell and contains values between 0 and 1 that determine how much of the previous cell state, Ct–1, should be retained.
-
The concatenated vector is also passed through an input gate which, like the forget gate, is a dense layer with weights matrix Wi, bias bi, and a sigmoid activation function. The output from this gate, it, has length equal to the number of units in the cell and contains values between 0 and 1 that determine how much new information will be added to the previous cell state, Ct–1.
-
The concatenated vector is passed through a dense layer with weights matrix WC, bias bC, and a tanh activation function to generate a vector that contains the new information that the cell wants to consider keeping. It also has length equal to the number of units in the cell and contains values between –1 and 1.
-
ft and Ct–1 are multiplied element-wise and added to the element-wise multiplication of it and . This represents forgetting parts of the previous cell state and then adding new relevant information to produce the updated cell state, Ct.
-
The original concatenated vector is also passed through an output gate: a dense layer with weights matrix Wo, bias bo, and a sigmoid activation. The resulting vector, ot, has a length equal to the number of units in the cell and stores values between 0 and 1 that determine how much of the updated cell state, Ct, to output from the cell.
-
ot is multiplied element-wise with the updated cell state Ct after a tanh activation has been applied to produce the new hidden state, ht.
The code to build the LSTM network is given in Example 6-3.
Example 6-3. Building the LSTM network
fromkeras.layersimportDense,LSTM,Input,Embedding,Dropoutfromkeras.modelsimportModelfromkeras.optimizersimportRMSpropn_units=256embedding_size=100text_in=Input(shape=(None,))x=Embedding(total_words,embedding_size)(text_in)x=LSTM(n_units)(x)x=Dropout(0.2)(x)text_out=Dense(total_words,activation='softmax')(x)model=Model(text_in,text_out)opti=RMSprop(lr=0.001)model.compile(loss='categorical_crossentropy',optimizer=opti)epochs=100batch_size=32model.fit(X,y,epochs=epochs,batch_size=batch_size,shuffle=True)
Generating New Text
Now that we have compiled and trained the LSTM network, we can start to use it to generate long strings of text by applying the following process:
-
Feed the network with an existing sequence of words and ask it to predict the following word.
-
Append this word to the existing sequence and repeat.
The network will output a set of probabilities for each word that we can sample from. Therefore, we can make the text generation stochastic, rather than deterministic. Moreover, we can introduce a temperature parameter to the sampling process to indicate how deterministic we would like the process to be.
This is achieved with the code in Example 6-4.
Example 6-4. Generating text with an LSTM network
defsample_with_temp(preds,temperature=1.0):# helper function to sample an index from a probability arraypreds=np.asarray(preds).astype('float64')preds=np.log(preds)/temperatureexp_preds=np.exp(preds)preds=exp_preds/np.sum(exp_preds)probs=np.random.multinomial(1,preds,1)returnnp.argmax(probs)defgenerate_text(seed_text,next_words,model,max_sequence_len,temp):output_text=seed_textseed_text=start_story+seed_textfor_inrange(next_words):token_list=tokenizer.texts_to_sequences([seed_text])[0]token_list=token_list[-max_sequence_len:]token_list=np.reshape(token_list,(1,max_sequence_len))probs=model.predict(token_list,verbose=0)[0]y_class=sample_with_temp(probs,temperature=temp)output_word=tokenizer.index_word[y_class]ify_class>0else''ifoutput_word=="|":breakseed_text+=output_word+''output_text+=output_word+''returnoutput_text
This function weights the logits with a
temperaturescaling factor before reapplying the softmax function. A temperature close to zero makes the sampling more deterministic (i.e., the word with highest probability is very likely to be chosen), whereas a temperature of 1 means each word is chosen with the probability output by the model.
The seed text is a string of words that you would like to give the model to start the generation process (it can be blank). This is prepended with the block of characters we use to indicate the start of a story (||||||||||||||||||||).

The words are converted to a list of tokens.

Only the last
max_sequence_lentokens are kept. The LSTM layer can accept any length of sequence as input, but the longer the sequence is the more time it will take to generate the next word, so the sequence length should be capped.
The model outputs the probabilities of each word being next in the sequence.

The probabilities are passed through the sampler to output the next word, parameterized by
temperature.
If the output word is the start story token, we stop generating any more words as this is the model telling us it wants to end this story and start the next one!

Otherwise, we append the new word to the seed text, ready for the next iteration of the generative process.
Let’s take a look at this in action, at two different temperature values (Figure 6-9).

Figure 6-9. Example of LSTM-generated passages, at two different temperature values
There are a few things to note about these two passages. First, both are stylistically similar to a fable from the original training set. They both open with the familiar statement of the characters in the story, and generally the text within speech marks is more dialogue-like, using personal pronouns and prepared by the occurrence of the word said.
Second, the text generated at temperature = 0.2 is less adventurous but more coherent in its choice of words than the text generated at temperature = 1.0, as lower temperature values result in more deterministic sampling.
Last, it is clear that neither flows particularly well as a story across multiple sentences, because the LSTM network cannot grasp the semantic meaning of the words that it is generating. In order to generate passages that have greater chance of being semantically reasonable, we can build a human-assisted text generator, where the model outputs the top 10 words with the highest probabilities and it is then ultimately up to a human to choose the next word from among this list. This is similar to predictive text on your mobile phone, where you are given the choice of a few words that might follow on from what you have already typed.
To demonstrate this, Figure 6-10 shows the top 10 words with the highest probabilities to follow various sequences (not from the training set).

Figure 6-10. Distribution of word probabilities following various sequences
The model is able to generate a suitable distribution for the next most likely word across a range of contexts. For example, even though the model was never told about parts of speech such as nouns, verbs, adjectives, and prepositions, it is generally able to separate words into these classes and use them in a way that is grammatically correct. It can also guess that the article that begins a story about an eagle is more likely to be an, rather than a.
The punctuation example from Figure 6-10 shows how the model is also sensitive to subtle changes in the input sequence. In the first passage (the lion said ,), the model guesses that speech marks follow with 98% likelihood, so that the clause precedes the spoken dialogue. However, if we instead input the next word as and, it is able to understand that speech marks are now unlikely, as the clause is more likely to have superseded the dialogue and the sentence will more likely continue as descriptive prose.
RNN Extensions
The network in the preceding section is a simple example of how an LSTM network can be trained to learn how to generate text in a given style. In this section we will explore several extensions to this idea.
Stacked Recurrent Networks
The network we just looked at contained a single LSTM layer, but we can also train networks with stacked LSTM layers, so that deeper features can be learned from the text.
To achieve this, we set the return_sequences parameter within the first LSTM layer to True. This makes the layer output the hidden state from every timestep, rather than just the final timestep. The second LSTM layer can then use the hidden states from the first layer as its input data. This is shown in Figure 6-11, and the overall model architecture is shown in Figure 6-12.

Figure 6-11. Diagram of a multilayer RNN: gt denotes hidden states of the first layer and ht denotes hidden states of the second layer

Figure 6-12. A stacked LSTM network
The code to build the stacked LSTM network is given in Example 6-5.
Example 6-5. Building a stacked LSTM network
text_in=Input(shape=(None,))embedding=Embedding(total_words,embedding_size)x=embedding(text_in)x=LSTM(n_units,return_sequences=True)(x)x=LSTM(n_units)(x)x=Dropout(0.2)(x)text_out=Dense(total_words,activation='softmax')(x)model=Model(text_in,text_out)
Gated Recurrent Units
Another type of commonly used RNN layer is the gated recurrent unit (GRU).2 The key differences from the LSTM unit are as follows:
-
The forget and input gates are replaced by reset and update gates.
-
There is no cell state or output gate, only a hidden state that is output from the cell.
The hidden state is updated in four steps, as illustrated in Figure 6-13.
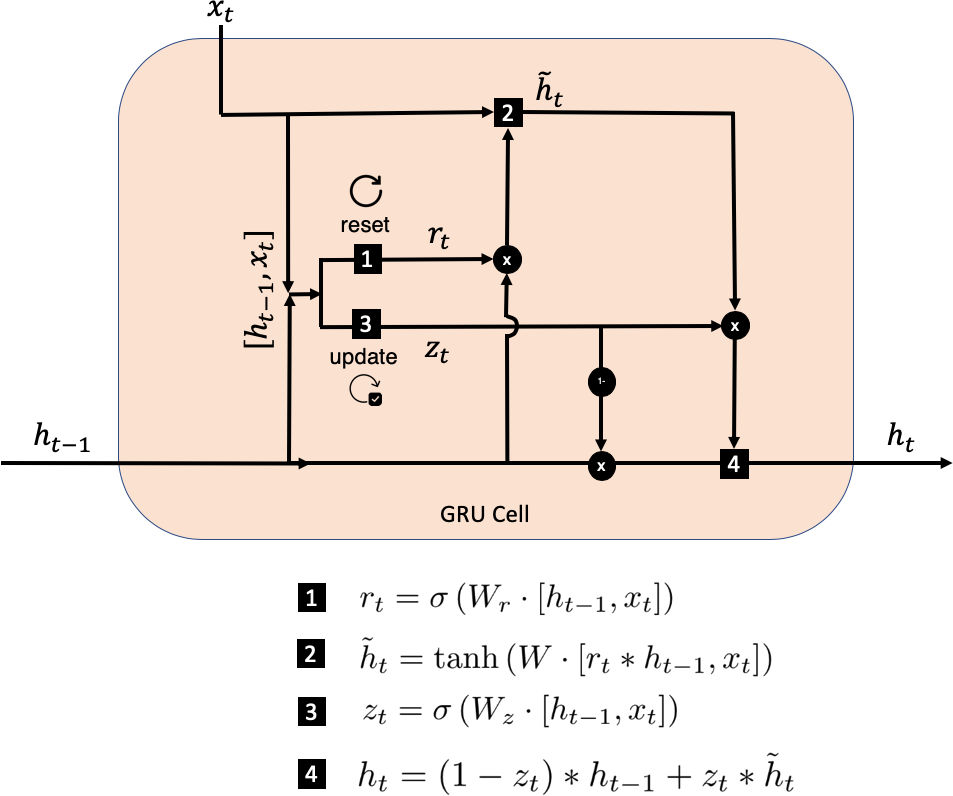
Figure 6-13. A single GRU cell
The process is as follows:
-
The hidden state of the previous timestep, ht–1, and the current word embedding, xt, are concatenated and used to create the reset gate. This gate is a dense layer, with weights matrix Wr and a sigmoid activation function. The resulting vector, rt, has a length equal to the number of units in the cell and stores values between 0 and 1 that determine how much of the previous hidden state, ht–1, should be carried forward into the calculation for the new beliefs of the cell.
-
The reset gate is applied to the hidden state, ht–1, and concatenated with the current word embedding, xt. This vector is then fed to a dense layer with weights matrix W and a tanh activation function to generate a vector, , that stores the new beliefs of the cell. It has length equal to the number of units in the cell and stores values between –1 and 1.
-
The concatenation of the hidden state of the previous timestep, ht–1, and the current word embedding, xt, are also used to create the update gate. This gate is a dense layer with weights matrix Wz and a sigmoid activation. The resulting vector, zt, has length equal to the number of units in the cell and stores values between 0 and 1, which are used to determine how much of the new beliefs, , to blend into the current hidden state, ht–1.
-
The new beliefs of the cell and the current hidden state, ht–1, are blended in a proportion determined by the update gate, zt, to produce the updated hidden state, ht, that is output from the cell.
Bidirectional Cells
For prediction problems where the entire text is available to the model at inference time, there is no reason to process the sequence only in the forward direction—it could just as well be processed backwards. A bidirectional layer takes advantage of this by storing two sets of hidden states: one that is produced as a result of the sequence being processed in the usual forward direction and another that is produced when the sequence is processed backwards. This way, the layer can learn from information both preceding and succeeding the given timestep.
In Keras, this is implemented as a wrapper around a recurrent layer, as shown here:
layer = Bidirectional(GRU(100))
The hidden states in the resulting layer are vectors of length equal to double the number of units in the wrapped cell (a concatenation of the forward and backward hidden states). Thus, in this example the hidden states of the layer are vectors of length 200.
Encoder–Decoder Models
So far, we have looked at using LSTM networks for generating the continuation of an existing text sequence. We have seen how a single LSTM layer can process the data sequentially to update a hidden state that represents the layer’s current understanding of the sequence. By connecting the final hidden state to a dense layer, the network can output a probability distribution for the next word.
For some tasks, the goal isn’t to predict the single next word in the existing sequence; instead we wish to predict a completely different sequence of words that is in some way related to the input sequence. Some examples of this style of task are:
- Language translation
-
The network is fed a text string in the source language and the goal is to output the text translated into a target language.
- Question generation
-
The network is fed a passage of text and the goal is to generate a viable question that could be asked about the text.
- Text summarization
-
The network is fed a long passage of text and the goal is to generate a short summary of the passage.
For these kinds of problems, we can use a type of network known as an encoder–decoder. We have already seen one type of encoder–decoder network in the context of image generation: the variational autoencoder. For sequential data, the encoder–decoder process works as follows:
-
The original input sequence is summarized into a single vector by the encoder RNN.
-
This vector is used to initialize the decoder RNN.
-
The hidden state of the decoder RNN at each timestep is connected to a dense layer that outputs a probability distribution over the vocabulary of words. This way, the decoder can generate a novel sequence of text, having been initialized with a representation of the input data produced by the encoder.
This process is shown in Figure 6-14, in the context of translation between English and German.

Figure 6-14. An encoder–decoder network
The final hidden state of the encoder can be thought of as a representation of the entire input document. The decoder then transforms this representation into sequential output, such as the translation of the text into another language, or a question relating to the document.
During training, the output distribution produced by the decoder at each timestep is compared against the true next word, to calculate the loss. The decoder doesn’t need to sample from these distributions to generate words during the training process, as the subsequent cell is fed with the ground-truth next word, rather than a word sampled from the previous output distribution. This way of training encoder–decoder networks is known as teacher forcing. We can imagine that the network is a student sometimes making erroneous distribution predictions, but no matter what the network outputs at each timestep, the teacher provides the correct response as input to the network for the attempt at the next word.
A Question and Answer Generator
We’re now going to put everything together and build a model that can generate question and answer pairs from a block of text. This project is inspired by the qgen-workshop TensorFlow codebase and the model proposed by Tong Wang, Xingdi Yuan, and Adam Trischler.3
The model consists of two parts:
-
An RNN that identifies candidate answers from the block of text
-
An encoder–decoder network that generates a suitable question, given one of the candidate answers highlighted by the RNN
For example, consider the following opening to a passage of text about a football match:
The winning goal was scored by 23-year-old striker Joe Bloggs during the match between Arsenal and Barcelona . Arsenal recently signed the striker for 50 million pounds . The next match is in two weeks time, on July 31st 2005 . "
We would like our first network to be able to identify potential answers such as:
"Joe Bloggs" "Arsenal" "Barcelona" "50 million pounds" "July 31st 2005"
And our second network should be able to generate a question, given each of the answers, such as:
"Who scored the winning goal?" "Who won the match?" "Who were Arsenal playing?" "How much did the striker cost?" "When is the next match?"
Let’s first take a look at the dataset we shall be using in more detail.
A Question-Answer Dataset
We’ll be using the Maluuba NewsQA dataset, which you can download by following the set of instructions on GitHub.
The resulting train.csv, test.csv, and dev.csv files should be placed in the ./data/qa/ folder inside the book repository. These files all have the same column structure, as follows:
story_id-
A unique identifier for the story.
story_text-
The text of the story (e.g., “The winning goal was scored by 23-year-old striker Joe Bloggs during the match…”).
question-
A question that could be asked about the story text (e.g., “How much did the striker cost?”).
answer_token_ranges-
The token positions of the answer in the story text (e.g.,
24:27). There might be multiple ranges (comma separated) if the answer appears multiple times in the story.
This raw data is processed and tokenized so that is it able to be used as input to our model. After this transformation, each observation in the training set consists of the following five features:
document_tokens-
The tokenized story text (e.g.,
[1, 4633, 7, 66, 11, ...]), clipped/padded with zeros to be of lengthmax_document_length(a parameter). question_input_tokens-
The tokenized question (e.g.,
[2, 39, 1, 52, ...]), padded with zeros to be of lengthmax_question_length(another parameter). question_output_tokens-
The tokenized question, offset by one timestep (e.g.,
[39, 1, 52, 1866, ...], padded with zeros to be of lengthmax_question_length. answer_masks-
A binary mask matrix having shape
[max_answer_length, max_document_length]. The[i, j]value of the matrix is 1 if theith word of the answer to the question is located at thejth word of the document and 0 otherwise. answer_labels-
A binary vector of length
max_document_length(e.g.,[0, 1, 1, 0, ...]). Theith element of the vector is 1 if theith word of the document could be considered part of an answer and 0 otherwise.
Let’s now take a look at the model architecture that is able to generate question-answer pairs from a given block of text.
Model Architecture
Figure 6-15 shows the overall model architecture that we will be building. Don’t worry if this looks intimidating! It’s only built from elements that we have seen already and we will be walking through the architecture step by step in this section.

Figure 6-15. The architecture for generating question–answer pairs; input data is shown in green bordered boxes
Let’s start by taking a look at the Keras code that builds the part of the model at the top of the diagram, which predicts if each word in the document is part of an answer or not. This code is shown in Example 6-6. You can also follow along with the accompanying notebook in the book repository, 06_02_qa_train.ipynb.
Example 6-6. Model architecture for generating question–answer pairs
fromkeras.layersimportInput,Embedding,GRU,Bidirectional,Dense,Lambdafromkeras.modelsimportModel,load_modelimportkeras.backendasKfromqgen.embeddingimportglove#### PARAMETERS ####VOCAB_SIZE=glove.shape[0]# 9984EMBEDDING_DIMENS=glove.shape[1]# 100GRU_UNITS=100DOC_SIZE=NoneANSWER_SIZE=NoneQ_SIZE=Nonedocument_tokens=Input(shape=(DOC_SIZE,),name="document_tokens")embedding=Embedding(input_dim=VOCAB_SIZE,output_dim=EMBEDDING_DIMENS,weights=[glove],mask_zero=True,name='embedding')document_emb=embedding(document_tokens)answer_outputs=Bidirectional(GRU(GRU_UNITS,return_sequences=True),name='answer_outputs')(document__emb)answer_tags=Dense(2,activation='softmax',name='answer_tags')(answer_outputs)
The document tokens are provided as input to the model. Here, we use the variable
DOC_SIZEto describe the size of this input, but the variable is actually set toNone. This is because the architecture of the model isn’t dependent on the length of the input sequence—the number of cells in the layer will adapt to equal the length of the input sequence, so we don’t need to specify it explicitly.The embedding layer is initialized with GloVe word vectors (explained in the following sidebar).
The recurrent layer is a bidirectional GRU that returns the hidden state at each timestep.
The output
Denselayer is connected to the hidden state at each timestep and has only two units, with a softmax activation, representing the probability that each word is part of an answer (1) or is not part of an answer (0).
To work with the GloVe word vectors within this project, download the file glove.6B.100d.txt (6 billion words each with an embedding of length 100) from the GloVe project website and then run the following Python script from the book repository to trim this file to only include words that are present in the training corpus:
python ./utils/write.py
The second part of the model is the encoder–decoder network that takes a given answer and tries to formulate a matching question (the bottom part of Figure 6-15).
The Keras code for this part of the network is given in Example 6-7.
Example 6-7. Model architecture for the encoder–decoder network that formulates a question given an answer
encoder_input_mask=Input(shape=(ANSWER_SIZE,DOC_SIZE),name="encoder_input_mask")encoder_inputs=Lambda(lambdax:K.batch_dot(x[0],x[1]),name="encoder_inputs")([encoder_input_mask,answer_outputs])encoder_cell=GRU(2*GRU_UNITS,name='encoder_cell')(encoder_inputs)decoder_inputs=Input(shape=(Q_SIZE,),name="decoder_inputs")decoder_emb=embedding(decoder_inputs)decoder_emb.trainable=Falsedecoder_cell=GRU(2*GRU_UNITS,return_sequences=True,name='decoder_cell')decoder_states=decoder_cell(decoder_emb,initial_state=[encoder_cell])decoder_projection=Dense(VOCAB_SIZE,name='decoder_projection',activation='softmax',use_bias=False)decoder_outputs=decoder_projection(decoder_states)total_model=Model([document_tokens,decoder_inputs,encoder_input_mask],[answer_tags,decoder_outputs])answer_model=Model(document_tokens,[answer_tags])decoder_initial_state_model=Model([document_tokens,encoder_input_mask],[encoder_cell])
The answer mask is passed as an input to the model—this allows us to pass the hidden states from a single answer range through to the encoder–decoder. This is achieved using a
Lambdalayer.The encoder is a
GRUlayer that is fed the hidden states for the given answer range as input data.The input data to the decoder is the question matching the given answer range.
The question word tokens are passed through the same embedding layer used in the answer identification model.
The decoder is a
GRUlayer and is initialized with the final hidden state from the encoder.The hidden states of the decoder are passed through a
Denselayer to generate a distribution over the entire vocabulary for the next word in the sequence.
This completes our network for question–answer pair generation. To train the network, we pass the document text, question text, and answer masks as input data in batches and minimize the cross-entropy loss on both the answer position prediction and question word generation, weighted equally.
Inference
To test the model on an input document sequence that it has never seen before, we need to run the following process:
-
Feed the document string to the answer generator to produce sample positions for answers in the document.
-
Choose one of these answer blocks to carry forward to the encoder–decoder question generator (i.e., create the appropriate answer mask).
-
Feed the document and answer mask to the encoder to generate the initial state for the decoder.
-
Initialize the decoder with this initial state and feed in the
<START>token to generate the first word of the question. Continue this process, feeding in generated words one by one until the<END>token is predicted by the model.
As discussed previously, during training the model uses teacher forcing to feed the ground-truth words (rather than the predicted next words) back into the decoder cell. However during inference the model must generate a question by itself, so we want to be able to feed the predicted words back into the decoder cell while retaining its hidden state.
One way we can achieve this is by defining an additional Keras model (question_model) that accepts the current word token and current decoder hidden state as input, and outputs the predicted next word distribution and updated decoder hidden state. This is shown in Example 6-8.
Example 6-8. Inference models
decoder_inputs_dynamic=Input(shape=(1,),name="decoder_inputs_dynamic")decoder_emb_dynamic=embedding(decoder_inputs_dynamic)decoder_init_state_dynamic=Input(shape=(2*GRU_UNITS,),name='decoder_init_state_dynamic')decoder_states_dynamic=decoder_cell(decoder_emb_dynamic,initial_state=[decoder_init_state_dynamic])decoder_outputs_dynamic=decoder_projection(decoder_states_dynamic)question_model=Model([decoder_inputs_dynamic,decoder_init_state_dynamic],[decoder_outputs_dynamic,decoder_states_dynamic])
We can then use this model in a loop to generate the output question word by word, as shown in Example 6-9.
Example 6-9. Generating question–answer pairs from a given document
test_data_gen=test_data()batch=next(test_data_gen)answer_preds=answer_model.predict(batch["document_tokens"])idx=0start_answer=37end_answer=39answers=[[0]*len(answer_preds[idx])]foriinrange(start_answer,end_answer+1):answers[idx][i]=1answer_batch=expand_answers(batch,answers)next_decoder_init_state=decoder_initial_state_model.predict([answer_batch['document_tokens'][[idx]],answer_batch['answer_masks'][[idx]]])word_tokens=[START_TOKEN]questions=[look_up_token(START_TOKEN)]ended=Falsewhilenotended:word_preds,next_decoder_init_state=question_model.predict([word_tokens,next_decoder_init_state])next_decoder_init_state=np.squeeze(next_decoder_init_state,axis=1)word_tokens=np.argmax(word_preds,2)[0]questions.append(look_up_token(word_tokens[0]))ifword_tokens[0]==END_TOKEN:ended=Truequestions=' '.join(questions)
Model Results
Sample results from the model are shown in Figure 6-16 (see also the accompanying notebook in the book repository, 06_03_qa_analysis.ipynb). The chart on the right shows the probability of each word in the document forming part of an answer, according to the model. These answer phrases are then fed to the question generator and the output of this model is shown on the lefthand side of the diagram (“Predicted Question”).
First, notice how the answer generator is able to accurately identify which words in the document are most likely to be contained in an answer. This is already quite impressive given that it has never seen this text before and also may not have seen certain words from the document that are included in the answer, such as Bloggs. It is able to understand from the context that this is likely to be the surname of a person and therefore likely to form part of an answer.

Figure 6-16. Sample results from the model
The encoder extracts the context from each of these possible answers, so that the decoder is able to generate suitable questions. It is remarkable that the encoder is able to capture that the person mentioned in the first answer, 23-year-old striker Joe Bloggs, would probably have a matching question relating to his goal-scoring abilities, and is able to pass this context on to the decoder so that it can generate the question “who scored the <UNK> ?” rather than, for example, “who is the president ?”
The decoder has finished this question with the tag <UNK>, but not because it doesn’t know what to do next—it is predicting that the word that follows is likely to be from outside the core vocabulary. We shouldn’t be surprised that the model resorts to using the tag <UNK> in this context, as many of the niche words in the original corpus would be tokenized this way.
We can see that in each case, the decoder chooses the correct “type” of question—who, how much, or when—depending on the type of answer. There are still some problems though, such as asking how much money did he lose ? rather than how much money was paid for the striker ?. This is understandable, as the decoder only has the final encoder state to work with and cannot reference the original document for extra information.
There are several extensions to encoder–decoder networks that improve the accuracy and generative power of the model. Two of the most widely used are pointer networks4 and attention mechanisms.5 Pointer networks give the model the ability to “point” at specific words in the input text to include in the generated question, rather than only relying on the words in the known vocabulary. This helps to solve the <UNK> problem mentioned earlier. We shall explore attention mechanisms in detail in the next chapter.
Summary
In this chapter we have seen how recurrent neural networks can be applied to generate text sequences that mimic a particular style of writing, and also generate plausible question–answer pairs from a given document.
We explored two different types of recurrent layer, long short-term memory and GRU, and saw how these cells can be stacked or made bidirectional to form more complex network architectures. The encoder–decoder architecture introduced in this chapter is an important generative tool as it allows sequence data to be condensed into a single vector that can then be decoded into another sequence. This is applicable to a range of problems aside from question–answer pair generation, such as translation and text summarization.
In both cases we have seen how it is important to understand how to transform unstructured text data to a structured format that can be used with recurrent neural network layers. A good understanding of how the shape of the tensor changes as data flows through the network is also pivotal to building successful networks, and recurrent layers require particular care in this regard as the time dimension of sequential data adds additional complexity to the transformation process.
In the next chapter we will see how many of the same ideas around RNNs can be applied to another type of sequential data: music.
1 Sepp Hochreiter and Jürgen Schmidhuber, “Long Short-Term Memory,” Neural Computation 9 (1997): 1735–1780, http://bit.ly/2In7NnH.
2 Kyunghyun Cho et al., “Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation,” 3 June 2014, https://arxiv.org/abs/1406.1078.
3 Tong Wang, Xingdi Yuan, and Adam Trischler, “A Joint Model for Question Answering and Question Generation,” 5 July 2017, https://arxiv.org/abs/1706.01450.
4 Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly, “Pointer Networks,” 9 July 2015, https://arxiv.org/abs/1506.03134.
5 Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” 1 September 2014, https://arxiv.org/abs/1409.0473.