
Chapter 6. A Journey into Sound
One of the most successful applications of deep learning is something that we carry around with us every day. Whether it’s Siri or Google Now, the engines that power both systems and Amazon’s Alexa are neural networks. In this chapter, we’ll take a look at PyTorch’s torchaudio library. You’ll learn how to use it to construct a pipeline for classifying audio data with a convolutional-based model. After that, I’ll suggest a different approach that will allow you to use some of the tricks you learned for images and obtain good accuracy on the ESC-50 audio dataset.
But first, let’s take a look at sound itself. What is it? How is it often represented in data form, and does that provide us with any clues as to what type of neural net we should use to gain insight from our data?
Sound
Sound is created via the vibration of air. All the sounds we hear are combinations of high and low pressure that we often represent in a waveform, like the one in Figure 6-1. In this image, the wave above the origin is high pressure, and the part below is low pressure.

Figure 6-1. Sine wave
Figure 6-2 shows a more complex waveform of a complete song.

Figure 6-2. Song waveform
In digital sound, we sample this waveform many times a second, traditionally 44,100 for CD-quality sound, and store the amplitude values of the wave during each sample point. At a time t, we have a single value stored. This is slightly different from an image, which requires two values, x and y, to store a value (for a grayscale image). If we use convolutional filters in our neural network, we need a 1D filter rather than the 2D filters we were using for images.
Now that you know a little more about sound, let’s look at the dataset we use so you can get a little more familiar with it.
The ESC-50 Dataset
The Environmental Sound Classification (ESC) dataset is a collection of field recordings, each of which is 5 seconds long and assigned to one of 50 classes (e.g., a dog barking, snoring, a knock on a door). We use this set for the rest of the chapter to experiment with two ways of classifying audio, as well as to explore using torchaudio to simplify loading and manipulating audio.
Obtaining the Dataset
The ESC-50 dataset is a set of WAV files. You can download it either by cloning the Git repository:
git clone https://github.com/karoldvl/ESC-50
Or you can download the entire repo just by using curl:
curl https://github.com/karoldvl/ESC-50/archive/master.zip
All the WAV files are stored in the audio directory with filenames like this:
1-100032-A-0.wav
We care about the final number in the filename, because that tells us what class this sound clip has been assigned to. The other parts of the filename don’t matter to us but mostly relate to the larger Freesound dataset from which ESC-50 has been drawn (with one exception that I’ll come back to shortly). If you’re interested in finding out more, the README document in the ESC-50 repo goes into further detail.
Now that we’ve downloaded the dataset, let’s look at some of the sounds it contains.
Playing Audio in Jupyter
If you want to actually hear a sound from ESC-50, then instead of loading one of the files into a standard music player such as iTunes, you can use Jupyter’s built-in player for audio, IPython.display.Audio:
importIPython.displayasdisplaydisplay.Audio('ESC-50/audio/1-100032-A-0.wav')
The function will read in our WAV files and MP3 files. You can also generate tensors, convert them into NumPy arrays, and play those directly. Play some of the files in the ESC-50 directory to get a feel for the sounds available. Once you’ve done that, we’ll explore the dataset in depth a little more.
Exploring ESC-50
When dealing with a new dataset, it’s always a good idea to get a feeling for the shape of the data before you dive right into building models. In classification tasks, for example, you’ll want to know whether your dataset actually contains examples from all the possible classes, and ideally that all classes are present in equal numbers. Let’s take a look at how ESC-50 breaks down.
Note
If your dataset has an unbalanced amount of data, a simple solution is to randomly duplicate the smaller class examples until you have increased them to the number of the other classes. Although this feels like fake accounting, it’s surprisingly effective (and cheap!) in practice.
We know that the final set of digits in each filename describes the class it belongs to, so what we need to do is grab a list of the files and count up the occurrences of each class:
importglobfromcollectionsimportCounteresc50_list=[f.split("-")[-1].replace(".wav","")forfinglob.glob("ESC-50/audio/*.wav")]Counter(esc50_list)
First, we build up a list of our ESC-50 filenames. Because we care about only the class number at the end of the filename, we chop off the .wav extension and split the filename on the - separator. We finally take the last element in that split string. If you inspect esc50_list, you’ll get a bunch of strings that range from 0 to 49. We could write more code that builds a dict and counts all the occurrences for us, but I’m lazy, so I’m using a Python convenience function, Counter, that does all that for us.
Here’s the output!
Counter({'15':40,'22':40,'36':40,'44':40,'23':40,'31':40,'9':40,'13':40,'4':40,'3':40,'27':40,…})
We have one of those rare things, a perfectly balanced dataset. Let’s break out the champagne and install a few more libraries that we’re going to need shortly.
SoX and LibROSA
Most of the audio processing that torchaudio carries out relies on two other pieces of software: SoX and LibROSA. LibROSA is a Python library for audio analysis, including generating mel spectrograms (You’ll see what these are a little later in the chapter), detecting beats, and even generating music.
SoX, on the other hand, is a program that you might already be familiar with if you’ve been using Linux for years. In fact, SoX is so old that it predates Linux itself; its first release was in July 1991, compared to the Linux debut in September 1991. I remember using it back in 1997 to convert WAV files into MP3s on my first ever Linux box. But it’s still useful!1
If you’re installing torchaudio via conda, you can skip to the next section. If you’re using pip, you’ll probably need to install SoX itself. For a Red Hat-based system, enter the following:
yum install sox
Or on a Debian-based system, you’ll use this:
apt intall sox
Once SoX is installed, you can move on to obtaining torchaudio itself.
torchaudio
Installing torchaudio can be performed with either conda or pip:
conda install -c derickl torchaudio pip install torchaudio
In comparison with torchvision, torchaudio is similar to torchtext in that it’s not quite as well loved, maintained, or documented. I’d expect this to change in the near future as PyTorch gets more popular and better text and audio handling pipelines are created. Still, torchaudio is plenty for our needs; we just have to write some custom dataloaders (which we didn’t have to do for audio or text processing).
Anyhow, the core of torchaudio is found within load() and save(). We’re concerned only with load() in this chapter, but you’ll need to use save() if you’re generating new audio from your input (e.g., a text-to-speech model). load() takes a file specified in filepath and returns a tensor representation of the audio file and the sample rate of that audio file as a separate variable.
We now have the means for loading one of the WAV files from the ESC-50 dataset and turning it into a tensor. Unlike our earlier work with text and images, we need to write a bit more code before we can get on with creating and training a model. We need to write a custom dataset.
Building an ESC-50 Dataset
We’ve talked about datasets in Chapter 2, but torchvision and torchtext did all the heavy lifting for us, so we didn’t have to worry too much about the details. As you may remember, a custom dataset has to implement two class methods, __getitem__ and __len__, so that the data loader can get a batch of tensors and their labels, as well as a total count of tensors in the dataset. We also have an __init__ method for setting up things like file paths that’ll be used over and over again.
Here’s our first pass at the ESC-50 dataset:
classESC50(Dataset):def__init__(self,path):# Get directory listing from pathfiles=Path(path).glob('*.wav')# Iterate through the listing and create a list of tuples (filename, label)self.items=[(f,int(f.name.split("-")[-1].replace(".wav","")))forfinfiles]self.length=len(self.items)def__getitem__(self,index):filename,label=self.items[index]audio_tensor,sample_rate=torchaudio.load(filename)returnaudio_tensor,labeldef__len__(self):returnself.length
The majority of the work in the class happens when a new instance of it is created. The __init__ method takes the path parameter, finds all the WAV files inside that path, and then produces tuples of (filename, label) by using the same string split we used earlier in the chapter to get the label of that audio sample. When PyTorch requests an item from the dataset, we index into the items list, use torchaudio.load to make torchaudio load in the audio file, turn it into a tensor, and then return both the tensor and the label.
And that’s enough for us to start with. For a sanity check, let’s create an ESC50 object and extract the first item:
test_esc50=ESC50(PATH_TO_ESC50)tensor,label=list(test_esc50)[0]tensortensor([-0.0128,-0.0131,-0.0143,...,0.0000,0.0000,0.0000])tensor.shapetorch.Size([220500])label'15'
We can construct a data loader by using standard PyTorch constructs:
example_loader=torch.utils.data.DataLoader(test_esc50,batch_size=64,shuffle=True)
But before we do that, we have to go back to our data. As you might remember, we should always create training, validation, and test sets. At the moment, we have just one directory with all the data, which is no good for our purposes. A 60/20/20 split of data into training, validation, and test collections should suffice. Now, we could do this by taking random samples of our entire dataset (taking care to sample without replacement and making sure that our newly constructed datasets are still balanced), but again the ESC-50 dataset saves us from having to do much work. The compilers of the dataset separated the data into five equal balanced folds, indicated by the first digit in the filename. We’ll have folds 1,2,3 be the training set, 4 the validation set, and 5 the test set. But feel free to mix it up if you don’t want to be boring and consecutive! Move each of the folds to test, train, and validation directories:
mv 1* ../train mv 2* ../train mv 3* ../train mv 4* ../valid mv 5* ../test
Now we can create the individual datasets and loaders:
frompathlibimportPathbs=64PATH_TO_ESC50=Path.cwd()/'esc50'path='test.md'testtrain_esc50=ESC50(PATH_TO_ESC50/"train")valid_esc50=ESC50(PATH_TO_ESC50/"valid")test_esc50=ESC50(PATH_TO_ESC50/"test")train_loader=torch.utils.data.DataLoader(train_esc50,batch_size=bs,shuffle=True)valid_loader=torch.utils.data.DataLoader(valid_esc50,batch_size=bs,shuffle=True)test_loader=torch.utils.data.DataLoader(test_esc50,batch_size=bs,shuffle=True)
We have our data all set up, so we’re all ready to look at a classification model.
A CNN Model for ESC-50
For our first attempt at classifying sounds, we build a model that borrows heavily from a paper called “Very Deep Convolutional Networks For Raw Waveforms.”2 You’ll see that it uses a lot of our building blocks from Chapter 3, but instead of using 2D layers, we’re using 1D variants, as we have one fewer dimension in our audio input:
classAudioNet(nn.Module):def__init__(self):super(AudioNet,self).__init__()self.conv1=nn.Conv1d(1,128,80,4)self.bn1=nn.BatchNorm1d(128)self.pool1=nn.MaxPool1d(4)self.conv2=nn.Conv1d(128,128,3)self.bn2=nn.BatchNorm1d(128)self.pool2=nn.MaxPool1d(4)self.conv3=nn.Conv1d(128,256,3)self.bn3=nn.BatchNorm1d(256)self.pool3=nn.MaxPool1d(4)self.conv4=nn.Conv1d(256,512,3)self.bn4=nn.BatchNorm1d(512)self.pool4=nn.MaxPool1d(4)self.avgPool=nn.AvgPool1d(30)self.fc1=nn.Linear(512,10)defforward(self,x):x=self.conv1(x)x=F.relu(self.bn1(x))x=self.pool1(x)x=self.conv2(x)x=F.relu(self.bn2(x))x=self.pool2(x)x=self.conv3(x)x=F.relu(self.bn3(x))x=self.pool3(x)x=self.conv4(x)x=F.relu(self.bn4(x))x=self.pool4(x)x=self.avgPool(x)x=x.permute(0,2,1)x=self.fc1(x)returnF.log_softmax(x,dim=2)
We also need an optimizer and a loss function. For the optimizer, we use Adam as before, but what loss function do you think we should use? (If you answered CrossEntropyLoss, give yourself a gold star!)
audio_net=AudioNet()audio_net.to(device)
Having created our model, we save our weights and use the find_lr() function from Chapter 4:
audio_net.save("audionet.pth")importtorch.optimasoptimoptimizer=optim.Adam(audionet.parameters(),lr=0.001)logs,losses=find_lr(audio_net,nn.CrossEntropyLoss(),optimizer)plt.plot(logs,losses)
From the plot in Figure 6-3, we determine that the appropriate learning rate is around 1e-5 (based on where the descent looks steepest). We set that to be our learning rate and reload our model’s initial weights:

Figure 6-3. AudioNet learning rate plot
lr=1e-5model.load("audionet.pth")importtorch.optimasoptimoptimizer=optim.Adam(audionet.parameters(),lr=lr)
We train the model for 20 epochs:
train(audio_net,optimizer,torch.nn.CrossEntropyLoss(),train_data_loader,valid_data_loader,epochs=20)
After training, you should find that the model attains around 13%–17% accuracy on our dataset. That’s better than the 2% we could expect if we were just picking one of the 50 classes at random. But perhaps we can do better; let’s investigate a different way of looking at our audio data that may yield better results.
This Frequency Is My Universe
If you look back at the GitHub page for ESC-50, you’ll see a leaderboard of network architectures and their accuracy scores. You’ll notice that in comparison, we’re not doing great. We could extend the model we’ve created to be deeper, and that would likely increase our accuracy a little, but for a real increase in performance, we need to switch domains. In audio processing, you can work on the pure waveform as we’ve been doing; but most of the time, you’ll work in the frequency domain. This different representation transforms the raw waveform into a view that shows all of the frequencies of sound at a given point in time. This is perhaps a more information-rich representation to present to a neural network, as it’ll be able to work on those frequencies directly, rather than having to work out how to map the raw waveform signal into something the model can use.
Let’s look at how to generate frequency spectrograms with LibROSA.
Mel Spectrograms
Traditionally, getting into the frequency domain requires applying the Fourier transform on the audio signal. We’re going to go beyond that a little by generating our spectrograms in the mel scale. The mel scale defines a scale of pitches that are equal in distance from another, where 1000 mels = 1000 Hz. This scale is commonly used in audio processing, especially in speech recognition and classification applications. Producing a mel spectrogram with LibROSA requires two lines of code:
sample_data,sr=librosa.load("ESC-50/train/1-100032-A-0.wav",sr=None)spectrogram=librosa.feature.melspectrogram(sample_data,sr=sr)
This results in a NumPy array containing the spectrogram data. If we display this spectrogram as shown in Figure 6-4, we can see the frequencies in our sound:
librosa.display.specshow(spectrogram,sr=sr,x_axis='time',y_axis='mel')
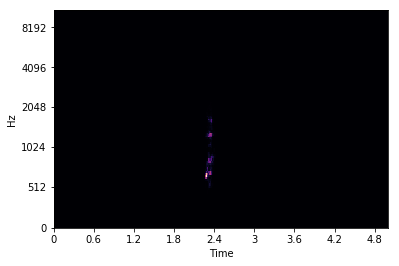
Figure 6-4. Mel spectrogram
However, not a lot of information is present in the image. We can do better! If we convert the spectrogram to a logarithmic scale, we can see a lot more of the audio’s structure, due to the scale being able to represent a wider range of values. And this is common enough in audio procressing that LibROSA includes a method for it:
log_spectrogram=librosa.power_to_db(spectrogram,ref=np.max)
This computes a scaling factor of 10 * log10(spectrogram / ref). ref defaults to 1.0, but here we’re passing in np.max() so that spectrogram / ref will fall within the range of [0,1]. Figure 6-5 shows the new spectrogram.

Figure 6-5. Log mel spectrogram
We now have a log-scaled mel spectrogram! If you call log_spectrogram.shape, you’ll see it’s a 2D tensor, which makes sense because we’ve plotted images with the tensor. We could create a new neural network architecture and feed this new data into it, but I have a diabolical trick up my sleeve. We literally just generated images of the spectrogram data. Why don’t we work on those instead?
This might seem silly at first; after all, we have the underlying spectrogram data, and that’s more exact than the image representation (to our eyes, knowing that a data point is 58 rather than 60 means more to us than a different shade of, say, purple). And if we were starting from scratch, that’d definitely be the case. But! We have, just lying around the place, already-trained networks such as ResNet and Inception that we know are amazing at recognizing structure and other parts of images. We can construct image representations of our audio and use a pretrained network to make big jumps in accuracy with very little training by using the super power of transfer learning once again. This could be useful with our dataset, as we don’t have a lot of examples (only 2,000!) to train our network.
This trick can be employed across many disparate datasets. If you can find a way of cheaply turning your data into an image representation, it’s worth doing that and throwing a ResNet network against it to get a baseline of what transfer learning can do for you, so you know what you have to beat by using a different approach. Armed with this, let’s create a new dataset that will generate these images for us on demand.
A New Dataset
Now throw away the original ESC50 dataset class and build a new one, ESC50Spectrogram. Although this will share some code with the older class, quite a lot more is going on in the __get_item__ method in this version. We generate the spectrogram by using LibROSA, and then we do some fancy matplotlib footwork to get the data into a NumPy array. We apply the array to our transformation pipeline (which just uses ToTensor) and return that and the item’s label. Here’s the code:
classESC50Spectrogram(Dataset):def__init__(self,path):files=Path(path).glob('*.wav')self.items=[(f,int(f.name.split("-")[-1].replace(".wav","")))forfinfiles]self.length=len(self.items)self.transforms=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])def__getitem__(self,index):filename,label=self.items[index]audio_tensor,sample_rate=librosa.load(filename,sr=None)spectrogram=librosa.feature.melspectrogram(audio_tensor,sr=sample_rate)log_spectrogram=librosa.power_to_db(spectrogram,ref=np.max)librosa.display.specshow(log_spectrogram,sr=sample_rate,x_axis='time',y_axis='mel')plt.gcf().canvas.draw()audio_data=np.frombuffer(fig.canvas.tostring_rgb(),dtype=np.uint8)audio_data=audio_data.reshape(fig.canvas.get_width_height()[::-1]+(3,))return(self.transforms(audio_data),label)def__len__(self):returnself.length
We’re not going to spend too much time on this version of the dataset because it has a large flaw, which I demonstrate with Python’s process_time() method:
oldESC50=ESC50("ESC-50/train/")start_time=time.process_time()oldESC50.__getitem__(33)end_time=time.process_time()old_time=end_time-start_timenewESC50=ESC50Spectrogram("ESC-50/train/")start_time=time.process_time()newESC50.__getitem__(33)end_time=time.process_time()new_time=end_time-start_timeold_time=0.004786839000075815new_time=0.39544327499993415
The new dataset is almost one hundred times slower than our original one that just returned the raw audio! That will make training incredibly slow, and may even negate any of the benefits we could get from using transfer learning.
We can use a couple of tricks to get around most of our troubles here. The first approach would be to add a cache to store the generated spectrogram in memory, so we don’t have to regenerate it every time the __getitem__ method is called. Using Python’s functools package, we can do this easily:
importfunctoolsclassESC50Spectrogram(Dataset):#skipping init code@functools.lru_cache(maxsize=<sizeofdataset>)def__getitem__(self,index):
Provided you have enough memory to store the entire contents of the dataset into RAM, this may be good enough. We’ve set up a least recently used (LRU) cache that will keep the contents in memory for as long as possible, with indices that haven’t been accessed recently being the first for ejection from the cache when memory gets tight. However, if you don’t have enough memory to store everything, you’ll hit slowdowns on every batch iteration as ejected spectrograms need to be regenerated.
My preferred approach is to precompute all the possible plots and then create a new custom dataset class that loads these images from the disk. (You can even add the LRU cache annotation as well for further speed-up.)
We don’t need to do anything fancy for precomputing, just a method that saves the plots into the same directory it’s traversing:
defprecompute_spectrograms(path,dpi=50):files=Path(path).glob('*.wav')forfilenameinfiles:audio_tensor,sample_rate=librosa.load(filename,sr=None)spectrogram=librosa.feature.melspectrogram(audio_tensor,sr=sr)log_spectrogram=librosa.power_to_db(spectrogram,ref=np.max)librosa.display.specshow(log_spectrogram,sr=sr,x_axis='time',y_axis='mel')plt.gcf().savefig("{}{}_{}.png".format(filename.parent,dpi,filename.name),dpi=dpi)
This method is simpler than our previous dataset because we can use matplotlib’s savefig method to save a plot directly to disk rather than having to mess around with NumPy. We also provide an additional input parameter, dpi, which allows us to control the quality of the generated output. Run this on all the train, test, and valid paths that we have already set up (it will likely take a couple of hours to get through all the images).
All we need now is a new dataset that reads these images. We can’t use the standard ImageDataLoader from Chapters 2–4, as the PNG filename scheme doesn’t match the directory structure that it uses. But no matter, we can just open an image by using the Python Imaging Library:
fromPILimportImageclassPrecomputedESC50(Dataset):def__init__(self,path,dpi=50,transforms=None):files=Path(path).glob('{}*.wav.png'.format(dpi))self.items=[(f,int(f.name.split("-")[-1].replace(".wav.png","")))forfinfiles]self.length=len(self.items)iftransforms=None:self.transforms=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])else:self.transforms=transformsdef__getitem__(self,index):filename,label=self.items[index]img=Image.open(filename)return(self.transforms(img),label)def__len__(self):returnself.length
This code is much simpler, and hopefully that’s also reflected in the time it takes to get an entry from the dataset:
start_time=time.process_time()b.__getitem__(33)end_time=time.process_time()end_time-start_time>>0.0031465259999094997
Obtaining an element from this dataset takes roughly the same time as in our original audio-based one, so we won’t be losing anything by moving to our image-based approach, except for the one-time cost of precomputing all the images before creating the database. We’ve also supplied a default transform pipeline that turns an image into a tensor, but it can be swapped out for a different pipeline during initialization. Armed with these optimizations, we can start to apply transfer learning to the problem.
A Wild ResNet Appears
As you may remember from Chapter 4, transfer learning requires that we take a model that has already been trained on a particular dataset (in the case of images, likely ImageNet), and then fine-tune it on our particular data domain, the ESC-50 dataset that we’re turning into spectrogram images. You might be wondering whether a model that is trained on normal photographs is of any use to us. It turns out that the pretrained models do learn a lot of structure that can be applied to domains that at first glance might seem wildly different. Here’s our code from Chapter 4 that initializes a model:
fromtorchvisionimportmodelsspec_resnet=models.ResNet50(pretrained=True)forparaminspec_resnet.parameters():param.requires_grad=Falsespec_resnet.fc=nn.Sequential(nn.Linear(spec_resnet.fc.in_features,500),nn.ReLU(),nn.Dropout(),nn.Linear(500,50))
This initializes us with a pretrained (and frozen) ResNet50 model and swaps out the head of the model for an untrained Sequential module that ends with a Linear with an output of 50, one for each of the classes in the ESC-50 dataset. We also need to create a DataLoader that takes our precomputed spectrograms. When we create our ESC-50 dataset, we’ll also want to normalize the incoming images with the standard ImageNet standard deviation and mean, as that’s what the pretrained ResNet-50 architecture was trained with. We can do that by passing in a new pipeline:
esc50pre_train=PreparedESC50(PATH,transforms=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])]))esc50pre_valid=PreparedESC50(PATH,transforms=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])]))esc50_train_loader=(esc50pre_train,bs,shuffle=True)esc50_valid_loader=(esc50pre_valid,bs,shuffle=True)
With our data loaders set up, we can move on to finding a learning rate and get ready to train.
Finding a Learning Rate
We need to find a learning rate to use in our model. As in Chapter 4, we’ll save the model’s initial parameters and use our find_lr() function to find a decent learning rate for training. Figure 6-6 shows the plot of the losses against the learning rate.
spec_resnet.save("spec_resnet.pth")loss_fn=nn.CrossEntropyLoss()optimizer=optim.Adam(spec_resnet.parameters(),lr=lr)logs,losses=find_lr(spec_resnet,loss_fn,optimizer)plt.plot(logs,losses)

Figure 6-6. A SpecResNet learning rate plot
Looking at the graph of the learning rate plotted against loss, it seems like 1e-2 is a good place to start. As our ResNet-50 model is somewhat deeper than our previous one, we’re also going to use differential learning rates of [1e-2,1e-4,1e-8], with the highest learning rate applied to our classifier (as it requires the most training!) and slower rates for the already-trained backbone. Again, we use Adam as our optimizer, but feel free to experiment with the others available.
Before we apply those differential rates, though, we train for a few epochs that update only the classifier, as we froze the ResNet-50 backbone when we created our network:
optimizer=optim.Adam(spec_resnet.parameters(),lr=[1e-2,1e-4,1e-8])train(spec_resnet,optimizer,nn.CrossEntropyLoss(),esc50_train_loader,esc50_val_loader,epochs=5,device="cuda")
We now unfreeze the backbone and apply our differential rates:
forparaminspec_resnet.parameters():param.requires_grad=Trueoptimizer=optim.Adam(spec_resnet.parameters(),lr=[1e-2,1e-4,1e-8])train(spec_resnet,optimizer,nn.CrossEntropyLoss(),esc50_train_loader,esc50_val_loader,epochs=20,device="cuda")>Epoch19,accuracy=0.80
As you can see, with a validation accuracy of around 80%, we’re already vastly outperforming our original AudioNet model. The power of transfer learning strikes again! Feel free to train for more epochs to see if your accuracy continues to improve. If we look at the ESC-50 leaderboard, we’re closing in on human-level accuracy. And that’s just with ResNet-50. You could try with ResNet-101 and perhaps an ensemble of different architectures to push the score up even higher.
And there’s data augmentation to consider. Let’s take a look at a few ways of doing that in both domains that we’ve been working in so far.
Audio Data Augmentation
When we were looking at images in Chapter 4, we saw that we could improve the accuracy of our classifier by making changes to our incoming pictures. By flipping them, cropping them, or applying other transformations, we made our neural network work harder in the training phase and obtained a more generalized model at the end of it, one that was not simply fitting to the data presented (the scourge of overfitting, don’t forget). Can we do the same here? Yes! In fact, there are two approaches that we can use—one obvious approach that works on the original audio waveform, and a perhaps less-obvious idea that arises from our decision to use a ResNet-based classifier on images of mel spectrograms. Let’s take a look at audio transforms first.
torchaudio Transforms
In a similar manner to torchvision, torchaudio includes a transforms module that perform transformations on incoming data. However, the number of transformations offered is somewhat sparse, especially compared to the plethora that we get when we’re working with images. If you’re interested, have a look at the documentation for a full list, but the only one we look at here is torchaudio.transforms.PadTrim. In the ESC-50 dataset, we are fortunate in that every audio clip is the same length. That isn’t something that happens in the real world, but our neural networks like (and sometimes insist on, depending on how they’re constructed) input data to be regular. PadTrim will take an incoming audio tensor and either pad it out to the required length, or trim it down so it doesn’t exceed that length. If we wanted to trim down a clip to a new length, we’d use PadTrim like this:
audio_tensor,rate=torchaudio.load("test.wav")audio_tensor.shapetrimmed_tensor=torchaudio.transforms.PadTrim(max_len=1000)(audio_orig)
However, if you’re looking for augmentation that actually changes how the audio sounds (e.g., adding an echo, noise, or changing the tempo of the clip), then the torchaudio.transforms module is of no use to you. Instead, we need to use SoX.
SoX Effect Chains
Why it’s not part of the transforms module, I’m really not sure, but torchaudio.sox_effects.SoxEffectsChain allows you to create a chain of one or more SoX effects and apply those to an input file. The interface is a bit fiddly, so let’s see it in action in a new version of the dataset that changes the pitch of the audio file:
classESC50WithPitchChange(Dataset):def__init__(self,path):# Get directory listing from pathfiles=Path(path).glob('*.wav')# Iterate through the listing and create a list of tuples (filename, label)self.items=[(f,f.name.split("-")[-1].replace(".wav",""))forfinfiles]self.length=len(self.items)self.E=torchaudio.sox_effects.SoxEffectsChain()self.E.append_effect_to_chain("pitch",[0.5])def__getitem__(self,index):filename,label=self.items[index]self.E.set_input_file(filename)audio_tensor,sample_rate=self.E.sox_build_flow_effects()returnaudio_tensor,labeldef__len__(self):returnself.length
In our __init__ method, we create a new instance variable, E, a SoxEffectsChain, that will contain all the effects that we want to apply to our audio data. We then add a new effect by using append_effect_to_chain, which takes a string indicating the name of the effect, and an array of parameters to send to sox. You can get a list of available effects by calling torchaudio.sox_effects.effect_names(). If we were to add another effect, it would take place after the pitch effect we have already set up, so if you want to create a list of separate effects and randomly apply them, you’ll need to create separate chains for each one.
When it comes to selecting an item to return to the data loader, things are a little different. Instead of using torchaudio.load(), we refer to our effects chain and point it to the file by using set_input_file. But note that this doesn’t load the file! Instead, we have to use sox_build_flow_effects(), which kicks off SoX in the background, applies the effects in the chain, and returns the tensor and sample rate information we would have otherwise obtained from load().
The number of things that SoX can do is pretty staggering, and I won’t go into more detail on all the possible effects you could use. I suggest having a look at the SoX documentation in conjunction with list_effects() to see the possibilities.
These transformations allow us to alter the original audio, but we’ve spent quite a bit of this chapter building up a processing pipeline that works on images of mel spectrograms. We could do what we did to generate the initial dataset for that pipeline, by creating altered audio samples and then creating the spectrograms from them, but at that point we’re creating an awful lot of data that we will need to mix together at run-time. Thankfully, we can do some transformations on the spectrograms themselves.
SpecAugment
Now, you might be thinking at this point: “Wait, these spectrograms are just images! We can use any image transform we want on them!” And yes! Gold star for you in the back. But we do have to be a little careful; it’s possible, for example, that a random crop may cut out enough frequencies that it potentially changes the output class. This is much less of an issue in our ESC-50 dataset, but if you were doing something like speech recognition, that would definitely be something you’d have to consider when applying augmentations. Another intriguing possibility is that because we know that all the spectrograms have the same structure (they’re always going to be a frequency graph!), we could create image-based transforms that work specifically around that structure.
In 2019, Google released a paper on SpecAugment,3 which reported new state-of-the-art results on many audio datasets. The team obtained these results by using three new data augmentation techniques that they applied directly to a mel spectrogram: time warping, frequency masking, and time masking. We won’t look at time warping because the benefit derived from it is small, but we’ll implement custom transforms for masking time and frequency.
Frequency masking
Frequency masking randomly removes a frequency or set of frequencies from our audio input. This attempts to make the model work harder; it cannot simply memorize an input and its class, because the input will have different frequencies masked during each batch. The model will instead have to learn other features that can determine how to map the input to a class, which hopefully should result in a more accurate model.
In our mel spectrograms, this is shown by making sure that nothing appears in the spectrograph for that frequency at any time step. Figure 6-7 shows what this looks like: essentially, a blank line drawn across a natural spectrogram.
Here’s the code for a custom Transform that implements frequency masking:
classFrequencyMask(object):"""Example:>>> transforms.Compose([>>> transforms.ToTensor(),>>> FrequencyMask(max_width=10, use_mean=False),>>> ])"""def__init__(self,max_width,use_mean=True):self.max_width=max_widthself.use_mean=use_meandef__call__(self,tensor):"""Args:tensor (Tensor): Tensor image ofsize (C, H, W) where the frequencymask is to be applied.Returns:Tensor: Transformed image with Frequency Mask."""start=random.randrange(0,tensor.shape[2])end=start+random.randrange(1,self.max_width)ifself.use_mean:tensor[:,start:end,:]=tensor.mean()else:tensor[:,start:end,:]=0returntensordef__repr__(self):format_string=self.__class__.__name__+"(max_width="format_string+=str(self.max_width)+")"format_string+='use_mean='+(str(self.use_mean)+')')returnformat_string
When the transform is applied, PyTorch will call the __call__ method with the tensor representation of the image (so we need to place it in a Compose chain after the image has been converted to a tensor, not before). We’re assuming that the tensor will be in channels × height × width format, and we want to set the height values in a small range, to either zero or the mean of the image (because we’re using log mel spectrograms, the mean should be the same as zero, but we include both options so you can experiment to see if one works better than the other). The range is provided by the max_width parameter, and our resulting pixel mask will be between 1 and max_pixels wide. We also need to pick a random starting point for the mask, which is what the start variable is for. Finally, the complicated part of this transform—we apply our generated mask:
tensor[:, start:end, :] = tensor.mean()
This isn’t quite so bad when we break it down. Our tensor has three dimensions, but we want to apply this transform across all the red, green, and blue channels, so we use the bare : to select everything in that dimension. Using start:end, we select our height range, and then we select everything in the width channel, as we want to apply our mask across every time step. And then on the righthand side of the expression, we set the value; in this case, tensor.mean(). If we take a random tensor from the ESC-50 dataset and apply the transform to it, we can see in Figure 6-7 that this class is creating the required mask.
torchvision.transforms.Compose([FrequencyMask(max_width=10,use_mean=False),torchvision.transforms.ToPILImage()])(torch.rand(3,250,200))

Figure 6-7. Frequency mask applied to a random ESC-50 sample
Next we’ll turn our attention to time masking.
Time masking
With our frequency mask complete, we can turn to the time mask, which does the same as the frequency mask, but in the time domain. The code here is mostly the same:
classTimeMask(object):"""Example:>>> transforms.Compose([>>> transforms.ToTensor(),>>> TimeMask(max_width=10, use_mean=False),>>> ])"""def__init__(self,max_width,use_mean=True):self.max_width=max_widthself.use_mean=use_meandef__call__(self,tensor):"""Args:tensor (Tensor): Tensor image ofsize (C, H, W) where the time maskis to be applied.Returns:Tensor: Transformed image with Time Mask."""start=random.randrange(0,tensor.shape[1])end=start+random.randrange(0,self.max_width)ifself.use_mean:tensor[:,:,start:end]=tensor.mean()else:tensor[:,:,start:end]=0returntensordef__repr__(self):format_string=self.__class__.__name__+"(max_width="format_string+=str(self.max_width)+")"format_string+='use_mean='+(str(self.use_mean)+')')returnformat_string
As you can see, this class is similar to the frequency mask. The only difference is that our start variable now ranges at some point on the height axis, and when we’re doing our masking, we do this:
tensor[:, :, start:end] = 0
This indicates that we select all the values of the first two dimensions of our tensor and the start:end range in the last dimension. And again, we can apply this to a random tensor from ESC-50 to see that the mask is being applied correctly, as shown in Figure 6-8.
torchvision.transforms.Compose([TimeMask(max_width=10,use_mean=False),torchvision.transforms.ToPILImage()])(torch.rand(3,250,200))

Figure 6-8. Time mask applied to a random ESC-50 sample
To finish our augmentation, we create a new wrapper transformation that ensures that one or both of the masks is applied to a spectrogram image:
classPrecomputedTransformESC50(Dataset):def__init__(self,path,dpi=50):files=Path(path).glob('{}*.wav.png'.format(dpi))self.items=[(f,f.name.split("-")[-1].replace(".wav.png",""))forfinfiles]self.length=len(self.items)self.transforms=transforms.Compose([transforms.ToTensor(),RandomApply([FrequencyMask(self.max_freqmask_width)]p=0.5),RandomApply([TimeMask(self.max_timemask_width)]p=0.5)])def__getitem__(self,index):filename,label=self.items[index]img=Image.open(filename)return(self.transforms(img),label)def__len__(self):returnself.length
Try rerunning the training loop with this data augmentation and see if you, like Google, achieve better accuracy with these masks. But maybe there’s still more that we can try with this dataset?
Further Experiments
So far, we’ve created two neural networks—one based on the raw audio waveform, and the other based on the images of mel spectrograms—to classify sounds from the ESC-50 dataset. Although you’ve seen that the ResNet-powered model is more accurate using the power of transfer learning, it would be an interesting experiment to create a combination of the two networks to see whether that increases or decreases the accuracy. A simple way of doing this would be to revisit the ensembling approach from Chapter 4: just combine and average the predictions. Also, we skipped over the idea of building a network based on the raw data we were getting from the spectrograms. If a model is created that works on that data, does it help overall accuracy if it is introduced to the ensemble? We can also use other versions of ResNet, or we could create new architectures that use different pretrained models such as VGG or Inception as a backbone. Explore some of these options and see what happens; in my experiments, SpecAugment improves ESC-50 classification accuracy by around 2%.
Conclusion
In this chapter, we used two very different strategies for audio classification, took a brief tour of PyTorch’s torchaudio library, and saw how to precompute transformations on datasets when doing transformations on the fly would have a severe impact on training time. We discussed two approaches to data augmentation. As an unexpected bonus, we again stepped through how to train an image-based model by using transfer learning to quickly generate a classifier with decent accuracy compared to the others on the ESC-50 leaderboard.
This wraps up our tour through images, test, and audio, though we return to all three in Chapter 9 when we look at some applications that use PyTorch. Next up, though, we look at how to debug models when they’re not training quite right or fast enough.
Further Reading
-
“Interpreting and Explaining Deep Neural Networks for Classification of Audio Signals” by Sören Becker et al. (2018)
-
“CNN Architectures for Large-Scale Audio Classification” by Shawn Hershey et al. (2016)
1 Understanding all of what SoX can do is beyond the scope of this book, and won’t be necessary for what we’re going to be doing in the rest of this chapter.
2 See “Very Deep Convolutional Neural Networks for Raw Waveforms” by Wei Dai et al. (2016).
3 See “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition” by Daniel S. Park et al. (2019).